Anteckning
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
GÄLLER FÖR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dricks
Prova Data Factory i Microsoft Fabric, en allt-i-ett-analyslösning för företag. Microsoft Fabric omfattar allt från dataflytt till datavetenskap, realtidsanalys, business intelligence och rapportering. Lär dig hur du startar en ny utvärderingsversion kostnadsfritt!
Den här artikeln beskriver hur du använder kopieringsaktivitet i Azure Data Factory- eller Synapse Analytics-pipelines för att kopiera data från Netezza. Artikeln bygger på kopieringsaktivitet, som visar en allmän översikt över kopieringsaktivitet.
Dricks
För datamigreringsscenario från Netezza till Azure kan du läsa mer från Migrera data från en lokal Netezza-server till Azure.
Funktioner som stöds
Den här Netezza-anslutningsappen stöds för följande funktioner:
| Funktioner som stöds | IR |
|---|---|
| aktiviteten Kopiera (källa/-) | (1) (2) |
| Sökningsaktivitet | (1) (2) |
(1) Azure Integration Runtime (2) Lokalt installerad integrationskörning
En lista över datalager som kopieringsaktivitet stöder som källor och mottagare finns i Datalager och format som stöds.
Den här Netezza-anslutningsappen stöder:
- Parallell kopiering från källan. Mer information finns i avsnittet Parallell kopia från Netezza .
- Netezza Performance Server version 11.
- Windows-versioner i den här artikeln.
Tjänsten tillhandahåller en inbyggd drivrutin för att aktivera anslutning. Du behöver inte installera någon drivrutin manuellt för att använda den här anslutningsappen.
Förutsättningar
Om ditt datalager finns i ett lokalt nätverk, ett virtuellt Azure-nätverk eller Amazon Virtual Private Cloud måste du konfigurera en lokalt installerad integrationskörning för att ansluta till det.
Om ditt datalager är en hanterad molndatatjänst kan du använda Azure Integration Runtime. Om åtkomsten är begränsad till IP-adresser som är godkända i brandväggsreglerna kan du lägga till Azure Integration Runtime-IP-adresser i listan över tillåtna.
Du kan också använda funktionen för integrering av hanterade virtuella nätverk i Azure Data Factory för att få åtkomst till det lokala nätverket utan att installera och konfigurera en lokalt installerad integrationskörning.
Mer information om de nätverkssäkerhetsmekanismer och alternativ som stöds av Data Factory finns i Strategier för dataåtkomst.
Kom igång
Du kan skapa en pipeline som använder en kopieringsaktivitet med hjälp av .NET SDK, Python SDK, Azure PowerShell, REST API eller en Azure Resource Manager-mall. I självstudien Kopiera aktivitet finns stegvisa instruktioner för att skapa en pipeline med en kopieringsaktivitet.
Skapa en länkad tjänst till Netezza med hjälp av användargränssnittet
Använd följande steg för att skapa en länkad tjänst till Netezza i Azure Portal användargränssnittet.
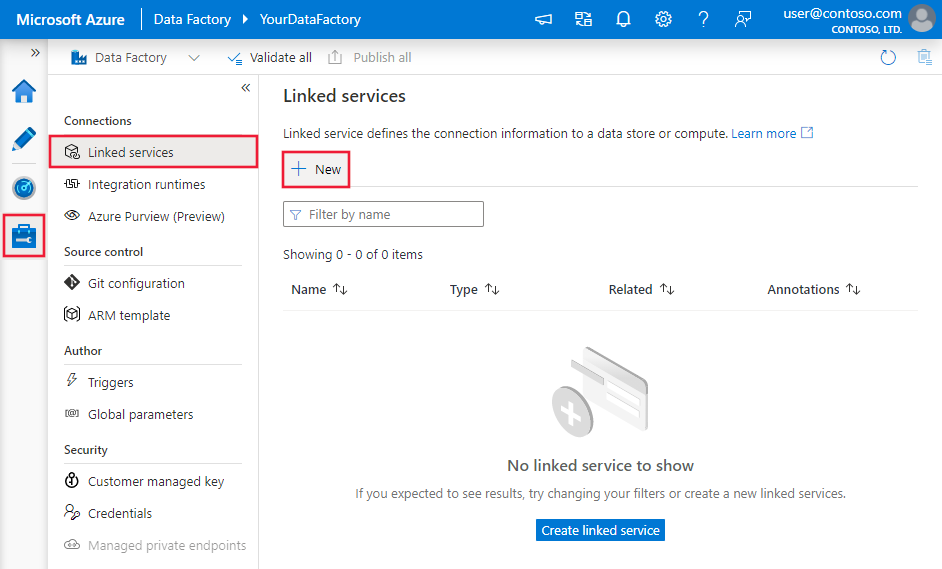
Bläddra till fliken Hantera i Din Azure Data Factory- eller Synapse-arbetsyta och välj Länkade tjänster och klicka sedan på Ny:
Sök efter Netezza och välj Netezza-anslutningsappen.

Konfigurera tjänstinformationen, testa anslutningen och skapa den nya länkade tjänsten.
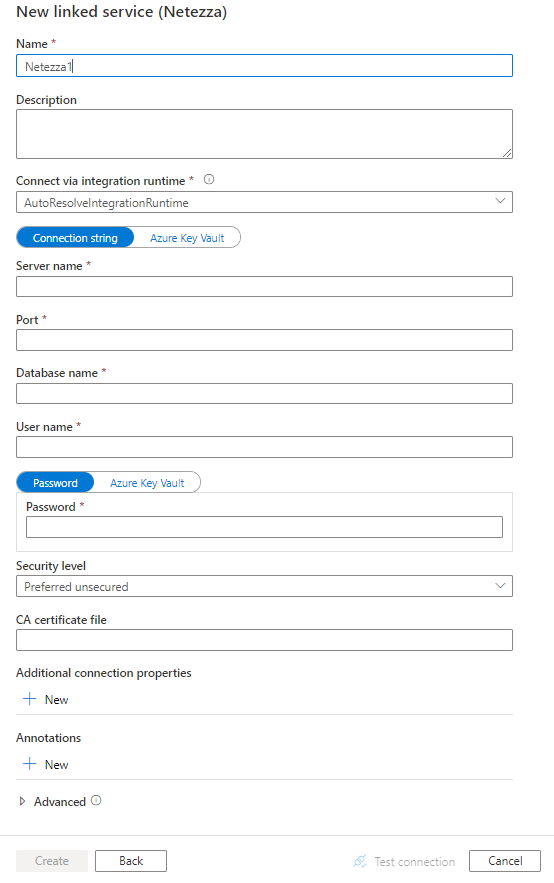
Konfigurationsinformation för anslutningsprogram
Följande avsnitt innehåller information om egenskaper som du kan använda för att definiera entiteter som är specifika för Netezza-anslutningsappen.
Länkade tjänstegenskaper
Följande egenskaper stöds för den länkade Netezza-tjänsten:
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| type | Typegenskapen måste vara inställd på Netezza. | Ja |
| connectionString | En ODBC-anslutningssträng för att ansluta till Netezza. Du kan också lägga till lösenord i Azure Key Vault och hämta konfigurationen pwd från anslutningssträng. Mer information finns i följande exempel och artikeln Lagra autentiseringsuppgifter i Azure Key Vault . |
Ja |
| connectVia | Integration Runtime som ska användas för att ansluta till datalagret. Läs mer i avsnittet Förutsättningar . Om det inte anges används standardkörningen för Azure Integration Runtime. | Nej |
En typisk anslutningssträng är Server=<server>;Port=<port>;Database=<database>;UID=<user name>;PWD=<password>. I följande tabell beskrivs fler egenskaper som du kan ange:
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| SecurityLevel | Säkerhetsnivån som drivrutinen använder för anslutningen till datalagret. Exempel: SecurityLevel=preferredUnSecured. Värden som stöds är:- Endast oskyddad (endastUnSecured): Drivrutinen använder inte SSL. - Prioriterad oskyddad (preferredUnSecured) (standard): Om servern ger ett val använder drivrutinen inte SSL. |
Nej |
Kommentar
Anslutningsappen stöder inte SSLv3 eftersom den officiellt är inaktuell av Netezza.
Exempel
{
"name": "NetezzaLinkedService",
"properties": {
"type": "Netezza",
"typeProperties": {
"connectionString": "Server=<server>;Port=<port>;Database=<database>;UID=<user name>;PWD=<password>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Exempel: Lagra lösenord i Azure Key Vault
{
"name": "NetezzaLinkedService",
"properties": {
"type": "Netezza",
"typeProperties": {
"connectionString": "Server=<server>;Port=<port>;Database=<database>;UID=<user name>;",
"pwd": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Egenskaper för datauppsättning
Det här avsnittet innehåller en lista över egenskaper som Netezza-datauppsättningen stöder.
En fullständig lista över avsnitt och egenskaper som är tillgängliga för att definiera datauppsättningar finns i Datauppsättningar.
Om du vill kopiera data från Netezza anger du datamängdens typegenskap till NetezzaTable. Följande egenskaper stöds:
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| type | Typegenskapen för datamängden måste anges till: NetezzaTable | Ja |
| schema | Namnet på schemat. | Nej (om "fråga" i aktivitetskällan har angetts) |
| table | Tabellens namn. | Nej (om "fråga" i aktivitetskällan har angetts) |
| tableName | Namnet på tabellen med schemat. Den här egenskapen stöds för bakåtkompatibilitet. Använd schema och table för ny arbetsbelastning. |
Nej (om "fråga" i aktivitetskällan har angetts) |
Exempel
{
"name": "NetezzaDataset",
"properties": {
"type": "NetezzaTable",
"linkedServiceName": {
"referenceName": "<Netezza linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {}
}
}
Egenskaper för kopieringsaktivitet
Det här avsnittet innehåller en lista över egenskaper som Netezza-källan stöder.
En fullständig lista över avsnitt och egenskaper som är tillgängliga för att definiera aktiviteter finns i Pipelines.
Netezza som källa
Dricks
Om du vill läsa in data från Netezza effektivt med hjälp av datapartitionering kan du läsa mer från avsnittet Parallellkopia från Netezza .
Om du vill kopiera data från Netezza anger du källtypen i Kopiera aktivitet till NetezzaSource. Följande egenskaper stöds i avsnittet Kopieringsaktivitetskälla:
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| type | Typegenskapen för kopieringsaktivitetskällan måste anges till NetezzaSource. | Ja |
| query | Använd den anpassade SQL-frågan för att läsa data. Exempel: "SELECT * FROM MyTable" |
Nej (om "tableName" i datauppsättningen har angetts) |
| partitionOptions | Anger de datapartitioneringsalternativ som används för att läsa in data från Netezza. Tillåtna värden är: Ingen (standard), DataSlice och DynamicRange. När ett partitionsalternativ är aktiverat (dvs. inte None) styrs graden av parallellitet för att samtidigt läsa in data från en Netezza-databas genom parallelCopies att ange kopieringsaktiviteten. |
Nej |
| partitionSettings | Ange gruppen med inställningarna för datapartitionering. Använd när partitionsalternativet inte Noneär . |
Nej |
| partitionColumnName | Ange namnet på källkolumnen i heltalstyp som ska användas av intervallpartitionering för parallell kopiering. Om den inte anges identifieras den primära nyckeln i tabellen automatiskt och används som partitionskolumn. Använd när partitionsalternativet är DynamicRange. Om du använder en fråga för att hämta källdata ansluter du ?AdfRangePartitionColumnName i WHERE-satsen. Se exempel i avsnittet Parallell kopia från Netezza . |
Nej |
| partitionUpperBound | Det maximala värdet för partitionskolumnen för att kopiera ut data. Använd när partitionsalternativet är DynamicRange. Om du använder frågan för att hämta källdata kopplar du ?AdfRangePartitionUpbound in WHERE-satsen. Ett exempel finns i avsnittet Parallell kopia från Netezza . |
Nej |
| partitionLowerBound | Det minsta värdet för partitionskolumnen för att kopiera ut data. Använd när partitionsalternativet är DynamicRange. Om du använder en fråga för att hämta källdata kopplar ?AdfRangePartitionLowbound du in WHERE-satsen. Ett exempel finns i avsnittet Parallell kopia från Netezza . |
Nej |
Exempel:
"activities":[
{
"name": "CopyFromNetezza",
"type": "Copy",
"inputs": [
{
"referenceName": "<Netezza input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "NetezzaSource",
"query": "SELECT * FROM MyTable"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Parallell kopia från Netezza
Data Factory Netezza-anslutningsappen tillhandahåller inbyggd datapartitionering för att kopiera data från Netezza parallellt. Du hittar alternativ för datapartitionering i källtabellen för kopieringsaktiviteten.

När du aktiverar partitionerad kopiering kör tjänsten parallella frågor mot Netezza-källan för att läsa in data efter partitioner. Den parallella graden styrs av parallelCopies inställningen för kopieringsaktiviteten. Om du till exempel anger parallelCopies till fyra genererar och kör tjänsten samtidigt fyra frågor baserat på det angivna partitionsalternativet och inställningarna, och varje fråga hämtar en del data från Netezza-databasen.
Du rekommenderas att aktivera parallell kopiering med datapartitionering, särskilt när du läser in stora mängder data från din Netezza-databas. Följande är föreslagna konfigurationer för olika scenarier. När du kopierar data till filbaserat datalager rekommenderar vi att du skriver till en mapp som flera filer (anger endast mappnamn), i vilket fall prestandan är bättre än att skriva till en enda fil.
| Scenario | Föreslagna inställningar |
|---|---|
| Full belastning från en stor tabell. |
Partitionsalternativ: Datasektor. Under körningen partitionerar tjänsten automatiskt data baserat på Netezzas inbyggda datasektorer och kopierar data efter partitioner. |
| Läs in stora mängder data med hjälp av en anpassad fråga. |
Partitionsalternativ: Datasektor. Fråga: SELECT * FROM <TABLENAME> WHERE mod(datasliceid, ?AdfPartitionCount) = ?AdfDataSliceCondition AND <your_additional_where_clause>.Under körningen ersätter tjänsten (med parallellt kopieringsnummer ?AdfPartitionCount inställt på kopieringsaktivitet) och ?AdfDataSliceCondition med datasektorpartitionslogik och skickar till Netezza. |
| Läs in stora mängder data med hjälp av en anpassad fråga med en heltalskolumn med jämnt distribuerat värde för intervallpartitionering. |
Partitionsalternativ: Partition med dynamiskt intervall. Fråga: SELECT * FROM <TABLENAME> WHERE ?AdfRangePartitionColumnName <= ?AdfRangePartitionUpbound AND ?AdfRangePartitionColumnName >= ?AdfRangePartitionLowbound AND <your_additional_where_clause>.Partitionskolumn: Ange den kolumn som används för att partitionera data. Du kan partitionera mot kolumnen med heltalsdatatypen. Partitionens övre gräns och partitionens nedre gräns: Ange om du vill filtrera mot partitionskolumnen för att endast hämta data mellan det nedre och det övre intervallet. Under körningen ersätter ?AdfRangePartitionColumnNametjänsten , ?AdfRangePartitionUpboundoch ?AdfRangePartitionLowbound med det faktiska kolumnnamnet och värdeintervallen för varje partition och skickar till Netezza. Om till exempel partitionskolumnen "ID" har angetts med den nedre gränsen som 1 och den övre gränsen som 80, med parallell kopiering inställd som 4, hämtar tjänsten data med 4 partitioner. Deras ID:n är mellan [1,20], [21, 40], [41, 60] respektive [61, 80]. |
Exempel: fråga med datasektorpartition
"source": {
"type": "NetezzaSource",
"query": "SELECT * FROM <TABLENAME> WHERE mod(datasliceid, ?AdfPartitionCount) = ?AdfDataSliceCondition AND <your_additional_where_clause>",
"partitionOption": "DataSlice"
}
Exempel: fråga med partition för dynamiskt intervall
"source": {
"type": "NetezzaSource",
"query": "SELECT * FROM <TABLENAME> WHERE ?AdfRangePartitionColumnName <= ?AdfRangePartitionUpbound AND ?AdfRangePartitionColumnName >= ?AdfRangePartitionLowbound AND <your_additional_where_clause>",
"partitionOption": "DynamicRange",
"partitionSettings": {
"partitionColumnName": "<dynamic_range_partition_column_name>",
"partitionUpperBound": "<upper_value_of_partition_column>",
"partitionLowerBound": "<lower_value_of_partition_column>"
}
}
Egenskaper för uppslagsaktivitet
Mer information om egenskaperna finns i Sökningsaktivitet.
Relaterat innehåll
En lista över datalager som kopieringsaktivitet stöder som källor och mottagare finns i Datalager och format som stöds.