In dit artikel vindt u antwoorden op enkele van de meest voorkomende vragen over het uitvoeren van Azure HDInsight.
HDInsight-clusters maken of verwijderen
Hoe kan ik een HDInsight-cluster inrichten?
Zie Clusters instellen in HDInsight met Apache Hadoop, Apache Spark, Apache Kafka en meer om de typen HDInsight-clusters en de inrichtingsmethoden te bekijken.
Hoe kan ik een bestaand HDInsight-cluster verwijderen?
Zie Een HDInsight-cluster verwijderen voor meer informatie over het verwijderen van een cluster wanneer het niet meer wordt gebruikt.
Probeer minstens 30 tot 60 minuten te laten tussen het maken en verwijderen van bewerkingen. Anders kan de bewerking mislukken met het volgende foutbericht:
Conflict (HTTP Status Code: 409) error when attempting to delete a cluster immediately after creation of a cluster. If you encounter this error, wait until the newly created cluster is in operational state before attempting to delete it.
Hoe kan ik het juiste aantal kernen of knooppunten voor mijn workload selecteren?
Het juiste aantal kernen en andere configuratieopties is afhankelijk van verschillende factoren.
Zie Capaciteitsplanning voor HDInsight-clusters voor meer informatie.
Wat zijn de verschillende typen knooppunten in een HDInsight-cluster?
Wat zijn de aanbevolen procedures voor het maken van grote HDInsight-clusters?
- U kunt het beste HDInsight-clusters instellen met een aangepaste Ambari-database om de schaalbaarheid van het cluster te verbeteren.
- Gebruik Azure Data Lake Storage Gen2 om HDInsight-clusters te maken om te profiteren van een hogere bandbreedte en andere prestatiekenmerken van Azure Data Lake Storage Gen2.
- Hoofdknooppunten moeten voldoende groot zijn voor meerdere hoofdservices die op deze knooppunten worden uitgevoerd.
- Sommige specifieke workloads, zoals Interactive Query, hebben ook grotere Zookeeper-knooppunten nodig. Overweeg minimaal acht kern-VM's.
- Gebruik in het geval van Hive en Spark externe Hive-metastore.
Afzonderlijke onderdelen
Kan ik extra onderdelen op mijn cluster installeren?
Ja. Als u aanvullende onderdelen wilt installeren of clusterconfiguratie wilt aanpassen, gebruikt u:
Scripts tijdens of na het maken. Scripts worden aangeroepen via scriptactie. Scriptactie is een configuratieoptie die u kunt gebruiken vanuit Azure Portal, HDInsight Windows PowerShell-cmdlets of de HDInsight .NET SDK. Deze configuratieoptie kan worden gebruikt vanuit de Azure-portal, HDInsight Windows PowerShell-cmdlets of de HDInsight .NET SDK.
HDInsight Application Platform om toepassingen te installeren.
Zie Wat zijn de Apache Hadoop-onderdelen en -versies die beschikbaar zijn met HDInsight voor een lijst met ondersteunde onderdelen ?
Kan ik de afzonderlijke onderdelen upgraden die vooraf op het cluster zijn geïnstalleerd?
Als u ingebouwde onderdelen of toepassingen upgradet die vooraf op uw cluster zijn geïnstalleerd, wordt de resulterende configuratie niet ondersteund door Microsoft. Deze systeemconfiguraties zijn niet getest door Microsoft. Probeer een andere versie van het HDInsight-cluster te gebruiken waarop mogelijk al de bijgewerkte versie van het onderdeel vooraf is geïnstalleerd.
Het upgraden van Hive als een afzonderlijk onderdeel wordt bijvoorbeeld niet ondersteund. HDInsight is een beheerde service en veel services zijn geïntegreerd met de Ambari-server en getest. Als u een Hive op zichzelf bijwerken, worden de geïndexeerde binaire bestanden van andere onderdelen gewijzigd en worden er problemen met de integratie van onderdelen in uw cluster veroorzaakt.
Kan Spark en Kafka worden uitgevoerd op hetzelfde HDInsight-cluster?
Nee, het is niet mogelijk om Apache Kafka en Apache Spark uit te voeren op hetzelfde HDInsight-cluster. Maak afzonderlijke clusters voor Kafka en Spark om problemen met resourceconflicten te voorkomen.
Hoe kan ik tijdzone wijzigen in Ambari?
Open de Ambari-webgebruikersinterface op
https://CLUSTERNAME.azurehdinsight.net, waarbij CLUSTERNAME de naam van uw cluster is.Selecteer in de rechterbovenhoek de optie Beheerder | Instellingen.
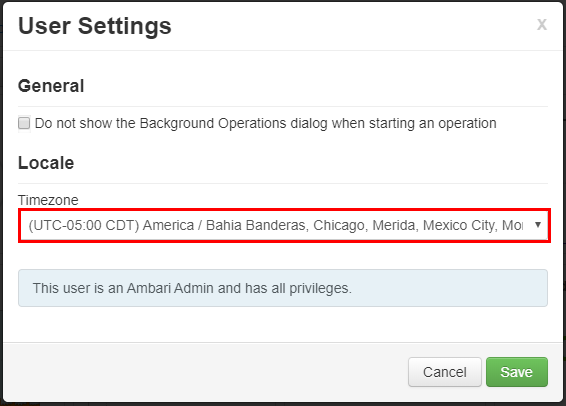
Selecteer in het venster User Instellingen de nieuwe tijdzone in de vervolgkeuzelijst Tijdzone en klik vervolgens op Opslaan.
Metastore
Hoe kan ik migreren van de bestaande metastore naar Azure SQL Database?
Als u wilt migreren van SQL Server naar Azure SQL Database, raadpleegt u zelfstudie: SQL Server offline migreren naar één database of pooldatabase in Azure SQL Database met behulp van DMS.
Wordt de Hive-metastore verwijderd wanneer het cluster wordt verwijderd?
Dit is afhankelijk van het type metastore dat uw cluster is geconfigureerd voor gebruik.
Voor een standaard-metastore: De standaard-metastore maakt deel uit van de levenscyclus van het cluster. Wanneer u een cluster verwijdert, worden ook de bijbehorende metastore en metagegevens verwijderd.
Voor een aangepaste metastore: de levenscyclus van de metastore is niet gekoppeld aan de levenscyclus van een cluster. U kunt dus clusters maken en verwijderen zonder metagegevens te verliezen. Metagegevens zoals uw Hive-schema's blijven behouden, zelfs nadat u het HDInsight-cluster hebt verwijderd en opnieuw hebt gemaakt.
Zie Externe metagegevensarchieven gebruiken in Azure HDInsight voor meer informatie.
Migreert het migreren van een Hive-metastore ook het standaardbeleid van de Ranger-database?
Nee, de beleidsdefinitie bevindt zich in de Ranger-database, dus als u de Ranger-database migreert, wordt het beleid gemigreerd.
Kunt u een Hive-metastore migreren van een ESP-cluster (Enterprise Security Package) naar een niet-ESP-cluster en andersom?
Ja, u kunt een Hive-metastore migreren van een ESP naar een niet-ESP-cluster.
Hoe kan ik de grootte van een Hive-metastore-database schatten?
Een Hive-metastore wordt gebruikt voor het opslaan van de metagegevens voor gegevensbronnen die worden gebruikt door de Hive-server. De groottevereisten zijn deels afhankelijk van het aantal en de complexiteit van uw Hive-gegevensbronnen. Deze items kunnen niet vooraf worden geschat. Zoals wordt beschreven in de Hive-metastore-richtlijnen, kunt u beginnen met een S2-laag. De laag biedt 50 DTU en 250 GB opslagruimte en als u een knelpunt ziet, schaalt u de database omhoog.
Ondersteunt u andere databases dan Azure SQL Database als een externe metastore?
Nee, Microsoft ondersteunt alleen Azure SQL Database als een externe aangepaste metastore.
Kan ik een metastore delen tussen meerdere clusters?
Ja, u kunt aangepaste metastore delen in meerdere clusters zolang ze dezelfde versie van HDInsight gebruiken.
Verbinding maken iviteit en virtuele netwerken
Wat zijn de gevolgen van het blokkeren van poorten 22 en 23 op mijn netwerk?
Als u poort 22 en poort 23 blokkeert, hebt u geen SSH-toegang tot het cluster. Deze poorten worden niet gebruikt door de HDInsight-service.
Zie de volgende documenten voor meer informatie:
Kan ik een extra virtuele machine in hetzelfde subnet implementeren als een HDInsight-cluster?
Ja, u kunt een extra virtuele machine binnen hetzelfde subnet implementeren als een HDInsight-cluster. De volgende configuraties zijn mogelijk:
Edge-knooppunten: u kunt nog een edge-knooppunt toevoegen aan het cluster, zoals beschreven in Lege edge-knooppunten gebruiken in Apache Hadoop-clusters in HDInsight.
Zelfstandige knooppunten: u kunt een zelfstandige virtuele machine toevoegen aan hetzelfde subnet en toegang krijgen tot het cluster vanaf die virtuele machine met behulp van het privé-eindpunt
https://<CLUSTERNAME>-int.azurehdinsight.net. Zie Netwerkverkeer beheren voor meer informatie.
Moet ik gegevens opslaan op de lokale schijf van een Edge-knooppunt?
Nee, het opslaan van gegevens op een lokale schijf is geen goed idee. Als het knooppunt mislukt, gaan alle gegevens die lokaal zijn opgeslagen verloren. We raden u aan gegevens op te slaan in Azure Data Lake Storage Gen2 of Azure Blob Storage, of door een Azure Files-share te koppelen voor het opslaan van de gegevens.
Kan ik een bestaand HDInsight-cluster toevoegen aan een ander virtueel netwerk?
Nee dat kan niet. Het virtuele netwerk moet worden opgegeven op het moment van inrichten. Als er tijdens het inrichten geen virtueel netwerk is opgegeven, maakt de implementatie een intern netwerk dat niet toegankelijk is van buiten. Zie HDInsight toevoegen aan een bestaand virtueel netwerk voor meer informatie.
Beveiliging en certificaten
Wat zijn de aanbevelingen voor malwarebeveiliging op Azure HDInsight-clusters?
Zie Microsoft Antimalware voor Azure Cloud Services en Virtual Machines voor informatie over malwarebeveiliging.
Hoe kan ik een keytab maken voor een HDInsight ESP-cluster?
Maak een Kerberos-sleuteltab voor de gebruikersnaam van uw domein. U kunt deze keytab later gebruiken om te verifiëren bij externe clusters die lid zijn van een domein zonder een wachtwoord in te voeren. De domeinnaam is hoofdletters:
ktutil
ktutil: addent -password -p <username>@<DOMAIN.COM> -k 1 -e aes256-cts-hmac-sha1-96
Password for <username>@<DOMAIN.COM>: <password>
ktutil: wkt <username>.keytab
ktutil: q
Wanneer is zout vereist voor AES256-versleuteling bij het maken van de keytab?
Als uw TenantName & DomainName anders is (bijvoorbeeld TenantName – bob@CONTOSO.ONMICROSOFT.COM & DomainName – bob@CONTOSOMicrosoft.ONMICROSOFT.COM), moet u een SALT-waarde toevoegen met behulp van de optie -s.
Hoe kan ik de juiste SALT-waarde bepalen?
- Gebruik een interactieve Kerberos-aanmelding om de juiste zoutwaarde voor de keytab te bepalen. Interactieve Kerberos-aanmelding gebruikt standaard de hoogste versleuteling. Tracering moet zijn ingeschakeld om het zout te observeren. Hieronder ziet u een voorbeeld van kerberos-aanmelding:
$ KRB5_TRAACE=/dev/stdout kinit <username> -V
- Bekijk de uitvoer voor het zout "......." Lijn.
- Gebruik deze zoutwaarde bij het maken van de keytab.
ktutil
ktutil: addent -password -p <username>@<DOMAIN.COM> -k 1 -e aes256-cts-hmac-sha1-96 -s <SALTvalue>
Password for <username>@<DOMAIN.COM>: <password>
ktutil: wkt <username>.keytab
ktutil: q
Kan ik een bestaande Microsoft Entra-tenant gebruiken om een HDInsight-cluster met de ESP te maken?
Schakel Microsoft Entra Domain Services in voordat u een HDInsight-cluster met ESP kunt maken. Opensource Hadoop is afhankelijk van Kerberos voor verificatie (in plaats van OAuth).
Als u VM's wilt koppelen aan een domein, moet u een domeincontroller hebben. Microsoft Entra Domain Services is de beheerde domeincontroller en wordt beschouwd als een uitbreiding van Microsoft Entra-id. Microsoft Entra Domain Services biedt alle Kerberos-vereisten voor het bouwen van een beveiligd Hadoop-cluster op een beheerde manier. HDInsight als een beheerde service kan worden geïntegreerd met Microsoft Entra Domain Services om beveiliging te bieden.
Kan ik een zelfondertekend certificaat gebruiken in een Secure LDAP-installatie van Microsoft Entra Domain Services en een ESP-cluster inrichten?
Het gebruik van een certificaat dat is uitgegeven door een certificeringsinstantie wordt aanbevolen. Maar het gebruik van een zelfondertekend certificaat wordt ook ondersteund op ESP. Zie voor meer informatie:
Kan ik Data Analytics Studio (DAS) installeren als een ESP-cluster?
Nee, DAS wordt niet ondersteund op ESP-clusters.
Hoe kan ik aanmeldingsactiviteiten ophalen die worden weergegeven in Ranger?
Voor controlevereisten raadt Microsoft aan Om Azure Monitor-logboeken in te schakelen, zoals beschreven in Azure Monitor-logboeken gebruiken om HDInsight-clusters te bewaken.
Kan ik Clamscan uitschakelen op mijn cluster?
Clamscan is de antivirussoftware die wordt uitgevoerd op het HDInsight-cluster en wordt gebruikt door Azure Security (azsecd) om uw clusters te beschermen tegen virusaanvallen. Microsoft raadt gebruikers ten zeerste aan geen wijzigingen aan te brengen in de standaardconfiguratie Clamscan .
Dit proces verstoort of neemt geen cycli weg van andere processen. Het zal altijd tot een ander proces leiden. CPU-pieken uit Clamscan moeten alleen worden gezien wanneer het systeem inactief is.
In scenario's waarin u het schema moet beheren, kunt u de volgende stappen uitvoeren:
Schakel automatische uitvoering uit met behulp van de volgende opdracht:
sudo sudo
usr/local/bin/azsecd config -s clamav -d Disabledservice azsecd restartVoeg een Cron-taak toe waarmee de volgende opdracht als hoofdmap wordt uitgevoerd:
/usr/local/bin/azsecd manual -s clamav
Waarom is LLAP beschikbaar op Spark ESP-clusters?
LLAP is ingeschakeld om beveiligingsredenen (Apache Ranger), geen prestaties. Gebruik grotere knooppunt-VM's voor het resourcegebruik van LLAP (bijvoorbeeld minimaal D13V2).
Hoe kan ik extra Microsoft Entra-groepen toevoegen nadat ik een ESP-cluster heb gemaakt?
Er zijn twee manieren om dit doel te bereiken: 1: u kunt het cluster opnieuw maken en de extra groep toevoegen op het moment dat het cluster wordt gemaakt. Als u bereiksynchronisatie gebruikt in Microsoft Entra Domain Services, controleert u of groep B is opgenomen in de bereiksynchronisatie.
2- Voeg de groep toe als een geneste subgroep van de vorige groep die is gebruikt om het ESP-cluster te maken. Als u bijvoorbeeld een ESP-cluster met groep Ahebt gemaakt, kunt u later groep B toevoegen als een geneste subgroep van A en na ongeveer één uur wordt deze automatisch gesynchroniseerd en beschikbaar in het cluster.
Storage
Kan ik een Azure Data Lake Storage Gen2 toevoegen aan een bestaand HDInsight-cluster als extra opslagaccount?
Nee, het is momenteel niet mogelijk om een Azure Data Lake Storage Gen2-opslagaccount toe te voegen aan een cluster met blobopslag als primaire opslag. Zie Opslagopties vergelijken voor meer informatie.
Hoe vind ik de momenteel gekoppelde service-principal voor een Data Lake-opslagaccount?
U vindt uw instellingen in Data Lake Storage Gen1-toegang onder de clustereigenschappen in Azure Portal. Zie Clusterconfiguratie controleren voor meer informatie.
Hoe kan ik het gebruik van opslagaccounts en blobcontainers voor mijn HDInsight-clusters berekenen?
Ga op een van de volgende manieren te werk:
Zoek de grootte van de /user/hive/. Prullenbak/ map in het HDInsight-cluster met behulp van de volgende opdrachtregel:
hdfs dfs -du -h /user/hive/.Trash/
Hoe kan ik controle instellen voor mijn Blob Storage-account?
Als u blob-opslagaccounts wilt controleren, configureert u bewaking met behulp van de procedure bij Bewaken van een opslagaccount in Azure Portal. Een HDFS-auditlogboek biedt alleen controle-informatie voor het lokale HDFS-bestandssysteem (hdfs://mycluster). Het bevat geen bewerkingen die worden uitgevoerd op externe opslag.
Hoe kan ik bestanden overdragen tussen een blobcontainer en een HDInsight-hoofdknooppunt?
Voer een script uit dat vergelijkbaar is met het volgende shell-script op uw hoofdknooppunt:
for i in cat filenames.txt
do
hadoop fs -get $i <local destination>
done
Notitie
Het bestand filenames.txt heeft het absolute pad van de bestanden in de blobcontainers.
Zijn er Ranger-invoegtoepassingen voor opslag?
Er bestaat momenteel geen Ranger-invoegtoepassing voor blobopslag en Azure Data Lake Storage Gen1 of Gen2. Voor ESP-clusters moet u Azure Data Lake Storage gebruiken. U kunt ten minste gedetailleerde machtigingen handmatig instellen op bestandssysteemniveau met behulp van HDFS-hulpprogramma's. Wanneer u Azure Data Lake Storage gebruikt, voeren ESP-clusters ook een deel van het toegangsbeheer van het bestandssysteem uit met behulp van Microsoft Entra ID op clusterniveau.
U kunt beleid voor gegevenstoegang toewijzen aan de beveiligingsgroepen van uw gebruikers met behulp van Azure Storage Explorer. Zie voor meer informatie:
Kan ik HDFS-opslag op een cluster vergroten zonder de schijfgrootte van werkknooppunten te vergroten?
Nee U kunt de schijfgrootte van een werkknooppunt niet vergroten. De enige manier om de schijfgrootte te vergroten, is door het cluster te verwijderen en opnieuw te maken met grotere werkrol-VM's. Gebruik HDFS niet voor het opslaan van uw HDInsight-gegevens, omdat de gegevens worden verwijderd als u het cluster verwijdert. Sla in plaats daarvan uw gegevens op in Azure. Als u het cluster omhoog schaalt, kunt u ook extra capaciteit toevoegen aan uw HDInsight-cluster.
Edge-knooppunten
Kan ik een Edge-knooppunt toevoegen nadat het cluster is gemaakt?
Raadpleeg Lege Edge-knooppunten op Apache Hadoop-clusters gebruiken in HDInsight voor meer informatie.
Hoe kan ik verbinding maken met een Edge-knooppunt?
Nadat u een Edge-knooppunt hebt gemaakt, kunt u er verbinding mee maken met behulp van SSH op poort 22. U vindt de naam van het edge-knooppunt in de clusterportal. De namen eindigen meestal op -ed.
Waarom worden persistente scripts niet automatisch uitgevoerd op nieuw gemaakte Edge-knooppunten?
U gebruikt persistente scripts om nieuwe werkknooppunten die aan het cluster zijn toegevoegd, aan te passen via schaalbewerkingen. Persistente scripts zijn niet van toepassing op edge-knooppunten.
REST-API
Wat zijn de REST API-aanroepen om een Tez-queryweergave op te halen uit het cluster?
U kunt de volgende REST-eindpunten gebruiken om de benodigde informatie op te halen in JSON-indeling. Gebruik basisverificatieheaders om de aanvragen te maken.
Tez Query View: https://< clusternaam.azurehdinsight.net/ws/v1/timeline/HIVE_QUERY_ID/>Tez Dag View: https://< clusternaam.azurehdinsight.net/ws/v1/timeline/TEZ_DAG_ID/>
Hoe kan ik de configuratiegegevens ophalen uit het HDI-cluster met behulp van een Microsoft Entra-gebruiker?
Als u wilt onderhandelen over de juiste verificatietokens met uw Microsoft Entra-gebruiker, gaat u via de gateway met behulp van de volgende indeling:
<cluster dnsname>https://.azurehdinsight.net/api/v1/clusters/testclusterdem/stack_versions/1/repository_versions/1
Hoe kan ik Ambari RESTful gebruiken om DE YARN-prestaties te bewaken?
Als u de Curl-opdracht aanroept in hetzelfde virtuele netwerk of een gekoppeld virtueel netwerk, is de opdracht:
curl -u <cluster login username> -sS -G
http://<headnodehost>:8080/api/v1/clusters/<ClusterName>/services/YARN/components/NODEMANAGER?fields=metrics/cpu
Als u de opdracht aanroept van buiten het virtuele netwerk of vanuit een niet-gekoppeld virtueel netwerk, is de opdrachtindeling:
Voor een niet-ESP-cluster:
curl -u <cluster login username> -sS -G https://<ClusterName>.azurehdinsight.net/api/v1/clusters/<ClusterName>/services/YARN/components/NODEMANAGER?fields=metrics/cpuVoor een ESP-cluster:
curl -u <cluster login username>-sS -G https://<ClusterName>.azurehdinsight.net/api/v1/clusters/<ClusterName>/services/YARN/components/NODEMANAGER?fields=metrics/cpu
Notitie
Curl vraagt u om een wachtwoord. U moet een geldig wachtwoord opgeven voor de gebruikersnaam van de clusteraanmelding.
Billing
Hoeveel kost het om een HDInsight-cluster te implementeren?
Zie de pagina prijzen van Azure HDInsight voor meer informatie over prijzen en veelgestelde vragen met betrekking tot facturering.
Wanneer wordt de facturering van HDInsight gestart en gestopt?
De facturering voor het gebruik van HDInsight-clusters begint zodra er een cluster is gemaakt en stopt als een cluster wordt verwijderd. Facturering wordt naar rato per minuut beoordeeld.
Hoe kan ik mijn abonnement opzeggen?
Wat gebeurt er na het annuleren van mijn abonnement voor betalen per gebruik?
Zie Wat gebeurt er nadat ik mijn abonnement heb opgezegd voor meer informatie over uw abonnement?
Hive
Waarom wordt de Hive-versie weergegeven als 1.2.1000 in plaats van 2.1 in de Ambari-gebruikersinterface, ook al heb ik een HDInsight 3.6-cluster?
Hoewel slechts 1.2 wordt weergegeven in de Ambari-gebruikersinterface, bevat HDInsight 3.6 zowel Hive 1.2 als Hive 2.1.
Andere veelgestelde vragen
Wat biedt HDInsight voor realtime mogelijkheden voor streamverwerking?
Zie Een technologie voor stroomverwerking kiezen in Azure voor meer informatie over integratiemogelijkheden voor stroomverwerking.
Is er een manier om het hoofdknooppunt van het cluster dynamisch te beëindigen wanneer het cluster gedurende een bepaalde periode inactief is?
U kunt deze actie niet uitvoeren met HDInsight-clusters. U kunt Azure Data Factory gebruiken voor deze scenario's.
Welke nalevingsaanbiedingen biedt HDInsight?
Zie het Vertrouwenscentrum van Microsoft voor informatie over naleving.