Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
DOTYCZY:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Napiwek
Wypróbuj usługę Data Factory w usłudze Microsoft Fabric — rozwiązanie analityczne typu all-in-one dla przedsiębiorstw. Usługa Microsoft Fabric obejmuje wszystko, od przenoszenia danych do nauki o danych, analizy w czasie rzeczywistym, analizy biznesowej i raportowania. Dowiedz się, jak bezpłatnie rozpocząć nową wersję próbną !
W tym artykule opisano sposób kopiowania danych z magazynu zgodnego z usługą Amazon Simple Storage Service (Amazon S3). Aby dowiedzieć się więcej, przeczytaj artykuły wprowadzające dotyczące usług Azure Data Factory i Synapse Analytics.
Obsługiwane możliwości
Ten łącznik magazynu zgodnego z usługą Amazon S3 jest obsługiwany w następujących funkcjach:
| Obsługiwane możliwości | IR |
|---|---|
| działanie Kopiuj (źródło/-) | (1) (2) |
| Działanie Lookup | (1) (2) |
| Działanie GetMetadata | (1) (2) |
| Działanie usuwania | (1) (2) |
(1) Środowisko Azure Integration Runtime (2) Self-hosted Integration Runtime
W szczególności ten łącznik magazynu zgodnego z usługą Amazon S3 obsługuje kopiowanie plików w formacie is lub analizowanie plików przy użyciu obsługiwanych formatów plików i koderów kompresji. Łącznik używa usługi AWS Signature w wersji 4 do uwierzytelniania żądań do usługi S3. Możesz użyć tego łącznika magazynu zgodnego z usługą Amazon S3, aby skopiować dane z dowolnego dostawcy magazynu zgodnego z usługą S3. Określ odpowiedni adres URL usługi w konfiguracji połączonej usługi.
Wymagane uprawnienia
Aby skopiować dane z magazynu zgodnego z usługą Amazon S3, upewnij się, że udzielono następujących uprawnień do operacji obiektów amazon S3: s3:GetObject i s3:GetObjectVersion.
Jeśli używasz interfejsu użytkownika do tworzenia, dodatkowe s3:ListAllMyBuckets uprawnienia i s3:ListBucket/s3:GetBucketLocation są wymagane w przypadku operacji, takich jak testowanie połączenia z połączoną usługą i przeglądanie z katalogu głównego. Jeśli nie chcesz udzielać tych uprawnień, możesz wybrać opcje "Testuj połączenie ze ścieżką pliku" lub "Przeglądaj z określonej ścieżki" z interfejsu użytkownika.
Aby uzyskać pełną listę uprawnień usługi Amazon S3, zobacz Określanie uprawnień w zasadach w witrynie platformy AWS.
Wprowadzenie
Aby wykonać działanie Kopiuj za pomocą potoku, możesz użyć jednego z następujących narzędzi lub zestawów SDK:
- Narzędzie do kopiowania danych
- Witryna Azure Portal
- Zestaw SDK platformy .NET
- Zestaw SDK języka Python
- Azure PowerShell
- Interfejs API REST
- Szablon usługi Azure Resource Manager
Tworzenie połączonej usługi z magazynem zgodnym z usługą Amazon S3 przy użyciu interfejsu użytkownika
Wykonaj poniższe kroki, aby utworzyć połączoną usługę z magazynem zgodnym z usługą Amazon S3 w interfejsie użytkownika witryny Azure Portal.
Przejdź do karty Zarządzanie w obszarze roboczym usługi Azure Data Factory lub Synapse i wybierz pozycję Połączone usługi, a następnie kliknij pozycję Nowy:
Wyszukaj pozycję Amazon i wybierz łącznik magazynu zgodnego z usługą Amazon S3.
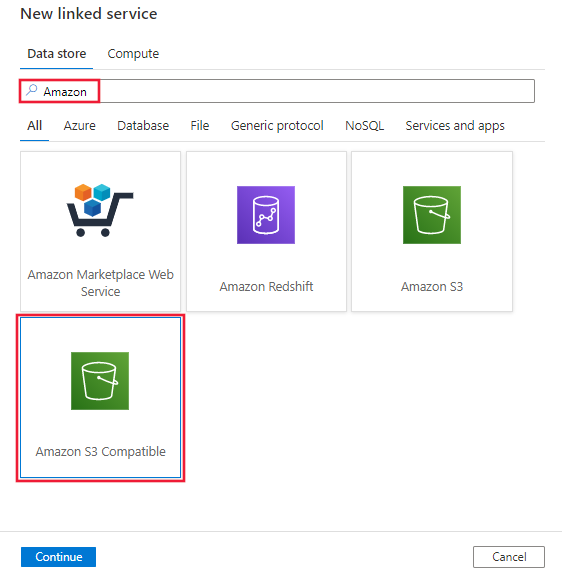
Skonfiguruj szczegóły usługi, przetestuj połączenie i utwórz nową połączoną usługę.
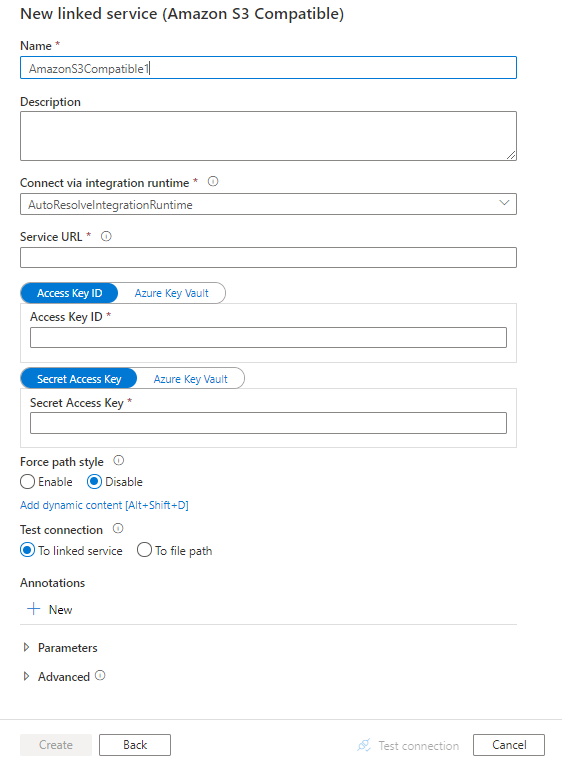
Szczegóły konfiguracji łącznika
Poniższe sekcje zawierają szczegółowe informacje o właściwościach używanych do definiowania jednostek specyficznych dla magazynu zgodnego z usługą Amazon S3.
Właściwości połączonej usługi
Następujące właściwości są obsługiwane dla połączonej usługi Amazon S3 Zgodne:
| Właściwości | Opis | Wymagania |
|---|---|---|
| type | Właściwość type musi być ustawiona na AmazonS3Compatible. | Tak |
| accessKeyId | Identyfikator klucza dostępu wpisu tajnego. | Tak |
| secretAccessKey | Sam klucz dostępu wpisu tajnego. Oznacz to pole jako element SecureString w celu bezpiecznego przechowywania go lub odwołuj się do wpisu tajnego przechowywanego w usłudze Azure Key Vault. | Tak |
| serviceUrl | Określ niestandardowy punkt końcowy https://<service url>S3 . |
Nie. |
| forcePathStyle | Wskazuje, czy należy używać dostępu w stylu ścieżki S3 zamiast dostępu do wirtualnego stylu hostowanego. Dozwolone wartości to: false (wartość domyślna), true. Sprawdź dokumentację każdego magazynu danych, jeśli jest wymagany dostęp w stylu ścieżki, czy nie. |
Nie. |
| connectVia | Środowisko Integration Runtime do nawiązania połączenia z magazynem danych. Możesz użyć środowiska Azure Integration Runtime lub własnego środowiska Integration Runtime (jeśli magazyn danych znajduje się w sieci prywatnej). Jeśli ta właściwość nie zostanie określona, usługa używa domyślnego środowiska Azure Integration Runtime. | Nie. |
Przykład:
{
"name": "AmazonS3CompatibleLinkedService",
"properties": {
"type": "AmazonS3Compatible",
"typeProperties": {
"accessKeyId": "<access key id>",
"secretAccessKey": {
"type": "SecureString",
"value": "<secret access key>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Właściwości zestawu danych
Aby uzyskać pełną listę sekcji i właściwości dostępnych do definiowania zestawów danych, zobacz artykuł Zestawy danych.
Usługa Azure Data Factory obsługuje następujące formaty plików. Zapoznaj się z każdym artykułem, aby zapoznać się z ustawieniami opartymi na formacie.
- Format Avro
- Format binarny
- Format tekstu rozdzielanego
- Format programu Excel
- Format JSON
- Format ORC
- Format Parquet
- Format XML
Następujące właściwości są obsługiwane dla usługi Amazon S3 Zgodne w ustawieniach location w zestawie danych opartym na formacie:
| Właściwości | Opis | Wymagania |
|---|---|---|
| type | Właściwość type w obszarze location w zestawie danych musi być ustawiona na AmazonS3CompatibleLocation. |
Tak |
| bucketName | Nazwa zasobnika magazynu zgodnego z usługą S3. | Tak |
| folderPath | Ścieżka do folderu w danym zasobniku. Jeśli chcesz użyć symbolu wieloznakowego do filtrowania folderu, pomiń to ustawienie i określ je w ustawieniach źródła działania. | Nie. |
| fileName | Nazwa pliku w ramach danego zasobnika i ścieżki folderu. Jeśli chcesz używać symbolu wieloznakowego do filtrowania plików, pomiń to ustawienie i określ je w ustawieniach źródła działań. | Nie. |
| version | Wersja obiektu magazynu zgodnego z usługą S3, jeśli włączono obsługę wersji zgodnego magazynu S3. Jeśli nie zostanie określona, zostanie pobrana najnowsza wersja. | Nie. |
Przykład:
{
"name": "DelimitedTextDataset",
"properties": {
"type": "DelimitedText",
"linkedServiceName": {
"referenceName": "<Amazon S3 Compatible Storage linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, auto retrieved during authoring > ],
"typeProperties": {
"location": {
"type": "AmazonS3CompatibleLocation",
"bucketName": "bucketname",
"folderPath": "folder/subfolder"
},
"columnDelimiter": ",",
"quoteChar": "\"",
"firstRowAsHeader": true,
"compressionCodec": "gzip"
}
}
}
Właściwości działania kopiowania
Aby uzyskać pełną listę sekcji i właściwości dostępnych do definiowania działań, zobacz artykuł Pipelines (Potoki ). Ta sekcja zawiera listę właściwości obsługiwanych przez źródło magazynu zgodnego z usługą Amazon S3.
Magazyn zgodny z usługą Amazon S3 jako typ źródła
Usługa Azure Data Factory obsługuje następujące formaty plików. Zapoznaj się z każdym artykułem, aby zapoznać się z ustawieniami opartymi na formacie.
- Format Avro
- Format binarny
- Format tekstu rozdzielanego
- Format programu Excel
- Format JSON
- Format ORC
- Format Parquet
- Format XML
Następujące właściwości są obsługiwane w przypadku magazynu zgodnego z usługą Amazon S3 w ustawieniach storeSettings w źródle kopiowania opartym na formacie:
| Właściwości | Opis | Wymagania |
|---|---|---|
| type | Właściwość type w obszarze storeSettings musi być ustawiona na AmazonS3CompatibleReadSettings. |
Tak |
| Znajdź pliki do skopiowania: | ||
| OPCJA 1: ścieżka statyczna |
Skopiuj z danego zasobnika lub ścieżki folderu/pliku określonego w zestawie danych. Jeśli chcesz skopiować wszystkie pliki z zasobnika lub folderu, dodatkowo określ wildcardFileName wartość *. |
|
| OPCJA 2. Prefiks magazynu zgodny z S3 -przedrostek |
Prefiks nazwy klucza magazynu zgodnego z usługą S3 w ramach danego zasobnika skonfigurowanego w zestawie danych do filtrowania źródłowych plików magazynu zgodnego z protokołem S3. Wybrano klucze magazynu zgodne ze standardem S3, których nazwy zaczynają się od bucket_in_dataset/this_prefix . Korzysta z filtru po stronie usługi zgodnego z usługą S3 Storage, który zapewnia lepszą wydajność niż filtr wieloznaczny.Jeśli używasz prefiksu i zdecydujesz się skopiować do ujścia opartego na plikach z zachowaniem hierarchii, zwróć uwagę, że ścieżka podrzędna po ostatnim prefiksie "/" zostanie zachowana. Na przykład masz źródłowy bucket/folder/subfolder/file.txtprefiks i skonfiguruj prefiks jako folder/sub, a następnie zachowaną ścieżkę pliku to subfolder/file.txt. |
Nie. |
| OPCJA 3: symbol wieloznaczny - symbol wieloznacznyFolderPath |
Ścieżka folderu z symbolami wieloznacznymi w danym zasobniku skonfigurowanym w zestawie danych do filtrowania folderów źródłowych. Dozwolone symbole wieloznaczne to: * (pasuje do zera lub większej liczby znaków) i ? (pasuje do zera lub pojedynczego znaku). Użyj ^ polecenia , aby uniknąć, jeśli nazwa folderu ma symbol wieloznaczny lub znak ucieczki wewnątrz. Zobacz więcej przykładów w przykładach filtru folderów i plików. |
Nie. |
| OPCJA 3: symbol wieloznaczny - symbol wieloznacznyFileName |
Nazwa pliku z symbolami wieloznacznymi w ramach danego zasobnika i ścieżki folderu (lub ścieżki folderu z symbolami wieloznacznymi) do filtrowania plików źródłowych. Dozwolone symbole wieloznaczne to: * (pasuje do zera lub większej liczby znaków) i ? (pasuje do zera lub pojedynczego znaku). Użyj ^ polecenia , aby uniknąć, jeśli nazwa pliku ma symbol wieloznaczny lub znak ucieczki wewnątrz. Zobacz więcej przykładów w przykładach filtru folderów i plików. |
Tak |
| OPCJA 4: lista plików - fileListPath |
Wskazuje, aby skopiować dany zestaw plików. Wskaż plik tekstowy zawierający listę plików, które chcesz skopiować, jeden plik na wiersz, czyli ścieżkę względną do ścieżki skonfigurowanej w zestawie danych. Jeśli używasz tej opcji, nie należy określać nazwy pliku w zestawie danych. Zobacz więcej przykładów na przykładach na liście plików. |
Nie. |
| Dodatkowe ustawienia: | ||
| Cykliczne | Wskazuje, czy dane są odczytywane rekursywnie z podfolderów, czy tylko z określonego folderu. Należy pamiętać, że gdy rekursywna ma wartość true, a ujście jest magazynem opartym na plikach, pusty folder lub podfolder nie jest kopiowany ani tworzony w ujściu. Dozwolone wartości to true (wartość domyślna) i false. Ta właściwość nie ma zastosowania podczas konfigurowania fileListPathelementu . |
Nie. |
| deleteFilesAfterCompletion | Wskazuje, czy pliki binarne zostaną usunięte z magazynu źródłowego po pomyślnym przeniesieniu do magazynu docelowego. Usunięcie pliku jest na plik, więc gdy działanie kopiowania nie powiedzie się, zobaczysz, że niektóre pliki zostały już skopiowane do miejsca docelowego i usunięte ze źródła, podczas gdy inne nadal pozostają w magazynie źródłowym. Ta właściwość jest prawidłowa tylko w scenariuszu kopiowania plików binarnych. Wartość domyślna: false. |
Nie. |
| modifiedDatetimeStart | Pliki są filtrowane na podstawie atrybutu: ostatnia modyfikacja. Pliki zostaną wybrane, jeśli ich czas ostatniej modyfikacji jest większy lub równy modifiedDatetimeStart i mniejszy niż modifiedDatetimeEnd. Czas jest stosowany do strefy czasowej UTC w formacie "2018-12-01T05:00:00Z". Właściwości mogą mieć wartość NULL, co oznacza, że do zestawu danych nie zostanie zastosowany filtr atrybutu pliku. Jeśli modifiedDatetimeStart ma wartość data/godzina, ale modifiedDatetimeEnd ma wartość NULL, zostaną wybrane pliki, których ostatnio zmodyfikowany atrybut jest większy lub równy wartości daty/godziny. Jeśli modifiedDatetimeEnd ma wartość data/godzina, ale modifiedDatetimeStart ma wartość NULL, zostaną wybrane pliki, których ostatnio zmodyfikowany atrybut jest mniejszy niż wartość typu data/godzina.Ta właściwość nie ma zastosowania podczas konfigurowania fileListPathelementu . |
Nie. |
| modifiedDatetimeEnd | Jak wyżej. | Nie. |
| enablePartitionDiscovery | W przypadku plików podzielonych na partycje określ, czy analizować partycje ze ścieżki pliku i dodać je jako dodatkowe kolumny źródłowe. Dozwolone wartości to false (wartość domyślna) i true. |
Nie. |
| partitionRootPath | Po włączeniu odnajdywania partycji określ bezwzględną ścieżkę katalogu głównego, aby odczytywać foldery podzielone na partycje jako kolumny danych. Jeśli nie zostanie określony, domyślnie, — Jeśli używasz ścieżki pliku w zestawie danych lub liście plików w źródle, ścieżka główna partycji jest ścieżką skonfigurowaną w zestawie danych. — W przypadku używania filtru folderów wieloznacznych ścieżka główna partycji jest ścieżką podrzędną przed pierwszym symbolem wieloznacznymi. — W przypadku używania prefiksu ścieżka główna partycji jest ścieżką podrzędną przed ostatnim "/". Załóżmy na przykład, że ścieżka w zestawie danych zostanie skonfigurowana jako "root/folder/year=2020/month=08/day=27": - Jeśli określisz ścieżkę główną partycji jako "root/folder/year=2020", działanie kopiowania wygeneruje dwie kolejne kolumny month i day z wartością "08" i "27" odpowiednio, oprócz kolumn wewnątrz plików.— Jeśli nie określono ścieżki głównej partycji, nie zostanie wygenerowana żadna dodatkowa kolumna. |
Nie. |
| maxConcurrentConnections | Górny limit połączeń współbieżnych ustanowionych z magazynem danych podczas uruchamiania działania. Określ wartość tylko wtedy, gdy chcesz ograniczyć połączenia współbieżne. | Nie. |
Przykład:
"activities":[
{
"name": "CopyFromAmazonS3CompatibleStorage",
"type": "Copy",
"inputs": [
{
"referenceName": "<Delimited text input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "DelimitedTextSource",
"formatSettings":{
"type": "DelimitedTextReadSettings",
"skipLineCount": 10
},
"storeSettings":{
"type": "AmazonS3CompatibleReadSettings",
"recursive": true,
"wildcardFolderPath": "myfolder*A",
"wildcardFileName": "*.csv"
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
Przykłady filtrów folderów i plików
W tej sekcji opisano wynikowe zachowanie ścieżki folderu i nazwy pliku z filtrami wieloznacznymi.
| wiadro | key | Cykliczne | Struktura folderu źródłowego i wynik filtru (pobierane są pliki pogrubione) |
|---|---|---|---|
| wiadro | Folder*/* |
fałsz | wiadro FolderA File1.csv File2.json Podfolder1 File3.csv File4.json File5.csv InnyfolderB File6.csv |
| wiadro | Folder*/* |
prawda | wiadro FolderA File1.csv File2.json Podfolder1 File3.csv File4.json File5.csv InnyfolderB File6.csv |
| wiadro | Folder*/*.csv |
fałsz | wiadro FolderA File1.csv File2.json Podfolder1 File3.csv File4.json File5.csv InnyfolderB File6.csv |
| wiadro | Folder*/*.csv |
prawda | wiadro FolderA File1.csv File2.json Podfolder1 File3.csv File4.json File5.csv InnyfolderB File6.csv |
Przykłady listy plików
W tej sekcji opisano wynikowe zachowanie używania ścieżki listy plików w źródle działanie Kopiuj.
Załóżmy, że masz następującą strukturę folderu źródłowego i chcesz skopiować pliki pogrubioną:
| Przykładowa struktura źródła | Zawartość w FileListToCopy.txt | Konfigurowanie |
|---|---|---|
| wiadro FolderA File1.csv File2.json Podfolder1 File3.csv File4.json File5.csv Metadane FileListToCopy.txt |
File1.csv Podfolder1/File3.csv Podfolder1/File5.csv |
W zestawie danych: -Wiadro: bucket- Ścieżka folderu: FolderAW działanie Kopiuj źródle: - Ścieżka listy plików: bucket/Metadata/FileListToCopy.txt Ścieżka listy plików wskazuje plik tekstowy w tym samym magazynie danych, który zawiera listę plików, które chcesz skopiować, jeden plik na wiersz, ze ścieżką względną do ścieżki skonfigurowanej w zestawie danych. |
Właściwości działania wyszukiwania
Aby dowiedzieć się więcej o właściwościach, sprawdź działanie Wyszukiwania.
Właściwości działania GetMetadata
Aby dowiedzieć się więcej o właściwościach, sprawdź działanie GetMetadata.
Usuń właściwości działania
Aby dowiedzieć się więcej o właściwościach, zobacz Działanie Usuń.
Powiązana zawartość
Aby uzyskać listę magazynów danych obsługiwanych przez działanie Kopiuj jako źródła i ujścia, zobacz Obsługiwane magazyny danych.