Sincronização de vários mecanismos
A maioria das GPUs modernas contém vários mecanismos independentes que fornecem funcionalidade especializada. Muitos têm um ou mais mecanismos de cópia dedicados e um mecanismo de computação, geralmente distintos do mecanismo 3D. Cada um desses mecanismos pode executar comandos em paralelo entre si. O Direct3D 12 fornece acesso refinado aos mecanismos 3D, computação e cópia, usando filas e listas de comandos.
Mecanismos de GPU
O diagrama a seguir mostra os threads de CPU de um título, cada um preenchendo uma ou mais das filas de cópia, computação e 3D. A fila 3D pode conduzir todos os três mecanismos de GPU; a fila de computação pode conduzir os mecanismos de computação e cópia; e a fila de cópia simplesmente o mecanismo de cópia.
À medida que os diferentes threads preenchem as filas, não pode haver uma garantia simples da ordem de execução, daí a necessidade de mecanismos de sincronização, quando o título os requer.
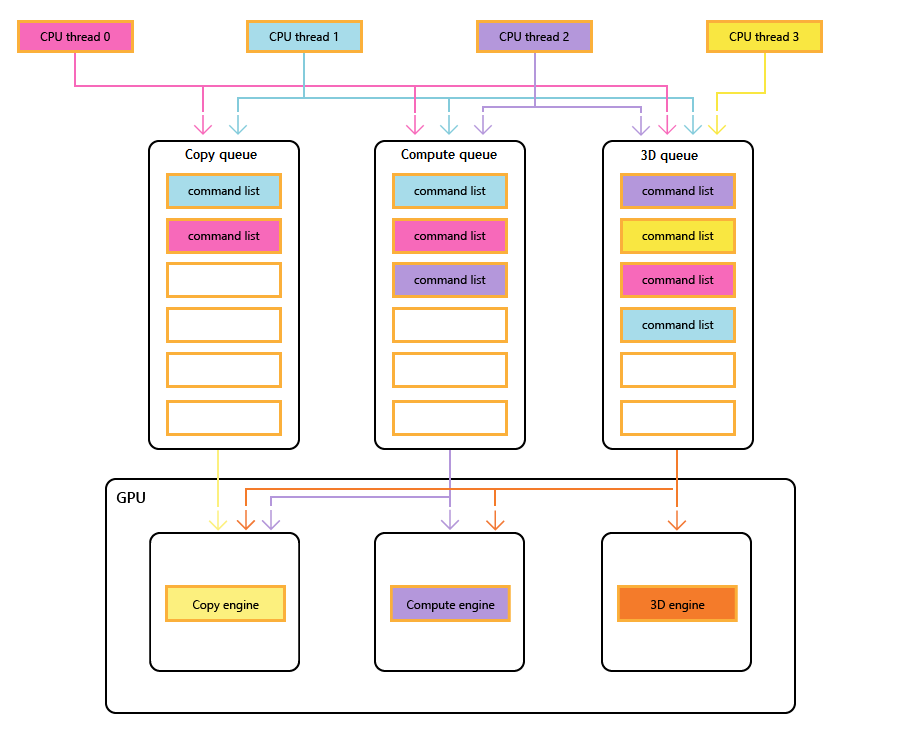
A imagem a seguir ilustra como um título pode agendar o trabalho em vários mecanismos de GPU, incluindo a sincronização entre mecanismos, quando necessário: mostra as cargas de trabalho por mecanismo com dependências entre mecanismos. Neste exemplo, o mecanismo de cópia primeiro copia alguma geometria necessária para renderização. O mecanismo 3D aguarda a conclusão dessas cópias e renderiza uma passagem prévia sobre a geometria. Em seguida, isso é consumido pelo mecanismo de computação. Os resultados do Dispatch do mecanismo de computação, juntamente com várias operações de cópia de textura no mecanismo de cópia, são consumidos pelo mecanismo 3D para a chamada de desenho final.
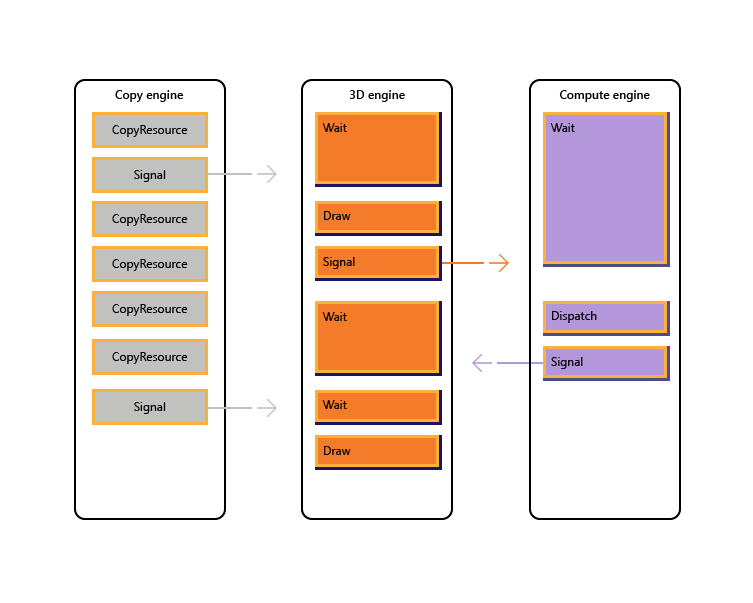
O pseudocódigo a seguir ilustra como um título pode enviar essa carga de trabalho.
// Get per-engine contexts. Note that multiple queues may be exposed
// per engine, however that design is not reflected here.
copyEngine = device->GetCopyEngineContext();
renderEngine = device->GetRenderEngineContext();
computeEngine = device->GetComputeEngineContext();
copyEngine->CopyResource(geometry, ...); // copy geometry
copyEngine->Signal(copyFence, 101);
copyEngine->CopyResource(tex1, ...); // copy textures
copyEngine->CopyResource(tex2, ...); // copy more textures
copyEngine->CopyResource(tex3, ...); // copy more textures
copyEngine->CopyResource(tex4, ...); // copy more textures
copyEngine->Signal(copyFence, 102);
renderEngine->Wait(copyFence, 101); // geometry copied
renderEngine->Draw(); // pre-pass using geometry only into rt1
renderEngine->Signal(renderFence, 201);
computeEngine->Wait(renderFence, 201); // prepass completed
computeEngine->Dispatch(); // lighting calculations on pre-pass (using rt1 as SRV)
computeEngine->Signal(computeFence, 301);
renderEngine->Wait(computeFence, 301); // lighting calculated into buf1
renderEngine->Wait(copyFence, 102); // textures copied
renderEngine->Draw(); // final render using buf1 as SRV, and tex[1-4] SRVs
O pseudocódigo a seguir ilustra a sincronização entre os mecanismos de cópia e 3D para realizar a alocação de memória semelhante ao heap por meio de um buffer de anel. Os títulos têm a flexibilidade de escolher o equilíbrio certo entre maximizar o paralelismo (por meio de um buffer grande) e reduzir o consumo de memória e a latência (por meio de um buffer pequeno).
device->CreateBuffer(&ringCB);
for(int i=1;i++){
if(i > length) copyEngine->Wait(fence1, i - length);
copyEngine->Map(ringCB, value%length, WRITE, pData); // copy new data
copyEngine->Signal(fence2, i);
renderEngine->Wait(fence2, i);
renderEngine->Draw(); // draw using copied data
renderEngine->Signal(fence1, i);
}
// example for length = 3:
// copyEngine->Map();
// copyEngine->Signal(fence2, 1); // fence2 = 1
// copyEngine->Map();
// copyEngine->Signal(fence2, 2); // fence2 = 2
// copyEngine->Map();
// copyEngine->Signal(fence2, 3); // fence2 = 3
// copy engine has exhausted the ring buffer, so must wait for render to consume it
// copyEngine->Wait(fence1, 1); // fence1 == 0, wait
// renderEngine->Wait(fence2, 1); // fence2 == 3, pass
// renderEngine->Draw();
// renderEngine->Signal(fence1, 1); // fence1 = 1, copy engine now unblocked
// renderEngine->Wait(fence2, 2); // fence2 == 3, pass
// renderEngine->Draw();
// renderEngine->Signal(fence1, 2); // fence1 = 2
// renderEngine->Wait(fence2, 3); // fence2 == 3, pass
// renderEngine->Draw();
// renderEngine->Signal(fence1, 3); // fence1 = 3
// now render engine is starved, and so must wait for the copy engine
// renderEngine->Wait(fence2, 4); // fence2 == 3, wait
Cenários de vários mecanismos
O Direct3D 12 permite que você evite acidentalmente encontrar ineficiências causadas por atrasos inesperados de sincronização. Ele também permite que você introduza a sincronização em um nível mais alto em que a sincronização necessária pode ser determinada com maior certeza. Um segundo problema que aborda vários mecanismos é tornar as operações caras mais explícitas, o que inclui transições entre 3D e vídeo que tradicionalmente custavam caro devido à sincronização entre vários contextos de kernel.
Em particular, os cenários a seguir podem ser abordados com o Direct3D 12.
- Trabalho de GPU assíncrona e de baixa prioridade. Isso permite a execução simultânea de operações atômicas e de trabalho de GPU de baixa prioridade que permitem que um thread de GPU consuma os resultados de outro thread não sincronizado sem bloqueio.
- Trabalho de computação de alta prioridade. Com a computação em segundo plano, é possível interromper a renderização 3D para fazer uma pequena quantidade de trabalho de computação de alta prioridade. Os resultados desse trabalho podem ser obtidos antecipadamente para processamento adicional na CPU.
- Trabalho de computação em segundo plano. Uma fila separada de baixa prioridade para cargas de trabalho de computação permite que um aplicativo utilize ciclos de GPU de reposição para executar a computação em segundo plano sem impacto negativo nas tarefas de renderização primária (ou outras). Tarefas em segundo plano podem incluir descompactação de recursos ou atualização de simulações ou estruturas de aceleração. As tarefas em segundo plano devem ser sincronizadas com pouca frequência na CPU (aproximadamente uma vez por quadro) para evitar paralisar ou retardar o trabalho em primeiro plano.
- Streaming e carregamento de dados. Uma fila de cópia separada substitui os conceitos D3D11 de dados iniciais e recursos de atualização. Embora o aplicativo seja responsável por mais detalhes no modelo Direct3D 12, essa responsabilidade vem com potência. O aplicativo pode controlar a quantidade de memória do sistema dedicada ao buffer de dados de carregamento. O aplicativo pode escolher quando e como (CPU vs GPU, bloqueio versus não bloqueio) para sincronizar e pode acompanhar o progresso e controlar a quantidade de trabalho na fila.
- Aumento do paralelismo. Os aplicativos podem usar filas mais profundas para cargas de trabalho em segundo plano (por exemplo, decodificar vídeo) quando tiverem filas separadas para o trabalho em primeiro plano.
No Direct3D 12, o conceito de uma fila de comandos é a representação da API de uma sequência de trabalho aproximadamente serial enviada pelo aplicativo. Barreiras e outras técnicas permitem que esse trabalho seja executado em um pipeline ou fora de ordem, mas o aplicativo vê apenas um único linha do tempo de conclusão. Isso corresponde ao contexto imediato em D3D11.
APIs de sincronização
Dispositivos e filas
O dispositivo Direct3D 12 tem métodos para criar e recuperar filas de comando de diferentes tipos e prioridades. A maioria dos aplicativos deve usar as filas de comando padrão porque elas permitem o uso compartilhado por outros componentes. Aplicativos com requisitos de simultaneidade adicionais podem criar filas adicionais. As filas são especificadas pelo tipo de lista de comandos que consomem.
Consulte os seguintes métodos de criação de ID3D12Device.
- CreateCommandQueue : cria uma fila de comandos com base em informações em uma estrutura de 12_COMMAND_QUEUE_DESC direct3D .
- CreateCommandList : cria uma lista de comandos do tipo 12_COMMAND_LIST_TYPE Direct3D.
- CreateFence : cria uma cerca, observando os sinalizadores no 12_FENCE_FLAGS Direct3D. As cercas são usadas para sincronizar filas.
Filas de todos os tipos (3D, computação e cópia) compartilham a mesma interface e são todas baseadas em lista de comandos.
Consulte os seguintes métodos de ID3D12CommandQueue.
- ExecuteCommandLists : envia uma matriz de listas de comandos para execução. Cada lista de comandos que está sendo definida por ID3D12CommandList.
- Sinal : define um valor de cerca quando a fila (em execução na GPU) atinge um determinado ponto.
- Aguarde : a fila aguarda até que a cerca especificada atinja o valor especificado.
Observe que os pacotes não são consumidos por nenhuma fila e, portanto, esse tipo não pode ser usado para criar uma fila.
Limites
A API de vários mecanismos fornece APIs explícitas para criar e sincronizar usando cercas. Uma cerca é uma construção de sincronização controlada por um valor UINT64. Os valores de cerca são definidos pelo aplicativo. Uma operação de sinal modifica o valor da cerca e uma operação de espera bloqueia até que a cerca atinja o valor solicitado ou maior. Um evento pode ser disparado quando uma cerca atinge um determinado valor.
Consulte os métodos da interface ID3D12Fence .
- GetCompletedValue : retorna o valor atual da cerca.
- SetEventOnCompletion : faz com que um evento seja acionado quando a cerca atinge um determinado valor.
- Sinal : define a cerca como o valor fornecido.
As cercas permitem o acesso da CPU ao valor de cerca atual e os sinais e esperas da CPU.
O método Signal na interface ID3D12Fence atualiza uma cerca do lado da CPU. Essa atualização ocorre imediatamente. O método Signal em ID3D12CommandQueue atualiza uma cerca do lado da GPU. Essa atualização ocorre depois que todas as outras operações na fila de comandos foram concluídas.
Todos os nós em uma configuração de vários mecanismos podem ler e reagir a qualquer cerca que atinja o valor certo.
Os aplicativos definem seus próprios valores de cerca, um bom ponto de partida pode estar aumentando uma cerca uma vez por quadro.
Uma cerca pode ser relançada. Isso significa que o valor da cerca não precisa incrementar apenas. Se uma operação signal for enfileirada em duas filas de comando diferentes ou se dois threads de CPU estiverem chamando Signal em uma cerca, poderá haver uma corrida para determinar qual Signal é concluído por último e, portanto, qual valor de cerca será aquele que permanecerá. Se uma cerca for recolhida, quaisquer novas esperas (incluindo solicitações SetEventOnCompletion ) serão comparadas com o novo valor de cerca inferior e, portanto, podem não ser atendidas, mesmo que o valor da cerca tenha sido anteriormente alto o suficiente para satisfazê-los. Se ocorrer uma corrida, entre um valor que atenderá a uma espera pendente e um valor menor que não ocorrerá, a espera será atendida independentemente de qual valor permanecerá posteriormente.
As APIs de cerca fornecem uma funcionalidade de sincronização avançada, mas podem criar problemas potencialmente difíceis de depurar. É recomendável que cada cerca seja usada apenas para indicar o progresso em uma linha do tempo para evitar corridas entre sinalizadores.
Copiar e computar listas de comandos
Todos os três tipos de lista de comandos usam a interface ID3D12GraphicsCommandList , no entanto, apenas um subconjunto dos métodos tem suporte para cópia e computação.
As listas de comandos de cópia e computação podem usar os métodos a seguir.
As listas de comandos de computação também podem usar os métodos a seguir.
- ClearState
- ClearUnorderedAccessViewFloat
- ClearUnorderedAccessViewUint
- DiscardResource
- Dispatch
- ExecuteIndirect
- SetComputeRoot32BitConstant
- SetComputeRoot32BitConstants
- SetComputeRootConstantBufferView
- SetComputeRootDescriptorTable
- SetComputeRootShaderResourceView
- SetComputeRootSignature
- SetComputeRootUnorderedAccessView
- SetDescriptorHeaps
- SetPipelineState
- SetPredication
- EndQuery
As listas de comandos de computação devem definir um PSO de computação ao chamar SetPipelineState.
Os pacotes não podem ser usados com listas de comandos ou filas de computação ou cópia.
Exemplo de computação e elementos gráficos em pipeline
Este exemplo mostra como a sincronização de limite pode ser usada para criar um pipeline de trabalho de computação em uma fila (referenciado por pComputeQueue) que é consumido pelo trabalho gráfico na fila pGraphicsQueue. O trabalho de computação e gráficos é empacotado com a fila de gráficos consumindo o resultado do trabalho de computação de vários quadros para trás, e um evento de CPU é usado para limitar o trabalho total enfileirado em geral.
void PipelinedComputeGraphics()
{
const UINT CpuLatency = 3;
const UINT ComputeGraphicsLatency = 2;
HANDLE handle = CreateEvent(nullptr, FALSE, FALSE, nullptr);
UINT64 FrameNumber = 0;
while (1)
{
if (FrameNumber > ComputeGraphicsLatency)
{
pComputeQueue->Wait(pGraphicsFence,
FrameNumber - ComputeGraphicsLatency);
}
if (FrameNumber > CpuLatency)
{
pComputeFence->SetEventOnFenceCompletion(
FrameNumber - CpuLatency,
handle);
WaitForSingleObject(handle, INFINITE);
}
++FrameNumber;
pComputeQueue->ExecuteCommandLists(1, &pComputeCommandList);
pComputeQueue->Signal(pComputeFence, FrameNumber);
if (FrameNumber > ComputeGraphicsLatency)
{
UINT GraphicsFrameNumber = FrameNumber - ComputeGraphicsLatency;
pGraphicsQueue->Wait(pComputeFence, GraphicsFrameNumber);
pGraphicsQueue->ExecuteCommandLists(1, &pGraphicsCommandList);
pGraphicsQueue->Signal(pGraphicsFence, GraphicsFrameNumber);
}
}
}
Para dar suporte a essa pipelining, deve haver um buffer de ComputeGraphicsLatency+1 diferentes cópias dos dados que passam da fila de computação para a fila de gráficos. As listas de comandos devem usar UAVs e indireção para ler e gravar a partir da "versão" apropriada dos dados no buffer. A fila de computação deve aguardar até que a fila de gráficos termine a leitura dos dados para o quadro N antes de poder gravar o quadro N+ComputeGraphicsLatency.
Observe que a quantidade de fila de computação trabalhada em relação à CPU não depende diretamente da quantidade de buffer necessária, no entanto, o trabalho de GPU de enfileiramento além da quantidade de espaço em buffer disponível é menos valioso.
Um mecanismo alternativo para evitar a indireção seria criar várias listas de comandos correspondentes a cada uma das versões "renomeadas" dos dados. O exemplo a seguir usa essa técnica ao estender o exemplo anterior para permitir que as filas de computação e gráficos sejam executadas de forma mais assíncrona.
Exemplo de computação e elementos gráficos assíncronos
Este próximo exemplo permite que os gráficos sejam renderizados de forma assíncrona da fila de computação. Ainda há uma quantidade fixa de dados armazenados em buffer entre os dois estágios, no entanto, agora o trabalho gráfico continua independentemente e usa o resultado mais atualizado do estágio de computação, como conhecido na CPU, quando o trabalho gráfico é enfileirado. Isso seria útil se o trabalho gráfico estivesse sendo atualizado por outra fonte, por exemplo, entrada do usuário. Deve haver várias listas de comandos para permitir que os ComputeGraphicsLatency quadros de elementos gráficos funcionem em versão de pré-lançamento por vez, e a função UpdateGraphicsCommandList representa a atualização da lista de comandos para incluir os dados de entrada mais recentes e ler os dados de computação do buffer apropriado.
A fila de computação ainda deve aguardar a conclusão da fila de gráficos com os buffers de pipe, mas uma terceira cerca (pGraphicsComputeFence) é introduzida para que o progresso do trabalho de computação de leitura de gráficos versus o progresso dos elementos gráficos em geral possa ser acompanhado. Isso reflete o fato de que agora quadros gráficos consecutivos podem ler do mesmo resultado de computação ou ignorar um resultado de computação. Um design mais eficiente, mas um pouco mais complicado, usaria apenas a cerca de elementos gráficos únicos e armazenaria um mapeamento para os quadros de computação usados por cada quadro gráfico.
void AsyncPipelinedComputeGraphics()
{
const UINT CpuLatency{ 3 };
const UINT ComputeGraphicsLatency{ 2 };
// The compute fence is at index 0; the graphics fence is at index 1.
ID3D12Fence* rgpFences[]{ pComputeFence, pGraphicsFence };
HANDLE handles[2];
handles[0] = CreateEvent(nullptr, FALSE, TRUE, nullptr);
handles[1] = CreateEvent(nullptr, FALSE, TRUE, nullptr);
UINT FrameNumbers[]{ 0, 0 };
ID3D12GraphicsCommandList* rgpGraphicsCommandLists[CpuLatency];
CreateGraphicsCommandLists(ARRAYSIZE(rgpGraphicsCommandLists),
rgpGraphicsCommandLists);
// Graphics needs to wait for the first compute frame to complete; this is the
// only wait that the graphics queue will perform.
pGraphicsQueue->Wait(pComputeFence, 1);
while (true)
{
for (auto i = 0; i < 2; ++i)
{
if (FrameNumbers[i] > CpuLatency)
{
rgpFences[i]->SetEventOnCompletion(
FrameNumbers[i] - CpuLatency,
handles[i]);
}
else
{
::SetEvent(handles[i]);
}
}
auto WaitResult = ::WaitForMultipleObjects(2, handles, FALSE, INFINITE);
if (WaitResult > WAIT_OBJECT_0 + 1) continue;
auto Stage = WaitResult - WAIT_OBJECT_0;
++FrameNumbers[Stage];
switch (Stage)
{
case 0:
{
if (FrameNumbers[Stage] > ComputeGraphicsLatency)
{
pComputeQueue->Wait(pGraphicsComputeFence,
FrameNumbers[Stage] - ComputeGraphicsLatency);
}
pComputeQueue->ExecuteCommandLists(1, &pComputeCommandList);
pComputeQueue->Signal(pComputeFence, FrameNumbers[Stage]);
break;
}
case 1:
{
// Recall that the GPU queue started with a wait for pComputeFence, 1
UINT64 CompletedComputeFrames = min(1,
pComputeFence->GetCompletedValue());
UINT64 PipeBufferIndex =
(CompletedComputeFrames - 1) % ComputeGraphicsLatency;
UINT64 CommandListIndex = (FrameNumbers[Stage] - 1) % CpuLatency;
// Update graphics command list based on CPU input and using the appropriate
// buffer index for data produced by compute.
UpdateGraphicsCommandList(PipeBufferIndex,
rgpGraphicsCommandLists[CommandListIndex]);
// Signal *before* new rendering to indicate what compute work
// the graphics queue is DONE with
pGraphicsQueue->Signal(pGraphicsComputeFence, CompletedComputeFrames - 1);
pGraphicsQueue->ExecuteCommandLists(1,
rgpGraphicsCommandLists + PipeBufferIndex);
pGraphicsQueue->Signal(pGraphicsFence, FrameNumbers[Stage]);
break;
}
}
}
}
Acesso a recursos de várias filas
Para acessar um recurso em mais de uma fila, um aplicativo deve seguir as regras a seguir.
O acesso a recursos (consulte Direct3D 12_RESOURCE_STATES) é determinado pela classe de tipo de fila e não pelo objeto queue. Há duas classes de tipo de fila: fila de computação/3D é uma classe de tipo, Copy é uma segunda classe de tipo. Portanto, um recurso que tem uma barreira ao estado NON_PIXEL_SHADER_RESOURCE em uma fila 3D pode ser usado nesse estado em qualquer fila 3D ou de Computação, sujeito a requisitos de sincronização que exigem que a maioria das gravações seja serializada. Os estados de recurso compartilhados entre as duas classes de tipo (COPY_SOURCE e COPY_DEST) são considerados estados diferentes para cada classe de tipo. Portanto, se um recurso fizer a transição para COPY_DEST em uma fila de Cópia, ele não estará acessível como um destino de cópia de filas 3D ou de Computação e vice-versa.
Para resumir.
- Um "objeto" de fila é qualquer fila única.
- Um "tipo" de fila é qualquer um destes três: Computação, 3D e Cópia.
- Uma fila "classe de tipo" é qualquer uma destas duas: Computação/3D e Cópia.
Os sinalizadores COPY (COPY_DEST e COPY_SOURCE) usados como estados iniciais representam estados na classe de tipo 3D/Compute. Para usar um recurso inicialmente em uma fila de Cópia, ele deve começar no estado COMMON. O estado COMMON pode ser usado para todos os usos em uma fila de Cópia usando as transições de estado implícitas.
Embora o estado do recurso seja compartilhado em todas as filas de Computação e 3D, não é permitido gravar no recurso simultaneamente em filas diferentes. "Simultaneamente" aqui significa não sincronizado, observando que a execução não sincronizada não é possível em algum hardware. As regras a seguir se aplicam.
- Somente uma fila pode gravar em um recurso por vez.
- Várias filas podem ler do recurso desde que não leiam os bytes que estão sendo modificados pelo gravador (a leitura de bytes gravados simultaneamente produz resultados indefinidos).
- Uma cerca deve ser usada para sincronizar após a gravação antes que outra fila possa ler os bytes gravados ou fazer qualquer acesso de gravação.
Os buffers traseiros que estão sendo apresentados devem estar no estado 12_RESOURCE_STATE_COMMON Direct3D.
Tópicos relacionados
Guia de programação do Direct3D 12
Usando barreiras de recursos para sincronizar estados de recursos no Direct3D 12
Comentários
Em breve: Ao longo de 2024, eliminaremos os problemas do GitHub como o mecanismo de comentários para conteúdo e o substituiremos por um novo sistema de comentários. Para obter mais informações, consulte https://aka.ms/ContentUserFeedback.
Enviar e exibir comentários de