TDSP to elastyczna i iteracyjna metodologia nauki o danych, której można użyć do wydajnego dostarczania rozwiązań analizy predykcyjnej i aplikacji sztucznej inteligencji. TDSP zwiększa współpracę zespołu i uczenie się, zalecając optymalne sposoby współpracy ról zespołu. TDSP zawiera najlepsze rozwiązania i struktury od firmy Microsoft i innych liderów branży, aby pomóc zespołowi w efektywnym wdrażaniu inicjatyw nauki o danych. TDSP umożliwia pełne realizowanie korzyści z programu analitycznego.
Ten artykuł zawiera omówienie dostawcy TDSP i jego głównych składników. Przedstawia wskazówki dotyczące implementowania dostawcy TDSP przy użyciu narzędzi i infrastruktury firmy Microsoft. Więcej szczegółowych zasobów można znaleźć w tym artykule.
Kluczowe składniki TDSP
TDSP ma następujące kluczowe składniki:
- Definicja cyklu życia nauki o danych
- Ustandaryzowana struktura projektu
- Infrastruktura i zasoby idealne dla projektów nauki o danych
- Odpowiedzialne używanie sztucznej inteligencji: i zobowiązanie do rozwoju sztucznej inteligencji opartej na zasadach etycznych
Cykl życia nauki o danych
TDSP zapewnia cykl życia, którego można użyć do tworzenia projektów nauki o danych. Cykl życia przedstawia pełne kroki, które należy wykonać pomyślnie.
Zestaw TDSP oparty na zadaniach można połączyć z innymi cyklami życia nauki o danych, takimi jak proces wyszukiwania danych w różnych branżach (CRISP-DM), odnajdywanie wiedzy w bazach danych (KDD) lub inny proces niestandardowy. Na wysokim poziomie te różne metodologie mają wiele wspólnego.
Użyj tego cyklu życia, jeśli masz projekt nauki o danych, który jest częścią inteligentnej aplikacji. Inteligentne aplikacje wdrażają modele uczenia maszynowego lub sztucznej inteligencji na potrzeby analizy predykcyjnej. Możesz również użyć tego procesu do eksploracyjnych projektów nauki o danych i improwizowanych projektów analitycznych.
Cykl życia TDSP składa się z pięciu głównych etapów, które zespół wykonuje iteracyjnie. Te etapy obejmują:
Oto wizualna reprezentacja cyklu życia TDSP:
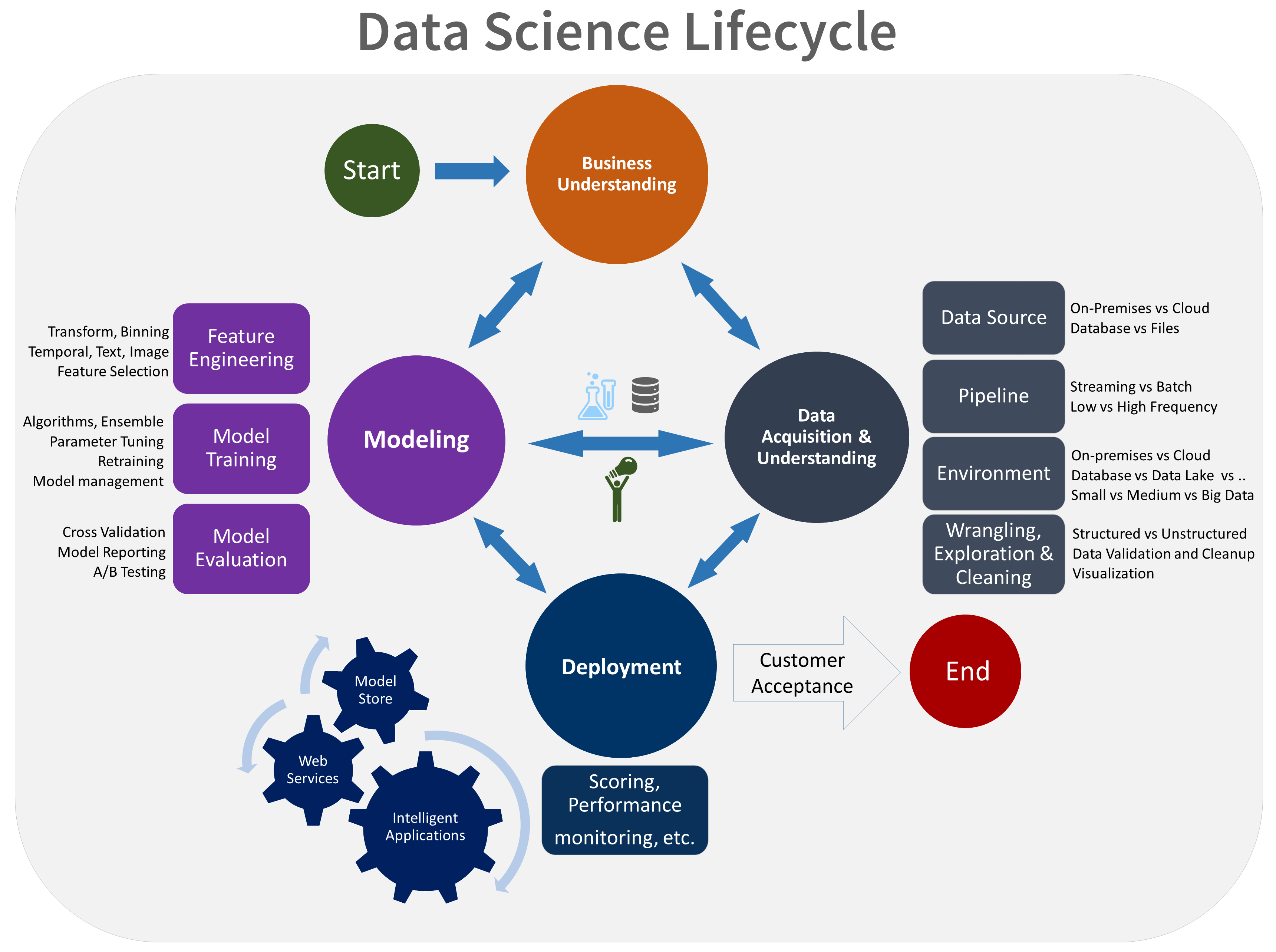
Aby uzyskać więcej informacji na temat celów, zadań i artefaktów dokumentacji dla każdego etapu, zobacz Cykl życia TDSP.
Te zadania i artefakty są zgodne z rolami projektu, takimi jak:
- Architekt rozwiązań
- Menedżer projektu
- Inżynier danych
- Mistrz danych
- Deweloper aplikacji
- Lider projektu
Na poniższym diagramie przedstawiono zadania (w kolorze niebieskim) i artefakty (w kolorze zielonym), które odpowiadają każdemu etapowi cyklu życia przedstawionemu na osi poziomej i ról przedstawionych na osi pionowej.

Ustandaryzowana struktura projektu
Twój zespół może używać infrastruktury platformy Azure do organizowania zasobów nauki o danych.
Usługa Azure Machine Learning obsługuje bibliotekę MLflow typu open source. Zalecamy używanie biblioteki MLflow do nauki o danych i zarządzania projektami sztucznej inteligencji. Rozwiązanie MLflow jest przeznaczone do zarządzania pełnym cyklem życia uczenia maszynowego. Trenuje i obsługuje modele na różnych platformach, dzięki czemu można używać spójnego zestawu narzędzi niezależnie od tego, gdzie są uruchamiane eksperymenty. Możesz użyć platformy MLflow lokalnie na komputerze, na zdalnym obiekcie docelowym obliczeniowym, na maszynie wirtualnej lub w wystąpieniu obliczeniowym uczenia maszynowego.
Rozwiązanie MLflow składa się z kilku kluczowych funkcji:
Śledzenie eksperymentów: możesz użyć biblioteki MLflow, aby śledzić eksperymenty, w tym parametry, wersje kodu, metryki i pliki wyjściowe. Ta funkcja ułatwia porównywanie różnych przebiegów i efektywne zarządzanie procesem eksperymentowania.
Kod pakietu: zapewnia standardowy format pakowania kodu uczenia maszynowego, który obejmuje zależności i konfiguracje. To opakowanie ułatwia odtwarzanie przebiegów i udostępnianie kodu innym osobom.
Zarządzanie modelami: platforma MLflow udostępnia funkcje do zarządzania modelami wersji i zarządzania nimi. Obsługuje ona różne struktury uczenia maszynowego, dzięki czemu można przechowywać, wersje i obsługiwać modele.
Obsługa i wdrażanie modeli: platforma MLflow integruje możliwości obsługi modeli i wdrażania, dzięki czemu można łatwo wdrażać modele w różnych środowiskach.
Rejestrowanie modeli: możesz zarządzać cyklem życia modelu, który obejmuje przechowywanie wersji, przejścia na etapy i adnotacje. Za pomocą platformy MLflow można zachować scentralizowany magazyn modeli w środowisku współpracy.
Korzystanie z interfejsu API i interfejsu użytkownika: wewnątrz platformy Azure rozwiązanie MLflow jest powiązane w interfejsie API usługi Machine Learning w wersji 2, dzięki czemu można programowo korzystać z systemu. Możesz użyć witryny Azure Portal do interakcji z interfejsem użytkownika.
Platforma MLflow upraszcza i standandaryzuje proces opracowywania uczenia maszynowego, od eksperymentowania po wdrożenie.
Usługa Machine Learning integruje się z repozytoriami Git, dzięki czemu można używać usług zgodnych z usługą Git, takich jak GitHub, GitLab, Bitbucket, Azure DevOps lub inna usługa zgodna z usługą Git. Oprócz zasobów, które są już śledzone w usłudze Machine Learning, zespół może opracować własną taksonomię w ramach usługi zgodnej z usługą Git w celu przechowywania innych danych projektu, takich jak:
- Dokumentacja
- Dane projektu: na przykład końcowy raport projektu
- Raport dotyczący danych: taki jak słownik danych lub raporty dotyczące jakości danych
- Model: na przykład raporty modelu
- Kod
- Przygotowywanie danych
- Opracowywanie modeli
- Operacjonalizacja, która obejmuje zabezpieczenia i zgodność
Infrastruktura i zasoby
Przewodnik rozwiązywania problemów zawiera zalecenia dotyczące zarządzania udostępnioną analizą i infrastrukturą magazynu w następujących kategoriach:
- Systemy plików w chmurze do przechowywania zestawów danych
- Bazy danych w chmurze
- Klastry danych big data korzystające z języka SQL lub Spark
- Sztuczna inteligencja i usługi uczenia maszynowego
Systemy plików w chmurze do przechowywania zestawów danych
Systemy plików w chmurze mają kluczowe znaczenie dla dostawcy TDSP z kilku powodów:
Scentralizowany magazyn danych: systemy plików w chmurze zapewniają scentralizowaną lokalizację do przechowywania zestawów danych, co jest niezbędne do współpracy między członkami zespołu ds. nauki o danych. Centralizacja zapewnia, że wszyscy członkowie zespołu będą mogli uzyskać dostęp do najbardziej aktualnych danych i zmniejszyć ryzyko pracy z nieaktualnymi lub niespójnymi zestawami danych.
Skalowalność: systemy plików w chmurze mogą obsługiwać duże ilości danych, co jest wspólne w projektach nauki o danych. Systemy plików zapewniają skalowalne rozwiązania magazynu, które rosną wraz z potrzebami projektu. Umożliwiają zespołom przechowywanie i przetwarzanie ogromnych zestawów danych bez obaw o ograniczenia sprzętu.
Ułatwienia dostępu: Dzięki systemom plików w chmurze można uzyskiwać dostęp do danych z dowolnego miejsca za pomocą połączenia internetowego. Ten dostęp jest ważny w przypadku zespołów rozproszonych lub gdy członkowie zespołu muszą pracować zdalnie. Systemy plików w chmurze ułatwiają bezproblemową współpracę i zapewniają, że dane są zawsze dostępne.
Zabezpieczenia i zgodność: dostawcy usług w chmurze często implementują niezawodne środki zabezpieczeń, takie jak szyfrowanie, mechanizmy kontroli dostępu i zgodność z branżowymi standardami i przepisami. Silne środki zabezpieczeń mogą chronić poufne dane i pomóc zespołowi spełnić wymagania prawne i prawne.
Kontrola wersji: systemy plików w chmurze często obejmują funkcje kontroli wersji, których zespoły mogą używać do śledzenia zmian w zestawach danych w czasie. Kontrola wersji ma kluczowe znaczenie dla zachowania integralności danych i odtworzenia wyników w projektach nauki o danych. Ułatwia również przeprowadzanie inspekcji i rozwiązywanie wszelkich pojawiających się problemów.
Integracja z narzędziami: systemy plików w chmurze mogą bezproblemowo integrować się z różnymi narzędziami i platformami do nauki o danych. Integracja narzędzi obsługuje łatwiejsze pozyskiwanie danych, przetwarzanie danych i analizę danych. Na przykład usługa Azure Storage dobrze integruje się z usługą Machine Learning, Azure Databricks i innymi narzędziami do nauki o danych.
Współpraca i udostępnianie: Systemy plików w chmurze ułatwiają udostępnianie zestawów danych innym członkom zespołu lub uczestnikom projektu. Systemy te obsługują funkcje współpracy, takie jak foldery udostępnione i zarządzanie uprawnieniami. Funkcje współpracy ułatwiają pracę zespołową i zapewniają odpowiednim osobom dostęp do potrzebnych im danych.
Efektywność kosztowa: Systemy plików w chmurze mogą być bardziej ekonomiczne niż utrzymywanie lokalnych rozwiązań magazynu. Dostawcy usług w chmurze mają elastyczne modele cenowe, które obejmują opcje płatności zgodnie z rzeczywistym użyciem, które mogą pomóc w zarządzaniu kosztami w oparciu o rzeczywiste wymagania dotyczące użycia i magazynowania projektu nauki o danych.
Odzyskiwanie po awarii: systemy plików w chmurze zwykle obejmują funkcje tworzenia kopii zapasowych danych i odzyskiwania po awarii. Te funkcje pomagają chronić dane przed awariami sprzętu, przypadkowymi usunięciami i innymi awariami. Zapewnia spokój i wspiera ciągłość operacji nauki o danych.
Automatyzacja i integracja przepływu pracy: systemy magazynowania w chmurze mogą integrować się z zautomatyzowanymi przepływami pracy, co umożliwia bezproblemowy transfer danych między różnymi etapami procesu nauki o danych. Automatyzacja może pomóc zwiększyć wydajność i zmniejszyć nakład pracy ręcznej w celu zarządzania danymi.
Zalecane zasoby platformy Azure dla systemów plików w chmurze
- Azure Blob Storage — kompleksowa dokumentacja usługi Azure Blob Storage, która jest skalowalną usługą magazynu obiektów dla danych bez struktury.
- Azure Data Lake Storage — informacje o usłudze Azure Data Lake Storage Gen2, przeznaczone do analizy danych big data i obsługują zestawy danych na dużą skalę.
- Azure Files — szczegóły dotyczące usługi Azure Files , która udostępnia w pełni zarządzane udziały plików w chmurze.
Podsumowując, systemy plików w chmurze mają kluczowe znaczenie dla dostawcy TDSP, ponieważ zapewniają skalowalne, bezpieczne i dostępne rozwiązania magazynu, które obsługują cały cykl życia danych. Systemy plików w chmurze umożliwiają bezproblemową integrację danych z różnych źródeł, które obsługują kompleksowe pozyskiwanie i zrozumienie danych. Analitycy danych mogą używać systemów plików w chmurze do wydajnego przechowywania dużych zestawów danych, zarządzania nimi i uzyskiwania do nich dostępu. Ta funkcja jest niezbędna do trenowania i wdrażania modeli uczenia maszynowego. Te systemy zwiększają również współpracę, umożliwiając członkom zespołu udostępnianie i pracę nad danymi jednocześnie w ujednoliconym środowisku. Systemy plików w chmurze zapewniają niezawodne funkcje zabezpieczeń, które pomagają chronić dane i zapewniać zgodność z wymaganiami prawnymi, co jest niezbędne do utrzymania integralności danych i zaufania.
Bazy danych w chmurze
Bazy danych w chmurze odgrywają kluczową rolę w programie TDSP z kilku powodów:
Skalowalność: Bazy danych w chmurze zapewniają skalowalne rozwiązania, które mogą łatwo rosnąć w celu zaspokojenia rosnących potrzeb związanych z danymi projektu. Skalowalność ma kluczowe znaczenie dla projektów nauki o danych, które często obsługują duże i skomplikowane zestawy danych. Bazy danych w chmurze mogą obsługiwać różne obciążenia bez konieczności ręcznej interwencji lub uaktualnień sprzętowych.
Optymalizacja wydajności: Deweloperzy optymalizują bazy danych w chmurze pod kątem wydajności, korzystając z funkcji, takich jak automatyczne indeksowanie, optymalizacja zapytań i równoważenie obciążenia. Te funkcje pomagają zapewnić szybkie i wydajne pobieranie i przetwarzanie danych, co ma kluczowe znaczenie dla zadań nauki o danych, które wymagają dostępu do danych w czasie rzeczywistym lub niemal w czasie rzeczywistym.
Ułatwienia dostępu i współpraca: usługa Teams może uzyskiwać dostęp do przechowywanych danych w bazach danych w chmurze z dowolnej lokalizacji. Ta dostępność wspiera współpracę między członkami zespołu, którzy mogą być rozproszeni geograficznie. Ułatwienia dostępu i współpraca są ważne dla rozproszonych zespołów lub osób, które pracują zdalnie. Bazy danych w chmurze obsługują środowiska wielu użytkowników, które umożliwiają równoczesny dostęp i współpracę.
Integracja z narzędziami do nauki o danych: bazy danych w chmurze bezproblemowo integrują się z różnymi narzędziami i platformami do nauki o danych. Na przykład bazy danych w chmurze platformy Azure dobrze integrują się z usługą Machine Learning, Usługą Power BI i innymi narzędziami do analizy danych. Ta integracja usprawnia potok danych, od pozyskiwania i przechowywania do analizy i wizualizacji.
Zabezpieczenia i zgodność: dostawcy usług w chmurze implementują niezawodne środki zabezpieczeń, które obejmują szyfrowanie danych, mechanizmy kontroli dostępu i zgodność z branżowymi standardami i przepisami. Środki zabezpieczeń chronią poufne dane i pomagają zespołowi spełnić wymagania prawne i prawne. Funkcje zabezpieczeń są niezbędne do utrzymania integralności danych i prywatności.
Efektywność kosztowa: bazy danych w chmurze często działają w modelu płatności zgodnie z rzeczywistym użyciem, co może być bardziej ekonomiczne niż utrzymywanie lokalnych systemów baz danych. Ta elastyczność cenowa umożliwia organizacjom efektywne zarządzanie budżetami i płacenie tylko za używane zasoby magazynu i zasobów obliczeniowych.
Automatyczne kopie zapasowe i odzyskiwanie po awarii: Bazy danych w chmurze zapewniają automatyczne rozwiązania do tworzenia kopii zapasowych i odzyskiwania po awarii. Te rozwiązania pomagają zapobiegać utracie danych, jeśli występują awarie sprzętowe, przypadkowe usunięcie lub inne awarie. Niezawodność ma kluczowe znaczenie dla utrzymania ciągłości i integralności danych w projektach nauki o danych.
Przetwarzanie danych w czasie rzeczywistym: wiele baz danych w chmurze obsługuje przetwarzanie i analizę danych w czasie rzeczywistym, co jest niezbędne w przypadku zadań nauki o danych, które wymagają najnowszych informacji. Ta funkcja ułatwia analitykom danych podejmowanie aktualnych decyzji na podstawie najnowszych dostępnych danych.
Integracja danych: bazy danych w chmurze mogą łatwo integrować się z innymi źródłami danych, bazami danych, magazynami danych typu lake i zewnętrznymi źródłami danych. Integracja ułatwia analitykom danych łączenie danych z wielu źródeł i zapewnia kompleksowy widok i bardziej zaawansowaną analizę.
Elastyczność i różnorodność: bazy danych w chmurze są dostępne w różnych formach, takich jak relacyjne bazy danych, bazy danych NoSQL i magazyny danych. Ta różnorodność umożliwia zespołom nauki o danych wybór najlepszego typu bazy danych dla określonych potrzeb, niezależnie od tego, czy wymagają magazynu danych ustrukturyzowanych, obsługi danych bez struktury, czy analizy danych na dużą skalę.
Obsługa zaawansowanej analizy: bazy danych w chmurze często są wyposażone w wbudowaną obsługę zaawansowanej analizy i uczenia maszynowego. Na przykład usługa Azure SQL Database udostępnia wbudowane usługi uczenia maszynowego. Te usługi ułatwiają analitykom danych wykonywanie zaawansowanych analiz bezpośrednio w środowisku bazy danych.
Zalecane zasoby platformy Azure dla baz danych w chmurze
- Azure SQL Database — dokumentacja usługi Azure SQL Database , w pełni zarządzana usługa relacyjnej bazy danych.
- Azure Cosmos DB — informacje o usłudze Azure Cosmos DB, globalnie rozproszonej, wielomodelowej usłudze bazy danych.
- Azure Database for PostgreSQL — przewodnik po usłudze Azure Database for PostgreSQL, usłudze zarządzanej bazy danych na potrzeby tworzenia i wdrażania aplikacji.
- Azure Database for MySQL — szczegóły dotyczące usługi Azure Database for MySQL, usługi zarządzanej dla baz danych MySQL.
Podsumowując, bazy danych w chmurze mają kluczowe znaczenie dla dostawcy TDSP, ponieważ zapewniają skalowalne, niezawodne i wydajne rozwiązania do przechowywania danych i zarządzania, które obsługują projekty oparte na danych. Ułatwiają bezproblemową integrację danych, która pomaga analitykom danych pozyskiwać, wstępnie przetwarzać i analizować duże zestawy danych z różnych źródeł. Bazy danych w chmurze umożliwiają szybkie wykonywanie zapytań i przetwarzanie danych, co jest niezbędne do tworzenia, testowania i wdrażania modeli uczenia maszynowego. Ponadto bazy danych w chmurze zwiększają współpracę, zapewniając scentralizowaną platformę dla członków zespołu w celu uzyskiwania dostępu do danych i pracy z nimi jednocześnie. Ponadto bazy danych w chmurze zapewniają zaawansowane funkcje zabezpieczeń i obsługę zgodności, aby zapewnić ochronę danych i zgodność ze standardami prawnymi, co ma kluczowe znaczenie dla zachowania integralności danych i zaufania.
Klastry danych big data korzystające z języka SQL lub Spark
Klastry danych big data, takie jak te korzystające z programu SQL lub Spark, mają podstawowe znaczenie dla dostawcy TDSP z kilku powodów:
Obsługa dużych ilości danych: klastry danych big data są zaprojektowane tak, aby efektywnie obsługiwać duże ilości danych. Projekty nauki o danych często obejmują ogromne zestawy danych, które przekraczają pojemność tradycyjnych baz danych. Klastry danych big data oparte na języku SQL i platforma Spark mogą zarządzać tymi danymi i przetwarzać je na dużą skalę.
Przetwarzanie rozproszone: klastry danych big data używają przetwarzania rozproszonego do rozpowszechniania danych i zadań obliczeniowych w wielu węzłach. Możliwość przetwarzania równoległego znacznie przyspiesza przetwarzanie danych i zadania analizy, co jest niezbędne do uzyskania terminowych szczegółowych informacji w projektach nauki o danych.
Skalowalność: klastry danych big data zapewniają wysoką skalowalność, zarówno w poziomie, dodając więcej węzłów, jak i w pionie przez zwiększenie mocy istniejących węzłów. Skalowalność pomaga zapewnić, że infrastruktura danych rośnie wraz z potrzebami projektu dzięki obsłudze rosnących rozmiarów danych i złożoności.
Integracja z narzędziami do nauki o danych: klastry danych big data dobrze integrują się z różnymi narzędziami i platformami do nauki o danych. Na przykład platforma Spark bezproblemowo integruje się z usługą Hadoop, a klastry SQL współpracują z różnymi narzędziami do analizy danych. Integracja ułatwia bezproblemowy przepływ pracy z pozyskiwania danych do analizy i wizualizacji.
Zaawansowana analiza: klastry danych big data obsługują zaawansowaną analizę i uczenie maszynowe. Na przykład platforma Spark udostępnia następujące wbudowane biblioteki:
- Uczenie maszynowe, MLlib
- Przetwarzanie grafu, GraphX
- Przetwarzanie strumieniowe, przesyłanie strumieniowe platformy Spark
Te możliwości ułatwiają analitykom danych wykonywanie złożonych analiz bezpośrednio w klastrze.
Przetwarzanie danych w czasie rzeczywistym: klastry danych big data, zwłaszcza te, które korzystają z platformy Spark, obsługują przetwarzanie danych w czasie rzeczywistym. Ta możliwość ma kluczowe znaczenie dla projektów wymagających analizy danych i podejmowania decyzji. Przetwarzanie w czasie rzeczywistym pomaga w scenariuszach, takich jak wykrywanie oszustw, zalecenia w czasie rzeczywistym i dynamiczne ceny.
Przekształcanie i wyodrębnianie, przekształcanie, ładowanie (ETL) : klastry danych big data są idealne do transformacji danych i procesów ETL. Mogą wydajnie obsługiwać złożone przekształcenia danych, czyszczenie i zadania agregacji, które są często niezbędne, zanim będzie można analizować dane.
Efektywność kosztowa: klastry danych big data mogą być ekonomiczne, szczególnie w przypadku korzystania z rozwiązań opartych na chmurze, takich jak Azure Databricks i inne usługi w chmurze. Te usługi zapewniają elastyczne modele cenowe, które obejmują płatność zgodnie z rzeczywistym użyciem, co może być bardziej ekonomiczne niż utrzymywanie lokalnej infrastruktury danych big data.
Odporność na uszkodzenia: klastry danych big data zostały zaprojektowane z myślą o odporności na uszkodzenia. Replikują dane między węzłami, aby zapewnić, że system pozostanie operacyjny nawet w przypadku awarii niektórych węzłów. Ta niezawodność ma kluczowe znaczenie dla utrzymania integralności danych i dostępności w projektach nauki o danych.
Integracja z usługą Data Lake: klastry danych big data często integrują się bezproblemowo z magazynami danych, co umożliwia analitykom danych uzyskiwanie dostępu do różnych źródeł danych i analizowanie ich w ujednolicony sposób. Integracja wspiera bardziej kompleksowe analizy poprzez wspieranie kombinacji danych ustrukturyzowanych i nieustrukturyzowanych.
Przetwarzanie oparte na języku SQL: w przypadku analityków danych, którzy znają język SQL, klastry danych big data, które współpracują z zapytaniami SQL, takimi jak Spark SQL lub SQL w usłudze Hadoop, udostępniają znany interfejs do wykonywania zapytań i analizowania danych big data. Ta łatwość użycia może przyspieszyć proces analizy i uczynić go bardziej dostępnym dla szerszego zakresu użytkowników.
Współpraca i udostępnianie: klastry danych big data obsługują środowiska współpracy, w których wielu analityków danych i analityków może współpracować z tymi samymi zestawami danych. Udostępniają one funkcje udostępniania kodu, notesów i wyników, które wspierają pracę zespołową i udostępnianie wiedzy.
Zabezpieczenia i zgodność: klastry danych big data zapewniają niezawodne funkcje zabezpieczeń, takie jak szyfrowanie danych, mechanizmy kontroli dostępu i zgodność ze standardami branżowymi. Funkcje zabezpieczeń chronią poufne dane i pomagają zespołowi spełnić wymagania prawne.
Zalecane zasoby platformy Azure dla klastrów danych big data
- Platforma Apache Spark w usłudze Machine Learning: integracja usługi Machine Learning z usługą Azure Synapse Analytics zapewnia łatwy dostęp do rozproszonych zasobów obliczeniowych za pośrednictwem platformy Apache Spark.
- Azure Synapse Analytics: kompleksowa dokumentacja usługi Azure Synapse Analytics, która integruje magazyn danych big data i danych.
Podsumowując, klastry danych big data, zarówno SQL, jak i Spark, mają kluczowe znaczenie dla dostawcy TDSP, ponieważ zapewniają moc obliczeniową i skalowalność niezbędną do wydajnego obsługi ogromnych ilości danych. Klastry danych big data umożliwiają analitykom danych wykonywanie złożonych zapytań i zaawansowanych analiz na dużych zestawach danych, które ułatwiają szczegółowe informacje i dokładne opracowywanie modeli. W przypadku korzystania z przetwarzania rozproszonego te klastry umożliwiają szybkie przetwarzanie i analizę danych, co przyspiesza ogólny przepływ pracy nauki o danych. Klastry danych big data obsługują również bezproblemową integrację z różnymi źródłami danych i narzędziami, co zwiększa możliwość pozyskiwania, przetwarzania i analizowania danych z wielu środowisk. Klastry danych big data promują również współpracę i powtarzalność, zapewniając ujednoliconą platformę, na której zespoły mogą efektywnie udostępniać zasoby, przepływy pracy i wyniki.
Sztuczna inteligencja i usługi uczenia maszynowego
Usługi sztucznej inteligencji i uczenia maszynowego (ML) są integralną częścią dostawcy TDSP z kilku powodów:
Analiza zaawansowana: usługi sztucznej inteligencji i uczenia maszynowego umożliwiają zaawansowaną analizę. Analitycy danych mogą używać zaawansowanych analiz do odkrywania złożonych wzorców, tworzenia przewidywań i generowania szczegółowych informacji, które nie są możliwe przy użyciu tradycyjnych metod analitycznych. Te zaawansowane możliwości mają kluczowe znaczenie dla tworzenia rozwiązań do nauki o danych o dużym wpływie.
Automatyzacja powtarzających się zadań: usługi sztucznej inteligencji i uczenia maszynowego mogą automatyzować powtarzające się zadania, takie jak czyszczenie danych, inżynieria cech i trenowanie modeli. Automatyzacja oszczędza czas i pomaga analitykom danych skupić się na bardziej strategicznych aspektach projektu, co zwiększa ogólną produktywność.
Zwiększona dokładność i wydajność: modele uczenia maszynowego mogą poprawić dokładność i wydajność przewidywań i analiz, ucząc się na podstawie danych. Modele te mogą stale się ulepszać, gdy stają się narażone na więcej danych, co prowadzi do lepszego podejmowania decyzji i bardziej niezawodnych wyników.
Skalowalność: usługi sztucznej inteligencji i uczenia maszynowego udostępniane przez platformy w chmurze, takie jak Machine Learning, są wysoce skalowalne. Mogą obsługiwać duże ilości danych i złożonych obliczeń, które ułatwiają zespołom nauki o danych skalowanie swoich rozwiązań w celu spełnienia rosnących wymagań bez obaw o podstawowe ograniczenia infrastruktury.
Integracja z innymi narzędziami: usługi sztucznej inteligencji i uczenia maszynowego bezproblemowo integrują się z innymi narzędziami i usługami w ekosystemie firmy Microsoft, takimi jak Azure Data Lake, Azure Databricks i Power BI. Integracja obsługuje usprawniony przepływ pracy z pozyskiwania i przetwarzania danych do wdrażania modelu i wizualizacji.
Wdrażanie modeli i zarządzanie nimi: usługi sztucznej inteligencji i uczenia maszynowego zapewniają niezawodne narzędzia do wdrażania modeli uczenia maszynowego i zarządzania nimi w środowisku produkcyjnym. Funkcje, takie jak kontrola wersji, monitorowanie i automatyczne ponowne trenowanie, pomagają zapewnić, że modele pozostają dokładne i skuteczne w czasie. Takie podejście upraszcza konserwację rozwiązań uczenia maszynowego.
Przetwarzanie w czasie rzeczywistym: usługi sztucznej inteligencji i uczenia maszynowego obsługują przetwarzanie i podejmowanie decyzji w czasie rzeczywistym. Przetwarzanie w czasie rzeczywistym jest niezbędne w przypadku aplikacji wymagających natychmiastowych szczegółowych informacji i akcji, takich jak wykrywanie oszustw, dynamiczne ceny i systemy rekomendacji.
Możliwość dostosowywania i elastyczność: usługi sztucznej inteligencji i uczenia maszynowego oferują szereg opcji dostosowywalnych, od wstępnie utworzonych modeli i interfejsów API po struktury do tworzenia niestandardowych modeli od podstaw. Ta elastyczność ułatwia zespołom nauki o danych dostosowanie rozwiązań do konkretnych potrzeb biznesowych i przypadków użycia.
Dostęp do najnowocześniejszych algorytmów: usługi sztucznej inteligencji i uczenia maszynowego zapewniają analitykom danych dostęp do najnowocześniejszych algorytmów i technologii opracowanych przez czołowych badaczy. Dostęp zapewnia, że zespół może korzystać z najnowszych postępów w zakresie sztucznej inteligencji i uczenia maszynowego w swoich projektach.
Współpraca i udostępnianie: platformy sztucznej inteligencji i uczenia maszynowego obsługują wspólne środowiska programistyczne, w których wielu członków zespołu może współpracować nad tym samym projektem, udostępniać kod i odtwarzać eksperymenty. Współpraca zwiększa pracę zespołową i pomaga zapewnić spójność w tworzeniu modeli.
Efektywność kosztowa: usługi sztucznej inteligencji i uczenia maszynowego w chmurze mogą być bardziej ekonomiczne niż tworzenie i utrzymywanie rozwiązań lokalnych. Dostawcy usług w chmurze mają elastyczne modele cenowe, które obejmują opcje płatności zgodnie z rzeczywistym użyciem, które mogą obniżyć koszty i zoptymalizować użycie zasobów.
Zwiększone zabezpieczenia i zgodność: usługi sztucznej inteligencji i uczenia maszynowego są wyposażone w niezawodne funkcje zabezpieczeń, takie jak szyfrowanie danych, bezpieczne mechanizmy kontroli dostępu i zgodność z branżowymi standardami i przepisami. Te funkcje pomagają chronić dane i modele oraz spełniać wymagania prawne i prawne.
Wstępnie utworzone modele i interfejsy API: wiele usług sztucznej inteligencji i uczenia maszynowego udostępnia wstępnie utworzone modele i interfejsy API dla typowych zadań, takich jak przetwarzanie języka naturalnego, rozpoznawanie obrazów i wykrywanie anomalii. Wstępnie utworzone rozwiązania mogą przyspieszyć opracowywanie i wdrażanie oraz pomóc zespołom szybko zintegrować możliwości sztucznej inteligencji z aplikacjami.
Eksperymentowanie i tworzenie prototypów: platformy sztucznej inteligencji i uczenia maszynowego zapewniają środowiska do szybkiego eksperymentowania i tworzenia prototypów. Analitycy danych mogą szybko testować różne algorytmy, parametry i zestawy danych, aby znaleźć najlepsze rozwiązanie. Eksperymentowanie i tworzenie prototypów obsługuje iteracyjne podejście do opracowywania modeli.
Zalecane zasoby platformy Azure dla usług sztucznej inteligencji i uczenia maszynowego
Usługa Machine Learning to główny zasób, który zalecamy w przypadku aplikacji do nauki o danych i dostawcy TDSP. Ponadto platforma Azure udostępnia usługi sztucznej inteligencji, które mają gotowe do użycia modele sztucznej inteligencji dla określonych aplikacji.
- Machine Learning: główna strona dokumentacji usługi Machine Learning obejmująca konfigurację, trenowanie modelu, wdrażanie itd.
- Usługi sztucznej inteligencji platformy Azure: informacje na temat usług sztucznej inteligencji, które udostępniają wstępnie utworzone modele sztucznej inteligencji na potrzeby zadań przetwarzania obrazów, mowy, języka i podejmowania decyzji.
Podsumowując, usługi sztucznej inteligencji i uczenia maszynowego mają kluczowe znaczenie dla dostawcy TDSP, ponieważ zapewniają zaawansowane narzędzia i struktury, które usprawniają opracowywanie, szkolenie i wdrażanie modeli uczenia maszynowego. Te usługi automatyzują złożone zadania, takie jak wybór algorytmu i dostrajanie hiperparametrów, co znacznie przyspiesza proces tworzenia modelu. Te usługi zapewniają również skalowalną infrastrukturę, która pomaga analitykom danych wydajnie obsługiwać duże zestawy danych i zadania intensywnie korzystające z obliczeń. Narzędzia sztucznej inteligencji i uczenia maszynowego bezproblemowo integrują się z innymi usługami platformy Azure i rozszerzają pozyskiwanie danych, przetwarzanie wstępne i wdrażanie modelu. Integracja ułatwia zapewnienie bezproblemowego kompleksowego przepływu pracy. Ponadto te usługi wspierają współpracę i powtarzalność. Zespoły mogą udostępniać szczegółowe informacje i skutecznie eksperymentować z wynikami i modelami, zachowując jednocześnie wysokie standardy zabezpieczeń i zgodności.
Odpowiedzialne AI
Dzięki rozwiązaniom sztucznej inteligencji lub uczenia maszynowego firma Microsoft promuje odpowiedzialne narzędzia sztucznej inteligencji w swoich rozwiązaniach sztucznej inteligencji i uczenia maszynowego. Te narzędzia obsługują standard odpowiedzialnej sztucznej inteligencji firmy Microsoft. Obciążenie musi nadal indywidualnie odpowiadać na szkody związane ze sztuczną inteligencją.
Recenzowane cytaty równorzędne
TDSP to dobrze ugruntowana metodologia, z którą zespoły korzystają w ramach zaangażowania firmy Microsoft. TDSP jest udokumentowany i badany w literaturze z przeglądem równorzędnym. Cytaty umożliwiają zbadanie funkcji i aplikacji TDSP. Aby uzyskać więcej informacji i listę cytatów, zobacz Cykl życia TDSP.