Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
DOTYCZY: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Wskazówka
Wypróbuj usługę Data Factory w usłudze Microsoft Fabric — rozwiązanie analityczne typu all-in-one dla przedsiębiorstw. Usługa Microsoft Fabric obejmuje wszystko, od przenoszenia danych do nauki o danych, analizy w czasie rzeczywistym, analizy biznesowej i raportowania. Dowiedz się, jak bezpłatnie rozpocząć nową wersję próbną !
W tym artykule opisano sposób użycia działania kopiowania w potoku usługi Azure Data Factory lub Synapse Analytics w celu skopiowania danych z bazy danych Cassandra. Opiera się na artykule przeglądowym dotyczącym działań kopiowania, który przedstawia ogólne informacje na temat tych działań.
Ważne
Łącznik Cassandra w wersji 2.0 zapewnia ulepszoną natywną obsługę systemu Cassandra. Jeśli używasz łącznika Cassandra w wersji 1.0 w rozwiązaniu, uaktualnij łącznik Cassandra przed 31 lipca 2025 r. Zapoznaj się z tą sekcją , aby uzyskać szczegółowe informacje na temat różnic między wersją 2.0 a wersją 1.0.
Obsługiwane możliwości
Ten łącznik Cassandra jest obsługiwany dla następujących funkcjonalności:
| Obsługiwane możliwości | IR |
|---|---|
| działanie kopiowania (źródło/-) | (1) (2) |
| Działanie Wyszukiwania | (1) (2) |
(1) Środowisko uruchomieniowe integracji Azure (2) Lokalne środowisko uruchomieniowe integracji
Aby uzyskać listę magazynów danych obsługiwanych jako źródła/ujścia, zobacz tabelę Obsługiwane magazyny danych.
W szczególności ten łącznik Cassandra obsługuje następujące funkcje:
- System Cassandra w wersji 3.x.x i 4.x.x dla wersji 2.0.
- System Cassandra w wersji 2.x i 3.x dla wersji 1.0.
- Kopiowanie danych przy użyciu uwierzytelniania podstawowego lub anonimowego .
Uwaga
W przypadku operacji uruchamianych w środowisku Integration Runtime hostowanym samodzielnie, system Cassandra 3.x jest obsługiwany od wersji 3.7 środowiska IR lub nowszej.
Wymagania wstępne
Jeśli magazyn danych znajduje się wewnątrz sieci lokalnej, sieci wirtualnej platformy Azure lub Amazon Virtual Private Cloud, musisz skonfigurować samodzielnie hostowane środowisko Integration Runtime, aby się z nim połączyć.
Jeśli magazyn danych jest zarządzaną usługą danych w chmurze, możesz użyć środowiska Azure Integration Runtime. Jeśli dostęp jest ograniczony do adresów IP zatwierdzonych w regułach zapory, możesz dodać adresy IP środowiska Azure Integration Runtime do listy dozwolonych.
Możesz również użyć funkcji zarządzanego środowiska uruchomieniowego integracji w sieci wirtualnej w usłudze Azure Data Factory, aby uzyskać dostęp do sieci lokalnej bez instalowania i konfigurowania lokalnie uruchamianego środowiska integracji.
Aby uzyskać więcej informacji na temat mechanizmów zabezpieczeń sieci i opcji obsługiwanych przez usługę Data Factory, zobacz Strategie dostępu do danych.
Środowisko Integration Runtime udostępnia wbudowany sterownik Cassandra, dlatego nie trzeba ręcznie instalować żadnego sterownika podczas kopiowania danych z/do rozwiązania Cassandra.
Wprowadzenie
Aby wykonać operację kopiowania za pomocą pipeline'u, możesz użyć jednego z następujących narzędzi lub zestawów SDK.
- Narzędzie do kopiowania danych
- Portal Azure
- SDK .NET
- Zestaw SDK języka Python
- Azure PowerShell
- API REST
- Szablon usługi Azure Resource Manager
Tworzenie połączonej usługi z usługą Cassandra przy użyciu interfejsu użytkownika
Wykonaj poniższe kroki, aby utworzyć połączoną usługę z usługą Cassandra w interfejsie użytkownika witryny Azure Portal.
Przejdź do karty Zarządzanie w obszarze roboczym usługi Azure Data Factory lub Synapse i wybierz pozycję Połączone usługi, a następnie kliknij pozycję Nowy:
Wyszukaj Cassandrę i wybierz łącznik Cassandra.
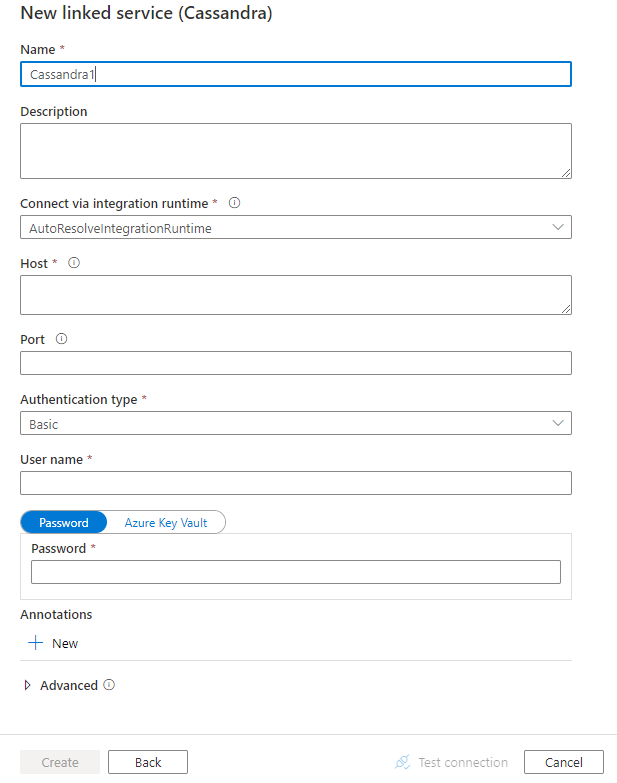
Skonfiguruj szczegóły usługi, przetestuj połączenie i utwórz nową połączoną usługę.
Szczegóły konfiguracji łącznika
Poniższe sekcje zawierają szczegółowe informacje o właściwościach używanych do definiowania jednostek usługi Data Factory specyficznych dla łącznika Cassandra.
Właściwości połączonej usługi
Następujące właściwości są obsługiwane dla połączonej usługi Cassandra:
| Nieruchomość | Opis | Wymagane |
|---|---|---|
| rodzaj | Właściwość type musi być ustawiona na: Cassandra | Tak |
| wersja | Wersja, którą określisz. | Tak dla wersji 2.0. |
| gospodarz | Co najmniej jeden adres IP lub nazwy hostów serwerów Cassandra. Określ rozdzielaną przecinkami listę adresów IP lub nazw hostów, aby łączyć się ze wszystkimi serwerami jednocześnie. |
Tak |
| port | Port TCP używany przez serwer Cassandra do nasłuchiwania połączeń klienckich. | Nie (wartość domyślna to 9042) |
| typUwierzytelnienia | Typ uwierzytelniania używanego do nawiązywania połączenia z bazą danych Cassandra. Dozwolone wartości to: Podstawowa i Anonimowa. |
Tak |
| nazwa użytkownika | Określ nazwę użytkownika dla konta użytkownika. | Tak, jeśli wartość authenticationType jest ustawiona na Wartość Podstawowa. |
| hasło | Określ hasło dla konta użytkownika. Oznacz to pole jako element SecureString w celu bezpiecznego przechowywania go lub odwołuj się do wpisu tajnego przechowywanego w usłudze Azure Key Vault. | Tak, jeśli wartość authenticationType jest ustawiona na Wartość Podstawowa. |
| connectVia | Środowisko Integration Runtime używane do połączenia z repozytorium danych. Dowiedz się więcej w sekcji Wymagania wstępne . Jeśli nie zostanie określony, używa domyślnego środowiska Azure Integration Runtime. | Nie. |
Uwaga
Obecnie połączenie z rozwiązaniem Cassandra przy użyciu protokołu TLS nie jest obsługiwane.
Przykład: wersja 2.0
{
"name": "CassandraLinkedService",
"properties": {
"type": "Cassandra",
"version": "2.0",
"typeProperties": {
"host": "<host>",
"authenticationType": "Basic",
"username": "<username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Przykład: wersja 1.0
{
"name": "CassandraLinkedService",
"properties": {
"type": "Cassandra",
"typeProperties": {
"host": "<host>",
"authenticationType": "Basic",
"username": "<username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Właściwości zestawu danych
Pełna lista sekcji i właściwości dostępnych do definiowania zestawów danych znajduje się w artykule dotyczącym zestawów danych. Ta sekcja zawiera listę właściwości obsługiwanych przez zestaw danych Cassandra.
Aby skopiować dane z bazy danych Cassandra, ustaw właściwość type zestawu danych na CassandraTable. Obsługiwane są następujące właściwości:
| Nieruchomość | Opis | Wymagane |
|---|---|---|
| rodzaj | Właściwość type zestawu danych musi być ustawiona na: CassandraTable | Tak |
| przestrzeń kluczowa | Nazwa przestrzeni kluczy lub schematu w bazie danych Cassandra. | Nie (jeśli określono "zapytanie" dla elementu "CassandraSource") |
| nazwaTabeli | Nazwa tabeli w bazie danych Cassandra. | Nie (jeśli określono "zapytanie" dla elementu "CassandraSource") |
Przykład:
{
"name": "CassandraDataset",
"properties": {
"type": "CassandraTable",
"typeProperties": {
"keySpace": "<keyspace name>",
"tableName": "<table name>"
},
"schema": [],
"linkedServiceName": {
"referenceName": "<Cassandra linked service name>",
"type": "LinkedServiceReference"
}
}
}
Właściwości działania kopiowania
Aby uzyskać pełną listę sekcji i właściwości dostępnych do definiowania działań, zobacz artykuł Pipelines. Ta sekcja zawiera listę właściwości obsługiwanych przez źródło Cassandra.
Cassandra jako źródło
Jeśli używasz wersji 2.0 do kopiowania danych z bazy danych Cassandra, ustaw typ źródła w działaniu kopiowania na cassandraSource. Następujące właściwości są obsługiwane w sekcji źródło działania kopiowania:
| Nieruchomość | Opis | Wymagane |
|---|---|---|
| rodzaj | Właściwość type źródła działania kopiowania musi być ustawiona na: CassandraSource | Tak |
| zapytanie | Użyj zapytania niestandardowego, aby odczytać dane. Zapytanie CQL, zobacz Dokumentację języka CQL. | Jeśli w zestawie danych określono "tableName" i "keyspace", to nie. |
| poziom spójności | Poziom spójności określa, ile replik musi odpowiadać na żądanie odczytu przed zwróceniem danych do aplikacji klienckiej. System Cassandra sprawdza określoną liczbę replik dla danych w celu spełnienia żądania odczytu. Aby uzyskać szczegółowe informacje, zobacz Konfigurowanie spójności danych. Dozwolone wartości to: JEDEN, DWA, TRZY, KWORUM, WSZYSTKIE, LOCAL_QUORUM, EACH_QUORUM i LOCAL_ONE. |
Nie (wartość domyślna to ONE) |
Przykład:
"activities":[
{
"name": "CopyFromCassandra",
"type": "Copy",
"inputs": [
{
"referenceName": "<Cassandra input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "CassandraSource",
"query": "select id, firstname, lastname from mykeyspace.mytable",
"consistencyLevel": "one"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Jeśli używasz wersji 1.0 do kopiowania danych z bazy danych Cassandra, ustaw typ źródła w działaniu kopiowania na cassandraSource. Następujące właściwości są obsługiwane w sekcji źródło działania kopiowania:
| Nieruchomość | Opis | Wymagane |
|---|---|---|
| rodzaj | Właściwość type źródła działania kopiowania musi być ustawiona na: CassandraSource | Tak |
| zapytanie | Użyj zapytania niestandardowego, aby odczytać dane. Zapytanie SQL-92 lub zapytanie CQL. Zobacz dokumentację języka CQL. Podczas korzystania z zapytania SQL określ nazwa_przestrzeni_kluczy.nazwa_tabeli, aby odnieść się do tabeli, którą chcesz zapytać. |
Jeśli w zestawie danych określono "tableName" i "keyspace", to nie. |
| poziom spójności | Poziom spójności określa, ile replik musi odpowiadać na żądanie odczytu przed zwróceniem danych do aplikacji klienckiej. System Cassandra sprawdza określoną liczbę replik dla danych w celu spełnienia żądania odczytu. Aby uzyskać szczegółowe informacje, zobacz Konfigurowanie spójności danych. Dozwolone wartości to: JEDEN, DWA, TRZY, KWORUM, WSZYSTKIE, LOCAL_QUORUM, EACH_QUORUM i LOCAL_ONE. |
Nie (wartość domyślna to ONE) |
Mapowanie typów danych dla bazy danych Cassandra
Podczas kopiowania danych z bazy danych Cassandra następujące mapowania są używane z typów danych Cassandra do tymczasowych typów danych używanych wewnętrznie w usłudze. Zobacz Mapowania schematu i typu danych, aby dowiedzieć się, jak działanie kopiowania mapuje schemat źródłowy i typ danych na miejsce docelowe.
| Typ danych Cassandra | Typ danych usługi tymczasowej (wersja 2.0) | Typ danych usługi tymczasowej (wersja 1.0) |
|---|---|---|
| ASCII | Sznurek | Sznurek |
| BIGINT | Int64 | Int64 |
| BLOB (Baza Danych Obiektów Binarowych) | Bajt[] | Bajt[] |
| BOOLOWSKI | Boolowski | Boolowski |
| DATA | Data i Czas | Data i Czas |
| DZIESIĘTNA | Liczba dziesiętna | Liczba dziesiętna |
| Podwójny | Podwójny | Podwójny |
| PŁYWAĆ | Singiel | Singiel |
| ZESTAW INET | Sznurek | Sznurek |
| INT | Int32 | Int32 |
| SMALLINT | Krótki | Int16 |
| TEKST | Sznurek | Sznurek |
| SYGNATURA CZASOWA | Data i Czas | Data i Czas |
| IDENTYFIKATOR TIMEUUID | Przewodnik | Przewodnik |
| TINYINT | SByte | Int16 |
| Identyfikator UUID | Przewodnik | Przewodnik |
| VARCHAR | Sznurek | Sznurek |
| VARINT | Liczba dziesiętna | Liczba dziesiętna |
Uwaga
W przypadku typów kolekcji (map, set, list itp.) w wersji 1.0 zapoznaj się z sekcją „Praca z typami kolekcji Cassandra przy użyciu tabeli wirtualnej w wersji 1.0”.
Typy zdefiniowane przez użytkownika nie są obsługiwane.
Długości kolumny binarnej i kolumny ciągu nie mogą być większe niż 4000.
Praca z kolekcjami w przypadku korzystania z wersji 2.0
W przypadku używania wersji 2.0 do kopiowania danych z bazy danych Cassandra nie są tworzone żadne tabele wirtualne dla typów kolekcji. Tabelę źródłową można skopiować do ujścia w oryginalnym typie w formacie JSON.
Przykład
Na przykład następująca tabela "ExampleTable" to tabela bazy danych Cassandra zawierająca kolumnę klucza podstawowego o nazwie "pk_int", kolumnę tekstową o nazwie value, kolumnę listy, kolumnę mapy i kolumnę zestawu (o nazwie "StringSet").
| pk_int | Wartość | Lista | Mapa | Zestaw Łańcuchów |
|---|---|---|---|---|
| 1 | "przykładowa wartość 1" | ["1", "2", "3"] | {"S1": "a", "S2": "b"} | {"A", "B", "C"} |
| 3 | "przykładowa wartość 3" | ["100", "101", "102", "105"] | {"S1": "t"} | {"A", "E"} |
Dane mogą być odczytywane bezpośrednio z tabeli źródłowej, a wartości kolumn są zachowywane w ich oryginalnych typach w formacie JSON, jak pokazano w poniższej tabeli:
| pk_int | Wartość | Lista | Mapa | Zestaw Łańcuchów |
|---|---|---|---|---|
| 1 | "przykładowa wartość 1" | ["1", "2", "3"] | {"S1": "a", "S2": "b"} | ["A", "B", "C"] |
| 3 | "przykładowa wartość 3" | ["100", "101", "102", "105"] | {"S1": "t"} | ["A", "E"] |
Praca z kolekcjami przy użyciu tabeli wirtualnej w przypadku korzystania z wersji 1.0
Usługa używa wbudowanego sterownika ODBC do nawiązywania połączenia i kopiowania danych z bazy danych Cassandra. Dla typów kolekcji, takich jak mapa, zbiór i lista, sterownik renormalizuje dane w odpowiednich tabelach wirtualnych. W szczególności jeśli tabela zawiera jakiekolwiek kolumny kolekcji, sterownik generuje następujące tabele wirtualne:
- Tabela podstawowa zawierająca te same dane co rzeczywista tabela z wyjątkiem kolumn kolekcji. Tabela podstawowa używa takiej samej nazwy jak rzeczywista tabela, którą reprezentuje.
- Dla każdej kolumny kolekcji istnieje tabela wirtualna, która rozszerza zagnieżdżone dane. Tabele wirtualne reprezentujące kolekcje mają nazwę przy użyciu nazwy rzeczywistej tabeli, separatora "vt" i nazwy kolumny.
Tabele wirtualne odwołują się do danych w rzeczywistej tabeli, umożliwiając sterownikowi dostęp do danych, które nie są znormalizowane. Aby uzyskać szczegółowe informacje, zobacz sekcję Przykład. Dostęp do zawartości kolekcji Cassandra można uzyskać, wykonując zapytania i łącząc tabele wirtualne.
Przykład
Na przykład następująca tabela "ExampleTable" to tabela bazy danych Cassandra zawierająca kolumnę klucza podstawowego o nazwie "pk_int", kolumnę tekstową o nazwie value, kolumnę listy, kolumnę mapy i kolumnę zestawu (o nazwie "StringSet").
| pk_int | Wartość | Lista | Mapa | Zestaw Łańcuchów |
|---|---|---|---|---|
| 1 | "przykładowa wartość 1" | ["1", "2", "3"] | {"S1": "a", "S2": "b"} | {"A", "B", "C"} |
| 3 | "przykładowa wartość 3" | ["100", "101", "102", "105"] | {"S1": "t"} | {"A", "E"} |
Sterownik wygenerowałby wiele tabel wirtualnych reprezentujących tę pojedynczą tabelę. Kolumny klucza obcego w tabelach wirtualnych odwołują się do kolumn klucza podstawowego w rzeczywistej tabeli i wskazują, który rzeczywisty wiersz tabeli odpowiada wierszowi tabeli wirtualnej.
Pierwsza tabela wirtualna to tabela podstawowa o nazwie "ExampleTable" pokazana w poniższej tabeli:
| pk_int | Wartość |
|---|---|
| 1 | "przykładowa wartość 1" |
| 3 | "przykładowa wartość 3" |
Tabela podstawowa zawiera te same dane co oryginalna tabela bazy danych z wyjątkiem kolekcji, które zostały pominięte z tej tabeli i rozwinięte w innych tabelach wirtualnych.
W poniższych tabelach przedstawiono tabele wirtualne, które renormalizują dane z kolumn List, Map i StringSet. Kolumny z nazwami kończącymi się ciągiem "_index" lub "_key" wskazują położenie danych na oryginalnej liście lub mapie. Kolumny z nazwami, które kończą się na "_value," zawierają w sobie rozwinięte dane z kolekcji.
Tabela „ExampleTable_vt_List”:
| pk_int | Lista_indeks | Wartość_listy |
|---|---|---|
| 1 | 0 | 1 |
| 1 | 1 | 2 |
| 1 | 2 | 3 |
| 3 | 0 | 100 |
| 3 | 1 | 101 |
| 3 | 2 | 102 |
| 3 | 3 | 103 |
Tabela "ExampleTable_vt_Map":
| pk_int | Klucz_mapy | Wartość mapy |
|---|---|---|
| 1 | S1 | A |
| 1 | S2 | b |
| 3 | S1 | t |
Tabela "ExampleTable_vt_StringSet":
| pk_int | ZbiórStringów_wartość |
|---|---|
| 1 | A |
| 1 | B |
| 1 | C |
| 3 | A |
| 3 | E |
Właściwości czynności wyszukiwania
Aby poznać szczegóły dotyczące właściwości, sprawdź Aktywność wyszukiwania.
Uaktualnianie łącznika Cassandra
Poniżej przedstawiono kroki ułatwiające uaktualnienie łącznika Cassandra:
Na stronie Edytowanie połączonej usługi wybierz wersję 2.0 i skonfiguruj połączoną usługę, odwołując się do właściwości połączonej usługi.
W wersji 2.0 źródło operacji kopiowania
queryobsługuje tylko zapytania CQL, a nie zapytania SQL-92. Aby uzyskać więcej informacji, zobacz Cassandra jako źródło.Mapowanie typu danych dla wersji 2.0 różni się od tego w wersji 1.0. Aby dowiedzieć się więcej na temat najnowszego mapowania typów danych, zobacz Mapowanie typów danych dla bazy danych Cassandra.
Różnice między wersją Cassandra w wersji 2.0 a wersją 1.0
Łącznik Cassandra w wersji 2.0 oferuje nowe funkcje i jest zgodny z większością funkcji wersji 1.0. W poniższej tabeli przedstawiono różnice funkcji między wersją 2.0 a wersją 1.0.
| Wersja 2.0 | Wersja 1.0 |
|---|---|
| Obsługa zapytania CQL. | Obsługa zapytania SQL-92 lub zapytania CQL. |
Obsługa określania keyspace i tableName oddzielnie w zestawie danych. |
Obsługa edycji keyspace podczas wybierania opcji ręcznego wprowadzania nazwy tabeli w zestawie danych. |
| Dla typów kolekcji nie są tworzone żadne tabele wirtualne. Aby uzyskać więcej informacji, zobacz Praca z kolekcjami w przypadku korzystania z wersji 2.0. | Tabele wirtualne są tworzone dla typów kolekcji. Aby uzyskać więcej informacji, zobacz Praca z typami kolekcji Cassandra przy użyciu tabeli wirtualnej w przypadku korzystania z wersji 1.0. |
| Następujące mapowania są używane z typów danych Cassandra do tymczasowego typu danych usługi. SMALLINT —> krótki TINYINT —> SByte |
Następujące mapowania są używane z typów danych Cassandra do tymczasowego typu danych usługi. SMALLINT —> Int16 TINYINT — > Int16 |
Powiązana zawartość
Aby uzyskać listę magazynów danych obsługiwanych jako źródła i ujścia działania kopiowania, zobacz obsługiwane magazyny danych.