Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
Depois de exportar dados do Microsoft Dataverse para o Azure Data Lake Storage Gen2 com o Azure Synapse Link para Dataverse, pode utilizar o Azure Data Factory para criar fluxos de dados, transformar os seus dados e executar análises.
Nota
O Azure Synapse Link para Dataverse era anteriormente conhecido como o serviço Exportar para data lake. O serviço foi renomeado a partir de maio de 2021 e continuará a exportar dados para o Azure Data Lake, bem como Azure Synapse Analytics.
Este artigo mostra como executar as tarefas seguintes:
Defina a conta de armazenamento do Data Lake Storage Gen2 com os dados do Dataverse como uma origem num fluxo de dados do Data Factory.
Transforme os dados do Dataverse no Data Factory com um fluxo de dados.
Defina a conta de armazenamento do Data Lake Storage Gen2 com os dados do Dataverse como um sink num fluxo de dados do Data Factory.
Execute o seu fluxo de dados ao criar um pipeline.
Pré-requisitos
Esta secção descreve os pré-requisitos necessários para ingerir os dados exportados do Dataverse com o Data Factory.
Funções do Azure. A conta de utilizador que é utilizada para iniciar sessão no Azure tem de ser membro da função contribuidor ou proprietário, ou como um administrador da subscrição do Azure. Para ver as permissões que tem na subscrição, vá para o portal do Azure, selecione o seu nome de utilizador no canto superior direito, selecione ... e selecione As minhas permissões. Se tiver acesso a várias subscrições, selecione a adequada. Para criar e gerir recursos subordinados para o Data Factory no portal do Azure, incluindo os conjuntos de dados, serviços associados, pipelines, acionadores e runtimes de integração, tem de pertencer à função Contribuidor do Data Factory ao nível do grupo de recursos ou superior.
Azure Synapse Link para Dataverse. Este guia pressupõe que já exportou dados do Dataverse utilizando o Azure Synapse Link para Dataverse. Neste exemplo, os dados da tabela de contas são exportados para o data lake.
Azure Data Factory. Este guia pressupõe que já criou uma fábrica de dados sob a mesma descrição e grupo de recursos que a conta de armazenamento que contém os dados do Dataverse exportados.
Definir a conta de armazenamento do Data Lake Storage Gen2 como uma origem
Abra o Azure Data Factory e selecione a fábrica de dados que está na mesma subscrição e grupo de recursos que a conta de armazenamento que contém os seus dados do Dataverse exportados. Em seguida, selecione Criar fluxo de dados a partir da home page.
Ative o modo de Depuração do fluxo de dados e selecione o seu tempo preferido para entrar em direto. Isto poderá demorar até 10 minutos, mas pode prosseguir com os seguintes passos.

Selecione Adicionar Origem.

Em Definições de origem, faça o seguinte:
- Nome do fluxo de saída: Introduza o nome que pretende.
- Tipo de origem: Selecione Em linha.
- Tipo de conjunto de dados em linha: Selecione Common Data Model.
- Serviço associado: Selecione a conta de armazenamento a partir do menu suspenso e, em seguida, associe um novo serviço, fornecendo os seus detalhes de subscrição e deixando todas as configurações predefinidas.
- Amostragem: se pretender utilizar todos os seus dados, selecione Desativar.
Em Opções de origem, faça o seguinte:
Formato dos metadados: selecione Model.json.
Localização da raiz: introduza o nome do contentor na primeira caixa (Contentor) ou Procurar pelo nome do contentor e selecione OK.
Entidade: introduza o nome da tabela ou Procure pela tabela.

Verifique o separador Projeção para se certificar de que o seu esquema foi importado com sucesso. Se não vir nenhuma coluna, selecione Opções de esquema e verifique a opção Inferir tipos de colunas derivadas. Configure as opções de formatação para corresponder ao seu conjunto de dados e, em seguida, selecione Aplicar.
Pode ver os seus dados no separador Pré-visualização de dados para garantir que a criação da Origem está completa e precisa.
Transformar os seus dados do Dataverse
Depois de definir os dados do Dataverse exportados na conta do Azure Data Lake Storage Gen2 como uma origem no fluxo de dados do Data Factory, existem muitas possibilidades de transformar os seus dados. Mais informações: Azure Data Factory
Siga estas instruções para criar um classificação para cada linha pelo campo receita da tabela de contas.
Selecione + no canto inferior direito da transformação anterior e, em seguida, pesquise por e selecione Classificação.
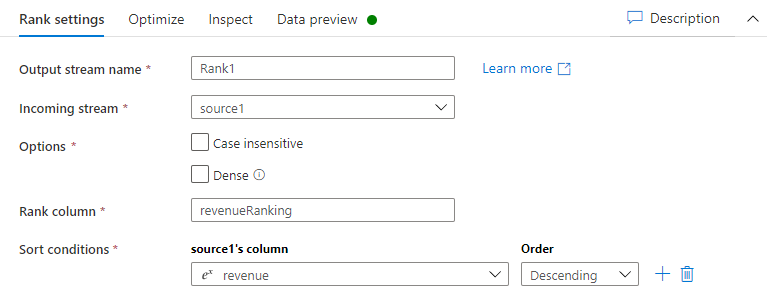
No separador Definições de classificação, faça o seguinte:
Nome do fluxo de saída: introduza o nome que pretende, tal como Classificação1.
Fluxo de Entrada: selecione o nome de origem que pretende. Neste caso, o nome de origem do passo anterior.
Opções: deixe as opções desmarcadas.
Coluna de classificação: introduza o nome da coluna de classificação gerada.
Condições de ordenação: selecione a coluna de receitas e ordene por ordem Descendente.
Pode ver os seus dados no separador de pré-visualização de dados onde encontrará a nova coluna revenueRank na posição mais à direita.
Defina a conta de armazenamento do Data Lake Storage Gen2 como um sink
Em última análise, tem de definir um sink pia para o seu fluxo de dados. Siga estas instruções para colocar os seus dados transformados como um ficheiro de texto delimitado no data lake.
Selecione + no canto inferior direito da transformação anterior e, em seguida, pesquise por e selecione Sink.
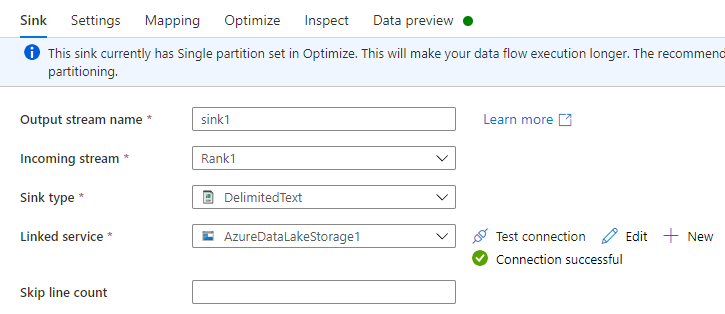
No separador Sink, efetue um dos seguintes procedimentos:
Nome do fluxo de saída: introduza o nome pretendido, como Sink1.
Fluxo de entrada: selecione o nome de origem que pretende. Neste caso, o nome de origem do passo anterior.
Tipo de sink: selecione DelimitedText.
Serviço associado: selecione o seu contentor de armazenamento do Data Lake Storage Gen2 que tem os dados que exportou utilizando o serviço Azure Synapse Link para Dataverse.
No separador Definições, faça o seguinte:
Caminho da pasta: introduza o nome do contentor na primeira caixa (Sistema de ficheiros) ou Procurar pelo nome do contentor e selecione OK.
Opção de nome do ficheiro: selecione saída para ficheiro único.
Saída para ficheiro único: introduza um nome de ficheiro, como ADFOutput
Deixe todas as outras predefinições.
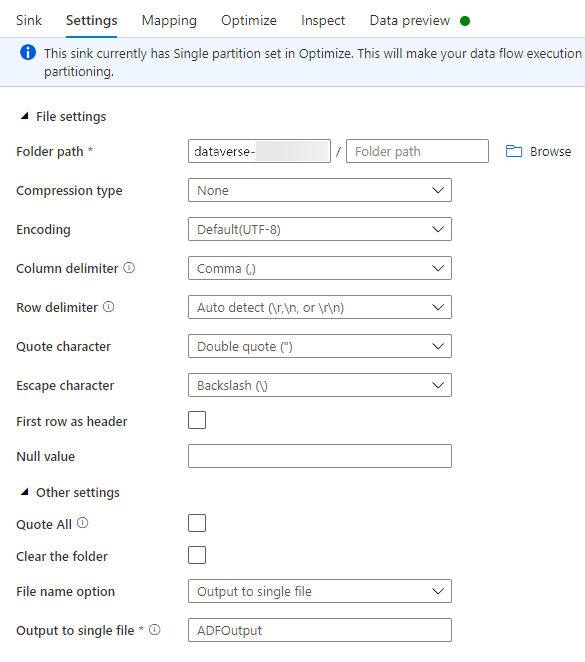
No separador Otimizar, defina a opção Opção de partição para Partição única.
Pode ver os seus dados no separador Pré-visualização de dados.
Executar o seu fluxo de dados
No painel esquerdo, em Recursos de Fábrica, selecione + e selecione Pipeline.

Em Atividades, selecione Mover e Transformar e, em seguida, arraste Fluxo de dados para a área de trabalho.
Selecione Utilizar fluxo de dados existente e selecione o fluxo de dados que criou nos passos anteriores.
Na barra de comandos, selecione Depurar.
Permita a execução do fluxo de dados até a vista inferior mostrar que foi concluída. Isto poderá demorar alguns minutos.
Vá ao contentor de armazenamento de destino final e encontre o ficheiro de dados da tabela transformado.
Veja também
Configurar o Azure Synapse Link para Dataverse com o Azure Data Lake
Analisar os dados do Dataverse no Azure Data Lake Storage Gen2 com o Power BI