Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
GÄLLER FÖR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tips
Data Factory i Microsoft Fabric är nästa generations Azure Data Factory, med en enklare arkitektur, inbyggd AI och nya funktioner. Om dataintegrering är nytt för dig börjar du med Fabric Data Factory. Befintliga ADF-arbetsbelastningar kan uppgraderas till Fabric för att få åtkomst till nya funktioner inom datavetenskap, realtidsanalys och rapportering.
Den här artikeln beskriver hur du använder kopieringsaktiviteten i Azure Data Factory- och Synapse Analytics-pipelines för att kopiera data från en Amazon Redshift. Den bygger vidare på översiktsartikeln för kopieringsaktivitet som presenterar en allmän översikt över kopieringsaktiviteten.
Viktigt!
Amazon Redshift-anslutningsappen version 2.0 ger förbättrat inbyggt Amazon Redshift-stöd. Om du använder Amazon Redshift Connector version 1.0 i din lösning uppgraderar du Amazon Redshift-anslutningsappen eftersom version 1.0 är i slutfasen av supporten. Din pipeline kommer att misslyckas efter den 30 april 2026. Mer information om skillnaden mellan version 2.0 och version 1.0 finns i det här avsnittet .
Funktioner som stöds
Den här Amazon Redshift-anslutningsappen stöds för följande funktioner:
| Funktioner som stöds | Infrarött |
|---|---|
| Copy activity (källa/-) | (1) (2) |
| Sökningsaktivitet | (1) (2) |
(1) Azure integration runtime (2) Lokalt installerad integrationskörning
En lista över datalager som stöds som källor eller mottagare av kopieringsaktiviteten finns i tabellen Datalager som stöds.
Tjänsten tillhandahåller en inbyggd drivrutin för att aktivera anslutningen, därför behöver du inte installera någon drivrutin manuellt.
Amazon Redshift-anslutningen stöder hämtning av data från Redshift med hjälp av frågor eller inbyggd UNLOAD-funktion för Redshift.
Anslutningen stöder Windows-versioner i den här artikeln.
Tips
Om du vill uppnå bästa prestanda vid kopiering av stora mängder data från Redshift bör du överväga att använda den inbyggda Redshift UNLOAD via Amazon S3. Mer information finns i Använda UNLOAD för att kopiera data från Amazon Redshift .
Förutsättningar
Om du kopierar data till ett lokalt datalager med hjälp av Self-hosted Integration Runtime beviljar du Integration Runtime (datorns IP-adress) åtkomst till Amazon Redshift-klustret. Anvisningar finns i Auktorisera åtkomst till klustret . För version 2.0 bör din lokalt installerade integrationskörningsversion vara 5.61 eller senare.
Om du kopierar data till ett Azure datalager kan du läsa Azure Data Center IP-intervall för beräknings-IP-adressen och SQL-intervallen som används av Azure datacenter.
Om ditt datalager är en hanterad molndatatjänst kan du använda Azure Integration Runtime. Om åtkomsten är begränsad till IP-adresser som är godkända i brandväggsreglerna kan du lägga till Azure Integration Runtime IP-adresser i listan över tillåtna.
Du kan också använda funktionen hanterad virtuell nätverksintegrering i Azure Data Factory för att få åtkomst till det lokala nätverket utan att installera och konfigurera en integrationskörning med egen värd.
Komma igång
Om du vill utföra kopieringsaktiviteten med en pipeline kan du använda något av följande verktyg eller SDK:er:
- Kopiera data-verktyget
- Azure Portal
- .NET SDK
- Python SDK
- Azure PowerShell
- REST-API
- mall för Azure Resource Manager
Skapa en länkad tjänst till Amazon Redshift med hjälp av användargränssnittet
Använd följande steg för att skapa en länkad tjänst till Amazon Redshift i användargränssnittet för Azure-portalen.
Bläddra till fliken Hantera på din Azure Data Factory- eller Synapse-arbetsyta och välj Länkade tjänster och klicka sedan på Nytt:
Sök efter Amazon och välj Amazon Redshift-anslutningsappen.
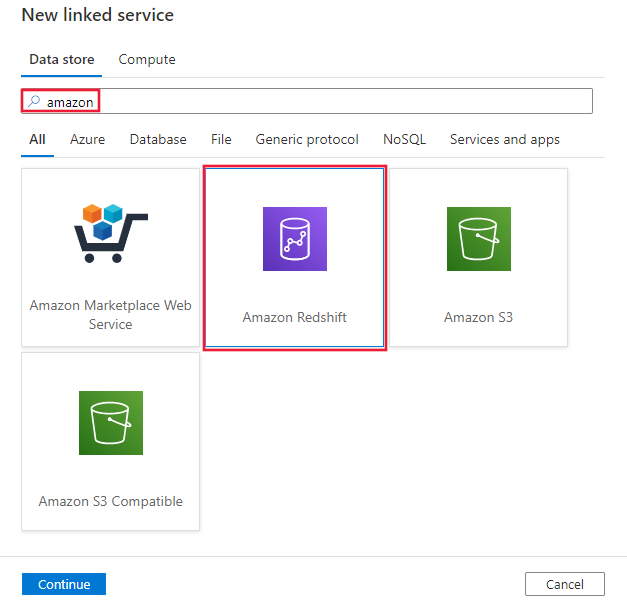
Konfigurera tjänstinformationen, testa anslutningen och skapa den nya länkade tjänsten.
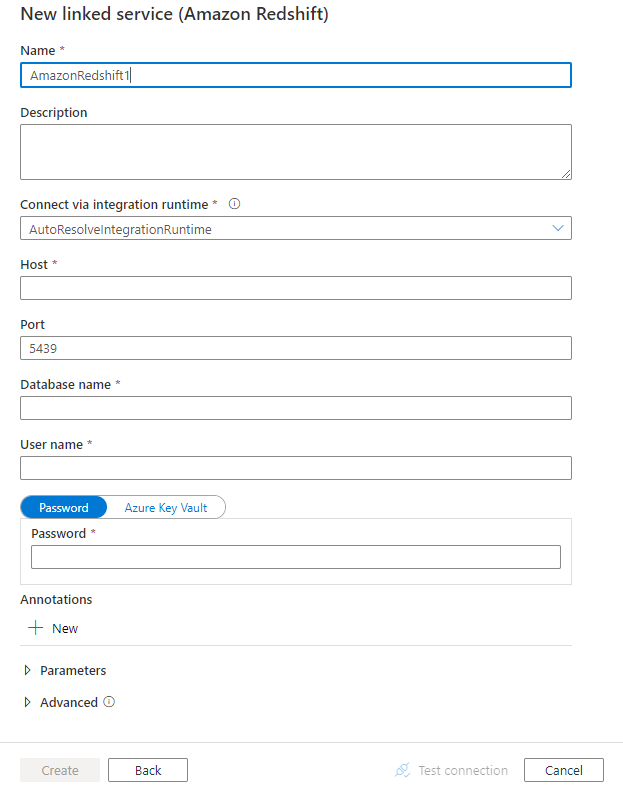
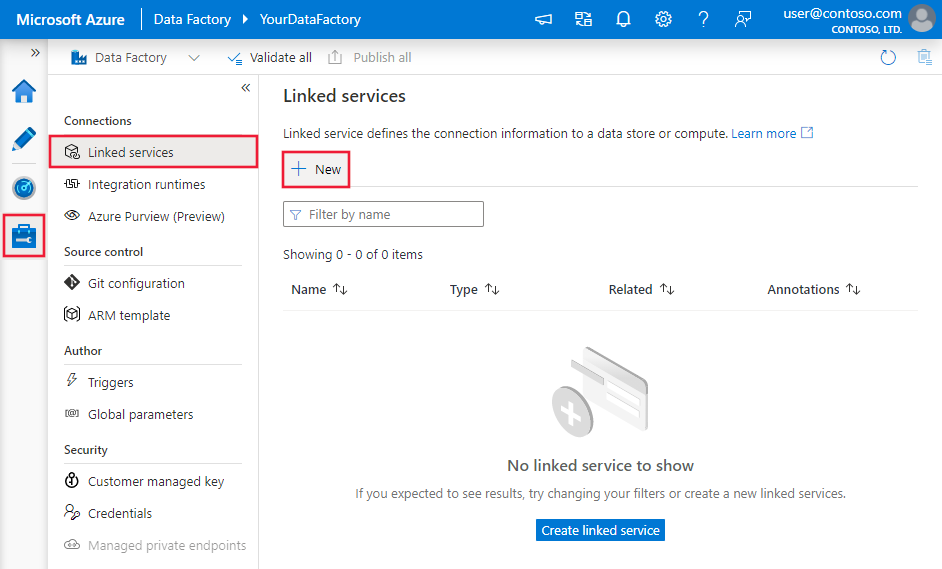
Konfigurationsdetaljer för anslutning
Följande avsnitt innehåller information om egenskaper som används för att definiera Data Factory-entiteter som är specifika för Amazon Redshift-anslutningsappen.
Länkade tjänstegenskaper
Följande egenskaper stöds för amazon redshift-länkad tjänst:
| Fastighet | Beskrivning | Obligatoriskt |
|---|---|---|
| typ | Typegenskapen måste anges till: AmazonRedshift | Ja |
| version | Den version som du anger. | Ja för version 2.0. |
| server | IP-adress eller värdnamn för Amazon Redshift-servern. | Ja |
| port/hamn | Antalet TCP-portar som Amazon Redshift-servern använder för att lyssna efter klientanslutningar. | Nej, standardvärdet är 5439 |
| databas | Namnet på Amazon Redshift-databasen. | Ja |
| användarnamn | Namn på användare som har åtkomst till databasen. | Ja |
| lösenord | Lösenord för användarkontot. Markera det här fältet som en SecureString för att lagra det på ett säkert sätt, eller referera en hemlighet som lagras i Azure Key Vault. | Ja |
| sslmode | Det SSL-certifikatverifieringsläge som ska användas vid anslutning till Amazon Redshift. Den här egenskapen stöds endast i version 2.0. - Verify_full: Anslut endast med SSL, en betrodd certifikatutfärdare och ett servernamn som matchar certifikatet. - Verify_ca: Anslut endast med SSL och en betrodd certifikatutfärdare. - Krävs: Anslut endast med SSL. - Prioriterat: Anslut med SSL om det är tillgängligt. Annars ansluter du utan att använda SSL. - Tillåten: Anslut som standard utan att använda SSL. Om servern kräver SSL-anslutningar använder du SSL. - Inaktiverad: Anslut utan att använda SSL. Alternativ: verify-full (standard) / verify-ca / require / prefer / allow / disable |
Nej, standardvärdet är verify-full |
| connectVia | Den Integration Runtime som ska användas för att ansluta till datalagret. Du kan använda Azure Integration Runtime eller lokalt installerad Integration Runtime (om ditt datalager finns i ett privat nätverk). Om det inte anges används standard Azure Integration Runtime. | Nej |
Anmärkning
Version 2.0 stöder Azure Integration Runtime och lokalt installerad Integration Runtime version 5.61 eller senare. Drivrutinsinstallation behövs inte längre med lokalt installerad Integration Runtime version 5.61 eller senare.
Exempel: version 2.0
{
"name": "AmazonRedshiftLinkedService",
"properties":
{
"type": "AmazonRedshift",
"version": "2.0",
"typeProperties":
{
"server": "<server name>",
"database": "<database name>",
"username": "<username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Exempel: version 1.0
{
"name": "AmazonRedshiftLinkedService",
"properties":
{
"type": "AmazonRedshift",
"typeProperties":
{
"server": "<server name>",
"database": "<database name>",
"username": "<username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Egenskaper för dataset
En fullständig lista över avsnitt och egenskaper som är tillgängliga för att definiera datauppsättningar finns i artikeln datauppsättningar . Det här avsnittet innehåller en lista över egenskaper som stöds av Amazon Redshift-datauppsättningen.
Följande egenskaper stöds för att kopiera data från Amazon Redshift:
| Fastighet | Beskrivning | Obligatoriskt |
|---|---|---|
| typ | Typegenskapen för datauppsättningen måste anges till: AmazonRedshiftTable | Ja |
| Schemat | Namnet på schemat. | Nej (om "fråga" i aktivitetskällan har angetts) |
| bord/tabell | Tabellens namn. | Nej (om "fråga" i aktivitetskällan har angetts) |
| tabellnamn | Namnet på tabellen med schemat. Den här egenskapen stöds för bakåtkompatibilitet. Använd schema och table för ny arbetsbelastning. |
Nej (om "fråga" i aktivitetskällan har angetts) |
Exempel
{
"name": "AmazonRedshiftDataset",
"properties":
{
"type": "AmazonRedshiftTable",
"typeProperties": {},
"schema": [],
"linkedServiceName": {
"referenceName": "<Amazon Redshift linked service name>",
"type": "LinkedServiceReference"
}
}
}
Om du använder RelationalTable en typ av datauppsättning stöds den fortfarande i sin form, medan du rekommenderas att använda den nya framöver.
Egenskaper av kopieringsaktivitet
En fullständig lista över avsnitt och egenskaper som är tillgängliga för att definiera aktiviteter finns i artikeln Pipelines . Det här avsnittet innehåller en lista över egenskaper som stöds av Amazon Redshift-källan.
Amazon Redshift som källa
Om du vill kopiera data från Amazon Redshift anger du källtypen i kopieringsaktiviteten till AmazonRedshiftSource. Följande egenskaper stöds i avsnittet kopieringsaktivitetens källa :
| Fastighet | Beskrivning | Obligatoriskt |
|---|---|---|
| typ | Typegenskapen för kopieringsaktivitetskällan måste anges till: AmazonRedshiftSource | Ja |
| förfrågan | Använd den anpassade frågan för att läsa data. Till exempel: välj * från MyTable. | Nej (när "tableName" i datauppsättningen har specificerats) |
| redshiftUnloadInställningar | Egenskapsgrupp när du använder Amazon Redshift UNLOAD. | Nej |
| s3LinkedServiceName | Refererar till en Amazon S3 som ska användas som interimslager genom att ange ett länkat tjänstnamn av typen "AmazonS3". | Ja om du använder AVLASTA |
| bucket-namn | Ange S3-bucketen för att lagra interimsdata. Om den inte tillhandahålls genererar tjänsten den automatiskt. | Ja om du använder AVLASTA |
Exempel: Amazon Redshift-källa i kopieringsaktivitet med HJÄLP av UNLOAD
"source": {
"type": "AmazonRedshiftSource",
"query": "<SQL query>",
"redshiftUnloadSettings": {
"s3LinkedServiceName": {
"referenceName": "<Amazon S3 linked service>",
"type": "LinkedServiceReference"
},
"bucketName": "bucketForUnload"
}
}
Lär dig mer om hur du använder UNLOAD för att kopiera data från Amazon Redshift effektivt från nästa avsnitt.
Använda UNLOAD för att kopiera data från Amazon Redshift
UNLOAD är en mekanism som tillhandahålls av Amazon Redshift, som kan avlasta resultaten från en fråga till en eller flera filer på Amazon Simple Storage Service (Amazon S3). Det är det sätt som rekommenderas av Amazon för att kopiera stora datamängder från Redshift.
Example: kopiera data från Amazon Redshift till Azure Synapse Analytics med hjälp av UNLOAD, mellanlagrad kopia och PolyBase
I det här exempelanvändningsfallet tar kopieringsaktiviteten bort data från Amazon Redshift till Amazon S3 enligt konfigurationen i "redshiftUnloadSettings" och kopierar sedan data från Amazon S3 till Azure Blob enligt vad som anges i "stagingSettings", och använder slutligen PolyBase för att läsa in data i Azure Synapse Analytics. Allt mellanliggande format hanteras korrekt av kopieringsaktiviteten.

"activities":[
{
"name": "CopyFromAmazonRedshiftToSQLDW",
"type": "Copy",
"inputs": [
{
"referenceName": "AmazonRedshiftDataset",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "AzureSQLDWDataset",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AmazonRedshiftSource",
"query": "select * from MyTable",
"redshiftUnloadSettings": {
"s3LinkedServiceName": {
"referenceName": "AmazonS3LinkedService",
"type": "LinkedServiceReference"
},
"bucketName": "bucketForUnload"
}
},
"sink": {
"type": "SqlDWSink",
"allowPolyBase": true
},
"enableStaging": true,
"stagingSettings": {
"linkedServiceName": "AzureStorageLinkedService",
"path": "adfstagingcopydata"
},
"dataIntegrationUnits": 32
}
}
]
Datatypsmappning för Amazon Redshift
När du kopierar data från Amazon Redshift gäller följande mappningar från Amazon Redshifts datatyper för de interna datatyper som används av tjänsten. Information om hur kopieringsoperationen mappar datatyper och källschema till målet finns i Mappningar av schema och datatyper.
| Amazon Redshift-datatyp | Tillfällig tjänstdatatyp (för version 2.0) | Tillfällig tjänstdatatyp (för version 1.0) |
|---|---|---|
| BIGINT | Int64 | Int64 |
| BOOLESK | Boolesk | Sträng |
| RÖDING | Sträng | Sträng |
| DATUM | Datum/tid | Datum/tid |
| DECIMAL (Noggrannhet <= 28) | Decimal | Decimal |
| DECIMAL (precision > 28) | Sträng | Sträng |
| Dubbel precision | Dubbel | Dubbel |
| heltal | Int32 | Int32 |
| verklig | Enkel | Enkel |
| SMALLINT | Int16 | Int16 |
| TEXT | Sträng | Sträng |
| TIDSSTÄMPEL | Datum/tid | Datum/tid |
| VARCHAR | Sträng | Sträng |
Egenskaper för uppslagsaktivitet
Mer information om egenskaperna finns i Sökningsaktivitet.
Amazon Redshift-anslutningslivscykel och uppgradering
I följande tabell visas versionssteget och ändringsloggarna för olika versioner av Amazon Redshift-anslutningsappen:
| Utgåva | Utgivningsfas | Ändringslogg |
|---|---|---|
| Version 1.0 | Slutet på support har meddelats | / |
| Version 2.0 | GA-version tillgänglig | • Stöder Azure Integration Runtime och lokalt installerad Integration Runtime version 5.61 eller senare. Drivrutinsinstallation behövs inte längre med lokalt installerad Integration Runtime version 5.61 eller senare. • BOOLEAN läses som Boolesk datatyp. • Support sslmode i den länkade tjänsten. |
Uppgradera Amazon Redshift-anslutningsappen från version 1.0 till version 2.0
På sidan Redigera länkad tjänst väljer du version 2.0 och konfigurerar den länkade tjänsten genom att referera till länkade tjänstegenskaper.
Datatypsmappningen för den länkade Amazon Redshift-tjänsten version 2.0 skiljer sig från den för version 1.0. Information om den senaste datatypsmappningen finns i Datatypsmappning för Amazon Redshift.
Använd en lokalt installerad integrationskörning med version 5.61 eller senare. Drivrutinsinstallation behövs inte längre med lokalt installerad Integration Runtime version 5.61 eller senare.
Relaterat innehåll
För en lista över datalager som stöds som käll- och mottagaralternativ av kopieringsaktiviteten, se stödda datalager.