Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
VAN TOEPASSING OP: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Probeer Data Factory uit in Microsoft Fabric, een alles-in-één analyseoplossing voor ondernemingen. Microsoft Fabric omvat alles, van gegevensverplaatsing tot gegevenswetenschap, realtime analyses, business intelligence en rapportage. Meer informatie over het gratis starten van een nieuwe proefversie .
In dit artikel wordt beschreven hoe u kopieeractiviteit gebruikt om gegevens te kopiëren uit Amazon Simple Storage Service (Amazon S3) en Gegevensstroom te gebruiken om gegevens in Amazon S3 te transformeren. Lees de inleidende artikelen voor Azure Data Factory en Synapse Analytics voor meer informatie.
Ondersteunde mogelijkheden
Deze Amazon S3-connector wordt ondersteund voor de volgende mogelijkheden:
| Ondersteunde mogelijkheden | IR |
|---|---|
| Copy-activiteit (bron/-) | (1) (2) |
| Toewijzingsgegevensstroom (bron/sink) | (1) |
| Activiteit Lookup | (1) (2) |
| GetMetadata-activiteit | (1) (2) |
| Activiteit verwijderen | (1) (2) |
(1) Azure Integration Runtime (2) Zelf-hostende Integration Runtime
Deze Amazon S3-connector ondersteunt het kopiëren van bestanden zoals het is of het parseren van bestanden met de ondersteunde bestandsindelingen en compressiecodecs. U kunt er ook voor kiezen om metagegevens van bestanden tijdens het kopiëren te behouden. De connector maakt gebruik van AWS Signature versie 4 om aanvragen voor S3 te verifiëren.
Tip
Als u gegevens wilt kopiëren van een S3-compatibele opslagprovider, raadpleegt u Amazon S3 Compatible Storage.
Vereiste machtigingen
Als u gegevens van Amazon S3 wilt kopiëren, moet u ervoor zorgen dat u de volgende machtigingen hebt gekregen voor Amazon S3-objectbewerkingen: s3:GetObject en s3:GetObjectVersion.
Als u de Data Factory-gebruikersinterface gebruikt om te schrijven, zijn aanvullende s3:ListAllMyBuckets machtigingen s3:ListBucket/s3:GetBucketLocation vereist voor bewerkingen zoals het testen van de verbinding met de gekoppelde service en bladeren vanuit de hoofdmap. Als u deze machtigingen niet wilt verlenen, kunt u de opties Verbinding met bestandspad testen of Bladeren vanuit het opgegeven pad in de gebruikersinterface kiezen.
Zie Machtigingen opgeven in een beleid op de AWS-site voor de volledige lijst met Amazon S3-machtigingen.
Aan de slag
Als u de kopieeractiviteit wilt uitvoeren met een pijplijn, kunt u een van de volgende hulpprogramma's of SDK's gebruiken:
- Het hulpprogramma voor het kopiëren van gegevens
- Azure Portal
- De .NET-SDK
- De Python-SDK
- Azure PowerShell
- De REST API
- Een Azure Resource Manager-sjabloon
Een gekoppelde Amazon Simple Storage Service -service (S3) maken met behulp van de gebruikersinterface
Gebruik de volgende stappen om een gekoppelde Amazon S3-service te maken in de gebruikersinterface van Azure Portal.
Blader naar het tabblad Beheren in uw Azure Data Factory- of Synapse-werkruimte en selecteer Gekoppelde services en klik vervolgens op Nieuw:
Zoek naar Amazon en selecteer de Amazon S3-connector.
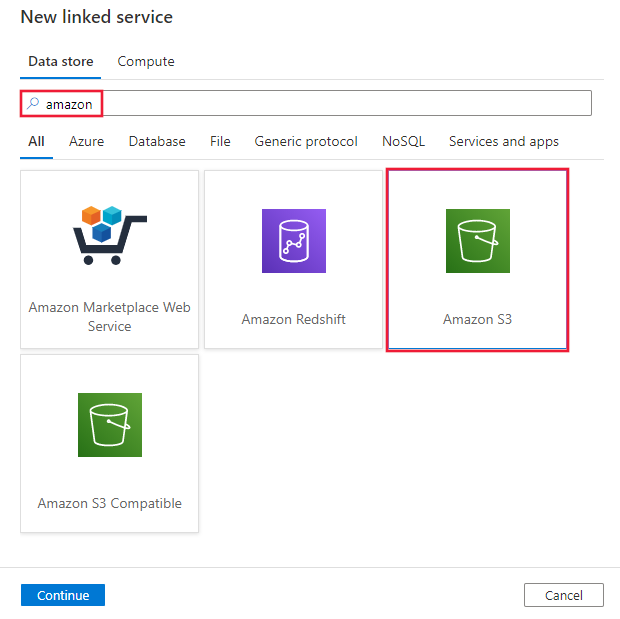
Configureer de servicedetails, test de verbinding en maak de nieuwe gekoppelde service.
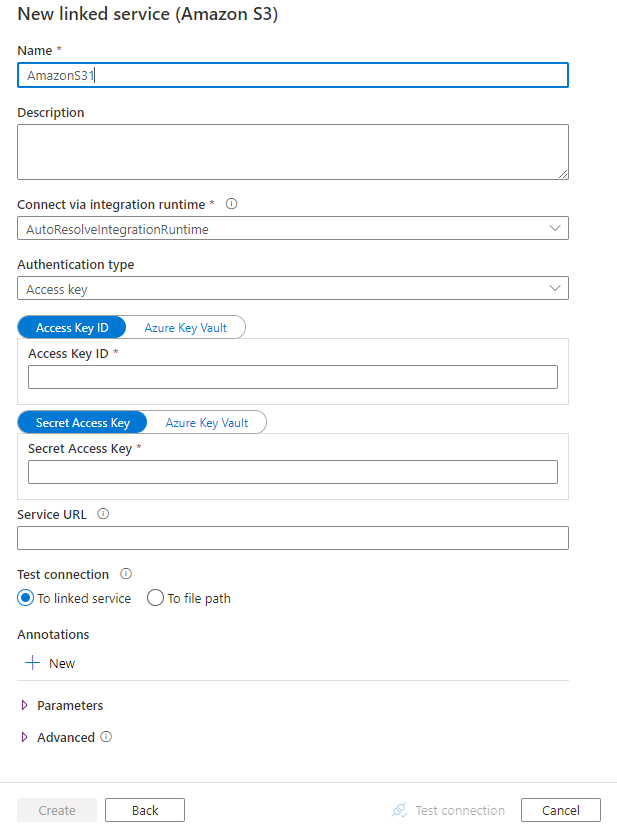
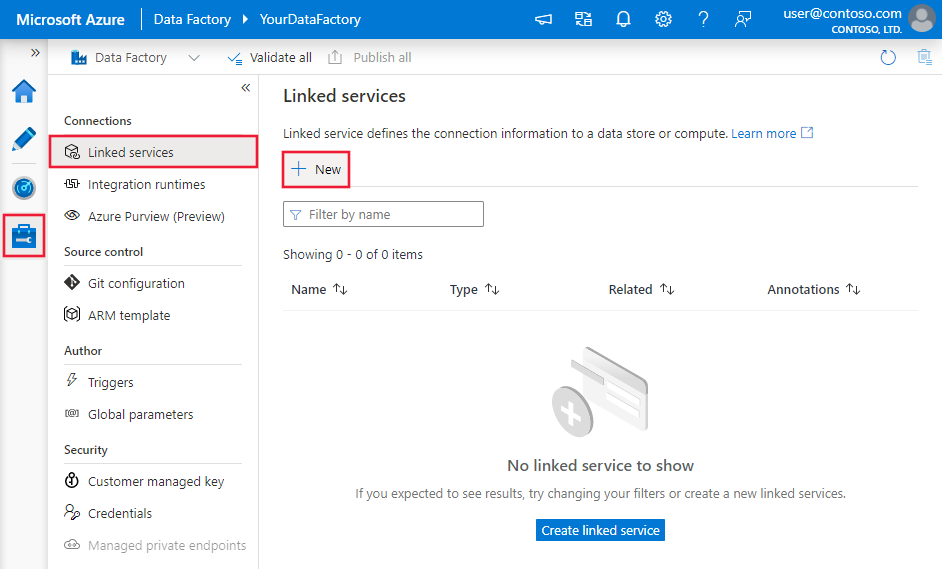
Configuratiedetails van connector
De volgende secties bevatten details over eigenschappen die worden gebruikt voor het definiëren van Data Factory-entiteiten die specifiek zijn voor Amazon S3.
Eigenschappen van gekoppelde service
De volgende eigenschappen worden ondersteund voor een gekoppelde Amazon S3-service:
| Eigenschappen | Beschrijving | Vereist |
|---|---|---|
| type | De eigenschap type moet worden ingesteld op AmazonS3. | Ja |
| authenticationType | Geef het verificatietype op dat wordt gebruikt om verbinding te maken met Amazon S3. U kunt ervoor kiezen om toegangssleutels te gebruiken voor een IAM-account (AWS Identity and Access Management) of tijdelijke beveiligingsreferenties. Toegestane waarden zijn: AccessKey (standaard) en TemporarySecurityCredentials. |
Nee |
| accessKeyId | Id van de geheime toegangssleutel. | Ja |
| secretAccessKey | De geheime toegangssleutel zelf. Markeer dit veld als SecureString om het veilig op te slaan of verwijs naar een geheim dat is opgeslagen in Azure Key Vault. | Ja |
| sessionToken | Van toepassing bij het gebruik van tijdelijke verificatie van beveiligingsreferenties . Meer informatie over het aanvragen van tijdelijke beveiligingsreferenties van AWS. Let op: tijdelijke AWS-referenties verlopen tussen 15 minuten en 36 uur op basis van instellingen. Zorg ervoor dat uw referentie geldig is wanneer de activiteit wordt uitgevoerd, met name voor een ge operationaliseerde workload. U kunt deze bijvoorbeeld periodiek vernieuwen en opslaan in Azure Key Vault. Markeer dit veld als SecureString om het veilig op te slaan of verwijs naar een geheim dat is opgeslagen in Azure Key Vault. |
Nee |
| serviceUrl | Geef het aangepaste S3-eindpunt https://<service url>op.Wijzig deze alleen als u een ander service-eindpunt wilt proberen of wilt schakelen tussen https en http. |
Nee |
| connectVia | De Integration Runtime die moet worden gebruikt om verbinding te maken met het gegevensarchief. U kunt de Azure Integration Runtime of de zelf-hostende Integration Runtime gebruiken (als uw gegevensarchief zich in een privénetwerk bevindt). Als deze eigenschap niet is opgegeven, gebruikt de service de standaard Azure Integration Runtime. | Nee |
Voorbeeld: toegangssleutelverificatie gebruiken
{
"name": "AmazonS3LinkedService",
"properties": {
"type": "AmazonS3",
"typeProperties": {
"accessKeyId": "<access key id>",
"secretAccessKey": {
"type": "SecureString",
"value": "<secret access key>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Voorbeeld: tijdelijke verificatie van beveiligingsreferenties gebruiken
{
"name": "AmazonS3LinkedService",
"properties": {
"type": "AmazonS3",
"typeProperties": {
"authenticationType": "TemporarySecurityCredentials",
"accessKeyId": "<access key id>",
"secretAccessKey": {
"type": "SecureString",
"value": "<secret access key>"
},
"sessionToken": {
"type": "SecureString",
"value": "<session token>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Eigenschappen van gegevensset
Zie het artikel Gegevenssets voor een volledige lijst met secties en eigenschappen die beschikbaar zijn voor het definiëren van gegevenssets .
Azure Data Factory ondersteunt de volgende bestandsindelingen. Raadpleeg elk artikel voor op indeling gebaseerde instellingen.
- Avro-indeling
- Binaire indeling
- Tekstindeling met scheidingstekens
- Excel-indeling
- JSON-indeling
- ORC-indeling
- Parquet-indeling
- XML-indeling
De volgende eigenschappen worden ondersteund voor Amazon S3 onder location instellingen in een op indeling gebaseerde gegevensset:
| Eigenschappen | Beschrijving | Vereist |
|---|---|---|
| type | De typeeigenschap onder location in een gegevensset moet worden ingesteld op AmazonS3Location. |
Ja |
| bucketName | De naam van de S3-bucket. | Ja |
| folderPath | Het pad naar de map onder de opgegeven bucket. Als u een jokerteken wilt gebruiken om de map te filteren, slaat u deze instelling over en geeft u dat op in de instellingen van de activiteitsbron. | Nee |
| fileName | De bestandsnaam onder het opgegeven bucket- en mappad. Als u een jokerteken wilt gebruiken om bestanden te filteren, slaat u deze instelling over en geeft u dat op in de instellingen van de activiteitsbron. | Nee |
| version | De versie van het S3-object, als S3-versiebeheer is ingeschakeld. Als deze niet is opgegeven, wordt de nieuwste versie opgehaald. | Nee |
Voorbeeld:
{
"name": "DelimitedTextDataset",
"properties": {
"type": "DelimitedText",
"linkedServiceName": {
"referenceName": "<Amazon S3 linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, auto retrieved during authoring > ],
"typeProperties": {
"location": {
"type": "AmazonS3Location",
"bucketName": "bucketname",
"folderPath": "folder/subfolder"
},
"columnDelimiter": ",",
"quoteChar": "\"",
"firstRowAsHeader": true,
"compressionCodec": "gzip"
}
}
}
Eigenschappen van de kopieeractiviteit
Zie het artikel Pijplijnen voor een volledige lijst met secties en eigenschappen die beschikbaar zijn voor het definiëren van activiteiten. Deze sectie bevat een lijst met eigenschappen die door de Amazon S3-bron worden ondersteund.
Amazon S3 als brontype
Azure Data Factory ondersteunt de volgende bestandsindelingen. Raadpleeg elk artikel voor op indeling gebaseerde instellingen.
- Avro-indeling
- Binaire indeling
- Tekstindeling met scheidingstekens
- Excel-indeling
- JSON-indeling
- ORC-indeling
- Parquet-indeling
- XML-indeling
De volgende eigenschappen worden ondersteund voor Amazon S3 onder storeSettings instellingen in een op indeling gebaseerde kopieerbron:
| Eigenschappen | Beschrijving | Vereist |
|---|---|---|
| type | De eigenschap type onder storeSettings moet worden ingesteld op AmazonS3ReadSettings. |
Ja |
| Zoek de bestanden die u wilt kopiëren: | ||
| OPTIE 1: statisch pad |
Kopieer vanuit de opgegeven bucket of map/bestandspad dat is opgegeven in de gegevensset. Als u alle bestanden uit een bucket of map wilt kopiëren, moet u ook opgeven wildcardFileName als *. |
|
| OPTIE 2: S3-voorvoegsel -voorvoegsel |
Voorvoegsel voor de S3-sleutelnaam onder de opgegeven bucket die is geconfigureerd in een gegevensset om bron-S3-bestanden te filteren. S3-sleutels waarvan de namen beginnen met bucket_in_dataset/this_prefix geselecteerd. Het maakt gebruik van het servicefilter van S3, wat betere prestaties biedt dan een jokertekenfilter.Wanneer u voorvoegsel gebruikt en ervoor kiest om te kopiëren naar een op bestanden gebaseerde sink met behoud van de hiërarchie, blijft het subpad na het laatste '/' in voorvoegsel behouden. U hebt bijvoorbeeld bron bucket/folder/subfolder/file.txten configureer het voorvoegsel als folder/sub, dan is subfolder/file.txthet behouden bestandspad . |
Nee |
| OPTIE 3: jokerteken - jokertekenFolderPath |
Het mappad met jokertekens onder de opgegeven bucket die is geconfigureerd in een gegevensset om bronmappen te filteren. Toegestane jokertekens zijn: * (komt overeen met nul of meer tekens) en ? (komt overeen met nul of één teken). Gebruik ^ deze optie om te escapen als uw mapnaam een jokerteken of dit escape-teken bevat. Bekijk meer voorbeelden in voorbeelden van mappen en bestandsfilters. |
Nee |
| OPTIE 3: jokerteken - wildcardFileName |
De bestandsnaam met jokertekens onder het opgegeven bucket- en mappad (of pad naar een jokerteken) om bronbestanden te filteren. Toegestane jokertekens zijn: * (komt overeen met nul of meer tekens) en ? (komt overeen met nul of één teken). Gebruik ^ deze optie om te escapen als uw bestandsnaam een jokerteken of dit escape-teken bevat. Bekijk meer voorbeelden in voorbeelden van mappen en bestandsfilters. |
Ja |
| OPTIE 4: een lijst met bestanden - fileListPath |
Geeft aan om een bepaalde bestandsset te kopiëren. Wijs een tekstbestand aan met een lijst met bestanden die u wilt kopiëren, één bestand per regel. Dit is het relatieve pad naar het pad dat is geconfigureerd in de gegevensset. Wanneer u deze optie gebruikt, geeft u geen bestandsnaam op in de gegevensset. Bekijk meer voorbeelden in voorbeelden van de lijst met bestanden. |
Nee |
| Aanvullende instellingen: | ||
| recursief | Hiermee wordt aangegeven of de gegevens recursief worden gelezen uit de submappen of alleen uit de opgegeven map. Houd er rekening mee dat wanneer recursief is ingesteld op true en de sink een archief op basis van bestanden is, een lege map of submap niet wordt gekopieerd of gemaakt in de sink. Toegestane waarden zijn waar (standaard) en onwaar. Deze eigenschap is niet van toepassing wanneer u configureert fileListPath. |
Nee |
| deleteFilesAfterCompletion | Geeft aan of de binaire bestanden worden verwijderd uit het bronarchief nadat ze naar het doelarchief zijn verplaatst. Het verwijderen van bestanden is per bestand, dus wanneer de kopieeractiviteit mislukt, ziet u dat sommige bestanden al naar het doel zijn gekopieerd en uit de bron zijn verwijderd, terwijl anderen nog steeds in het bronarchief blijven. Deze eigenschap is alleen geldig in het scenario voor het kopiëren van binaire bestanden. De standaardwaarde: false. |
Nee |
| modifiedDatetimeStart | Bestanden worden gefilterd op basis van het kenmerk: laatst gewijzigd. De bestanden worden geselecteerd als de laatste wijzigingstijd groter is dan of gelijk is aan modifiedDatetimeStart en kleiner is dan modifiedDatetimeEnd. De tijd wordt toegepast op een UTC-tijdzone in de notatie 2018-12-01T05:00:00Z. De eigenschappen kunnen NULL zijn, wat betekent dat er geen bestandskenmerkfilter wordt toegepast op de gegevensset. Wanneer modifiedDatetimeStart een datum/tijd-waarde heeft maar modifiedDatetimeEnd NULL is, worden de bestanden waarvan het kenmerk voor het laatst gewijzigd is groter dan of gelijk aan de datum/tijd-waarde geselecteerd. Wanneer modifiedDatetimeEnd een datum/tijd-waarde heeft maar modifiedDatetimeStart NULL is, worden de bestanden waarvan het kenmerk voor het laatst gewijzigd is kleiner dan de datum/tijd-waarde geselecteerd.Deze eigenschap is niet van toepassing wanneer u configureert fileListPath. |
Nee |
| modifiedDatetimeEnd | Hetzelfde als hierboven. | Nee |
| enablePartitionDiscovery | Geef voor bestanden die zijn gepartitioneerd op of de partities van het bestandspad moeten worden geparseerd en als extra bronkolommen moeten worden toegevoegd. Toegestane waarden zijn onwaar (standaard) en waar. |
Nee |
| partitionRootPath | Wanneer partitiedetectie is ingeschakeld, geeft u het absolute hoofdpad op om gepartitioneerde mappen als gegevenskolommen te lezen. Als deze niet is opgegeven, is dit standaard het volgende: - Wanneer u bestandspad gebruikt in de gegevensset of lijst met bestanden op de bron, is het pad naar de partitiehoofdmap dat is geconfigureerd in de gegevensset. - Wanneer u het filter voor jokertekens gebruikt, is partitiehoofdpad het subpad vóór het eerste jokerteken. - Wanneer u voorvoegsel gebruikt, is het hoofdpad van de partitie vóór het laatste '/'. Stel dat u het pad in de gegevensset configureert als 'root/folder/year=2020/month=08/day=27': - Als u partitiehoofdpad opgeeft als root/folder/year=2020, genereert de kopieeractiviteit twee kolommen month en day met de waarde '08' en '27', naast de kolommen in de bestanden.- Als het hoofdpad van de partitie niet is opgegeven, wordt er geen extra kolom gegenereerd. |
Nee |
| maxConcurrentConnections | De bovengrens van gelijktijdige verbindingen die tijdens de uitvoering van de activiteit tot stand zijn gebracht met het gegevensarchief. Geef alleen een waarde op wanneer u gelijktijdige verbindingen wilt beperken. | Nee |
Voorbeeld:
"activities":[
{
"name": "CopyFromAmazonS3",
"type": "Copy",
"inputs": [
{
"referenceName": "<Delimited text input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "DelimitedTextSource",
"formatSettings":{
"type": "DelimitedTextReadSettings",
"skipLineCount": 10
},
"storeSettings":{
"type": "AmazonS3ReadSettings",
"recursive": true,
"wildcardFolderPath": "myfolder*A",
"wildcardFileName": "*.csv"
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
Voorbeelden van map- en bestandsfilters
In deze sectie wordt het resulterende gedrag van het mappad en de bestandsnaam met jokertekenfilters beschreven.
| emmer | sleutel | recursief | Structuur van bronmap en filterresultaat (bestanden vetgedrukt worden opgehaald) |
|---|---|---|---|
| emmer | Folder*/* |
false | emmer MapA File1.csv File2.json Submap1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
| emmer | Folder*/* |
true | emmer MapA File1.csv File2.json Submap1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
| emmer | Folder*/*.csv |
false | emmer MapA File1.csv File2.json Submap1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
| emmer | Folder*/*.csv |
true | emmer MapA File1.csv File2.json Submap1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
Voorbeelden van bestandslijsten
In deze sectie wordt het resulterende gedrag beschreven van het gebruik van een bestandslijstpad in een Copy-activiteit bron.
Stel dat u de volgende bronmapstructuur hebt en de bestanden vetgedrukt wilt kopiëren:
| Voorbeeldbronstructuur | Inhoud in FileListToCopy.txt | Configuratie |
|---|---|---|
| emmer MapA File1.csv File2.json Submap1 File3.csv File4.json File5.csv Metagegevens FileListToCopy.txt |
File1.csv Submap1/File3.csv Submap1/File5.csv |
In gegevensset: -Emmer: bucket- Mappad: FolderAIn Copy-activiteit bron: - Pad naar bestandslijst: bucket/Metadata/FileListToCopy.txt Het bestandslijstpad verwijst naar een tekstbestand in hetzelfde gegevensarchief met een lijst met bestanden die u wilt kopiëren, één bestand per regel, met het relatieve pad naar het pad dat is geconfigureerd in de gegevensset. |
Metagegevens behouden tijdens het kopiëren
Wanneer u bestanden van Amazon S3 naar Azure Data Lake Storage Gen2 of Azure Blob Storage kopieert, kunt u ervoor kiezen om de metagegevens van bestanden samen met gegevens te behouden. Meer informatie over metagegevens behouden.
Eigenschappen van toewijzingsgegevensstroom
Wanneer u gegevens transformeert in toewijzingsgegevensstromen, kunt u bestanden van Amazon S3 lezen in de volgende indelingen:
Indelingsspecifieke instellingen bevinden zich in de documentatie voor die indeling. Zie Brontransformatie in toewijzingsgegevensstroom voor meer informatie.
Brontransformatie
In brontransformatie kunt u lezen uit een container, map of afzonderlijk bestand in Amazon S3. Gebruik het tabblad Bronopties om te beheren hoe de bestanden worden gelezen.
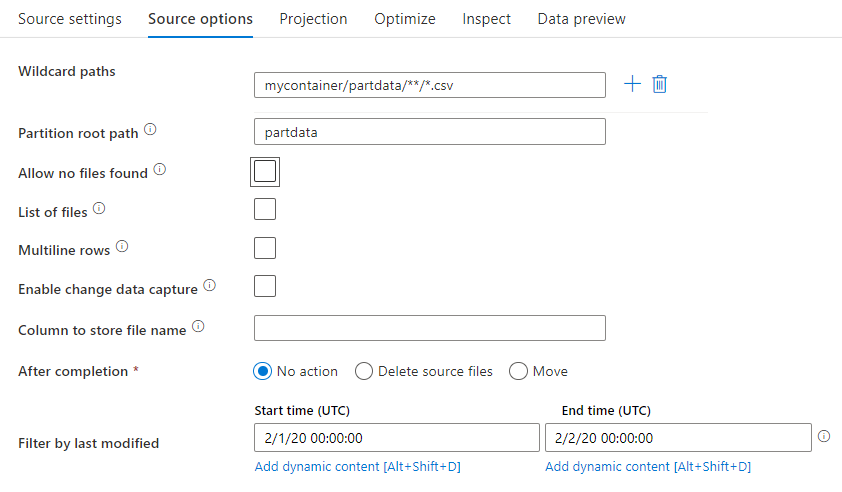
Jokertekenpaden: Met behulp van een jokertekenpatroon wordt de service geïnstrueerd om elke overeenkomende map en elk bestand in één brontransformatie te doorlopen. Dit is een effectieve manier om meerdere bestanden binnen één stroom te verwerken. Voeg meerdere jokertekenpatronen toe met het plusteken dat wordt weergegeven wanneer u de muisaanwijzer boven het bestaande jokertekenpatroon beweegt.
Kies in uw broncontainer een reeks bestanden die overeenkomen met een patroon. Alleen een container kan worden opgegeven in de gegevensset. Uw jokertekenpad moet daarom ook uw mappad uit de hoofdmap bevatten.
Voorbeelden van jokertekens:
*Vertegenwoordigt een set tekens.**Vertegenwoordigt recursieve map genest.?Hiermee vervangt u één teken.[]Komt overeen met een of meer tekens tussen de haken./data/sales/**/*.csvHiermee worden alle .csv bestanden opgehaald onder /data/sales./data/sales/20??/**/Haalt alle bestanden in de 20e eeuw op./data/sales/*/*/*.csvHiermee worden .csv bestanden twee niveaus onder /data/sales opgehaald./data/sales/2004/*/12/[XY]1?.csvHiermee worden alle .csv bestanden opgehaald in december 2004, beginnend met X of Y, voorafgegaan door een getal van twee cijfers.
Hoofdpad partitie: Als u gepartitioneerde mappen in uw bestandsbron hebt met een key=value indeling (bijvoorbeeld year=2019), kunt u het hoogste niveau van die partitiemapstructuur toewijzen aan een kolomnaam in de gegevensstroom van uw gegevensstroom.
Stel eerst een jokerteken in om alle paden op te nemen die de gepartitioneerde mappen zijn plus de leaf-bestanden die u wilt lezen.
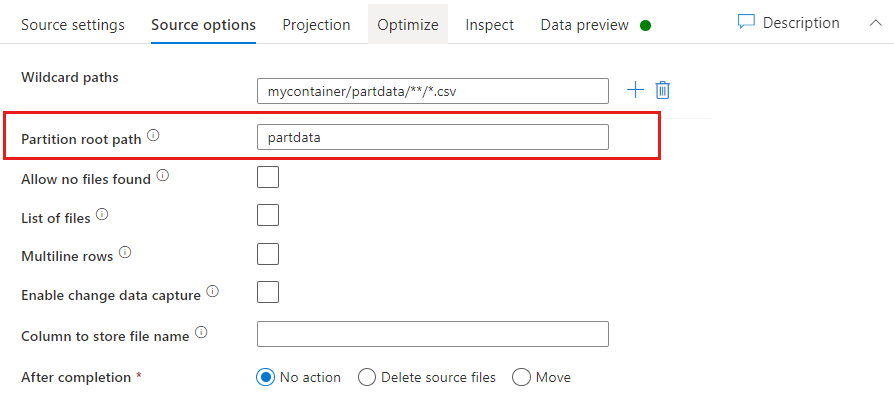
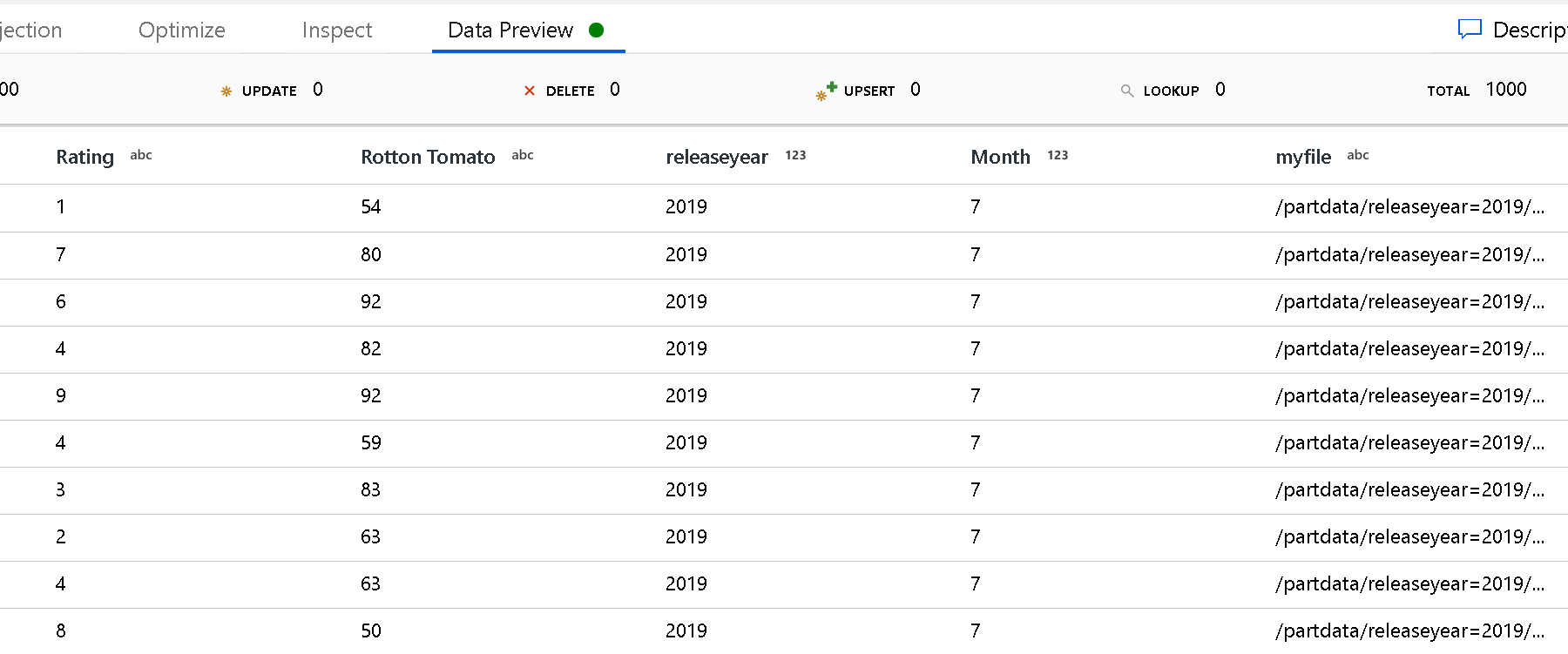
Gebruik de instelling Partitiehoofdpad om te definiëren wat het hoogste niveau van de mapstructuur is. Wanneer u de inhoud van uw gegevens bekijkt via een voorbeeld van een gegevensvoorbeeld, ziet u dat de service de opgeloste partities toevoegt die in elk van uw mapniveaus zijn gevonden.
Lijst met bestanden: dit is een bestandsset. Maak een tekstbestand met een lijst met relatieve padbestanden die moeten worden verwerkt. Wijs dit tekstbestand aan.
Kolom voor het opslaan van bestandsnaam: Sla de naam van het bronbestand op in een kolom in uw gegevens. Voer hier een nieuwe kolomnaam in om de bestandsnaamtekenreeks op te slaan.
Na voltooiing: Kies ervoor om niets te doen met het bronbestand nadat de gegevensstroom is uitgevoerd, verwijder het bronbestand of verplaats het bronbestand. De paden voor de verplaatsing zijn relatief.
Als u bronbestanden wilt verplaatsen naar een andere locatie na verwerking, selecteert u eerst Verplaatsen voor bestandsbewerking. Stel vervolgens de map 'from' in. Als u geen jokertekens voor uw pad gebruikt, is de instelling 'van' dezelfde map als uw bronmap.
Als u een bronpad met jokertekens hebt, ziet uw syntaxis er als volgt uit:
/data/sales/20??/**/*.csv
U kunt 'van' opgeven als:
/data/sales
En u kunt 'aan' opgeven als:
/backup/priorSales
In dit geval worden alle bestanden die zijn opgehaald, /data/sales verplaatst naar /backup/priorSales.
Notitie
Bestandsbewerkingen worden alleen uitgevoerd wanneer u de gegevensstroom start vanuit een pijplijnuitvoering (een pijplijnopsporing of uitvoeringsuitvoering) die gebruikmaakt van de uitvoering Gegevensstroom-activiteit uitvoeren in een pijplijn. Bestandsbewerkingen worden niet uitgevoerd in Gegevensstroom foutopsporingsmodus.
Filteren op laatst gewijzigd: u kunt filteren welke bestanden u verwerkt door een datumbereik op te geven van wanneer ze voor het laatst zijn gewijzigd. Alle datum/tijd-datums zijn in UTC.
Eigenschappen van opzoekactiviteit
Als u meer wilt weten over de eigenschappen, controleert u de lookup-activiteit.
Eigenschappen van GetMetadata-activiteit
Raadpleeg de activiteit GetMetadata voor meer informatie over de eigenschappen.
Activiteitseigenschappen verwijderen
Als u meer wilt weten over de eigenschappen, schakelt u De activiteit Verwijderen in.
Verouderde modellen
Notitie
De volgende modellen worden nog steeds ondersteund, net als voor achterwaartse compatibiliteit. U wordt aangeraden het eerder genoemde nieuwe model te gebruiken. De ontwerpgebruikersinterface is overgeschakeld naar het genereren van het nieuwe model.
Verouderd gegevenssetmodel
| Eigenschappen | Beschrijving | Vereist |
|---|---|---|
| type | De typeeigenschap van de gegevensset moet worden ingesteld op AmazonS3Object. | Ja |
| bucketName | De naam van de S3-bucket. Het jokertekenfilter wordt niet ondersteund. | Ja voor de activiteit Kopiëren of Opzoeken, nee voor de GetMetadata-activiteit |
| sleutel | De naam of het jokertekenfilter van de S3-objectsleutel onder de opgegeven bucket. Is alleen van toepassing wanneer de eigenschap voorvoegsel niet is opgegeven. Het jokertekenfilter wordt ondersteund voor zowel het maponderdeel als het bestandsnaamonderdeel. Toegestane jokertekens zijn: * (komt overeen met nul of meer tekens) en ? (komt overeen met nul of één teken).- Voorbeeld 1: "key": "rootfolder/subfolder/*.csv"- Voorbeeld 2: "key": "rootfolder/subfolder/???20180427.txt"Bekijk meer voorbeelden in voorbeelden van mappen en bestandsfilters. Gebruik ^ deze optie om te escapen als uw werkelijke map of bestandsnaam een jokerteken of dit escape-teken bevat. |
Nee |
| voorvoegsel | Voorvoegsel voor de S3-objectsleutel. Objecten waarvan de sleutels met dit voorvoegsel beginnen, worden geselecteerd. Is alleen van toepassing wanneer de sleuteleigenschap niet is opgegeven. | Nee |
| version | De versie van het S3-object, als S3-versiebeheer is ingeschakeld. Als er geen versie is opgegeven, wordt de nieuwste versie opgehaald. | Nee |
| modifiedDatetimeStart | Bestanden worden gefilterd op basis van het kenmerk: laatst gewijzigd. De bestanden worden geselecteerd als de laatste wijzigingstijd groter is dan of gelijk is aan modifiedDatetimeStart en kleiner is dan modifiedDatetimeEnd. De tijd wordt toegepast op de UTC-tijdzone in de notatie '2018-12-01T05:00:00Z'. Houd er rekening mee dat het inschakelen van deze instelling van invloed is op de algehele prestaties van gegevensverplaatsing wanneer u grote hoeveelheden bestanden wilt filteren. De eigenschappen kunnen NULL zijn, wat betekent dat er geen bestandskenmerkfilter wordt toegepast op de gegevensset. Wanneer modifiedDatetimeStart een datum/tijd-waarde heeft maar modifiedDatetimeEnd NULL is, worden de bestanden waarvan het kenmerk voor het laatst gewijzigd is groter dan of gelijk aan de datum/tijd-waarde geselecteerd. Wanneer modifiedDatetimeEnd een datum/tijd-waarde heeft maar modifiedDatetimeStart NULL is, worden de bestanden waarvan het kenmerk voor het laatst gewijzigd is kleiner dan de datum/tijd-waarde geselecteerd. |
Nee |
| modifiedDatetimeEnd | Bestanden worden gefilterd op basis van het kenmerk: laatst gewijzigd. De bestanden worden geselecteerd als de laatste wijzigingstijd groter is dan of gelijk is aan modifiedDatetimeStart en kleiner is dan modifiedDatetimeEnd. De tijd wordt toegepast op de UTC-tijdzone in de notatie '2018-12-01T05:00:00Z'. Houd er rekening mee dat het inschakelen van deze instelling van invloed is op de algehele prestaties van gegevensverplaatsing wanneer u grote hoeveelheden bestanden wilt filteren. De eigenschappen kunnen NULL zijn, wat betekent dat er geen bestandskenmerkfilter wordt toegepast op de gegevensset. Wanneer modifiedDatetimeStart een datum/tijd-waarde heeft maar modifiedDatetimeEnd NULL is, worden de bestanden waarvan het kenmerk voor het laatst gewijzigd is groter dan of gelijk aan de datum/tijd-waarde geselecteerd. Wanneer modifiedDatetimeEnd een datum/tijd-waarde heeft maar modifiedDatetimeStart NULL is, worden de bestanden waarvan het kenmerk voor het laatst gewijzigd is kleiner dan de datum/tijd-waarde geselecteerd. |
Nee |
| indeling | Als u bestanden wilt kopiëren zoals tussen bestandsarchieven (binaire kopie), slaat u de indelingssectie over in definities van invoer- en uitvoergegevenssets. Als u bestanden met een specifieke indeling wilt parseren of genereren, worden de volgende bestandstypen ondersteund: TextFormat, JsonFormat, AvroFormat, OrcFormat, ParquetFormat. Stel de typeeigenschap onder opmaak in op een van deze waarden. Zie de secties Tekstindeling, JSON-indeling, Avro-indeling, Orc-indeling en Parquet-indeling voor meer informatie. |
Nee (alleen voor binair kopieerscenario) |
| compressie | Geef het type en het compressieniveau voor de gegevens op. Zie Ondersteunde bestandsindelingen en compressiecodecs voor meer informatie. Ondersteunde typen zijn GZip, Deflate, BZip2 en ZipDeflate. Ondersteunde niveaus zijn Optimaal en Snelste. |
Nee |
Tip
Als u alle bestanden onder een map wilt kopiëren, geeft u bucketName op voor de bucket en het voorvoegsel voor het maponderdeel.
Als u één bestand met een bepaalde naam wilt kopiëren, geeft u bucketName op voor de bucket en sleutel voor het maponderdeel plus bestandsnaam.
Als u een subset van bestanden onder een map wilt kopiëren, geeft u bucketName op voor de bucket en sleutel voor het maponderdeel plus jokertekenfilter.
Voorbeeld: voorvoegsel gebruiken
{
"name": "AmazonS3Dataset",
"properties": {
"type": "AmazonS3Object",
"linkedServiceName": {
"referenceName": "<Amazon S3 linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {
"bucketName": "testbucket",
"prefix": "testFolder/test",
"modifiedDatetimeStart": "2018-12-01T05:00:00Z",
"modifiedDatetimeEnd": "2018-12-01T06:00:00Z",
"format": {
"type": "TextFormat",
"columnDelimiter": ",",
"rowDelimiter": "\n"
},
"compression": {
"type": "GZip",
"level": "Optimal"
}
}
}
}
Voorbeeld: sleutel en versie gebruiken (optioneel)
{
"name": "AmazonS3Dataset",
"properties": {
"type": "AmazonS3",
"linkedServiceName": {
"referenceName": "<Amazon S3 linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {
"bucketName": "testbucket",
"key": "testFolder/testfile.csv.gz",
"version": "XXXXXXXXXczm0CJajYkHf0_k6LhBmkcL",
"format": {
"type": "TextFormat",
"columnDelimiter": ",",
"rowDelimiter": "\n"
},
"compression": {
"type": "GZip",
"level": "Optimal"
}
}
}
}
Verouderd bronmodel voor de Copy-activiteit
| Eigenschappen | Beschrijving | Vereist |
|---|---|---|
| type | De typeeigenschap van de Copy-activiteit bron moet worden ingesteld op FileSystemSource. | Ja |
| recursief | Hiermee wordt aangegeven of de gegevens recursief worden gelezen uit de submappen of alleen uit de opgegeven map. Houd er rekening mee dat wanneer recursief is ingesteld op true en de sink een archief op basis van bestanden is, een lege map of submap niet wordt gekopieerd of gemaakt in de sink. Toegestane waarden zijn waar (standaard) en onwaar. |
Nee |
| maxConcurrentConnections | De bovengrens van gelijktijdige verbindingen die tijdens de uitvoering van de activiteit tot stand zijn gebracht met het gegevensarchief. Geef alleen een waarde op wanneer u gelijktijdige verbindingen wilt beperken. | Nee |
Voorbeeld:
"activities":[
{
"name": "CopyFromAmazonS3",
"type": "Copy",
"inputs": [
{
"referenceName": "<Amazon S3 input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "FileSystemSource",
"recursive": true
},
"sink": {
"type": "<sink type>"
}
}
}
]
Gerelateerde inhoud
Zie Ondersteunde gegevensarchieven voor een lijst met gegevensarchieven die door de Copy-activiteit worden ondersteund als bronnen en sinks.