Kopiera data från och till Oracle med hjälp av Azure Data Factory eller Azure Synapse Analytics
GÄLLER FÖR:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dricks
Prova Data Factory i Microsoft Fabric, en allt-i-ett-analyslösning för företag. Microsoft Fabric omfattar allt från dataflytt till datavetenskap, realtidsanalys, business intelligence och rapportering. Lär dig hur du startar en ny utvärderingsversion kostnadsfritt!
Den här artikeln beskriver hur du använder kopieringsaktiviteten i Azure Data Factory för att kopiera data från och till en Oracle-databas. Den bygger på översikten över kopieringsaktiviteten.
Funktioner som stöds
Den här Oracle-anslutningsappen stöds för följande funktioner:
| Funktioner som stöds | IR |
|---|---|
| Kopieringsaktivitet (källa/mottagare) | (1) (2) |
| Sökningsaktivitet | (1) (2) |
| Skriptaktivitet | (1) (2) |
(1) Azure Integration Runtime (2) Lokalt installerad integrationskörning
En lista över datalager som stöds som källor eller mottagare av kopieringsaktiviteten finns i tabellen Datalager som stöds.
Mer specifikt stöder den här Oracle-anslutningsappen:
- Följande versioner av en Oracle-databas:
- Oracle 19c R1 (19.1) och senare
- Oracle 18c R1 (18.1) och senare
- Oracle 12c R1 (12.1) och senare
- Oracle 11g R1 (11.1) och högre
- Oracle 10g R1 (10.1) och högre
- Oracle 9i R2 (9,2) och högre
- Oracle 8i R3 (8.1.7) och senare
- Oracle Database Cloud Exadata Service
- Parallell kopiering från en Oracle-källa. Mer information finns i avsnittet Parallell kopia från Oracle .
Kommentar
Oracle-proxyserver stöds inte.
Förutsättningar
Om ditt datalager finns i ett lokalt nätverk, ett virtuellt Azure-nätverk eller Amazon Virtual Private Cloud måste du konfigurera en lokalt installerad integrationskörning för att ansluta till det.
Om ditt datalager är en hanterad molndatatjänst kan du använda Azure Integration Runtime. Om åtkomsten är begränsad till IP-adresser som är godkända i brandväggsreglerna kan du lägga till Azure Integration Runtime-IP-adresser i listan över tillåtna.
Du kan också använda funktionen för integrering av hanterade virtuella nätverk i Azure Data Factory för att få åtkomst till det lokala nätverket utan att installera och konfigurera en lokalt installerad integrationskörning.
Mer information om de nätverkssäkerhetsmekanismer och alternativ som stöds av Data Factory finns i Strategier för dataåtkomst.
Integreringskörningen tillhandahåller en inbyggd Oracle-drivrutin. Därför behöver du inte installera en drivrutin manuellt när du kopierar data från och till Oracle.
Kom igång
Om du vill utföra kopieringsaktiviteten med en pipeline kan du använda något av följande verktyg eller SDK:er:
- Verktyget Kopiera data
- Azure-portalen
- The .NET SDK
- The Python SDK
- Azure PowerShell
- REST-API:et
- Azure Resource Manager-mallen
Skapa en länkad tjänst till Oracle med hjälp av användargränssnittet
Använd följande steg för att skapa en länkad tjänst till Oracle i azure-portalens användargränssnitt.
Bläddra till fliken Hantera i Din Azure Data Factory- eller Synapse-arbetsyta och välj Länkade tjänster och klicka sedan på Ny:
Sök efter Oracle och välj Oracle-anslutningsappen.
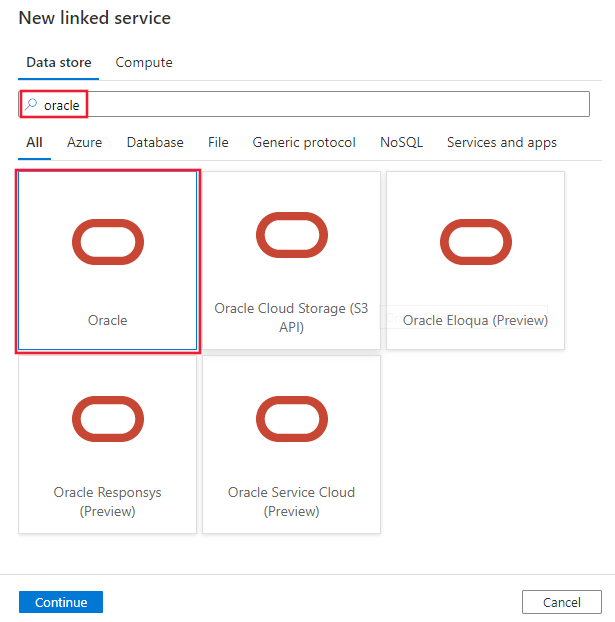
Konfigurera tjänstinformationen, testa anslutningen och skapa den nya länkade tjänsten.
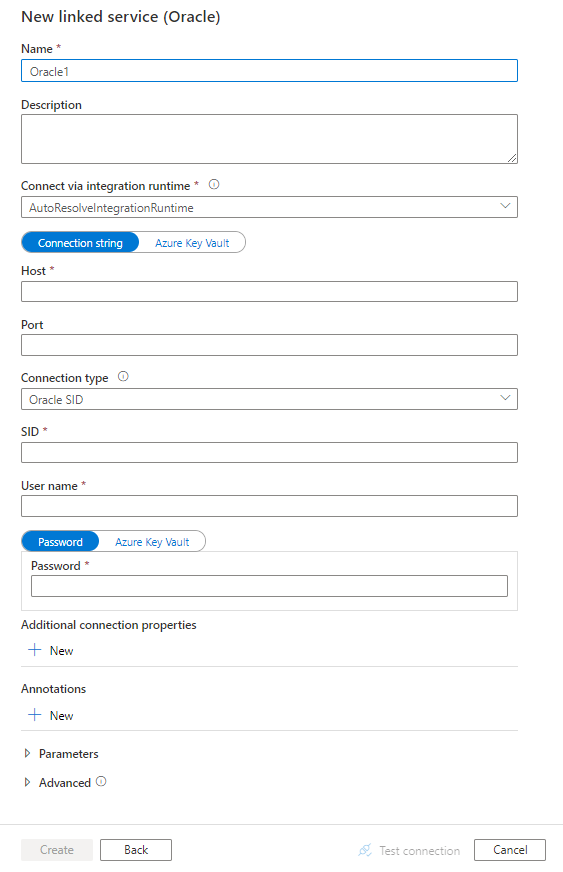
Konfigurationsinformation för anslutningsprogram
Följande avsnitt innehåller information om egenskaper som används för att definiera entiteter som är specifika för Oracle-anslutningsappen.
Länkade tjänstegenskaper
Den länkade Oracle-tjänsten har stöd för följande egenskaper:
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| type | Typegenskapen måste vara inställd på Oracle. | Ja |
| connectionString | Anger den information som behövs för att ansluta till Oracle Database-instansen. Du kan också placera ett lösenord i Azure Key Vault och hämta konfigurationen password från niska veze. Mer information finns i följande exempel och Lagra autentiseringsuppgifter i Azure Key Vault . Anslutningstyp som stöds: Du kan använda Oracle SID eller Oracle-tjänstnamn för att identifiera din databas: – Om du använder SID: Host=<host>;Port=<port>;Sid=<sid>;User Id=<username>;Password=<password>;– Om du använder tjänstnamn: Host=<host>;Port=<port>;ServiceName=<servicename>;User Id=<username>;Password=<password>;För avancerade inbyggda Oracle-anslutningsalternativ kan du välja att lägga till en post i TNSNAMES. ORA-fil på Oracle-servern och i Oracle-länkad tjänst väljer du att använda anslutningstypen Oracle-tjänstnamn och konfigurera motsvarande tjänstnamn. |
Ja |
| connectVia | Den integrationskörning som ska användas för att ansluta till datalagret. Läs mer i avsnittet Förutsättningar . Om det inte anges används standardkörningen för Azure Integration Runtime. | Nej |
Dricks
Om du får ett fel, "ORA-01025: UPI parameter out of range", och oracle-versionen är 8i, lägger du till WireProtocolMode=1 i din niska veze. Försök sedan igen.
Om du har flera Oracle-instanser för redundansscenario kan du skapa oracle-länkad tjänst och fylla i den primära värden, porten, användarnamnet, lösenordet osv. och lägga till en ny "Ytterligare anslutningsegenskaper" med egenskapsnamn som AlternateServers och värde som (HostName=<secondary host>:PortNumber=<secondary port>:ServiceName=<secondary service name>) – missa inte hakparenteserna och var uppmärksam på kolonen (:) som avgränsare. Till exempel definierar följande värde för alternativa servrar två alternativa databasservrar för redundans vid anslutning: (HostName=AccountingOracleServer:PortNumber=1521:SID=Accounting,HostName=255.201.11.24:PortNumber=1522:ServiceName=ABackup.NA.MyCompany).
Fler anslutningsegenskaper som du kan ange i niska veze per ditt ärende:
| Property | beskrivning | Tillåtna värden |
|---|---|---|
| Matrisstorlek | Antalet byte som anslutningsappen kan hämta i ett enda nätverk tur och retur. T.ex. ArraySize=10485760.Större värden ökar dataflödet genom att minska antalet gånger som data hämtas i nätverket. Mindre värden ökar svarstiden, eftersom det är mindre fördröjning som väntar på att servern ska överföra data. |
Ett heltal från 1 till 4294967296 (4 GB). Standardvärdet är 60000. Värdet 1 definierar inte antalet byte, men anger allokering av utrymme för exakt en rad med data. |
Om du vill aktivera kryptering på Oracle-anslutning har du två alternativ:
Om du vill använda Triple-DES Encryption (3DES) och Advanced Encryption Standard (AES) går du till Oracle Advanced Security (OAS) och konfigurerar krypteringsinställningarna på Oracle-serversidan. Mer information finns i den här Oracle-dokumentationen. Oracle Application Development Framework-anslutningsappen (ADF) förhandlar automatiskt om krypteringsmetoden för att använda den som du konfigurerar i OAS när du upprättar en anslutning till Oracle.
Om du vill använda TLS konfigurerar
truststoredu för SSL-serverautentisering genom att använda någon av följande tre metoder:Metod 1 (rekommenderas):
Installera TLS/SSL-certifikatet genom att importera det till det lokala certifikatarkivet. Den inbyggda Oracle-drivrutinen kan läsa in det certifikat som behövs från certifikatarkivet.
I tjänsten konfigurerar du Oracle-niska veze med
EncryptionMethod=1.
Metod 2:
Hämta TLS/SSL-certifikatinformationen. Hämta den unika kodningsreglerna (DER)-kodad eller PEM-kodad certifikatinformation (Privacy Enhanced Mail) för ditt TLS/SSL-certifikat.
openssl x509 -inform (DER|PEM) -in [Full Path to the DER/PEM Certificate including the name of the DER/PEM Certificate] -textI tjänsten konfigurerar du Oracle-niska veze med
EncryptionMethod=1och motsvarandeTrustStorevärde. Till exempel:Host=<host>;Port=<port>;Sid=<sid>;User Id=<username>;Password=<password>;EncryptionMethod=1;TrustStore= data:// -----BEGIN CERTIFICATE-----<certificate content>-----END CERTIFICATE-----Kommentar
- Värdet för fältet
TrustStoreska vara prefixet meddata://. - När du anger innehåll för flera certifikat anger du innehållet i varje certifikat mellan
-----BEGIN CERTIFICATE-----och-----END CERTIFICATE-----. Antalet bindestreck (-----) ska vara detsamma före och efter bådeBEGIN CERTIFICATEochEND CERTIFICATE. Till exempel:
-----BEGIN CERTIFICATE-----<certificate content 1>-----END CERTIFICATE-----
-----BEGIN CERTIFICATE-----<certificate content 2>-----END CERTIFICATE-----
-----BEGIN CERTIFICATE-----<certificate content 3>-----END CERTIFICATE----- - Fältet
TrustStorestöder innehåll på upp till 8 192 tecken.
- Värdet för fältet
Metod 3:
truststoreSkapa filen med starka chiffer som AES256.openssl pkcs12 -in [Full Path to the DER/PEM Certificate including the name of the DER/PEM Certificate] -out [Path and name of TrustStore] -passout pass:[Keystore PWD] -keypbe AES-256-CBC -certpbe AES-256-CBC -nokeys -exporttruststorePlacera filen på den lokalt installerade integrationskörningsdatorn. Placera till exempel filen påC:\MyTrustStoreFile.I tjänsten konfigurerar du Oracle-niska veze med
EncryptionMethod=1och motsvarandeTrustStore/TrustStorePasswordvärde. Till exempelHost=<host>;Port=<port>;Sid=<sid>;User Id=<username>;Password=<password>;EncryptionMethod=1;TrustStore=C:\\MyTrustStoreFile;TrustStorePassword=<trust_store_password>.
Exempel:
{
"name": "OracleLinkedService",
"properties": {
"type": "Oracle",
"typeProperties": {
"connectionString": "Host=<host>;Port=<port>;Sid=<sid>;User Id=<username>;Password=<password>;"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Exempel: Lagra lösenord i Azure Key Vault
{
"name": "OracleLinkedService",
"properties": {
"type": "Oracle",
"typeProperties": {
"connectionString": "Host=<host>;Port=<port>;Sid=<sid>;User Id=<username>;",
"password": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Egenskaper för datauppsättning
Det här avsnittet innehåller en lista över egenskaper som stöds av Oracle-datamängden. En fullständig lista över avsnitt och egenskaper som är tillgängliga för att definiera datauppsättningar finns i Datauppsättningar.
Om du vill kopiera data från och till Oracle anger du typegenskapen för datauppsättningen till OracleTable. Följande egenskaper stöds.
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| type | Datamängdens typegenskap måste anges till OracleTable. |
Ja |
| schema | Namnet på schemat. | Nej för källa, Ja för mottagare |
| table | Namnet på tabellen/vyn. | Nej för källa, Ja för mottagare |
| tableName | Namnet på tabellen/vyn med schemat. Den här egenskapen stöds för bakåtkompatibilitet. För ny arbetsbelastning använder du schema och table. |
Nej för källa, Ja för mottagare |
Exempel:
{
"name": "OracleDataset",
"properties":
{
"type": "OracleTable",
"schema": [],
"typeProperties": {
"schema": "<schema_name>",
"table": "<table_name>"
},
"linkedServiceName": {
"referenceName": "<Oracle linked service name>",
"type": "LinkedServiceReference"
}
}
}
Kopiera egenskaper för aktivitet
Det här avsnittet innehåller en lista över egenskaper som stöds av Oracle-källan och mottagaren. En fullständig lista över avsnitt och egenskaper som är tillgängliga för att definiera aktiviteter finns i Pipelines.
Oracle som källa
Dricks
Om du vill läsa in data från Oracle effektivt med hjälp av datapartitionering kan du läsa mer från Parallell kopiering från Oracle.
Om du vill kopiera data från Oracle anger du källtypen i kopieringsaktiviteten till OracleSource. Följande egenskaper stöds i avsnittet kopieringsaktivitetskälla.
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| type | Typegenskapen för kopieringsaktivitetskällan måste vara inställd på OracleSource. |
Ja |
| oracleReaderQuery | Använd den anpassade SQL-frågan för att läsa data. Ett exempel är "SELECT * FROM MyTable".När du aktiverar partitionerad belastning måste du koppla motsvarande inbyggda partitionsparametrar i frågan. Exempel finns i avsnittet Parallell kopia från Oracle . |
Nej |
| convertDecimalToInteger | Oracle NUMBER-typen med noll eller ospecificerad skala konverteras till motsvarande heltal. Tillåtna värden är true och false (standard). | Nej |
| partitionOptions | Anger de datapartitioneringsalternativ som används för att läsa in data från Oracle. Tillåtna värden är: Ingen (standard), PhysicalPartitionsOfTable och DynamicRange. När ett partitionsalternativ är aktiverat (dvs. inte None) styrs graden av parallellitet för samtidig inläsning av data från en Oracle-databas av parallelCopies inställningen för kopieringsaktiviteten. |
Nej |
| partitionSettings | Ange gruppen med inställningarna för datapartitionering. Använd när partitionsalternativet inte Noneär . |
Nej |
| partitionNames | Listan över fysiska partitioner som måste kopieras. Använd när partitionsalternativet är PhysicalPartitionsOfTable. Om du använder en fråga för att hämta källdata kopplar ?AdfTabularPartitionName du in WHERE-satsen. Ett exempel finns i avsnittet Parallell kopia från Oracle . |
Nej |
| partitionColumnName | Ange namnet på källkolumnen i heltalstyp som ska användas av intervallpartitionering för parallell kopiering. Om den inte anges identifieras den primära nyckeln i tabellen automatiskt och används som partitionskolumn. Använd när partitionsalternativet är DynamicRange. Om du använder en fråga för att hämta källdata kopplar ?AdfRangePartitionColumnName du in WHERE-satsen. Ett exempel finns i avsnittet Parallell kopia från Oracle . |
Nej |
| partitionUpperBound | Det maximala värdet för partitionskolumnen för att kopiera ut data. Använd när partitionsalternativet är DynamicRange. Om du använder en fråga för att hämta källdata kopplar ?AdfRangePartitionUpbound du in WHERE-satsen. Ett exempel finns i avsnittet Parallell kopia från Oracle . |
Nej |
| partitionLowerBound | Det minsta värdet för partitionskolumnen för att kopiera ut data. Använd när partitionsalternativet är DynamicRange. Om du använder en fråga för att hämta källdata kopplar ?AdfRangePartitionLowbound du in WHERE-satsen. Ett exempel finns i avsnittet Parallell kopia från Oracle . |
Nej |
Exempel: kopiera data med hjälp av en grundläggande fråga utan partition
"activities":[
{
"name": "CopyFromOracle",
"type": "Copy",
"inputs": [
{
"referenceName": "<Oracle input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "OracleSource",
"convertDecimalToInteger": false,
"oracleReaderQuery": "SELECT * FROM MyTable"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Oracle som mottagare
Om du vill kopiera data till Oracle anger du mottagartypen i kopieringsaktiviteten till OracleSink. Följande egenskaper stöds i avsnittet kopieringsaktivitetsmottagare.
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| type | Typegenskapen för kopieringsaktivitetsmottagaren måste vara inställd på OracleSink. |
Ja |
| writeBatchSize | Infogar data i SQL-tabellen när buffertstorleken når writeBatchSize.Tillåtna värden är Heltal (antal rader). |
Nej (standardvärdet är 10 000) |
| writeBatchTimeout | Väntetiden för att batchinfogningsåtgärden ska slutföras innan tidsgränsen uppnås. Tillåtna värden är Tidsintervall. Ett exempel är 00:30:00 (30 minuter). |
Nej |
| preCopyScript | Ange en SQL-fråga för kopieringsaktiviteten som ska köras innan du skriver data till Oracle i varje körning. Du kan använda den här egenskapen för att rensa inlästa data. | Nej |
| maxConcurrentConnections | Den övre gränsen för samtidiga anslutningar som upprättats till datalagret under aktivitetskörningen. Ange endast ett värde när du vill begränsa samtidiga anslutningar. | Nej |
Exempel:
"activities":[
{
"name": "CopyToOracle",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Oracle output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "OracleSink"
}
}
}
]
Parallell kopia från Oracle
Oracle-anslutningsappen tillhandahåller inbyggd datapartitionering för att kopiera data från Oracle parallellt. Du hittar alternativ för datapartitionering på fliken Källa i kopieringsaktiviteten.

När du aktiverar partitionerad kopiering kör tjänsten parallella frågor mot Oracle-källan för att läsa in data efter partitioner. Den parallella graden styrs av parallelCopies inställningen för kopieringsaktiviteten. Om du till exempel anger parallelCopies till fyra genererar och kör tjänsten samtidigt fyra frågor baserat på ditt angivna partitionsalternativ och inställningar, och varje fråga hämtar en del data från Oracle-databasen.
Du rekommenderas att aktivera parallell kopiering med datapartitionering, särskilt när du läser in stora mängder data från Oracle-databasen. Följande är föreslagna konfigurationer för olika scenarier. När du kopierar data till filbaserat datalager är det dags att skriva till en mapp som flera filer (ange endast mappnamn), i vilket fall prestandan är bättre än att skriva till en enda fil.
| Scenario | Föreslagna inställningar |
|---|---|
| Full belastning från en stor tabell med fysiska partitioner. | Partitionsalternativ: Fysiska partitioner i tabellen. Under körningen identifierar tjänsten automatiskt de fysiska partitionerna och kopierar data efter partitioner. |
| Full belastning från stor tabell, utan fysiska partitioner, medan med en heltalskolumn för datapartitionering. | Partitionsalternativ: Partition med dynamiskt intervall. Partitionskolumn: Ange den kolumn som används för att partitionera data. Om den inte anges används primärnyckelkolumnen. |
| Läs in en stor mängd data med hjälp av en anpassad fråga med fysiska partitioner. | Partitionsalternativ: Fysiska partitioner i tabellen. Fråga: SELECT * FROM <TABLENAME> PARTITION("?AdfTabularPartitionName") WHERE <your_additional_where_clause>.Partitionsnamn: Ange partitionsnamnen som du vill kopiera data från. Om det inte anges identifierar tjänsten automatiskt de fysiska partitionerna i tabellen som du angav i Oracle-datauppsättningen. Under körningen ersätter tjänsten med det faktiska partitionsnamnet ?AdfTabularPartitionName och skickar till Oracle. |
| Läs in en stor mängd data med hjälp av en anpassad fråga, utan fysiska partitioner, medan du har en heltalskolumn för datapartitionering. | Partitionsalternativ: Partition med dynamiskt intervall. Fråga: SELECT * FROM <TABLENAME> WHERE ?AdfRangePartitionColumnName <= ?AdfRangePartitionUpbound AND ?AdfRangePartitionColumnName >= ?AdfRangePartitionLowbound AND <your_additional_where_clause>.Partitionskolumn: Ange den kolumn som används för att partitionera data. Du kan partitionera mot kolumnen med heltalsdatatypen. Partitionens övre gräns och partitionens nedre gräns: Ange om du vill filtrera mot partitionskolumnen för att hämta data endast mellan det nedre och det övre intervallet. Under körningen ersätter ?AdfRangePartitionColumnNametjänsten , ?AdfRangePartitionUpboundoch ?AdfRangePartitionLowbound med det faktiska kolumnnamnet och värdeintervallen för varje partition och skickar till Oracle. Om till exempel partitionskolumnen "ID" har angetts med den nedre gränsen som 1 och den övre gränsen som 80, med parallell kopiering inställd som 4, hämtar tjänsten data med 4 partitioner. Deras ID:n är mellan [1,20], [21, 40], [41, 60] respektive [61, 80]. |
Dricks
När du kopierar data från en icke-partitionerad tabell kan du använda partitionsalternativet "Dynamiskt intervall" för att partitionera mot en heltalskolumn. Om dina källdata inte har en sådan typ av kolumn kan du använda ORA_HASH funktion i källfrågan för att generera en kolumn och använda den som partitionskolumn.
Exempel: fråga med fysisk partition
"source": {
"type": "OracleSource",
"query": "SELECT * FROM <TABLENAME> PARTITION(\"?AdfTabularPartitionName\") WHERE <your_additional_where_clause>",
"partitionOption": "PhysicalPartitionsOfTable",
"partitionSettings": {
"partitionNames": [
"<partitionA_name>",
"<partitionB_name>"
]
}
}
Exempel: fråga med partition för dynamiskt intervall
"source": {
"type": "OracleSource",
"query": "SELECT * FROM <TABLENAME> WHERE ?AdfRangePartitionColumnName <= ?AdfRangePartitionUpbound AND ?AdfRangePartitionColumnName >= ?AdfRangePartitionLowbound AND <your_additional_where_clause>",
"partitionOption": "DynamicRange",
"partitionSettings": {
"partitionColumnName": "<partition_column_name>",
"partitionUpperBound": "<upper_value_of_partition_column>",
"partitionLowerBound": "<lower_value_of_partition_column>"
}
}
Datatypsmappning för Oracle
När du kopierar data från och till Oracle används följande interimdatatypmappningar i tjänsten. Information om hur kopieringsaktiviteten mappar källschemat och datatypen till mottagaren finns i Mappningar av schema- och datatyper.
| Oracle-datatyp | Tillfällig datatyp |
|---|---|
| BFILE | Byte[] |
| BLOB | Byte[] (stöds endast på Oracle 10g och senare) |
| CHAR | String |
| CLOB | String |
| DATUM | Datum/tid |
| FLYTA | Decimal, Sträng (om precision > 28) |
| INTEGER | Decimal, Sträng (om precision > 28) |
| LÅNG | String |
| LÅNG RÅ | Byte[] |
| NCHAR | String |
| NCLOB | String |
| NUMBER (p,s) | Decimal, Sträng (om p > 28) |
| NUMBER utan precision och skalning | Dubbel |
| NVARCHAR2 | String |
| RÅ | Byte[] |
| ROWID | String |
| TIMESTAMP | Datum/tid |
| TIDSSTÄMPEL MED LOKAL TIDSZON | String |
| TIDSSTÄMPEL MED TIDSZON | String |
| OSIGNERAT HELTAL | Antal |
| VARCHAR2 | String |
| XML | String |
Kommentar
Datatyperna INTERVALL ÅR TILL MÅNAD och INTERVALL DAG TILL SEKUND stöds inte.
Egenskaper för uppslagsaktivitet
Mer information om egenskaperna finns i Sökningsaktivitet.
Relaterat innehåll
En lista över datalager som stöds som källor och mottagare av kopieringsaktiviteten finns i Datalager som stöds.
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för