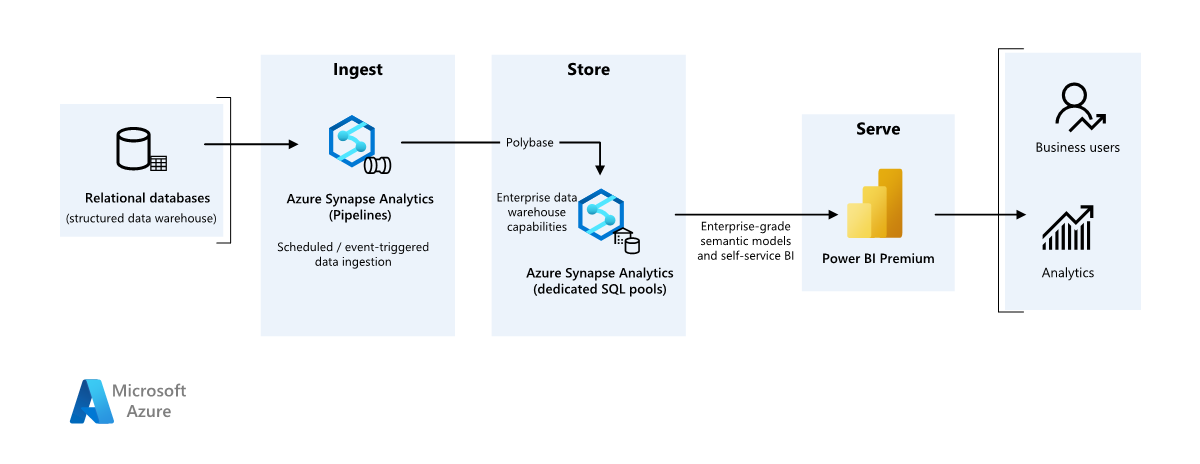
W tym przykładowym scenariuszu pokazano, jak dane można pozyskiwać do środowiska chmury z lokalnego magazynu danych, a następnie obsługiwać przy użyciu modelu analizy biznesowej (BI). Takie podejście może być celem końcowym lub pierwszym krokiem w kierunku pełnej modernizacji składników opartych na chmurze.
Poniższe kroki opierają się na scenariuszu kompleksowej usługi Azure Synapse Analytics. Usługa Azure Pipelines używa usługi Azure Pipelines do pozyskiwania danych z bazy danych SQL do pul SQL usługi Azure Synapse, a następnie przekształca dane na potrzeby analizy.
Architektura

Pobierz plik programu Visio z tą architekturą.
Przepływ pracy
Źródło danych
- Dane źródłowe znajdują się w bazie danych programu SQL Server na platformie Azure. Aby zasymulować środowisko lokalne, skrypty wdrażania dla tego scenariusza aprowizować bazę danych Azure SQL Database. Przykładowa baza danych AdventureWorks jest używana jako schemat danych źródłowych i przykładowe dane. Aby uzyskać informacje na temat kopiowania danych z lokalnej bazy danych, zobacz Kopiowanie i przekształcanie danych do i z programu SQL Server.
Pozyskiwanie i przechowywanie danych
Usługa Azure Data Lake Gen2 jest używana jako tymczasowy obszar przejściowy podczas pozyskiwania danych. Następnie można użyć technologii PolyBase do skopiowania danych do dedykowanej puli SQL usługi Azure Synapse.
Usługa Azure Synapse Analytics to rozproszony system przeznaczony do przeprowadzania analiz na dużych danych. Obsługuje równoległe przetwarzanie ogromnej ilości danych (MPP), dzięki czemu pozwala na uruchamianie analiz o wysokiej wydajności. Dedykowana pula SQL usługi Azure Synapse jest celem ciągłego pozyskiwania ze środowiska lokalnego. Może służyć do dalszego przetwarzania, a także obsługiwać dane dla usługi Power BI za pośrednictwem trybu DirectQuery.
Usługa Azure Pipelines służy do organizowania pozyskiwania i przekształcania danych w obszarze roboczym usługi Azure Synapse.
Analiza i raportowanie
- Podejście do modelowania danych w tym scenariuszu jest prezentowane przez połączenie modelu przedsiębiorstwa i modelu semantycznego analizy biznesowej. Model przedsiębiorstwa jest przechowywany w dedykowanej puli SQL usługi Azure Synapse, a model semantyczny analizy biznesowej jest przechowywany w pojemnościach usługi Power BI Premium. Usługa Power BI uzyskuje dostęp do danych za pośrednictwem trybu DirectQuery.
Elementy
W tym scenariuszu są używane następujące składniki:
- Azure SQL Database
- Azure Data Lake
- Azure Synapse Analytics
- Power BI Premium
- Tożsamość Microsoft Entra
Uproszczona architektura
Szczegóły scenariusza
Organizacja ma duży lokalny magazyn danych przechowywany w bazie danych SQL. Organizacja chce używać usługi Azure Synapse do przeprowadzania analizy, a następnie udostępniać te szczegółowe informacje przy użyciu usługi Power BI.
Uwierzytelnianie
Firma Microsoft Entra uwierzytelnia użytkowników, którzy łączą się z pulpitami nawigacyjnymi i aplikacjami usługi Power BI. Logowanie jednokrotne służy do nawiązywania połączenia ze źródłem danych w aprowizowanej puli usługi Azure Synapse. Autoryzacja odbywa się w źródle.
Ładowanie przyrostowe
W przypadku uruchamiania zautomatyzowanego procesu wyodrębniania i przekształcania transformacji (ETL) lub wyodrębniania-ładowania (ELT) najbardziej efektywne jest ładowanie tylko danych, które uległy zmianie od poprzedniego uruchomienia. Jest to nazywane obciążeniem przyrostowym, a nie pełnym obciążeniem, które ładuje wszystkie dane. Aby wykonać obciążenie przyrostowe, należy określić, które dane uległy zmianie. Najczęstszym podejściem jest użycie wysokiej wartości znaku wodnego, która śledzi najnowszą wartość kolumny w tabeli źródłowej, kolumnę typu data/godzina lub unikatową kolumnę całkowitą.
Począwszy od programu SQL Server 2016, można użyć tabel czasowych, które są tabelami w wersji systemowej, które zachowują pełną historię zmian danych. Aparat bazy danych automatycznie rejestruje historię każdej zmiany w oddzielnej tabeli historii. Możesz wykonywać zapytania dotyczące danych historycznych, dodając klauzulę FOR SYSTEM_TIME do zapytania. Aparat bazy danych wykonuje zapytanie względem tabeli historii, ale jest niewidoczny dla aplikacji.
Uwaga
W przypadku wcześniejszych wersji programu SQL Server można użyć funkcji przechwytywania zmian danych (CDC). Takie podejście jest mniej wygodne niż tabele czasowe, ponieważ trzeba wykonywać zapytania dotyczące oddzielnej tabeli zmian, a zmiany są śledzone przez numer sekwencji dzienników, a nie sygnaturę czasową.
Tabele czasowe są przydatne w przypadku danych wymiarów, które mogą ulec zmianie w czasie. Tabele faktów zwykle reprezentują niezmienną transakcję, taką jak sprzedaż, w takim przypadku utrzymywanie historii wersji systemu nie ma sensu. Zamiast tego transakcje mają zwykle kolumnę reprezentującą datę transakcji, która może być używana jako wartość limitu. Na przykład w usłudze AdventureWorks Data Warehouse SalesLT.* tabele mają LastModified pole.
Oto ogólny przepływ potoku ELT:
Dla każdej tabeli w źródłowej bazie danych śledź czas odcięcia po uruchomieniu ostatniego zadania ELT. Zapisz te informacje w magazynie danych. W początkowej konfiguracji wszystkie czasy są ustawione na
1-1-1900.W kroku eksportowania danych czas odcięcia jest przekazywany jako parametr do zestawu procedur składowanych w źródłowej bazie danych. Te procedury składowane wysyłają zapytania do wszystkich rekordów, które zostały zmienione lub utworzone po czasie odcięcia. W przypadku wszystkich tabel w przykładzie można użyć kolumny
ModifiedDate.Po zakończeniu migracji danych zaktualizuj tabelę, która przechowuje czasy odcięcia.
Potok danych
W tym scenariuszu przykładowa baza danych AdventureWorks jest używana jako źródło danych. Wzorzec obciążenia danych przyrostowych jest implementowany, aby zagwarantować, że załadujemy tylko dane, które zostały zmodyfikowane lub dodane po ostatnim uruchomieniu potoku.
Narzędzie do kopiowania opartego na metadanych
Wbudowane narzędzie do kopiowania metadanych w usłudze Azure Pipelines przyrostowo ładuje wszystkie tabele zawarte w naszej relacyjnej bazie danych. Przechodząc przez środowisko oparte na kreatorze, możesz połączyć narzędzie copy data z źródłową bazą danych i skonfigurować przyrostowe lub pełne ładowanie dla każdej tabeli. Narzędzie do kopiowania danych tworzy potoki i skrypty SQL w celu wygenerowania tabeli kontrolnej wymaganej do przechowywania danych dla procesu ładowania przyrostowego — na przykład wysokiej wartości/kolumny limitu dla każdej tabeli. Po uruchomieniu tych skryptów potok jest gotowy do załadowania wszystkich tabel w magazynie danych źródłowych do dedykowanej puli usługi Synapse.
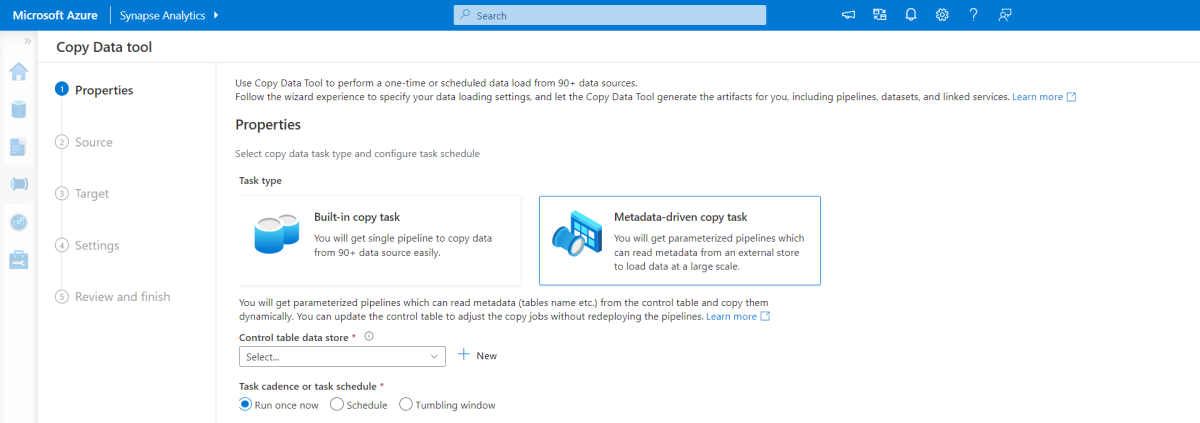
Narzędzie tworzy trzy potoki w celu iterowania wszystkich tabel w bazie danych przed załadowaniem danych.
Potoki generowane przez to narzędzie:
- Zlicz liczbę obiektów, takich jak tabele, które mają być kopiowane w przebiegu potoku.
- Iteruj nad każdym obiektem, który ma zostać załadowany/skopiowany, a następnie:
- Sprawdź, czy wymagane jest obciążenie różnicowe; w przeciwnym razie wykonaj normalne pełne obciążenie.
- Pobierz wysoką wartość limitu z tabeli kontrolnej.
- Skopiuj dane z tabel źródłowych do konta przejściowego w usłudze ADLS Gen2.
- Załaduj dane do dedykowanej puli SQL za pomocą wybranej metody kopiowania — na przykład polybase, polecenie Kopiuj.
- Zaktualizuj wysoką wartość limitu w tabeli kontrolnej.
Ładowanie danych do puli SQL usługi Azure Synapse
Działanie kopiowania kopiuje dane z bazy danych SQL do puli SQL usługi Azure Synapse SQL. W tym przykładzie, ponieważ nasza baza danych SQL znajduje się na platformie Azure, używamy środowiska Azure Integration Runtime do odczytywania danych z bazy danych SQL Database i zapisywania danych w określonym środowisku przejściowym.
Instrukcja copy jest następnie używana do ładowania danych ze środowiska przejściowego do dedykowanej puli usługi Synapse.
Korzystanie z usługi Azure Pipelines
Potoki w usłudze Azure Synapse służą do definiowania uporządkowanego zestawu działań w celu ukończenia wzorca obciążenia przyrostowego. Wyzwalacze są używane do uruchamiania potoku, który można wyzwalać ręcznie lub w określonym czasie.
Przekształcanie danych
Ponieważ przykładowa baza danych w naszej architekturze referencyjnej nie jest duża, utworzyliśmy zreplikowane tabele bez partycji. W przypadku obciążeń produkcyjnych użycie tabel rozproszonych może poprawić wydajność zapytań. Zobacz Wskazówki dotyczące projektowania tabel rozproszonych w usłudze Azure Synapse. Przykładowe skrypty uruchamiają zapytania przy użyciu statycznej klasy zasobów.
W środowisku produkcyjnym rozważ utworzenie tabel przejściowych z dystrybucją okrężną. Następnie przekształć i przenieść dane do tabel produkcyjnych przy użyciu klastrowanych indeksów magazynu kolumn, które oferują najlepszą ogólną wydajność zapytań. Indeksy magazynu kolumn są zoptymalizowane pod kątem zapytań, które skanują wiele rekordów. Indeksy magazynu kolumn nie działają tak dobrze w przypadku pojedynczych odnośników, czyli wyszukiwania w górę jednego wiersza. Jeśli musisz wykonywać częste pojedyncze wyszukiwania, możesz dodać indeks nieklasterowany do tabeli. Pojedyncze wyszukiwania mogą działać znacznie szybciej przy użyciu indeksu nieklasterowanego. Jednak pojedyncze wyszukiwania są zwykle mniej powszechne w scenariuszach magazynu danych niż obciążenia OLTP. Aby uzyskać więcej informacji, zobacz Indeksowanie tabel w usłudze Azure Synapse.
Uwaga
Tabele klastrowanego magazynu kolumn nie obsługują varchar(max)typów danych , nvarchar(max)ani varbinary(max) . W takim przypadku należy wziąć pod uwagę stertę lub indeks klastrowany. Możesz umieścić te kolumny w oddzielnej tabeli.
Uzyskiwanie dostępu, modelowanie i wizualizowanie danych przy użyciu usługi Power BI Premium
Usługa Power BI Premium obsługuje kilka opcji nawiązywania połączenia ze źródłami danych na platformie Azure, w szczególności w aprowizowanej puli usługi Azure Synapse:
- Importowanie: dane są importowane do modelu usługi Power BI.
- Zapytanie bezpośrednie: dane są pobierane bezpośrednio z magazynu relacyjnego.
- Model złożony: połącz importowanie dla niektórych tabel i zapytania bezpośredniego dla innych.
Ten scenariusz jest dostarczany z pulpitem nawigacyjnym trybu DirectQuery, ponieważ ilość używanych danych i złożoność modelu nie jest wysoka, dzięki czemu możemy zapewnić dobre środowisko użytkownika. Zapytanie bezpośrednie deleguje zapytanie do zaawansowanego aparatu obliczeniowego poniżej i korzysta z rozbudowanych funkcji zabezpieczeń w źródle. Ponadto użycie trybu DirectQuery gwarantuje, że wyniki są zawsze zgodne z najnowszymi danymi źródłowymi.
Tryb importu zapewnia najszybszy czas odpowiedzi zapytań i powinien być brany pod uwagę, gdy model mieści się w całości w pamięci usługi Power BI, opóźnienie danych między odświeżeniami może być tolerowane i może wystąpić pewne złożone przekształcenia między systemem źródłowym a ostatecznym modelem. W takim przypadku użytkownicy końcowi chcą mieć pełny dostęp do najnowszych danych bez opóźnień w odświeżaniu usługi Power BI i wszystkich danych historycznych, które są większe niż to, co może obsłużyć zestaw danych usługi Power BI — w zależności od rozmiaru pojemności. Ponieważ model danych w dedykowanej puli SQL znajduje się już w schemacie gwiazdy i nie wymaga przekształcenia, zapytanie bezpośrednie jest odpowiednim wyborem.
Usługa Power BI Premium Gen2 umożliwia obsługę dużych modeli, raportów podzielonych na strony, potoków wdrażania i wbudowanego punktu końcowego usług Analysis Services. Możesz również mieć dedykowaną pojemność z unikatową propozycją wartości.
Gdy model analizy biznesowej rośnie lub zwiększa się złożoność pulpitu nawigacyjnego, możesz przełączyć się na modele złożone i rozpocząć importowanie części tabel odnośników, za pośrednictwem tabel hybrydowych i niektórych wstępnie zagregowanych danych. Włączenie buforowania zapytań w usłudze Power BI dla zaimportowanych zestawów danych jest opcją, a także użycie dwóch tabel dla właściwości trybu przechowywania.
W ramach modelu złożonego zestawy danych działają jako warstwa przekazywania wirtualnego. Gdy użytkownik wchodzi w interakcję z wizualizacjami, usługa Power BI generuje zapytania SQL do pul SQL synapse SQL z dwoma magazynami: w pamięci lub zapytaniu bezpośrednim w zależności od tego, który z nich jest bardziej wydajny. Aparat decyduje, kiedy przełączyć się z pamięci na zapytanie bezpośrednie i wypchnie logikę do puli SQL usługi Synapse. W zależności od kontekstu tabel zapytań mogą one działać jako buforowane (importowane) lub nie buforowane modele złożone. Wybierz i wybierz tabelę do buforowania w pamięci, połącz dane z co najmniej jednego źródła trybu DirectQuery i/lub połącz dane z kombinacji źródeł trybu DirectQuery i zaimportowanych danych.
Rekomendacje: W przypadku korzystania z trybu DirectQuery w aprowizowanej puli usługi Azure Synapse Analytics:
- Buforowanie zestawu wyników usługi Azure Synapse umożliwia buforowanie wyników zapytań w bazie danych użytkownika w celu powtarzalnego użycia, zwiększanie wydajności zapytań w milisekundach i zmniejszanie użycia zasobów obliczeniowych. Zapytania korzystające z buforowanych zestawów wyników nie używają żadnych miejsc współbieżności w usłudze Azure Synapse Analytics i w związku z tym nie są uwzględniane w istniejących limitach współbieżności.
- Użyj zmaterializowanych widoków usługi Azure Synapse, aby wstępnie obliczyć, przechowywać i obsługiwać dane tak jak tabela. Zapytania korzystające ze wszystkich lub podzestawu danych w zmaterializowanych widokach mogą uzyskać szybszą wydajność i nie muszą odwoływać się bezpośrednio do zdefiniowanego zmaterializowanego widoku, aby go używać.
Kwestie wymagające rozważenia
Te zagadnienia implementują filary struktury Azure Well-Architected Framework, która jest zestawem wytycznych, które mogą służyć do poprawy jakości obciążenia. Aby uzyskać więcej informacji, zobacz Microsoft Azure Well-Architected Framework.
Zabezpieczenia
Zabezpieczenia zapewniają ochronę przed celowymi atakami i nadużyciami cennych danych i systemów. Aby uzyskać więcej informacji, zobacz Omówienie filaru zabezpieczeń.
Częste nagłówki naruszeń danych, infekcje złośliwym oprogramowaniem i wstrzyknięcie złośliwego kodu należą do szerokiej listy problemów z zabezpieczeniami firm, które chcą modernizacji chmury. Klienci korporacyjni potrzebują dostawcy usług lub dostawcy usług, które mogą rozwiązać swoje problemy, ponieważ nie mogą sobie pozwolić na błędne rozwiązanie.
Ten scenariusz dotyczy najbardziej wymagających problemów z zabezpieczeniami przy użyciu kombinacji warstwowych mechanizmów kontroli zabezpieczeń: sieci, tożsamości, prywatności i autoryzacji. Większość danych jest przechowywana w aprowizowanej puli usługi Azure Synapse, a usługa Power BI korzysta z trybu DirectQuery za pośrednictwem logowania jednokrotnego. Do uwierzytelniania można użyć identyfikatora Entra firmy Microsoft. Istnieją również obszerne mechanizmy kontroli zabezpieczeń na potrzeby autoryzacji danych aprowizowania pul.
Oto niektóre typowe pytania dotyczące zabezpieczeń:
- Jak mogę kontrolować, kto może wyświetlać jakie dane?
- Organizacje muszą chronić swoje dane w celu zachowania zgodności z wytycznymi federalnymi, lokalnymi i firmowymi w celu ograniczenia ryzyka naruszenia danych. Usługa Azure Synapse oferuje wiele funkcji ochrony danych w celu zapewnienia zgodności.
- Jakie są opcje weryfikowania tożsamości użytkownika?
- Usługa Azure Synapse obsługuje szeroką gamę możliwości kontrolowania, kto może uzyskiwać dostęp do danych za pośrednictwem kontroli dostępu i uwierzytelniania.
- Jakiej technologii zabezpieczeń sieci można użyć do ochrony integralności, poufności i dostępu do moich sieci i danych?
- Jakie narzędzia wykrywają i powiadamiają mnie o zagrożeniach?
- Usługa Azure Synapse oferuje wiele funkcji wykrywania zagrożeń, takich jak inspekcja SQL, wykrywanie zagrożeń SQL i ocena luk w zabezpieczeniach w celu przeprowadzania inspekcji, ochrony i monitorowania baz danych.
- Co mogę zrobić, aby chronić dane na moim koncie magazynu?
Optymalizacja kosztów
Optymalizacja kosztów dotyczy sposobów zmniejszenia niepotrzebnych wydatków i poprawy wydajności operacyjnej. Aby uzyskać więcej informacji, zobacz Omówienie filaru optymalizacji kosztów.
Ta sekcja zawiera informacje na temat cen różnych usług zaangażowanych w to rozwiązanie oraz zawiera informacje o decyzjach podjętych w tym scenariuszu przy użyciu przykładowego zestawu danych.
Azure Synapse
Architektura bezserwerowa usługi Azure Synapse Analytics umożliwia niezależne skalowanie poziomów zasobów obliczeniowych i magazynu. Opłaty za zasoby obliczeniowe są naliczane na podstawie użycia i można skalować lub wstrzymać te zasoby na żądanie. Opłaty za zasoby magazynu są naliczane za terabajt, więc koszty będą rosnąć w miarę pozyskiwania większej ilości danych.
Azure Pipelines
Szczegóły cennika potoków w usłudze Azure Synapse można znaleźć na karcie Integracja danych na stronie cennika usługi Azure Synapse. Istnieją trzy główne składniki wpływające na cenę potoku:
- Działania potoku danych i godziny środowiska Integration Runtime
- Rozmiar i wykonywanie klastra przepływów danych
- opłat za operacje
Cena różni się w zależności od składników lub działań, częstotliwości i liczby jednostek środowiska Integration Runtime.
W przypadku przykładowego zestawu danych standardowe środowisko Integration Runtime hostowane na platformie Azure, działanie kopiowania danych dla rdzenia potoku jest wyzwalane zgodnie z dziennym harmonogramem dla wszystkich jednostek (tabel) w źródłowej bazie danych. Scenariusz nie zawiera przepływów danych. Nie ma żadnych kosztów operacyjnych, ponieważ istnieje mniej niż 1 milion operacji z potokami miesięcznie.
Dedykowana pula i magazyn usługi Azure Synapse
Szczegóły cennika dedykowanej puli usługi Azure Synapse można znaleźć na karcie Magazyn danych na stronie cennika usługi Azure Synapse. W ramach modelu Dedykowane zużycie klienci są rozliczani za aprowizowaną jednostkę DWU na godzinę czasu pracy. Innym czynnikiem przyczyniającym się jest koszt magazynowania danych: rozmiar danych magazynowanych i migawek i nadmiarowości geograficznej, jeśli istnieje.
W przypadku przykładowego zestawu danych można aprowizować 500DWU, co gwarantuje dobre środowisko ładowania analitycznego. Obliczenia można utrzymywać i uruchamiać w godzinach pracy raportowania. W przypadku uwzględnienia w środowisku produkcyjnym pojemność zarezerwowanego magazynu danych jest atrakcyjną opcją zarządzania kosztami. W celu zmaksymalizowania metryk kosztów/wydajności, które zostały omówione w poprzednich sekcjach, należy użyć różnych technik.
Blob storage
Rozważ użycie funkcji pojemności zarezerwowanej usługi Azure Storage, aby obniżyć koszty magazynowania. Dzięki temu modelowi uzyskasz rabat, jeśli rezerwujesz stałą pojemność magazynu przez jeden lub trzy lata. Aby uzyskać więcej informacji, zobacz Optymalizowanie kosztów magazynu obiektów blob przy użyciu pojemności zarezerwowanej.
W tym scenariuszu nie ma magazynu trwałego.
Power BI Premium
Szczegóły cennika usługi Power BI Premium można znaleźć na stronie cennika usługi Power BI.
W tym scenariuszu są używane obszary robocze usługi Power BI Premium z szeregiem ulepszeń wydajności wbudowanych w celu zaspokojenia wymagających potrzeb analitycznych.
Doskonałość operacyjna
Doskonałość operacyjna obejmuje procesy operacyjne, które wdrażają aplikację i działają w środowisku produkcyjnym. Aby uzyskać więcej informacji, zobacz Omówienie filaru doskonałości operacyjnej.
Zalecenia dotyczące metodyki DevOps
Utwórz oddzielne grupy zasobów dla środowisk produkcyjnych, programistycznych i testowych. Oddzielne grupy zasobów ułatwiają zarządzanie wdrożeniami, usuwanie wdrożeń testowych i przypisywanie praw dostępu.
Umieść każde obciążenie w osobnym szablonie wdrożenia i zapisz zasoby w systemach kontroli źródła. Szablony można wdrażać razem lub indywidualnie w ramach procesu ciągłej integracji i ciągłego dostarczania (CD), co ułatwia proces automatyzacji. W tej architekturze istnieją cztery główne obciążenia:
- Serwer magazynu danych i powiązane zasoby
- Potoki usługi Azure Synapse
- Zasoby usługi Power BI: pulpity nawigacyjne, aplikacje, zestawy danych
- Scenariusz symulowany w środowisku lokalnym do chmury
Należy mieć oddzielny szablon wdrożenia dla każdego z obciążeń.
Rozważ przemieszczanie obciążeń tam, gdzie jest to praktyczne. Wdróż na różnych etapach i uruchom testy weryfikacyjne na każdym etapie przed przejściem do następnego etapu. Dzięki temu można wypychać aktualizacje do środowisk produkcyjnych w kontrolowany sposób i zminimalizować nieprzewidziane problemy z wdrażaniem. Użyj strategii wdrażania niebieski-zielony i kanary wydania na potrzeby aktualizowania środowisk produkcyjnych na żywo.
Mają dobrą strategię wycofywania do obsługi wdrożeń, które zakończyły się niepowodzeniem. Możesz na przykład automatycznie ponownie wdrożyć wcześniejsze, pomyślne wdrożenie z historii wdrożenia. Zobacz flagę w interfejsie wiersza polecenia platformy
--rollback-on-errorAzure.Usługa Azure Monitor jest zalecaną opcją analizowania wydajności magazynu danych i całej platformy azure analytics w celu uzyskania zintegrowanego środowiska monitorowania. Usługa Azure Synapse Analytics udostępnia środowisko monitorowania w witrynie Azure Portal, aby wyświetlić szczegółowe informacje o obciążeniu magazynu danych. Witryna Azure Portal jest zalecanym narzędziem do monitorowania magazynu danych, ponieważ zapewnia konfigurowalne okresy przechowywania, alerty, zalecenia i konfigurowalne wykresy i pulpity nawigacyjne dla metryk i dzienników.
Szybki start
- Portal: weryfikacja koncepcji w usłudze Azure Synapse
- Interfejs wiersza polecenia platformy Azure: tworzenie obszaru roboczego usługi Azure Synapse przy użyciu interfejsu wiersza polecenia platformy Azure
- Terraform: nowoczesne magazynowanie danych za pomocą programu Terraform i platformy Microsoft Azure
Efektywność wydajności
Efektywność wydajności to możliwość skalowania obciążenia w celu zaspokojenia zapotrzebowania użytkowników w wydajny sposób. Aby uzyskać więcej informacji, zobacz Omówienie filaru wydajności.
Ta sekcja zawiera szczegółowe informacje na temat decyzji o określaniu rozmiaru, aby uwzględnić ten zestaw danych.
Aprowizowana pula usługi Azure Synapse
Istnieje szereg konfiguracji magazynu danych do wyboru.
| Jednostki magazynu danych | Liczba węzłów obliczeniowych | Liczba dystrybucji na węzeł |
|---|---|---|
| DW100c | 1 | 60 |
-- TO -- |
||
| DW30000c | 60 | 1 |
Aby zobaczyć korzyści z wydajności skalowania w poziomie, szczególnie w przypadku większych jednostek magazynu danych, należy użyć co najmniej zestawu danych o rozmiarze 1 TB. Aby znaleźć najlepszą liczbę jednostek magazynu danych dla dedykowanej puli SQL, spróbuj skalować w górę i w dół. Uruchom kilka zapytań z różnymi liczbami jednostek magazynu danych po załadowaniu danych. Ponieważ skalowanie jest szybkie, możesz wypróbować różne poziomy wydajności w ciągu godziny lub mniej.
Znajdowanie najlepszej liczby jednostek magazynu danych
Aby utworzyć dedykowaną pulę SQL, zacznij od wybrania mniejszej liczby jednostek magazynu danych. Dobrym punktem wyjścia jest DW400c lub DW200c. Monitoruj wydajność aplikacji, obserwując liczbę wybranych jednostek magazynu danych w porównaniu z obserwowaną wydajnością. Załóżmy skalę liniową i określ, ile trzeba zwiększyć lub zmniejszyć liczbę jednostek magazynu danych. Kontynuuj wprowadzanie korekt, dopóki nie osiągniesz optymalnego poziomu wydajności dla wymagań biznesowych.
Skalowanie puli SQL usługi Synapse
- Skalowanie zasobów obliczeniowych dla puli SQL usługi Synapse przy użyciu witryny Azure Portal
- Skalowanie zasobów obliczeniowych dla dedykowanej puli SQL przy użyciu programu Azure PowerShell
- Skalowanie zasobów obliczeniowych dla dedykowanej puli SQL w usłudze Azure Synapse Analytics przy użyciu języka T-SQL
- Wstrzymanie, monitorowanie i automatyzacja
Azure Pipelines
Aby uzyskać funkcje optymalizacji skalowalności i wydajności potoków w usłudze Azure Synapse i używane działanie kopiowania, zapoznaj się z przewodnikiem dotyczącym wydajności i skalowalności działanie Kopiuj.
Power BI Premium
W tym artykule przedstawiono możliwości analizy biznesowej przy użyciu usługi Power BI Premium Gen 2 . Jednostki SKU pojemności dla usługi Power BI Premium wahają się od P1 (osiem rdzeni wirtualnych) do P5 (obecnie 128 rdzeni wirtualnych). Najlepszym sposobem wybrania wymaganej pojemności jest przeprowadzenie oceny ładowania pojemności, zainstalowanie aplikacji metryk gen2 na potrzeby ciągłego monitorowania i rozważ użycie autoskalowania w usłudze Power BI Premium.
Współautorzy
Ten artykuł jest obsługiwany przez firmę Microsoft. Pierwotnie został napisany przez następujących współautorów.
Autorzy zabezpieczeń:
- Galina Polyakova | Starszy architekt rozwiązań w chmurze
- Noah Costar | Architekt rozwiązań w chmurze
- George Stevens | Architekt rozwiązań w chmurze
Inni współautorzy:
- Jim McLeod | Architekt rozwiązań w chmurze
- Miguel Myers | Starszy menedżer programu
Aby wyświetlić niepubalne profile serwisu LinkedIn, zaloguj się do serwisu LinkedIn.
Następne kroki
- Co to jest usługa Power BI Premium?
- Co to jest identyfikator Entra firmy Microsoft?
- Uzyskiwanie dostępu do usługi Azure Data Lake Storage Gen2 i usługi Blob Storage za pomocą usługi Azure Databricks
- Co to jest usługa Azure Synapse Analytics?
- Potoki i działania w usłudze Azure Data Factory i Azure Synapse Analytics
- Co to jest usługa Azure SQL?