Wilt u meer weten over Service Fabric?
Azure Service Fabric is een gedistribueerde systemen platform waarmee u gemakkelijk pakket, implementeren en beheren van schaalbare en betrouwbare microservices. Service Fabric heeft echter een groot oppervlak en er is veel te leren. Dit artikel bevat een overzicht van Service Fabric en beschrijft de kernconcepten, programmeermodellen, de levenscyclus van toepassingen, testen, clusters en statuscontrole. Lees het overzicht en wat zijn microservices? voor een inleiding en hoe Service Fabric kan worden gebruikt om microservices te maken. Dit artikel bevat geen uitgebreide inhoudslijst, maar bevat wel een koppeling naar overzichts- en aan de slag-artikelen voor elk gebied van Service Fabric.
Basisconcepten
Service Fabric-terminologie, toepassingsmodel en ondersteunde programmeermodellen bieden meer concepten en beschrijvingen, maar hier volgen de basisbeginselen.
- Service Fabric-cluster: bekijk deze koppeling voor een trainingsvideo om een inleiding te krijgen tot de Service Fabric-architectuur en de belangrijkste concepten en om veel service fabric-functies te verkennen.
- Runtimeconcepten: Bekijk deze koppeling voor een trainingsvideo om inzicht te hebben in runtimeconcepten en aanbevolen procedures van Service Fabric.
- Concepten voor ontwerptypen: bekijk deze koppeling voor een trainingsvideo om inzicht te krijgen in toepassing, verpakking en implementatie; belangrijke Service Fabric-terminologie, abstracties en concepten.
Ontwerptijd: servicetype, servicepakket en manifest, toepassingstype, toepassingspakket en manifest
Een servicetype is de naam/versie die is toegewezen aan de codepakketten, gegevenspakketten en configuratiepakketten van een service. Dit wordt gedefinieerd in een ServiceManifest.xml-bestand. Het servicetype bestaat uit uitvoerbare code- en serviceconfiguratie-instellingen, die tijdens runtime worden geladen en statische gegevens die door de service worden gebruikt.
Een servicepakket is een schijfmap met het ServiceManifest.xml-bestand van het servicetype, dat verwijst naar de code, statische gegevens en configuratiepakketten voor het servicetype. Een servicepakket kan bijvoorbeeld verwijzen naar de code, statische gegevens en configuratiepakketten waaruit een databaseservice bestaat.
Een toepassingstype is de naam/versie die is toegewezen aan een verzameling servicetypen. Dit wordt gedefinieerd in een ApplicationManifest.xml-bestand.
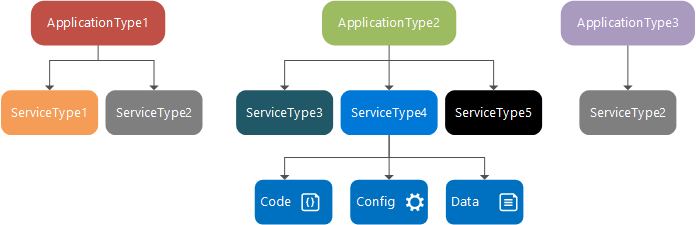
Het toepassingspakket is een schijfmap die het ApplicationManifest.xml-bestand van het toepassingstype bevat, dat verwijst naar de servicepakketten voor elk servicetype waaruit het toepassingstype bestaat. Een toepassingspakket voor een type e-mailtoepassing kan bijvoorbeeld verwijzingen bevatten naar een wachtrijservicepakket, een front-endservicepakket en een databaseservicepakket.
De bestanden in de map met toepassingspakketten worden gekopieerd naar het installatiekopieënarchief van het Service Fabric-cluster. Vervolgens kunt u een benoemde toepassing maken op basis van dit toepassingstype, dat vervolgens binnen het cluster wordt uitgevoerd. Nadat u een benoemde toepassing hebt gemaakt, kunt u een benoemde service maken op basis van een van de servicetypen van het toepassingstype.
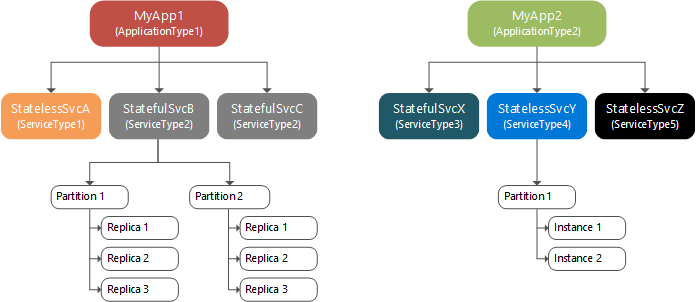
Runtime: clusters en knooppunten, benoemde toepassingen, benoemde services, partities en replica's
Een Service Fabric-cluster is een met het netwerk verbonden reeks virtuele of fysieke machines waarop uw microservices worden geïmplementeerd en beheerd. Clusters kunnen naar duizenden machines worden geschaald.
Een machine of VM die onderdeel uitmaakt van een cluster, heet een knooppunt. Aan elk knooppunt wordt een knooppuntnaam toegewezen (een tekenreeks). Knooppunten hebben kenmerken zoals plaatsingseigenschappen. Elke machine of VM heeft een Windows-service voor automatisch starten, FabricHost.exedie wordt uitgevoerd bij het opstarten en vervolgens twee uitvoerbare bestanden start: Fabric.exe en FabricGateway.exe. Deze twee uitvoerbare bestanden vormen het knooppunt. Voor ontwikkelings- of testscenario's kunt u meerdere knooppunten hosten op één machine of VM door meerdere exemplaren van Fabric.exe en FabricGateway.exe.
Een benoemde toepassing is een verzameling benoemde services die een bepaalde functie of functies uitvoeren. Een service voert een volledige en zelfstandige functie uit (deze kan onafhankelijk van andere services worden gestart en uitgevoerd) en bestaat uit code, configuratie en gegevens. Nadat een toepassingspakket is gekopieerd naar het installatiekopiearchief, maakt u een exemplaar van de toepassing in het cluster door het toepassingstype van het toepassingspakket op te geven (met de naam/versie). Aan elk exemplaar van het toepassingstype wordt een URI-naam toegewezen die eruitziet als fabric:/MyNamedApp. Binnen een cluster kunt u meerdere benoemde toepassingen maken op basis van één toepassingstype. U kunt ook benoemde toepassingen maken op basis van verschillende toepassingstypen. Elke benoemde toepassing wordt onafhankelijk beheerd en geversied.
Nadat u een benoemde toepassing hebt gemaakt, kunt u een exemplaar van een van de servicetypen (een benoemde service) binnen het cluster maken door het servicetype op te geven (met de naam/versie). Aan elk servicetype-exemplaar wordt een URI-naam toegewezen binnen het bereik van de URI van de bijbehorende toepassing. Als u bijvoorbeeld een 'MyDatabase'-benoemde service maakt in een 'MyNamedApp'-toepassing met de naam, ziet de URI er als volgt uit: fabric:/MyNamedApp/MyDatabase. Binnen een benoemde toepassing kunt u een of meer benoemde services maken. Elke benoemde service kan een eigen partitieschema en het aantal exemplaren/replica's hebben.
Er zijn twee soorten services: staatloos en stateful. Stateless services slaan de status niet op binnen de service. Stateless services hebben helemaal geen permanente opslag of slaan permanente status op in een externe opslagservice, zoals Azure Storage, Azure SQL Database of Azure Cosmos DB. Een stateful service slaat de status op binnen de service en maakt gebruik van Reliable Collections of Reliable Actors-programmeermodellen om de status te beheren.
Wanneer u een benoemde service maakt, geeft u een partitieschema op. Services met grote hoeveelheden status splitsen de gegevens over partities. Elke partitie is verantwoordelijk voor een deel van de volledige status van de service, die wordt verdeeld over de knooppunten van het cluster.
In het volgende diagram ziet u de relatie tussen toepassingen en service-exemplaren, partities en replica's.
Partitioneren, schalen en beschikbaarheid
Partitionering is niet uniek voor Service Fabric. Een bekende vorm van partitionering is gegevenspartitionering of sharding. Stateful services met grote hoeveelheden status splitsen de gegevens over partities. Elke partitie is verantwoordelijk voor een deel van de volledige status van de service.
De replica's van elke partitie worden verdeeld over de knooppunten van het cluster, waardoor de status van de benoemde service kan worden geschaald. Naarmate de gegevens moeten toenemen, worden partities groter en worden partities in Service Fabric opnieuw verdeeld over knooppunten om efficiënt gebruik te maken van hardwareresources. Als u nieuwe knooppunten aan het cluster toevoegt, worden de partitiereplica's in Service Fabric opnieuw verdeeld over het toegenomen aantal knooppunten. De algehele prestaties van toepassingen verbeteren en conflicten voor toegang tot geheugen nemen af. Als de knooppunten in het cluster niet efficiënt worden gebruikt, kunt u het aantal knooppunten in het cluster verlagen. Service Fabric herverdeling van de partitiereplica's over het verminderde aantal knooppunten om beter gebruik te maken van de hardware op elk knooppunt.
Binnen een partitie hebben stateless benoemde services exemplaren terwijl stateful benoemde services replica's hebben. Normaal gesproken hebben stateless benoemde services slechts één partitie omdat ze geen interne status hebben, hoewel er uitzonderingen zijn. De partitie-exemplaren bieden beschikbaarheid. Als het ene exemplaar mislukt, blijven andere exemplaren normaal werken en wordt er door Service Fabric een nieuw exemplaar gemaakt. Stateful benoemde services behouden hun status binnen replica's en elke partitie heeft een eigen replicaset. Lees- en schrijfbewerkingen worden uitgevoerd op één replica (de primaire replica genoemd). Wijzigingen in status van schrijfbewerkingen worden gerepliceerd naar meerdere andere replica's (actieve secundaire replica's genoemd). Als een replica mislukt, bouwt Service Fabric een nieuwe replica van de bestaande replica's.
Staatloze en stateful microservices voor Service Fabric
Met Service Fabric kunt u toepassingen bouwen die uit microservices of containers bestaan. Staatloze microservices (zoals protocolgateways en webproxy's) handhaven buiten een aanvraag en de reactie erop van de service geen veranderlijke status. Azure Cloud Services-werkrollen zijn een voorbeeld van een staatloze service. Stateful microservices (zoals gebruikersaccounts, databases, apparaten, winkelwagentjes en wachtrijen) handhaven een veranderlijke, gezaghebbende status, buiten de aanvraag en de reactie erop. De huidige toepassingen op internetschaal bestaan uit een combinatie van staatloze en stateful microservices.
Een belangrijke differentiatie met Service Fabric is de sterke focus op het bouwen van stateful services, hetzij met de ingebouwde programmeermodellen of met stateful services in containers. De toepassingsscenario's beschrijven de scenario's waarin stateful services worden gebruikt.
Waarom hebben stateful microservices samen met staatloze microservices? De twee belangrijkste redenen zijn:
- U kunt oltp-services (high-throughput, low-latency, failure-tolerant online transaction processing) bouwen door code en gegevens dicht op dezelfde computer te houden. Enkele voorbeelden zijn interactieve winkels, zoek-, Internet of Things-systemen (IoT), handelssystemen, creditcardverwerking en fraudedetectiesystemen en persoonlijk recordbeheer.
- U kunt het toepassingsontwerp vereenvoudigen. Stateful microservices verwijderen de noodzaak voor extra wachtrijen en caches, die traditioneel vereist zijn om te voldoen aan de beschikbaarheids- en latentievereisten van een puur staatloze toepassing. Stateful services zijn natuurlijk hoge beschikbaarheid en lage latentie, waardoor het aantal bewegende onderdelen dat in uw toepassing als geheel moet worden beheerd, wordt verminderd.
Ondersteunde programmeermodellen
Service Fabric biedt meerdere manieren om uw services te schrijven en te beheren. Services kunnen de Service Fabric-API's gebruiken om optimaal te profiteren van de functies en toepassingsframeworks van het platform. Services kunnen ook elk gecompileerd uitvoerbaar programma zijn dat in elke taal is geschreven en wordt gehost op een Service Fabric-cluster. Zie Ondersteunde programmeermodellen voor meer informatie.
Containers
Service Fabric implementeert en activeert standaard services als processen. Service Fabric kan ook services implementeren in containers. Belangrijk is dat u services in processen en services in containers in dezelfde toepassing kunt combineren. Service Fabric ondersteunt de implementatie van Linux-containers en Windows-containers in Windows Server 2016. U kunt bestaande toepassingen, stateless services of stateful services implementeren in containers.
Reliable Services
Reliable Services is een lichtgewicht framework voor het schrijven van services die zijn geïntegreerd met het Service Fabric-platform en profiteren van de volledige set platformfuncties. Reliable Services kan staatloos zijn (vergelijkbaar met de meeste serviceplatforms, zoals webservers of werkrollen in Azure Cloud Services), waarbij de status wordt behouden in een externe oplossing, zoals Azure DB of Azure Table Storage. Reliable Services kan ook stateful zijn, waarbij de status rechtstreeks in de service zelf wordt bewaard met behulp van Reliable Collections. De status wordt maximaal beschikbaar gemaakt via replicatie en gedistribueerd via partitionering, die allemaal automatisch worden beheerd door Service Fabric.
Reliable Actors
Het Reliable Actor-framework is een toepassingsframework dat het Virtual Actor-patroon implementeert op basis van het ontwerppatroon van de actor. Het Reliable Actor-framework maakt gebruik van onafhankelijke rekeneenheden en statussen met uitvoering met één thread, actoren genoemd. Het Reliable Actor-framework biedt ingebouwde communicatie voor actoren en vooraf ingestelde statuspersistentie en uitschaalconfiguraties.
ASP.NET Core
Service Fabric kan worden geïntegreerd met ASP.NET Core als een eersteklas programmeermodel voor het bouwen van web- en API-toepassingen. ASP.NET Core kan op twee verschillende manieren worden gebruikt in Service Fabric:
- Gehost als een uitvoerbaar gastbestand. Dit wordt voornamelijk gebruikt voor het uitvoeren van bestaande ASP.NET Core-toepassingen in Service Fabric zonder codewijzigingen.
- Voer in een Reliable Service uit. Dit maakt een betere integratie met de Service Fabric-runtime mogelijk en staat stateful ASP.NET Core-services toe.
Uitvoerbare gastbestanden
Een uitvoerbaar gastbestand is een bestaand, willekeurig uitvoerbaar bestand (geschreven in een willekeurige taal) dat wordt gehost op een Service Fabric-cluster naast andere services. Uitvoerbare gastbestanden kunnen niet rechtstreeks worden geïntegreerd met Service Fabric-API's. Ze profiteren echter nog steeds van functies die het platform biedt, zoals aangepaste status- en belastingrapportage en servicedetectie door REST API's aan te roepen. Ze hebben ook volledige ondersteuning voor de levenscyclus van toepassingen.
Toepassingslevenscyclus
Net als bij andere platforms doorloopt een toepassing in Service Fabric meestal de volgende fasen: ontwerpen, ontwikkelen, testen, implementatie, upgrade, onderhoud en verwijdering. Service Fabric biedt eersteklas ondersteuning voor de volledige levenscyclus van cloudtoepassingen, van ontwikkeling tot implementatie, dagelijks beheer en onderhoud tot uiteindelijk buiten gebruik stellen. Met het servicemodel kunnen verschillende rollen onafhankelijk deelnemen aan de levenscyclus van de toepassing. De levenscyclus van de Service Fabric-toepassing biedt een overzicht van de API's en hoe deze worden gebruikt door de verschillende rollen gedurende de fasen van de levenscyclus van de Service Fabric-toepassing.
De volledige levenscyclus van de app kan worden beheerd met behulp van PowerShell-cmdlets, CLI-opdrachten, C#-API's, Java-API's en REST API's. U kunt ook pijplijnen voor continue integratie/continue implementatie instellen met behulp van hulpprogramma's zoals Azure Pipelines of Jenkins.
Testtoepassingen en -services
Om echt cloudservices te maken, is het essentieel om te controleren of uw toepassingen en services bestand zijn tegen echte fouten. De Fault Analysis Service is ontworpen voor het testen van services die zijn gebouwd op Service Fabric. Met de Fault Analysis Service kunt u zinvolle fouten veroorzaken en volledige testscenario's uitvoeren voor uw toepassingen. Deze fouten en scenario's oefenen uit en valideren de talrijke statussen en overgangen die een service gedurende de hele levensduur zal ervaren, allemaal op een gecontroleerde, veilige en consistente manier.
Acties richten zich op een service voor het testen met behulp van afzonderlijke fouten. Een serviceontwikkelaar kan deze gebruiken als bouwstenen om ingewikkelde scenario's te schrijven. Voorbeelden van gesimuleerde fouten zijn:
- Start een knooppunt opnieuw op om een willekeurig aantal situaties te simuleren waarin een machine of VM opnieuw wordt opgestart.
- Verplaats een replica van uw stateful service om taakverdeling, failover of toepassingsupgrade te simuleren.
- Roep quorumverlies aan voor een stateful service om een situatie te creëren waarin schrijfbewerkingen niet kunnen worden voortgezet omdat er onvoldoende 'back-up' of 'secundaire' replica's zijn om nieuwe gegevens te accepteren.
- Roep gegevensverlies aan op een stateful service om een situatie te creëren waarin alle in-memory status volledig wordt gewist.
Scenario's zijn complexe bewerkingen die bestaan uit een of meer acties. De Fault Analysis Service biedt twee ingebouwde volledige scenario's:
- Chaos-scenario: simuleert doorlopende, interleaved fouten (zowel sierlijk als ondankbaar) gedurende langere tijd in het cluster.
- Failoverscenario: een versie van het chaostestscenario dat is gericht op een specifieke servicepartitie terwijl andere services niet worden beïnvloed.
Clusters
Een Service Fabric-cluster is een met het netwerk verbonden reeks virtuele of fysieke machines waarop uw microservices worden geïmplementeerd en beheerd. Clusters kunnen naar duizenden machines worden geschaald. Een machine of VM die deel uitmaakt van een cluster, wordt een clusterknooppunt genoemd. Aan elk knooppunt wordt een knooppuntnaam toegewezen (een tekenreeks). Knooppunten hebben kenmerken zoals plaatsingseigenschappen. Elke machine of VM heeft een service voor automatisch starten, FabricHost.exedie wordt gestart bij het opstarten en vervolgens twee uitvoerbare bestanden start: Fabric.exe en FabricGateway.exe. Deze twee uitvoerbare bestanden vormen het knooppunt. Voor testscenario's kunt u meerdere knooppunten hosten op één machine of VM door meerdere exemplaren van Fabric.exe en FabricGateway.exeuit te voeren.
Service Fabric-clusters kunnen worden gemaakt op virtuele of fysieke machines met Windows Server of Linux. U kunt Service Fabric-toepassingen implementeren en uitvoeren in elke omgeving waarin u een set Windows Server- of Linux-computers hebt die zijn verbonden: on-premises, op Microsoft Azure of in elke cloudprovider.
Clusters op Azure
Het uitvoeren van Service Fabric-clusters in Azure biedt integratie met andere Azure-functies en -services, waardoor bewerkingen en beheer van het cluster eenvoudiger en betrouwbaarder worden. Een cluster is een Azure Resource Manager-resource, zodat u clusters als andere resources in Azure kunt modelleren. Resource Manager biedt ook eenvoudig beheer van alle resources die door het cluster als één eenheid worden gebruikt. Clusters in Azure zijn geïntegreerd met Diagnostische gegevens van Azure en Azure Monitor-logboeken. Clusterknooppunttypen zijn virtuele-machineschaalsets, zodat de functionaliteit voor automatisch schalen is ingebouwd.
U kunt een cluster in Azure maken via Azure Portal, vanuit een sjabloon of vanuit Visual Studio.
Met Service Fabric op Linux kunt u maximaal beschikbare, zeer schaalbare toepassingen op Linux bouwen, implementeren en beheren, net zoals in Windows. De Service Fabric-frameworks (Reliable Services en Reliable Actors) zijn beschikbaar in Java op Linux, naast C# (.NET Core). U kunt ook uitvoerbare gastservices bouwen met elke taal of elk framework. Het organiseren van Docker-containers wordt ook ondersteund. Docker-containers kunnen uitvoerbare gastbestanden of systeemeigen Service Fabric-services uitvoeren, die gebruikmaken van de Service Fabric-frameworks. Lees voor meer informatie over Service Fabric op Linux.
Er zijn enkele functies die worden ondersteund in Windows, maar niet in Linux. Lees verschillen tussen Service Fabric in Linux en Windows voor meer informatie.
Zelfstandige clusters
Service Fabric biedt een installatiepakket voor u om on-premises of op elke cloudprovider zelfstandige Service Fabric-clusters te maken. Zelfstandige clusters bieden u de vrijheid om een cluster te hosten waar u maar wilt. Als uw gegevens onderhevig zijn aan nalevings- of wettelijke beperkingen, of als u uw gegevens lokaal wilt houden, kunt u uw eigen cluster en toepassingen hosten. Service Fabric-toepassingen kunnen zonder wijzigingen worden uitgevoerd in meerdere hostingomgevingen, zodat uw kennis van het bouwen van toepassingen van de ene hostingomgeving naar de andere wordt overgedragen.
Uw eerste zelfstandige Service Fabric-cluster maken
Zelfstandige Linux-clusters worden nog niet ondersteund.
Clusterbeveiliging
Clusters moeten worden beveiligd om te voorkomen dat onbevoegde gebruikers verbinding maken met uw cluster, met name wanneer er productieworkloads op het cluster worden uitgevoerd. Hoewel het mogelijk is om een niet-beveiligd cluster te maken, kunnen anonieme gebruikers hiermee verbinding maken als beheereindpunten worden blootgesteld aan het openbare internet. Het is niet mogelijk om later beveiliging in te schakelen op een niet-beveiligd cluster: clusterbeveiliging is ingeschakeld tijdens het maken van het cluster.
De clusterbeveiligingsscenario's zijn:
- Beveiliging van knooppunt naar knooppunt
- Beveiliging van client-naar-knooppunt
- Op rollen gebaseerd toegangsbeheer van Service Fabric
Lees Een cluster beveiligen voor meer informatie.
Schalen
Als u nieuwe knooppunten aan het cluster toevoegt, worden in Service Fabric de partitiereplica's en exemplaren opnieuw verdeeld over het toegenomen aantal knooppunten. De algehele prestaties van toepassingen verbeteren en conflicten voor toegang tot geheugen nemen af. Als de knooppunten in het cluster niet efficiënt worden gebruikt, kunt u het aantal knooppunten in het cluster verlagen. Service Fabric herverdeling van de partitiereplica's en exemplaren over het verminderde aantal knooppunten om beter gebruik te maken van de hardware op elk knooppunt. U kunt clusters in Azure handmatig of programmatisch schalen. Zelfstandige clusters kunnen handmatig worden geschaald.
Clusterupgrades
Regelmatig worden nieuwe versies van de Service Fabric-runtime uitgebracht. Voer runtime- of infrastructuurupgrades uit op uw cluster, zodat u altijd een ondersteunde versie uitvoert. Naast infrastructuurupgrades kunt u ook clusterconfiguratie bijwerken, zoals certificaten of toepassingspoorten.
Een Service Fabric-cluster is een resource die u bezit, maar wordt deels beheerd door Microsoft. Microsoft is verantwoordelijk voor het patchen van het onderliggende besturingssysteem en het uitvoeren van infrastructuurupgrades op uw cluster. U kunt instellen dat uw cluster automatische infrastructuurupgrades ontvangt, wanneer Microsoft een nieuwe versie publiceert of ervoor kiest om een ondersteunde infrastructuurversie te selecteren die u wilt. Infrastructuur- en configuratie-upgrades kunnen worden ingesteld via De Azure-portal of via Resource Manager. Lees Een Service Fabric-cluster upgraden voor meer informatie.
Een zelfstandig cluster is een resource die u volledig bezit. U bent verantwoordelijk voor het patchen van het onderliggende besturingssysteem en het initiëren van infrastructuurupgrades. Als uw cluster verbinding kan maken https://www.microsoft.com/download, kunt u uw cluster zo instellen dat het nieuwe Service Fabric-runtimepakket automatisch wordt gedownload en ingericht. Vervolgens start u de upgrade. Als uw cluster geen toegang https://www.microsoft.com/downloadheeft, kunt u het nieuwe runtimepakket handmatig downloaden vanaf een computer met internetverbinding en vervolgens de upgrade starten. Lees Een zelfstandig Service Fabric-cluster upgraden voor meer informatie.
Statuscontrole
Service Fabric introduceert een statusmodel dat is ontworpen om beschadigde cluster- en toepassingsvoorwaarden te markeren voor specifieke entiteiten (zoals clusterknooppunten en servicereplica's). Het statusmodel maakt gebruik van statusrapporters (systeemonderdelen en watchdogs). Het doel is eenvoudig en snel diagnose en reparatie. Serviceschrijvers moeten vooraf nadenken over de status en het ontwerpen van statusrapportage. Elke voorwaarde die van invloed kan zijn op de status, moet worden gerapporteerd, met name als dit kan helpen bij het markeren van problemen dicht bij de hoofdmap. De statusinformatie kan tijd en moeite besparen op foutopsporing en onderzoek zodra de service op schaal in productie is.
De Service Fabric-reporters controleren geïdentificeerde interessevoorwaarden. Ze rapporteren over deze voorwaarden op basis van hun lokale weergave. In het statusarchief worden statusgegevens geaggregeerd die door alle rapportmakers worden verzonden om te bepalen of entiteiten globaal in orde zijn. Het model is bedoeld om rijk, flexibel en gebruiksvriendelijk te zijn. De kwaliteit van de statusrapporten bepaalt de nauwkeurigheid van de statusweergave van het cluster. Fout-positieven die ten onrechte beschadigde problemen vertonen, kunnen negatieve gevolgen hebben voor upgrades of andere services die gebruikmaken van statusgegevens. Voorbeelden van dergelijke services zijn reparatieservices en waarschuwingsmechanismen. Daarom is enige gedachte nodig om rapporten te verstrekken die op de best mogelijke manier de voorwaarden van belang vastleggen.
Rapportage kan worden uitgevoerd vanaf:
- De bewaakte Service Fabric-servicereplica of het bewaakte exemplaar.
- Interne waakhonden die zijn geïmplementeerd als een Service Fabric-service (bijvoorbeeld een stateless Service Fabric-service waarmee voorwaarden en problemen worden bewaakt). De watchdogs kunnen op alle knooppunten worden geïmplementeerd of kunnen worden geaffineerd met de bewaakte service.
- Interne watchdogs die worden uitgevoerd op de Service Fabric-knooppunten, maar die niet worden geïmplementeerd als Service Fabric-services.
- Externe watchdogs die de resource van buiten het Service Fabric-cluster testen (bijvoorbeeld bewakingsservice zoals Gomez).
Kant-en-klare Service Fabric-onderdelen rapporteren de status van alle entiteiten in het cluster. Systeemstatusrapporten bieden inzicht in cluster- en toepassingsfunctionaliteit en vlagproblemen via status. Voor toepassingen en services controleren systeemstatusrapporten of entiteiten zijn geïmplementeerd en zich correct gedragen vanuit het perspectief van de Service Fabric-runtime. De rapporten bieden geen statuscontrole van de bedrijfslogica van de service of detecteren processen die niet meer reageren. Als u statusinformatie wilt toevoegen die specifiek is voor de logica van uw service, implementeert u aangepaste statusrapportage in uw services.
Service Fabric biedt meerdere manieren om statusrapporten weer te geven die zijn samengevoegd in het statusarchief:
- Service Fabric Explorer of andere visualisatiehulpprogramma's.
- Statusquery's (via PowerShell, CLI, C# FabricClient-API's en Java FabricClient-API's of REST API's).
- Algemene query's die een lijst met entiteiten retourneren die de status hebben als een van de eigenschappen (via PowerShell, CLI, de API's of REST).
Controle en diagnose
Bewaking en diagnose zijn essentieel voor het ontwikkelen, testen en implementeren van toepassingen en services in elke omgeving. Service Fabric-oplossingen werken het beste wanneer u bewaking en diagnose plant en implementeert om ervoor te zorgen dat toepassingen en services werken zoals verwacht in een lokale ontwikkelomgeving of in productie.
De belangrijkste doelen van bewaking en diagnose zijn:
- Hardware- en infrastructuurproblemen detecteren en diagnosticeren
- Software- en app-problemen detecteren, service-downtime verminderen
- Inzicht in resourceverbruik en hulp bij het nemen van beslissingen over bewerkingen
- Prestaties van toepassingen, services en infrastructuur optimaliseren
- Bedrijfsinzichten genereren en gebieden van verbetering identificeren
De algehele werkstroom van bewaking en diagnose bestaat uit drie stappen:
- Gebeurtenisgeneratie: dit omvat gebeurtenissen (logboeken, traceringen, aangepaste gebeurtenissen) op de infrastructuur (cluster), het platform en het toepassings-/serviceniveau
- Gebeurtenisaggregatie: gegenereerde gebeurtenissen moeten worden verzameld en samengevoegd voordat ze kunnen worden weergegeven
- Analyse: gebeurtenissen moeten in een bepaalde indeling worden gevisualiseerd en toegankelijk zijn om analyse mogelijk te maken en indien nodig weer te geven
Er zijn meerdere producten beschikbaar die betrekking hebben op deze drie gebieden en u kunt voor elk product verschillende technologieën kiezen. Lees bewaking en diagnostische gegevens voor Azure Service Fabric voor meer informatie.
Volgende stappen
- Leer hoe u een cluster maakt in Azure of hoe u een zelfstandig cluster maakt in Windows.
- Maak een service met het programmeermodel Reliable Services of Reliable Actors.
- Leer hoe u migreert vanuit Cloud Services.
- Meer informatie over het bewaken en diagnosticeren van services.
- Meer informatie over het testen van uw apps en services.
- Meer informatie over het beheren en organiseren van clusterbronnen.
- Bekijk de Service Fabric-voorbeelden.
- Meer informatie over service fabric-ondersteuningsopties.
- Lees het teamblog voor artikelen en aankondigingen.