Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Gebruik de volgende strategieën om de prestatie van transformaties in gegevensmappingstromen in de Azure Data Factory en Azure Synapse Analytics pijplijnen te optimaliseren.
Joins, Exists en Lookups optimaliseren
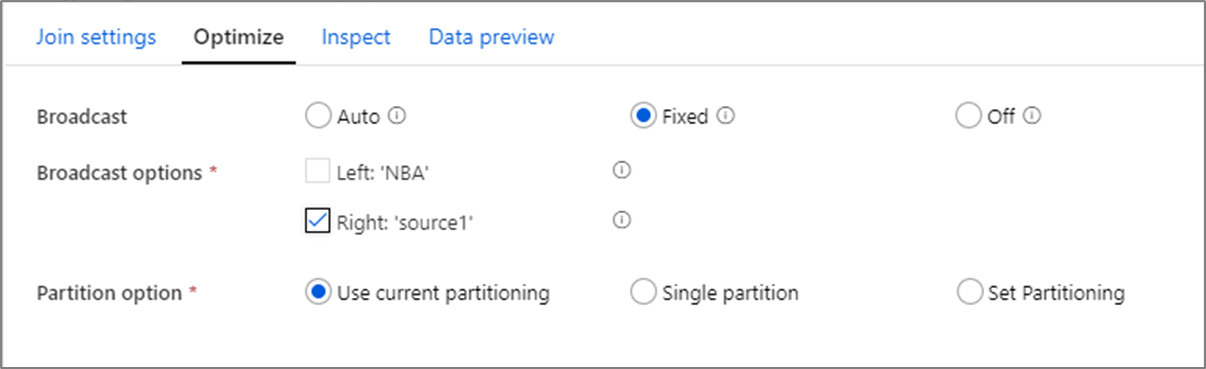
Uitzenden
Bij joins, lookups en exists-transformaties, als een of beide gegevensstromen klein genoeg zijn om in het geheugen van het werkknooppunt te passen, kunt u de prestaties optimaliseren door Broadcasting in te schakelen. Uitzenden is wanneer u kleine gegevensframes naar alle knooppunten in het cluster verzendt. Hierdoor kan de Spark-engine een join uitvoeren zonder de gegevens in de grote stroom opnieuw te schudden. Standaard bepaalt de Spark-engine automatisch of één kant van een join moet worden uitgezonden. Als u vertrouwd bent met de binnenkomende gegevens en weet dat de ene stream kleiner is dan de andere, kunt u Fixed broadcasting selecteren. Vaste uitzending dwingt Spark om de geselecteerde stream uit te zenden.
Als de grootte van de uitgezonden gegevens te groot is voor het Spark-knooppunt, kan er een geheugenfout optreden. Als u geheugenfouten wilt voorkomen, gebruikt u clusters die zijn geoptimaliseerd voor geheugen . Als u time-outs ondervindt tijdens gegevensstroomuitvoeringen, kunt u de broadcastoptimalisatie uitschakelen. Dit resulteert echter in tragere uitvoering van gegevensstromen.
Wanneer u werkt met gegevensbronnen die langer duren om te worden opgevraagd, zoals bij grote databasequery's, is het raadzaam om broadcast uit te schakelen voor join-operaties. Bron met lange querytijden kan leiden tot Spark-time-outs wanneer het cluster probeert uit te zenden naar rekenknooppunten. Een andere goede keuze voor het uitschakelen van broadcast is wanneer u een stream in uw gegevensstroom hebt die waarden samenvoegt voor gebruik in een opzoektransformatie later. Dit patroon kan de Optimalisatie van Spark verwarren en time-outs veroorzaken.
Kruisvermeldingen
Als u letterlijke waarden in uw joinvoorwaarden gebruikt of meerdere overeenkomsten aan beide zijden van een join hebt, wordt de join als cross join uitgevoerd. Een cross join is een volledig cartesisch product dat vervolgens de samengevoegde waarden filtert. Dit is langzamer dan andere join-typen. Zorg ervoor dat u kolomverwijzingen aan beide zijden van uw joinvoorwaarden hebt om de gevolgen voor de prestaties te voorkomen.
Sorteren voor joins
In tegenstelling tot samenvoegen in hulpprogramma's zoals SSIS, is de samenvoegtransformatie geen verplichte samenvoegbewerking. Voor de joinsleutels is geen sortering vereist voordat de transformatie wordt uitgevoerd. Het gebruik van sorteertransformaties in gegevensstromen binnen mappings wordt niet aanbevolen.
Prestaties van venstertransformatie
Met de venstertransformatie in gegevensafstroom worden uw gegevens volgens waarde gepartitioneerd in kolommen die u selecteert als onderdeel van de over() clausule in de transformatie-instellingen. Er zijn veel populaire statistische en analytische functies die beschikbaar zijn in de Windows-transformatie. Als uw use-case echter is om een venster te genereren voor de volledige gegevensset voor rangschikking rank() of rijnummer rowNumber(), wordt u aangeraden in plaats daarvan de rangschikkingstransformatie en de surrogaatsleuteltransformatie te gebruiken. Deze transformaties voeren betere volledige gegevenssetbewerkingen uit met behulp van deze functies.
Scheve gegevens opnieuw partitioneren
Bepaalde transformaties, zoals joins en aggregaties, herschikken uw gegevenspartities en kunnen af en toe leiden tot scheefgetrokken gegevens. Scheve gegevens betekent dat gegevens niet gelijkmatig over de partities worden verdeeld. Sterk scheefgetrokken gegevens kunnen leiden tot tragere downstreamtransformaties en sink-schrijfbewerkingen. U kunt de scheefheid van uw gegevens op elk moment in een gegevensstroom controleren door te klikken op de transformatie in de bewakingsweergave.
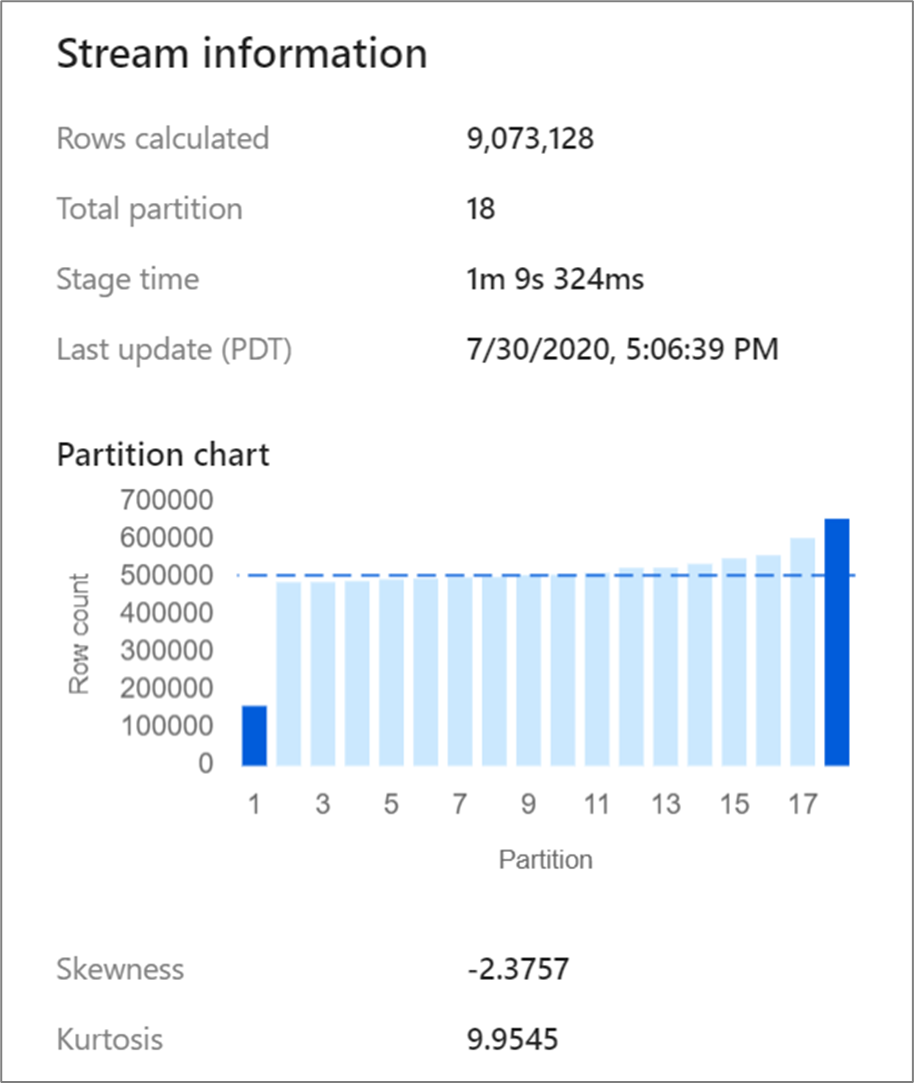
De bewakingsweergave laat zien hoe de gegevens over elke partitie worden verdeeld, samen met twee metrische gegevens, scheefheid en kurtosis. Scheefheid is een meting van hoe asymmetrisch de gegevens zijn en kan een positieve, nul, negatieve of niet-gedefinieerde waarde hebben. Negatieve scheefheid betekent dat de linkerstaart langer is dan de rechterzijde. Kurtosis is de maatstaf voor of de gegevens een zware staart of een lichte staart hebben. Hoge kurtosiswaarden zijn niet wenselijk. Ideale intervallen van scheefheid liggen tussen -3 en 3 en intervallen van kurtosis zijn kleiner dan 10. Een eenvoudige manier om deze getallen te interpreteren, is het bekijken van de partitiegrafiek en zien of 1 staaf groter is dan de rest.
Als uw gegevens na een transformatie niet gelijkmatig zijn gepartitioneerd, kunt u het tabblad Optimaliseren gebruiken om opnieuw te partitioneren. Het opnieuw inschakelen van gegevens kost tijd en kan de prestaties van uw gegevensstroom mogelijk niet verbeteren.
Aanbeveling
Als u uw gegevens opnieuw partitioneert maar vervolgtransformaties hebt die uw gegevens opnieuw indelen, gebruik hashpartitionering op een kolom die als joinsleutel wordt gebruikt.
Opmerking
Transformaties in uw gegevensstroom (met uitzondering van de Sink-transformatie) wijzigen het partitioneren van gegevens in rust niet. Partitionering in elke transformatie verdeelt gegevens in de dataframes van het serverloze, tijdelijke Spark-cluster dat ADF beheert voor elke gegevensstroomuitvoering.
Verwante inhoud
- Overzicht van prestaties van gegevensstromen
- Bronnen optimaliseren
- Sinks optimaliseren
- Gegevensstromen gebruiken in pijplijnen
Zie andere artikelen over gegevensstromen met betrekking tot prestaties: