Problemen met prestaties van kopieeractiviteit oplossen
VAN TOEPASSING OP:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Probeer Data Factory uit in Microsoft Fabric, een alles-in-één analyseoplossing voor ondernemingen. Microsoft Fabric omvat alles, van gegevensverplaatsing tot gegevenswetenschap, realtime analyses, business intelligence en rapportage. Meer informatie over het gratis starten van een nieuwe proefversie .
In dit artikel wordt beschreven hoe u prestatieproblemen met kopieeractiviteiten in Azure Data Factory kunt oplossen.
Nadat u een kopieeractiviteit hebt uitgevoerd, kunt u het uitvoeringsresultaat en de prestatiestatistieken verzamelen in de weergave controle van kopieeractiviteiten. Hier volgt een voorbeeld.
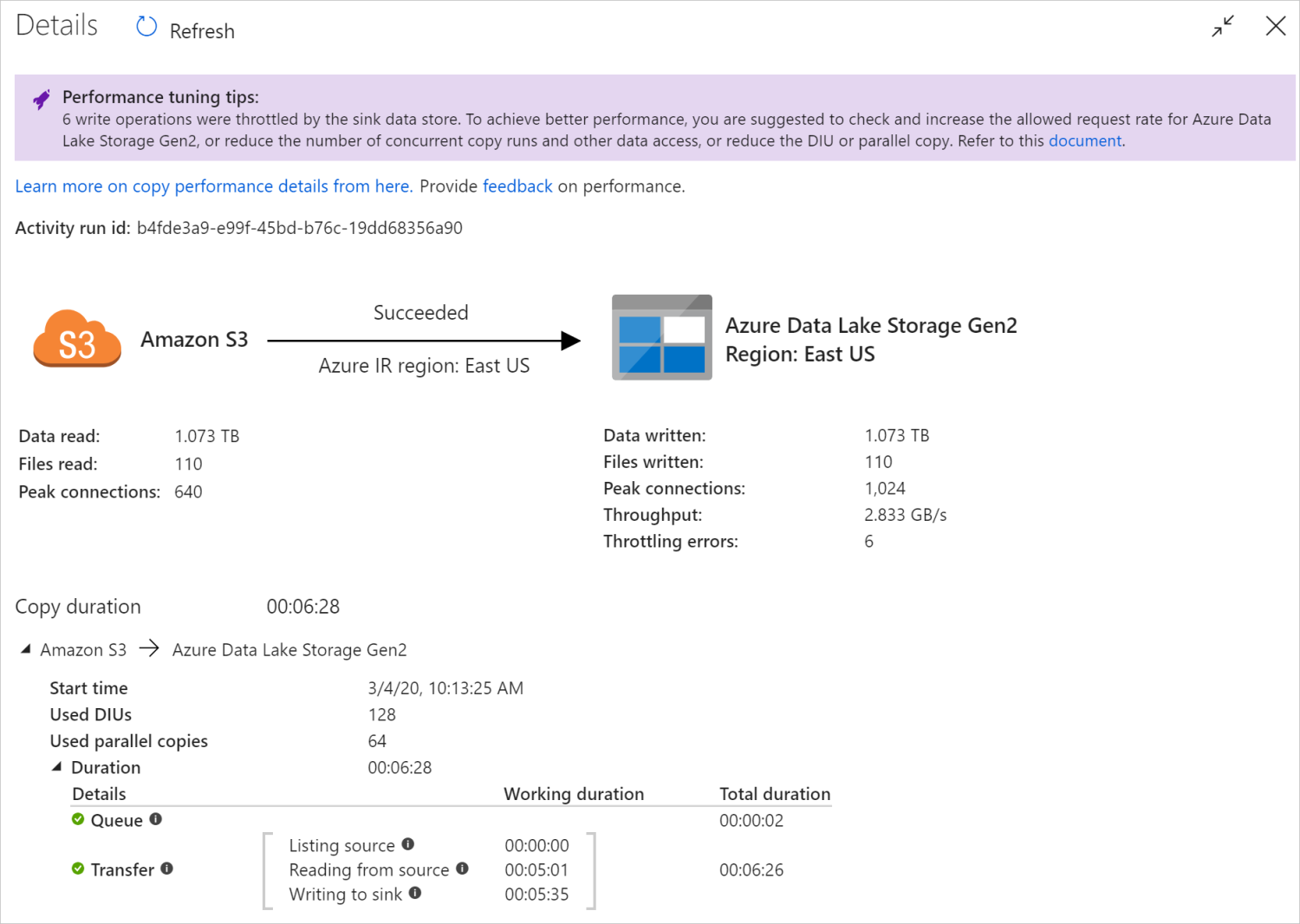
Tips voor het afstemmen van prestaties
In sommige scenario's ziet u bovenaan 'Tips voor het afstemmen van prestaties' wanneer u een kopieeractiviteit uitvoert, zoals wordt weergegeven in het bovenstaande voorbeeld. De tips vertellen u het knelpunt dat is geïdentificeerd door de service voor deze specifieke kopieeruitvoering, samen met suggesties voor het verhogen van de kopieerdoorvoer. Probeer de aanbevolen wijziging aan te brengen en voer de kopie opnieuw uit.
Ter referentie bieden momenteel de tips voor het afstemmen van prestaties suggesties voor de volgende gevallen:
| Categorie | Tips voor het afstemmen van prestaties |
|---|---|
| Gegevensarchief specifiek | Gegevens laden in Azure Synapse Analytics: stel voor om de PolyBase- of COPY-instructie te gebruiken als deze niet wordt gebruikt. |
| Gegevens kopiëren van/naar Azure SQL Database: wanneer DTU onder hoog gebruik valt, kunt u een upgrade naar een hogere laag voorstellen. | |
| Gegevens kopiëren van/naar Azure Cosmos DB: wanneer RU onder hoog gebruik valt, kunt u een upgrade naar een grotere RU voorstellen. | |
| Gegevens kopiëren uit SAP Table: bij het kopiëren van grote hoeveelheden gegevens kunt u de partitieoptie van de SAP-connector gebruiken om parallelle belasting in te schakelen en het maximale partitienummer te verhogen. | |
| Gegevens opnemen van Amazon Redshift: stel voor om UNLOAD te gebruiken als deze niet wordt gebruikt. | |
| Beperking van gegevensopslag | Als een aantal lees-/schrijfbewerkingen tijdens het kopiëren wordt beperkt door het gegevensarchief, stelt u voor om de toegestane aanvraagsnelheid voor het gegevensarchief te controleren en te verhogen of de gelijktijdige workload te verminderen. |
| Integration Runtime | Als u een zelf-hostende Integration Runtime (IR) gebruikt en kopieeractiviteit lang in de wachtrij wacht totdat de IR beschikbare resource heeft om uit te voeren, kunt u het uitschalen/omhoog schalen van uw IR voorstellen. |
| Als u een Azure Integration Runtime gebruikt die zich in een niet optimale regio bevindt, wat resulteert in trage lees-/schrijfbewerkingen, kunt u het configureren voor het gebruik van een IR in een andere regio voorstellen. | |
| Fouttolerantie | Als u fouttolerantie configureert en incompatibele rijen overslaat, leidt dit tot trage prestaties, raden we u aan ervoor te zorgen dat bron- en sinkgegevens compatibel zijn. |
| Gefaseerde kopie | Als gefaseerde kopie is geconfigureerd, maar niet nuttig is voor uw bron-sinkpaar, kunt u het verwijderen ervan voorstellen. |
| Hervatten | Wanneer de kopieeractiviteit wordt hervat vanaf het laatste storingspunt, maar u de DIU-instelling na de oorspronkelijke uitvoering wijzigt, ziet u dat de nieuwe DIU-instelling niet van kracht wordt. |
Meer informatie over uitvoeringsdetails van kopieeractiviteit
In de uitvoeringsdetails en duur onder aan de bewakingsweergave van de kopieeractiviteit worden de belangrijkste fasen beschreven die uw kopieeractiviteit doorloopt (zie het voorbeeld aan het begin van dit artikel). Dit is vooral handig voor het oplossen van problemen met de kopieerprestaties. Het knelpunt van de kopieeruitvoering is het knelpunt met de langste duur. Raadpleeg de volgende tabel in de definitie van elke fase en leer hoe u problemen met kopieeractiviteit in Azure IR kunt oplossen en problemen met kopieeractiviteit op zelf-hostende IR kunt oplossen met dergelijke informatie.
| Fase | Beschrijving |
|---|---|
| Queue | De verstreken tijd totdat de kopieeractiviteit daadwerkelijk begint op de integratieruntime. |
| Script vooraf kopiëren | De verstreken tijd tussen de kopieeractiviteit die begint op IR en de kopieeractiviteit wordt beëindigd en het uitvoeren van het script vóór het kopiëren in de sink-gegevensopslag wordt uitgevoerd. Pas toe wanneer u het script voor het vooraf kopiëren voor database-sinks configureert, bijvoorbeeld wanneer u gegevens naar Azure SQL Database schrijft, opschonen voordat u nieuwe gegevens kopieert. |
| Overdracht | De verstreken tijd tussen het einde van de vorige stap en de IR die alle gegevens van de bron naar sink overdraagt. Let op de substappen onder overdracht worden parallel uitgevoerd en sommige bewerkingen worden nu niet weergegeven, bijvoorbeeld het parseren/genereren van bestandsindelingen. - Tijd tot eerste byte: de tijd die is verstreken tussen het einde van de vorige stap en de tijd waarop de IR de eerste byte van het brongegevensarchief ontvangt. Van toepassing op niet-bestandsbronnen. - Bron vermelden: de hoeveelheid tijd die is besteed aan het inventariseren van bronbestanden of gegevenspartities. Dit laatste geldt wanneer u partitieopties voor databasebronnen configureert, bijvoorbeeld wanneer u gegevens kopieert uit databases zoals Oracle/SAP HANA/Teradata/Netezza/etc. -Lezen uit bron: De hoeveelheid tijd die is besteed aan het ophalen van gegevens uit het brongegevensarchief. - Schrijven naar sink: de hoeveelheid tijd die is besteed aan het schrijven van gegevens naar sinkgegevensopslag. Houd er rekening mee dat sommige connectors momenteel niet over deze metrische gegevens beschikken, waaronder Azure AI Search, Azure Data Explorer, Azure Table Storage, Oracle, SQL Server, Common Data Service, Dynamics 365, Dynamics CRM, Salesforce/Salesforce Service Cloud. |
Problemen met kopieeractiviteit in Azure IR oplossen
Volg de stappen voor het afstemmen van prestaties om prestatietests voor uw scenario te plannen en uit te voeren.
Wanneer de prestaties van de kopieeractiviteit niet aan uw verwachting voldoen, kunt u problemen met één kopieeractiviteit oplossen die wordt uitgevoerd in Azure Integration Runtime. Als u tips ziet voor het afstemmen van prestaties die worden weergegeven in de weergave voor kopiëren, past u de suggestie toe en probeert u het opnieuw. Anders moet u de uitvoeringsdetails van de kopieeractiviteit begrijpen, controleren welke fase de langste duur heeft en de onderstaande richtlijnen toepassen om de kopieerprestaties te verbeteren:
'Script vooraf kopiëren' heeft een lange duur ervaren: dit betekent dat het script dat wordt uitgevoerd op de sinkdatabase lang duurt. Stem de opgegeven pre-copy scriptlogica af om de prestaties te verbeteren. Neem contact op met het databaseteam als u meer hulp nodig hebt bij het verbeteren van het script.
'Overdracht - Tijd naar eerste byte' heeft lange werkduur ervaren: dit betekent dat het lang duurt voordat uw bronquery gegevens retourneert. Controleer en optimaliseer de query of server. Neem contact op met uw gegevensarchiefteam als u meer hulp nodig hebt.
'Overdracht - Bron vermelden' heeft lange werkduur ervaren: dit betekent dat het inventariseren van bronbestanden of brondatabasegegevenspartities traag is.
Wanneer u gegevens kopieert uit een bron op basis van een bestand, als u een jokertekenfilter gebruikt op mappad of bestandsnaam (
wildcardFolderPathofwildcardFileName), of als u het filter voor het laatst gewijzigd bestand gebruikt (modifiedDatetimeStartofmodifiedDatetimeEnd), resulteert dit filter in kopieeractiviteit met alle bestanden onder de opgegeven map op de clientzijde en past u het filter toe. Dergelijke bestandsumeratie kan het knelpunt worden, met name wanneer slechts een kleine set bestanden voldoet aan de filterregel.Controleer of u bestanden kunt kopiëren op basis van het gepartitioneerde bestandspad of de naam van datum/tijd. Een dergelijke manier brengt geen lasten met zich mee voor de bronzijde.
Controleer of u in plaats daarvan het systeemeigen filter van het gegevensarchief kunt gebruiken, met name 'voorvoegsel' voor Amazon S3/Azure Blob Storage/Azure Files en 'listAfter/listBefore' voor ADLS Gen1. Deze filters zijn het filter aan de serverzijde van het gegevensarchief en zouden veel betere prestaties hebben.
Overweeg om één grote gegevensset te splitsen in verschillende kleinere gegevenssets en deze kopieertaken gelijktijdig uit te voeren op elk deel van de gegevens. U kunt dit doen met Lookup/GetMetadata + ForEach + Copy. Raadpleeg Bestanden kopiëren uit meerdere containers of gegevens migreren van Amazon S3 naar ADLS Gen2-oplossingssjablonen als algemeen voorbeeld.
Controleer of de service een beperkingsfout rapporteert aan de bron of of uw gegevensarchief een hoge gebruiksstatus heeft. Als dit het geval is, vermindert u uw workloads in het gegevensarchief of neemt u contact op met de beheerder van het gegevensarchief om de beperkingslimiet of de beschikbare resource te verhogen.
Gebruik Azure IR in hetzelfde of dicht bij uw brongegevensarchiefregio.
"Overdracht - lezen van bron" heeft een lange werkduur ervaren:
Gebruik de aanbevolen procedure voor het laden van connectorspecifieke gegevens als dit van toepassing is. Wanneer u bijvoorbeeld gegevens van Amazon Redshift kopieert, configureert u voor het gebruik van Redshift UNLOAD.
Controleer of de service een beperkingsfout rapporteert aan de bron of of uw gegevensarchief te veel wordt gebruikt. Als dit het geval is, vermindert u uw workloads in het gegevensarchief of neemt u contact op met de beheerder van het gegevensarchief om de beperkingslimiet of de beschikbare resource te verhogen.
Controleer uw kopieerbron- en sinkpatroon:
Als uw kopieerpatroon ondersteuning biedt voor meer dan 4 Data-Integratie eenheden (DIU's), raadpleegt u deze sectie over details. Over het algemeen kunt u proberen om dius te verhogen om betere prestaties te krijgen.
Anders kun je overwegen om één grote gegevensset op te splitsen in een aantal kleinere gegevenssets en die kopieertaken gelijktijdig uit te voeren op elke gegevensset. U kunt dit doen met Lookup/GetMetadata + ForEach + Copy. Raadpleeg Bestanden kopiëren uit meerdere containers, Gegevens migreren van Amazon S3 naar ADLS Gen2 of bulksgewijs kopiëren met sjablonen voor beheertabellen als algemeen voorbeeld.
Gebruik Azure IR in hetzelfde of dicht bij uw brongegevensarchiefregio.
"Overdracht - schrijven naar sink" heeft een lange werkduur ervaren:
Gebruik de aanbevolen procedure voor het laden van connectorspecifieke gegevens als dit van toepassing is. Als u bijvoorbeeld gegevens kopieert naar Azure Synapse Analytics, gebruikt u de PolyBase- of COPY-instructie.
Controleer of de service een beperkingsfout rapporteert aan de sink of of uw gegevensarchief onder hoog gebruik valt. Als dit het geval is, vermindert u uw workloads in het gegevensarchief of neemt u contact op met de beheerder van het gegevensarchief om de beperkingslimiet of de beschikbare resource te verhogen.
Controleer uw kopieerbron- en sinkpatroon:
Als uw kopieerpatroon ondersteuning biedt voor meer dan 4 Data-Integratie eenheden (DIU's), raadpleegt u deze sectie over details. Over het algemeen kunt u proberen om dius te verhogen om betere prestaties te krijgen.
Anders kunt u de parallelle kopieën geleidelijk afstemmen. Houd er rekening mee dat te veel parallelle kopieën zelfs de prestaties kunnen schaden.
Gebruik Azure IR in hetzelfde of dicht bij uw sinkgegevensarchiefregio.
Problemen met kopieeractiviteit in zelf-hostende IR oplossen
Volg de stappen voor het afstemmen van prestaties om prestatietests voor uw scenario te plannen en uit te voeren.
Wanneer de kopieerprestaties niet aan uw verwachtingen voldoen, kunt u problemen met enkele kopieeractiviteit oplossen die wordt uitgevoerd in Azure Integration Runtime. Als u tips voor het afstemmen van prestaties ziet die worden weergegeven in de weergave voor het bewaken van kopiëren, past u de suggestie toe en probeert u het opnieuw. Anders moet u de uitvoeringsdetails van de kopieeractiviteit begrijpen, controleren welke fase de langste duur heeft en de onderstaande richtlijnen toepassen om de kopieerprestaties te verbeteren:
'Wachtrij' heeft lange duur ervaren: dit betekent dat de kopieeractiviteit lang in de wachtrij wacht totdat uw zelf-hostende IR resource heeft om uit te voeren. Controleer de ir-capaciteit en het gebruik en schaal omhoog of uit op basis van uw workload.
'Overdracht - Tijd naar eerste byte' heeft lange werkduur ervaren: dit betekent dat het lang duurt voordat uw bronquery gegevens retourneert. Controleer en optimaliseer de query of server. Neem contact op met uw gegevensarchiefteam als u meer hulp nodig hebt.
'Overdracht - Bron vermelden' heeft lange werkduur ervaren: dit betekent dat het inventariseren van bronbestanden of brondatabasegegevenspartities traag is.
Controleer of de zelf-hostende IR-machine een lage latentie heeft die verbinding maakt met het brongegevensarchief. Als uw bron zich in Azure bevindt, kunt u dit hulpprogramma gebruiken om de latentie van de zelf-hostende IR-machine naar de Azure-regio te controleren, hoe minder des te beter.
Wanneer u gegevens kopieert uit een bron op basis van een bestand, als u een jokertekenfilter gebruikt op mappad of bestandsnaam (
wildcardFolderPathofwildcardFileName), of als u het filter voor het laatst gewijzigd bestand gebruikt (modifiedDatetimeStartofmodifiedDatetimeEnd), resulteert dit filter in kopieeractiviteit met alle bestanden onder de opgegeven map op de clientzijde en past u het filter toe. Dergelijke bestandsumeratie kan het knelpunt worden, met name wanneer slechts een kleine set bestanden voldoet aan de filterregel.Controleer of u bestanden kunt kopiëren op basis van het gepartitioneerde bestandspad of de naam van datum/tijd. Een dergelijke manier brengt geen lasten met zich mee voor de bronzijde.
Controleer of u in plaats daarvan het systeemeigen filter van het gegevensarchief kunt gebruiken, met name 'voorvoegsel' voor Amazon S3/Azure Blob Storage/Azure Files en 'listAfter/listBefore' voor ADLS Gen1. Deze filters zijn het filter aan de serverzijde van het gegevensarchief en zouden veel betere prestaties hebben.
Overweeg om één grote gegevensset te splitsen in verschillende kleinere gegevenssets en deze kopieertaken gelijktijdig uit te voeren op elk deel van de gegevens. U kunt dit doen met Lookup/GetMetadata + ForEach + Copy. Raadpleeg Bestanden kopiëren uit meerdere containers of gegevens migreren van Amazon S3 naar ADLS Gen2-oplossingssjablonen als algemeen voorbeeld.
Controleer of de service een beperkingsfout rapporteert aan de bron of of uw gegevensarchief een hoge gebruiksstatus heeft. Als dit het geval is, vermindert u uw workloads in het gegevensarchief of neemt u contact op met de beheerder van het gegevensarchief om de beperkingslimiet of de beschikbare resource te verhogen.
"Overdracht - lezen van bron" heeft een lange werkduur ervaren:
Controleer of de zelf-hostende IR-machine een lage latentie heeft die verbinding maakt met het brongegevensarchief. Als uw bron zich in Azure bevindt, kunt u dit hulpprogramma gebruiken om de latentie van de zelf-hostende IR-machine naar de Azure-regio's te controleren, hoe minder beter.
Controleer of de zelf-hostende IR-machine voldoende binnenkomende bandbreedte heeft om de gegevens efficiënt te lezen en over te dragen. Als uw brongegevensarchief zich in Azure bevindt, kunt u dit hulpprogramma gebruiken om de downloadsnelheid te controleren.
Controleer de trend van het CPU- en geheugengebruik van de zelf-hostende IR in Azure Portal:> uw data factory of Synapse-werkruimte -> overzichtspagina. Overweeg om ir omhoog/uit te schalen als het CPU-gebruik hoog of beschikbaar geheugen laag is.
Gebruik de aanbevolen procedure voor het laden van connectorspecifieke gegevens als dit van toepassing is. Voorbeeld:
Bij het kopiëren van gegevens uit Oracle, Netezza, Teradata, SAP HANA, SAP Table en SAP Open Hub), schakelt u opties voor gegevenspartitie in om gegevens parallel te kopiëren.
Wanneer u gegevens kopieert vanuit HDFS, configureert u deze om DistCp te gebruiken.
Wanneer u gegevens van Amazon Redshift kopieert, configureert u voor het gebruik van Redshift UNLOAD.
Controleer of de service een beperkingsfout rapporteert aan de bron of of uw gegevensarchief te veel wordt gebruikt. Als dit het geval is, vermindert u uw workloads in het gegevensarchief of neemt u contact op met de beheerder van het gegevensarchief om de beperkingslimiet of de beschikbare resource te verhogen.
Controleer uw kopieerbron- en sinkpatroon:
Als u gegevens kopieert uit gegevensarchieven met partitieopties, kunt u overwegen om de parallelle kopieën geleidelijk af te stemmen. Houd er rekening mee dat te veel parallelle kopieën zelfs de prestaties kunnen schaden.
Anders kun je overwegen om één grote gegevensset op te splitsen in een aantal kleinere gegevenssets en die kopieertaken gelijktijdig uit te voeren op elke gegevensset. U kunt dit doen met Lookup/GetMetadata + ForEach + Copy. Raadpleeg Bestanden kopiëren uit meerdere containers, Gegevens migreren van Amazon S3 naar ADLS Gen2 of bulksgewijs kopiëren met sjablonen voor beheertabellen als algemeen voorbeeld.
"Overdracht - schrijven naar sink" heeft een lange werkduur ervaren:
Gebruik de aanbevolen procedure voor het laden van connectorspecifieke gegevens als dit van toepassing is. Als u bijvoorbeeld gegevens kopieert naar Azure Synapse Analytics, gebruikt u de PolyBase- of COPY-instructie.
Controleer of de zelf-hostende IR-machine een lage latentie heeft die verbinding maakt met sinkgegevensopslag. Als uw sink zich in Azure bevindt, kunt u dit hulpprogramma gebruiken om de latentie van de zelf-hostende IR-machine naar de Azure-regio te controleren, hoe minder des te beter.
Controleer of de zelf-hostende IR-machine voldoende uitgaande bandbreedte heeft om de gegevens efficiënt over te dragen en te schrijven. Als uw sinkgegevensarchief zich in Azure bevindt, kunt u dit hulpprogramma gebruiken om de uploadsnelheid te controleren.
Controleer of de trend voor cpu- en geheugengebruik van de zelf-hostende IR in Azure Portal,> uw data factory of Synapse-werkruimte,> overzichtspagina. Overweeg om ir omhoog/uit te schalen als het CPU-gebruik hoog of beschikbaar geheugen laag is.
Controleer of de service een beperkingsfout rapporteert aan de sink of of uw gegevensarchief onder hoog gebruik valt. Als dit het geval is, vermindert u uw workloads in het gegevensarchief of neemt u contact op met de beheerder van het gegevensarchief om de beperkingslimiet of de beschikbare resource te verhogen.
Overweeg om de parallelle kopieën geleidelijk af te stemmen. Houd er rekening mee dat te veel parallelle kopieën zelfs de prestaties kunnen schaden.
Connector- en IR-prestaties
In deze sectie worden enkele handleidingen voor het oplossen van prestatieproblemen besproken voor een bepaald type connector of integratieruntime.
Uitvoeringstijd van activiteit varieert met Behulp van Azure IR versus Azure VNet IR
De uitvoeringstijd van de activiteit varieert wanneer de gegevensset is gebaseerd op verschillende Integration Runtime.
Symptomen: Door de vervolgkeuzelijst Gekoppelde service in de gegevensset in te schakelen, worden dezelfde pijplijnactiviteiten uitgevoerd, maar zijn er drastisch verschillende runtimes. Wanneer de gegevensset is gebaseerd op de Managed Virtual Network Integration Runtime, duurt het gemiddeld meer tijd dan de uitvoering wanneer deze is gebaseerd op de Default Integration Runtime.
Oorzaak: Als u de details van pijplijnuitvoeringen controleert, ziet u dat de trage pijplijn wordt uitgevoerd op de beheerde VNet-IR (virtueel netwerk) terwijl de normale uitvoering wordt uitgevoerd in Azure IR. Beheerde VNet-IR duurt standaard langer in de wachtrij dan Azure IR, omdat we niet één rekenknooppunt per service-exemplaar reserveren, dus er is een opwarming voor elke kopieeractiviteit die moet worden gestart en het gebeurt voornamelijk bij VNet-join in plaats van Azure IR.
Lage prestaties bij het laden van gegevens in Azure SQL Database
Symptomen: het kopiëren van gegevens naar Azure SQL Database is traag.
Oorzaak: de hoofdoorzaak van het probleem wordt meestal geactiveerd door het knelpunt van de azure SQL Database-zijde. Hier volgen enkele mogelijke oorzaken:
De Azure SQL Database-laag is niet hoog genoeg.
Het DTU-gebruik van Azure SQL Database ligt dicht bij 100%. U kunt de prestaties bewaken en overwegen om de Azure SQL Database-laag te upgraden.
Indexen zijn niet juist ingesteld. Verwijder alle indexen voordat gegevens worden geladen en maak ze opnieuw nadat de belasting is voltooid.
WriteBatchSize is niet groot genoeg om de grootte van de schemarij aan te passen. Probeer de eigenschap voor het probleem te vergroten.
In plaats van bulksgewijs invoegen wordt opgeslagen procedure gebruikt, wat naar verwachting slechtere prestaties heeft.
Time-out of trage prestaties bij het parseren van een groot Excel-bestand
Symptomen:
Wanneer u een Excel-gegevensset maakt en een schema importeert uit verbinding/archief, voorbeeldgegevens, lijsten of werkbladen vernieuwt, kan er een time-outfout optreden als het Excel-bestand groot is.
Wanneer u kopieeractiviteit gebruikt om gegevens uit een groot Excel-bestand (>= 100 MB) te kopiëren naar een ander gegevensarchief, kan er sprake zijn van trage prestaties of OOM-problemen.
Oorzaak:
Voor bewerkingen zoals het importeren van een schema, het bekijken van gegevens en het weergeven van werkbladen in excel-gegevensset, is de time-out 100 s en statisch. Voor een groot Excel-bestand worden deze bewerkingen mogelijk niet voltooid binnen de time-outwaarde.
De kopieeractiviteit leest het hele Excel-bestand in het geheugen en zoekt vervolgens het opgegeven werkblad en de opgegeven cellen om gegevens te lezen. Dit gedrag wordt veroorzaakt door de onderliggende SDK die door de service wordt gebruikt.
Oplossing:
Voor het importeren van een schema kunt u een kleiner voorbeeldbestand genereren. Dit is een subset van het oorspronkelijke bestand en kiest u 'Schema importeren uit voorbeeldbestand' in plaats van 'schema importeren uit verbinding/archief'.
Als u een werkblad wilt weergeven, klikt u in de vervolgkeuzelijst van het werkblad op Bewerken en voert u in plaats daarvan de naam/index van het blad in.
Als u een groot Excel-bestand (>100 MB) naar een ander archief wilt kopiëren, kunt u Gegevensstroom Excel-bron gebruiken die sportstreaming beter leest en beter presteert.
Het OOM-probleem van het lezen van grote JSON-/Excel/XML-bestanden
Symptomen: wanneer u grote JSON-/Excel/XML-bestanden leest, voldoet u aan het probleem met onvoldoende geheugen (OOM) tijdens de uitvoering van de activiteit.
Oorzaak:
- Voor grote XML-bestanden: het OOM-probleem van het lezen van grote XML-bestanden is standaard. De oorzaak is dat het hele XML-bestand in het geheugen moet worden gelezen omdat het één object is, waarna het schema wordt afgeleid en de gegevens worden opgehaald.
- Voor grote Excel-bestanden: het OOM-probleem van het lezen van grote Excel-bestanden is standaard. De oorzaak is dat de SDK (POI/NPOI) die wordt gebruikt, het hele Excel-bestand in het geheugen moet lezen en vervolgens het schema moet afleiden en gegevens moet ophalen.
- Voor grote JSON-bestanden: het OOM-probleem van het lezen van grote JSON-bestanden is standaard wanneer het JSON-bestand één object is.
Aanbeveling: Pas een van de volgende opties toe om uw probleem op te lossen.
- Optie-1: Registreer een online zelf-hostende Integration Runtime met krachtige computer (hoog CPU/geheugen) om gegevens uit uw grote bestand te lezen via uw kopieeractiviteit.
- Optie-2: Gebruik geoptimaliseerd geheugen en cluster met grote grootte (bijvoorbeeld 48 kernen) om gegevens uit uw grote bestand te lezen via de activiteit van de toewijzingsgegevensstroom.
- Optie-3: Splits het grote bestand in kleine bestanden en gebruik vervolgens de activiteit kopieer- of toewijzingsgegevensstroom om de map te lezen.
- Optie-4: Als u vastloopt of voldoet aan het OOM-probleem tijdens het kopiëren van de map XML/Excel/JSON, gebruikt u de foreach-activiteit + kopieer-/toewijzingsgegevensstroomactiviteit in uw pijplijn om elk bestand of elke submap te verwerken.
- Optie 5: Overige:
- Gebruik voor XML Notebook-activiteit met een cluster dat is geoptimaliseerd voor geheugen om gegevens uit bestanden te lezen als elk bestand hetzelfde schema heeft. Spark heeft momenteel verschillende implementaties voor het verwerken van XML.
- Gebruik voor JSON verschillende documentformulieren (bijvoorbeeld Één document, Document per regel en Matrix van documenten) in JSON-instellingen onder de bron van de toewijzingsgegevensstroom. Als de inhoud van het JSON-bestand document per regel is, verbruikt het weinig geheugen.
Andere naslaginformatie
Hier volgt prestatiebewaking en afstemmingsverwijzingen voor een aantal ondersteunde gegevensarchieven:
- Azure Blob Storage: schaalbaarheids- en prestatiedoelen voor blobopslag en controlelijst voor prestaties en schaalbaarheid voor Blob-opslag.
- Azure Table Storage: schaalbaarheids- en prestatiedoelen voor tableopslag en controlelijst voor prestaties en schaalbaarheid voor Table Storage.
- Azure SQL Database: u kunt de prestaties bewaken en het DTU-percentage (Database Transaction Unit) controleren.
- Azure Synapse Analytics: de mogelijkheid wordt gemeten in DWU's (Data Warehouse Units). Zie Rekenkracht beheren in Azure Synapse Analytics (overzicht).
- Azure Cosmos DB: prestatieniveaus in Azure Cosmos DB.
- SQL Server: De prestaties bewaken en afstemmen.
- On-premises bestandsserver: prestaties afstemmen voor bestandsservers.
Gerelateerde inhoud
Zie de andere artikelen over kopieeractiviteiten: