Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
DOTYCZY: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Wskazówka
Data Factory w usłudze Microsoft Fabric jest następną generacją Azure Data Factory z prostszą architekturą, wbudowaną sztuczną inteligencją i nowymi funkcjami. Jeśli dopiero zaczynasz integrować dane, zacznij od Fabric Data Factory. Istniejące obciążenia ADF można zaktualizować do Fabric, aby uzyskać dostęp do nowych możliwości w zakresie nauki o danych, analiz w czasie rzeczywistym oraz raportowania.
Postępuj zgodnie z tym artykułem, jeśli chcesz analizować pliki Excel. Usługa obsługuje zarówno ".xls" jak i ".xlsx".
Format Excel jest obsługiwany dla następujących łączników:
Uwaga
Format ".xls" nie jest obsługiwany podczas korzystania z protokołu HTTP.
Właściwości zestawu danych
Aby uzyskać pełną listę sekcji i właściwości dostępnych do definiowania zestawów danych, zobacz artykuł Zestawy danych. Ta sekcja zawiera listę właściwości obsługiwanych przez zestaw danych Excel.
| Właściwości | Opis | Wymagane |
|---|---|---|
| typ | Właściwość type zestawu danych musi być ustawiona na wartość Excel. | Tak |
| lokalizacja | Ustawienia lokalizacji plików. Każdy łącznik oparty na plikach ma własny typ lokalizacji i obsługiwane właściwości w obszarze location. |
Tak |
| nazwa arkusza | Nazwa arkusza Excel do odczytywania danych. | Określ sheetName lub sheetIndex |
| IndeksArkusza | Indeks arkusza Excel do odczytywania danych, począwszy od 0. | Określ sheetName lub sheetIndex |
| zakres | Zakres komórek w danym arkuszu w celu zlokalizowania danych selektywnych, np.: - Nie określono: odczytuje cały arkusz jako tabelę z pierwszego niepustego wiersza i kolumny - A3: odczytuje tabelę rozpoczynającą się od danej komórki, dynamicznie wykrywa wszystkie poniższe wiersze i wszystkie kolumny po prawej stronie- A3:H5: odczytuje ten stały zakres jako tabelę- A3:A3: odczytuje tę pojedynczą komórkę |
Nie. |
| firstRowAsHeader | Określa, czy pierwszy wiersz w podanym arkuszu lub zakresie ma być traktowany jako wiersz nagłówka z nazwami kolumn. Dozwolone wartości to true i false (wartość domyślna). |
Nie. |
| wartość null | Określa ciąg reprezentujący wartość null. Wartość domyślna to pusty ciąg. |
Nie. |
| kompresja | Grupa właściwości do skonfigurowania kompresji pliku. Skonfiguruj tę sekcję, gdy chcesz wykonać kompresję/dekompresję podczas wykonywania działań. | Nie. |
| typ (w obszarze compression) |
Kodek kompresji używany do odczytu/zapisu plików JSON. Dozwolone wartości to bzip2, gzip, deflate, ZipDeflate, TarGzip, Tar, snappy lub lz4. Wartość domyślna nie jest kompresowana. Uwaga obecnie funkcja kopiowania nie obsługuje "snappy" oraz "lz4", a przepływ danych nie obsługuje "ZipDeflate", "TarGzip" i "Tar". Uwaga, podczas korzystania z działania kopiowania do dekompresowania plików ZipDeflate i zapisywania w docelowym magazynie danych opartym na plikach, pliki są wyodrębniane do folderu: <path specified in dataset>/<folder named as source zip file>/. |
Nr. |
| poziom (w obszarze compression) |
Współczynnik kompresji. Dozwolone wartości są optymalne lub najszybsze. - Najszybsza: operacja kompresji powinna zostać ukończona tak szybko, jak to możliwe, nawet jeśli wynikowy plik nie jest optymalnie skompresowany. - Optymalna: operacja kompresji powinna być optymalnie skompresowana, nawet jeśli operacja trwa dłużej. Aby uzyskać więcej informacji, zobacz Temat Poziom kompresji. |
Nie. |
Poniżej przedstawiono przykład zestawu danych Excel w Azure Blob Storage:
{
"name": "ExcelDataset",
"properties": {
"type": "Excel",
"linkedServiceName": {
"referenceName": "<Azure Blob Storage linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"typeProperties": {
"location": {
"type": "AzureBlobStorageLocation",
"container": "containername",
"folderPath": "folder/subfolder",
},
"sheetName": "MyWorksheet",
"range": "A3:H5",
"firstRowAsHeader": true
}
}
}
Właściwości aktywności kopiowania
Aby uzyskać pełną listę sekcji i właściwości dostępnych do definiowania działań, zobacz artykuł Pipelines (Potoki ). Ta sekcja zawiera listę właściwości obsługiwanych przez źródło Excel.
Excel jako źródło
Następujące właściwości są obsługiwane w sekcji *źródło* działania kopiowania.
| Właściwości | Opis | Wymagane |
|---|---|---|
| typ | Właściwość type źródła działania kopiowania musi być ustawiona na ExcelSource. | Tak |
| ustawienia sklepu | Grupa właściwości dotyczących odczytywania danych z magazynu danych. Każdy łącznik oparty na plikach ma własne obsługiwane ustawienia odczytu w obszarze storeSettings. |
Nie. |
"activities": [
{
"name": "CopyFromExcel",
"type": "Copy",
"typeProperties": {
"source": {
"type": "ExcelSource",
"storeSettings": {
"type": "AzureBlobStorageReadSettings",
"recursive": true
}
},
...
}
...
}
]
Właściwości przepływu mapowania danych
W przepływach danych można odczytywać pliki w formacie Excel w następujących magazynach danych: Azure Blob Storage, Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2, Amazon S3 i SFTP. Możesz wskazać pliki Excel, korzystając z zestawu danych Excel lub zestawu danych wbudowanego.
Właściwości źródła
W poniższej tabeli wymieniono właściwości obsługiwane przez źródło Excel. Te właściwości można edytować na karcie Opcje źródła. W przypadku korzystania z wbudowanego zestawu danych zobaczysz dodatkowe ustawienia plików, które są takie same jak właściwości opisane w sekcji właściwości zestawu danych.
| Nazwa/nazwisko | Opis | Wymagane | Dozwolone wartości | Właściwość skryptu przepływu danych |
|---|---|---|---|---|
| Ścieżki z symbolami wieloznacznymi | Wszystkie pliki pasujące do ścieżki z symbolami wieloznacznymi zostaną przetworzone. Zastępuje folder i ścieżkę pliku określoną w zbiorze danych. | nie | String[] | symbole wieloznacznePaths |
| Ścieżka główna partycji | W przypadku danych plików podzielonych na partycje można wprowadzić ścieżkę katalogu głównego partycji, aby odczytywać foldery podzielone na partycje jako kolumny | nie | String | partitionRootPath |
| Lista plików | Czy źródło wskazuje plik tekstowy, który wyświetla listę plików do przetworzenia | nie |
true lub false |
lista plików |
| Kolumna do przechowywania nazwy pliku | Utwórz nową kolumnę z nazwą pliku źródłowego i ścieżką | nie | String | rowUrlColumn |
| Po zakończeniu | Usuń lub przenieś pliki po przetworzeniu. Ścieżka pliku rozpoczyna się od katalogu głównego kontenera | nie | Usuń: true lub false Przenieś: ['<from>', '<to>'] |
Czyszczenie plików przenieśPliki |
| Filtruj według ostatniej modyfikacji | Wybierz filtrowanie plików w oparciu o czas ich ostatniej zmiany | nie | Sygnatura czasowa | zmodyfikowanoPo zmodyfikowany przed |
| Nie znaleziono plików | Jeśli prawda, błąd nie jest zgłaszany, jeśli nie znaleziono żadnych plików | nie |
true lub false |
ignorujBrakZnalezionychPlików |
Przykład źródła
Na poniższej ilustracji przedstawiono przykład konfiguracji źródła Excel w przepływach mapowania danych przy użyciu trybu zestawu danych.
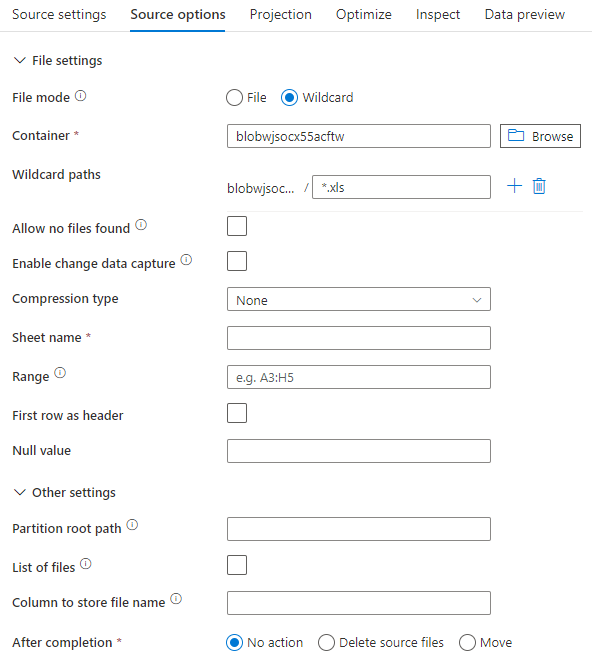
Skojarzony skrypt przepływu danych to:
source(allowSchemaDrift: true,
validateSchema: false,
wildcardPaths:['*.xls']) ~> ExcelSource
Jeśli używasz wbudowanego zestawu danych, w przepływie danych mapowania są widoczne następujące opcje źródła.
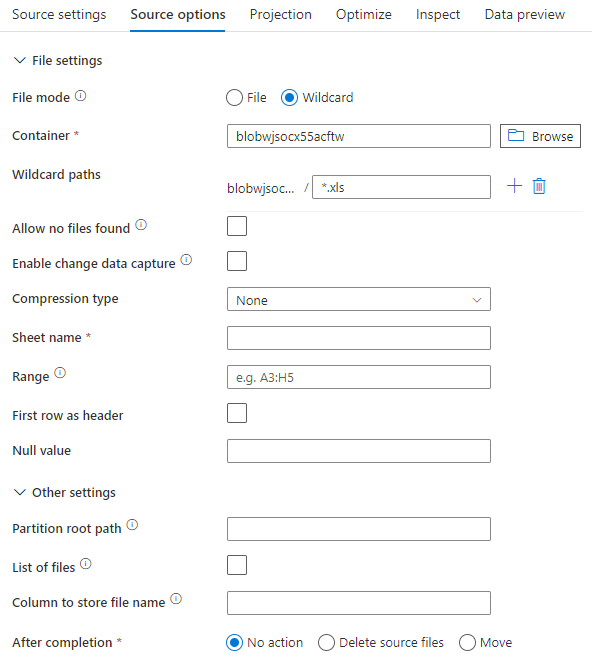
Skojarzony skrypt przepływu danych to:
source(allowSchemaDrift: true,
validateSchema: false,
format: 'excel',
fileSystem: 'container',
folderPath: 'path',
fileName: 'sample.xls',
sheetName: 'worksheet',
firstRowAsHeader: true) ~> ExcelSourceInlineDataset
Uwaga
Przepływ danych mapowania nie obsługuje odczytywania chronionych plików Excel, ponieważ te pliki mogą zawierać powiadomienia o poufności lub wymuszać określone ograniczenia dostępu ograniczające dostęp do ich zawartości.
Obsługa bardzo dużych plików Excel
Łącznik Excel nie obsługuje odczytu strumieniowego dla Copy activity i musi załadować cały plik do pamięci przed odczytaniem danych. Aby zaimportować schemat, wyświetlić podgląd danych lub odświeżyć zestaw danych Excel, dane muszą zostać zwrócone przed przekroczeniem limitu czasu żądania http (100s). W przypadku dużych plików Excel te operacje mogą nie zostać zakończone w tym przedziale czasu, powodując błąd przekroczenia limitu czasu. Jeśli chcesz przenieść duże pliki Excel (>100MB) do innego magazynu danych, możesz użyć jednej z następujących opcji, aby obejść to ograniczenie:
- Użyj własnego środowiska Integration Runtime (SHIR), a następnie użyj aktywności Kopiuj, aby przenieść duży plik Excel do innego magazynu danych za pomocą środowiska SHIR.
- Podziel duży plik Excel na kilka mniejszych, a następnie użyj Copy activity, aby przenieść folder zawierający pliki.
- Użyj działania przepływu danych, aby przenieść duży plik Excel do innego magazynu danych. Przepływ danych wspiera odczyt strumieniowy dla Excela i może szybko przesyłać duże pliki.
- Ręcznie przekonwertuj duży plik Excel na format CSV, a następnie użyj Copy activity, aby przenieść plik.