Gegevens kopiëren van en naar Azure Databricks Delta Lake met behulp van Azure Data Factory of Azure Synapse Analytics
VAN TOEPASSING OP:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Probeer Data Factory uit in Microsoft Fabric, een alles-in-één analyseoplossing voor ondernemingen. Microsoft Fabric omvat alles, van gegevensverplaatsing tot gegevenswetenschap, realtime analyses, business intelligence en rapportage. Meer informatie over het gratis starten van een nieuwe proefversie .
In dit artikel wordt beschreven hoe u de Copy-activiteit gebruikt in Azure Data Factory en Azure Synapse om gegevens te kopiëren van en naar Azure Databricks Delta Lake. Het is gebaseerd op het Copy-activiteit artikel, waarin een algemeen overzicht van de kopieeractiviteit wordt weergegeven.
Ondersteunde mogelijkheden
Deze Azure Databricks Delta Lake-connector wordt ondersteund voor de volgende mogelijkheden:
| Ondersteunde mogelijkheden | IR |
|---|---|
| Copy-activiteit (bron/sink) | (1) (2) |
| Toewijzingsgegevensstroom (bron/sink) | (1) |
| Activiteit Lookup | (1) (2) |
(1) Azure Integration Runtime (2) Zelf-hostende Integration Runtime
Over het algemeen ondersteunt de service Delta Lake met de volgende mogelijkheden om aan uw verschillende behoeften te voldoen.
- Copy-activiteit ondersteunt Azure Databricks Delta Lake-connector om gegevens te kopiëren van elke ondersteunde brongegevensopslag naar azure Databricks Delta Lake-tabel en van Delta Lake-tabel naar een ondersteund sinkgegevensarchief. Het maakt gebruik van uw Databricks-cluster om de gegevensverplaatsing uit te voeren. Zie de details in de sectie Vereisten.
- Toewijzing Gegevensstroom ondersteunt de algemene Delta-indeling in Azure Storage als bron en sink voor het lezen en schrijven van Delta-bestanden voor ETL zonder code en wordt uitgevoerd op beheerde Azure Integration Runtime.
- Databricks-activiteiten ondersteunen het organiseren van uw codegerichte ETL- of machine learning-workload boven op Delta Lake.
Vereisten
Als u deze Azure Databricks Delta Lake-connector wilt gebruiken, moet u een cluster instellen in Azure Databricks.
- Als u gegevens naar Delta Lake wilt kopiëren, roept Copy-activiteit het Azure Databricks-cluster aan om gegevens te lezen uit een Azure Storage. Dit is uw oorspronkelijke bron of een faseringsgebied waarnaar de service eerst de brongegevens schrijft via een ingebouwde gefaseerde kopie. Meer informatie van Delta Lake als sink.
- Als u gegevens uit Delta Lake wilt kopiëren, roept Copy-activiteit het Azure Databricks-cluster aan om gegevens naar een Azure Storage te schrijven. Dit is uw oorspronkelijke sink of een faseringsgebied van waaruit de service gegevens blijft schrijven naar de uiteindelijke sink via ingebouwde gefaseerde kopie. Meer informatie van Delta Lake als bron.
Het Databricks-cluster moet toegang hebben tot het Azure Blob- of Azure Data Lake Storage Gen2-account, zowel de opslagcontainer/het bestandssysteem dat wordt gebruikt voor bron/sink/fasering als het container-/bestandssysteem waarin u de Delta Lake-tabellen wilt schrijven.
Als u Azure Data Lake Storage Gen2 wilt gebruiken, kunt u een service-principal configureren in het Databricks-cluster als onderdeel van de Apache Spark-configuratie. Volg de stappen in Access rechtstreeks met een service-principal.
Als u Azure Blob Storage wilt gebruiken, kunt u een toegangssleutel voor een opslagaccount of SAS-token configureren op het Databricks-cluster als onderdeel van de Apache Spark-configuratie. Volg de stappen in Access Azure Blob Storage met behulp van de RDD-API.
Als het geconfigureerde cluster tijdens de kopieeractiviteit is beëindigd, wordt het automatisch gestart door de service. Als u pijplijn maakt met behulp van de ontwerpinterface, moet u voor bewerkingen zoals een voorbeeld van gegevens een livecluster hebben. De service start het cluster niet namens u.
De clusterconfiguratie opgeven
Selecteer Standard in de vervolgkeuzelijst Clustermodus.
Selecteer in de vervolgkeuzelijst Databricks Runtime-versie een Databricks Runtime-versie.
Schakel Automatisch optimaliseren in door de volgende eigenschappen toe te voegen aan uw Spark-configuratie:
spark.databricks.delta.optimizeWrite.enabled true spark.databricks.delta.autoCompact.enabled trueConfigureer uw cluster, afhankelijk van uw integratie- en schaalbehoeften.
Zie Clusters configureren voor meer informatie over clusterconfiguratie.
Aan de slag
Als u de kopieeractiviteit wilt uitvoeren met een pijplijn, kunt u een van de volgende hulpprogramma's of SDK's gebruiken:
- Het hulpprogramma voor het kopiëren van gegevens
- Azure Portal
- De .NET-SDK
- De Python-SDK
- Azure PowerShell
- De REST API
- Een Azure Resource Manager-sjabloon
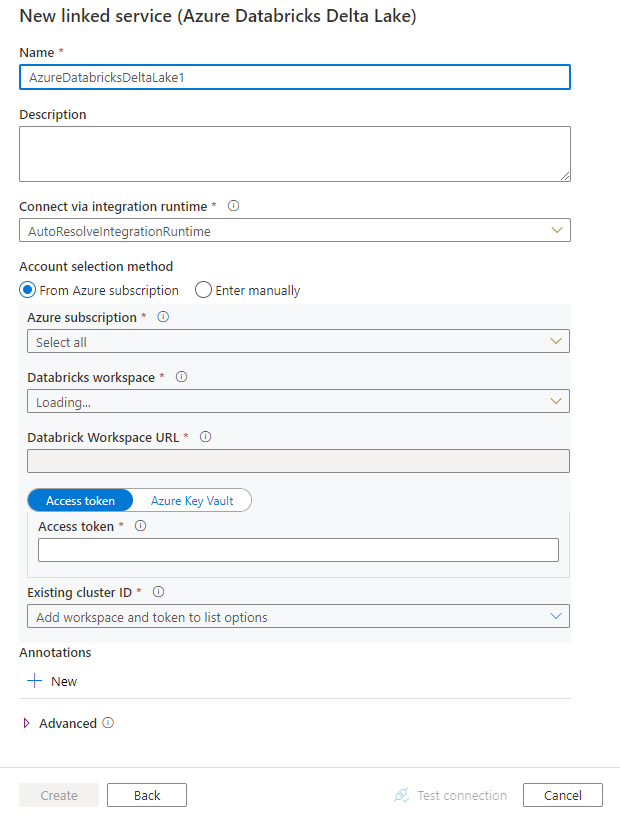
Een gekoppelde service maken voor Azure Databricks Delta Lake met behulp van de gebruikersinterface
Gebruik de volgende stappen om een gekoppelde service te maken voor Azure Databricks Delta Lake in de gebruikersinterface van Azure Portal.
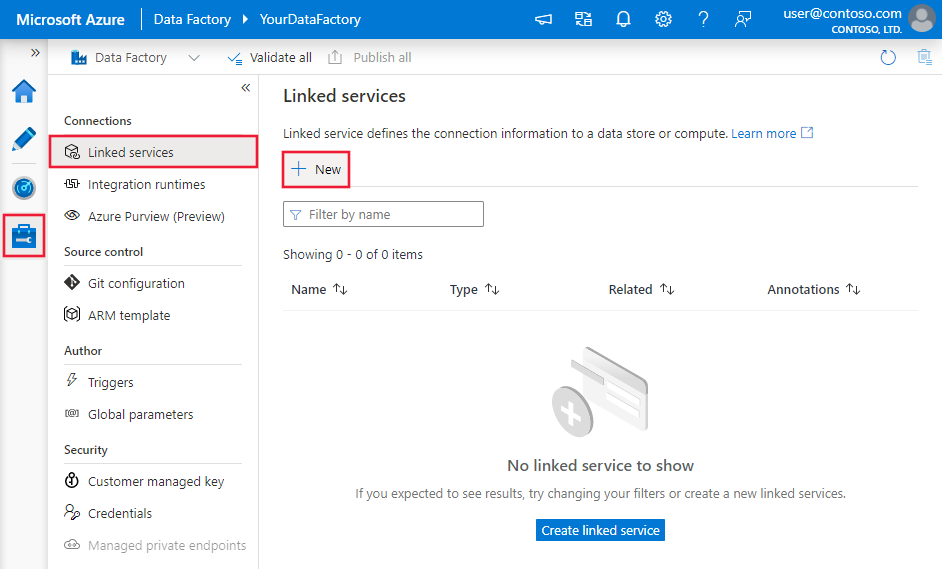
Blader naar het tabblad Beheren in uw Azure Data Factory- of Synapse-werkruimte en selecteer Gekoppelde services en klik vervolgens op Nieuw:
Zoek naar delta en selecteer de Azure Databricks Delta Lake-connector.

Configureer de servicedetails, test de verbinding en maak de nieuwe gekoppelde service.
Configuratiedetails van connector
De volgende secties bevatten details over eigenschappen waarmee entiteiten worden gedefinieerd die specifiek zijn voor een Azure Databricks Delta Lake-connector.
Eigenschappen van gekoppelde service
Deze Azure Databricks Delta Lake-connector ondersteunt de volgende verificatietypen. Zie de bijbehorende secties voor meer informatie.
- Toegangstoken
- Door het systeem toegewezen beheerde identiteitverificatie
- Door de gebruiker toegewezen beheerde identiteitverificatie
Toegangstoken
De volgende eigenschappen worden ondersteund voor de gekoppelde Azure Databricks Delta Lake-service:
| Eigenschappen | Beschrijving | Vereist |
|---|---|---|
| type | De eigenschap type moet worden ingesteld op AzureDatabricksDeltaLake. | Ja |
| domain | Geef de URL van de Azure Databricks-werkruimte op, bijvoorbeeld https://adb-xxxxxxxxx.xx.azuredatabricks.net. |
|
| clusterId | Geef de cluster-id van een bestaand cluster op. Het moet een al gemaakt interactief cluster zijn. U vindt de cluster-id van een interactief cluster in de Databricks-werkruimte - Clusters ->> Interactieve clusternaam -> Configuratie -> Tags. Meer informatie. |
|
| accessToken | Toegangstoken is vereist voor de service om te verifiëren bij Azure Databricks. Het toegangstoken moet worden gegenereerd op basis van de databricks-werkruimte. Meer gedetailleerde stappen voor het vinden van het toegangstoken vindt u hier. | |
| connectVia | De integratieruntime die wordt gebruikt om verbinding te maken met het gegevensarchief. U kunt de Azure Integration Runtime of een zelf-hostende Integration Runtime gebruiken (als uw gegevensarchief zich in een privénetwerk bevindt). Als dit niet is opgegeven, wordt de standaard Azure Integration Runtime gebruikt. | Nee |
Voorbeeld:
{
"name": "AzureDatabricksDeltaLakeLinkedService",
"properties": {
"type": "AzureDatabricksDeltaLake",
"typeProperties": {
"domain": "https://adb-xxxxxxxxx.xx.azuredatabricks.net",
"clusterId": "<cluster id>",
"accessToken": {
"type": "SecureString",
"value": "<access token>"
}
}
}
}
Door het systeem toegewezen beheerde identiteitverificatie
Als u door het systeem toegewezen beheerde identiteitverificatie wilt gebruiken, voert u de volgende stappen uit om machtigingen te verlenen:
Haal de informatie over de beheerde identiteit op door de waarde van de object-id van de beheerde identiteit te kopiëren die samen met uw data factory of Synapse-werkruimte is gegenereerd.
Verwijs de beheerde identiteit de juiste machtigingen in Azure Databricks. Over het algemeen moet u ten minste de rol Inzender verlenen aan uw door het systeem toegewezen beheerde identiteit in Toegangsbeheer (IAM) van Azure Databricks.
De volgende eigenschappen worden ondersteund voor de gekoppelde Azure Databricks Delta Lake-service:
| Eigenschappen | Beschrijving | Vereist |
|---|---|---|
| type | De eigenschap type moet worden ingesteld op AzureDatabricksDeltaLake. | Ja |
| domain | Geef de URL van de Azure Databricks-werkruimte op, bijvoorbeeld https://adb-xxxxxxxxx.xx.azuredatabricks.net. |
Ja |
| clusterId | Geef de cluster-id van een bestaand cluster op. Het moet een al gemaakt interactief cluster zijn. U vindt de cluster-id van een interactief cluster in de Databricks-werkruimte - Clusters ->> Interactieve clusternaam -> Configuratie -> Tags. Meer informatie. |
Ja |
| workspaceResourceId | Geef de resource-id van de werkruimte van uw Azure Databricks op. | Ja |
| connectVia | De integratieruntime die wordt gebruikt om verbinding te maken met het gegevensarchief. U kunt de Azure Integration Runtime of een zelf-hostende Integration Runtime gebruiken (als uw gegevensarchief zich in een privénetwerk bevindt). Als dit niet is opgegeven, wordt de standaard Azure Integration Runtime gebruikt. | Nee |
Voorbeeld:
{
"name": "AzureDatabricksDeltaLakeLinkedService",
"properties": {
"type": "AzureDatabricksDeltaLake",
"typeProperties": {
"domain": "https://adb-xxxxxxxxx.xx.azuredatabricks.net",
"clusterId": "<cluster id>",
"workspaceResourceId": "<workspace resource id>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Door de gebruiker toegewezen beheerde identiteitverificatie
Volg deze stappen om door de gebruiker toegewezen beheerde identiteitverificatie te gebruiken:
Maak een of meerdere door de gebruiker toegewezen beheerde identiteiten en verken machtigingen in uw Azure Databricks. Over het algemeen moet u ten minste de rol Inzender verlenen aan uw door de gebruiker toegewezen beheerde identiteit in Toegangsbeheer (IAM) van Azure Databricks.
Wijs een of meerdere door de gebruiker toegewezen beheerde identiteiten toe aan uw data factory of Synapse-werkruimte en maak referenties voor elke door de gebruiker toegewezen beheerde identiteit.
De volgende eigenschappen worden ondersteund voor de gekoppelde Azure Databricks Delta Lake-service:
| Eigenschappen | Beschrijving | Vereist |
|---|---|---|
| type | De eigenschap type moet worden ingesteld op AzureDatabricksDeltaLake. | Ja |
| domain | Geef de URL van de Azure Databricks-werkruimte op, bijvoorbeeld https://adb-xxxxxxxxx.xx.azuredatabricks.net. |
Ja |
| clusterId | Geef de cluster-id van een bestaand cluster op. Het moet een al gemaakt interactief cluster zijn. U vindt de cluster-id van een interactief cluster in de Databricks-werkruimte - Clusters ->> Interactieve clusternaam -> Configuratie -> Tags. Meer informatie. |
Ja |
| aanmeldingsgegevens | Geef de door de gebruiker toegewezen beheerde identiteit op als referentieobject. | Ja |
| workspaceResourceId | Geef de resource-id van de werkruimte van uw Azure Databricks op. | Ja |
| connectVia | De integratieruntime die wordt gebruikt om verbinding te maken met het gegevensarchief. U kunt de Azure Integration Runtime of een zelf-hostende Integration Runtime gebruiken (als uw gegevensarchief zich in een privénetwerk bevindt). Als dit niet is opgegeven, wordt de standaard Azure Integration Runtime gebruikt. | Nee |
Voorbeeld:
{
"name": "AzureDatabricksDeltaLakeLinkedService",
"properties": {
"type": "AzureDatabricksDeltaLake",
"typeProperties": {
"domain": "https://adb-xxxxxxxxx.xx.azuredatabricks.net",
"clusterId": "<cluster id>",
"credential": {
"referenceName": "credential1",
"type": "CredentialReference"
},
"workspaceResourceId": "<workspace resource id>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Eigenschappen van gegevensset
Zie het artikel Gegevenssets voor een volledige lijst met secties en eigenschappen die beschikbaar zijn voor het definiëren van gegevenssets .
De volgende eigenschappen worden ondersteund voor de Azure Databricks Delta Lake-gegevensset.
| Eigenschappen | Beschrijving | Vereist |
|---|---|---|
| type | De typeeigenschap van de gegevensset moet worden ingesteld op AzureDatabricksDeltaLakeDataset. | Ja |
| database | Naam van de database. | Nee voor bron, ja voor sink |
| table | Naam van de deltatabel. | Nee voor bron, ja voor sink |
Voorbeeld:
{
"name": "AzureDatabricksDeltaLakeDataset",
"properties": {
"type": "AzureDatabricksDeltaLakeDataset",
"typeProperties": {
"database": "<database name>",
"table": "<delta table name>"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"linkedServiceName": {
"referenceName": "<name of linked service>",
"type": "LinkedServiceReference"
}
}
}
Eigenschappen van de kopieeractiviteit
Zie het artikel Pijplijnen voor een volledige lijst met secties en eigenschappen die beschikbaar zijn voor het definiëren van activiteiten. Deze sectie bevat een lijst met eigenschappen die worden ondersteund door de Azure Databricks Delta Lake-bron en -sink.
Delta Lake als bron
Als u gegevens wilt kopiëren uit Azure Databricks Delta Lake, worden de volgende eigenschappen ondersteund in de sectie Copy-activiteit bron.
| Eigenschappen | Beschrijving | Vereist |
|---|---|---|
| type | De typeeigenschap van de Copy-activiteit-bron moet worden ingesteld op AzureDatabricksDeltaLakeSource. | Ja |
| query | Geef de SQL-query op om gegevens te lezen. Voor het besturingselement voor tijdreizen volgt u het onderstaande patroon: - SELECT * FROM events TIMESTAMP AS OF timestamp_expression- SELECT * FROM events VERSION AS OF version |
Nee |
| exportSettings | Geavanceerde instellingen die worden gebruikt om gegevens op te halen uit de Delta-tabel. | Nee |
Onder exportSettings: |
||
| type | Het type exportopdracht, ingesteld op AzureDatabricksDeltaLakeExportCommand. | Ja |
| dateFormat | Datumtype opmaken naar tekenreeks met een datumnotatie. Aangepaste datumnotaties volgen de notaties bij het datum/tijd-patroon. Als dit niet is opgegeven, wordt de standaardwaarde yyyy-MM-ddgebruikt. |
Nee |
| timestampFormat | Tijdstempeltype opmaken aan tekenreeks met een tijdstempelnotatie. Aangepaste datumnotaties volgen de notaties bij het datum/tijd-patroon. Als dit niet is opgegeven, wordt de standaardwaarde yyyy-MM-dd'T'HH:mm:ss[.SSS][XXX]gebruikt. |
Nee |
Directe kopie van Delta Lake
Als uw sinkgegevensarchief en -indeling voldoen aan de criteria die in deze sectie worden beschreven, kunt u de Copy-activiteit gebruiken om rechtstreeks vanuit de Azure Databricks Delta-tabel naar sink te kopiëren. De service controleert de instellingen en mislukt de Copy-activiteit wordt uitgevoerd als niet aan de volgende criteria wordt voldaan:
De gekoppelde sinkservice is Azure Blob Storage of Azure Data Lake Storage Gen2. De accountreferenties moeten vooraf zijn geconfigureerd in de configuratie van het Azure Databricks-cluster, voor meer informatie over vereisten.
De sinkgegevensindeling is van Parquet, gescheiden tekst of Avro met de volgende configuraties en verwijst naar een map in plaats van bestand.
- Voor parquet-indeling is de compressiecodec geen, snappy of gzip.
- Voor tekst met scheidingstekens :
rowDelimiteris een willekeurig teken.compressionkan geen zijn, bzip2, gzip.encodingNameUTF-7 wordt niet ondersteund.
- Voor Avro-indeling is de compressiecodec geen, deflate of snappy.
In de Copy-activiteit bron is
additionalColumnsniet opgegeven.Als u gegevens naar tekst met scheidingstekens kopieert,
fileExtensionmoet u '.csv' zijn in de sink van de kopieeractiviteit.In de toewijzing Copy-activiteit is typeconversie niet ingeschakeld.
Voorbeeld:
"activities":[
{
"name": "CopyFromDeltaLake",
"type": "Copy",
"inputs": [
{
"referenceName": "<Delta lake input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AzureDatabricksDeltaLakeSource",
"sqlReaderQuery": "SELECT * FROM events TIMESTAMP AS OF timestamp_expression"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Gefaseerde kopie van Delta Lake
Wanneer uw sinkgegevensarchief of -indeling niet overeenkomt met de criteria voor directe kopie, zoals vermeld in de laatste sectie, schakelt u de ingebouwde gefaseerde kopie in met behulp van een tussentijdse Azure-opslaginstantie. De functie voor gefaseerde kopie biedt u ook betere doorvoer. De service exporteert gegevens uit Azure Databricks Delta Lake naar faseringsopslag, kopieert vervolgens de gegevens naar de sink en schoont ten slotte uw tijdelijke gegevens op uit de faseringsopslag. Zie Gefaseerde kopie voor meer informatie over het kopiëren van gegevens met behulp van fasering.
Als u deze functie wilt gebruiken, maakt u een gekoppelde Azure Blob Storage-service of een gekoppelde Azure Data Lake Storage Gen2-service die verwijst naar het opslagaccount als tijdelijke fasering. Geef vervolgens de enableStaging en stagingSettings eigenschappen op in de Copy-activiteit.
Notitie
De referentie voor het faseringsopslagaccount moet vooraf zijn geconfigureerd in de configuratie van het Azure Databricks-cluster, voor meer informatie over vereisten.
Voorbeeld:
"activities":[
{
"name": "CopyFromDeltaLake",
"type": "Copy",
"inputs": [
{
"referenceName": "<Delta lake input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AzureDatabricksDeltaLakeSource",
"sqlReaderQuery": "SELECT * FROM events TIMESTAMP AS OF timestamp_expression"
},
"sink": {
"type": "<sink type>"
},
"enableStaging": true,
"stagingSettings": {
"linkedServiceName": {
"referenceName": "MyStagingStorage",
"type": "LinkedServiceReference"
},
"path": "mystagingpath"
}
}
}
]
Delta lake als sink
Als u gegevens wilt kopiëren naar Azure Databricks Delta Lake, worden de volgende eigenschappen ondersteund in de sectie Copy-activiteit sink.
| Eigenschappen | Beschrijving | Vereist |
|---|---|---|
| type | De typeeigenschap van de Copy-activiteit sink, ingesteld op AzureDatabricksDeltaLakeSink. | Ja |
| preCopyScript | Geef in elke uitvoering een SQL-query op voor de Copy-activiteit die moet worden uitgevoerd voordat u gegevens naar de Databricks Delta-tabel schrijft. Voorbeeld: VACUUM eventsTable DRY RUN U kunt deze eigenschap gebruiken om de vooraf geladen gegevens op te schonen of een afkappende tabel of vacuüminstructie toe te voegen. |
Nee |
| importSettings | Geavanceerde instellingen die worden gebruikt om gegevens naar deltatabel te schrijven. | Nee |
Onder importSettings: |
||
| type | Het type importopdracht, ingesteld op AzureDatabricksDeltaLakeImportCommand. | Ja |
| dateFormat | Tekenreeks opmaken naar datumtype met een datumnotatie. Aangepaste datumnotaties volgen de notaties bij het datum/tijd-patroon. Als dit niet is opgegeven, wordt de standaardwaarde yyyy-MM-ddgebruikt. |
Nee |
| timestampFormat | Tekenreeks opmaken naar tijdstempeltype met een tijdstempelnotatie. Aangepaste datumnotaties volgen de notaties bij het datum/tijd-patroon. Als dit niet is opgegeven, wordt de standaardwaarde yyyy-MM-dd'T'HH:mm:ss[.SSS][XXX]gebruikt. |
Nee |
Directe kopie naar Delta Lake
Als uw brongegevensarchief en -indeling voldoen aan de criteria die in deze sectie worden beschreven, kunt u de Copy-activiteit gebruiken om rechtstreeks van de bron naar Azure Databricks Delta Lake te kopiëren. De service controleert de instellingen en mislukt de Copy-activiteit wordt uitgevoerd als niet aan de volgende criteria wordt voldaan:
De gekoppelde bronservice is Azure Blob Storage of Azure Data Lake Storage Gen2. De accountreferenties moeten vooraf zijn geconfigureerd in de configuratie van het Azure Databricks-cluster, voor meer informatie over vereisten.
De brongegevensindeling is van Parquet, gescheiden tekst of Avro met de volgende configuraties en verwijst naar een map in plaats van bestand.
- Voor parquet-indeling is de compressiecodec geen, snappy of gzip.
- Voor tekst met scheidingstekens :
rowDelimiteris standaard of één teken.compressionkan geen zijn, bzip2, gzip.encodingNameUTF-7 wordt niet ondersteund.
- Voor Avro-indeling is de compressiecodec geen, deflate of snappy.
In de Copy-activiteit bron:
wildcardFileNamebevat alleen jokertekens*, maar niet?, enwildcardFolderNameis niet opgegeven.prefix,modifiedDateTimeStart,modifiedDateTimeEndenenablePartitionDiscoveryzijn niet opgegeven.additionalColumnsis niet opgegeven.
In de toewijzing Copy-activiteit is typeconversie niet ingeschakeld.
Voorbeeld:
"activities":[
{
"name": "CopyToDeltaLake",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Delta lake output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "AzureDatabricksDeltaLakeSink",
"sqlReadrQuery": "VACUUM eventsTable DRY RUN"
}
}
}
]
Gefaseerde kopie naar Delta Lake
Wanneer uw brongegevensarchief of -indeling niet overeenkomt met de criteria voor directe kopie, zoals vermeld in de laatste sectie, schakelt u de ingebouwde gefaseerde kopie in met behulp van een tussentijdse Azure-opslaginstantie. De functie voor gefaseerde kopie biedt u ook betere doorvoer. De service converteert de gegevens automatisch om te voldoen aan de vereisten voor de gegevensindeling in faseringsopslag en laad vervolgens gegevens in Delta Lake. Ten slotte worden uw tijdelijke gegevens uit de opslag opgeschoond. Zie Gefaseerde kopie voor meer informatie over het kopiëren van gegevens met behulp van fasering.
Als u deze functie wilt gebruiken, maakt u een gekoppelde Azure Blob Storage-service of een gekoppelde Azure Data Lake Storage Gen2-service die verwijst naar het opslagaccount als tijdelijke fasering. Geef vervolgens de enableStaging en stagingSettings eigenschappen op in de Copy-activiteit.
Notitie
De referentie voor het faseringsopslagaccount moet vooraf zijn geconfigureerd in de configuratie van het Azure Databricks-cluster, voor meer informatie over vereisten.
Voorbeeld:
"activities":[
{
"name": "CopyToDeltaLake",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Delta lake output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "AzureDatabricksDeltaLakeSink"
},
"enableStaging": true,
"stagingSettings": {
"linkedServiceName": {
"referenceName": "MyStagingBlob",
"type": "LinkedServiceReference"
},
"path": "mystagingpath"
}
}
}
]
Controleren
Dezelfde ervaring voor het bewaken van kopieeractiviteiten wordt geboden als voor andere connectors. Bovendien kunt u, omdat het laden van gegevens van/naar Delta Lake wordt uitgevoerd op uw Azure Databricks-cluster, gedetailleerde clusterlogboeken verder bekijken en de prestaties bewaken.
Eigenschappen van opzoekactiviteit
Zie Lookup-activiteit voor meer informatie over de eigenschappen.
De opzoekactiviteit kan maximaal 1000 rijen retourneren. Als de resultatenset meer records bevat, worden de eerste 1000 rijen geretourneerd.
Gerelateerde inhoud
Zie ondersteunde gegevensarchieven en -indelingen voor een lijst met gegevensarchieven die door Copy-activiteit worden ondersteund als bronnen en sinks.