Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
DOTYCZY:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Napiwek
Wypróbuj usługę Data Factory w usłudze Microsoft Fabric — rozwiązanie analityczne typu all-in-one dla przedsiębiorstw. Usługa Microsoft Fabric obejmuje wszystko, od przenoszenia danych do nauki o danych, analizy w czasie rzeczywistym, analizy biznesowej i raportowania. Dowiedz się, jak bezpłatnie rozpocząć nową wersję próbną !
W tym artykule opisano sposób kopiowania danych z usługi Google Cloud Storage (GCS). Aby dowiedzieć się więcej, przeczytaj artykuły wprowadzające dotyczące usług Azure Data Factory i Synapse Analytics.
Obsługiwane możliwości
Ten łącznik usługi Google Cloud Storage jest obsługiwany w następujących funkcjach:
| Obsługiwane możliwości | IR |
|---|---|
| działanie Kopiuj (źródło/-) | (1) (2) |
| Przepływ danych mapowania (źródło/-) | (1) |
| Działanie Lookup | (1) (2) |
| Działanie GetMetadata | (1) (2) |
| Działanie usuwania | (1) (2) |
(1) Środowisko Azure Integration Runtime (2) Self-hosted Integration Runtime
W szczególności ten łącznik usługi Google Cloud Storage obsługuje kopiowanie plików w postaci lub analizowanie plików z obsługiwanymi formatami plików i koderami kompresji. Korzysta z współdziałania zgodnego z standardem S3 GCS.
Wymagania wstępne
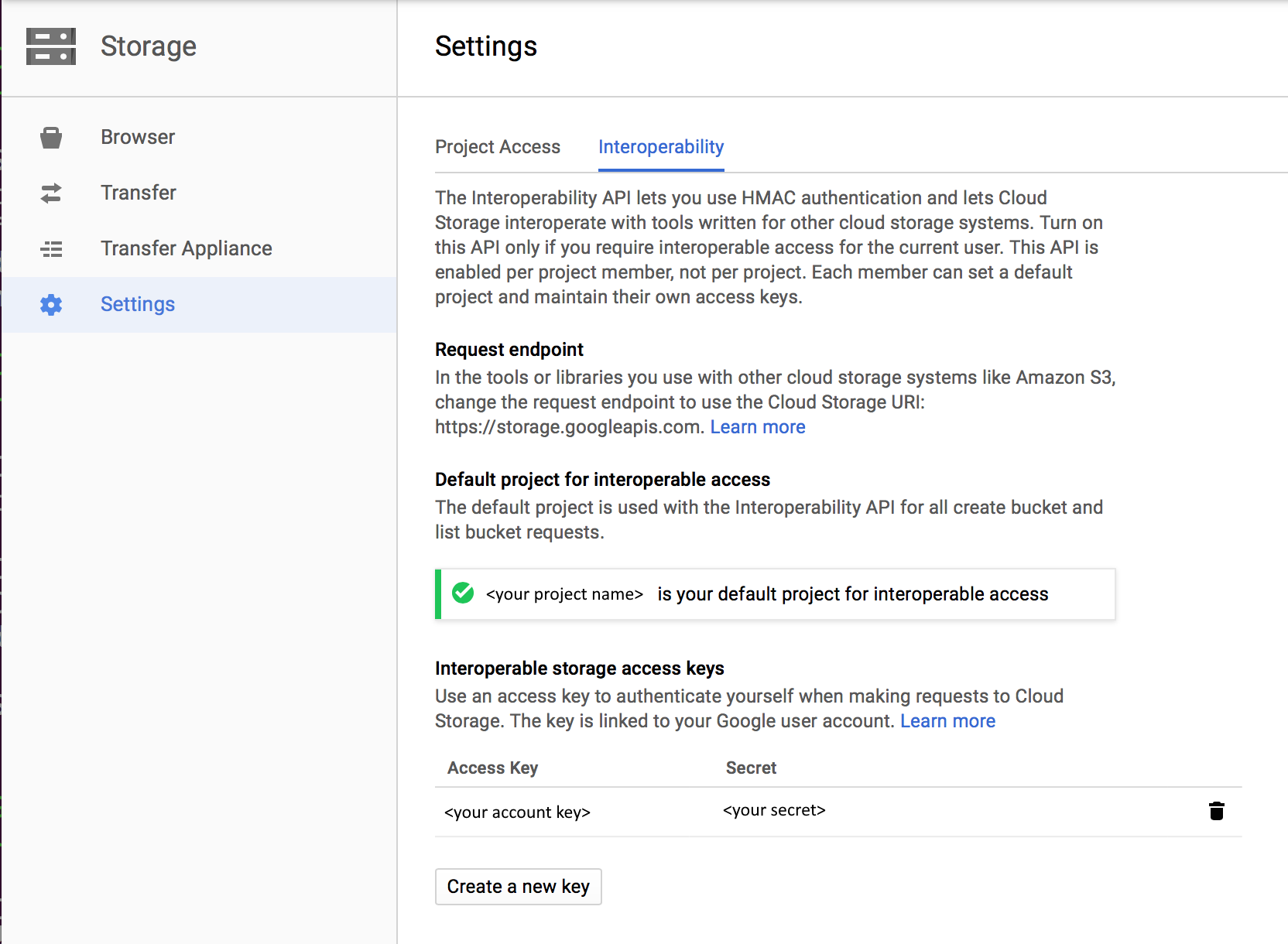
Na koncie usługi Google Cloud Storage wymagana jest następująca konfiguracja:
- Włączanie współdziałania konta usługi Google Cloud Storage
- Ustaw domyślny projekt zawierający dane, które chcesz skopiować z docelowego zasobnika GCS.
- Utwórz konto usługi i zdefiniuj odpowiednie poziomy uprawnień przy użyciu usługi Cloud IAM w usłudze GCP.
- Wygeneruj klucze dostępu dla tego konta usługi.
Wymagane uprawnienia
Aby skopiować dane z usługi Google Cloud Storage, upewnij się, że udzielono następujących uprawnień do operacji obiektów: storage.objects.get i storage.objects.list.
Jeśli używasz interfejsu użytkownika do tworzenia, wymagane jest dodatkowe storage.buckets.list uprawnienie do operacji, takich jak testowanie połączenia z połączoną usługą i przeglądanie z katalogu głównego. Jeśli nie chcesz udzielać tego uprawnienia, możesz wybrać opcje "Testuj połączenie ze ścieżką pliku" lub "Przeglądaj z określonej ścieżki" z interfejsu użytkownika.
Aby uzyskać pełną listę ról usługi Google Cloud Storage i skojarzonych uprawnień, zobacz Role zarządzania dostępem i tożsamościami dla usługi Cloud Storage w witrynie Google Cloud.
Wprowadzenie
Aby wykonać działanie Kopiuj za pomocą potoku, możesz użyć jednego z następujących narzędzi lub zestawów SDK:
- Narzędzie do kopiowania danych
- Witryna Azure Portal
- Zestaw SDK platformy .NET
- Zestaw SDK języka Python
- Azure PowerShell
- Interfejs API REST
- Szablon usługi Azure Resource Manager
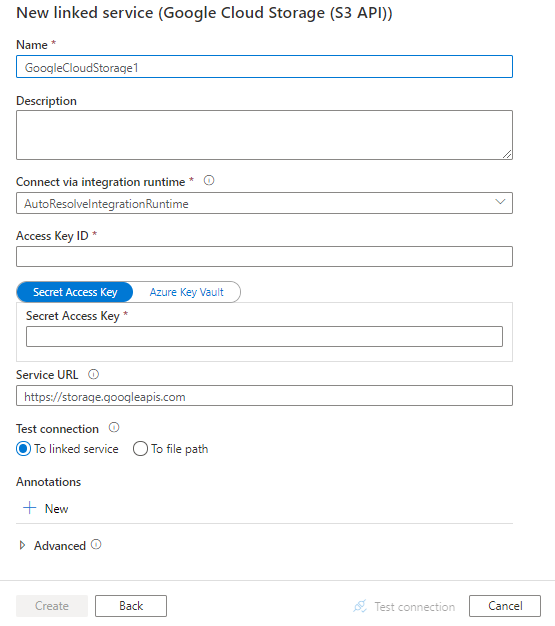
Tworzenie połączonej usługi z usługą Google Cloud Storage przy użyciu interfejsu użytkownika
Wykonaj poniższe kroki, aby utworzyć połączoną usługę z usługą Google Cloud Storage w interfejsie użytkownika witryny Azure Portal.
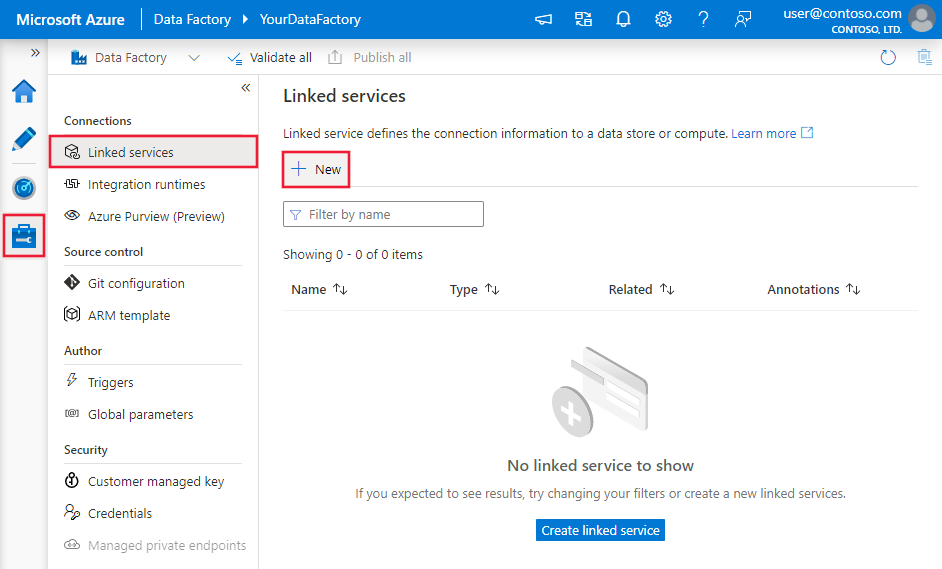
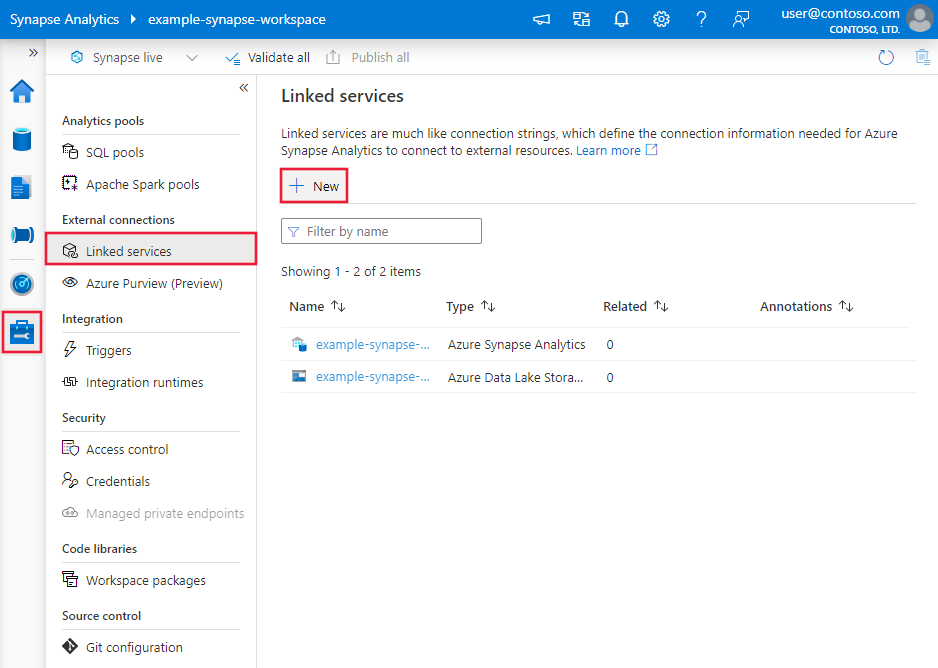
Przejdź do karty Zarządzanie w obszarze roboczym usługi Azure Data Factory lub Synapse i wybierz pozycję Połączone usługi, a następnie kliknij pozycję Nowy:
Wyszukaj pozycję Google i wybierz łącznik Google Cloud Storage (S3 API).

Skonfiguruj szczegóły usługi, przetestuj połączenie i utwórz nową połączoną usługę.
Szczegóły konfiguracji łącznika
Poniższe sekcje zawierają szczegółowe informacje o właściwościach używanych do definiowania jednostek usługi Data Factory specyficznych dla usługi Google Cloud Storage.
Właściwości połączonej usługi
Następujące właściwości są obsługiwane w przypadku połączonych usług Google Cloud Storage:
| Właściwości | Opis | Wymagania |
|---|---|---|
| type | Właściwość type musi być ustawiona na GoogleCloudStorage. | Tak |
| accessKeyId | Identyfikator klucza dostępu wpisu tajnego. Aby znaleźć klucz dostępu i klucz tajny, zobacz Wymagania wstępne. | Tak |
| secretAccessKey | Sam klucz dostępu wpisu tajnego. Oznacz to pole jako SecureString , aby bezpiecznie je przechowywać lub odwołuje się do wpisu tajnego przechowywanego w usłudze Azure Key Vault. | Tak |
| serviceUrl | Określ niestandardowy punkt końcowy GCS jako https://storage.googleapis.com. |
Tak |
| connectVia | Środowisko Integration Runtime do nawiązania połączenia z magazynem danych. Możesz użyć środowiska Azure Integration Runtime lub własnego środowiska Integration Runtime (jeśli magazyn danych znajduje się w sieci prywatnej). Jeśli ta właściwość nie zostanie określona, usługa używa domyślnego środowiska Azure Integration Runtime. | Nie. |
Oto przykład:
{
"name": "GoogleCloudStorageLinkedService",
"properties": {
"type": "GoogleCloudStorage",
"typeProperties": {
"accessKeyId": "<access key id>",
"secretAccessKey": {
"type": "SecureString",
"value": "<secret access key>"
},
"serviceUrl": "https://storage.googleapis.com"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Właściwości zestawu danych
Usługa Azure Data Factory obsługuje następujące formaty plików. Zapoznaj się z każdym artykułem, aby zapoznać się z ustawieniami opartymi na formacie.
- Format Avro
- Format binarny
- Format tekstu rozdzielanego
- Format programu Excel
- Format JSON
- Format ORC
- Format Parquet
- Format XML
Następujące właściwości są obsługiwane w usłudze Google Cloud Storage w ustawieniach location w zestawie danych opartym na formacie:
| Właściwości | Opis | Wymagania |
|---|---|---|
| type | Właściwość type w obszarze location w zestawie danych musi być ustawiona na GoogleCloudStorageLocation. |
Tak |
| bucketName | Nazwa zasobnika GCS. | Tak |
| folderPath | Ścieżka do folderu w danym zasobniku. Jeśli chcesz użyć symbolu wieloznakowego do filtrowania folderu, pomiń to ustawienie i określ je w ustawieniach źródła działań. | Nie. |
| fileName | Nazwa pliku w ramach danego zasobnika i ścieżki folderu. Jeśli chcesz użyć symbolu wieloznakowego do filtrowania plików, pomiń to ustawienie i określ je w ustawieniach źródła działań. | Nie. |
Przykład:
{
"name": "DelimitedTextDataset",
"properties": {
"type": "DelimitedText",
"linkedServiceName": {
"referenceName": "<Google Cloud Storage linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, auto retrieved during authoring > ],
"typeProperties": {
"location": {
"type": "GoogleCloudStorageLocation",
"bucketName": "bucketname",
"folderPath": "folder/subfolder"
},
"columnDelimiter": ",",
"quoteChar": "\"",
"firstRowAsHeader": true,
"compressionCodec": "gzip"
}
}
}
Właściwości działania kopiowania
Aby uzyskać pełną listę sekcji i właściwości dostępnych do definiowania działań, zobacz artykuł Pipelines (Potoki ). Ta sekcja zawiera listę właściwości, które obsługuje źródło usługi Google Cloud Storage.
Usługa Google Cloud Storage jako typ źródła
Usługa Azure Data Factory obsługuje następujące formaty plików. Zapoznaj się z każdym artykułem, aby zapoznać się z ustawieniami opartymi na formacie.
- Format Avro
- Format binarny
- Format tekstu rozdzielanego
- Format programu Excel
- Format JSON
- Format ORC
- Format Parquet
- Format XML
Następujące właściwości są obsługiwane w usłudze Google Cloud Storage w ustawieniach storeSettings w źródle kopiowania opartym na formacie:
| Właściwości | Opis | Wymagania |
|---|---|---|
| type | Właściwość type w obszarze storeSettings musi być ustawiona na GoogleCloudStorageReadSettings. |
Tak |
| Znajdź pliki do skopiowania: | ||
| OPCJA 1: ścieżka statyczna |
Skopiuj z danego zasobnika lub ścieżki folderu/pliku określonego w zestawie danych. Jeśli chcesz skopiować wszystkie pliki z zasobnika lub folderu, dodatkowo określ wildcardFileName wartość *. |
|
| OPCJA 2: prefiks GCS -przedrostek |
Prefiks nazwy klucza GCS w ramach danego zasobnika skonfigurowanego w zestawie danych do filtrowania źródłowych plików GCS. Klucze GCS, których nazwy zaczynają się od bucket_in_dataset/this_prefix , są zaznaczone. Wykorzystuje filtr po stronie usługi GCS, który zapewnia lepszą wydajność niż filtr wieloznaczny. |
Nie. |
| OPCJA 3: symbol wieloznaczny - symbol wieloznacznyFolderPath |
Ścieżka folderu z symbolami wieloznacznymi w danym zasobniku skonfigurowanym w zestawie danych do filtrowania folderów źródłowych. Dozwolone symbole wieloznaczne to: * (pasuje do zera lub większej liczby znaków) i ? (pasuje do zera lub pojedynczego znaku). Użyj ^ polecenia , aby uniknąć, jeśli nazwa folderu ma symbol wieloznaczny lub znak ucieczki wewnątrz. Zobacz więcej przykładów w przykładach filtru folderów i plików. |
Nie. |
| OPCJA 3: symbol wieloznaczny - symbol wieloznacznyFileName |
Nazwa pliku z symbolami wieloznacznymi w ramach danego zasobnika i ścieżki folderu (lub ścieżki folderu z symbolami wieloznacznymi) do filtrowania plików źródłowych. Dozwolone symbole wieloznaczne to: * (pasuje do zera lub większej liczby znaków) i ? (pasuje do zera lub pojedynczego znaku). Użyj ^ polecenia , aby uniknąć, jeśli nazwa pliku ma symbol wieloznaczny lub znak ucieczki wewnątrz. Zobacz więcej przykładów w przykładach filtru folderów i plików. |
Tak |
| OPCJA 3: lista plików - fileListPath |
Wskazuje, aby skopiować dany zestaw plików. Wskaż plik tekstowy zawierający listę plików, które chcesz skopiować, jeden plik na wiersz, czyli ścieżkę względną do ścieżki skonfigurowanej w zestawie danych. Jeśli używasz tej opcji, nie należy określać nazwy pliku w zestawie danych. Zobacz więcej przykładów na przykładach na liście plików. |
Nie. |
| Dodatkowe ustawienia: | ||
| Cykliczne | Wskazuje, czy dane są odczytywane rekursywnie z podfolderów, czy tylko z określonego folderu. Należy pamiętać, że gdy rekursywna ma wartość true, a ujście jest magazynem opartym na plikach, pusty folder lub podfolder nie jest kopiowany ani tworzony w ujściu. Dozwolone wartości to true (wartość domyślna) i false. Ta właściwość nie ma zastosowania podczas konfigurowania fileListPathelementu . |
Nie. |
| deleteFilesAfterCompletion | Wskazuje, czy pliki binarne zostaną usunięte z magazynu źródłowego po pomyślnym przeniesieniu do magazynu docelowego. Usunięcie pliku jest na plik, więc gdy działanie kopiowania nie powiedzie się, zobaczysz, że niektóre pliki zostały już skopiowane do miejsca docelowego i usunięte ze źródła, podczas gdy inne nadal pozostają w magazynie źródłowym. Ta właściwość jest prawidłowa tylko w scenariuszu kopiowania plików binarnych. Wartość domyślna: false. |
Nie. |
| modifiedDatetimeStart | Pliki są filtrowane na podstawie atrybutu: ostatnia modyfikacja. Pliki zostaną wybrane, jeśli ich czas ostatniej modyfikacji jest większy lub równy modifiedDatetimeStart i mniejszy niż modifiedDatetimeEnd. Czas jest stosowany do strefy czasowej UTC w formacie "2018-12-01T05:00:00Z". Właściwości mogą mieć wartość NULL, co oznacza, że do zestawu danych nie zostanie zastosowany filtr atrybutu pliku. Jeśli modifiedDatetimeStart ma wartość data/godzina, ale modifiedDatetimeEnd ma wartość NULL, zostaną wybrane pliki, których ostatnio zmodyfikowany atrybut jest większy lub równy wartości daty/godziny. Jeśli modifiedDatetimeEnd ma wartość data/godzina, ale modifiedDatetimeStart ma wartość NULL, zostaną wybrane pliki, których ostatnio zmodyfikowany atrybut jest mniejszy niż wartość typu data/godzina.Ta właściwość nie ma zastosowania podczas konfigurowania fileListPathelementu . |
Nie. |
| modifiedDatetimeEnd | Jak wyżej. | Nie. |
| enablePartitionDiscovery | W przypadku plików podzielonych na partycje określ, czy analizować partycje ze ścieżki pliku i dodać je jako dodatkowe kolumny źródłowe. Dozwolone wartości to false (wartość domyślna) i true. |
Nie. |
| partitionRootPath | Po włączeniu odnajdywania partycji określ bezwzględną ścieżkę katalogu głównego, aby odczytywać foldery podzielone na partycje jako kolumny danych. Jeśli nie zostanie określony, domyślnie, — Jeśli używasz ścieżki pliku w zestawie danych lub liście plików w źródle, ścieżka główna partycji jest ścieżką skonfigurowaną w zestawie danych. — W przypadku używania filtru folderów wieloznacznych ścieżka główna partycji jest ścieżką podrzędną przed pierwszym symbolem wieloznacznymi. Załóżmy na przykład, że ścieżka w zestawie danych zostanie skonfigurowana jako "root/folder/year=2020/month=08/day=27": - Jeśli określisz ścieżkę główną partycji jako "root/folder/year=2020", działanie kopiowania wygeneruje dwie kolejne kolumny month i day z wartością "08" i "27" odpowiednio, oprócz kolumn wewnątrz plików.— Jeśli nie określono ścieżki głównej partycji, nie zostanie wygenerowana żadna dodatkowa kolumna. |
Nie. |
| maxConcurrentConnections | Górny limit połączeń współbieżnych ustanowionych z magazynem danych podczas uruchamiania działania. Określ wartość tylko wtedy, gdy chcesz ograniczyć połączenia współbieżne. | Nie. |
Przykład:
"activities":[
{
"name": "CopyFromGoogleCloudStorage",
"type": "Copy",
"inputs": [
{
"referenceName": "<Delimited text input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "DelimitedTextSource",
"formatSettings":{
"type": "DelimitedTextReadSettings",
"skipLineCount": 10
},
"storeSettings":{
"type": "GoogleCloudStorageReadSettings",
"recursive": true,
"wildcardFolderPath": "myfolder*A",
"wildcardFileName": "*.csv"
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
Przykłady filtrów folderów i plików
W tej sekcji opisano wynikowe zachowanie ścieżki folderu i nazwy pliku z filtrami wieloznacznymi.
| wiadro | key | Cykliczne | Struktura folderu źródłowego i wynik filtru (pobierane są pliki pogrubione) |
|---|---|---|---|
| wiadro | Folder*/* |
fałsz | wiadro FolderA File1.csv File2.json Podfolder1 File3.csv File4.json File5.csv InnyfolderB File6.csv |
| wiadro | Folder*/* |
prawda | wiadro FolderA File1.csv File2.json Podfolder1 File3.csv File4.json File5.csv InnyfolderB File6.csv |
| wiadro | Folder*/*.csv |
fałsz | wiadro FolderA File1.csv File2.json Podfolder1 File3.csv File4.json File5.csv InnyfolderB File6.csv |
| wiadro | Folder*/*.csv |
prawda | wiadro FolderA File1.csv File2.json Podfolder1 File3.csv File4.json File5.csv InnyfolderB File6.csv |
Przykłady listy plików
W tej sekcji opisano wynikowe zachowanie używania ścieżki listy plików w źródle działanie Kopiuj.
Załóżmy, że masz następującą strukturę folderu źródłowego i chcesz skopiować pliki pogrubioną:
| Przykładowa struktura źródła | Zawartość w FileListToCopy.txt | Konfigurowanie |
|---|---|---|
| wiadro FolderA File1.csv File2.json Podfolder1 File3.csv File4.json File5.csv Metadane FileListToCopy.txt |
File1.csv Podfolder1/File3.csv Podfolder1/File5.csv |
W zestawie danych: -Wiadro: bucket- Ścieżka folderu: FolderAW źródle działania kopiowania: - Ścieżka listy plików: bucket/Metadata/FileListToCopy.txt Ścieżka listy plików wskazuje plik tekstowy w tym samym magazynie danych, który zawiera listę plików, które chcesz skopiować, jeden plik na wiersz, ze ścieżką względną do ścieżki skonfigurowanej w zestawie danych. |
Właściwości przepływu mapowania danych
Podczas przekształcania danych w przepływach mapowania danych można odczytywać pliki z usługi Google Cloud Storage w następujących formatach:
Ustawienia specyficzne dla formatu znajdują się w dokumentacji dla tego formatu. Aby uzyskać więcej informacji, zobacz Przekształcanie źródła w przepływie danych mapowania.
Przekształcanie źródła
W transformacji źródłowej można odczytywać dane z kontenera, folderu lub pojedynczego pliku w usłudze Google Cloud Storage. Użyj karty Opcje źródła, aby zarządzać sposobem odczytywania plików.
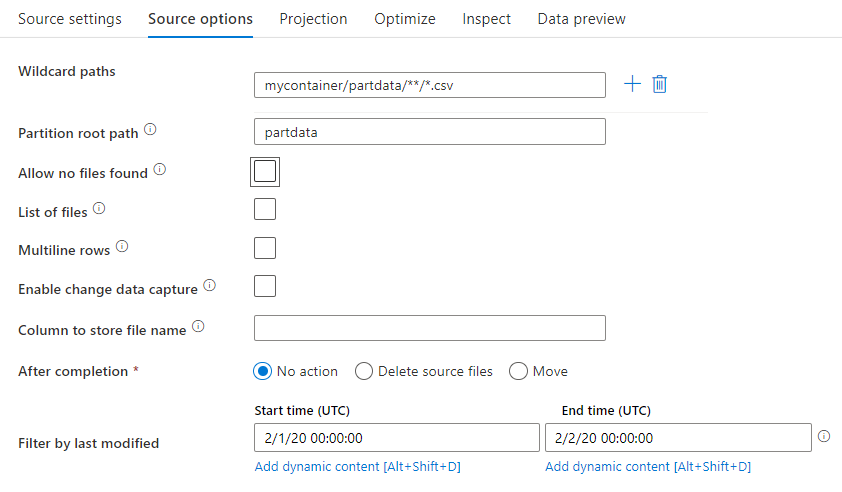
Ścieżki z symbolami wieloznacznymi: użycie wzorca z symbolami wieloznacznymi spowoduje, że usługa będzie przechodzić w pętli przez każdy pasujący folder i plik w ramach jednej transformacji źródłowej. Jest to skuteczny sposób przetwarzania wielu plików w ramach jednego przepływu. Dodaj wiele wzorców dopasowania symboli wieloznacznych z znakiem plusa wyświetlanym po umieszczeniu wskaźnika myszy na istniejącym wzorcu wieloznacznymi.
W kontenerze źródłowym wybierz serię plików pasujących do wzorca. W zestawie danych można określić tylko kontener. W związku z tym ścieżka wieloznaczny musi zawierać również ścieżkę folderu z folderu głównego.
Przykłady symboli wieloznacznych:
*Reprezentuje dowolny zestaw znaków.**Reprezentuje zagnieżdżanie katalogów cyklicznych.?Zamienia jeden znak.[]Pasuje do co najmniej jednego znaku w nawiasach kwadratowych./data/sales/**/*.csvPobiera wszystkie pliki .csv w obszarze /data/sales./data/sales/20??/**/Pobiera wszystkie pliki w XX wieku./data/sales/*/*/*.csvPobiera pliki .csv dwa poziomy w obszarze /data/sales./data/sales/2004/*/12/[XY]1?.csvPobiera wszystkie pliki .csv w grudniu 2004 r., począwszy od X lub Y poprzedzonej dwucyfrową liczbą.
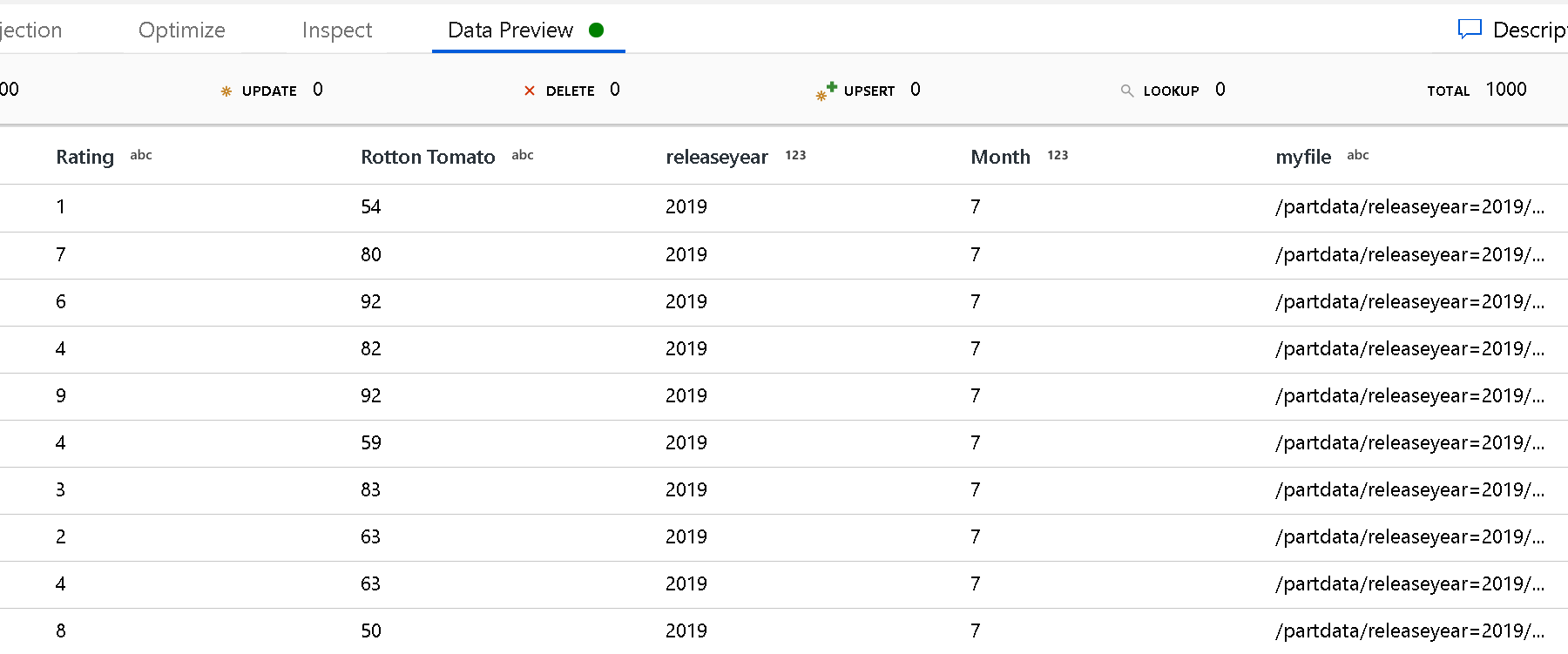
Ścieżka główna partycji: jeśli foldery partycjonowane w źródle key=value pliku mają format (na przykład year=2019), możesz przypisać najwyższy poziom drzewa folderów partycji do nazwy kolumny w strumieniu danych przepływu danych.
Najpierw ustaw symbol wieloznaczny, aby zawierał wszystkie ścieżki, które są folderami podzielonymi na partycje oraz plikami liścia, które chcesz odczytać.
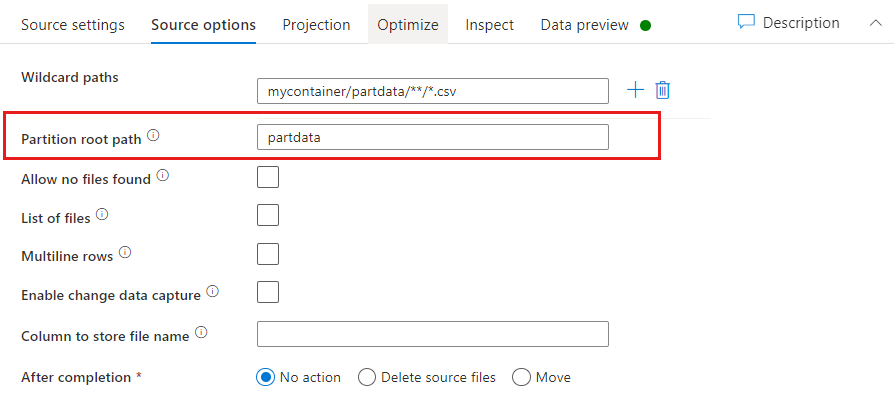
Użyj ustawienia Ścieżka główna partycji, aby zdefiniować, jaki jest najwyższy poziom struktury folderów. Podczas wyświetlania zawartości danych za pośrednictwem podglądu danych zobaczysz, że usługa doda rozpoznane partycje znajdujące się na każdym z poziomów folderów.
Lista plików: jest to zestaw plików. Utwórz plik tekstowy zawierający listę plików ścieżki względnej do przetworzenia. Wskaż ten plik tekstowy.
Kolumna do przechowywania nazwy pliku: zapisz nazwę pliku źródłowego w kolumnie w danych. Wprowadź tutaj nową nazwę kolumny, aby zapisać ciąg nazwy pliku.
Po zakończeniu: wybierz opcję wykonania niczego z plikiem źródłowym po uruchomieniu przepływu danych, usunięciu pliku źródłowego lub przeniesieniu pliku źródłowego. Ścieżki przenoszenia są względne.
Aby przenieść pliki źródłowe do innej lokalizacji po przetworzeniu, najpierw wybierz pozycję "Przenieś" dla operacji na plikach. Następnie ustaw katalog "from". Jeśli nie używasz żadnych symboli wieloznacznych dla ścieżki, ustawienie "from" będzie tym samym folderem co folder źródłowy.
Jeśli masz ścieżkę źródłową z symbolem wieloznacznymi, składnia będzie wyglądać następująco:
/data/sales/20??/**/*.csv
Możesz określić wartość "from" jako:
/data/sales
Możesz również określić wartość "do":
/backup/priorSales
W takim przypadku wszystkie pliki, które zostały pozyskane w obszarze /data/sales , są przenoszone do /backup/priorSales.
Uwaga
Operacje na plikach są uruchamiane tylko po uruchomieniu przepływu danych z uruchomienia potoku (przebiegu debugowania lub wykonywania potoku), które używa działania Wykonaj Przepływ danych w potoku. Operacje na plikach nie są uruchamiane w trybie debugowania Przepływ danych.
Filtruj według ostatniej modyfikacji: możesz filtrować, które pliki są przetwarzane, określając zakres dat ostatniej modyfikacji. Wszystkie daty/godziny są w formacie UTC.
Właściwości działania wyszukiwania
Aby dowiedzieć się więcej o właściwościach, sprawdź działanie Wyszukiwania.
Właściwości działania GetMetadata
Aby dowiedzieć się więcej o właściwościach, sprawdź działanie GetMetadata.
Usuń właściwości działania
Aby dowiedzieć się więcej o właściwościach, zobacz Działanie Usuń.
Starsze modele
Jeśli używasz łącznika Amazon S3 do kopiowania danych z usługi Google Cloud Storage, nadal jest obsługiwana w celu zapewnienia zgodności z poprzednimi wersjami. Zalecamy użycie nowego modelu wymienionego wcześniej. Interfejs użytkownika tworzenia został przełączony na generowanie nowego modelu.
Powiązana zawartość
Aby uzyskać listę magazynów danych obsługiwanych przez działanie Kopiuj jako źródła i ujścia, zobacz Obsługiwane magazyny danych.