Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
W 2025 r. wydano następujące funkcje i ulepszenia języka SQL usługi Databricks.
Listopad 2025 r.
Usługa Databricks SQL w wersji 2025.35 jest wdrażana w kanale Current.
20 listopada 2025 r.
Usługa Databricks SQL w wersji 2025.35 jest wdrażana do kanału Current. Zobacz funkcje w wersji 2025.35.
Alerty SQL usługi Databricks są teraz dostępne w publicznej wersji zapoznawczej
14 listopada 2025 r.
- Alerty SQL usługi Databricks: najnowsza wersja alertów SQL usługi Databricks z nowym środowiskiem edycji jest teraz dostępna w publicznej wersji zapoznawczej. Zobacz Alerty SQL usługi Databricks.
Poprawka wizualizacji edytora SQL
6 listopada 2025 r.
- Rozwiązano problem z wyświetlaniem etykietek narzędzi: rozwiązano problem polegający na tym, że etykietki narzędzi były ukryte za legendą w wizualizacjach notesu i edytora SQL.
Październik 2025 r.
Usługa Databricks SQL w wersji 2025.35 jest teraz dostępna w wersji zapoznawczej
30 października 2025 r.
Usługa Databricks SQL w wersji 2025.35 jest teraz dostępna w kanale Podgląd. Zapoznaj się z poniższą sekcją, aby dowiedzieć się więcej o nowych funkcjach, zmianach zachowań i poprawkach błędów.
EXECUTE IMMEDIATE używanie wyrażeń stałych
Teraz można przekazywać wyrażenia stałe jako ciągi SQL i jako argumenty do oznaczeń parametrów w EXECUTE IMMEDIATE komendach.
LIMIT ALL obsługa cyklicznych CT
Teraz możesz użyć LIMIT ALL do usunięcia ograniczenia całkowitego rozmiaru dla rekursywnych typowych wyrażeń tabeli (CTE).
st_dump obsługa funkcji
Teraz możesz użyć st_dump funkcji , aby uzyskać tablicę zawierającą pojedyncze geometrie geometrii danych wejściowych. Zobacz st_dump funkcję.
Funkcje pierścienia wewnętrznego wielokątnego są teraz obsługiwane
Teraz możesz użyć następujących funkcji do pracy z wielokątnymi pierścieniami wewnętrznymi:
-
st_numinteriorrings: Pobierz liczbę granic wewnętrznych (pierścieni) wielokąta. Zobaczst_numinteriorringsfunkcję. -
st_interiorringn: Wyodrębnij n-tą wewnętrzną granicę wielokąta i zwróć ją jako linię. Zobaczst_interiorringnfunkcję.
Obsługa informacji o odświeżaniu MV/ST w programie DESCRIBE EXTENDED AS JSON
Azure Databricks teraz generuje sekcję dotyczącą widoku zmaterializowanego i odświeżania tabeli strumieniowej w danych wyjściowych DESCRIBE EXTENDED AS JSON, w tym czas ostatniego odświeżenia, typ odświeżania, stan i harmonogram.
Dodawanie kolumny metadanych do DESCRIBE QUERY i DESCRIBE TABLE
Azure Databricks teraz zawiera kolumnę metadanych w danych wyjściowych DESCRIBE QUERY i DESCRIBE TABLE dla metadanych semantycznych.
W przypadku DESCRIBE QUERY, podczas opisywania zapytania z widokami metryk, semantyczne metadane są propagowane za pośrednictwem zapytania, jeśli wymiary są bezpośrednio przywoływane, a miary używają funkcji MEASURE().
W przypadku DESCRIBE TABLEelementu kolumna metadanych jest wyświetlana tylko dla widoków metryk, a nie innych typów tabel.
Prawidłowa obsługa struktur o wartości null podczas usuwania NullType kolumn
Podczas zapisywania w tabelach Delta Azure Databricks teraz poprawnie zachowuje wartości struktury null podczas usuwania kolumn NullType ze schematu. Wcześniej struktury null zostały niepoprawnie zastąpione wartościami struktur innych niż null, w których wszystkie pola zostały ustawione na null.
Nowe środowisko edytowania alertów
20 października 2025 r.
- Nowe środowisko edytowania alertów: tworzenie lub edytowanie alertu jest teraz otwierane w nowym edytorze wielokarty, zapewniając ujednolicony przepływ pracy edycji. Zobacz Alerty SQL usługi Databricks.
Poprawka wizualizacji
9 października 2025 r.
- Wybór legendy dla serii z aliasami nazw: Wybór legendy działa teraz poprawnie dla wykresów w edytorze SQL i w notesach.
Metadane semantyczne w widokach metryk
2 października 2025 r.
Teraz można zdefiniować metadane semantyczne w widoku metryki. Metadane semantyczne pomagają narzędziom AI, takim jak Genie Agents (dawniej Genie Spaces) i pulpity AI/BI, skuteczniej interpretować i wykorzystywać Twoje dane.
Aby korzystać z metadanych semantycznych, widok metryki musi używać specyfikacji YAML w wersji 1.1 lub nowszej i uruchamiać je w środowisku Databricks Runtime 17.3 lub nowszym. Wersja SQL usługi Databricks odpowiadająca wersji 2025.30, jest dostępna w kanale w wersji próbnej dla magazynów SQL.
Zobacz Metadane agenta w widokach metryk i Zaktualizuj do YAML 1.1.
Wrzesień 2025 r.
Usługa Databricks SQL w wersji 2025.30 jest teraz dostępna w wersji zapoznawczej
25 września 2025 r.
Usługa Databricks SQL w wersji 2025.30 jest teraz dostępna w kanale Preview. Zapoznaj się z poniższą sekcją, aby dowiedzieć się więcej o nowych funkcjach, zmianach zachowań i poprawkach błędów.
Sortowania oparte na protokole UTF8 obsługują teraz operator LIKE
Teraz możesz użyć funkcji LIKE z kolumnami, które mają włączone jedno z następujących sortowań: UTF8_Binary, UTF8_Binary_RTRIM, UTF8_LCASE, UTF8_LCASE_RTRIM. Zobacz Kolażowanie.
ST_ExteriorRing funkcja jest teraz obsługiwana
Teraz możesz użyć ST_ExteriorRing funkcji , aby wyodrębnić zewnętrzną granicę wielokąta i zwrócić ją jako ciąg liniowy. Zobacz st_exteriorring funkcję.
Deklarowanie wielu zmiennych sesji lub zmiennych lokalnych w jednej DECLARE instrukcji
Teraz można zadeklarować wiele sesji lub zmiennych lokalnych tego samego typu i wartości domyślnej w jednej DECLARE instrukcji. Zobacz DECLARE VARIABLE i złożoną instrukcję BEGIN END.
Obsługa TEMPORARY słowa kluczowego do tworzenia widoków metryk
Teraz możesz użyć słowa kluczowego TEMPORARY podczas tworzenia widoku metryki. Tymczasowe widoki metryk są widoczne tylko w sesji, która je utworzyła i są usuwane po zakończeniu sesji. Zobacz CREATE VIEW.
DESCRIBE CONNECTION pokazuje ustawienia środowiska dla połączeń JDBC
Azure Databricks teraz zawiera ustawienia środowiska zdefiniowane przez użytkownika w danych wyjściowych DESCRIBE CONNECTION dla połączeń JDBC, które obsługują sterowniki niestandardowe i działają w izolacji. Inne typy połączeń pozostają niezmienione.
Składnia SQL dla opcji odczytu Delta w zapytaniach przesyłania strumieniowego
Teraz można określić opcje odczytu Delta dla zapytań przesyłania strumieniowego opartych na języku SQL przy użyciu klauzuli WITH. Przykład:
SELECT * FROM STREAM tbl WITH (SKIPCHANGECOMMITS=true, STARTINGVERSION=X);
Poprawne wyniki dla split pustego wyrażenia regularnego i limitu dodatniego
Azure Databricks teraz zwraca poprawne wyniki przy użyciu split function z pustym wyrażeniem regularnym i limitem dodatnim. Wcześniej funkcja niepoprawnie obcinała pozostały ciąg zamiast dołączać go do ostatniego elementu.
Napraw url_decode i try_url_decode obsługę błędów w Photon
W aplikacji Photon try_url_decode() i url_decode() razem z failOnError = false teraz zwracają wynik NULL dla nieprawidłowych ciągów zakodowanych w URL zamiast zakończenia zapytania niepowodzeniem.
Sierpień 2025 r.
Domyślne ustawienie magazynu jest teraz dostępne w wersji beta
28 sierpnia 2025 r.
Ustaw domyślny magazyn, który zostanie automatycznie wybrany w selektorze zasobów obliczeniowych w edytorze SQL, pulpitach nawigacyjnych sztucznej inteligencji/analizy biznesowej, agentach Genie (dawniej Genie Spaces), alertach i Eksploratorze wykazu. Użytkownicy indywidualni mogą zastąpić to ustawienie, wybierając inny magazyn przed uruchomieniem zapytania. Użytkownicy mogą również definiować własny domyślny magazyn na poziomie użytkownika, który będzie stosowany podczas ich sesji. Zobacz Ustawianie domyślnego magazynu SQL dla obszaru roboczego i Ustawianie domyślnego magazynu na poziomie użytkownika.
Usługa Databricks SQL w wersji 2025.25 jest wdrażana w bieżącej wersji
21 sierpnia 2025 r.
Usługa Databricks SQL w wersji 2025.25 jest wdrażana w kanale Current od 20 sierpnia do 28 sierpnia 2025 r. Zobacz funkcje w wersji 2025.25.
Usługa Databricks SQL w wersji 2025.25 jest teraz dostępna w wersji zapoznawczej
14 sierpnia 2025 r.
Usługa Databricks SQL w wersji 2025.25 jest teraz dostępna w kanale Preview. Zapoznaj się z poniższą sekcją, aby dowiedzieć się więcej o nowych funkcjach i zmianach zachowań.
Rekursywne typowe wyrażenia tabeli (rCTE) są ogólnie dostępne
Rekursywne typowe wyrażenia tabeli (rCTE) są ogólnie dostępne. Nawiguj po danych hierarchicznych przy użyciu samoodwołującego się CTE z UNION ALL, aby podążać za relacją rekursywną.
Obsługa sortowania domyślnego na poziomie schematu i wykazu
Teraz można ustawić domyślne sortowanie schematów i katalogów. Dzięki temu można zdefiniować sortowanie, które ma zastosowanie do wszystkich obiektów utworzonych w schemacie lub wykazie, zapewniając spójne zachowanie sortowania w danych.
Obsługa wyrażeń przestrzennych SQL oraz typów danych GEOMETRY i GEOGRAPHY
Teraz można przechowywać dane geoprzestrzenne we wbudowanych GEOMETRY kolumnach i GEOGRAPHY w celu zwiększenia wydajności zapytań przestrzennych. W tej wersji dodano ponad 80 nowych wyrażeń przestrzennych SQL, w tym funkcji importowania, eksportowania, mierzenia, konstruowania, edytowania, walidacji, przekształcania i określania relacji topologicznych ze sprzężeniami przestrzennymi. Zobacz funkcje geoprzestrzenne ST, GEOGRAPHY typ i GEOMETRY typ.
Obsługa sortowania domyślnego na poziomie schematu i wykazu
Teraz można ustawić domyślne sortowanie schematów i katalogów. Dzięki temu można zdefiniować sortowanie, które ma zastosowanie do wszystkich obiektów utworzonych w schemacie lub wykazie, zapewniając spójne zachowanie sortowania w danych.
Lepsza obsługa opcji JSON za pomocą polecenia VARIANT
Funkcje from_json i to_json teraz poprawnie stosują opcje JSON podczas pracy ze schematami najwyższego poziomu VARIANT . Zapewnia to spójne zachowanie z innymi obsługiwanymi typami danych.
Obsługa sygnatury CZASOWEJ BEZ składni STREFY CZASOWEJ
Teraz można określić TIMESTAMP WITHOUT TIME ZONE zamiast TIMESTAMP_NTZ. Ta zmiana poprawia zgodność ze standardem SQL.
Rozwiązano problem z korelacją podzapytania
Azure Databricks nie koreluje już błędnie semantycznie równoważnych wyrażeń agregujących między podzapytaniem a jego zapytaniem zewnętrznym. Wcześniej może to prowadzić do nieprawidłowych wyników zapytania.
Rzucany jest błąd w przypadku nieprawidłowych CHECK ograniczeń
Azure Databricks teraz zgłasza AnalysisException, jeśli nie można rozpoznać wyrażenia ograniczenia CHECK podczas sprawdzania poprawności ograniczeń.
Surowsze reguły łączenia strumień-strumień w trybie dopisywania
Azure Databricks teraz nie zezwala na zapytania strumieniowe w trybie dodawania, które używają połączenia strumienia ze strumieniem, a następnie agregacji przez okno czasowe, chyba że znaki wodne są zdefiniowane po obu stronach. Zapytania bez odpowiednich znaków wodnych mogą generować wyniki inne niż ostateczne, naruszając gwarancje trybu dołączania.
Nowy edytor SQL jest ogólnie dostępny
14 sierpnia 2025 r.
Nowy edytor SQL jest teraz ogólnie dostępny. Nowy edytor SQL udostępnia ujednolicone środowisko tworzenia z obsługą wielu wyników instrukcji, wbudowaną historię wykonywania, współpracę w czasie rzeczywistym, rozszerzoną integrację asystenta usługi Databricks i dodatkowe funkcje produktywności. Zobacz Pisanie zapytań i eksplorowanie danych w nowym edytorze SQL.
Stała obsługa limitu czasu dla zmaterializowanych widoków i tabel przesyłania strumieniowego
14 sierpnia 2025 r.
Nowe zasady limitu czasu dla zmaterializowanych widoków oraz tabel strumieniowych utworzonych w Databricks SQL:
- Zmaterializowane widoki i tabele przesyłania strumieniowego utworzone po 14 sierpnia 2025 r. będą miały automatycznie stosowaną przerwę w działaniu magazynu danych.
- W przypadku zmaterializowanych widoków i tabel przesyłania strumieniowego utworzonych przed 14 sierpnia 2025 r. uruchom polecenie
CREATE OR REFRESH, aby zsynchronizować ustawienie limitu czasu z konfiguracją limitu czasu magazynu. - Wszystkie zmaterializowane widoki i tabele przesyłania strumieniowego mają teraz domyślny limit czasu dwóch dni.
Lipiec 2025 r.
Wstępne zakresy dat dla parametrów w edytorze SQL
31 lipca 2025 r.
W nowym edytorze SQL można teraz wybrać spośród wstępnie ustawionych zakresów dat, takich jak Ten tydzień, Ostatnie 30 dni lub Ostatni rok podczas korzystania z parametrów znacznika czasu, daty i zakresu dat. Te ustawienia wstępne umożliwiają szybsze stosowanie typowych filtrów czasu bez ręcznego wprowadzania dat.
Lista zadań i potoków teraz zawiera SQL Pipelines Databricks
29 lipca 2025 r.
Lista Zadania i potoki zawiera teraz potoki dla zmaterializowanych widoków i tabel przesyłania strumieniowego utworzonych za pomocą usługi Databricks SQL.
Wbudowana historia wykonywania w edytorze SQL
24 lipca 2025 r.
Historia wykonania inline jest teraz dostępna w nowym edytorze SQL, dzięki czemu można szybko uzyskać dostęp do poprzednich wyników bez ponownego wykonywania zapytań. Łatwe odwoływanie się do poprzednich wykonań, przechodzenie bezpośrednio do poprzednich profilów zapytań lub porównywanie czasów uruchamiania i stanów — wszystkie w kontekście bieżącego zapytania.
Usługa Databricks SQL w wersji 2025.20 jest teraz dostępna w Current.
17 lipca 2025 r.
Databricks SQL w wersji 2025.20 jest wprowadzany etapami do kanału Bieżącego. Aby uzyskać informacje o funkcjach i aktualizacjach w tej wersji, zobacz funkcje 2025.20.
Aktualizacje edytora SQL
17 lipca 2025 r.
Ulepszenia nazwanych parametrów: parametry dotyczące zakresu dat oraz wyboru wielokrotnego są teraz obsługiwane. Aby uzyskać informacje o parametrach zakresu dat, zobacz Dodawanie zakresu dat przy użyciu parametrów
.mini.max. Aby zapoznać się z parametrami wielokrotnego wyboru, zobacz Przekazywanie wielu wartości jako ciągu.Zaktualizowany układ nagłówka w edytorze SQL: przycisk uruchamiania i selektor wykazu zostały przeniesione do nagłówka, tworząc więcej miejsca w pionie na potrzeby pisania zapytań.
Wsparcie Git dla alertów
17 lipca 2025 r.
Teraz możesz używać folderów Git usługi Databricks do śledzenia zmian alertów i zarządzania nimi. Aby śledzić alerty za pomocą Git, umieść je w folderze Git Databricks. Nowo sklonowane alerty są wyświetlane tylko na stronie listy alertów lub interfejsie API po interakcji z nimi przez użytkownika. Wstrzymano harmonogramy i muszą zostać ręcznie wznowione przez użytkowników. Zobacz Jak działa integracja Gita z alertami.
Usługa Databricks SQL w wersji 2025.20 jest teraz dostępna w wersji zapoznawczej
3 lipca 2025 r.
Databricks SQL w wersji 2025.20 jest teraz dostępny w kanale wersja testowa. Zapoznaj się z poniższą sekcją, aby dowiedzieć się więcej o nowych funkcjach i zmianach zachowań.
Obsługa procedur SQL
Skrypty SQL można teraz enkapsulować w procedurze przechowywanej jako zasób wielokrotnego użytku w Unity Catalog. Procedurę można utworzyć przy użyciu polecenia CREATE PROCEDURE , a następnie wywołać ją za pomocą polecenia CALL .
Ustaw domyślne sortowanie dla funkcji SQL
Użycie nowej klauzuli DEFAULT COLLATION w poleceniu CREATE FUNCTION określa domyślne sortowanie stosowane do parametrów STRING, typu zwracania oraz literałów STRING wewnątrz funkcji.
Obsługa rekursywnych typowych wyrażeń tabelarycznych (rCTE)
Azure Databricks obsługuje teraz nawigację danych hierarchicznych przy użyciu recursive common table expressions (rCTEs).
Użyj rekursywnego CTE z UNION ALL do śledzenia relacji rekurencyjnej.
Obsługa ALL CATALOGS schematów SHOW
Składnia SHOW SCHEMAS jest aktualizowana w celu zaakceptowania następującej składni:
SHOW SCHEMAS [ { FROM | IN } { catalog_name | ALL CATALOGS } ] [ [ LIKE ] pattern ]
Gdy ALL CATALOGS jest określony w zapytaniu SHOW, wykonywanie przechodzi przez wszystkie aktywne katalogi, które obsługują przestrzenie nazw przy użyciu menedżera katalogu (DsV2). Dla każdego wykazu zawiera on przestrzenie nazw najwyższego poziomu.
Atrybuty wyjściowe i schemat polecenia zostały zmodyfikowane w celu dodania catalog kolumny wskazującej wykaz odpowiadającej przestrzeni nazw. Nowa kolumna zostanie dodana na końcu atrybutów wyjściowych, jak pokazano poniżej:
Poprzednie dane wyjściowe
| Namespace |
|------------------|
| test-namespace-1 |
| test-namespace-2 |
Nowe dane wyjściowe
| Namespace | Catalog |
|------------------|----------------|
| test-namespace-1 | test-catalog-1 |
| test-namespace-2 | test-catalog-2 |
Klastrowanie cieczy teraz kompaktuje wektory usuwania bardziej efektywnie.
Delta tables z klastrowaniem Liquid teraz stosują zmiany fizyczne z wektorów usuwania bardziej efektywnie, gdy OPTIMIZE jest uruchomione. Aby uzyskać więcej informacji, zobacz Stosowanie zmian do plików danych Parquet.
Zezwalaj na wyrażenia niedeterministyczne w UPDATE/INSERT wartościach kolumn dla operacji MERGE
Azure Databricks teraz umożliwia używanie wyrażeń niedeterministycznych w wartościach kolumn aktualizowanych i wstawianych w operacjach MERGE. Jednak wyrażenia niedeterministyczne w warunkach instrukcji MERGE nie są obsługiwane.
Można na przykład wygenerować wartości dynamiczne lub losowe dla kolumn:
MERGE INTO target USING source
ON target.key = source.key
WHEN MATCHED THEN UPDATE SET target.value = source.value + rand()
Może to być przydatne w przypadku prywatności danych przez zaciemnianie rzeczywistych danych przy zachowaniu właściwości danych (takich jak średnie wartości lub inne obliczone kolumny).
Obsługa słowa kluczowego VAR do deklarowania i usuwania zmiennych SQL
Składnia SQL do deklarowania i usuwania zmiennych teraz obsługuje słowo kluczowe VAR oprócz VARIABLE. Ta zmiana łączy składnię we wszystkich operacjach związanych ze zmiennymi, co zwiększa spójność i zmniejsza zamieszanie dla użytkowników, którzy już używają VAR podczas ustawiania zmiennych.
CREATE VIEW klauzule na poziomie kolumny teraz zgłaszają błędy, gdy klauzula ma zastosowanie tylko do zmaterializowanych widoków
CREATE VIEW polecenia, które określają klauzulę dotyczącą kolumny, prawidłową tylko dla MATERIALIZED VIEW, teraz zgłaszają błąd. Klauzule dotyczące poleceń CREATE VIEW to:
NOT NULL- Określony typ danych, taki jak
FLOATlubSTRING DEFAULTCOLUMN MASK
Czerwiec 2025 r.
Uaktualnienia silnika bezserwerowego SQL Databricks
11 czerwca 2025 r.
Następujące uaktualnienia silnika są teraz wdrażane na całym świecie, a ich dostępność będzie rozszerzana na wszystkie regiony w nadchodzących tygodniach.
- Mniejsze opóźnienie: pulpity nawigacyjne, zadania ETL i mieszane obciążenia działają teraz szybciej, z poprawą do 25%. Uaktualnienie jest automatycznie stosowane do bezserwerowych magazynów SQL Bez dodatkowych kosztów ani konfiguracji.
- Wykonywanie zapytań predykcyjnych (PQE): funkcja PQE monitoruje zadania w czasie rzeczywistym i dynamicznie dostosowuje wykonywanie zapytań, aby uniknąć niesymetryczności, rozlewów i niepotrzebnej pracy.
- Fotonowe przetwarzanie wektorowe: przechowuje dane w kompaktowym formacie kolumnowym, sortuje je w szybkiej pamięci podręcznej procesora CPU i przetwarza wiele wartości jednocześnie przy użyciu instrukcji wektoryzowanych. Zwiększa to przepustowość obciążeń ograniczonych przez CPU, takich jak duże łączenia i rozległa agregacja.
Aktualizacje interfejsu użytkownika
5 czerwca 2025 r.
-
Ulepszenia szczegółowych informacji o zapytaniach: Odwiedzanie strony Historia zapytań teraz emituje
listHistoryQuerieszdarzenie. Otwarcie profilu zapytania powoduje teraz emisjęgetHistoryQueryzdarzenia.
Maj 2025 r.
Widoki metryk są dostępne w publicznej wersji zapoznawczej
29 maja 2025 r.
Widoki metryk w Unity Catalog zapewniają scentralizowany sposób definiowania i zarządzania spójnymi, powtarzalnymi oraz nadzorowanymi podstawowymi metrykami biznesowymi. Abstrahują one złożoną logikę biznesową w scentralizowaną definicję, umożliwiając organizacjom definiowanie kluczowych wskaźników wydajności raz i używanie ich spójnie w narzędziach raportowania, takich jak pulpity nawigacyjne, agenci Genie (dawniej Genie Spaces) i alerty. Użyj magazynu SQL działającego w kanale wersji testowej (2025.16) lub innego zasobu obliczeniowego z uruchomionym środowiskiem Databricks Runtime 16.4 lub nowszym, aby pracować z widokami metryk. Zobacz Widoki metryk Unity Catalog.
Aktualizacje interfejsu użytkownika
29 maja 2025 r.
-
Nowe ulepszenia edytora SQL:
- Nowe zapytania w folderze Wersje robocze: nowe zapytania są domyślnie tworzone w folderze Wersje robocze. Po zapisaniu lub zmianie nazwy są one automatycznie przenoszone z wersji roboczych.
-
Obsługa fragmentów kodu zapytania: teraz można tworzyć i ponownie używać fragmentów zapytań — wstępnie zdefiniowanych segmentów języka SQL, takich jak
JOINlubCASEwyrażeń, z obsługą autouzupełniania i dynamicznych punktów wstawiania. Utwórz fragmenty kodu, wybierając pozycję Wyświetl>fragmenty zapytania. - Zdarzenia dziennika inspekcji: zdarzenia dziennika inspekcji są teraz emitowane dla akcji wykonywanych w nowym edytorze SQL.
- Filtry wpływają na wizualizacje: filtry stosowane do tabel wyników mają teraz również wpływ na wizualizacje, umożliwiając interaktywną eksplorację bez modyfikowania zapytania SQL.
Nowa wersja alertu w wersji beta
22 maja 2025 r.
Nowa wersja alertów jest teraz dostępna w wersji beta. Ta wersja upraszcza tworzenie alertów i zarządzanie nimi, konsolidując konfigurację zapytań, warunki, harmonogramy i miejsca docelowe powiadomień w jednym interfejsie. Nadal można używać starszych alertów wraz z nową wersją. Zobacz Alerty SQL usługi Databricks.
Aktualizacje interfejsu użytkownika
22 maja 2025 r.
- Formatowanie etykiet narzędziowych na wykresach: Etykiety narzędziowe na wykresach w edytorze SQL i notesach są teraz zgodne z formatowaniem liczb zdefiniowanym na karcie Etykiety danych. Zobacz Wizualizacje w notesach usługi Databricks i edytorze SQL.
Usługa Databricks SQL w wersji 2025.16 jest teraz dostępna
15 maja 2025 r.
Usługa Databricks SQL w wersji 2025.16 dostępna jest teraz w kanale Preview. Zapoznaj się z poniższą sekcją, aby dowiedzieć się więcej o nowych funkcjach, zmianach zachowań i poprawkach błędów.
IDENTIFIER obsługa jest teraz dostępna w usłudze Databricks SQL na potrzeby operacji katalogu
Teraz możesz użyć klauzuli IDENTIFIER podczas wykonywania następujących operacji katalogu:
CREATE CATALOGDROP CATALOGCOMMENT ON CATALOGALTER CATALOG
Ta nowa składnia umożliwia dynamiczne określanie nazw katalogów przy użyciu parametrów zdefiniowanych dla tych operacji, co umożliwia bardziej elastyczne i wielokrotnego użytku przepływy pracy SQL. Jako przykład składni rozważ CREATE CATALOG IDENTIFIER(:param) , gdzie param jest podany parametr, aby określić nazwę katalogu.
Aby uzyskać więcej informacji, zobacz IDENTIFIER klauzulę.
Teraz wyrażenia zebrane udostępniają automatycznie generowane aliasy przejściowe.
Automatycznie wygenerowane aliasy dla zestawionych wyrażeń będą teraz zawsze deterministycznie uwzględniać COLLATE informacje. Automatycznie wygenerowane aliasy są przejściowe (niestabilne) i nie należy na nich polegać. Zamiast tego, jako najlepsze rozwiązanie, należy używać expression AS alias spójnie i jawnie.
Funkcje UNION, EXCEPT i INTERSECT wewnątrz widoku oraz EXECUTE IMMEDIATE teraz zwracają poprawne wyniki.
Zapytania dotyczące definicji widoku tymczasowego i trwałego z kolumnami najwyższego poziomu UNION/EXCEPT/INTERSECTi bez aliasów zwróciły wcześniej nieprawidłowe wyniki, ponieważ UNION/EXCEPT/INTERSECT słowa kluczowe zostały uznane za aliasy. Teraz te zapytania będą poprawnie wykonywać całą operację zestawu.
EXECUTE IMMEDIATE ... INTO z top-level UNION/EXCEPT/INTERSECT i niealiasowanymi kolumnami również zapisał niepoprawny wynik operacji na zbiorze do określonej zmiennej, ponieważ parser interpretował te słowa kluczowe jako aliasy. Podobnie zapytania SQL z nieprawidłowym tekstem końcowym również były akceptowane. Operacje zbiorów w takich przypadkach zapisują poprawny wynik do określonej zmiennej lub zakończą się niepowodzeniem w przypadku nieprawidłowego tekstu SQL.
Nowe funkcje listagg i string_agg
Teraz możesz użyć funkcji listagg lub string_agg do agregowania wartości STRING i BINARY w grupie. Aby uzyskać więcej informacji, zobacz string_agg .
Poprawka dotycząca grupowania w aliasowanych literałach liczb całkowitych przerwała działanie niektórych operacji
Wyrażenia grupowania na aliasowaną literałę liczby całkowitej zostały wcześniej przerwane dla niektórych operacji, takich jak MERGE INTO. Na przykład to wyrażenie zwróci GROUP_BY_POS_OUT_OF_RANGE , ponieważ wartość (val) zostanie zastąpiona 202001:
merge into t
using
(select 202001 as val, count(current_date) as total_count group by val) on 1=1
when not matched then insert (id, name) values (val, total_count)
To zostało naprawione. Aby rozwiązać problem w istniejących zapytaniach, sprawdź, czy używane stałe nie są równe pozycji kolumny, która musi znajdować się w wyrażeniach grupowania.
Włącz flagę, aby uniemożliwić wyłączenie materializacji materiału źródłowego przy MERGE operacjach
Wcześniej użytkownicy mogli wyłączyć materializację źródła w MERGE, ustawiając merge.materializeSource na none. Po włączeniu nowej flagi będzie to zabronione i spowoduje błąd. Usługa Databricks planuje włączyć flagę tylko dla klientów, którzy wcześniej nie używali tej flagi konfiguracji, więc żaden klient nie powinien zauważyć żadnych zmian w zachowaniu.
Kwiecień 2025 r.
Usługa Databricks SQL w wersji 2025.15 jest teraz dostępna
10 kwietnia 2025 r.
Usługa Databricks SQL w wersji 2025.15 jest teraz dostępna w kanale Preview. Zapoznaj się z poniższą sekcją, aby dowiedzieć się więcej o nowych funkcjach, zmianach zachowań i poprawkach błędów.
Edytowanie wielu kolumn przy użyciu ALTER TABLE
Teraz można zmienić wiele kolumn w jednej ALTER TABLE instrukcji. Zobacz ALTER TABLE klauzulę ... COLUMN
Obniżenie protokołu tabeli Delta jest ogólnie dostępne z ochroną punktu kontrolnego.
DROP FEATURE jest ogólnie dostępny do usuwania funkcji tabel Delta Lake i obniżania wersji protokołu tabeli. Domyślnie DROP FEATURE tworzy teraz chronione punkty kontrolne, aby zapewnić bardziej zoptymalizowane i uproszczone doświadczenie związane z przesiadką, które nie wymaga czasu oczekiwania ani skracania historii. Zobacz Upuszczanie funkcji tabeli Delta Lake i obniżanie poziomu protokołu tabeli.
Pisanie proceduralnych skryptów SQL opartych na języku ANSI SQL/PSM (publiczna wersja zapoznawcza)
Teraz można używać funkcji skryptów opartych na języku ANSI SQL/PSM do pisania logiki proceduralnej za pomocą języka SQL, w tym instrukcji warunkowych, pętli, zmiennych lokalnych i obsługi wyjątków. Zobacz skrypty SQL.
Sortowanie domyślne na poziomie tabeli i widoku
Teraz można określić domyślne sortowanie tabel i widoków. Upraszcza to tworzenie tabel i widoków, w których wszystkie lub większość kolumn ma to samo sortowanie. Zobacz Kolażowanie.
Nowe funkcje H3
Dodano następujące funkcje H3:
Zakończono obsługę starszych pulpitów nawigacyjnych
10 kwietnia 2025 r.
Zakończono oficjalną obsługę starszych pulpitów nawigacyjnych. Nie można już tworzyć ani klonować starszych pulpitów nawigacyjnych przy użyciu interfejsu użytkownika lub interfejsu API. Databricks nadal rozwiązuje krytyczne problemy z zabezpieczeniami i awarie usług, ale zaleca korzystanie z dashboardów AI/BI dla wszystkich nowych projektów. Aby dowiedzieć się więcej na temat pulpitów nawigacyjnych sztucznej inteligencji/analizy biznesowej, zobacz Pulpity nawigacyjne. Aby uzyskać pomoc dotyczącą migracji, zobacz Klonowanie starszego pulpitu nawigacyjnego do pulpitu nawigacyjnego AI/BI i Używanie interfejsów API pulpitu nawigacyjnego do tworzenia pulpitów nawigacyjnych i zarządzania nimi.
Niestandardowe opcje autoformatowania dla zapytań SQL
3 kwietnia 2025 r.
Dostosuj opcje autoformatowania dla wszystkich zapytań SQL. Zobacz Instrukcje JĘZYKA SQL w formacie niestandardowym.
Rozwiązano problem z wizualizacjami boxplot
3 kwietnia 2025 r.
Rozwiązano problem polegający na tym, że wizualizacje pola SQL usługi Databricks z tylko osią x kategorii nie wyświetlały poprawnie kategorii i pasków. Wizualizacje są teraz renderowane zgodnie z oczekiwaniami.
Uprawnienie CAN VIEW dla magazynów SQL jest w publicznej wersji zapoznawczej
3 kwietnia 2025 r.
Uprawnienie CAN VIEW jest teraz dostępne w publicznej wersji zapoznawczej. To uprawnienie umożliwia użytkownikom monitorowanie magazynów SQL, w tym skojarzonej historii zapytań i profilów zapytań. Użytkownicy z uprawnieniem CAN VIEW nie mogą uruchamiać zapytań w usłudze SQL Warehouse bez udzielenia dodatkowych uprawnień. Zobacz ACL magazynu SQL.
Marzec 2025 r.
Aktualizacje interfejsu użytkownika
27 marca 2025 r.
- Profile zapytań zaktualizowane w celu zwiększenia użyteczności: profile zapytań zostały zaktualizowane w celu zwiększenia użyteczności i szybkiego uzyskiwania dostępu do kluczowych szczegółowych informacji. Zobacz Profil zapytania.
Aktualizacje interfejsu użytkownika
20 marca 2025 r.
- Przenoszenie własności magazynu SQL do jednostki usługi: teraz możesz użyć interfejsu użytkownika do przeniesienia własności magazynu do jednostki usługi.
Aktualizacje interfejsu użytkownika
6 marca 2025 r.
- Wykresy dwuosiowe obsługują teraz powiększenie: teraz możesz kliknąć i przeciągnąć, aby powiększyć wykresy z dwiema osiami.
- Przypnij kolumny tabeli: teraz możesz przypiąć kolumny tabeli do lewej strony wyświetlanej tabeli. Kolumny pozostają widoczne podczas przewijania tabeli w prawo. Zobacz Ustawienia kolumny.
- Rozwiązano problem z kombinowanymi wykresami: Rozwiązano niedopasowanie między etykietami osi x i słupkami podczas korzystania z pola czasowego na osi x.
Luty 2025 rok
Usługa Databricks SQL w wersji 2025.10 jest teraz dostępna
21 lutego 2025 r.
Wersja 2025.10 Databricks SQL jest teraz dostępna w kanale Preview. Zapoznaj się z poniższą sekcją, aby dowiedzieć się więcej o nowych funkcjach, zmianach zachowań i poprawkach błędów.
W Delta Sharing historia tabel jest domyślnie włączona
Udziały utworzone przy użyciu polecenia SQL ALTER SHARE <share> ADD TABLE <table> teraz mają domyślnie włączone udostępnianie historii (WITH HISTORY). Zobacz ALTER SHARE.
Instrukcje SQL dotyczące poświadczeń zwracają błąd, gdy pojawia się niezgodność typu poświadczeń.
Jeśli w tej wersji typ poświadczeń określony w instrukcji SQL zarządzania poświadczeniami nie jest zgodny z typem argumentu poświadczeń, zwracany jest błąd i instrukcja nie jest uruchamiana. Na przykład w przypadku oświadczenia DROP STORAGE CREDENTIAL 'credential-name', jeśli credential-name nie jest poświadczeniem magazynowym, oświadczenie zawodzi z powodu błędu.
Ta zmiana jest wprowadzana w celu zapobiegania błędom użytkownika. Wcześniej te instrukcje zostały uruchomione pomyślnie, nawet jeśli przekazano poświadczenia niezgodne z określonym typem poświadczeń. Na przykład następująca instrukcja pomyślnie usunie storage-credential: DROP SERVICE CREDENTIAL storage-credential.
Ta zmiana ma wpływ na następujące oświadczenia:
- DROP CREDENTIAL
- ALTER CREDENTIAL
- DESCRIBE CREDENTIAL
- GRANT…NA…POWIERNIK
- REVOKE…NA…POWIERNIK
- SHOW GRANTS ON... POŚWIADCZENIA
Użyj timestampdiff i timestampadd w wyrażeniach kolumn wygenerowanych
Wyrażenia kolumn wygenerowane przez usługę Delta Lake obsługują teraz funkcje timestampdiff i timestampadd.
Obsługa składni potoku SQL
Teraz możesz tworzyć potoki SQL. Pipeline SQL strukturyzuje standardowe zapytanie, takie jak SELECT c2 FROM T WHERE c1 = 5, w sekwencję kroków, jak pokazano w poniższym przykładzie.
FROM T
|> SELECT c2
|> WHERE c1 = 5
Aby dowiedzieć się więcej o obsługiwanej składni potoków SQL, zobacz Składnia potoku SQL.
Aby zapoznać się z tym rozszerzeniem międzysektorowym, zobacz SQL Has Problems (Problemy z SQL). Możemy je naprawić: składnia potoku w SQL (Google Research).
Wysyłanie żądania HTTP przy użyciu http_request funkcji
Teraz można tworzyć połączenia HTTP i za ich pomocą wysyłać żądania HTTP przy użyciu funkcji http_request.
Aktualizacja DESCRIBE TABLE zwraca metadane jako ustrukturyzowany JSON
Teraz możesz użyć polecenia DESCRIBE TABLE AS JSON, aby zwrócić metadane tabeli jako dokument JSON. Dane wyjściowe JSON są bardziej ustrukturyzowane niż domyślny raport czytelny dla człowieka i mogą służyć do programowego interpretowania schematu tabeli. Aby dowiedzieć się więcej, zobacz DESCRIBE TABLE AS JSON.
Końcowe porównania niewrażliwe na wielkość liter
Dodano obsługę sortowania ignorującego końcowe spacje. Na przykład te sortowania traktują 'Hello' i 'Hello ' jako równe. Więcej informacji można znaleźć w porządku sortowania RTRIM.
Ulepszone przetwarzanie klonowania przyrostowego
Ta wersja zawiera poprawkę dla przypadku brzegowego, w którym CLONE może ponownie kopiować pliki już skopiowane z tabeli źródłowej do tabeli docelowej. Zobacz Klonowanie tabeli w Azure Databricks.
Aktualizacje interfejsu użytkownika
13 lutego 2025 r.
- Podgląd metadanych Unity Catalog w odnajdowaniu danych: Podgląd metadanych zasobów Unity Catalog przez najechanie kursorem na zasób w przeglądarce schematu. Ta funkcja jest dostępna w Eksploratorze Katalogu i innych interfejsach, w których używa się przeglądarki schematów, takich jak pulpity AI/BI oraz edytor SQL.
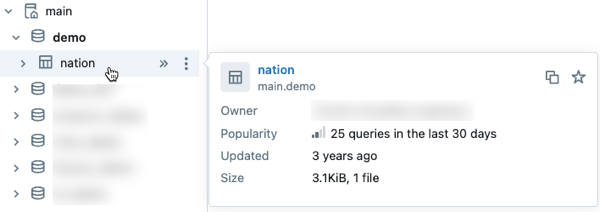
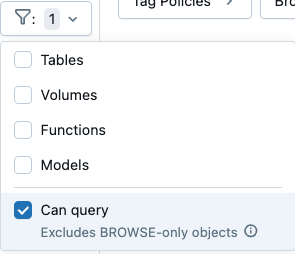
- Filtruj, aby znaleźć zasoby danych, które można przeszukiwać: Ustawienia filtru przeglądarki schematu w Eksploratorze katalogu zawierają teraz pole wyboru Możliwość przeszukiwania. Wybranie tej opcji wyklucza obiekty, które można wyświetlić, ale nie można ich zapytać.
Styczeń 2025 r.
Aktualizacje interfejsu użytkownika
30 stycznia 2025 r.
Ukończony wykres liczby zapytań dla magazynów SQL (publiczna wersja zapoznawcza): nowy ukończony wykres liczby zapytań jest teraz dostępny w interfejsie użytkownika monitorowania usługi SQL Warehouse. Ten wykres przedstawia liczbę zapytań zakończonych w przedziale czasu, w tym anulowanych i zakończonych niepowodzeniem zapytań. Wykres może być używany z innymi wykresami i tabelą Historia zapytań w celu oceny wydajności magazynu i rozwiązywania problemów z jej wydajnością. Zapytanie jest przydzielane do przedziału czasowego, w którym zostało ukończone. Liczby są średnie na minutę. Aby uzyskać więcej informacji, zobacz Monitorowanie magazynu SQL.
Rozwinięte wyświetlanie danych na wykresach edytora SQL: wizualizacje utworzone w edytorze SQL obsługują teraz maksymalnie 15 000 wierszy danych.
Usługa Databricks SQL w wersji 2024.50 jest teraz dostępna
23 stycznia 2025 r.
Usługa Databricks SQL w wersji 2024.50 jest teraz dostępna w kanale wersji zapoznawczej . Zapoznaj się z poniższą sekcją, aby dowiedzieć się więcej o nowych funkcjach, zmianach zachowań i poprawkach błędów.
Typ danych VARIANT nie może być już używany z operacjami, które wymagają porównań
W zapytaniach zawierających VARIANT typu danych nie można użyć następujących klauzul ani operatorów:
DISTINCTINTERSECTEXCEPTUNIONDISTRIBUTE BY
Te operacje wykonują porównania, a porównania korzystające z typu danych VARIANT generują niezdefiniowane wyniki i nie są obsługiwane w usłudze Databricks. Jeśli używasz typu VARIANT w obciążeniach lub tabelach Azure Databricks, usługa Databricks zaleca następujące zmiany:
- Zaktualizuj zapytania lub wyrażenia, aby jawnie konwertować
VARIANTwartości na typy danych inne niżVARIANT. - Jeśli masz pola, które muszą być używane z dowolną z powyższych operacji, wyodrębnij te pola z
VARIANTtypu danych i zapisz je przy użyciu typów danych innych niżVARIANT.
Aby dowiedzieć się więcej, zobacz Dane wariantu zapytania.
Obsługa parametryzacji klauzuli USE CATALOG with IDENTIFIER
Klauzula IDENTIFIER jest obsługiwana dla instrukcji USE CATALOG. Dzięki tej obsłudze można sparametryzować bieżący wykaz na podstawie zmiennej ciągu lub znacznika parametru.
COMMENT ON COLUMN obsługa tabel i widoków
Instrukcja COMMENT ON obsługuje zmienianie komentarzy dla kolumn widoku i tabeli.
Nowe funkcje SQL
Dostępne są następujące nowe wbudowane funkcje SQL:
- dayname(expr) zwraca trzyliterowy angielski akronim dnia tygodnia dla danej daty.
- uniform(expr1, expr2 [,seed]) zwraca wartość losową z niezależnymi i identycznymi wartościami rozproszonymi w określonym zakresie liczb.
-
randstr(length) zwraca losowy ciąg znaków alfanumerycznych
length.
Wywołanie nazwanego parametru dla większej liczby funkcji
Następujące funkcje obsługują wywołanie parametrów o nazwie :
Zagnieżdżone typy teraz prawidłowo akceptują ograniczenia o wartości NULL
W tej wersji naprawiono usterkę wpływającą na niektóre kolumny generowane przez Delta dla typów zagnieżdżonych, na przykład STRUCT. Te kolumny czasami niepoprawnie odrzucają wyrażenia w oparciu o ograniczenia NULL lub NOT NULL zagnieżdżonych pól. To zostało naprawione.
Aktualizacje interfejsu użytkownika edytora SQL
15 stycznia 2025 r.
Nowy edytor SQL (publiczna wersja zapoznawcza) zawiera następujące ulepszenia interfejsu użytkownika:
- Ulepszone środowisko pobierania: dane wyjściowe zapytań są automatycznie nazwane po pobraniu zapytania.
-
Klucze skróty do określania rozmiaru czcionek: Użyj
Alt +iAlt -(Windows/Linux) lubOpt +iOpt -(macOS), aby szybko dostosować rozmiar czcionki w edytorze SQL. -
Wzmianki użytkowników w komentarzach: oznaczaj określonych użytkowników
@w komentarzach, aby wysyłać im powiadomienia e-mail. - Szybsze nawigowanie między kartami: przełączanie kart jest teraz szybsze do 80% dla załadowanych kart i 62% szybsze dla niezaładowanych kart.
- Usprawniony wybór magazynu: informacje o rozmiarze usługi SQL Warehouse są wyświetlane bezpośrednio w selektorze obliczeniowym, aby ułatwić wybór.
-
Skróty do edytowania parametrów: Użyj
Ctrl + Enter(Windows/Linux) lubCmd + Enter(macOS), aby wykonywać zapytania podczas edytowania wartości parametrów. - Rozszerzona kontrola wersji: wyniki zapytań są zachowywane w historii wersji w celu lepszej współpracy.
Aktualizacje wizualizacji wykresu
15 stycznia 2025 r.
Nowy system wykresów z lepszą wydajnością, ulepszonymi schematami kolorów i szybszą interakcyjnością jest teraz ogólnie dostępny. Zobacz Wizualizacje w notesach usługi Databricks oraz edytorze SQL oraz typach wizualizacji w notesie i edytorze SQL.