Примечание
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Эта статья предназначена для ИТ-специалистов и ИТ-менеджеров. Вы узнаете об архитектуре решения бизнес-аналитики в COE и различных технологиях, используемых. Технологии включают Azure, Power BI и Excel. Вместе их можно использовать для создания масштабируемой и основанной на данных облачной бизнес-аналитической платформы BI.
Проектирование надежной платформы бизнес-аналитики несколько похоже на строительство моста; мост, который подключает преобразованные и обогащенные исходные данные к потребителям данных. Для проектирования такой сложной структуры требуется инженерный подход, хотя она может стать одной из самых творческих и удовлетворяющих ИТ-архитектур, которые вы можете разработать. В крупной организации архитектура решения бизнес-аналитики может состоять из следующих вариантов:
- Источники данных
- Прием данных
- Большие данные / подготовка данных
- Хранилище данных
- Семантические модели бизнес-аналитики
- Отчеты
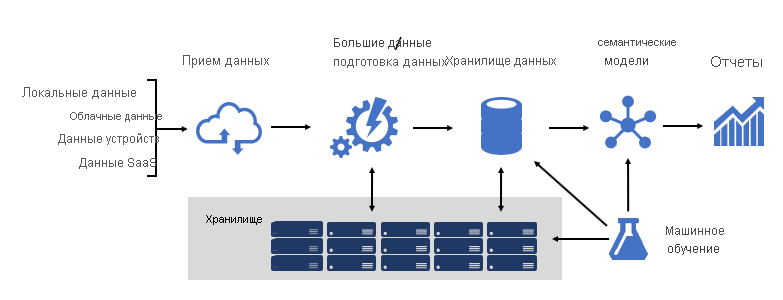
Платформа должна поддерживать конкретные требования. В частности, он должен масштабироваться и обеспечивать выполнение ожиданий бизнес-служб и потребителей данных. В то же время оно должно быть безопасным изначально. И оно должно быть достаточно гибким и устойчивым, чтобы адаптироваться к изменениям — поскольку неизбежно, что со временем новые данные и предметные области должны быть подключены к сети.
Платформы
В Корпорации Майкрософт, начиная с самого начала мы приняли системный подход, инвестируя в разработку платформ. Платформы технических и бизнес-процессов повышают повторное использование проектирования и логики и обеспечивают согласованный результат. Они также обеспечивают гибкость в архитектуре, используя множество технологий, и они упрощают и сокращают затраты на проектирование с помощью повторяемых процессов.
Мы узнали, что хорошо разработанные платформы повышают видимость происхождения данных, анализ влияния, обслуживание бизнес-логики, управление таксономией и упрощение управления. Кроме того, разработка стала быстрее и совместная работа между крупными командами стала более гибкой и эффективной.
В этой статье описано несколько наших платформ.
Модели данных
Модели данных обеспечивают контроль над структурой и доступом к данным. Для бизнес-служб и потребителей данных модели данных являются их интерфейсом с платформой бизнес-аналитики.
Платформа бизнес-аналитики может предоставлять три различных типа моделей:
- Корпоративные модели
- Семантические модели бизнес-аналитики
- Модели машинного обучения (ML)
Корпоративные модели
Корпоративные модели создаются и поддерживаются ИТ-архитекторами. Иногда они называются размерными моделями или киосками данных. Как правило, данные хранятся в реляционном формате в виде таблиц измерений и фактов. Эти таблицы хранят очищенные и обогащенные данные, объединенные из многих систем, и они представляют авторитетный источник для создания отчетов и аналитики.
Корпоративные модели предоставляют согласованный и единый источник данных для создания отчетов и бизнес-аналитики. Они создаются один раз и распространяются как стандарт компании. Политики управления обеспечивают безопасность данных, поэтому доступ к конфиденциальным наборам данных ( например, сведения о клиентах или финансовых службах) ограничен на основе потребностей. Они принимают соглашения об именовании, обеспечивающие согласованность, тем самым обеспечивая доверие к данным и качеству.
На облачной платформе бизнес-аналитики корпоративные модели можно развернуть в пуле SQL Synapse в Azure Synapse. Затем пул Synapse SQL становится единственным источником достоверных данных, на который организация может положиться для быстрых и надежных аналитических данных.
Семантические модели бизнес-аналитики
Семантические модели бизнес-аналитики представляют собой семантический слой по корпоративным моделям. Они создаются и поддерживаются разработчиками бизнес-аналитики и бизнес-пользователями. Разработчики бизнес-аналитики создают основные семантические модели бизнес-аналитики, исходные данные из корпоративных моделей. Бизнес-пользователи могут создавать небольшие, независимые модели или расширить основные семантические модели бизнес-аналитики с помощью отделальных или внешних источников. Семантические модели бизнес-аналитики обычно сосредоточены на одной области темы и часто широко распространены.
Бизнес-возможности обеспечиваются не только данными, а также семантическими моделями бизнес-аналитики, которые описывают понятия, связи, правила и стандарты. Таким образом, они представляют интуитивно понятные и понятные структуры, определяющие связи данных и инкапсулируют бизнес-правила в виде вычислений. Они также могут применять точные разрешения на данные, обеспечивая доступ нужным людям к нужным данным. Важно, что они ускоряют производительность запросов, обеспечивая чрезвычайно быструю интерактивную аналитику даже по терабайтам данных. Как и корпоративные модели, семантические модели бизнес-аналитики принимают соглашения об именовании, обеспечивающие согласованность.
На облачной платформе бизнес-аналитики разработчики бизнес-аналитики могут развертывать семантические модели бизнес-аналитики в Службах Azure Analysis Services, в емкостях Power BI Premium и в емкостях Microsoft Fabric.
Это важно
Эта статья относится к Power BI Premium или подпискам на емкость Power BI Premium (P SKU). В настоящее время корпорация Майкрософт объединяет варианты приобретения и упраздняет SKU Power BI Premium по мощности. Новым и существующим клиентам следует рассмотреть возможность приобретения подписок на емкость Fabric (F SKU) как альтернативу.
Дополнительные сведения см. в разделе Важное обновление, касающееся лицензирования Power BI Premium и в разделе Часто задаваемые вопросы по Power BI Premium.
Мы рекомендуем развертывание в Power BI, когда он используется в качестве уровня для отчетности и аналитики. Эти продукты поддерживают различные режимы хранения, позволяя таблицам модели данных кэшировать свои данные или использовать DirectQuery, которая является технологией, которая передает запросы в базовый источник данных. DirectQuery — это идеальный режим хранения, когда таблицы моделей представляют большие объемы данных или необходимо обеспечить практически в реальном времени результаты. Два режима хранения можно объединить: составные модели объединяют таблицы, использующие разные режимы хранения в одной модели.
Для часто запрашиваемых моделей Azure Load Balancer можно использовать для равномерного распределения нагрузки запросов между репликами модели. Он также позволяет масштабировать приложения и создавать высокодоступные семантические модели бизнес-аналитики.
Модели машинного обучения
Модели машинного обучения создаются и поддерживаются специалистами по обработке и анализу данных. Они в основном созданы из необработанных источников в хранилище данных.
Обученные модели машинного обучения могут обнаруживать закономерности в данных. Во многих случаях эти шаблоны можно использовать для прогнозирования, которые можно использовать для обогащения данных. Например, поведение покупки можно использовать для прогнозирования оттока клиентов или сегментирования клиентов. Результаты прогнозирования можно добавить в корпоративные модели, чтобы разрешить анализ по сегменту клиента.
На облачной платформе бизнес-аналитики можно использовать Машинное обучение Azure для обучения, развертывания, автоматизации, управления и отслеживания моделей машинного обучения.
Хранилище данных
В центре платформы бизнес-аналитики находится хранилище данных, которое размещает корпоративные модели. Это источник санкционированных данных ( как система записей и в качестве концентратора), обслуживающих корпоративные модели для создания отчетов, бизнес-аналитики и обработки и анализа данных.
Многие бизнес-службы, включая бизнес-приложения (LOB), могут полагаться на хранилище данных в качестве авторитетного и управляемого источника корпоративных знаний.
В Корпорации Майкрософт наш хранилище данных размещено в Azure Data Lake Storage 2-го поколения (ADLS 2-го поколения) и Azure Synapse Analytics.
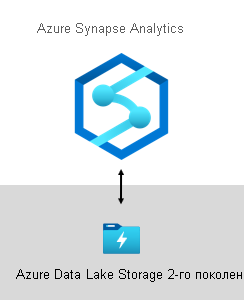
- ADLS 2-го поколения делает службу хранилища Azure основой для создания корпоративных озер данных в Azure. Она предназначена для обслуживания нескольких петабайтов информации при поддержании сотен гигабит пропускной способности. Кроме того, она предлагает низкую стоимость хранилища и транзакций. Кроме того, он поддерживает совместимый с Hadoop доступ, который позволяет управлять и получать доступ к данным так же, как и с распределенной файловой системой Hadoop (HDFS). На самом деле , Azure HDInsight, Azure Databricks и Azure Synapse Analytics могут получить доступ ко всем данным, хранящимся в ADLS 2-го поколения. Таким образом, на платформе БИЗНЕС-аналитики рекомендуется хранить необработанные исходные данные, полупроцессированные или промежуточные данные и готовые к работе данные. Мы используем его для хранения всех бизнес-данных.
- Azure Synapse Analytics — это служба аналитики, которая объединяет хранилище корпоративных данных и аналитику больших данных. Она предоставляет вам свободу запрашивать данные на ваших условиях, используя либо бессерверные решения по запросу, либо подготовленные ресурсы — в любом масштабе. Synapse SQL, компонент Azure Synapse Analytics, поддерживает полную аналитику на основе T-SQL, поэтому идеально подходит для размещения корпоративных моделей, состоящих из ваших таблиц измерений и фактов. Таблицы можно эффективно загружать из ADLS 2-го поколения с помощью простых запросов T-SQL Polybase . Затем у вас есть возможность MPP выполнять высокопроизводительную аналитику.
Платформа подсистемы бизнес-правил
Мы разработали платформу подсистемы бизнес-правил (BRE), чтобы каталогировать любую бизнес-логику, которая может быть реализована на уровне хранилища данных. BRE может иметь множество значений, но в контексте хранилища данных она полезна для создания вычисляемых столбцов в реляционных таблицах. Эти вычисляемые столбцы обычно представляются как математические вычисления или выражения с помощью условных инструкций.
Цель состоит в том, чтобы разделить бизнес-логику из основного кода бизнес-аналитики. Традиционно бизнес-правила жестко закодируются в хранимых процедурах SQL, поэтому часто это приводит к большому объему усилий по их поддержанию при изменении бизнес-потребностей. В bre бизнес-правила определяются один раз и используются несколько раз при применении к разным сущностям хранилища данных. Если логика вычисления должна измениться, ее необходимо обновить только в одном месте, а не в многочисленных хранимых процедурах. Кроме того, существует преимущество: платформа BRE обеспечивает прозрачность и видимость реализованной бизнес-логики, которая может быть предоставлена с помощью набора отчетов, создающих самообновиющуюся документацию.
Источники данных
Хранилище данных может консолидировать данные практически из любого источника данных. Он в основном построен на основе основных приложений данных, которые обычно представляют собой реляционные базы данных, хранящие данные для продаж, маркетинга, финансов и т. д. Эти базы данных могут быть размещены в облаке или находиться в локальной среде. Другие источники данных могут быть файловыми, например, веб-логами или данными IoT, полученными с устройств. Кроме того, данные можно получить от поставщиков Software-as-Service (SaaS).
В Корпорации Майкрософт некоторые из наших внутренних систем выводят операционные данные напрямую в ADLS Gen2 в формате сырого файла. Помимо нашего озера данных, другие исходные системы включают реляционные LOB-приложения, рабочие книги Excel, другие источники на основе файлов, управление основными данными (MDM), а также пользовательские репозитории данных. Репозитории MDM позволяют управлять основными данными, чтобы обеспечить достоверные, стандартизированные и проверенные версии данных.
Прием данных
Периодически и в соответствии с ритмами бизнеса данные поступают из исходных систем и загружаются в хранилище данных. Это может быть один раз в день или более частые интервалы. Прием данных связан с извлечением, преобразованием и загрузкой данных. Или, возможно, наоборот: извлечение, загрузка и преобразование данных. Разница сводится к тому, где происходит преобразование. Преобразования применяются для очистки, соответствия, интеграции и стандартизации данных. Дополнительные сведения см. в разделе "Извлечение", "Преобразование" и "Загрузка" (ETL).
В конечном счете, цель состоит в том, чтобы загрузить правильные данные в корпоративную модель как можно быстрее и эффективно.
В Корпорации Майкрософт мы используем фабрику данных Azure (ADF). Службы используются для планирования и оркестрации проверок данных, преобразований и массовых загрузок из внешних исходных систем в наше озеро данных. Он управляется настраиваемыми фреймворками для обработки данных параллельно и в крупных масштабах. Кроме того, комплексное ведение журналирования осуществляется для поддержки устранения неполадок, мониторинга производительности и активации уведомлений при выполнении определенных условий.
Между тем Azure Databricks — платформы аналитики на основе Apache Spark, оптимизированные для платформы облачных служб Azure, выполняют преобразования специально для обработки и анализа данных. Он также создает и выполняет модели машинного обучения с помощью записных книжек Python. Оценки из этих моделей машинного обучения загружаются в хранилище данных для интеграции прогнозов с корпоративными приложениями и отчетами. Так как Azure Databricks обращается к файлам озера данных напрямую, эта платформа устраняет или сводит к минимуму необходимость копирования или получения данных.
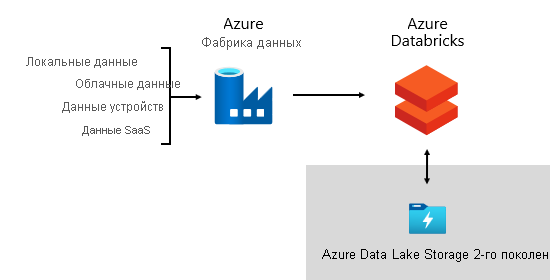
Фреймворк приема
Мы разработали фреймворк для приема данных как набор таблиц конфигурации и процедур. Он поддерживает управляемый данными подход к получению больших объемов данных с высокой скоростью и минимальным кодом. Короче говоря, эта платформа упрощает процесс получения данных для загрузки хранилища данных.
Платформа зависит от таблиц конфигурации, которые хранят сведения о источнике данных и назначении данных, таких как тип источника, сервер, база данных, схема и сведения, связанные с таблицами. Этот подход к проектированию означает, что нам не нужно разрабатывать определенные каналы ADF или пакеты Службы SQL Server Integration Services (SSIS). Вместо этого процедуры написаны на языке нашего выбора для создания конвейеров ADF, которые динамически создаются и выполняются во время выполнения. Таким образом, получение данных становится конфигурационной задачей, которая легко реализуется. Традиционно для создания жестко закодированных пакетов ADF или SSIS требуются обширные ресурсы разработки.
Платформа приема была разработана для упрощения процесса обработки изменений в схеме поставщика данных. Легко обновлять данные конфигурации вручную или автоматически, когда изменения схемы обнаруживаются для получения новых добавленных атрибутов в исходной системе.
Фреймворк оркестрации
Мы разработали платформу оркестрации для эксплуатации и оркестрации конвейеров данных. Платформа оркестрации использует управляемый данными дизайн, который зависит от набора таблиц конфигурации. Эти таблицы хранят метаданные, описывающие зависимости конвейера и как сопоставить исходные данные с целевыми структурами данных. Инвестиции в разработку этой адаптивной платформы с тех пор окупились; больше нет необходимости жестко кодировать каждое перемещение данных.
Хранилище данных
Озеро данных может хранить большие объемы необработанных данных для последующего использования вместе с промежуточными преобразованиями данных.
В Корпорации Майкрософт мы используем ADLS 2-го поколения в качестве единственного источника истины. Он сохраняет необработанные данные вместе с промежуточными данными и готовыми к работе данными. Она предоставляет высокомасштабируемое и экономичное решение озера данных для аналитики больших данных. Сочетая возможности высокопроизводительной файловой системы с большим масштабом, она оптимизирована для рабочих нагрузок аналитики данных, ускоряя получение инсайтов.
ADLS Gen2 представляет собой лучшее из двух миров: это хранилище BLOB-объектов и высокопроизводительное пространство имен файловой системы, которое мы конфигурируем с тонконастраиваемыми разрешениями на доступ.
Затем уточненные данные хранятся в реляционной базе данных для обеспечения высокой производительности, высокомасштабируемого хранилища данных для корпоративных моделей с безопасностью, управлением и управляемостью. Марты данных для конкретных субъектов хранятся в Azure Synapse Analytics, которые загружаются запросами Azure Databricks или Polybase T-SQL.
Потребление данных
На уровне отчетов бизнес-службы используют корпоративные данные, полученные из хранилища данных. Они также получают доступ к данным непосредственно в озере данных для оперативного анализа или задач в области Data Science.
Детализированные разрешения обеспечиваются на всех уровнях: в озере данных, корпоративных моделях и семантических моделях бизнес-аналитики. Разрешения гарантируют, что потребители данных могут просматривать только те данные, к которых они имеют права доступа.
В Корпорации Майкрософт используются отчеты и панели мониторинга Power BI, а также отчеты с разбивкой на страницы Power BI. Некоторые отчеты и нерегламентированный анализ выполняются в Excel, особенно для финансовых отчетов.
Мы публикуем словари данных, предоставляющие справочные сведения о моделях данных. Они предоставляются нашим пользователям, чтобы они могли узнать информацию о нашей платформе бизнес-аналитики. Словари документируют проектирование моделей, предоставляя описания сущностей, форматов, структуры, происхождения данных, связей и вычислений. Мы используем каталог данных Azure для упрощения обнаружения и понимания источников данных.
Как правило, шаблоны потребления данных различаются на основе роли:
- Аналитики данных подключаются непосредственно к основным семантическим моделям бизнес-аналитики. Если основные семантические модели бизнес-аналитики содержат все необходимые данные и логику, они используют динамические подключения для создания отчетов и панелей мониторинга Power BI. Когда им нужно расширить модели с помощью данных отдела, они создают составные модели Power BI. Если существует необходимость в отчетах по стилю электронной таблицы, они используют Excel для создания отчетов на основе основных семантических моделей бизнес-аналитики или семантических моделей отделов бизнес-аналитики.
- Разработчики бизнес-аналитики и разработчики операционных отчетов подключаются непосредственно к корпоративным моделям. Они используют Power BI Desktop для создания динамических отчетов аналитики подключений. Они также могут создавать отчеты бизнес-аналитики рабочего типа в виде отчетов Power BI с разбивкой на страницы, создавая собственные запросы SQL для доступа к данным из корпоративных моделей Azure Synapse Analytics с помощью T-SQL или семантических моделей Power BI с помощью DAX или многомерных выражений.
- Специалисты по обработке и анализу данных подключаются непосредственно к данным в озере данных. Они используют записные книжки Azure Databricks и Python для разработки моделей машинного обучения, которые часто являются экспериментальными и требуют специальных навыков для использования в рабочей среде.
Связанный контент
Дополнительные сведения об этой статье см. в следующих ресурсах:
- Дорожная карта внедрения платформы: Центр компетенции
- Корпоративная бизнес-аналитика в Azure с Azure Synapse Analytics
- Вопросы? попробуйте обратиться к сообществу Fabric
- Предложения? Вносите идеи для улучшения Fabric
Профессиональные услуги
Сертифицированные партнеры Power BI могут помочь вашей организации добиться успеха при настройке COE. Они могут предоставлять вам экономичное обучение или аудит данных. Чтобы найти партнера Power BI, перейдите на портал партнеров Microsoft Power BI .
Вы также можете взаимодействовать с опытными партнерами-консультантами. Они могут помочь вам оценить, оценить или реализовать Power BI.