Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
DOTYCZY: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Napiwek
Wypróbuj usługę Data Factory w usłudze Microsoft Fabric — rozwiązanie analityczne typu all-in-one dla przedsiębiorstw. Usługa Microsoft Fabric obejmuje wszystko, od przenoszenia danych do nauki o danych, analizy w czasie rzeczywistym, analizy biznesowej i raportowania. Dowiedz się, jak bezpłatnie rozpocząć nową wersję próbną !
W tym artykule opisano sposób używania działanie Kopiuj w usługach Azure Data Factory i Azure Synapse do kopiowania danych do i z usługi Azure Databricks Delta Lake. Opiera się on na artykule działanie Kopiuj, który przedstawia ogólne omówienie działania kopiowania.
Obsługiwane możliwości
Ten łącznik usługi Delta Lake usługi Azure Databricks jest obsługiwany w następujących funkcjach:
| Obsługiwane możliwości | IR |
|---|---|
| działanie Kopiuj (źródło/ujście) | (1) (2) |
| Przepływ danych mapowania (źródło/ujście) | (1) |
| Działanie Lookup | (1) (2) |
(1) Środowisko Azure Integration Runtime (2) Self-hosted Integration Runtime
Ogólnie rzecz biorąc, usługa obsługuje usługę Delta Lake z następującymi możliwościami, aby spełnić różne potrzeby.
- działanie Kopiuj obsługuje łącznik usługi Azure Databricks Delta Lake w celu kopiowania danych z dowolnego obsługiwanego magazynu danych źródłowych do tabeli typu delta lake usługi Azure Databricks oraz z tabeli usługi Delta Lake do dowolnego obsługiwanego magazynu danych ujścia. Wykorzystuje klaster usługi Databricks do wykonywania przenoszenia danych, zobacz szczegóły w sekcji Wymagania wstępne.
- Mapowanie Przepływ danych obsługuje ogólny format delta w usłudze Azure Storage jako źródło i ujście do odczytu i zapisu plików różnicowych dla wolnego od kodu ETL oraz działa w zarządzanym środowisku Azure Integration Runtime.
- Działania usługi Databricks obsługują organizowanie obciążenia ETL skoncentrowanego na kodzie lub uczenia maszynowego na bazie usługi Delta Lake.
Wymagania wstępne
Aby użyć tego łącznika usługi Azure Databricks Delta Lake, należy skonfigurować klaster w usłudze Azure Databricks.
- Aby skopiować dane do usługi Delta Lake, działanie Kopiuj wywołuje klaster usługi Azure Databricks w celu odczytu danych z usługi Azure Storage, czyli oryginalnego źródła lub obszaru przejściowego, do którego usługa najpierw zapisuje dane źródłowe za pośrednictwem wbudowanej kopii etapowej. Dowiedz się więcej z usługi Delta Lake jako zlewu.
- Podobnie, aby skopiować dane z usługi Delta Lake, działanie Kopiuj wywołuje klaster usługi Azure Databricks w celu zapisania danych w usłudze Azure Storage, czyli oryginalnego ujścia lub obszaru przejściowego, z którego usługa kontynuuje zapisywanie danych do końcowego ujścia za pomocą wbudowanej kopii etapowej. Dowiedz się więcej na temat usługi Delta Lake jako źródła.
Klaster usługi Databricks musi mieć dostęp do konta usługi Azure Blob lub Azure Data Lake Storage Gen2, zarówno kontenera magazynu,jak i systemu plików używanego do celów źródłowych/ujścia/przemieszczania oraz kontenera/systemu plików, w którym chcesz zapisać tabele usługi Delta Lake.
Aby użyć usługi Azure Data Lake Storage Gen2, możesz skonfigurować jednostkę usługi w klastrze usługi Databricks w ramach konfiguracji platformy Apache Spark. Wykonaj kroki opisane w artykule Uzyskiwanie dostępu bezpośrednio z jednostką usługi.
Aby użyć usługi Azure Blob Storage, możesz skonfigurować klucz dostępu konta magazynu lub token SAS w klastrze usługi Databricks w ramach konfiguracji platformy Apache Spark. Wykonaj kroki opisane w artykule Uzyskiwanie dostępu do usługi Azure Blob Storage przy użyciu interfejsu API RDD.
Podczas wykonywania działania kopiowania, jeśli skonfigurowany klaster został zakończony, usługa zostanie automatycznie uruchomiona. Jeśli tworzysz potok przy użyciu interfejsu użytkownika tworzenia, w przypadku operacji takich jak podgląd danych, musisz mieć klaster na żywo, usługa nie uruchomi klastra w Twoim imieniu.
Określanie konfiguracji klastra
Z listy rozwijanej Tryb klastra wybierz pozycję Standardowa.
Z listy rozwijanej Wersja środowiska uruchomieniowego usługi Databricks wybierz wersję środowiska uruchomieniowego usługi Databricks.
Włącz automatyczne optymalizowanie, dodając następujące właściwości do konfiguracji platformy Spark:
spark.databricks.delta.optimizeWrite.enabled true spark.databricks.delta.autoCompact.enabled trueSkonfiguruj klaster w zależności od potrzeb dotyczących integracji i skalowania.
Aby uzyskać szczegółowe informacje o konfiguracji klastra, zobacz Konfigurowanie klastrów.
Rozpocznij
Aby wykonać działanie Kopiuj za pomocą potoku, możesz użyć jednego z następujących narzędzi lub zestawów SDK:
- Narzędzie do kopiowania danych
- Witryna Azure Portal
- Zestaw SDK platformy .NET
- Zestaw SDK języka Python
- Azure PowerShell
- Interfejs API REST
- Szablon usługi Azure Resource Manager
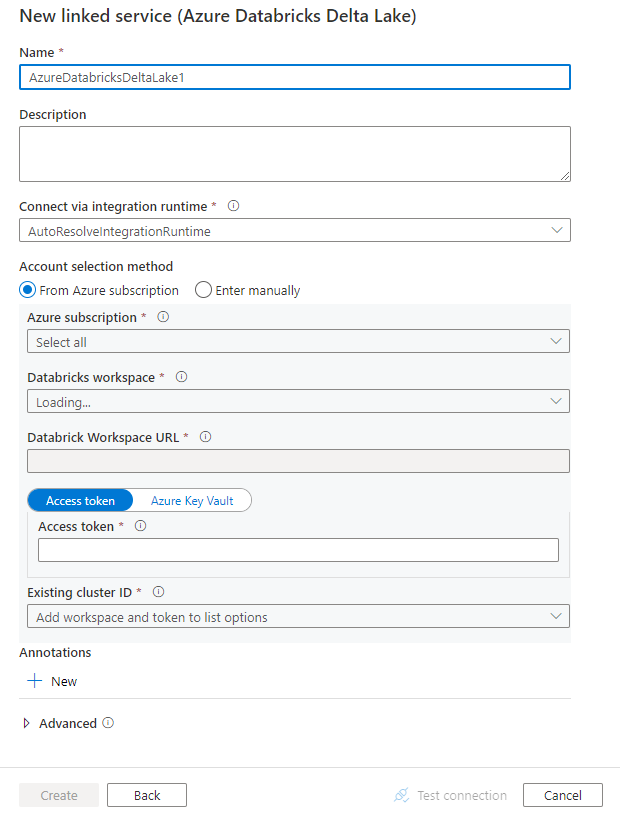
Tworzenie połączonej usługi z usługą Azure Databricks Delta Lake przy użyciu interfejsu użytkownika
Wykonaj poniższe kroki, aby utworzyć połączoną usługę z usługą Azure Databricks Delta Lake w interfejsie użytkownika witryny Azure Portal.
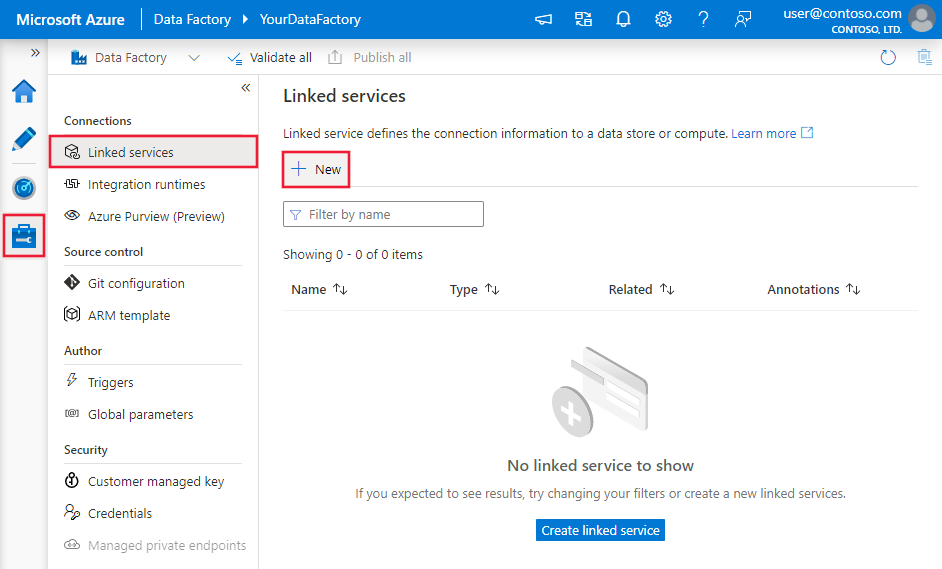
Przejdź do karty Zarządzanie w obszarze roboczym usługi Azure Data Factory lub Synapse i wybierz pozycję Połączone usługi, a następnie kliknij pozycję Nowy:
Wyszukaj delta i wybierz łącznik usługi Delta Lake usługi Azure Databricks.

Skonfiguruj szczegóły usługi, przetestuj połączenie i utwórz nową połączoną usługę.
Szczegóły konfiguracji łącznika
Poniższe sekcje zawierają szczegółowe informacje o właściwościach definiujących jednostki specyficzne dla łącznika usługi Delta Lake usługi Azure Databricks.
Właściwości połączonej usługi
Ten łącznik usługi Delta Lake usługi Azure Databricks obsługuje następujące typy uwierzytelniania. Aby uzyskać szczegółowe informacje, zobacz odpowiednie sekcje.
- Token dostępu
- Uwierzytelnianie tożsamości zarządzanej przypisanej przez system
- Uwierzytelnianie tożsamości zarządzanej przypisanej przez użytkownika
Token dostępu
Następujące właściwości są obsługiwane w przypadku połączonej usługi Azure Databricks Delta Lake:
| Właściwości | Opis | Wymagania |
|---|---|---|
| type | Właściwość type musi być ustawiona na AzureDatabricksDeltaLake. | Tak |
| domena | Określ adres URL obszaru roboczego usługi Azure Databricks, np. https://adb-xxxxxxxxx.xx.azuredatabricks.net. |
|
| clusterId | Określ identyfikator klastra istniejącego klastra. Powinien on być już utworzonym klastrem interaktywnym. Identyfikator klastra interaktywnego klastra można znaleźć w obszarze roboczym usługi Databricks —> Klastry — nazwa klastra interakcyjnego —>> konfiguracja —> tagi. Dowiedz się więcej. |
|
| accessToken | Token dostępu jest wymagany, aby usługa uwierzytelniła się w usłudze Azure Databricks. Token dostępu należy wygenerować z obszaru roboczego usługi Databricks. Bardziej szczegółowe kroki znajdowania tokenu dostępu można znaleźć tutaj. | |
| connectVia | Środowisko Integration Runtime używane do nawiązywania połączenia z magazynem danych. Możesz użyć środowiska Azure Integration Runtime lub własnego środowiska Integration Runtime (jeśli magazyn danych znajduje się w sieci prywatnej). Jeśli nie zostanie określony, używa domyślnego środowiska Azure Integration Runtime. | Nie. |
Przykład:
{
"name": "AzureDatabricksDeltaLakeLinkedService",
"properties": {
"type": "AzureDatabricksDeltaLake",
"typeProperties": {
"domain": "https://adb-xxxxxxxxx.xx.azuredatabricks.net",
"clusterId": "<cluster id>",
"accessToken": {
"type": "SecureString",
"value": "<access token>"
}
}
}
}
Uwierzytelnianie tożsamości zarządzanej przypisanej przez system
Aby dowiedzieć się więcej o tożsamościach zarządzanych przypisanych przez system dla zasobów platformy Azure, zobacz tożsamość zarządzana przypisana przez system dla zasobów platformy Azure.
Aby użyć uwierzytelniania tożsamości zarządzanej przypisanej przez system, wykonaj następujące kroki, aby udzielić uprawnień:
Pobierz informacje o tożsamości zarządzanej, kopiując wartość identyfikatora obiektu tożsamości zarządzanej wygenerowanego wraz z fabryką danych lub obszarem roboczym usługi Synapse.
Przyznaj tożsamości zarządzanej prawidłowe uprawnienia w usłudze Azure Databricks. Ogólnie rzecz biorąc, musisz przyznać co najmniej rolę Współautor tożsamości zarządzanej przypisanej przez system w kontroli dostępu (IAM) usługi Azure Databricks.
Następujące właściwości są obsługiwane w przypadku połączonej usługi Azure Databricks Delta Lake:
| Właściwości | Opis | Wymagania |
|---|---|---|
| type | Właściwość type musi być ustawiona na AzureDatabricksDeltaLake. | Tak |
| domena | Określ adres URL obszaru roboczego usługi Azure Databricks, np. https://adb-xxxxxxxxx.xx.azuredatabricks.net. |
Tak |
| clusterId | Określ identyfikator klastra istniejącego klastra. Powinien on być już utworzonym klastrem interaktywnym. Identyfikator klastra interaktywnego klastra można znaleźć w obszarze roboczym usługi Databricks —> Klastry — nazwa klastra interakcyjnego —>> konfiguracja —> tagi. Dowiedz się więcej. |
Tak |
| workspaceResourceId | Określ identyfikator zasobu obszaru roboczego usługi Azure Databricks. | Tak |
| connectVia | Środowisko Integration Runtime używane do nawiązywania połączenia z magazynem danych. Możesz użyć środowiska Azure Integration Runtime lub własnego środowiska Integration Runtime (jeśli magazyn danych znajduje się w sieci prywatnej). Jeśli nie zostanie określony, używa domyślnego środowiska Azure Integration Runtime. | Nie. |
Przykład:
{
"name": "AzureDatabricksDeltaLakeLinkedService",
"properties": {
"type": "AzureDatabricksDeltaLake",
"typeProperties": {
"domain": "https://adb-xxxxxxxxx.xx.azuredatabricks.net",
"clusterId": "<cluster id>",
"workspaceResourceId": "<workspace resource id>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Uwierzytelnianie tożsamości zarządzanej przypisanej przez użytkownika
Aby dowiedzieć się więcej o tożsamościach zarządzanych przypisanych przez użytkownika dla zasobów platformy Azure, zobacz tożsamości zarządzane przypisane przez użytkownika
Aby użyć uwierzytelniania tożsamości zarządzanej przypisanej przez użytkownika, wykonaj następujące kroki:
Utwórz jedną lub wiele tożsamości zarządzanych przypisanych przez użytkownika i przyznaj uprawnienie w usłudze Azure Databricks. Ogólnie rzecz biorąc, musisz przyznać co najmniej rolę Współautor tożsamości zarządzanej przypisanej przez użytkownika w kontroli dostępu (IAM) usługi Azure Databricks.
Przypisz jedną lub wiele tożsamości zarządzanych przypisanych przez użytkownika do fabryki danych lub obszaru roboczego usługi Synapse i utwórz poświadczenia dla każdej tożsamości zarządzanej przypisanej przez użytkownika.
Następujące właściwości są obsługiwane w przypadku połączonej usługi Azure Databricks Delta Lake:
| Właściwości | Opis | Wymagania |
|---|---|---|
| type | Właściwość type musi być ustawiona na AzureDatabricksDeltaLake. | Tak |
| domena | Określ adres URL obszaru roboczego usługi Azure Databricks, np. https://adb-xxxxxxxxx.xx.azuredatabricks.net. |
Tak |
| clusterId | Określ identyfikator klastra istniejącego klastra. Powinien on być już utworzonym klastrem interaktywnym. Identyfikator klastra interaktywnego klastra można znaleźć w obszarze roboczym usługi Databricks —> Klastry — nazwa klastra interakcyjnego —>> konfiguracja —> tagi. Dowiedz się więcej. |
Tak |
| poświadczenia | Określ tożsamość zarządzaną przypisaną przez użytkownika jako obiekt poświadczeń. | Tak |
| workspaceResourceId | Określ identyfikator zasobu obszaru roboczego usługi Azure Databricks. | Tak |
| connectVia | Środowisko Integration Runtime używane do nawiązywania połączenia z magazynem danych. Możesz użyć środowiska Azure Integration Runtime lub własnego środowiska Integration Runtime (jeśli magazyn danych znajduje się w sieci prywatnej). Jeśli nie zostanie określony, używa domyślnego środowiska Azure Integration Runtime. | Nie. |
Przykład:
{
"name": "AzureDatabricksDeltaLakeLinkedService",
"properties": {
"type": "AzureDatabricksDeltaLake",
"typeProperties": {
"domain": "https://adb-xxxxxxxxx.xx.azuredatabricks.net",
"clusterId": "<cluster id>",
"credential": {
"referenceName": "credential1",
"type": "CredentialReference"
},
"workspaceResourceId": "<workspace resource id>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Właściwości zestawu danych
Aby uzyskać pełną listę sekcji i właściwości dostępnych do definiowania zestawów danych, zobacz artykuł Zestawy danych.
Następujące właściwości są obsługiwane w przypadku zestawu danych usługi Delta Lake usługi Azure Databricks.
| Właściwości | Opis | Wymagania |
|---|---|---|
| type | Właściwość type zestawu danych musi być ustawiona na Wartość AzureDatabricksDeltaLakeDataset. | Tak |
| database | Nazwa bazy danych. | Nie dla źródła, tak dla ujścia |
| table | Nazwa tabeli delty. | Nie dla źródła, tak dla ujścia |
Przykład:
{
"name": "AzureDatabricksDeltaLakeDataset",
"properties": {
"type": "AzureDatabricksDeltaLakeDataset",
"typeProperties": {
"database": "<database name>",
"table": "<delta table name>"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"linkedServiceName": {
"referenceName": "<name of linked service>",
"type": "LinkedServiceReference"
}
}
}
Właściwości działania kopiowania
Aby uzyskać pełną listę sekcji i właściwości dostępnych do definiowania działań, zobacz artykuł Pipelines (Potoki ). Ta sekcja zawiera listę właściwości obsługiwanych przez źródło i ujście usługi Delta Lake usługi Azure Databricks.
Usługa Delta Lake jako źródło
Aby skopiować dane z usługi Azure Databricks Delta Lake, w sekcji źródła działanie Kopiuj są obsługiwane następujące właściwości.
| Właściwości | Opis | Wymagania |
|---|---|---|
| type | Właściwość type źródła działanie Kopiuj musi być ustawiona na Wartość AzureDatabricksDeltaLakeSource. | Tak |
| zapytanie | Określ zapytanie SQL do odczytu danych. W przypadku kontrolki podróży czasowej postępuj zgodnie z poniższym wzorcem: - SELECT * FROM events TIMESTAMP AS OF timestamp_expression- SELECT * FROM events VERSION AS OF version |
Nie. |
| exportSettings | Ustawienia zaawansowane używane do pobierania danych z tabeli delty. | Nie. |
W obszarze exportSettings: |
||
| type | Typ polecenia eksportu ustaw wartość AzureDatabricksDeltaLakeExportCommand. | Tak |
| dateFormat | Formatuj typ daty na ciąg w formacie daty. Niestandardowe formaty dat są zgodne ze wzorcem daty/godziny. Jeśli nie zostanie określony, używa wartości yyyy-MM-dddomyślnej . |
Nie. |
| timestampFormat | Formatuj typ znacznika czasu na ciąg w formacie znacznika czasu. Niestandardowe formaty dat są zgodne ze wzorcem daty/godziny. Jeśli nie zostanie określony, używa wartości yyyy-MM-dd'T'HH:mm:ss[.SSS][XXX]domyślnej . |
Nie. |
Bezpośrednie kopiowanie z usługi delta lake
Jeśli magazyn danych ujścia i format spełniają kryteria opisane w tej sekcji, możesz użyć działanie Kopiuj, aby bezpośrednio skopiować tabelę delty usługi Azure Databricks do ujścia. Usługa sprawdza ustawienia i kończy się niepowodzeniem działania działanie Kopiuj, jeśli nie zostały spełnione następujące kryteria:
Połączona usługa ujścia to Azure Blob Storage lub Azure Data Lake Storage Gen2. Poświadczenia konta powinny być wstępnie skonfigurowane w konfiguracji klastra usługi Azure Databricks. Dowiedz się więcej na stronie Wymagania wstępne.
Format danych ujścia to Parquet, tekst rozdzielany lub Avro z następującymi konfiguracjami i wskazuje folder zamiast pliku.
- W przypadku formatu Parquet koder kompresji to brak, snappy lub gzip.
- W przypadku formatu tekstu rozdzielanego:
-
rowDelimiterjest dowolnym pojedynczym znakiem. -
compressionmoże to być brak, bzip2, gzip. -
encodingNameUtF-7 nie jest obsługiwany.
-
- W przypadku formatu Avro koder kompresji to brak, deflate lub snappy.
W źródle
additionalColumnsdziałanie Kopiuj nie określono.Jeśli kopiowanie danych do tekstu rozdzielanego, w ujściu
fileExtensiondziałania kopiowania musi być ".csv".W mapowaniu działanie Kopiuj konwersja typów nie jest włączona.
Przykład:
"activities":[
{
"name": "CopyFromDeltaLake",
"type": "Copy",
"inputs": [
{
"referenceName": "<Delta lake input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AzureDatabricksDeltaLakeSource",
"sqlReaderQuery": "SELECT * FROM events TIMESTAMP AS OF timestamp_expression"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Kopiowanie etapowe z usługi delta lake
Jeśli magazyn danych ujścia lub format nie są zgodne z kryteriami kopiowania bezpośredniego, jak wspomniano w ostatniej sekcji, włącz wbudowaną kopię etapową przy użyciu tymczasowego wystąpienia usługi Azure Storage. Funkcja kopiowania etapowego zapewnia również lepszą przepływność. Usługa eksportuje dane z usługi Azure Databricks Delta Lake do magazynu przejściowego, a następnie kopiuje dane do ujścia, a na koniec czyści dane tymczasowe z magazynu przejściowego. Zobacz Kopiowanie etapowe, aby uzyskać szczegółowe informacje na temat kopiowania danych przy użyciu przemieszczania.
Aby użyć tej funkcji, utwórz połączoną usługę Azure Blob Storage lub połączoną usługę Azure Data Lake Storage Gen2, która odwołuje się do konta magazynu jako tymczasowego przemieszczania. Następnie określ enableStaging właściwości i stagingSettings w działanie Kopiuj.
Uwaga
Poświadczenia przejściowego konta magazynu powinny być wstępnie skonfigurowane w konfiguracji klastra usługi Azure Databricks. Dowiedz się więcej na temat wymagań wstępnych.
Przykład:
"activities":[
{
"name": "CopyFromDeltaLake",
"type": "Copy",
"inputs": [
{
"referenceName": "<Delta lake input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AzureDatabricksDeltaLakeSource",
"sqlReaderQuery": "SELECT * FROM events TIMESTAMP AS OF timestamp_expression"
},
"sink": {
"type": "<sink type>"
},
"enableStaging": true,
"stagingSettings": {
"linkedServiceName": {
"referenceName": "MyStagingStorage",
"type": "LinkedServiceReference"
},
"path": "mystagingpath"
}
}
}
]
Delta lake jako ujście
Aby skopiować dane do usługi Azure Databricks Delta Lake, następujące właściwości są obsługiwane w sekcji ujścia działanie Kopiuj.
| Właściwości | Opis | Wymagania |
|---|---|---|
| type | Właściwość type ujścia działanie Kopiuj ustawiona na AzureDatabricksDeltaLakeSink. | Tak |
| preCopyScript | Określ zapytanie SQL dla działanie Kopiuj do uruchomienia przed zapisaniem danych w tabeli różnicowej usługi Databricks w każdym przebiegu. Przykład: VACUUM eventsTable DRY RUN za pomocą tej właściwości można wyczyścić wstępnie załadowane dane lub dodać tabelę obciętą lub instrukcję Vacuum. |
Nie. |
| importSettings | Ustawienia zaawansowane używane do zapisywania danych w tabeli delty. | Nie. |
W obszarze importSettings: |
||
| type | Typ polecenia importu ustaw wartość AzureDatabricksDeltaLakeImportCommand. | Tak |
| dateFormat | Formatuj ciąg na typ daty w formacie daty. Niestandardowe formaty dat są zgodne ze wzorcem daty/godziny. Jeśli nie zostanie określony, używa wartości yyyy-MM-dddomyślnej . |
Nie. |
| timestampFormat | Formatuj ciąg do typu znacznika czasu z formatem znacznika czasu. Niestandardowe formaty dat są zgodne ze wzorcem daty/godziny. Jeśli nie zostanie określony, używa wartości yyyy-MM-dd'T'HH:mm:ss[.SSS][XXX]domyślnej . |
Nie. |
Bezpośrednie kopiowanie do usługi delta lake
Jeśli źródłowy magazyn danych i format spełniają kryteria opisane w tej sekcji, możesz użyć działanie Kopiuj, aby bezpośrednio skopiować ze źródła do usługi Azure Databricks Delta Lake. Usługa sprawdza ustawienia i kończy się niepowodzeniem działania działanie Kopiuj, jeśli nie zostały spełnione następujące kryteria:
Źródłowa połączona usługa to Azure Blob Storage lub Azure Data Lake Storage Gen2. Poświadczenia konta powinny być wstępnie skonfigurowane w konfiguracji klastra usługi Azure Databricks. Dowiedz się więcej na stronie Wymagania wstępne.
Format danych źródłowych to Parquet, tekst rozdzielany lub Avro z następującymi konfiguracjami i wskazuje folder zamiast pliku.
- W przypadku formatu Parquet koder kompresji to brak, snappy lub gzip.
- W przypadku formatu tekstu rozdzielanego:
-
rowDelimiterwartość domyślna lub dowolny pojedynczy znak. -
compressionmoże to być brak, bzip2, gzip. -
encodingNameUtF-7 nie jest obsługiwany.
-
- W przypadku formatu Avro koder kompresji to brak, deflate lub snappy.
W źródle działanie Kopiuj:
-
wildcardFileNamezawiera tylko symbol wieloznaczny*, ale nie?, iwildcardFolderNamenie jest określony. -
prefix, ,modifiedDateTimeStartmodifiedDateTimeEndienablePartitionDiscoverynie są określone. -
additionalColumnsnie jest określony.
-
W mapowaniu działanie Kopiuj konwersja typów nie jest włączona.
Przykład:
"activities":[
{
"name": "CopyToDeltaLake",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Delta lake output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "AzureDatabricksDeltaLakeSink",
"sqlReaderQuery": "VACUUM eventsTable DRY RUN"
}
}
}
]
Kopiowanie etapowe do usługi delta lake
Jeśli źródłowy magazyn danych lub format nie są zgodne z kryteriami kopiowania bezpośredniego, jak wspomniano w ostatniej sekcji, włącz wbudowaną kopię etapową przy użyciu tymczasowego wystąpienia usługi Azure Storage. Funkcja kopiowania etapowego zapewnia również lepszą przepływność. Usługa automatycznie konwertuje dane w celu spełnienia wymagań dotyczących formatu danych na magazyn przejściowy, a następnie ładuje dane do usługi delta lake z tego miejsca. Na koniec czyści dane tymczasowe z magazynu. Zobacz Kopiowanie etapowe, aby uzyskać szczegółowe informacje na temat kopiowania danych przy użyciu przemieszczania.
Aby użyć tej funkcji, utwórz połączoną usługę Azure Blob Storage lub połączoną usługę Azure Data Lake Storage Gen2, która odwołuje się do konta magazynu jako tymczasowego przemieszczania. Następnie określ enableStaging właściwości i stagingSettings w działanie Kopiuj.
Uwaga
Poświadczenia przejściowego konta magazynu powinny być wstępnie skonfigurowane w konfiguracji klastra usługi Azure Databricks. Dowiedz się więcej na temat wymagań wstępnych.
Przykład:
"activities":[
{
"name": "CopyToDeltaLake",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Delta lake output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "AzureDatabricksDeltaLakeSink"
},
"enableStaging": true,
"stagingSettings": {
"linkedServiceName": {
"referenceName": "MyStagingBlob",
"type": "LinkedServiceReference"
},
"path": "mystagingpath"
}
}
}
]
Monitorowanie
To samo środowisko monitorowania działania kopiowania jest udostępniane w przypadku innych łączników. Ponadto, ponieważ ładowanie danych z/do usługi delta lake jest uruchomione w klastrze usługi Azure Databricks, możesz dokładniej wyświetlić szczegółowe dzienniki klastra i monitorować wydajność.
Właściwości działania wyszukiwania
Aby uzyskać więcej informacji na temat właściwości, zobacz Działanie wyszukiwania.
Działanie Lookup może zwrócić maksymalnie 1000 wierszy. Jeśli zestaw wyników zawiera więcej rekordów, zostanie zwróconych pierwszych 1000 wierszy.
Powiązana zawartość
Aby uzyskać listę magazynów danych obsługiwanych jako źródła i ujścia według działanie Kopiuj, zobacz obsługiwane magazyny danych i formaty.