Gegevens kopiëren van Amazon Redshift met behulp van Azure Data Factory of Synapse Analytics
VAN TOEPASSING OP:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Probeer Data Factory uit in Microsoft Fabric, een alles-in-één analyseoplossing voor ondernemingen. Microsoft Fabric omvat alles, van gegevensverplaatsing tot gegevenswetenschap, realtime analyses, business intelligence en rapportage. Meer informatie over het gratis starten van een nieuwe proefversie .
In dit artikel wordt beschreven hoe u de kopieeractiviteit in Azure Data Factory- en Synapse Analytics-pijplijnen gebruikt om gegevens te kopiëren van een Amazon Redshift. Het is gebaseerd op het artikel over het overzicht van kopieeractiviteiten met een algemeen overzicht van de kopieeractiviteit.
Ondersteunde mogelijkheden
Deze Amazon Redshift-connector wordt ondersteund voor de volgende mogelijkheden:
| Ondersteunde mogelijkheden | IR |
|---|---|
| Copy-activiteit (bron/-) | (1) (2) |
| Activiteit Lookup | (1) (2) |
(1) Azure Integration Runtime (2) Zelf-hostende Integration Runtime
Zie de tabel Ondersteunde gegevensarchieven voor een lijst met gegevensarchieven die worden ondersteund als bronnen of sinks door de kopieeractiviteit.
Deze Amazon Redshift-connector ondersteunt het ophalen van gegevens uit Redshift met behulp van query of ingebouwde Redshift UNLOAD-ondersteuning.
De connector ondersteunt de Windows-versies in dit artikel.
Tip
Voor de beste prestaties bij het kopiëren van grote hoeveelheden gegevens uit Redshift, kunt u overwegen om de ingebouwde Redshift UNLOAD via Amazon S3 te gebruiken. Zie UNLOAD gebruiken om gegevens uit de sectie Amazon Redshift te kopiëren voor meer informatie.
Vereisten
- Als u gegevens naar een on-premises gegevensarchief kopieert met behulp van zelf-hostende Integration Runtime, verleent u Integration Runtime (ip-adres van de machine gebruiken) de toegang tot het Amazon Redshift-cluster. Zie Toegang tot het cluster autoriseren voor instructies.
- Als u gegevens kopieert naar een Azure-gegevensarchief, raadpleegt u IP-adresbereiken van Azure Data Center voor het COMPUTE-IP-adres en SQL-bereiken die worden gebruikt door de Azure-datacenters.
Aan de slag
Als u de kopieeractiviteit wilt uitvoeren met een pijplijn, kunt u een van de volgende hulpprogramma's of SDK's gebruiken:
- Het hulpprogramma voor het kopiëren van gegevens
- Azure Portal
- De .NET-SDK
- De Python-SDK
- Azure PowerShell
- De REST API
- Een Azure Resource Manager-sjabloon
Een gekoppelde service maken met Amazon Redshift met behulp van de gebruikersinterface
Gebruik de volgende stappen om een gekoppelde service te maken voor Amazon Redshift in de gebruikersinterface van Azure Portal.
Blader naar het tabblad Beheren in uw Azure Data Factory- of Synapse-werkruimte en selecteer Gekoppelde services en klik vervolgens op Nieuw:
Zoek naar Amazon en selecteer de Amazon Redshift-connector.
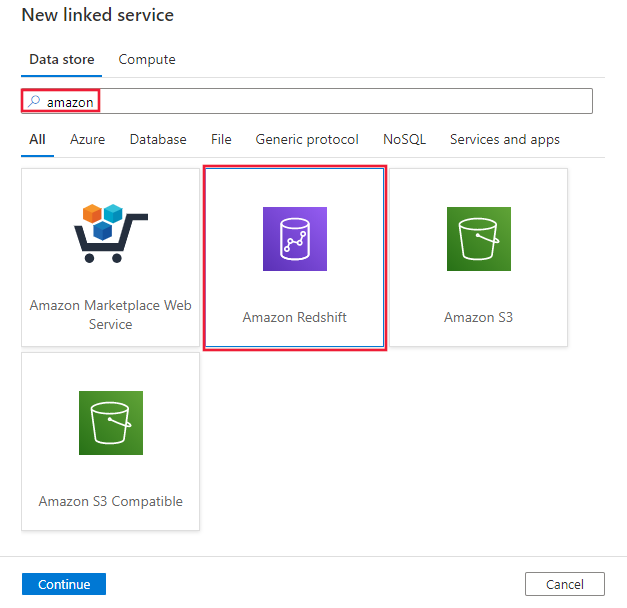
Configureer de servicedetails, test de verbinding en maak de nieuwe gekoppelde service.
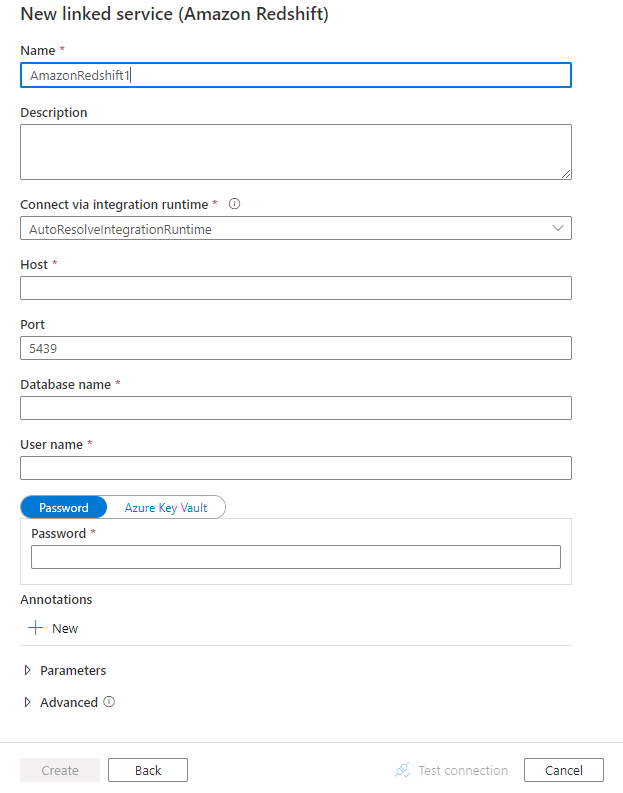
Configuratiedetails van connector
De volgende secties bevatten details over eigenschappen die worden gebruikt om Data Factory-entiteiten te definiëren die specifiek zijn voor Amazon Redshift-connector.
Eigenschappen van gekoppelde service
De volgende eigenschappen worden ondersteund voor gekoppelde Amazon Redshift-service:
| Eigenschappen | Beschrijving | Vereist |
|---|---|---|
| type | De eigenschap type moet worden ingesteld op: AmazonRedshift | Ja |
| server | IP-adres of hostnaam van de Amazon Redshift-server. | Ja |
| poort | Het nummer van de TCP-poort die de Amazon Redshift-server gebruikt om te luisteren naar clientverbindingen. | Nee, standaard is 5439 |
| database | Naam van de Amazon Redshift-database. | Ja |
| gebruikersnaam | Naam van de gebruiker die toegang heeft tot de database. | Ja |
| password | Wachtwoord voor het gebruikersaccount. Markeer dit veld als SecureString om het veilig op te slaan of verwijs naar een geheim dat is opgeslagen in Azure Key Vault. | Ja |
| connectVia | De Integration Runtime die moet worden gebruikt om verbinding te maken met het gegevensarchief. U kunt Azure Integration Runtime of zelf-hostende Integration Runtime gebruiken (als uw gegevensarchief zich in een privénetwerk bevindt). Als dit niet is opgegeven, wordt de standaard Azure Integration Runtime gebruikt. | Nee |
Voorbeeld:
{
"name": "AmazonRedshiftLinkedService",
"properties":
{
"type": "AmazonRedshift",
"typeProperties":
{
"server": "<server name>",
"database": "<database name>",
"username": "<username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Eigenschappen van gegevensset
Zie het artikel gegevenssets voor een volledige lijst met secties en eigenschappen die beschikbaar zijn voor het definiëren van gegevenssets . Deze sectie bevat een lijst met eigenschappen die worden ondersteund door de Amazon Redshift-gegevensset.
Als u gegevens van Amazon Redshift wilt kopiëren, worden de volgende eigenschappen ondersteund:
| Eigenschappen | Beschrijving | Vereist |
|---|---|---|
| type | De typeeigenschap van de gegevensset moet zijn ingesteld op: AmazonRedshiftTable | Ja |
| schema | Naam van het schema. | Nee (als 'query' in de activiteitsbron is opgegeven) |
| table | Naam van de tabel. | Nee (als 'query' in de activiteitsbron is opgegeven) |
| tableName | Naam van de tabel met schema. Deze eigenschap wordt ondersteund voor compatibiliteit met eerdere versies. Gebruik schema en table voor nieuwe workload. |
Nee (als 'query' in de activiteitsbron is opgegeven) |
Voorbeeld
{
"name": "AmazonRedshiftDataset",
"properties":
{
"type": "AmazonRedshiftTable",
"typeProperties": {},
"schema": [],
"linkedServiceName": {
"referenceName": "<Amazon Redshift linked service name>",
"type": "LinkedServiceReference"
}
}
}
Als u RelationalTable getypte gegevensset gebruikt, wordt deze nog steeds ondersteund terwijl u wordt aangeraden de nieuwe gegevensset te gebruiken.
Eigenschappen van de kopieeractiviteit
Zie het artikel Pijplijnen voor een volledige lijst met secties en eigenschappen die beschikbaar zijn voor het definiëren van activiteiten. Deze sectie bevat een lijst met eigenschappen die worden ondersteund door amazon Redshift-bron.
Amazon Redshift als bron
Als u gegevens van Amazon Redshift wilt kopiëren, stelt u het brontype in de kopieeractiviteit in op AmazonRedshiftSource. De volgende eigenschappen worden ondersteund in de sectie bron van kopieeractiviteit:
| Eigenschappen | Beschrijving | Vereist |
|---|---|---|
| type | De typeeigenschap van de bron van de kopieeractiviteit moet worden ingesteld op: AmazonRedshiftSource | Ja |
| query | Gebruik de aangepaste query om gegevens te lezen. Bijvoorbeeld: selecteer * in MyTable. | Nee (als 'tableName' in de gegevensset is opgegeven) |
| redshiftUnloadSettings | Eigenschapsgroep bij gebruik van Amazon Redshift UNLOAD. | Nee |
| s3LinkedServiceName | Verwijst naar een Amazon S3 die moet worden gebruikt als een tussentijdse winkel door een gekoppelde servicenaam van het type AmazonS3 op te geven. | Ja als u UNLOAD gebruikt |
| bucketName | Geef de S3-bucket aan om de tussentijdse gegevens op te slaan. Als deze niet is opgegeven, genereert de service deze automatisch. | Ja als u UNLOAD gebruikt |
Voorbeeld: Amazon Redshift-bron in kopieeractiviteit met UNLOAD
"source": {
"type": "AmazonRedshiftSource",
"query": "<SQL query>",
"redshiftUnloadSettings": {
"s3LinkedServiceName": {
"referenceName": "<Amazon S3 linked service>",
"type": "LinkedServiceReference"
},
"bucketName": "bucketForUnload"
}
}
Meer informatie over het gebruik van UNLOAD om gegevens van Amazon Redshift efficiënt te kopiëren vanuit de volgende sectie.
UNLOAD gebruiken om gegevens van Amazon Redshift te kopiëren
UNLOAD is een mechanisme dat wordt geleverd door Amazon Redshift, waarmee de resultaten van een query kunnen worden verwijderd naar een of meer bestanden op Amazon Simple Storage Service (Amazon S3). Het wordt door Amazon aanbevolen voor het kopiëren van grote gegevenssets vanuit Redshift.
Voorbeeld: gegevens kopiëren van Amazon Redshift naar Azure Synapse Analytics met behulp van UNLOAD, gefaseerde kopie en PolyBase
Voor dit voorbeeldgebruik worden gegevens van Amazon Redshift naar Amazon S3 als geconfigureerd in 'redshiftUnloadSettings' verwijderd en kopieert u vervolgens gegevens van Amazon S3 naar Azure Blob, zoals is opgegeven in 'stagingSettings', en gebruikt u ten slotte PolyBase om gegevens te laden in Azure Synapse Analytics. Alle tussentijdse indeling wordt verwerkt door de kopieeractiviteit correct.

"activities":[
{
"name": "CopyFromAmazonRedshiftToSQLDW",
"type": "Copy",
"inputs": [
{
"referenceName": "AmazonRedshiftDataset",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "AzureSQLDWDataset",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AmazonRedshiftSource",
"query": "select * from MyTable",
"redshiftUnloadSettings": {
"s3LinkedServiceName": {
"referenceName": "AmazonS3LinkedService",
"type": "LinkedServiceReference"
},
"bucketName": "bucketForUnload"
}
},
"sink": {
"type": "SqlDWSink",
"allowPolyBase": true
},
"enableStaging": true,
"stagingSettings": {
"linkedServiceName": "AzureStorageLinkedService",
"path": "adfstagingcopydata"
},
"dataIntegrationUnits": 32
}
}
]
Toewijzing van gegevenstypen voor Amazon Redshift
Bij het kopiëren van gegevens uit Amazon Redshift worden de volgende toewijzingen gebruikt van Amazon Redshift-gegevenstypen naar tussentijdse gegevenstypen die intern in de service worden gebruikt. Zie Schema- en gegevenstypetoewijzingen voor meer informatie over hoe kopieeractiviteit het bronschema en het gegevenstype toewijst aan de sink.
| Amazon Redshift-gegevenstype | Tussentijdse servicegegevenstype |
|---|---|
| BIGINT | Int64 |
| BOOLEAN | String |
| VERKOLEN | String |
| DATUM | Datum en tijd |
| DECIMAL | Decimal |
| DUBBELE PRECISIE | Dubbel |
| GEHEEL GETAL | Int32 |
| WERKELIJK | Eén |
| SMALLINT | Int16 |
| SMS | String |
| TIMESTAMP | Datum en tijd |
| VARCHAR | String |
Eigenschappen van opzoekactiviteit
Als u meer wilt weten over de eigenschappen, controleert u de lookup-activiteit.
Gerelateerde inhoud
Zie ondersteunde gegevensarchieven voor een lijst met gegevensarchieven die worden ondersteund als bronnen en sinks door de kopieeractiviteit.