Wskazówki i wzorce dotyczące migracji usługi Azure Data Lake Storage
Możesz migrować dane, obciążenia i aplikacje z usługi Azure Data Lake Storage Gen1 do usługi Azure Data Lake Storage Gen2. W tym artykule wyjaśniono zalecane podejście do migracji i opisano różne wzorce migracji oraz informacje o tym, kiedy należy ich używać. Aby ułatwić czytanie, w tym artykule użyto terminu Gen1 do odwoływania się do usługi Azure Data Lake Storage Gen1 oraz terminu Gen2, aby zapoznać się z usługą Azure Data Lake Storage Gen2.
Uwaga
Usługa Azure Data Lake Storage Gen1 została wycofana. Zobacz ogłoszenie o wycofaniu tutaj. Zasoby usługi Data Lake Storage Gen1 nie są już dostępne.
Usługa Azure Data Lake Storage Gen2 jest oparta na usłudze Azure Blob Storage i udostępnia zestaw funkcji przeznaczonych do analizy danych big data. Usługa Data Lake Storage Gen2 łączy funkcje usługi Azure Data Lake Storage Gen1, takie jak semantyka systemu plików, katalog i zabezpieczenia na poziomie plików oraz skalowanie z niskim kosztem, magazynem warstwowym, wysoką dostępnością/odzyskiwaniem po awarii z usługi Azure Blob Storage.
Uwaga
Ponieważ usługi Gen1 i Gen2 są różne, nie ma środowiska uaktualniania w miejscu. Aby uprościć migrację do usługi Gen2 przy użyciu witryny Azure Portal, zobacz Migrowanie usługi Azure Data Lake Storage z 1. generacji do 2. generacji przy użyciu witryny Azure Portal.
Zalecane podejście
Aby przeprowadzić migrację z wersji Gen1 do 2. generacji, zalecamy następujące podejście.
Krok 1. Ocena gotowości
Krok 2. Przygotowanie do migracji
Krok 3. Migrowanie danych i obciążeń aplikacji
Krok 4. Migracja jednorazowa z generacji 1 do 2. generacji
Krok 1. Ocena gotowości
Dowiedz się więcej o ofercie usługi Data Lake Storage Gen2, a także o korzyściach, kosztach i ogólnej architekturze.
Przejrzyj listę znanych problemów , aby ocenić wszelkie luki w funkcjonalności.
Usługa Gen2 obsługuje funkcje magazynu obiektów blob, takie jak rejestrowanie diagnostyczne, warstwy dostępu i zasady zarządzania cyklem życia magazynu obiektów blob. Jeśli interesuje Cię użycie dowolnej z tych funkcji, zapoznaj się z bieżącym poziomem pomocy technicznej.
Przejrzyj bieżący stan wsparcia ekosystemu platformy Azure, aby upewnić się, że usługa Gen2 obsługuje wszystkie usługi, od których zależą Twoje rozwiązania.
Krok 2. Przygotowanie do migracji
Zidentyfikuj zestawy danych, które zostaną zmigrowane.
Skorzystaj z tej okazji, aby wyczyścić zestawy danych, których już nie używasz. O ile nie planujesz migrować wszystkich danych jednocześnie, pośmiń tę chwilę, aby zidentyfikować logiczne grupy danych, które można migrować w fazach.
Wykonaj analizę starzenia (lub podobną) na koncie gen1, aby określić, które pliki lub foldery pozostają w spisie przez długi czas lub mogą stać się przestarzałe.
Określ wpływ migracji na Twoją firmę.
Rozważmy na przykład, czy można sobie pozwolić na przestoje podczas migracji. Te zagadnienia mogą pomóc w zidentyfikowaniu odpowiedniego wzorca migracji i wybraniu najbardziej odpowiednich narzędzi.
Utwórz plan migracji.
Zalecamy te wzorce migracji. Możesz wybrać jeden z tych wzorców, połączyć je razem lub zaprojektować własny wzorzec niestandardowy.
Krok 3. Migrowanie danych, obciążeń i aplikacji
Migrowanie danych, obciążeń i aplikacji przy użyciu preferowanego wzorca. Zalecamy przyrostowe weryfikowanie scenariuszy.
Utwórz konto magazynu i włącz funkcję hierarchicznej przestrzeni nazw.
Migrowanie danych.
Skonfiguruj usługi w obciążeniach , aby wskazywały punkt końcowy usługi Gen2.
W przypadku klastrów usługi HDInsight można dodać ustawienia konfiguracji konta magazynu do pliku %HADOOP_HOME%/conf/core-site.xml. Jeśli planujesz migrację zewnętrznych tabel programu Hive z gen1 do gen2, pamiętaj o dodaniu ustawień konta magazynu do pliku %HIVE_CONF_DIR%/hive-site.xml.
Ustawienia każdego pliku można modyfikować przy użyciu narzędzia Apache Ambari. Aby znaleźć ustawienia konta magazynu, zobacz Hadoop Azure Support: ABFS — Azure Data Lake Storage Gen2(Obsługa platformy Azure: ABFS — Azure Data Lake Storage Gen2). W tym przykładzie użyto
fs.azure.account.keyustawienia w celu włączenia autoryzacji klucza współdzielonego:<property> <name>fs.azure.account.key.abfswales1.dfs.core.windows.net</name> <value>your-key-goes-here</value> </property>Aby uzyskać linki do artykułów, które ułatwiają konfigurowanie usług HDInsight, Azure Databricks i innych usług platformy Azure do korzystania z usługi Gen2, zobacz Usługi platformy Azure, które obsługują usługę Azure Data Lake Storage Gen2.
Zaktualizuj aplikacje, aby korzystały z interfejsów API gen2. Zobacz następujące przewodniki:
Zaktualizuj skrypty, aby używały poleceń cmdlet programu PowerShell usługi Data Lake Storage Gen2 i poleceń interfejsu wiersza polecenia platformy Azure.
Wyszukaj odwołania identyfikatora URI zawierające ciąg
adl://w plikach kodu lub w notesach usługi Databricks, plikach HQL apache Hive lub innych plikach używanych w ramach obciążeń. Zastąp te odwołania identyfikatorem URI w formacie Gen2 nowego konta magazynu. Na przykład: identyfikator URI 1. generacji:adl://mydatalakestore.azuredatalakestore.net/mydirectory/myfilemoże stać się .abfss://myfilesystem@mydatalakestore.dfs.core.windows.net/mydirectory/myfileSkonfiguruj zabezpieczenia na koncie, aby obejmowały role platformy Azure, zabezpieczenia na poziomie plików i folderów oraz zapory i sieci wirtualne usługi Azure Storage.
Krok 4. Migracja jednorazowa z generacji 1 do 2. generacji
Po upewnieniu się, że aplikacje i obciążenia są stabilne w usłudze Gen2, możesz rozpocząć korzystanie z usługi Gen2 w celu zaspokojenia scenariuszy biznesowych. Wyłącz wszystkie pozostałe potoki uruchomione w usłudze Gen1 i likwiduj konto usługi Gen1.
Możliwości 1. generacji i 2. generacji
W tej tabeli porównaliśmy możliwości usługi Gen1 z generacji 2.
Wzorce gen1–Gen2
Wybierz wzorzec migracji, a następnie zmodyfikuj ten wzorzec zgodnie z potrzebami.
| Wzorzec migracji | Szczegóły |
|---|---|
| Lift and Shift | Najprostszy wzorzec. Idealne rozwiązanie, jeśli potoki danych mogą sobie pozwolić na przestoje. |
| Kopia przyrostowa | Podobnie jak lift and shift, ale z mniejszym przestojem. Idealne rozwiązanie do kopiowania dużych ilości danych. |
| Podwójny potok | Idealny dla potoków, które nie mogą sobie pozwolić na przestoje. |
| Synchronizacja dwukierunkowa | Podobnie jak w przypadku podwójnego potoku, ale z bardziej etapowym podejściem, które jest odpowiednie dla bardziej skomplikowanych potoków. |
Przyjrzyjmy się bliżej każdemu wzorcu.
Wzorzec lift-and-shift
Jest to najprostszy wzorzec.
Zatrzymaj wszystkie operacje zapisu w usłudze Gen1.
Przenoszenie danych z gen1 do 2. generacji. Zalecamy usługę Azure Data Factory lub przy użyciu witryny Azure Portal. Listy ACL kopiują dane.
Wskazywanie operacji pozyskiwania i obciążeń na gen2.
Likwiduj gen1.
Zapoznaj się z naszym przykładowym kodem dla wzorca migracji metodą "lift and shift" w naszym przykładzie migracji metodą Lift and Shift.
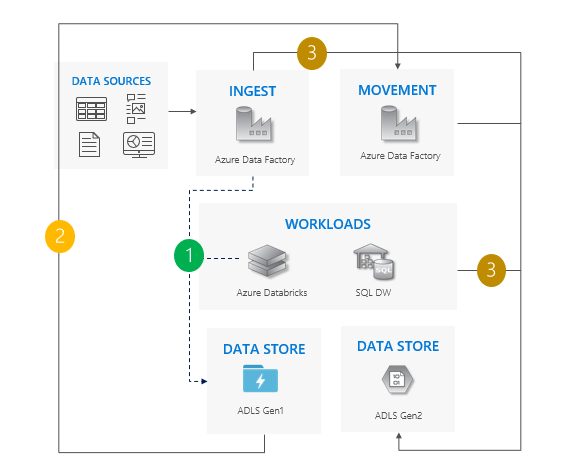
Zagadnienia dotyczące korzystania ze wzorca "lift and shift"
Przecięcie z gen1 do 2. generacji dla wszystkich obciążeń w tym samym czasie.
Spodziewaj się przestojów podczas migracji i okresu migracji jednorazowej.
Idealne rozwiązanie dla potoków, które mogą pozwolić na przestoje, a wszystkie aplikacje można uaktualnić jednocześnie.
Napiwek
Rozważ użycie witryny Azure Portal , aby skrócić czas przestoju i zmniejszyć liczbę kroków wymaganych do ukończenia migracji.
Wzorzec kopiowania przyrostowego
Rozpocznij przenoszenie danych z gen1 do 2. generacji. Zalecamy usługę Azure Data Factory. Listy ACL kopiują dane.
Przyrostowe kopiowanie nowych danych z usługi Gen1.
Po skopiowaniu wszystkich danych zatrzymaj wszystkie operacje zapisu w usłudze Gen1 i wskaż obciążenia gen2.
Likwiduj gen1.
Zapoznaj się z naszym przykładowym kodem dla wzorca kopiowania przyrostowego w naszym przykładzie migracji kopii przyrostowej.
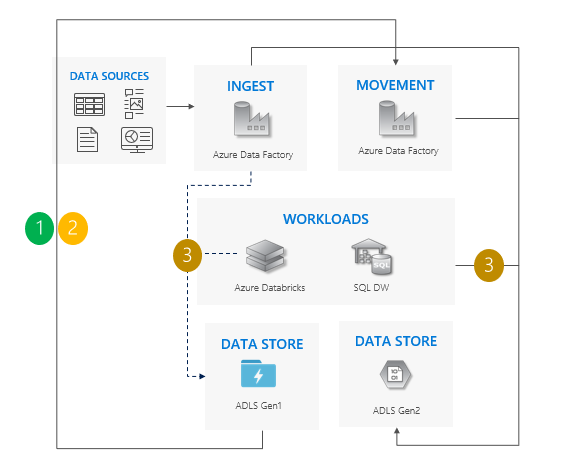
Zagadnienia dotyczące używania wzorca kopiowania przyrostowego:
Przecięcie z gen1 do 2. generacji dla wszystkich obciążeń w tym samym czasie.
Spodziewaj się przestoju tylko w okresie jednorazowym.
Idealne rozwiązanie w przypadku potoków, w których wszystkie aplikacje zostały uaktualnione jednocześnie, ale kopiowanie danych wymaga więcej czasu.
Wzorzec podwójnego potoku
Przenoszenie danych z gen1 do 2. generacji. Zalecamy usługę Azure Data Factory. Listy ACL kopiują dane.
Pozyskiwanie nowych danych zarówno do gen1, jak i 2. generacji.
Wskazywanie obciążeń na gen2.
Zatrzymaj wszystkie operacje zapisu w usłudze Gen1, a następnie likwiduj gen1.
Zapoznaj się z naszym przykładowym kodem dla wzorca podwójnego potoku w naszym przykładzie migracji podwójnego potoku.
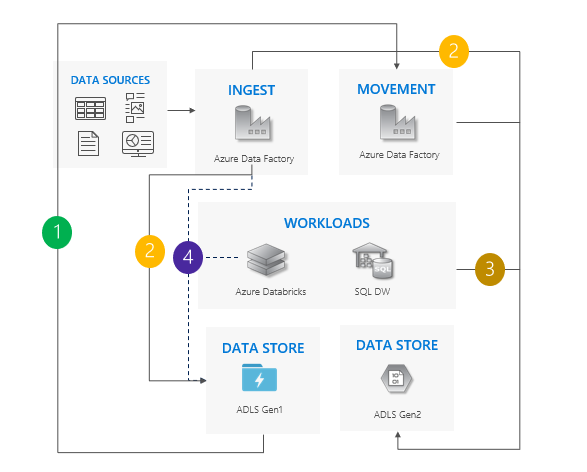
Zagadnienia dotyczące używania wzorca podwójnego potoku:
Potoki Gen1 i Gen2 są uruchamiane obok siebie.
Obsługuje zerowy przestój.
Idealnym rozwiązaniem w sytuacjach, w których obciążenia i aplikacje nie mogą sobie pozwolić na przestoje i można pozyskać je na obu kontach magazynu.
Wzorzec synchronizacji dwukierunkowej
Skonfiguruj replikację dwukierunkową między gen1 i gen2. Zalecamy usługę WanDisco. Oferuje ona funkcję naprawy istniejących danych.
Po zakończeniu wszystkich ruchów zatrzymaj wszystkie operacje zapisu w usłudze Gen1 i wyłącz replikację dwukierunkową.
Likwiduj gen1.
Zapoznaj się z naszym przykładowym kodem dla wzorca synchronizacji dwukierunkowej w naszym przykładzie migracji synchronizacji dwukierunkowej.
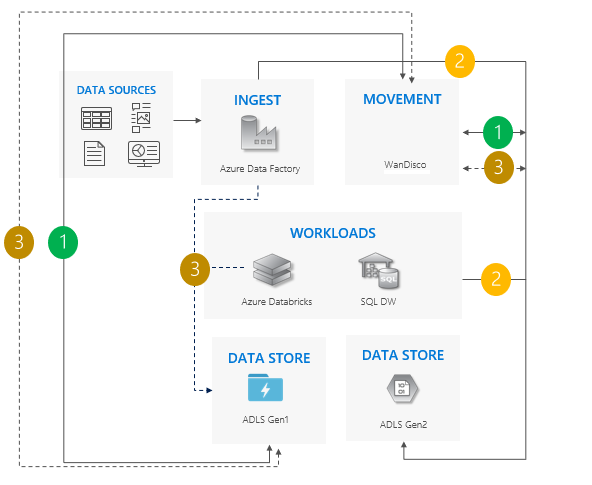
Zagadnienia dotyczące korzystania ze wzorca synchronizacji dwukierunkowej:
Idealne rozwiązanie w przypadku złożonych scenariuszy obejmujących dużą liczbę potoków i zależności, w których podejście etapowe może mieć większe znaczenie.
Nakład pracy nad migracją jest wysoki, ale zapewnia równoległą obsługę usług Gen1 i Gen2.
Następne kroki
- Dowiedz się więcej o różnych częściach konfigurowania zabezpieczeń dla konta magazynu. Aby uzyskać więcej informacji, zobacz Przewodnik po zabezpieczeniach usługi Azure Storage.
- Zoptymalizuj wydajność usługi Data Lake Store. Zobacz Optymalizowanie usługi Azure Data Lake Storage Gen2 pod kątem wydajności
- Zapoznaj się z najlepszymi rozwiązaniami dotyczącymi zarządzania usługą Data Lake Store. Zobacz Najlepsze rozwiązania dotyczące korzystania z usługi Azure Data Lake Storage Gen2