Excel-bestandsindeling in Azure Data Factory en Azure Synapse Analytics
VAN TOEPASSING OP:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Probeer Data Factory uit in Microsoft Fabric, een alles-in-één analyseoplossing voor ondernemingen. Microsoft Fabric omvat alles, van gegevensverplaatsing tot gegevenswetenschap, realtime analyses, business intelligence en rapportage. Meer informatie over het gratis starten van een nieuwe proefversie .
Volg dit artikel als u de Excel-bestanden wilt parseren. De service ondersteunt zowel '.xls' als '.xlsx'.
Excel-indeling wordt ondersteund voor de volgende connectors: Amazon S3, Amazon S3 Compatible Storage, Azure Blob, Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2, Azure Files, File System, FTP, Google Cloud Storage, HDFS, HTTP, Oracle Cloud Storage en SFTP. Het wordt ondersteund als bron, maar niet als sink.
Notitie
De indeling '.xls' wordt niet ondersteund tijdens het gebruik van HTTP.
Eigenschappen van gegevensset
Zie het artikel Gegevenssets voor een volledige lijst met secties en eigenschappen die beschikbaar zijn voor het definiëren van gegevenssets . Deze sectie bevat een lijst met eigenschappen die worden ondersteund door de Excel-gegevensset.
| Eigenschappen | Beschrijving | Vereist |
|---|---|---|
| type | De typeeigenschap van de gegevensset moet worden ingesteld op Excel. | Ja |
| locatie | Locatie-instellingen van de bestanden. Elke op bestanden gebaseerde connector heeft een eigen locatietype en ondersteunde eigenschappen onder location. |
Ja |
| bladnaam | De naam van het Excel-werkblad om gegevens te lezen. | Opgeven sheetName of sheetIndex |
| sheetIndex | De Excel-werkbladindex voor het lezen van gegevens vanaf 0. | Opgeven sheetName of sheetIndex |
| range | Het celbereik in het opgegeven werkblad om de selectieve gegevens te zoeken, bijvoorbeeld: - Niet opgegeven: leest het hele werkblad als een tabel uit de eerste niet-lege rij en kolom - A3: leest een tabel die begint vanuit de opgegeven cel, detecteert dynamisch alle rijen eronder en alle kolommen rechts- A3:H5: leest dit vaste bereik als een tabel- A3:A3: leest deze enkele cel |
Nee |
| firstRowAsHeader | Hiermee geeft u op of de eerste rij in het opgegeven werkblad/bereik moet worden behandeld als koptekstregel met namen van kolommen. Toegestane waarden zijn waar en onwaar (standaard). |
Nee |
| nullValue | Hiermee geeft u de tekenreeksweergave van null-waarde. De standaardwaarde is een lege tekenreeks. |
Nee |
| compressie | Groep eigenschappen voor het configureren van bestandscompressie. Configureer deze sectie wanneer u compressie/decompressie wilt uitvoeren tijdens de uitvoering van de activiteit. | Nee |
| type (onder compression) |
De compressiecodec die wordt gebruikt voor het lezen/schrijven van JSON-bestanden. Toegestane waarden zijn bzip2, gzip, deflate, ZipDeflate, TarGzip, Tar, snappy of lz4. De standaardwaarde wordt niet gecomprimeerd. Opmerking momenteel Copy-activiteit geen ondersteuning biedt voor 'snappy' en 'lz4', en toewijzingsgegevensstroom biedt geen ondersteuning voor 'ZipDeflate', 'TarGzip' en 'Tar'. Let op wanneer u kopieeractiviteit gebruikt om ZipDeflate-bestanden te decomprimeren en schrijven naar het op bestanden gebaseerde sinkgegevensarchief, worden bestanden uitgepakt naar de map: <path specified in dataset>/<folder named as source zip file>/. |
Nee |
| niveau (onder compression) |
De compressieverhouding. Toegestane waarden zijn Optimaal of Snelste. - Snelste: De compressiebewerking moet zo snel mogelijk worden voltooid, zelfs als het resulterende bestand niet optimaal is gecomprimeerd. - Optimaal: De compressiebewerking moet optimaal worden gecomprimeerd, zelfs als het langer duurt om de bewerking te voltooien. Zie het onderwerp Compressieniveau voor meer informatie. |
Nee |
Hieronder ziet u een voorbeeld van een Excel-gegevensset in Azure Blob Storage:
{
"name": "ExcelDataset",
"properties": {
"type": "Excel",
"linkedServiceName": {
"referenceName": "<Azure Blob Storage linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"typeProperties": {
"location": {
"type": "AzureBlobStorageLocation",
"container": "containername",
"folderPath": "folder/subfolder",
},
"sheetName": "MyWorksheet",
"range": "A3:H5",
"firstRowAsHeader": true
}
}
}
Eigenschappen van de kopieeractiviteit
Zie het artikel Pijplijnen voor een volledige lijst met secties en eigenschappen die beschikbaar zijn voor het definiëren van activiteiten. Deze sectie bevat een lijst met eigenschappen die worden ondersteund door de Excel-bron.
Excel als bron
De volgende eigenschappen worden ondersteund in de sectie kopieeractiviteit *source* .
| Eigenschappen | Beschrijving | Vereist |
|---|---|---|
| type | De typeeigenschap van de bron van de kopieeractiviteit moet worden ingesteld op ExcelSource. | Ja |
| storeSettings | Een groep eigenschappen over het lezen van gegevens uit een gegevensarchief. Elke op bestanden gebaseerde connector heeft zijn eigen ondersteunde leesinstellingen onder storeSettings. |
Nee |
"activities": [
{
"name": "CopyFromExcel",
"type": "Copy",
"typeProperties": {
"source": {
"type": "ExcelSource",
"storeSettings": {
"type": "AzureBlobStorageReadSettings",
"recursive": true
}
},
...
}
...
}
]
Eigenschappen van toewijzingsgegevensstroom
In toewijzingsgegevensstromen kunt u de Excel-indeling lezen in de volgende gegevensarchieven: Azure Blob Storage, Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2, Amazon S3 en SFTP. U kunt verwijzen naar Excel-bestanden met behulp van een Excel-gegevensset of een inlinegegevensset.
Broneigenschappen
De onderstaande tabel bevat de eigenschappen die worden ondersteund door een Excel-bron. U kunt deze eigenschappen bewerken op het tabblad Bronopties . Wanneer u een inlinegegevensset gebruikt, ziet u aanvullende bestandsinstellingen, die hetzelfde zijn als de eigenschappen die worden beschreven in de sectie eigenschappen van de gegevensset.
| Name | Beschrijving | Vereist | Toegestane waarden | Eigenschap gegevensstroomscript |
|---|---|---|---|---|
| Paden met jokertekens | Alle bestanden die overeenkomen met het jokertekenpad worden verwerkt. Hiermee overschrijft u de map en het bestandspad dat is ingesteld in de gegevensset. | nee | Tekenreeks[] | jokertekenpaden |
| Hoofdpad voor partitie | Voor bestandsgegevens die zijn gepartitioneerd, kunt u een partitiehoofdpad invoeren om gepartitioneerde mappen als kolommen te lezen | nee | String | partitionRootPath |
| Lijst met bestanden | Of uw bron verwijst naar een tekstbestand waarin bestanden worden vermeld die moeten worden verwerkt | nee | true of false |
fileList |
| Kolom voor het opslaan van de bestandsnaam | Een nieuwe kolom maken met de naam en het pad van het bronbestand | nee | String | rowUrlColumn |
| Na voltooiing | Verwijder of verplaats de bestanden na verwerking. Bestandspad begint vanuit de hoofdmap van de container | nee | Verwijderen: true of false Bewegen: ['<from>', '<to>'] |
purgeFiles moveFiles |
| Filteren op laatst gewijzigd | Kiezen om bestanden te filteren op basis van wanneer ze voor het laatst zijn gewijzigd | nee | Tijdstempel | modifiedAfter modifiedBefore |
| Geen bestanden gevonden toestaan | Indien waar, wordt er geen fout gegenereerd als er geen bestanden worden gevonden | nee | true of false |
ignoreNoFilesFound |
Bronvoorbeeld
De onderstaande afbeelding is een voorbeeld van een Excel-bronconfiguratie in toewijzingsgegevensstromen met behulp van de gegevenssetmodus.
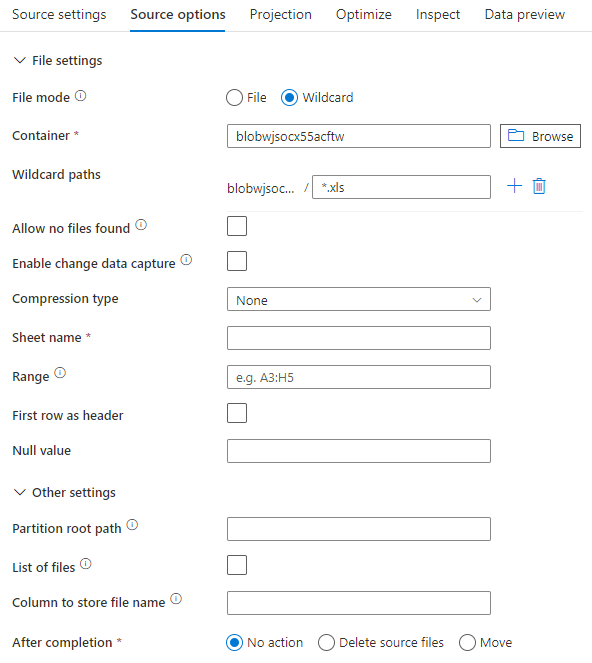
Het gekoppelde gegevensstroomscript is:
source(allowSchemaDrift: true,
validateSchema: false,
wildcardPaths:['*.xls']) ~> ExcelSource
Als u een inlinegegevensset gebruikt, ziet u de volgende bronopties in de toewijzingsgegevensstroom.
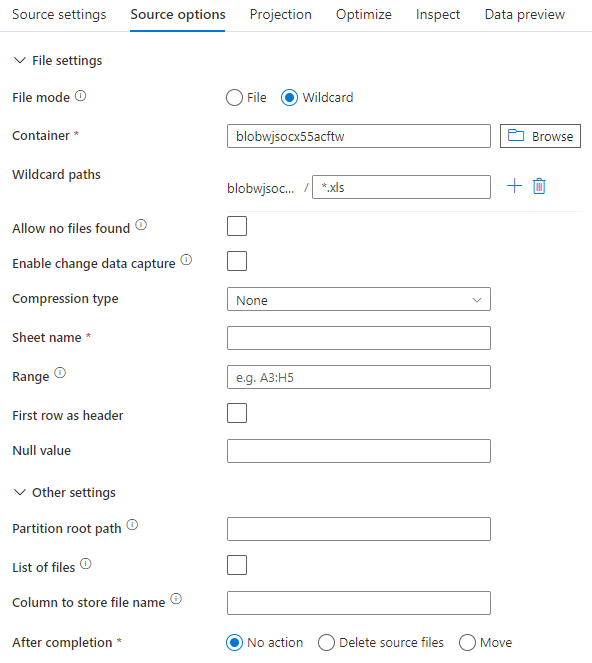
Het gekoppelde gegevensstroomscript is:
source(allowSchemaDrift: true,
validateSchema: false,
format: 'excel',
fileSystem: 'container',
folderPath: 'path',
fileName: 'sample.xls',
sheetName: 'worksheet',
firstRowAsHeader: true) ~> ExcelSourceInlineDataset
Zeer grote Excel-bestanden verwerken
De Excel-connector biedt geen ondersteuning voor het streamen van leesbewerkingen voor de Copy-activiteit en moet het hele bestand in het geheugen laden voordat gegevens kunnen worden gelezen. Als u een schema wilt importeren, een voorbeeld van gegevens wilt bekijken of een Excel-gegevensset wilt vernieuwen, moeten de gegevens worden geretourneerd vóór de time-out van de HTTP-aanvraag (100). Voor grote Excel-bestanden worden deze bewerkingen mogelijk niet binnen die periode voltooid, waardoor er een time-outfout optreedt. Als u grote Excel-bestanden (>100 MB) naar een ander gegevensarchief wilt verplaatsen, kunt u een van de volgende opties gebruiken om deze beperking te omzeilen:
- Gebruik de zelf-hostende Integration Runtime (SHIR) en gebruik vervolgens de Copy-activiteit om het grote Excel-bestand te verplaatsen naar een ander gegevensarchief met de SHIR.
- Splits het grote Excel-bestand in verschillende kleinere bestanden en gebruik vervolgens de Copy-activiteit om de map met de bestanden te verplaatsen.
- Gebruik een gegevensstroomactiviteit om het grote Excel-bestand naar een ander gegevensarchief te verplaatsen. Gegevensstroom ondersteunt streaming-leesbewerkingen voor Excel en kan grote bestanden snel verplaatsen/overdragen.
- Converteer het grote Excel-bestand handmatig naar CSV-indeling en gebruik vervolgens een Copy-activiteit om het bestand te verplaatsen.
Gerelateerde inhoud
Feedback
Binnenkort beschikbaar: In de loop van 2024 zullen we GitHub-problemen geleidelijk uitfaseren als het feedbackmechanisme voor inhoud en deze vervangen door een nieuw feedbacksysteem. Zie voor meer informatie: https://aka.ms/ContentUserFeedback.
Feedback verzenden en weergeven voor