Bronnen optimaliseren
Voor elke bron, met uitzondering van Azure SQL Database, is het raadzaam om huidige partitionering te blijven gebruiken als de geselecteerde waarde. Wanneer u gegevens leest uit alle andere bronsystemen, worden gegevens automatisch gelijkmatig gepartitioneert op basis van de grootte van de gegevens. Er wordt een nieuwe partitie gemaakt voor ongeveer elke 128 MB aan gegevens. Naarmate de gegevensgrootte toeneemt, neemt het aantal partities toe.
Aangepaste partitionering vindt plaats nadat Spark de gegevens heeft gelezen en negatieve invloed heeft op de prestaties van uw gegevensstroom. Omdat de gegevens gelijkmatig zijn gepartitioneerd bij lezen, wordt dit niet aanbevolen, tenzij u eerst de vorm en kardinaliteit van uw gegevens begrijpt.
Notitie
Leessnelheden kunnen worden beperkt door de doorvoer van uw bronsysteem.
Azure SQL Database-bronnen
Azure SQL Database heeft een unieke partitioneringsoptie met de naam Bronpartitionering. Als u bronpartitionering inschakelt, kunt u de leestijden van Azure SQL Database verbeteren door parallelle verbindingen op het bronsysteem in te schakelen. Geef het aantal partities op en hoe u uw gegevens partitioneert. Gebruik een partitiekolom met een hoge kardinaliteit. U kunt ook een query invoeren die overeenkomt met het partitioneringsschema van uw brontabel.
Tip
Voor bronpartitionering is de I/O van de SQL Server het knelpunt. Als u te veel partities toevoegt, kan uw brondatabase overbelast raken. Over het algemeen is vier of vijf partities ideaal bij het gebruik van deze optie.
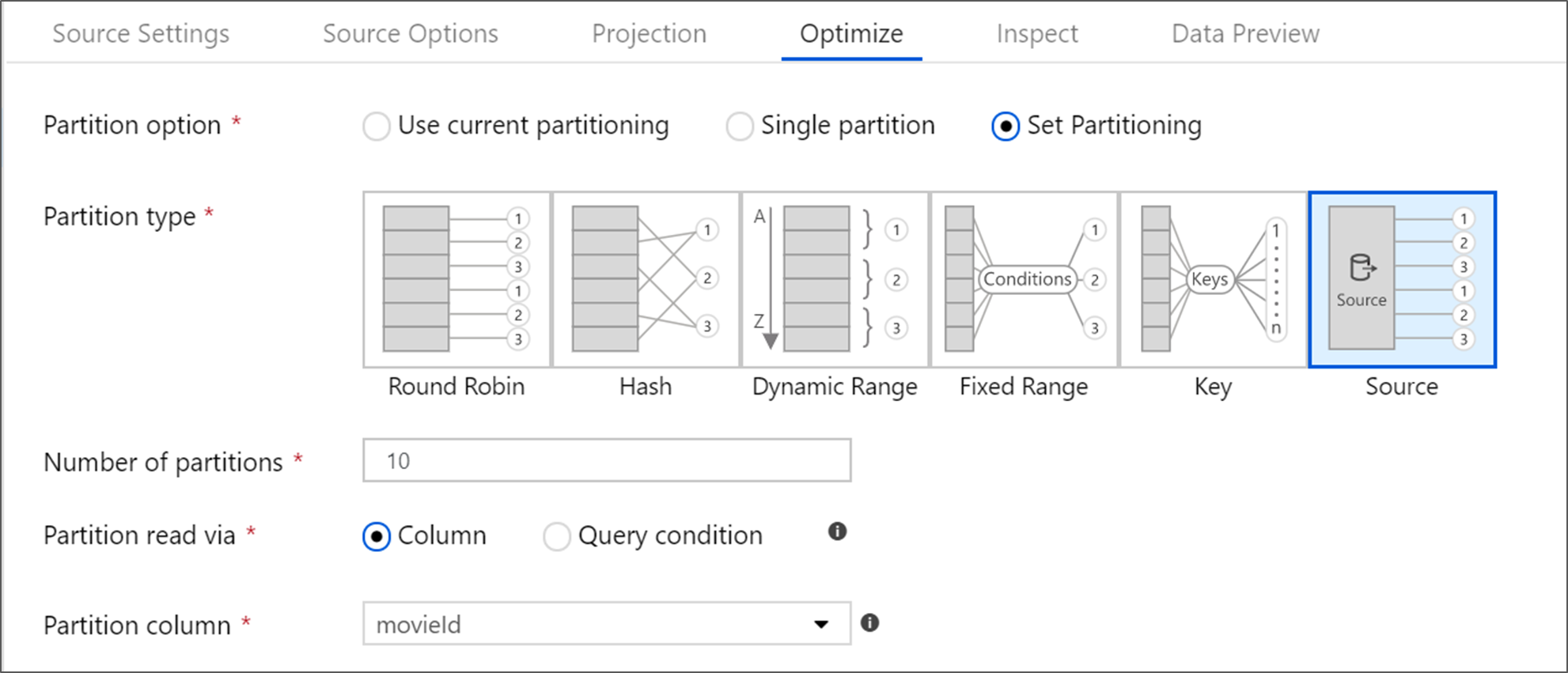
Isolatieniveau
Het isolatieniveau van de leesbewerking op een Azure SQL-bronsysteem is van invloed op de prestaties. Het kiezen van 'Niet-verzonden lezen' biedt de snelste prestaties en voorkomt dat databasevergrendelingen worden vergrendeld. Zie Isolatieniveaus voor meer informatie over SQL-isolatieniveaus.
Lezen met behulp van query
U kunt lezen uit Azure SQL Database met behulp van een tabel of een SQL-query. Als u een SQL-query uitvoert, moet de query worden voltooid voordat de transformatie kan worden gestart. SQL-query's kunnen handig zijn voor het pushen van bewerkingen die sneller kunnen worden uitgevoerd en de hoeveelheid gegevens die worden gelezen uit een SQL Server, zoals SELECT, WHERE en JOIN-instructies, verminderen. Wanneer u bewerkingen naar beneden pusht, verliest u de mogelijkheid om herkomst en prestaties van de transformaties bij te houden voordat de gegevens in de gegevensstroom binnenkomen.
Azure Synapse Analytics-bronnen
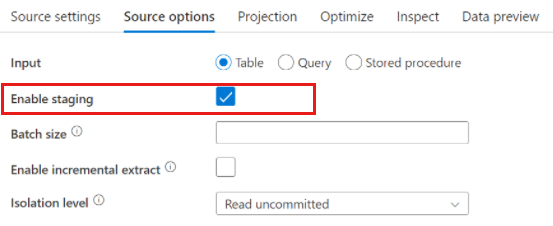
Wanneer u Azure Synapse Analytics gebruikt, bestaat er een instelling met de naam Fasering inschakelen in de bronopties. Hierdoor kan de service lezen vanuit Synapse met behulp Stagingvan, waardoor de leesprestaties aanzienlijk worden verbeterd met behulp van de meest presterende functie voor bulksgewijs laden, zoals cetas en de opdracht COPY. Voor het inschakelen Staging moet u een faseringslocatie voor Azure Blob Storage of Azure Data Lake Storage Gen2 opgeven in de instellingen voor de activiteit van de gegevensstroom.
Bronnen op basis van bestanden
Parquet versus tekst met scheidingstekens
Hoewel gegevensstromen verschillende bestandstypen ondersteunen, wordt de systeemeigen Parquet-indeling van Spark aanbevolen voor optimale lees- en schrijftijden.
Als u dezelfde gegevensstroom uitvoert voor een set bestanden, raden we u aan om te lezen vanuit een map, jokertekenpaden te gebruiken of te lezen uit een lijst met bestanden. Een uitvoering van één gegevensstroomactiviteit kan al uw bestanden in batch verwerken. Meer informatie over het configureren van deze instellingen vindt u in de sectie Brontransformatie van de documentatie van de Azure Blob Storage-connector .
Vermijd indien mogelijk het gebruik van de For-Each-activiteit om gegevensstromen uit te voeren via een set bestanden. Dit zorgt ervoor dat elke iteratie van de for-each een eigen Spark-cluster maakt, wat vaak niet nodig is en duur kan zijn.
Inline-gegevenssets versus gedeelde gegevenssets
ADF- en Synapse-gegevenssets zijn gedeelde resources in uw factory's en werkruimten. Wanneer u echter grote aantallen bronmappen en bestanden met tekstscheidingstekens en JSON-bronnen leest, kunt u de prestaties van de detectie van gegevensbestanden verbeteren door de optie 'Door de gebruiker geprojecteerd schema' in de projectie in te stellen | Dialoogvenster Schemaopties. Met deze optie wordt het standaardschema van ADF automatisch opsporen uitgeschakeld en worden de prestaties van bestandsdetectie aanzienlijk verbeterd. Voordat u deze optie instelt, moet u ervoor zorgen dat u de projectie importeert, zodat ADF een bestaand schema voor projectie heeft. Deze optie werkt niet met schemadrift.
Gerelateerde inhoud
- Overzicht van prestaties van gegevensstromen
- Sinks optimaliseren
- Transformaties optimaliseren
- Gegevensstromen gebruiken in pijplijnen
Zie andere Gegevensstroom artikelen met betrekking tot prestaties: