Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Usługa Azure Databricks to ujednolicona, otwarta platforma analityczna do tworzenia, wdrażania, udostępniania i obsługi danych klasy korporacyjnej, analiz i rozwiązań sztucznej inteligencji na dużą skalę. Platforma inteligencji danych Databricks integruje się z przechowywaniem danych w chmurze i zabezpieczeniami na Twoim koncie chmury, a także zarządza i wdraża infrastrukturę chmurową dla Ciebie.
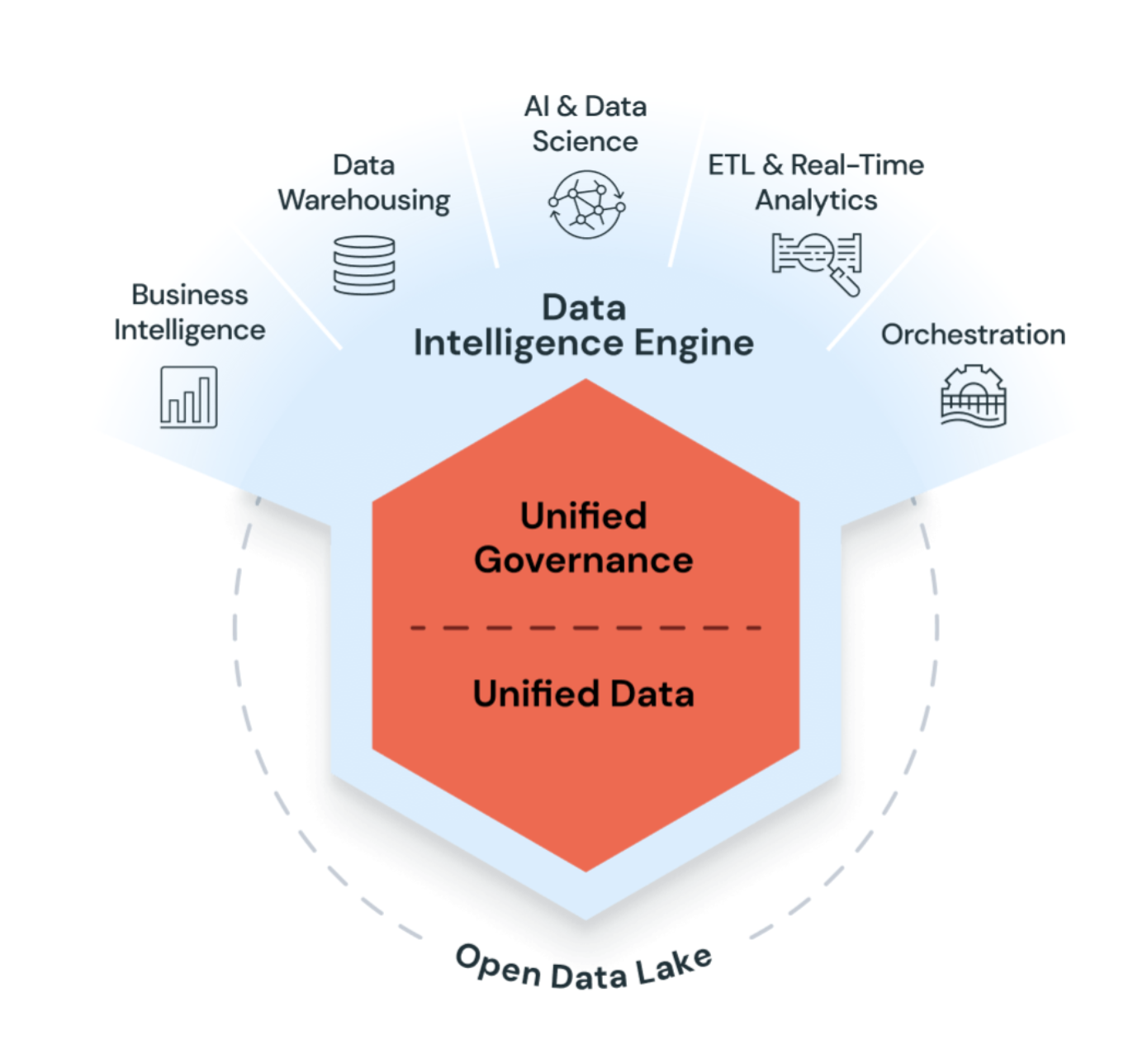
Usługa Azure Databricks używa generatywnej sztucznej inteligencji w połączeniu z Data Lakehouse w celu zrozumienia unikalnej semantyki danych. Następnie automatycznie optymalizuje wydajność i zarządza infrastrukturą zgodnie z potrzebami biznesowymi.
Przetwarzanie języka naturalnego uczy się języka firmy, dzięki czemu możesz wyszukiwać i odnajdywać dane, zadając pytanie własnymi słowami. Pomoc w języku naturalnym ułatwia pisanie kodu, rozwiązywanie problemów z błędami i znajdowanie odpowiedzi w dokumentacji.
Zarządzana integracja open source
Usługa Databricks jest zaangażowana w społeczność typu open source i zarządza aktualizacjami integracji typu open source z wersjami środowiska Databricks Runtime. Następujące technologie to projekty typu open source utworzone pierwotnie przez pracowników usługi Databricks:
- Delta Lake i Delta Sharing
- MLflow
- Apache Spark i przesyłanie strumieniowe ze strukturą
- Redash (Redash)
- Katalog Unity
Typowe przypadki użycia
Poniższe przykłady użycia ilustrują niektóre sposoby, w jakie klienci korzystają z usługi Azure Databricks do realizacji zadań niezbędnych do przetwarzania, przechowywania i analizowania danych, które napędzają krytyczne funkcje biznesowe i decyzje.
Zbuduj data lakehouse dla firmy
Usługa Data Lakehouse łączy hurtownie danych przedsiębiorstwa i jeziora danych, aby przyspieszyć, uprościć i ujednolicić rozwiązania danych dla przedsiębiorstw. Inżynierowie danych, analitycy danych i systemy produkcyjne mogą używać usługi Data Lakehouse jako jednego źródła prawdy, zapewniając dostęp do spójnych danych i zmniejszając złożoność tworzenia, utrzymywania i synchronizowania wielu rozproszonych systemów danych. Zobacz Co to jest usługa Data Lakehouse?.
ETL i inżynieria danych
Niezależnie od tego, czy generujesz pulpity nawigacyjne, czy obsługujesz aplikacje sztucznej inteligencji, inżynieria danych zapewnia szkielet dla firm skoncentrowanych na danych, upewniając się, że dane są dostępne, czyste i przechowywane w modelach danych w celu wydajnego odnajdywania i używania. Usługa Azure Databricks łączy możliwości platformy Apache Spark z Delta i niestandardowymi narzędziami, aby zapewnić niezrównane doświadczenie ETL. Użyj języków SQL, Python i Scala, aby utworzyć logikę ETL i zorganizować zaplanowane wdrożenie zadania za pomocą kilku kliknięć.
Potoki deklaratywne lakeflow dodatkowo upraszczają proces ETL przez inteligentne zarządzanie zależnościami między zestawami danych i automatyczne wdrażanie i skalowanie infrastruktury produkcyjnej w celu zapewnienia terminowego i dokładnego dostarczania danych do specyfikacji.
Usługa Azure Databricks udostępnia narzędzia do pozyskiwania danych, w tym Auto Loader, wydajne i skalowalne narzędzie do ładowania danych w sposób przyrostowy i idempotentny z magazynu obiektów w chmurze oraz jezior danych do usługi Data Lakehouse.
Uczenie maszynowe, sztuczna inteligencja i nauka o danych
Uczenie maszynowe usługi Azure Databricks rozszerza podstawowe funkcje platformy przy użyciu zestawu narzędzi dostosowanych do potrzeb analityków danych i inżynierów uczenia maszynowego, w tym MLflow i Databricks Runtime for Machine Learning.
Duże modele językowe i generowanie sztucznej inteligencji
Środowisko Databricks Runtime for Machine Learning zawiera biblioteki, takie jak Hugging Face Transformers , które umożliwiają integrację istniejących wstępnie wytrenowanych modeli lub innych bibliotek typu open source z przepływem pracy. Integracja usługi Databricks MLflow ułatwia korzystanie z usługi śledzenia MLflow z potokami transformerów, modelami i składnikami przetwarzania. Integrowanie modeli OpenAI lub rozwiązań od partnerów, takich jak John Snow Labs , w przepływach pracy usługi Databricks.
Za pomocą usługi Azure Databricks dostosuj LLM na podstawie swoich danych do określonego zadania. Dzięki obsłudze narzędzi typu open source, takich jak Hugging Face i DeepSpeed, możesz efektywnie podjąć podstawy LLM i rozpocząć trenowanie z własnymi danymi, aby uzyskać większą dokładność domeny i obciążenia.
Ponadto usługa Azure Databricks udostępnia funkcje sztucznej inteligencji, których analitycy danych SQL mogą używać do uzyskiwania dostępu do modeli LLM, w tym z platformy OpenAI, bezpośrednio w swoich potokach danych i przepływach pracy. Zobacz Zastosowanie AI do danych przy użyciu funkcji AI w Azure Databricks.
Magazynowanie danych, analityka i Business Intelligence
Usługa Azure Databricks łączy przyjazne dla użytkownika interfejsy użytkownika z kosztowo efektywnymi zasobami obliczeniowymi i nieskończenie skalowalnym, przystępnym cenowo przechowywaniem, aby zapewnić zaawansowaną platformę do uruchamiania zapytań analitycznych. Administratorzy konfigurują skalowalne klastry obliczeniowe jako magazyny SQL, umożliwiając użytkownikom końcowym wykonywanie zapytań bez obaw o złożoność pracy w chmurze. Użytkownicy SQL mogą uruchamiać zapytania dla danych w Lakehouse przy użyciu edytora zapytań SQL SQL query editor lub w notesach. Notesy obsługują języki Python, R i Scala oprócz języka SQL i umożliwiają użytkownikom osadzanie tych samych wizualizacji dostępnych na starszych pulpitach nawigacyjnych obok linków, obrazów i komentarzy napisanych w języku Markdown.
Nadzór nad danymi i bezpieczne udostępnianie danych
Unity Catalog zapewnia ujednolicony model zarządzania danymi dla jeziora danych. Administratorzy chmury konfigurują i integrują ogólne uprawnienia kontroli dostępu dla Unity Catalog, a następnie administratorzy Azure Databricks mogą zarządzać uprawnieniami dla zespołów i osób indywidualnych. Uprawnienia są zarządzane za pomocą list kontroli dostępu (ACL) za pomocą przyjaznych dla użytkownika interfejsów użytkownika lub składni SQL, co ułatwia administratorom bazy danych zabezpieczanie dostępu do danych bez konieczności skalowania zarządzania dostępem do tożsamości natywnych dla chmury (IAM) i sieci.
Katalog Unity upraszcza uruchamianie bezpiecznych analiz w chmurze i zapewnia podział odpowiedzialności, który pomaga ograniczyć przekwalifikowanie lub podnoszenie kwalifikacji niezbędne zarówno dla administratorów, jak i użytkowników końcowych platformy. Zobacz Co to jest katalog Unity?.
Usługa Lakehouse udostępnia dane w organizacji w sposób równie prosty, jak przyznanie dostępu do zapytań dla tabeli czy widoku. W celu udostępniania poza bezpiecznym środowiskiem, Katalog Unity oferuje zarządzaną wersję Delta Sharing.
DevOps, CI/CD (ciągła integracja/ciągłe wdrażanie) i orkiestracja zadań
Cykle rozwoju dla potoków ETL, modeli uczenia maszynowego i pulpitów nawigacyjnych do analizy mają swoje unikalne wyzwania. Usługa Azure Databricks umożliwia wszystkim użytkownikom korzystanie z jednego źródła danych, co zmniejsza zduplikowane nakłady pracy i raportowanie poza synchronizacją. Ponadto udostępniając zestaw typowych narzędzi do przechowywania wersji, automatyzowania, planowania, wdrażania kodu i zasobów produkcyjnych, można uprościć obciążenie związane z monitorowaniem, orkiestracją i operacjami.
Zadania harmonogramują uruchomienie notesów Azure Databricks, zapytań SQL i innego dowolnego kodu. Pakiety zasobów usługi Databricks umożliwiają programowe definiowanie, wdrażanie i uruchamianie zasobów usługi Databricks, takich jak zadania i potoki. foldery Git umożliwiają synchronizowanie projektów usługi Azure Databricks z wieloma popularnymi dostawcami usługi Git.
Aby zapoznać się z najlepszymi praktykami i zaleceniami dotyczącymi CI/CD, zobacz Najlepsze praktyki i zalecane przepływy pracy CI/CD w usłudze Databricks. Aby zapoznać się z pełnym omówieniem narzędzi dla deweloperów, zobacz Programowanie w usłudze Databricks.
Analiza danych w czasie rzeczywistym i analiza danych strumieniowych
Usługa Azure Databricks wykorzystuje strukturalne przesyłanie strumieniowe platformy Apache Spark do obsługi danych przesyłanych strumieniowo i przyrostowych zmian danych. Strukturalne przesyłanie strumieniowe ściśle integruje się z Delta Lake, a te technologie stanowią podstawy zarówno dla potoków deklaratywnych Lakeflow, jak i Auto Loader. Zobacz pojęcia streamingu strukturalnego.