Kopiowanie danych z usługi Teradata Vantage przy użyciu usług Azure Data Factory i Synapse Analytics
DOTYCZY: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Napiwek
Wypróbuj usługę Data Factory w usłudze Microsoft Fabric — rozwiązanie analityczne typu all-in-one dla przedsiębiorstw. Usługa Microsoft Fabric obejmuje wszystko, od przenoszenia danych do nauki o danych, analizy w czasie rzeczywistym, analizy biznesowej i raportowania. Dowiedz się, jak bezpłatnie rozpocząć nową wersję próbną !
W tym artykule opisano sposób używania działania kopiowania w potokach usługi Azure Data Factory i usługi Synapse Analytics do kopiowania danych z usługi Teradata Vantage. Jest on oparty na omówieniu działania kopiowania.
Obsługiwane możliwości
Ten łącznik Teradata jest obsługiwany w przypadku następujących możliwości:
| Obsługiwane możliwości | IR |
|---|---|
| działanie Kopiuj (źródło/-) | ① ② |
| Działanie Lookup | ① ② |
(1) Środowisko Azure Integration Runtime (2) Self-hosted Integration Runtime
Aby uzyskać listę magazynów danych obsługiwanych jako źródła/ujścia przez działanie kopiowania, zobacz tabelę Obsługiwane magazyny danych.
W szczególności ten łącznik Teradata obsługuje:
- Teradata w wersji 14.10, 15.0, 15.10, 16.0, 16.10 i 16.20.
- Kopiowanie danych przy użyciu uwierzytelniania Podstawowego, Windows lub LDAP .
- Równoległe kopiowanie ze źródła teradata. Aby uzyskać szczegółowe informacje, zobacz sekcję Kopiowanie równoległe z usługi Teradata .
Wymagania wstępne
Jeśli magazyn danych znajduje się wewnątrz sieci lokalnej, sieci wirtualnej platformy Azure lub chmury prywatnej Amazon Virtual, musisz skonfigurować własne środowisko Integration Runtime , aby się z nim połączyć.
Jeśli magazyn danych jest zarządzaną usługą danych w chmurze, możesz użyć środowiska Azure Integration Runtime. Jeśli dostęp jest ograniczony do adresów IP zatwierdzonych w regułach zapory, możesz dodać adresy IP środowiska Azure Integration Runtime do listy dozwolonych.
Możesz również użyć funkcji środowiska Integration Runtime zarządzanej sieci wirtualnej w usłudze Azure Data Factory, aby uzyskać dostęp do sieci lokalnej bez instalowania i konfigurowania własnego środowiska Integration Runtime.
Aby uzyskać więcej informacji na temat mechanizmów zabezpieczeń sieci i opcji obsługiwanych przez usługę Data Factory, zobacz Strategie dostępu do danych.
Jeśli używasz własnego środowiska Integration Runtime, pamiętaj, że udostępnia wbudowany sterownik Teradata, począwszy od wersji 3.18. Nie trzeba ręcznie instalować żadnego sterownika. Sterownik wymaga "pakiet redystrybucyjny programu Visual C++ 2012 Update 4" na maszynie własnego środowiska Integration Runtime. Jeśli jeszcze go nie zainstalowano, pobierz go z tego miejsca.
Wprowadzenie
Aby wykonać działanie Kopiuj za pomocą potoku, możesz użyć jednego z następujących narzędzi lub zestawów SDK:
- Narzędzie do kopiowania danych
- Witryna Azure Portal
- Zestaw SDK platformy .NET
- Zestaw SDK języka Python
- Azure PowerShell
- Interfejs API REST
- Szablon usługi Azure Resource Manager
Tworzenie połączonej usługi z usługą Teradata przy użyciu interfejsu użytkownika
Wykonaj poniższe kroki, aby utworzyć połączoną usługę z usługą Teradata w interfejsie użytkownika witryny Azure Portal.
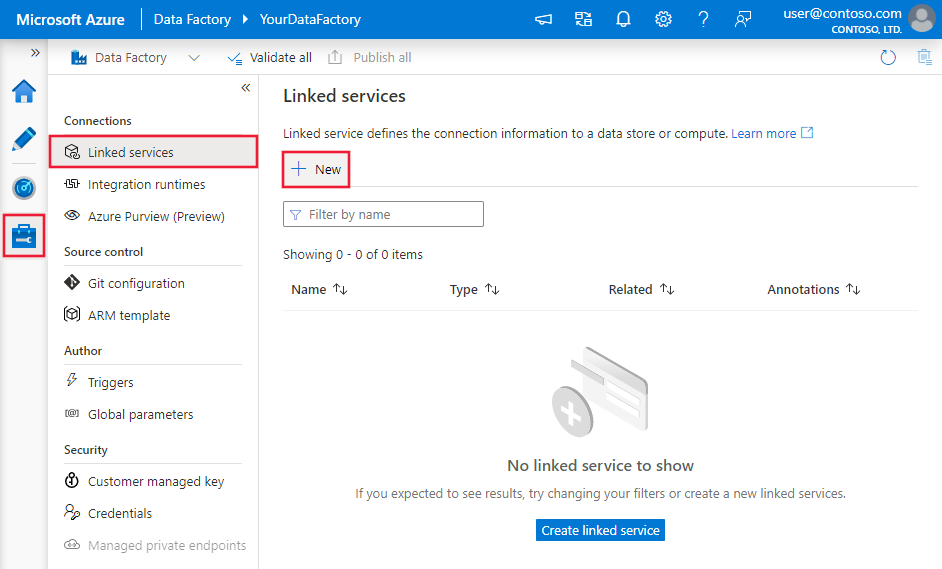
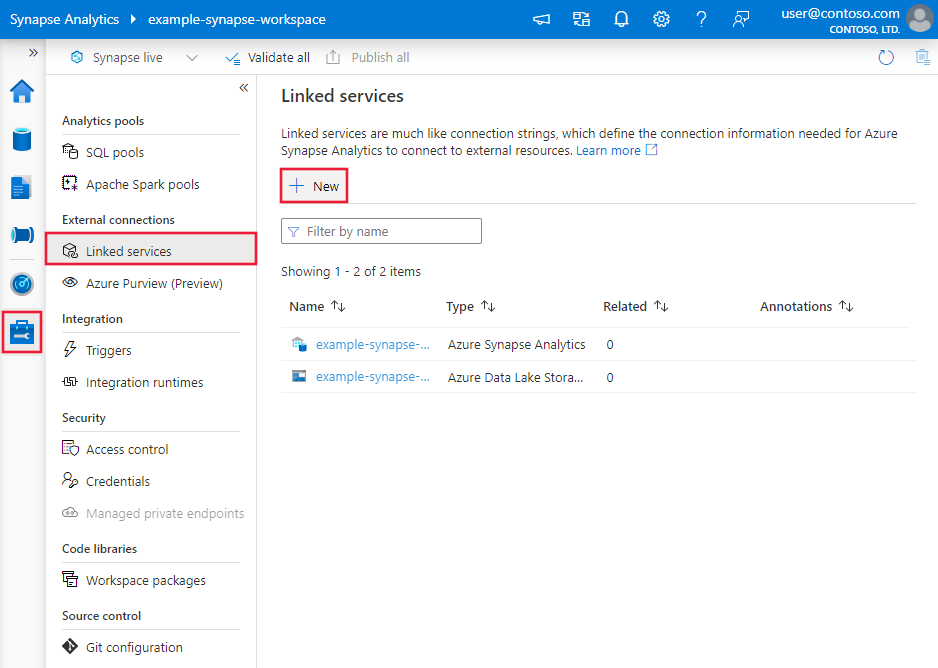
Przejdź do karty Zarządzanie w obszarze roboczym usługi Azure Data Factory lub Synapse i wybierz pozycję Połączone usługi, a następnie kliknij pozycję Nowy:
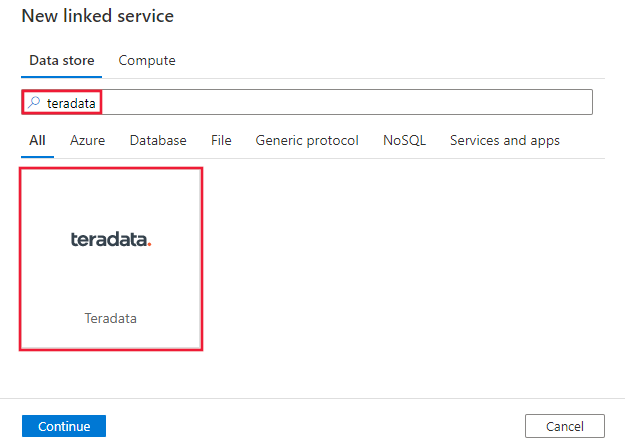
Wyszukaj ciąg Teradata i wybierz łącznik Teradata.
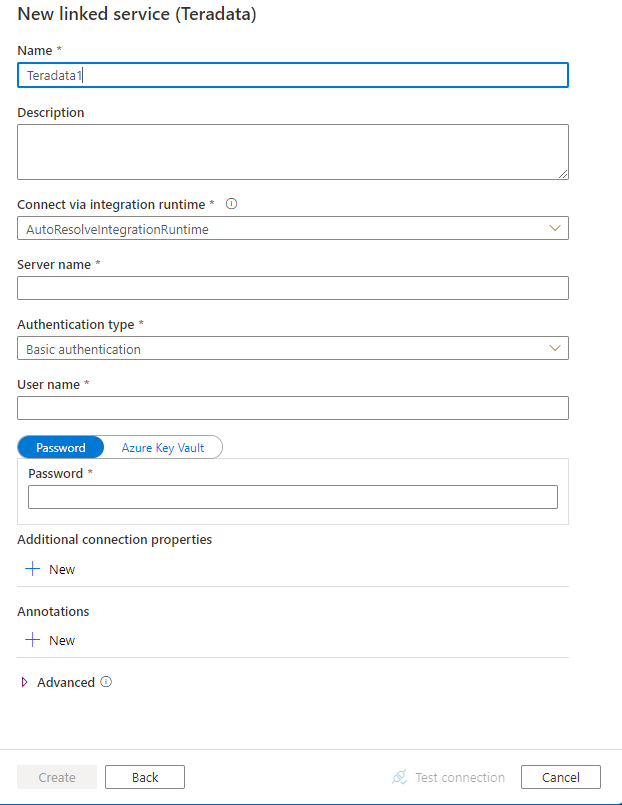
Skonfiguruj szczegóły usługi, przetestuj połączenie i utwórz nową połączoną usługę.
szczegóły konfiguracji Połączenie or
Poniższe sekcje zawierają szczegółowe informacje o właściwościach używanych do definiowania jednostek usługi Data Factory specyficznych dla łącznika Teradata.
Właściwości połączonej usługi
Połączona usługa Teradata obsługuje następujące właściwości:
| Właściwości | Opis | Wymagania |
|---|---|---|
| type | Właściwość type musi być ustawiona na Teradata. | Tak |
| Parametry połączenia | Określa informacje potrzebne do nawiązania połączenia z wystąpieniem teradata. Zapoznaj się z poniższymi przykładami. Możesz również umieścić hasło w usłudze Azure Key Vault i ściągnąć password konfigurację z parametry połączenia. Aby uzyskać więcej informacji, zobacz Przechowywanie poświadczeń w usłudze Azure Key Vault . |
Tak |
| nazwa użytkownika | Określ nazwę użytkownika, aby nawiązać połączenie z usługą Teradata. Ma zastosowanie w przypadku korzystania z uwierzytelniania systemu Windows. | Nie. |
| hasło | Określ hasło dla konta użytkownika określonego dla nazwy użytkownika. Możesz również odwołać się do wpisu tajnego przechowywanego w usłudze Azure Key Vault. Ma zastosowanie w przypadku korzystania z uwierzytelniania systemu Windows lub odwoływania się do hasła w usłudze Key Vault na potrzeby uwierzytelniania podstawowego. |
Nie. |
| connectVia | Środowisko Integration Runtime do nawiązania połączenia z magazynem danych. Dowiedz się więcej w sekcji Wymagania wstępne . Jeśli nie zostanie określony, używa domyślnego środowiska Azure Integration Runtime. | Nie. |
Więcej właściwości połączenia, które można ustawić w parametry połączenia w zależności od przypadku:
| Właściwości | Description | Domyślna wartość |
|---|---|---|
| TdmstPortNumber | Liczba portów używanych do uzyskiwania dostępu do bazy danych Teradata. Nie zmieniaj tej wartości, chyba że zostanie to poinstruowane przez pomoc techniczną. |
1025 |
| UseDataEncryption | Określa, czy szyfrować całą komunikację z bazą danych Teradata. Dozwolone wartości to 0 lub 1. - 0 (wyłączone, domyślne): szyfruje tylko informacje uwierzytelniania. - 1 (włączone): Szyfruje wszystkie dane przekazywane między sterownikiem a bazą danych. |
0 |
| Characterset | Zestaw znaków, który ma być używany dla sesji. Np. CharacterSet=UTF16.Ta wartość może być zestawem znaków zdefiniowanym przez użytkownika lub jednym z następujących wstępnie zdefiniowanych zestawów znaków: -ASCII - UTF8 - UTF16 - LATIN1252_0A - LATIN9_0A - LATIN1_0A - Shift-JIS (Windows, DOS zgodny, KANJISJIS_0S) - EUC (zgodne z systemem Unix, KANJIEC_0U) - IBM Mainframe (KANJIEBCDIC5035_0I) - KANJI932_1S0 - BIG5 (TCHBIG5_1R0) - GB (SCHGB2312_1T0) - SCHINESE936_6R0 - TCHINESE950_8R0 - NetworkKorean (HANGULKSC5601_2R4) - HANGUL949_7R0 - ARABIC1256_6A0 - CYRILLIC1251_2A0 - HEBREW1255_5A0 - LATIN1250_1A0 - LATIN1254_7A0 - LATIN1258_8A0 - THAI874_4A0 |
ASCII |
| MaxRespSize | Maksymalny rozmiar buforu odpowiedzi dla żądań SQL w kilobajtach (KB). Np. MaxRespSize=10485760.W przypadku bazy danych Teradata w wersji 16.00 lub nowszej maksymalna wartość to 7361536. W przypadku połączeń korzystających z wcześniejszych wersji maksymalna wartość to 1048576. |
65536 |
| Nazwa mechanizmu | Aby użyć protokołu LDAP do uwierzytelniania połączenia, określ wartość MechanismName=LDAP. |
Nie dotyczy |
Przykład użycia uwierzytelniania podstawowego
{
"name": "TeradataLinkedService",
"properties": {
"type": "Teradata",
"typeProperties": {
"connectionString": "DBCName=<server>;Uid=<username>;Pwd=<password>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Przykład użycia uwierzytelniania systemu Windows
{
"name": "TeradataLinkedService",
"properties": {
"type": "Teradata",
"typeProperties": {
"connectionString": "DBCName=<server>",
"username": "<username>",
"password": "<password>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Przykład użycia uwierzytelniania LDAP
{
"name": "TeradataLinkedService",
"properties": {
"type": "Teradata",
"typeProperties": {
"connectionString": "DBCName=<server>;MechanismName=LDAP;Uid=<username>;Pwd=<password>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Uwaga
Poniższy ładunek jest nadal obsługiwany. Jednak w przyszłości należy użyć nowego.
Poprzedni ładunek:
{
"name": "TeradataLinkedService",
"properties": {
"type": "Teradata",
"typeProperties": {
"server": "<server>",
"authenticationType": "<Basic/Windows>",
"username": "<username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Właściwości zestawu danych
Ta sekcja zawiera listę właściwości obsługiwanych przez zestaw danych Teradata. Aby uzyskać pełną listę sekcji i właściwości dostępnych do definiowania zestawów danych, zobacz Zestawy danych.
Aby skopiować dane z usługi Teradata, obsługiwane są następujące właściwości:
| Właściwości | Opis | Wymagania |
|---|---|---|
| type | Właściwość type zestawu danych musi być ustawiona na TeradataTable. |
Tak |
| database | Nazwa wystąpienia teradata. | Nie (jeśli określono "zapytanie" w źródle działania) |
| table | Nazwa tabeli w wystąpieniu teradata. | Nie (jeśli określono "zapytanie" w źródle działania) |
Przykład:
{
"name": "TeradataDataset",
"properties": {
"type": "TeradataTable",
"typeProperties": {},
"schema": [],
"linkedServiceName": {
"referenceName": "<Teradata linked service name>",
"type": "LinkedServiceReference"
}
}
}
Uwaga
RelationalTable Zestaw danych typu jest nadal obsługiwany. Zalecamy jednak użycie nowego zestawu danych.
Poprzedni ładunek:
{
"name": "TeradataDataset",
"properties": {
"type": "RelationalTable",
"linkedServiceName": {
"referenceName": "<Teradata linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {}
}
}
Właściwości działania kopiowania
Ta sekcja zawiera listę właściwości obsługiwanych przez źródło teradata. Aby uzyskać pełną listę sekcji i właściwości dostępnych do definiowania działań, zobacz Pipelines (Potoki).
Teradata jako źródło
Napiwek
Aby wydajnie ładować dane z teradata przy użyciu partycjonowania danych, dowiedz się więcej z sekcji Kopiowanie równoległe z usługi Teradata .
Aby skopiować dane z teradata, następujące właściwości są obsługiwane w sekcji źródła działania kopiowania:
| Właściwości | Opis | Wymagania |
|---|---|---|
| type | Właściwość type źródła działania kopiowania musi być ustawiona na TeradataSourcewartość . |
Tak |
| zapytanie | Użyj niestandardowego zapytania SQL, aby odczytać dane. Może to być na przykład "SELECT * FROM MyTable".Po włączeniu obciążenia partycjonowanego należy podłączyć wszystkie odpowiednie wbudowane parametry partycji w zapytaniu. Aby zapoznać się z przykładami, zobacz sekcję Kopiowanie równoległe z usługi Teradata . |
Nie (jeśli określono tabelę w zestawie danych) |
| partitionOptions | Określa opcje partycjonowania danych używane do ładowania danych z teradata. Dozwolone wartości to: Brak (wartość domyślna), Skrót i DynamicRange. Jeśli opcja partycji jest włączona (czyli nie None), stopień równoległości równoczesnego ładowania danych z teradata jest kontrolowany przez parallelCopies ustawienie działania kopiowania. |
Nie. |
| partycja Ustawienia | Określ grupę ustawień partycjonowania danych. Zastosuj, gdy opcja partycji nie Nonejest . |
Nie. |
| partitionColumnName | Określ nazwę kolumny źródłowej, która będzie używana przez partycję zakresu lub partycję skrótu na potrzeby kopiowania równoległego. Jeśli nie zostanie określony, podstawowy indeks tabeli jest automatycznie wykrywany i używany jako kolumna partycji. Zastosuj, gdy opcja partycji to Hash lub DynamicRange. Jeśli używasz zapytania do pobierania danych źródłowych, zaczepienia ?AdfHashPartitionCondition lub ?AdfRangePartitionColumnName klauzuli WHERE. Zobacz przykład w sekcji Kopiowanie równoległe z teradata . |
Nie. |
| partitionUpperBound | Maksymalna wartość kolumny partycji do skopiowania danych. Zastosuj, gdy opcja partycji to DynamicRange. Jeśli używasz zapytania do pobierania danych źródłowych, należy podłączyć ?AdfRangePartitionUpbound się do klauzuli WHERE. Aby zapoznać się z przykładem, zobacz sekcję Kopia równoległa z teradata . |
Nie. |
| partitionLowerBound | Minimalna wartość kolumny partycji do skopiowania danych. Zastosuj, gdy opcja partycji to DynamicRange. Jeśli używasz zapytania do pobierania danych źródłowych, należy podłączyć ?AdfRangePartitionLowbound się do klauzuli WHERE. Aby zapoznać się z przykładem, zobacz sekcję Kopia równoległa z teradata . |
Nie. |
Uwaga
RelationalSource Źródło kopiowania typu jest nadal obsługiwane, ale nie obsługuje nowego wbudowanego równoległego ładowania z teradata (opcje partycji). Zalecamy jednak użycie nowego zestawu danych.
Przykład: kopiowanie danych przy użyciu zapytania podstawowego bez partycji
"activities":[
{
"name": "CopyFromTeradata",
"type": "Copy",
"inputs": [
{
"referenceName": "<Teradata input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "TeradataSource",
"query": "SELECT * FROM MyTable"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Kopiowanie równoległe z teradata
Łącznik Teradata zapewnia wbudowane partycjonowanie danych w celu równoległego kopiowania danych z teradata. Opcje partycjonowania danych można znaleźć w tabeli Źródłowe działania kopiowania.

Po włączeniu kopii partycjonowanej usługa uruchamia zapytania równoległe względem źródła teradata w celu załadowania danych według partycji. Stopień równoległy jest kontrolowany przez parallelCopies ustawienie działania kopiowania. Jeśli na przykład ustawiono parallelCopies wartość cztery, usługa jednocześnie generuje i uruchamia cztery zapytania na podstawie określonej opcji partycji i ustawień, a każde zapytanie pobiera część danych z teradata.
Zaleca się włączenie kopiowania równoległego przy użyciu partycjonowania danych, szczególnie w przypadku ładowania dużej ilości danych z danych Teradata. Poniżej przedstawiono sugerowane konfiguracje dla różnych scenariuszy. Podczas kopiowania danych do magazynu danych opartego na plikach zaleca się zapisywanie w folderze jako wielu plików (tylko określ nazwę folderu), w tym przypadku wydajność jest lepsza niż zapisywanie w jednym pliku.
| Scenariusz | Sugerowane ustawienia |
|---|---|
| Pełne ładowanie z dużej tabeli. | Opcja partycji: skrót. Podczas wykonywania usługa automatycznie wykrywa kolumnę indeksu podstawowego, stosuje skrót względem niej i kopiuje dane według partycji. |
| Załaduj dużą ilość danych przy użyciu zapytania niestandardowego. | Opcja partycji: skrót. Zapytanie: SELECT * FROM <TABLENAME> WHERE ?AdfHashPartitionCondition AND <your_additional_where_clause>.Kolumna partycji: określ kolumnę używaną do zastosowania partycji skrótu. Jeśli nie zostanie określony, usługa automatycznie wykryje kolumnę PK tabeli określonej w zestawie danych Teradata. Podczas wykonywania usługa zastępuje ?AdfHashPartitionCondition logikę partycji skrótu i wysyła do teradata. |
| Załaduj dużą ilość danych przy użyciu zapytania niestandardowego, zawierającą kolumnę całkowitą z równomiernie rozproszoną wartością partycjonowania zakresu. | Opcje partycji: partycja zakresu dynamicznego. Zapytanie: SELECT * FROM <TABLENAME> WHERE ?AdfRangePartitionColumnName <= ?AdfRangePartitionUpbound AND ?AdfRangePartitionColumnName >= ?AdfRangePartitionLowbound AND <your_additional_where_clause>.Kolumna partycji: określ kolumnę używaną do partycjonowania danych. Kolumnę można podzielić na partycje przy użyciu typu danych całkowitych. Górna granica partycji i dolna granica partycji: określ, czy chcesz filtrować względem kolumny partycji, aby pobrać dane tylko między dolnym i górnym zakresem. Podczas wykonywania usługa zastępuje ?AdfRangePartitionColumnNamewartości , ?AdfRangePartitionUpboundi ?AdfRangePartitionLowbound rzeczywistymi nazwami kolumn i zakresami wartości dla każdej partycji oraz wysyła je do teradata. Na przykład jeśli kolumna partycji "ID" ustawiona z dolną granicą jako 1 i górną granicą jako 80, z zestawem kopii równoległej jako 4, usługa pobiera dane według 4 partycji. Ich identyfikatory to odpowiednio [120], [21, 40], [41, 60] i [61, 80]. |
Przykład: zapytanie z partycją skrótu
"source": {
"type": "TeradataSource",
"query": "SELECT * FROM <TABLENAME> WHERE ?AdfHashPartitionCondition AND <your_additional_where_clause>",
"partitionOption": "Hash",
"partitionSettings": {
"partitionColumnName": "<hash_partition_column_name>"
}
}
Przykład: zapytanie z partycją zakresu dynamicznego
"source": {
"type": "TeradataSource",
"query": "SELECT * FROM <TABLENAME> WHERE ?AdfRangePartitionColumnName <= ?AdfRangePartitionUpbound AND ?AdfRangePartitionColumnName >= ?AdfRangePartitionLowbound AND <your_additional_where_clause>",
"partitionOption": "DynamicRange",
"partitionSettings": {
"partitionColumnName": "<dynamic_range_partition_column_name>",
"partitionUpperBound": "<upper_value_of_partition_column>",
"partitionLowerBound": "<lower_value_of_partition_column>"
}
}
Mapowanie typów danych dla teradata
Podczas kopiowania danych z teradata następujące mapowania są stosowane z typów danych teradata do wewnętrznych typów danych używanych przez usługę. Aby dowiedzieć się, jak działanie kopiowania mapuje schemat źródłowy i typ danych na ujście, zobacz Mapowania schematu i typu danych.
| Typ danych Teradata | Typ danych usługi tymczasowej |
|---|---|
| BigInt | Int64 |
| Obiekt blob | Bajt[] |
| Byte | Bajt[] |
| ByteInt | Int16 |
| Char | String |
| Clob | String |
| Date | DateTime |
| Dziesiętne | Dziesiętne |
| Liczba rzeczywista | Liczba rzeczywista |
| Graficzny | Nieobsługiwane. Zastosuj jawne rzutowanie w zapytaniu źródłowym. |
| Liczba całkowita | Int32 |
| Dzień interwału | Nieobsługiwane. Zastosuj jawne rzutowanie w zapytaniu źródłowym. |
| Interwał od godziny do godziny | Nieobsługiwane. Zastosuj jawne rzutowanie w zapytaniu źródłowym. |
| Interwał od dnia do minuty | Nieobsługiwane. Zastosuj jawne rzutowanie w zapytaniu źródłowym. |
| Interwał od dnia do sekundy | Nieobsługiwane. Zastosuj jawne rzutowanie w zapytaniu źródłowym. |
| Godzina interwału | Nieobsługiwane. Zastosuj jawne rzutowanie w zapytaniu źródłowym. |
| Interwał od godziny do minuty | Nieobsługiwane. Zastosuj jawne rzutowanie w zapytaniu źródłowym. |
| Interwał od godziny do sekundy | Nieobsługiwane. Zastosuj jawne rzutowanie w zapytaniu źródłowym. |
| Minuta interwału | Nieobsługiwane. Zastosuj jawne rzutowanie w zapytaniu źródłowym. |
| Interwał od minuty do sekundy | Nieobsługiwane. Zastosuj jawne rzutowanie w zapytaniu źródłowym. |
| Interwał miesiąca | Nieobsługiwane. Zastosuj jawne rzutowanie w zapytaniu źródłowym. |
| Interwał drugi | Nieobsługiwane. Zastosuj jawne rzutowanie w zapytaniu źródłowym. |
| Interwał roku | Nieobsługiwane. Zastosuj jawne rzutowanie w zapytaniu źródłowym. |
| Interwał od roku do miesiąca | Nieobsługiwane. Zastosuj jawne rzutowanie w zapytaniu źródłowym. |
| Liczba | Liczba rzeczywista |
| Okres (data) | Nieobsługiwane. Zastosuj jawne rzutowanie w zapytaniu źródłowym. |
| Okres (czas) | Nieobsługiwane. Zastosuj jawne rzutowanie w zapytaniu źródłowym. |
| Okres (czas ze strefą czasową) | Nieobsługiwane. Zastosuj jawne rzutowanie w zapytaniu źródłowym. |
| Okres (znacznik czasu) | Nieobsługiwane. Zastosuj jawne rzutowanie w zapytaniu źródłowym. |
| Okres (znacznik czasu ze strefą czasową) | Nieobsługiwane. Zastosuj jawne rzutowanie w zapytaniu źródłowym. |
| Smallint | Int16 |
| Czas | przedział_czasu |
| Czas ze strefą czasową | przedział_czasu |
| Sygnatura czasowa | DateTime |
| Sygnatura czasowa ze strefą czasową | DateTime |
| VarByte | Bajt[] |
| Varchar | String |
| VarGraphic | Nieobsługiwane. Zastosuj jawne rzutowanie w zapytaniu źródłowym. |
| XML | Nieobsługiwane. Zastosuj jawne rzutowanie w zapytaniu źródłowym. |
Właściwości działania wyszukiwania
Aby dowiedzieć się więcej o właściwościach, sprawdź działanie Wyszukiwania.
Powiązana zawartość
Aby uzyskać listę magazynów danych obsługiwanych jako źródła i ujścia działania kopiowania, zobacz Obsługiwane magazyny danych.