Gegevens kopiëren van de HDFS-server met behulp van Azure Data Factory of Synapse Analytics
VAN TOEPASSING OP:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Probeer Data Factory uit in Microsoft Fabric, een alles-in-één analyseoplossing voor ondernemingen. Microsoft Fabric omvat alles, van gegevensverplaatsing tot gegevenswetenschap, realtime analyses, business intelligence en rapportage. Meer informatie over het gratis starten van een nieuwe proefversie .
In dit artikel wordt beschreven hoe u gegevens kopieert van de HDFS-server (Hadoop Distributed File System). Lees de inleidende artikelen voor Azure Data Factory en Synapse Analytics voor meer informatie.
Ondersteunde mogelijkheden
Deze HDFS-connector wordt ondersteund voor de volgende mogelijkheden:
| Ondersteunde mogelijkheden | IR |
|---|---|
| Copy-activiteit (bron/-) | (1) (2) |
| Activiteit Lookup | (1) (2) |
| Activiteit verwijderen | (1) (2) |
(1) Azure Integration Runtime (2) Zelf-hostende Integration Runtime
De HDFS-connector ondersteunt met name:
- Bestanden kopiëren met behulp van Windows (Kerberos) of anonieme verificatie.
- Bestanden kopiëren met behulp van het webhdfs-protocol of ingebouwde DistCp-ondersteuning .
- Bestanden kopiëren zoals dit is of door bestanden te parseren of genereren met de ondersteunde bestandsindelingen en compressiecodecs.
Vereisten
Als uw gegevensarchief zich in een on-premises netwerk, een virtueel Azure-netwerk of een virtuele particuliere cloud van Amazon bevindt, moet u een zelf-hostende Integration Runtime configureren om er verbinding mee te maken.
Als uw gegevensarchief een beheerde cloudgegevensservice is, kunt u De Azure Integration Runtime gebruiken. Als de toegang is beperkt tot IP-adressen die zijn goedgekeurd in de firewallregels, kunt u IP-adressen van Azure Integration Runtime toevoegen aan de acceptatielijst.
U kunt ook de beheerde functie voor integratieruntime voor virtuele netwerken in Azure Data Factory gebruiken om toegang te krijgen tot het on-premises netwerk zonder een zelf-hostende Integration Runtime te installeren en te configureren.
Zie Strategieën voor gegevenstoegang voor meer informatie over de netwerkbeveiligingsmechanismen en -opties die door Data Factory worden ondersteund.
Notitie
Zorg ervoor dat de integration runtime toegang heeft tot alle [naamknooppuntserver]:[naamknooppuntpoort] en [gegevensknooppuntservers]:[gegevensknooppuntpoort] van het Hadoop-cluster. De standaardpoort [naamknooppunt] is 50070 en de standaardpoort [gegevensknooppunt] is 50075.
Aan de slag
Als u de kopieeractiviteit wilt uitvoeren met een pijplijn, kunt u een van de volgende hulpprogramma's of SDK's gebruiken:
- Het hulpprogramma voor het kopiëren van gegevens
- Azure Portal
- De .NET-SDK
- De Python-SDK
- Azure PowerShell
- De REST API
- Een Azure Resource Manager-sjabloon
Een gekoppelde service maken met HDFS met behulp van de gebruikersinterface
Gebruik de volgende stappen om een gekoppelde service te maken met HDFS in de gebruikersinterface van Azure Portal.
Blader naar het tabblad Beheren in uw Azure Data Factory- of Synapse-werkruimte en selecteer Gekoppelde services en klik vervolgens op Nieuw:
Zoek naar HDFS en selecteer de HDFS-connector.
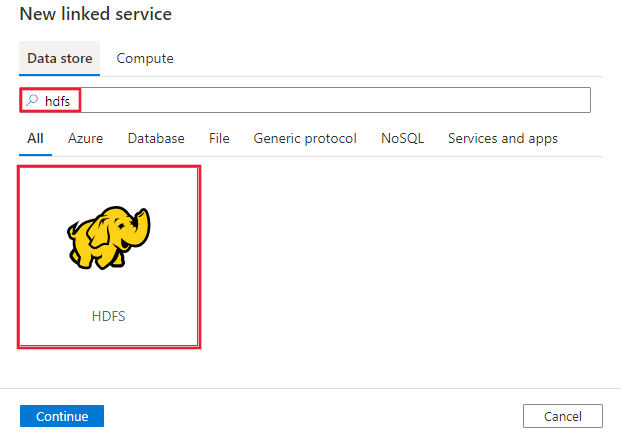
Configureer de servicedetails, test de verbinding en maak de nieuwe gekoppelde service.
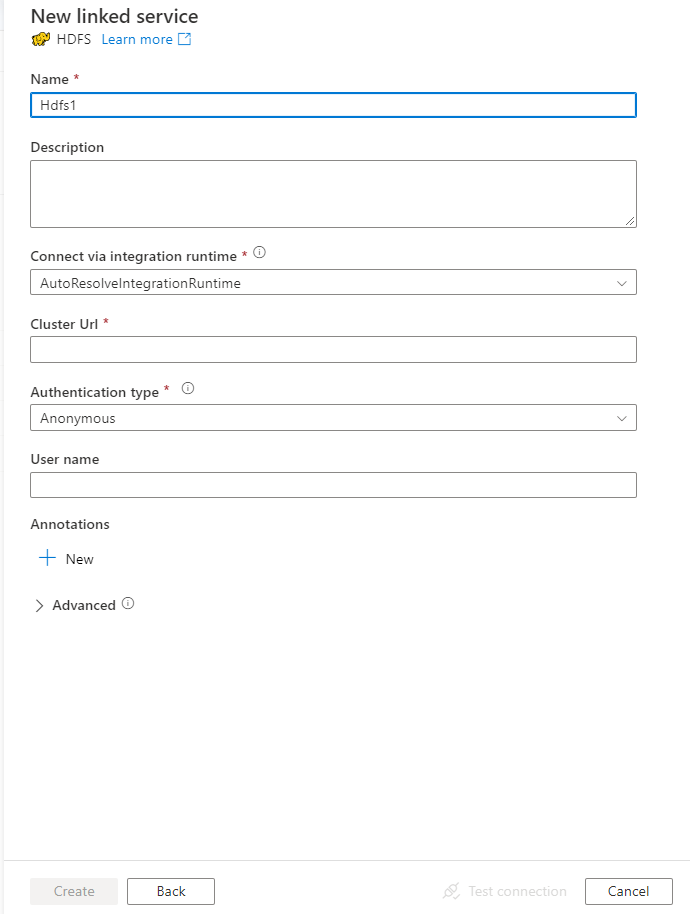
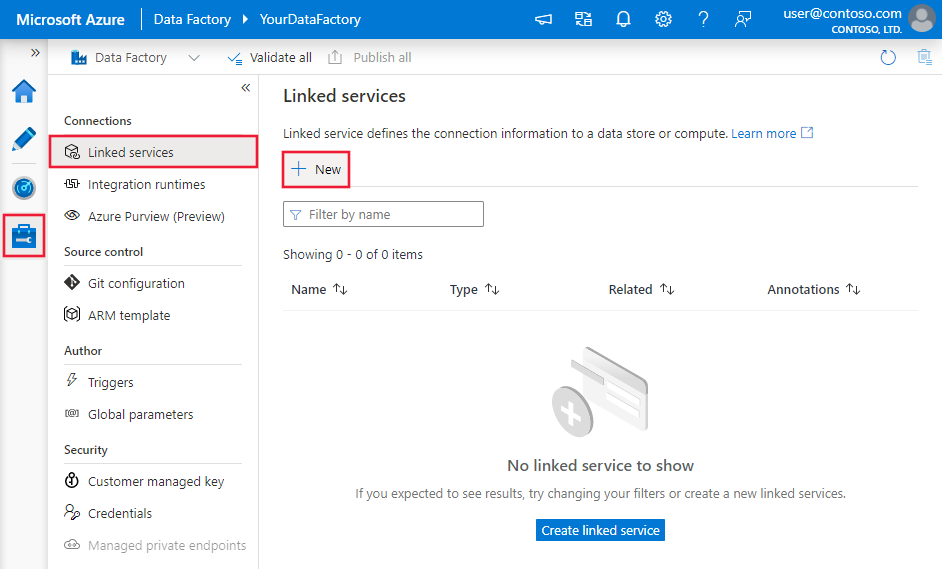
Configuratiedetails van connector
De volgende secties bevatten details over eigenschappen die worden gebruikt voor het definiëren van Data Factory-entiteiten die specifiek zijn voor HDFS.
Eigenschappen van gekoppelde service
De volgende eigenschappen worden ondersteund voor de gekoppelde HDFS-service:
| Eigenschappen | Beschrijving | Vereist |
|---|---|---|
| type | De eigenschap type moet worden ingesteld op Hdfs. | Ja |
| URL | De URL naar de HDFS | Ja |
| authenticationType | De toegestane waarden zijn Anoniem of Windows. Als u uw on-premises omgeving wilt instellen, raadpleegt u de sectie Kerberos-verificatie gebruiken voor de HDFS-connector . |
Ja |
| gebruikersnaam | De gebruikersnaam voor Windows-verificatie. Geef <voor Kerberos-verificatie gebruikersnaam>@<domein> op.com. | Ja (voor Windows-verificatie) |
| password | Het wachtwoord voor Windows-verificatie. Markeer dit veld als SecureString om het veilig op te slaan of verwijs naar een geheim dat is opgeslagen in een Azure-sleutelkluis. | Ja (voor Windows-verificatie) |
| connectVia | De Integration Runtime die moet worden gebruikt om verbinding te maken met het gegevensarchief. Zie de sectie Vereisten voor meer informatie. Als de integration runtime niet is opgegeven, gebruikt de service de standaard Azure Integration Runtime. | Nee |
Voorbeeld: anonieme verificatie gebruiken
{
"name": "HDFSLinkedService",
"properties": {
"type": "Hdfs",
"typeProperties": {
"url" : "http://<machine>:50070/webhdfs/v1/",
"authenticationType": "Anonymous",
"userName": "hadoop"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Voorbeeld: Windows-verificatie gebruiken
{
"name": "HDFSLinkedService",
"properties": {
"type": "Hdfs",
"typeProperties": {
"url" : "http://<machine>:50070/webhdfs/v1/",
"authenticationType": "Windows",
"userName": "<username>@<domain>.com (for Kerberos auth)",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Eigenschappen van gegevensset
Zie Gegevenssets voor een volledige lijst met secties en eigenschappen die beschikbaar zijn voor het definiëren van gegevenssets.
Azure Data Factory ondersteunt de volgende bestandsindelingen. Raadpleeg elk artikel voor op indeling gebaseerde instellingen.
- Avro-indeling
- Binaire indeling
- Tekstindeling met scheidingstekens
- Excel-indeling
- JSON-indeling
- ORC-indeling
- Parquet-indeling
- XML-indeling
De volgende eigenschappen worden ondersteund voor HDFS onder location instellingen in de op indeling gebaseerde gegevensset:
| Eigenschappen | Beschrijving | Vereist |
|---|---|---|
| type | De typeeigenschap onder location in de gegevensset moet worden ingesteld op HdfsLocation. |
Ja |
| folderPath | Het pad naar de map. Als u een jokerteken wilt gebruiken om de map te filteren, slaat u deze instelling over en geeft u het pad op in de instellingen van de activiteitsbron. | Nee |
| fileName | De bestandsnaam onder het opgegeven folderPath. Als u een jokerteken wilt gebruiken om bestanden te filteren, slaat u deze instelling over en geeft u de bestandsnaam op in de instellingen van de activiteitsbron. | Nee |
Voorbeeld:
{
"name": "DelimitedTextDataset",
"properties": {
"type": "DelimitedText",
"linkedServiceName": {
"referenceName": "<HDFS linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, auto retrieved during authoring > ],
"typeProperties": {
"location": {
"type": "HdfsLocation",
"folderPath": "root/folder/subfolder"
},
"columnDelimiter": ",",
"quoteChar": "\"",
"firstRowAsHeader": true,
"compressionCodec": "gzip"
}
}
}
Eigenschappen van de kopieeractiviteit
Zie Pijplijnen en activiteiten voor een volledige lijst met secties en eigenschappen die beschikbaar zijn voor het definiëren van activiteiten. Deze sectie bevat een lijst met eigenschappen die worden ondersteund door de HDFS-bron.
HDFS als bron
Azure Data Factory ondersteunt de volgende bestandsindelingen. Raadpleeg elk artikel voor op indeling gebaseerde instellingen.
- Avro-indeling
- Binaire indeling
- Tekstindeling met scheidingstekens
- Excel-indeling
- JSON-indeling
- ORC-indeling
- Parquet-indeling
- XML-indeling
De volgende eigenschappen worden ondersteund voor HDFS onder storeSettings instellingen in de op indeling gebaseerde kopieerbron:
| Eigenschappen | Beschrijving | Vereist |
|---|---|---|
| type | De eigenschap type onder storeSettings moet worden ingesteld op HdfsReadSettings. |
Ja |
| De bestanden zoeken die u wilt kopiëren | ||
| OPTIE 1: statisch pad |
Kopieer vanuit de map of het bestandspad dat is opgegeven in de gegevensset. Als u alle bestanden uit een map wilt kopiëren, moet u ook opgeven wildcardFileName als *. |
|
| OPTIE 2: jokerteken - jokertekenFolderPath |
Het pad naar de map met jokertekens om bronmappen te filteren. Toegestane jokertekens zijn: * (komt overeen met nul of meer tekens) en ? (komt overeen met nul of één teken). Gebruik ^ deze optie om te ontsnappen als de naam van uw map een jokerteken of dit escape-teken bevat. Zie voorbeelden van map- en bestandsfilters voor meer voorbeelden. |
Nee |
| OPTIE 2: jokerteken - wildcardFileName |
De bestandsnaam met jokertekens onder de opgegeven folderPath/wildcardFolderPath om bronbestanden te filteren. Toegestane jokertekens zijn: * (komt overeen met nul of meer tekens) en ? (komt overeen met nul of één teken); gebruik ^ dit om te ontsnappen als uw werkelijke bestandsnaam een jokerteken of dit escape-teken bevat. Zie voorbeelden van map- en bestandsfilters voor meer voorbeelden. |
Ja |
| OPTIE 3: een lijst met bestanden - fileListPath |
Geeft aan om een opgegeven bestandsset te kopiëren. Wijs een tekstbestand aan met een lijst met bestanden die u wilt kopiëren (één bestand per regel, met het relatieve pad naar het pad dat is geconfigureerd in de gegevensset). Wanneer u deze optie gebruikt, geeft u geen bestandsnaam op in de gegevensset. Zie Voorbeelden van bestandslijsten voor meer voorbeelden. |
Nee |
| Aanvullende instellingen | ||
| recursief | Hiermee wordt aangegeven of de gegevens recursief worden gelezen uit de submappen of alleen uit de opgegeven map. Wanneer recursive deze is ingesteld op true en de sink een archief op basis van bestanden is, wordt een lege map of submap niet gekopieerd of gemaakt in de sink. Toegestane waarden zijn waar (standaard) en onwaar. Deze eigenschap is niet van toepassing wanneer u configureert fileListPath. |
Nee |
| deleteFilesAfterCompletion | Geeft aan of de binaire bestanden worden verwijderd uit het bronarchief nadat ze naar het doelarchief zijn verplaatst. Het verwijderen van bestanden is per bestand, dus wanneer de kopieeractiviteit mislukt, ziet u dat sommige bestanden al naar het doel zijn gekopieerd en uit de bron zijn verwijderd, terwijl anderen nog steeds in het bronarchief blijven. Deze eigenschap is alleen geldig in het scenario voor het kopiëren van binaire bestanden. De standaardwaarde: false. |
Nee |
| modifiedDatetimeStart | Bestanden worden gefilterd op basis van het kenmerk Laatst gewijzigd. De bestanden worden geselecteerd als de laatste wijzigingstijd groter is dan of gelijk is aan modifiedDatetimeStart en kleiner is dan modifiedDatetimeEnd. De tijd wordt toegepast op de UTC-tijdzone in de notatie 2018-12-01T05:00:00Z. De eigenschappen kunnen NULL zijn, wat betekent dat er geen bestandskenmerkfilter wordt toegepast op de gegevensset. Wanneer modifiedDatetimeStart een datum/tijd-waarde is maar modifiedDatetimeEnd NULL is, betekent dit dat de bestanden waarvan het kenmerk voor het laatst is gewijzigd groter dan of gelijk zijn aan de datum/tijd-waarde zijn geselecteerd. Wanneer modifiedDatetimeEnd een datum/tijd-waarde heeft maar modifiedDatetimeStart NULL is, betekent dit dat de bestanden waarvan het kenmerk voor het laatst is gewijzigd kleiner zijn dan de datum/tijd-waarde zijn geselecteerd.Deze eigenschap is niet van toepassing wanneer u configureert fileListPath. |
Nee |
| modifiedDatetimeEnd | Hetzelfde als hierboven. | |
| enablePartitionDiscovery | Geef voor bestanden die zijn gepartitioneerd op of de partities van het bestandspad moeten worden geparseerd en als extra bronkolommen moeten worden toegevoegd. Toegestane waarden zijn onwaar (standaard) en waar. |
Nee |
| partitionRootPath | Wanneer partitiedetectie is ingeschakeld, geeft u het absolute hoofdpad op om gepartitioneerde mappen als gegevenskolommen te lezen. Als deze niet is opgegeven, is dit standaard het volgende: - Wanneer u bestandspad gebruikt in de gegevensset of lijst met bestanden op de bron, is het pad naar de partitiehoofdmap dat is geconfigureerd in de gegevensset. - Wanneer u het filter voor jokertekens gebruikt, is partitiehoofdpad het subpad vóór het eerste jokerteken. Stel dat u het pad in de gegevensset configureert als 'root/folder/year=2020/month=08/day=27': - Als u partitiehoofdpad opgeeft als root/folder/year=2020, genereert de kopieeractiviteit twee kolommen month en day met de waarde '08' en '27', naast de kolommen in de bestanden.- Als het hoofdpad van de partitie niet is opgegeven, wordt er geen extra kolom gegenereerd. |
Nee |
| maxConcurrentConnections | De bovengrens van gelijktijdige verbindingen die tijdens de uitvoering van de activiteit tot stand zijn gebracht met het gegevensarchief. Geef alleen een waarde op wanneer u gelijktijdige verbindingen wilt beperken. | Nee |
| DistCp-instellingen | ||
| distcpSettings | De eigenschapsgroep die moet worden gebruikt wanneer u HDFS DistCp gebruikt. | Nee |
| resourceManagerEndpoint | Het YARN-eindpunt (nog een andere resourceonderhandelaar) | Ja, als u DistCp gebruikt |
| tempScriptPath | Een mappad dat wordt gebruikt voor het opslaan van het tijdelijke DistCp-opdrachtscript. Het scriptbestand wordt gegenereerd en wordt verwijderd nadat de kopieertaak is voltooid. | Ja, als u DistCp gebruikt |
| distcpOptions | Aanvullende opties die beschikbaar zijn voor de distcp-opdracht. | Nee |
Voorbeeld:
"activities":[
{
"name": "CopyFromHDFS",
"type": "Copy",
"inputs": [
{
"referenceName": "<Delimited text input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "DelimitedTextSource",
"formatSettings":{
"type": "DelimitedTextReadSettings",
"skipLineCount": 10
},
"storeSettings":{
"type": "HdfsReadSettings",
"recursive": true,
"distcpSettings": {
"resourceManagerEndpoint": "resourcemanagerendpoint:8088",
"tempScriptPath": "/usr/hadoop/tempscript",
"distcpOptions": "-m 100"
}
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
Voorbeelden van map- en bestandsfilters
In deze sectie wordt het resulterende gedrag beschreven als u een jokertekenfilter gebruikt met het mappad en de bestandsnaam.
| folderPath | fileName | recursief | Structuur van bronmap en filterresultaat (bestanden vetgedrukt worden opgehaald) |
|---|---|---|---|
Folder* |
(leeg, standaard gebruiken) | false | MapA File1.csv File2.json Submap1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
Folder* |
(leeg, standaard gebruiken) | true | MapA File1.csv File2.json Submap1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
Folder* |
*.csv |
false | MapA File1.csv File2.json Submap1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
Folder* |
*.csv |
true | MapA File1.csv File2.json Submap1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
Voorbeelden van bestandslijsten
In deze sectie wordt het gedrag beschreven dat het resultaat is van het gebruik van een bestandslijstpad in de Copy-activiteit bron. Hierbij wordt ervan uitgegaan dat u de volgende bronmapstructuur hebt en de bestanden wilt kopiëren die vet zijn:
| Voorbeeldbronstructuur | Inhoud in FileListToCopy.txt | Configuratie |
|---|---|---|
| wortel MapA File1.csv File2.json Submap1 File3.csv File4.json File5.csv Metagegevens FileListToCopy.txt |
File1.csv Submap1/File3.csv Submap1/File5.csv |
In de gegevensset: - Mappad: root/FolderAIn de Copy-activiteit bron: - Pad naar bestandslijst: root/Metadata/FileListToCopy.txt Het pad naar de bestandslijst verwijst naar een tekstbestand in hetzelfde gegevensarchief met een lijst met bestanden die u wilt kopiëren (één bestand per regel, met het relatieve pad naar het pad dat is geconfigureerd in de gegevensset). |
DistCp gebruiken om gegevens uit HDFS te kopiëren
DistCp is een systeemeigen hadoop-opdrachtregelprogramma voor het uitvoeren van een gedistribueerde kopie in een Hadoop-cluster. Wanneer u een opdracht uitvoert in DistCp, worden eerst alle bestanden weergegeven die moeten worden gekopieerd en vervolgens verschillende toewijzingstaken in het Hadoop-cluster gemaakt. Elke toewijzingstaak voert een binaire kopie uit van de bron naar de sink.
De Copy-activiteit ondersteunt het gebruik van DistCp om bestanden te kopiëren naar Azure Blob Storage (inclusief gefaseerde kopie) of een Azure Data Lake Store. In dit geval kan DistCp profiteren van de kracht van uw cluster in plaats van te worden uitgevoerd op de zelf-hostende Integration Runtime. Het gebruik van DistCp biedt betere kopieerdoorvoer, met name als uw cluster zeer krachtig is. Op basis van de configuratie maakt de Copy-activiteit automatisch een DistCp-opdracht, verzendt deze naar uw Hadoop-cluster en bewaakt de kopieerstatus.
Vereisten
Als u DistCp wilt gebruiken om bestanden te kopiëren van HDFS naar Azure Blob Storage (inclusief gefaseerde kopie) of de Azure Data Lake Store, moet u ervoor zorgen dat uw Hadoop-cluster voldoet aan de volgende vereisten:
De MapReduce- en YARN-services zijn ingeschakeld.
YARN-versie is 2.5 of hoger.
De HDFS-server is geïntegreerd met uw doelgegevensarchief: Azure Blob Storage of Azure Data Lake Store (ADLS Gen1):
- Azure Blob FileSystem wordt systeemeigen ondersteund sinds Hadoop 2.7. U hoeft alleen het JAR-pad op te geven in de Hadoop-omgevingsconfiguratie.
- Azure Data Lake Store FileSystem is verpakt vanaf Hadoop 3.0.0-alpha1. Als uw Hadoop-clusterversie eerder is dan die versie, moet u vanaf hier handmatig JAR-pakketten (azure-datalake-store.jar) van Azure Data Lake Store importeren in het cluster en het JAR-bestandspad opgeven in de hadoop-omgevingsconfiguratie.
Bereid een tijdelijke map voor in HDFS. Deze tijdelijke map wordt gebruikt voor het opslaan van een DistCp-shellscript, zodat deze ruimte op KB-niveau in beslag neemt.
Zorg ervoor dat het gebruikersaccount dat is opgegeven in de gekoppelde HDFS-service, gemachtigd is voor:
- Dien een toepassing in YARN in.
- Maak een submap en lees-/schrijfbestanden onder de tijdelijke map.
Configuraties
Voor distCp-gerelateerde configuraties en voorbeelden gaat u als bronsectie naar HDFS.
Kerberos-verificatie gebruiken voor de HDFS-connector
Er zijn twee opties voor het instellen van de on-premises omgeving voor het gebruik van Kerberos-verificatie voor de HDFS-connector. U kunt kiezen welke beter past bij uw situatie.
- Optie 1: Deelnemen aan een zelf-hostende Integration Runtime-machine in de Kerberos-realm
- Optie 2: wederzijdse vertrouwensrelatie tussen het Windows-domein en de Kerberos-realm inschakelen
Voor beide opties moet u webhdfs inschakelen voor Hadoop-cluster:
Maak de HTTP-principal en keytab voor webhdfs.
Belangrijk
De HTTP Kerberos-principal moet beginnen met 'HTTP/' volgens de Kerberos HTTP SPNEGO-specificatie. Hier vindt u meer informatie.
Kadmin> addprinc -randkey HTTP/<namenode hostname>@<REALM.COM> Kadmin> ktadd -k /etc/security/keytab/spnego.service.keytab HTTP/<namenode hostname>@<REALM.COM>HDFS-configuratieopties: voeg de volgende drie eigenschappen toe in
hdfs-site.xml.<property> <name>dfs.webhdfs.enabled</name> <value>true</value> </property> <property> <name>dfs.web.authentication.kerberos.principal</name> <value>HTTP/_HOST@<REALM.COM></value> </property> <property> <name>dfs.web.authentication.kerberos.keytab</name> <value>/etc/security/keytab/spnego.service.keytab</value> </property>
Optie 1: Deelnemen aan een zelf-hostende Integration Runtime-machine in de Kerberos-realm
Vereisten
- De zelf-hostende Integration Runtime-machine moet lid worden van de Kerberos-realm en kan geen windows-domein toevoegen.
Configureren
Op de KDC-server:
Maak een principal en geef het wachtwoord op.
Belangrijk
De gebruikersnaam mag de hostnaam niet bevatten.
Kadmin> addprinc <username>@<REALM.COM>
Op de zelf-hostende Integration Runtime-machine:
Voer het hulpprogramma Ksetup uit om de KDC-server en -realm (Kerberos Key Distribution Center) te configureren.
De computer moet worden geconfigureerd als lid van een werkgroep, omdat een Kerberos-realm verschilt van een Windows-domein. U kunt deze configuratie bereiken door de Kerberos-realm in te stellen en een KDC-server toe te voegen door de volgende opdrachten uit te voeren. Vervang REALM.COM door uw eigen realmnaam.
C:> Ksetup /setdomain REALM.COM C:> Ksetup /addkdc REALM.COM <your_kdc_server_address>Nadat u deze opdrachten hebt uitgevoerd, start u de computer opnieuw op.
Controleer de configuratie met de
Ksetupopdracht. De uitvoer moet er als volgt uitzien:C:> Ksetup default realm = REALM.COM (external) REALM.com: kdc = <your_kdc_server_address>
In uw data factory of Synapse-werkruimte:
- Configureer de HDFS-connector met behulp van Windows-verificatie samen met uw Kerberos-principalnaam en -wachtwoord om verbinding te maken met de HDFS-gegevensbron. Raadpleeg de sectie Met HDFS gekoppelde service-eigenschappen voor configuratiedetails.
Optie 2: wederzijdse vertrouwensrelatie tussen het Windows-domein en de Kerberos-realm inschakelen
Vereisten
- De zelf-hostende Integration Runtime-machine moet lid worden van een Windows-domein.
- U hebt toestemming nodig om de instellingen van de domeincontroller bij te werken.
Configureren
Notitie
Vervang REALM.COM en AD.COM in de volgende zelfstudie door uw eigen realmnaam en domeincontroller.
Op de KDC-server:
Bewerk de KDC-configuratie in het krb5.conf-bestand om KDC het Windows-domein te laten vertrouwen door te verwijzen naar de volgende configuratiesjabloon. Standaard bevindt de configuratie zich op /etc/krb5.conf.
[logging] default = FILE:/var/log/krb5libs.log kdc = FILE:/var/log/krb5kdc.log admin_server = FILE:/var/log/kadmind.log [libdefaults] default_realm = REALM.COM dns_lookup_realm = false dns_lookup_kdc = false ticket_lifetime = 24h renew_lifetime = 7d forwardable = true [realms] REALM.COM = { kdc = node.REALM.COM admin_server = node.REALM.COM } AD.COM = { kdc = windc.ad.com admin_server = windc.ad.com } [domain_realm] .REALM.COM = REALM.COM REALM.COM = REALM.COM .ad.com = AD.COM ad.com = AD.COM [capaths] AD.COM = { REALM.COM = . }Nadat u het bestand hebt geconfigureerd, start u de KDC-service opnieuw op.
Bereid een principal met de naam krbtgt/REALM.COM@AD.COM in de KDC-server voor met de volgende opdracht:
Kadmin> addprinc krbtgt/REALM.COM@AD.COMVoeg in het configuratiebestand van de HADOOP.SECURITY.AUTH_TO_LOCAL HDFS-service toe
RULE:[1:$1@$0](.*\@AD.COM)s/\@.*//.
Op de domeincontroller:
Voer de volgende
Ksetupopdrachten uit om een realm-vermelding toe te voegen:C:> Ksetup /addkdc REALM.COM <your_kdc_server_address> C:> ksetup /addhosttorealmmap HDFS-service-FQDN REALM.COMStel een vertrouwensrelatie tot stand van het Windows-domein in de Kerberos-realm. [wachtwoord] is het wachtwoord voor de principal krbtgt/REALM.COM@AD.COM.
C:> netdom trust REALM.COM /Domain: AD.COM /add /realm /password:[password]Selecteer het versleutelingsalgoritme dat wordt gebruikt in Kerberos.
a. Selecteer Serverbeheer> Groepsbeleidsbeheer>groepsbeleidsobjecten>>standaard of actief domeinbeleid en selecteer vervolgens Bewerken.
b. Selecteer in het deelvenster Editor voor groepsbeleidsbeheer computerconfiguratiebeleid>>Windows-instellingen>Beveiligingsinstellingen>Lokale beleidsbeveiligingsopties> en configureer vervolgens netwerkbeveiliging: Versleutelingstypen configureren die zijn toegestaan voor Kerberos.
c. Selecteer het versleutelingsalgoritmen dat u wilt gebruiken wanneer u verbinding maakt met de KDC-server. U kunt alle opties selecteren.
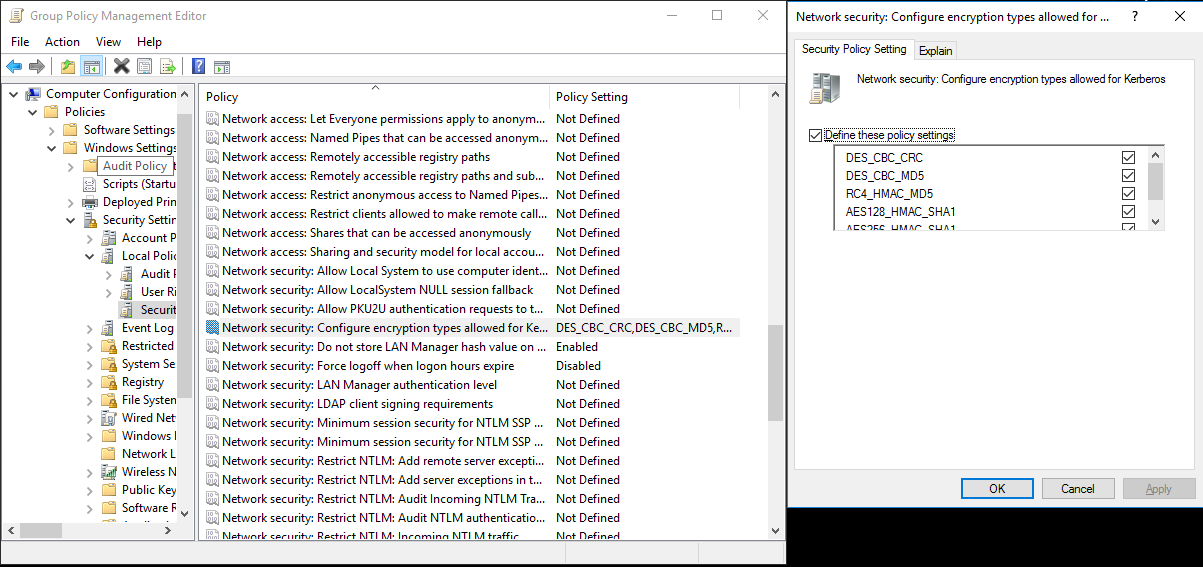
d. Gebruik de
Ksetupopdracht om het versleutelingsalgoritmen op te geven dat moet worden gebruikt voor de opgegeven realm.C:> ksetup /SetEncTypeAttr REALM.COM DES-CBC-CRC DES-CBC-MD5 RC4-HMAC-MD5 AES128-CTS-HMAC-SHA1-96 AES256-CTS-HMAC-SHA1-96Maak de toewijzing tussen het domeinaccount en de Kerberos-principal, zodat u de Kerberos-principal in het Windows-domein kunt gebruiken.
a. Selecteer Systeembeheer> Active Directory.
b. Configureer geavanceerde functies door Geavanceerde functies weergeven>te selecteren.
c. Klik in het deelvenster Geavanceerde functies met de rechtermuisknop op het account waarnaar u toewijzingen wilt maken en selecteer in het deelvenster Naamtoewijzingen het tabblad Kerberos-namen .
d. Voeg een principal toe uit het realm.
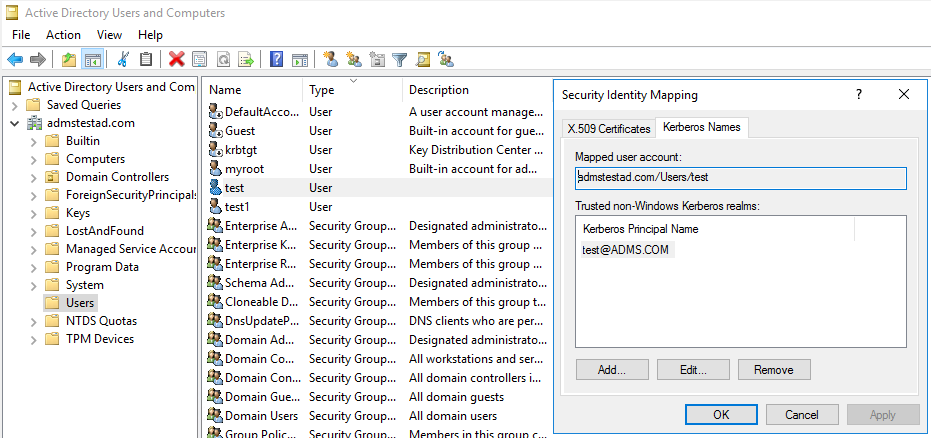
Op de zelf-hostende Integration Runtime-machine:
Voer de volgende
Ksetupopdrachten uit om een realm-vermelding toe te voegen.C:> Ksetup /addkdc REALM.COM <your_kdc_server_address> C:> ksetup /addhosttorealmmap HDFS-service-FQDN REALM.COM
In uw data factory of Synapse-werkruimte:
- Configureer de HDFS-connector met behulp van Windows-verificatie samen met uw domeinaccount of Kerberos-principal om verbinding te maken met de HDFS-gegevensbron. Zie de sectie Met HDFS gekoppelde service-eigenschappen voor configuratiedetails.
Eigenschappen van opzoekactiviteit
Zie Lookup-activiteit voor informatie over eigenschappen van lookup-activiteiten.
Activiteitseigenschappen verwijderen
Zie Activiteit verwijderen voor meer informatie over eigenschappen van Delete-activiteit.
Verouderde modellen
Notitie
De volgende modellen worden nog steeds ondersteund, net als voor achterwaartse compatibiliteit. U wordt aangeraden het eerder besproken nieuwe model te gebruiken, omdat de ontwerpgebruikersinterface is overgeschakeld naar het genereren van het nieuwe model.
Verouderd gegevenssetmodel
| Eigenschappen | Beschrijving | Vereist |
|---|---|---|
| type | De typeeigenschap van de gegevensset moet worden ingesteld op FileShare | Ja |
| folderPath | Het pad naar de map. Een jokertekenfilter wordt ondersteund. Toegestane jokertekens zijn * (komt overeen met nul of meer tekens) en ? (komt overeen met nul of één teken); gebruik ^ deze optie om te ontsnappen als uw werkelijke bestandsnaam een jokerteken of dit escape-teken bevat. Voorbeelden: rootfolder/submap/, zie meer voorbeelden in voorbeelden van map- en bestandsfilters. |
Ja |
| fileName | De naam of het jokertekenfilter voor de bestanden onder het opgegeven mapPath. Als u geen waarde voor deze eigenschap opgeeft, verwijst de gegevensset naar alle bestanden in de map. Voor filter zijn * toegestane jokertekens (komt overeen met nul of meer tekens) en ? (komt overeen met nul of één teken).- Voorbeeld 1: "fileName": "*.csv"- Voorbeeld 2: "fileName": "???20180427.txt"Gebruik ^ deze optie om te ontsnappen als de naam van uw map een jokerteken of dit escape-teken bevat. |
Nee |
| modifiedDatetimeStart | Bestanden worden gefilterd op basis van het kenmerk Laatst gewijzigd. De bestanden worden geselecteerd als de laatste wijzigingstijd groter is dan of gelijk is aan modifiedDatetimeStart en kleiner is dan modifiedDatetimeEnd. De tijd wordt toegepast op de UTC-tijdzone in de notatie 2018-12-01T05:00:00Z. Houd er rekening mee dat de algehele prestaties van gegevensverplaatsing worden beïnvloed door deze instelling in te schakelen wanneer u een bestandsfilter wilt toepassen op grote aantallen bestanden. De eigenschappen kunnen NULL zijn, wat betekent dat er geen bestandskenmerkfilter wordt toegepast op de gegevensset. Wanneer modifiedDatetimeStart een datum/tijd-waarde is maar modifiedDatetimeEnd NULL is, betekent dit dat de bestanden waarvan het kenmerk voor het laatst is gewijzigd groter dan of gelijk zijn aan de datum/tijd-waarde zijn geselecteerd. Wanneer modifiedDatetimeEnd een datum/tijd-waarde heeft maar modifiedDatetimeStart NULL is, betekent dit dat de bestanden waarvan het kenmerk voor het laatst is gewijzigd kleiner zijn dan de datum/tijd-waarde zijn geselecteerd. |
Nee |
| modifiedDatetimeEnd | Bestanden worden gefilterd op basis van het kenmerk Laatst gewijzigd. De bestanden worden geselecteerd als de laatste wijzigingstijd groter is dan of gelijk is aan modifiedDatetimeStart en kleiner is dan modifiedDatetimeEnd. De tijd wordt toegepast op de UTC-tijdzone in de notatie 2018-12-01T05:00:00Z. Houd er rekening mee dat de algehele prestaties van gegevensverplaatsing worden beïnvloed door deze instelling in te schakelen wanneer u een bestandsfilter wilt toepassen op grote aantallen bestanden. De eigenschappen kunnen NULL zijn, wat betekent dat er geen bestandskenmerkfilter wordt toegepast op de gegevensset. Wanneer modifiedDatetimeStart een datum/tijd-waarde is maar modifiedDatetimeEnd NULL is, betekent dit dat de bestanden waarvan het kenmerk voor het laatst is gewijzigd groter dan of gelijk zijn aan de datum/tijd-waarde zijn geselecteerd. Wanneer modifiedDatetimeEnd een datum/tijd-waarde heeft maar modifiedDatetimeStart NULL is, betekent dit dat de bestanden waarvan het kenmerk voor het laatst is gewijzigd kleiner zijn dan de datum/tijd-waarde zijn geselecteerd. |
Nee |
| indeling | Als u bestanden wilt kopiëren zoals tussen op bestanden gebaseerde archieven (binaire kopie), slaat u de indelingssectie over in de definities van de invoer- en uitvoergegevensset. Als u bestanden met een specifieke indeling wilt parseren, worden de volgende bestandstypen ondersteund: TextFormat, JsonFormat, AvroFormat, OrcFormat, ParquetFormat. Stel de typeeigenschap onder opmaak in op een van deze waarden. Zie de secties Tekstindeling, JSON-indeling, Avro-indeling, ORC-indeling en Parquet-indeling voor meer informatie. |
Nee (alleen voor binair kopieerscenario) |
| compressie | Geef het type en het compressieniveau voor de gegevens op. Zie Ondersteunde bestandsindelingen en compressiecodecs voor meer informatie. Ondersteunde typen zijn: Gzip, Deflate, Bzip2 en ZipDeflate. Ondersteunde niveaus zijn: Optimaal en Snelst. |
Nee |
Tip
Als u alle bestanden onder een map wilt kopiëren, geeft u alleen folderPath op.
Als u één bestand met een opgegeven naam wilt kopiëren, geeft u folderPath op met maponderdeel en fileName met bestandsnaam.
Als u een subset van bestanden onder een map wilt kopiëren, geeft u folderPath op met maponderdeel en fileName met jokertekenfilter.
Voorbeeld:
{
"name": "HDFSDataset",
"properties": {
"type": "FileShare",
"linkedServiceName":{
"referenceName": "<HDFS linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {
"folderPath": "folder/subfolder/",
"fileName": "*",
"modifiedDatetimeStart": "2018-12-01T05:00:00Z",
"modifiedDatetimeEnd": "2018-12-01T06:00:00Z",
"format": {
"type": "TextFormat",
"columnDelimiter": ",",
"rowDelimiter": "\n"
},
"compression": {
"type": "GZip",
"level": "Optimal"
}
}
}
}
Verouderd Copy-activiteit bronmodel
| Eigenschappen | Beschrijving | Vereist |
|---|---|---|
| type | De typeeigenschap van de Copy-activiteit bron moet worden ingesteld op HdfsSource. | Ja |
| recursief | Hiermee wordt aangegeven of de gegevens recursief worden gelezen uit de submappen of alleen uit de opgegeven map. Wanneer recursief is ingesteld op true en de sink een archief op basis van bestanden is, wordt een lege map of submap niet gekopieerd of gemaakt in de sink. Toegestane waarden zijn waar (standaard) en onwaar. |
Nee |
| distcpSettings | De eigenschapsgroep wanneer u HDFS DistCp gebruikt. | Nee |
| resourceManagerEndpoint | Het YARN Resource Manager-eindpunt | Ja, als u DistCp gebruikt |
| tempScriptPath | Een mappad dat wordt gebruikt voor het opslaan van het tijdelijke DistCp-opdrachtscript. Het scriptbestand wordt gegenereerd en wordt verwijderd nadat de kopieertaak is voltooid. | Ja, als u DistCp gebruikt |
| distcpOptions | Er zijn extra opties beschikbaar voor de opdracht DistCp. | Nee |
| maxConcurrentConnections | De bovengrens van gelijktijdige verbindingen die tijdens de uitvoering van de activiteit tot stand zijn gebracht met het gegevensarchief. Geef alleen een waarde op wanneer u gelijktijdige verbindingen wilt beperken. | Nee |
Voorbeeld: HDFS-bron in Copy-activiteit met DistCp
"source": {
"type": "HdfsSource",
"distcpSettings": {
"resourceManagerEndpoint": "resourcemanagerendpoint:8088",
"tempScriptPath": "/usr/hadoop/tempscript",
"distcpOptions": "-m 100"
}
}
Gerelateerde inhoud
Zie ondersteunde gegevensarchieven voor een lijst met gegevensarchieven die worden ondersteund als bronnen en sinks door de Copy-activiteit.