Den här arkitekturen ger vägledning för att utforma en verksamhetskritisk arbetsbelastning i Azure. Den använder molnbaserade funktioner för att maximera tillförlitligheten och drifteffektiviteten. Den tillämpar designmetoden för välarkitekterade verksamhetskritiska arbetsbelastningar på ett internetbaserat program, där arbetsbelastningen nås via en offentlig slutpunkt och inte kräver privat nätverksanslutning till andra företagsresurser.
Viktigt!
 Vägledningen stöds av ett exempelimplementering i produktionsklass som visar verksamhetskritisk programutveckling i Azure. Den här implementeringen kan användas som grund för ytterligare lösningsutveckling i ditt första steg mot produktion.
Vägledningen stöds av ett exempelimplementering i produktionsklass som visar verksamhetskritisk programutveckling i Azure. Den här implementeringen kan användas som grund för ytterligare lösningsutveckling i ditt första steg mot produktion.
Tillförlitlighetsnivå
Tillförlitlighet är ett relativt begrepp, och för att en arbetsbelastning ska vara korrekt tillförlitlig bör den återspegla de affärskrav som omger den, inklusive servicenivåmål (SLO) och serviceavtal (SLA), för att samla in procentandelen av tiden som programmet ska vara tillgängligt.
Den här arkitekturen är avsedd för ett servicemål på 99,99 %, vilket motsvarar en tillåten årlig stilleståndstid på 52 minuter och 35 sekunder. Alla omfattande designbeslut är därför avsedda att uppnå detta mål-SLO.
Dricks
För att definiera ett realistiskt serviceavtal är det viktigt att förstå serviceavtalet för alla Azure-komponenter i arkitekturen. Dessa enskilda tal bör aggregeras för att fastställa ett sammansatt serviceavtal som ska överensstämma med arbetsbelastningsmål.
Se Väldefinierade verksamhetskritiska arbetsbelastningar: Design för affärskrav.
Viktiga designstrategier
Många faktorer kan påverka tillförlitligheten för ett program, till exempel möjligheten att återställa från fel, regional tillgänglighet, distributionseffektivitet och säkerhet. Den här arkitekturen tillämpar en uppsättning övergripande designstrategier som är avsedda att hantera dessa faktorer och säkerställa att måltillförlitlighetsnivån uppnås.
Redundans i lager
Distribuera till flera regioner i en aktiv-aktiv modell. Programmet distribueras i två eller flera Azure-regioner som hanterar aktiv användartrafik.
Använd tillgänglighetszoner för alla tjänster som övervägs för att maximera tillgängligheten i en enda Azure-region och distribuera komponenter mellan fysiskt separata datacenter i en region.
Välj resurser som stöder global distribution.
Se Väldefinierade verksamhetskritiska arbetsbelastningar: Global distribution.
Distributionsstämplar
Distribuera en regional stämpel som en skalningsenhet där en logisk uppsättning resurser kan etableras oberoende för att hänga med i efterfrågeändringarna. Varje stämpel tillämpar också flera kapslade skalningsenheter, till exempel klientdels-API:er och bakgrundsprocessorer som kan skalas in och ut oberoende av varandra.
Se Välarkitekterade verksamhetskritiska arbetsbelastningar: Arkitektur för skalningsenheter.
Tillförlitliga och repeterbara distributioner
Tillämpa principen infrastruktur som kod (IaC) med hjälp av tekniker, till exempel Terraform, för att tillhandahålla versionskontroll och en standardiserad driftmetod för infrastrukturkomponenter.
Implementera blå/gröna distributionspipelines utan stilleståndstid. Bygg- och versionspipelines måste vara helt automatiserade för att distribuera stämplar som en enda driftenhet med hjälp av blå/gröna distributioner med kontinuerlig validering tillämpad.
Tillämpa miljökonsekvens i alla miljöövervägande miljöer med samma distributionspipelinekod i produktions- och förproduktionsmiljöer. Detta eliminerar risker som är kopplade till distribution och processvariationer i olika miljöer.
Ha kontinuerlig validering genom att integrera automatiserad testning som en del av DevOps-processer, inklusive synkroniserad belastning och kaostestning, för att fullständigt verifiera hälsotillståndet för både programkoden och den underliggande infrastrukturen.
Se Väldefinierade verksamhetskritiska arbetsbelastningar: Distribution och testning.
Driftinsikter
Ha federerade arbetsytor för observerbarhetsdata. Övervakningsdata för globala resurser och regionala resurser lagras oberoende av varandra. Ett centraliserat observerbarhetslager rekommenderas inte för att undvika en enda felpunkt. Frågor mellan arbetsytor används för att uppnå en enhetlig datamottagare och en enda fönsterruta för åtgärder.
Konstruera en hälsomodell med flera lager som mappar programmets hälsa till en trafikljusmodell för kontextualisering. Hälsopoäng beräknas för varje enskild komponent och aggregeras sedan på användarflödesnivå och kombineras med viktiga icke-funktionella krav, till exempel prestanda, som koefficienter för att kvantifiera programmets hälsa.
Se Välarkitekterade verksamhetskritiska arbetsbelastningar: Hälsomodellering.
Arkitektur

*Ladda ned en Visio-fil med den här arkitekturen.
Komponenterna i den här arkitekturen kan kategoriseras brett på det här sättet. Produktdokumentation om Azure-tjänster finns i Relaterade resurser.
Globala resurser
De globala resurserna lever länge och delar systemets livslängd. De har möjlighet att vara globalt tillgängliga inom ramen för en distributionsmodell för flera regioner.
Här följer de övergripande övervägandena om komponenterna. Detaljerad information om besluten finns i Globala resurser.
Global lastbalanserare
En global lastbalanserare är viktig för att tillförlitligt dirigera trafik till de regionala distributionerna med viss garantinivå baserat på tillgängligheten för serverdelstjänster i en region. Dessutom bör den här komponenten ha möjlighet att inspektera inkommande trafik, till exempel via brandväggen för webbprogram.
Azure Front Door används som global startpunkt för all inkommande HTTP(S)-trafik för klienter, med WAF-funktioner (Web Application Firewall) som används för säker layer 7-inkommande trafik. Den använder TCP Anycast för att optimera routning med hjälp av Microsofts stamnätverk och möjliggör transparent redundans vid försämrad regional hälsa. Routning är beroende av anpassade hälsoavsökningar som kontrollerar den sammansatta heden för viktiga regionala resurser. Azure Front Door tillhandahåller också ett inbyggt nätverk för innehållsleverans (CDN) som cachelagrar statiska tillgångar för webbplatskomponenten.
Ett annat alternativ är Traffic Manager, som är en DNS-baserad Layer 4-lastbalanserare. Felet är dock inte transparent för alla klienter eftersom DNS-spridning måste ske.
Se Väldefinierade verksamhetskritiska arbetsbelastningar: Global trafikroutning.
Databas
Alla tillstånd som är relaterade till arbetsbelastningen lagras i en extern databas, Azure Cosmos DB för NoSQL. Det här alternativet valdes eftersom det har den funktionsuppsättning som krävs för prestanda- och tillförlitlighetsjustering, både på klient- och serversidan. Vi rekommenderar starkt att kontot har aktiverat skrivning med flera original.
Kommentar
Även om en konfiguration för skrivning i flera regioner representerar guldstandarden för tillförlitlighet, finns det en betydande kompromiss om kostnaden, som bör övervägas korrekt.
Kontot replikeras till varje regional stämpel och har även zonredundans aktiverat. Dessutom aktiveras automatisk skalning på containernivå så att containrar automatiskt skalar det etablerade dataflödet efter behov.
Mer information finns i Dataplattform för verksamhetskritiska arbetsbelastningar.
Se Väldefinierade verksamhetskritiska arbetsbelastningar: Globalt distribuerat datalager för flera skrivningar.
Containerregister
Azure Container Registry används för att lagra alla containeravbildningar. Den har geo-replikeringsfunktioner som gör att resurserna kan fungera som ett enda register som betjänar flera regioner med regionala register med flera huvudservrar.
Som en säkerhetsåtgärd tillåter du endast åtkomst till nödvändiga entiteter och autentiserar den åtkomsten. I implementeringen inaktiveras till exempel administratörsåtkomst. Därför kan beräkningsklustret endast hämta avbildningar med Microsoft Entra-rolltilldelningar.
Se Väldefinierade verksamhetskritiska arbetsbelastningar: Containerregister.
Regionala resurser
De regionala resurserna etableras som en del av en distributionsstämpel till en enda Azure-region. Dessa resurser delar ingenting med resurser i en annan region. De kan tas bort eller replikeras separat till ytterligare regioner. De delar dock globala resurser mellan varandra.
I den här arkitekturen distribuerar en enhetlig distributionspipeline en stämpel med dessa resurser.
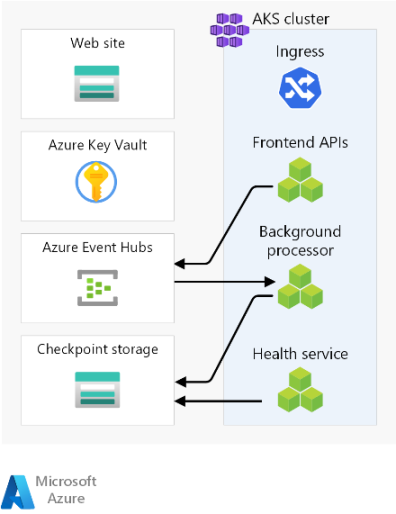
Här följer de övergripande övervägandena om komponenterna. Detaljerad information om besluten finns i Regionala stämpelresurser.
Klientdel
Den här arkitekturen använder ett ensidesprogram (SPA) som skickar begäranden till serverdelstjänster. En fördel är att den beräkning som behövs för webbplatsupplevelsen avlastas till klienten i stället för dina servrar. SPA:et finns som en statisk webbplats i ett Azure Storage-konto.
Ett annat val är Azure Static Web Apps, som introducerar ytterligare överväganden, till exempel hur certifikaten exponeras, anslutning till en global lastbalanserare och andra faktorer.
Statiskt innehåll cachelagras vanligtvis i ett arkiv nära klienten med hjälp av ett nätverk för innehållsleverans (CDN), så att data kan hanteras snabbt utan att kommunicera direkt med serverdelsservrar. Det är ett kostnadseffektivt sätt att öka tillförlitligheten och minska nätverksfördröjningen. I den här arkitekturen används de inbyggda CDN-funktionerna i Azure Front Door för att cachelagras statiskt webbplatsinnehåll i gränsnätverket.
Beräkningskluster
Serverdelsberäkningen kör ett program som består av tre mikrotjänster och är tillståndslös. Containerisering är därför en lämplig strategi för att vara värd för programmet. Azure Kubernetes Service (AKS) valdes eftersom det uppfyller de flesta affärskrav och Kubernetes används i många branscher. AKS stöder avancerad skalbarhet och distributionstopologier. AKS Uptime SLA-nivån rekommenderas starkt för att vara värd för verksamhetskritiska program eftersom det ger tillgänglighetsgarantier för Kubernetes-kontrollplanet.
Azure erbjuder andra beräkningstjänster, till exempel Azure Functions och Azure App Services. Dessa alternativ avlastar ytterligare hanteringsansvar till Azure på bekostnad av flexibilitet och densitet.
Kommentar
Undvik att lagra tillstånd i beräkningsklustret med tanke på stämplarnas tillfälliga karaktär. Så mycket som möjligt bevarar du tillståndet i en extern databas för att hålla skalnings- och återställningsåtgärderna lätta. Till exempel i AKS ändras poddar ofta. Om du kopplar tillstånd till poddar läggs datakonsekvensen till.
Se Välarkitekterade verksamhetskritiska arbetsbelastningar: Container Orchestration och Kubernetes.
Regional meddelandekö
För att optimera prestanda och upprätthålla svarstider vid hög belastning använder designen asynkrona meddelanden för att hantera intensiva systemflöden. Eftersom en begäran snabbt bekräftas tillbaka till klientdels-API:erna placeras även begäran i en meddelandekö. Dessa meddelanden förbrukas därefter av en serverdelstjänst som till exempel hanterar en skrivåtgärd till en databas.
Hela stämpeln är tillståndslös förutom vid vissa tidpunkter, till exempel den här meddelandekoordinatorn. Data placeras i kö i asynkron meddelandekö under en kort tidsperiod. Meddelandekoordinatorn måste garantera leverans minst en gång. Det innebär att meddelanden kommer att finnas i kön, om asynkron meddelandekö blir otillgänglig när tjänsten har återställts. Det är dock konsumentens ansvar att avgöra om dessa meddelanden fortfarande behöver bearbetas. Kön töms när meddelandet har bearbetats och lagrats i en global databas.
I den här designen används Azure Event Hubs . Ytterligare ett Azure Storage-konto etableras för kontrollpunkter. Event Hubs är det rekommenderade valet för användningsfall som kräver högt dataflöde, till exempel händelseströmning.
För användningsfall som kräver ytterligare meddelandegarantier rekommenderas Azure Service Bus. Det möjliggör incheckningar i två faser med en markör på klientsidan, samt funktioner som en inbyggd kö med obeställbara bokstäver och dedupliceringsfunktioner.
Mer information finns i Meddelandetjänster för verksamhetskritiska arbetsbelastningar.
Se Välarkitekterade verksamhetskritiska arbetsbelastningar: Löst kopplad händelsedriven arkitektur.
Regionalt hemligt arkiv
Varje stämpel har ett eget Azure Key Vault som lagrar hemligheter och konfiguration. Det finns vanliga hemligheter som anslutningssträng till den globala databasen, men det finns också information som är unik för en enda stämpel, till exempel Event Hubs-anslutningssträng. Oberoende resurser undviker också en enskild felpunkt.
Se Väldefinierade verksamhetskritiska arbetsbelastningar: Dataskydd.
Distributionspipeline
Bygg- och versionspipelines för ett verksamhetskritiskt program måste vara helt automatiserade. Därför behöver ingen åtgärd utföras manuellt. Den här designen visar helt automatiserade pipelines som distribuerar en validerad stämpel konsekvent varje gång. En annan alternativ metod är att endast distribuera löpande uppdateringar till en befintlig stämpel.
Källkodslagringsplats
GitHub används för källkontroll, vilket ger en git-baserad plattform med hög tillgänglighet för samarbete om programkod och infrastrukturkod.
CI/CD-pipelines (Continuous Integration/Continuous Delivery)
Automatiserade pipelines krävs för att skapa, testa och distribuera en uppdragsarbetsbelastning i förproduktions - och produktionsmiljöer. Azure Pipelines väljs med tanke på dess omfattande verktygsuppsättning som kan riktas mot Azure och andra molnplattformar.
Ett annat val är GitHub Actions för CI/CD-pipelines. Den extra fördelen är att källkoden och pipelinen kan sammanställas. Azure Pipelines valdes dock på grund av de rikare CD-funktionerna.
Se Väldefinierade verksamhetskritiska arbetsbelastningar: DevOps-processer.
Skapa agenter
Microsoft-värdbaserade byggagenter används av den här implementeringen för att minska komplexiteten och hanteringskostnaderna. Lokalt installerade agenter kan användas för scenarier som kräver en härdad säkerhetsstatus.
Kommentar
Användningen av lokalt installerade agenter visas i referensimplementeringen Mission Critical – Anslut ed.
Observerbarhetsresurser
Driftdata från program och infrastruktur måste vara tillgängliga för att möjliggöra effektiva åtgärder och maximera tillförlitligheten. Den här referensen ger en baslinje för att uppnå holistisk observerbarhet för ett program.
Enhetlig datamottagare
- Azure Log Analytics används som en enhetlig mottagare för att lagra loggar och mått för alla program- och infrastrukturkomponenter.
- Azure Application Insights används som ett APM-verktyg (Application Performance Management) för att samla in alla programövervakningsdata och lagra dem direkt i Log Analytics.

Övervakningsdata för globala resurser och regionala resurser bör lagras oberoende av varandra. Ett enda centraliserat observerbarhetslager rekommenderas inte för att undvika en enda felpunkt. Frågor mellan arbetsytor används för att uppnå en enda fönsterruta.
I den här arkitekturen måste övervakningsresurser inom en region vara oberoende av själva stämpeln, för om du tar bort en stämpel vill du fortfarande bevara observerbarheten. Varje regional stämpel har en egen dedikerad Application Insights- och Log Analytics-arbetsyta. Resurserna etableras per region, men de överlever stämplarna.
På samma sätt lagras data från delade tjänster som Azure Front Door, Azure Cosmos DB och Container Registry i en dedikerad instans av Log Analytics-arbetsytan.
Dataarkivering och analys
Driftdata som inte krävs för aktiva åtgärder exporteras från Log Analytics till Azure Storage-konton i båda datakvarhållningssyftena och för att tillhandahålla en analyskälla för AIOps, som kan användas för att optimera programmets hälsomodell och operativa procedurer.
Se Väldefinierade verksamhetskritiska arbetsbelastningar: Förutsägande åtgärder och AI-åtgärder.
Begärande- och processorflöden
Den här bilden visar begäran och bakgrundsprocessorflödet för referensimplementeringen.

Beskrivningen av det här flödet finns i följande avsnitt.
Flöde för webbplatsbegäran
En begäran om webbanvändargränssnittet skickas till en global lastbalanserare. För den här arkitekturen är den globala lastbalanseraren Azure Front Door.
WAF-reglerna utvärderas. WAF-regler påverkar systemets tillförlitlighet positivt genom att skydda mot en mängd olika attacker, till exempel XSS (cross-site scripting) och SQL-inmatning. Azure Front Door returnerar ett fel till beställaren om en WAF-regel överträds och bearbetningen stoppas. Om inga WAF-regler överträds fortsätter Azure Front Door bearbetningen.
Azure Front Door använder routningsregler för att avgöra vilken serverdelspool som en begäran ska vidarebefordras till. Hur begäranden matchas med en routningsregel. I den här referensimplementeringen tillåter routningsreglerna Att Azure Front Door dirigerar API-begäranden och klientdels-API:er till olika serverdelsresurser. I det här fallet matchar mönstret "/*" UI-routningsregeln. Den här regeln dirigerar begäran till en serverdelspool som innehåller lagringskonton med statiska webbplatser som är värdar för spa-programmet (Single Page Application). Azure Front Door använder prioriteten och vikten som tilldelats serverdelarna i poolen för att välja serverdelen för att dirigera begäran. Trafikroutningsmetoder till ursprung. Azure Front Door använder hälsoavsökningar för att säkerställa att begäranden inte dirigeras till serverdelar som inte är felfria. SPA:et hanteras från det valda lagringskontot med statisk webbplats.
Kommentar
Termerna serverdelspooler och serverdelar i Azure Front Door Classic kallas ursprungsgrupper och ursprung i Azure Front Door Standard- eller Premium-nivåer.
SPA gör ett API-anrop till Azure Front Door-klientdelsvärden. Mönstret för URL:en för API-begäran är "/api/*".
Api-begärandeflöde för klientdels-API
WAF-reglerna utvärderas som i steg 2.
Azure Front Door matchar begäran till API-routningsregeln med mönstret "/api/*". API-routningsregeln dirigerar begäran till en serverdelspool som innehåller offentliga IP-adresser för NGINX-ingresskontrollanter som vet hur man dirigerar begäranden till rätt tjänst i Azure Kubernetes Service (AKS). Precis som tidigare använder Azure Front Door den prioritet och vikt som tilldelats serverdelarna för att välja rätt NGINX-ingresskontrollantsserverdel.
För GET-begäranden utför klientdels-API:et läsåtgärder på en databas. För den här referensimplementeringen är databasen en global Azure Cosmos DB-instans. Azure Cosmos DB har flera funktioner som gör det till ett bra val för en verksamhetskritisk arbetsbelastning, inklusive möjligheten att enkelt konfigurera regioner med flera skrivningar, vilket möjliggör automatisk redundans för läsningar och skrivningar till sekundära regioner. API:et använder klient-SDK:n som konfigurerats med omprövningslogik för att kommunicera med Azure Cosmos DB. SDK avgör den optimala ordningen för tillgängliga Azure Cosmos DB-regioner att kommunicera med baserat på parametern ApplicationRegion.
För POST- eller PUT-begäranden utför klientdels-API:et skrivningar till en meddelandekö. I referensimplementeringen är meddelandekoordinatorn Azure Event Hubs. Du kan också välja Service Bus. En hanterare läser senare meddelanden från meddelandekoordinatorn och utför alla nödvändiga skrivningar till Azure Cosmos DB. API:et använder klient-SDK:n för att utföra skrivningar. Klienten kan konfigureras för återförsök.
Bakgrundsprocessorflöde
Bakgrundsprocessorerna bearbetar meddelanden från meddelandekoordinatorn. Bakgrundsprocessorerna använder klient-SDK:et för att utföra läsningar. Klienten kan konfigureras för återförsök.
Bakgrundsprocessorerna utför lämpliga skrivåtgärder på den globala Azure Cosmos DB-instansen. Bakgrundsprocessorerna använder klient-SDK:et som konfigurerats med ett nytt försök att ansluta till Azure Cosmos DB. Klientens föredragna regionlista kan konfigureras med flera regioner. I så fall, om en skrivning misslyckas, görs återförsöket i nästa önskade region.
Designområden
Vi rekommenderar att du utforskar dessa designområden för rekommendationer och vägledning för bästa praxis när du definierar din verksamhetskritiska arkitektur.
| Designområde | beskrivning |
|---|---|
| Programdesign | Designmönster som möjliggör skalning och felhantering. |
| Programplattform | Alternativ och åtgärder för infrastruktur för potentiella felfall. |
| Dataplattform | Val i datalagertekniker, informerade genom att utvärdera nödvändiga egenskaper för volym, hastighet, variation och sanningshalt. |
| Nätverk och anslutning | Nätverksöverväganden för att dirigera inkommande trafik till stämplar. |
| Hälsomodellering | Observerbarhetsöverväganden via kundpåverkansanalys korrelerad övervakning för att fastställa övergripande programhälsa. |
| Distribution och testning | Strategier för CI/CD-pipelines och automatiseringsöverväganden, med inkorporerade testscenarier, till exempel synkroniserad belastningstestning och haveriinmatning (kaos). |
| Säkerhet | Minskning av attackvektorer via Microsoft Nolltillit modell. |
| Operativa procedurer | Processer som rör distribution, nyckelhantering, korrigering och uppdateringar. |
** Anger designområdesöverväganden som är specifika för den här arkitekturen.
Relaterade resurser
Produktdokumentation om De Azure-tjänster som används i den här arkitekturen finns i de här artiklarna.
- Azure Front Door
- Azure Cosmos DB
- Azure Container Registry
- Azure Log Analytics
- Azure Key Vault
- Azure Service Bus
- Azure Kubernetes Service
- Azure Application Insights
- Azure Event Hubs
- Azure Blob Storage
Distribuera den här arkitekturen
Distribuera referensimplementeringen för att få en fullständig förståelse för övervägda resurser, inklusive hur de operationaliseras i en verksamhetskritisk kontext. Den innehåller en distributionsguide som är avsedd att illustrera en lösningsorienterad metod för verksamhetskritisk programutveckling i Azure.
Nästa steg
Om du vill utöka baslinjearkitekturen med nätverkskontroller för inkommande och utgående trafik kan du läsa den här arkitekturen.