Ladda ned lakehouse-referensarkitekturer
Den här artikeln beskriver arkitekturvägledning för lakehouse när det gäller datakälla, inmatning, transformering, frågekörning och bearbetning, servering, analys/utdata och lagring.
Varje referensarkitektur har en nedladdningsbar PDF i formatet 11 x 17 (A3).
Allmän referensarkitektur
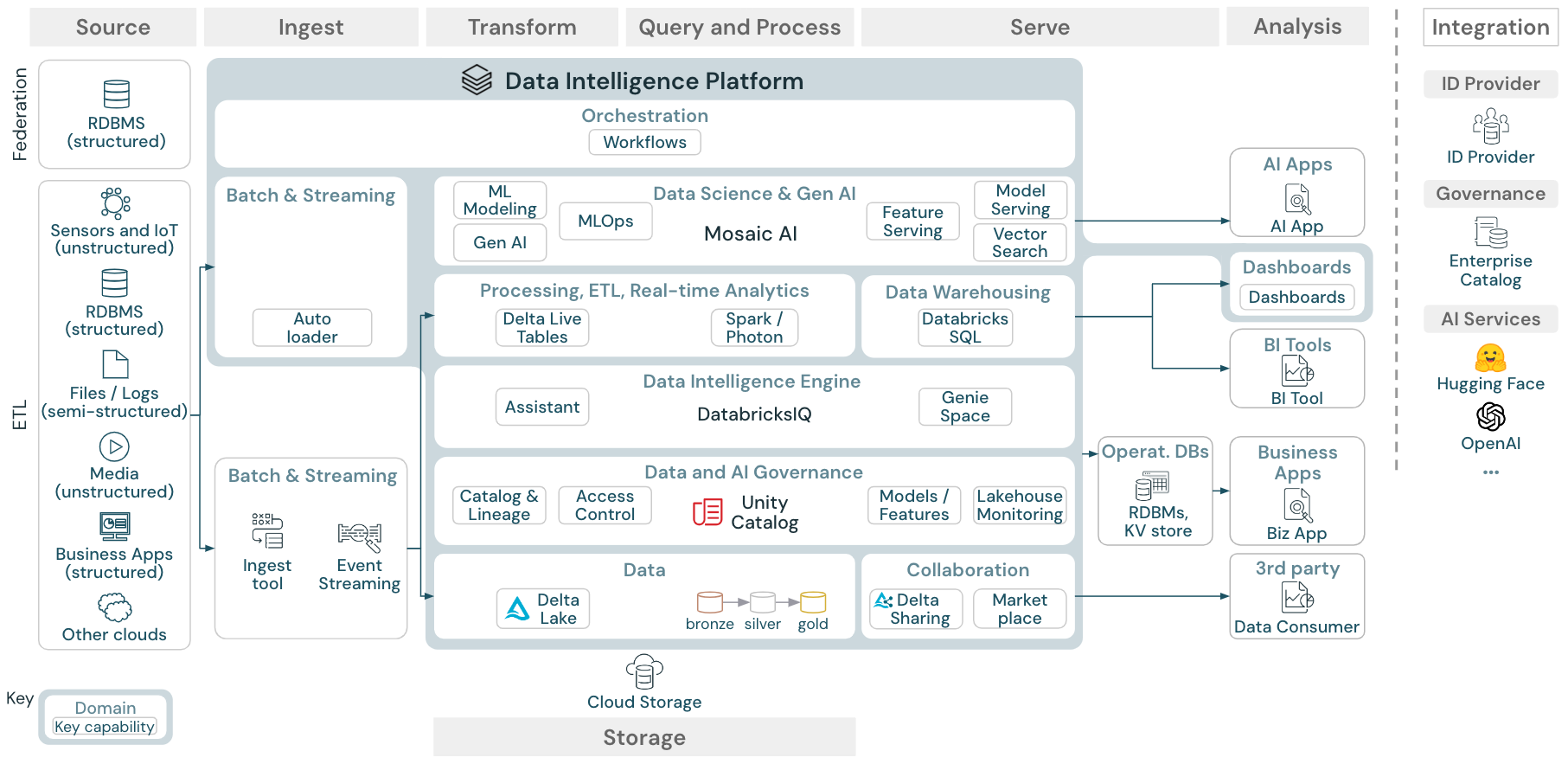
Ladda ned: Allmän lakehouse-referensarkitektur för Databricks (PDF)
Organisation av referensarkitekturerna
Referensarkitekturen är strukturerad längs simbanorna Source, Ingest, Transform, Query and Process, Serve, Analysis och Storage:
Source
Arkitekturen skiljer mellan halvstrukturerade och ostrukturerade data (sensorer och IoT, media, filer/loggar) och strukturerade data (RDBMS, affärsprogram). SQL-källor (RDBMS) kan också integreras i lakehouse och Unity Catalog utan ETL via lakehouse federation. Dessutom kan data läsas in från andra molnleverantörer.
Äter
Data kan matas in i lakehouse via batch eller strömning:
- Filer som levereras till molnlagring kan läsas in direkt med Databricks Auto Loader.
- För batchinmatning av data från företagsprogram till Delta Lake förlitar sig Databricks lakehouse på partnerinmatningsverktyg med specifika kort för dessa postsystem.
- Direktuppspelningshändelser kan matas in direkt från händelseströmningssystem som Kafka med Databricks Structured Streaming. Strömmande källor kan vara sensorer, IoT- eller ändringsprocesser för datainsamling .
Storage
Data lagras vanligtvis i molnlagringssystemet där ETL-pipelines använder medallion-arkitekturen för att lagra data på ett kuraterat sätt som Delta-filer/tabeller.
Transformera och fråga och bearbeta
Databricks lakehouse använder sina motorer Apache Spark och Photon för alla omvandlingar och frågor.
På grund av enkelheten är det deklarativa ramverket DLT (Delta Live Tables) ett bra val för att skapa tillförlitliga, underhållsbara och testbara databearbetningspipelines.
Databricks Data Intelligence Platform drivs av Apache Spark och Photon och stöder båda typerna av arbetsbelastningar: SQL-frågor via SQL-lager och SQL-, Python- och Scala-arbetsbelastningar via arbetsytekluster.
För datavetenskap (ML-modellering och Gen AI) tillhandahåller Databricks AI och Mašinsko učenje-plattformen specialiserade ML-körningar för AutoML och för kodning av ML-jobb. Alla arbetsflöden för datavetenskap och MLOps stöds bäst av MLflow.
Servera
För DWH- och BI-användningsfall tillhandahåller Databricks lakehouse Databricks SQL, informationslagret som drivs av SQL-lager och serverlösa SQL-lager.
För maskininlärning är modellservering en skalbar modell i realtid i företagsklass som betjänar funktioner i Databricks-kontrollplanet.
Driftdatabaser: Externa system, till exempel driftdatabaser, kan användas för att lagra och leverera slutgiltiga dataprodukter till användarprogram.
Samarbete: Affärspartner får säker åtkomst till de data de behöver via DeltaDelning. Databricks Marketplace är baserat på deltadelning och är ett öppet forum för utbyte av dataprodukter.
Analys
De sista affärsprogrammen finns i denna simbana. Exempel är anpassade klienter som AI-program som är anslutna till Mosaic AI Model Serving för slutsatsdragning i realtid eller program som har åtkomst till data som skickas från lakehouse till en driftdatabas.
För BI-användningsfall använder analytiker vanligtvis BI-verktyg för att komma åt informationslagret. SQL-utvecklare kan dessutom använda Databricks SQL-redigeraren (visas inte i diagrammet) för frågor och instrumentpaneler.
Data Intelligence Platform erbjuder även instrumentpaneler för att skapa datavisualiseringar och dela insikter.
Funktioner för dina arbetsbelastningar
Dessutom levereras Databricks lakehouse med hanteringsfunktioner som stöder alla arbetsbelastningar:
Data- och AI-styrning
Det centrala data- och AI-styrningssystemet i Databricks Data Intelligence Platform är Unity Catalog. Unity Catalog tillhandahåller en enda plats för att hantera dataåtkomstprinciper som gäller för alla arbetsytor och stöder alla tillgångar som skapats eller används i lakehouse, till exempel tabeller, volymer, funktioner (funktionslager) och modeller (modellregister). Unity Catalog kan också användas för att samla in körningsdata härstamning mellan frågor som körs på Databricks.
Med Databricks lakehouse-övervakning kan du övervaka datakvaliteten i alla tabeller i ditt konto. Den kan också spåra prestanda för maskininlärningsmodeller och modellbetjäningsslutpunkter.
För observerbarhet är systemtabeller ett Databricks-värdbaserat analyslager för ditt kontos driftdata. Systemtabeller kan användas för historisk observerbarhet i hela ditt konto.
Dataintelligensmotor
Databricks Data Intelligence Platform gör att hela organisationen kan använda data och AI. Den drivs av DatabricksIQ och kombinerar generativ AI med fördelarna med en sammanslagning av ett sjöhus för att förstå de unika semantiken i dina data.
Databricks Assistant finns i Databricks Notebooks, SQL-redigeraren och filredigeraren som en kontextmedveten AI-assistent för utvecklare.
Orkestrering
Databricks-jobb samordnar databearbetning, maskininlärning och analyspipelines på Databricks Data Intelligence Platform. Med Delta Live Tables kan du skapa tillförlitliga och underhållsbara ETL-pipelines med deklarativ syntax.
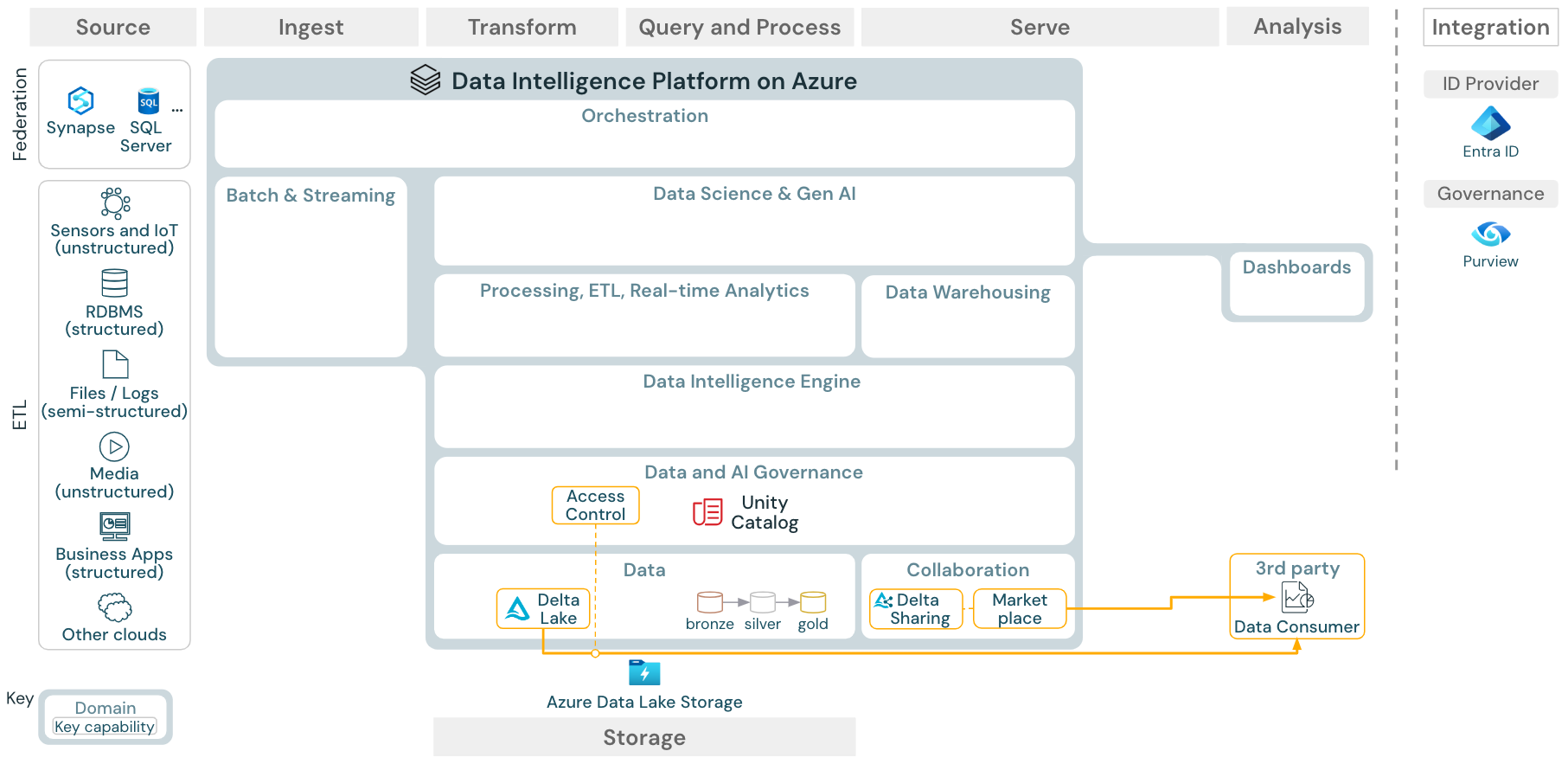
Referensarkitekturen för Data Intelligence Platform i Azure
Referensarkitekturen för Azure Databricks härleds från den allmänna referensarkitekturen genom att lägga till Azure-specifika tjänster för elementen Källa, Inmatning, Serve, Analys/Utdata och Lagring.
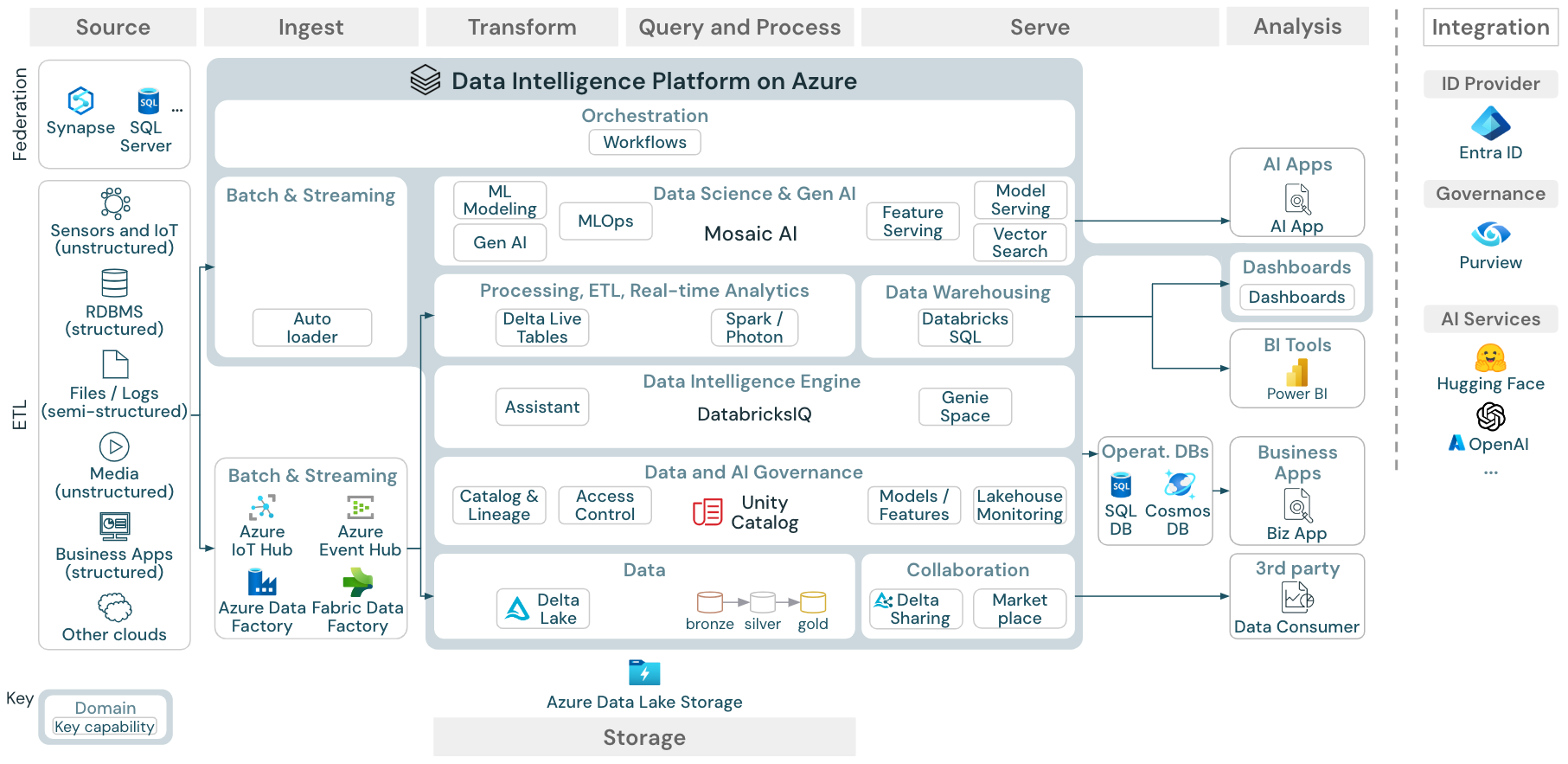
Ladda ned: Referensarkitektur för Databricks Lakehouse i Azure
Azure-referensarkitekturen visar följande Azure-specifika tjänster för inmatning, lagring, serve och analys/utdata:
- Azure Synapse och SQL Server som källsystem för Lakehouse Federation
- Azure IoT Hub och Azure Event Hubs för strömmande inmatning
- Azure Data Factory för batch-inmatning
- Azure Data Lake Storage Gen 2 (ADLS) som objektlagring
- Azure SQL DB och Azure Cosmos DB som driftdatabaser
- Azure Purview som företagskatalog till vilken UC exporterar schema- och ursprungsinformation
- Power BI som BI-verktyg
Kommentar
- Den här vyn av referensarkitekturen fokuserar bara på Azure-tjänster och Databricks lakehouse. Lakehouse på Databricks är en öppen plattform som integreras med ett stort ekosystem av partnerverktyg.
- De molnleverantörstjänster som visas är inte uttömmande. De väljs för att illustrera konceptet.
Användningsfall: Batch ETL
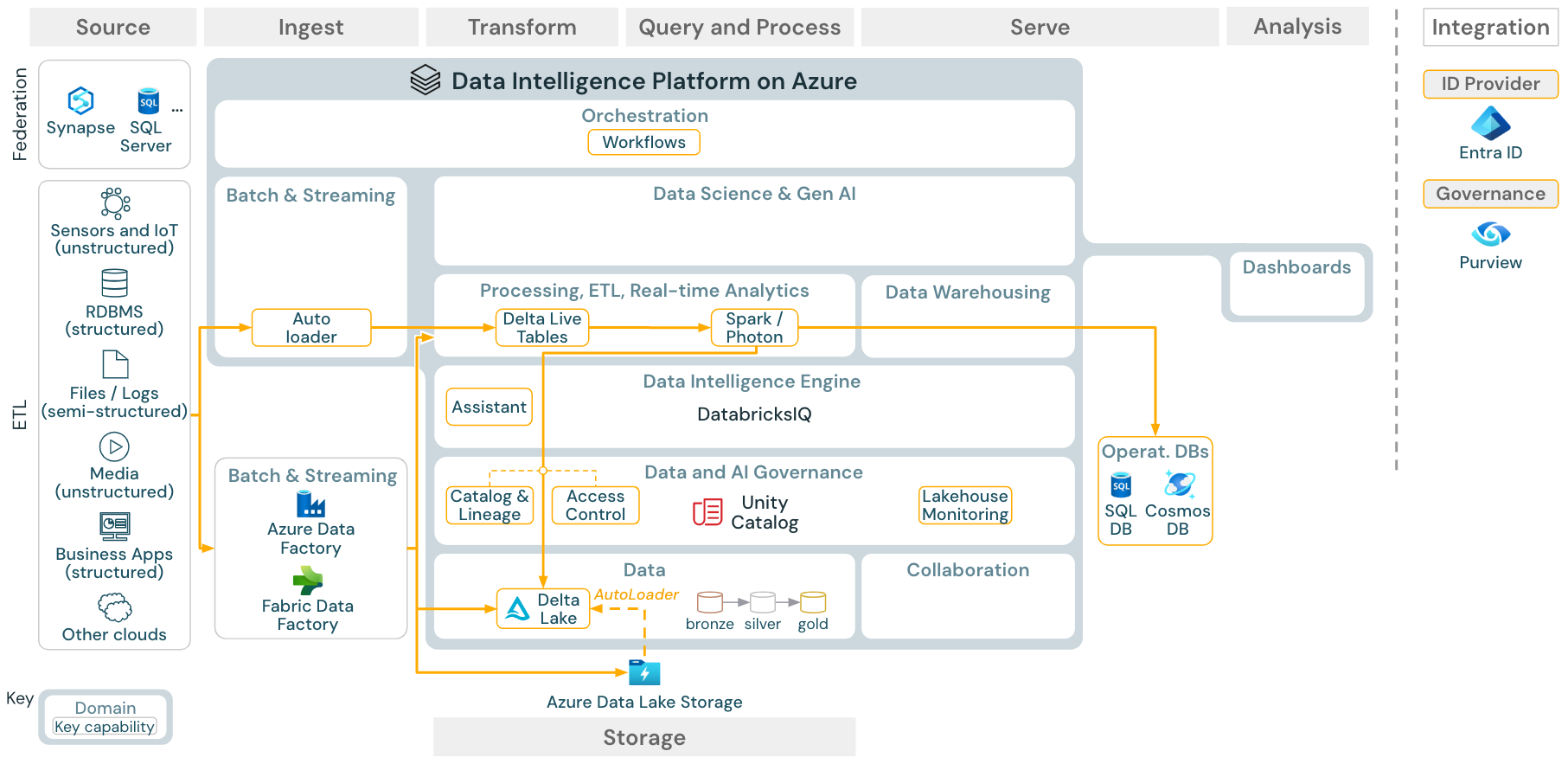
Ladda ned: Batch ETL-referensarkitektur för Azure Databricks
Inmatningsverktyg använder källspecifika kort för att läsa data från källan och lagrar dem sedan i molnlagringen där Auto Loader kan läsa dem, eller anropa Databricks direkt (till exempel med partnerinmatningsverktyg integrerade i Databricks lakehouse). För att läsa in data kör Databricks ETL och bearbetningsmotorn – via DLT – frågorna. Enkla arbetsflöden eller arbetsflöden med flera flöden kan samordnas av Databricks-jobb och styras av Unity Catalog (åtkomstkontroll, granskning, ursprung och så vidare). Om driftsystem med låg latens kräver åtkomst till specifika gyllene tabeller kan de exporteras till en driftdatabas, till exempel ett RDBMS- eller nyckelvärdeslager i slutet av ETL-pipelinen.
Användningsfall: Strömma och ändra datainsamling (CDC)
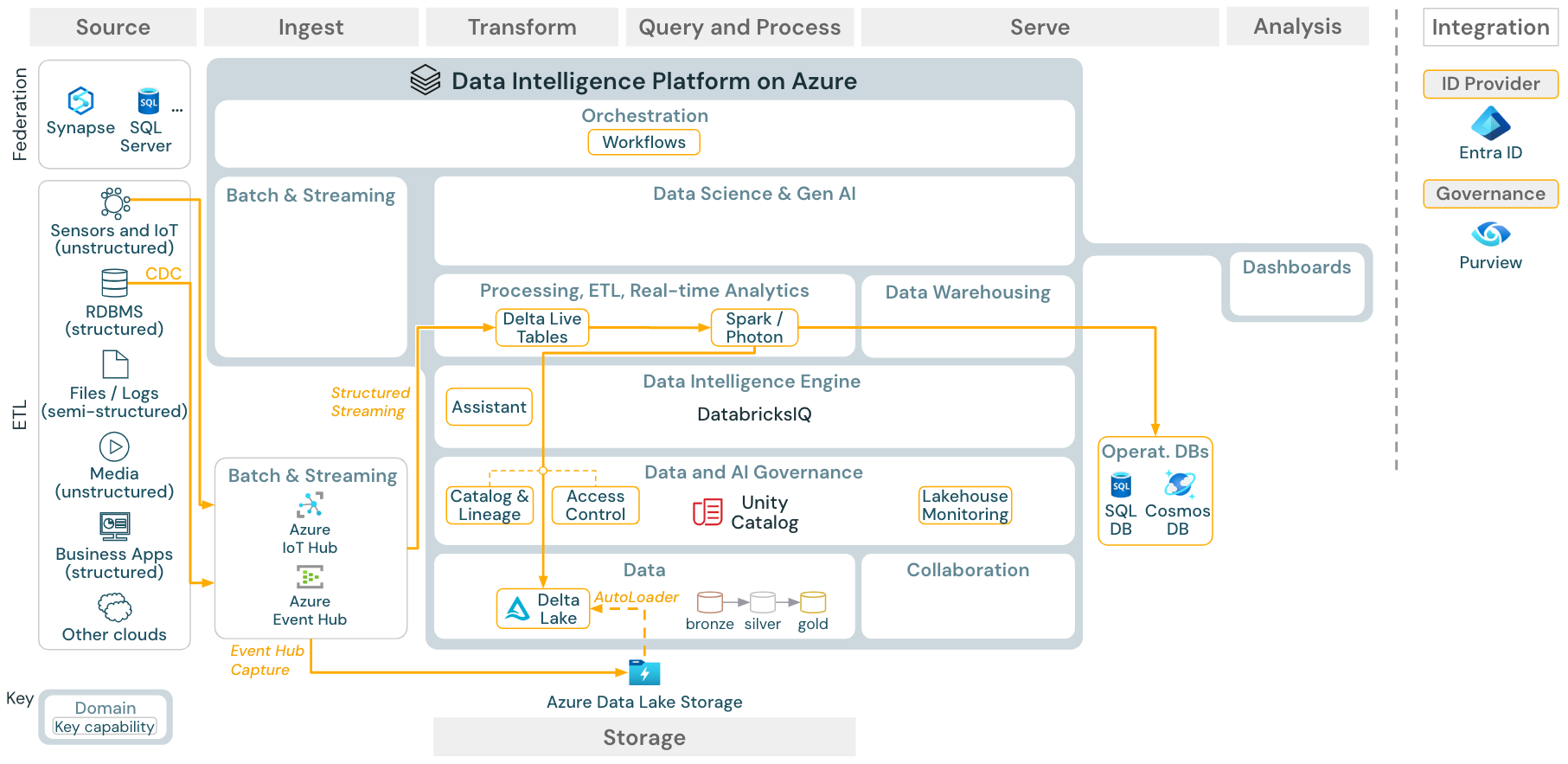
Ladda ned: Spark-strukturerad strömningsarkitektur för Azure Databricks
Databricks ETL-motorn använder Spark Structured Streaming för att läsa från händelseköer som Apache Kafka eller Azure Event Hub. De underordnade stegen följer metoden för Batch-användningsfallet ovan.
CDC (Real-Time Change Data Capture) använder vanligtvis en händelsekö för att lagra de extraherade händelserna. Därifrån följer användningsfallet användningsfallet för direktuppspelning.
Om CDC görs i batch där de extraherade posterna lagras i molnlagring först kan Databricks Autoloader läsa dem och användningsfallet följer Batch ETL.
Användningsfall: Maskininlärning och AI
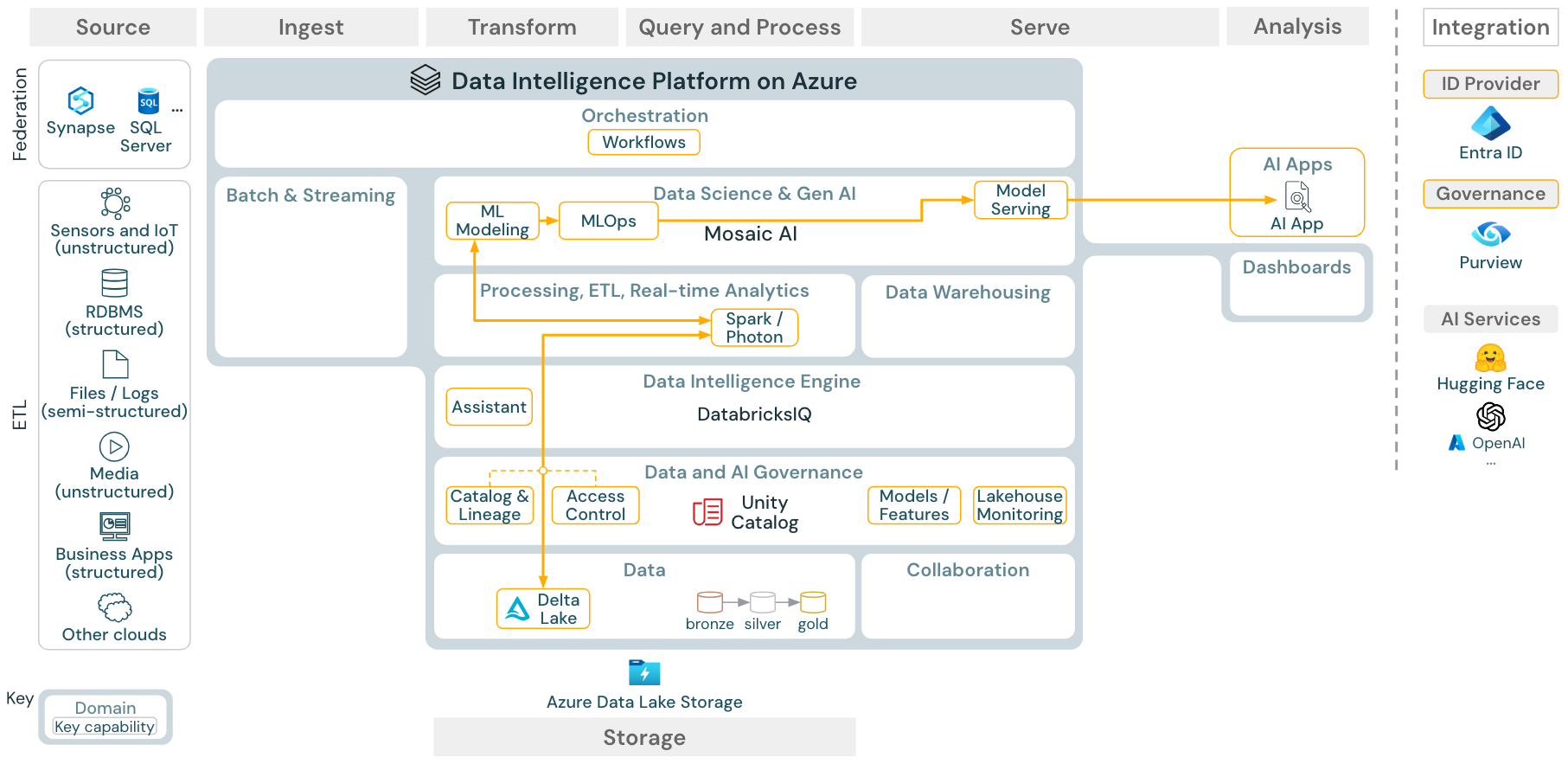
Ladda ned: Referensarkitektur för maskininlärning och AI för Azure Databricks
För maskininlärning tillhandahåller Databricks Data Intelligence Platform Mosaic AI, som levereras med toppmoderna maskin- och djupinlärningsbibliotek. Den innehåller funktioner som Funktionslager och modellregister (både integrerade i Unity Catalog), funktioner med låg kod med AutoML och MLflow-integrering i datavetenskapens livscykel.
Alla datavetenskapsrelaterade tillgångar (tabeller, funktioner och modeller) styrs av Unity Catalog och dataexperter kan använda Databricks-jobb för att samordna sina jobb.
För att distribuera modeller på ett skalbart och företagsbaserat sätt använder du MLOps-funktionerna för att publicera modellerna i modellservern.
Användningsfall: Hämtning av utökad generation (Gen AI)
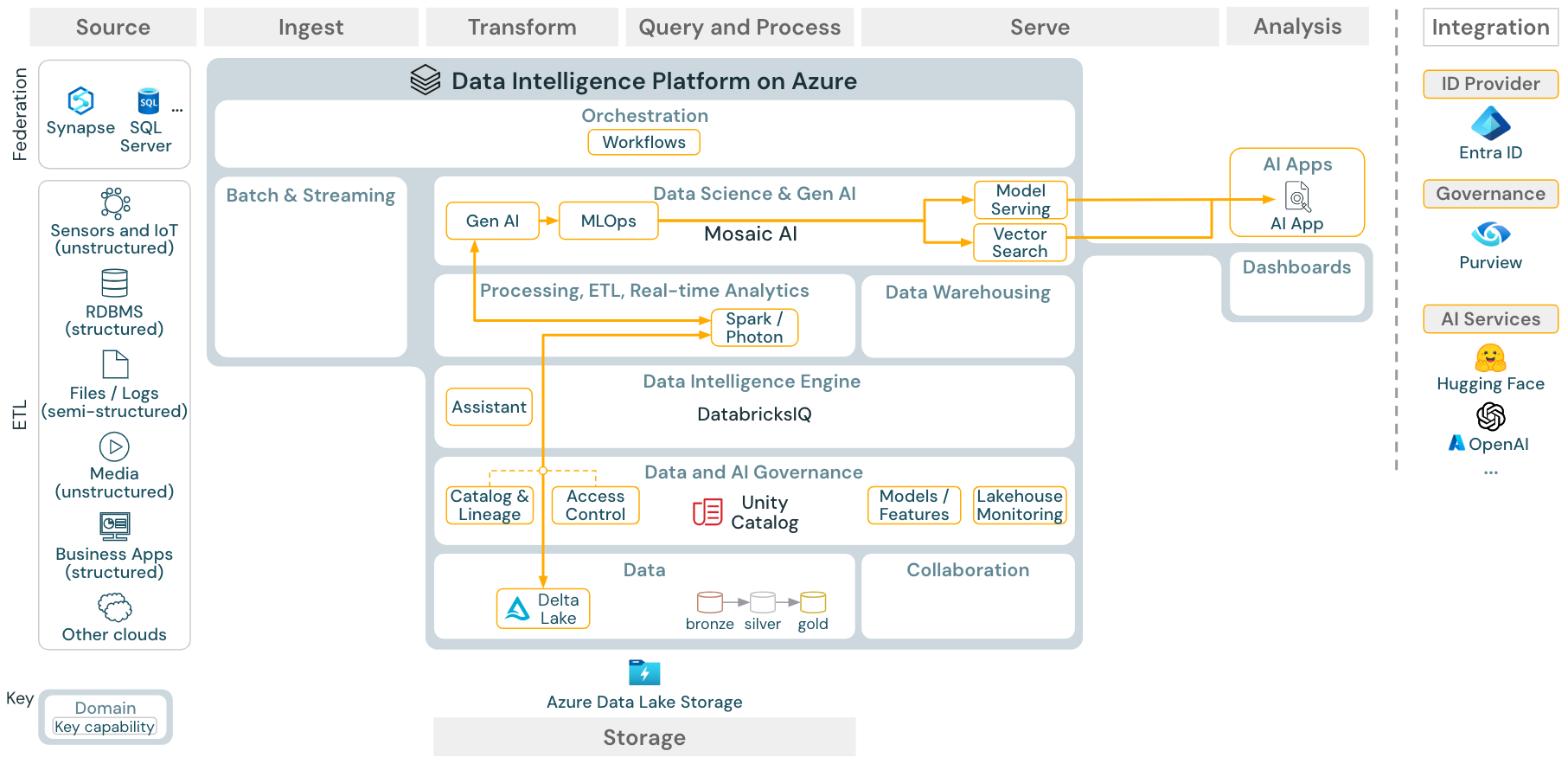
Ladda ned: Gen AI RAG-referensarkitektur för Azure Databricks
För generativa AI-användningsfall levereras Mosaic AI med toppmoderna bibliotek och specifika Gen AI-funktioner från snabb teknik till finjustering av befintliga modeller och förträning från grunden. Arkitekturen ovan visar ett exempel på hur vektorsökning kan integreras för att skapa ett RAG-AI-program (hämtningsförhöjd generation).
För att distribuera modeller på ett skalbart och företagsbaserat sätt använder du MLOps-funktionerna för att publicera modellerna i modellservern.
Användningsfall: BI- och SQL-analys
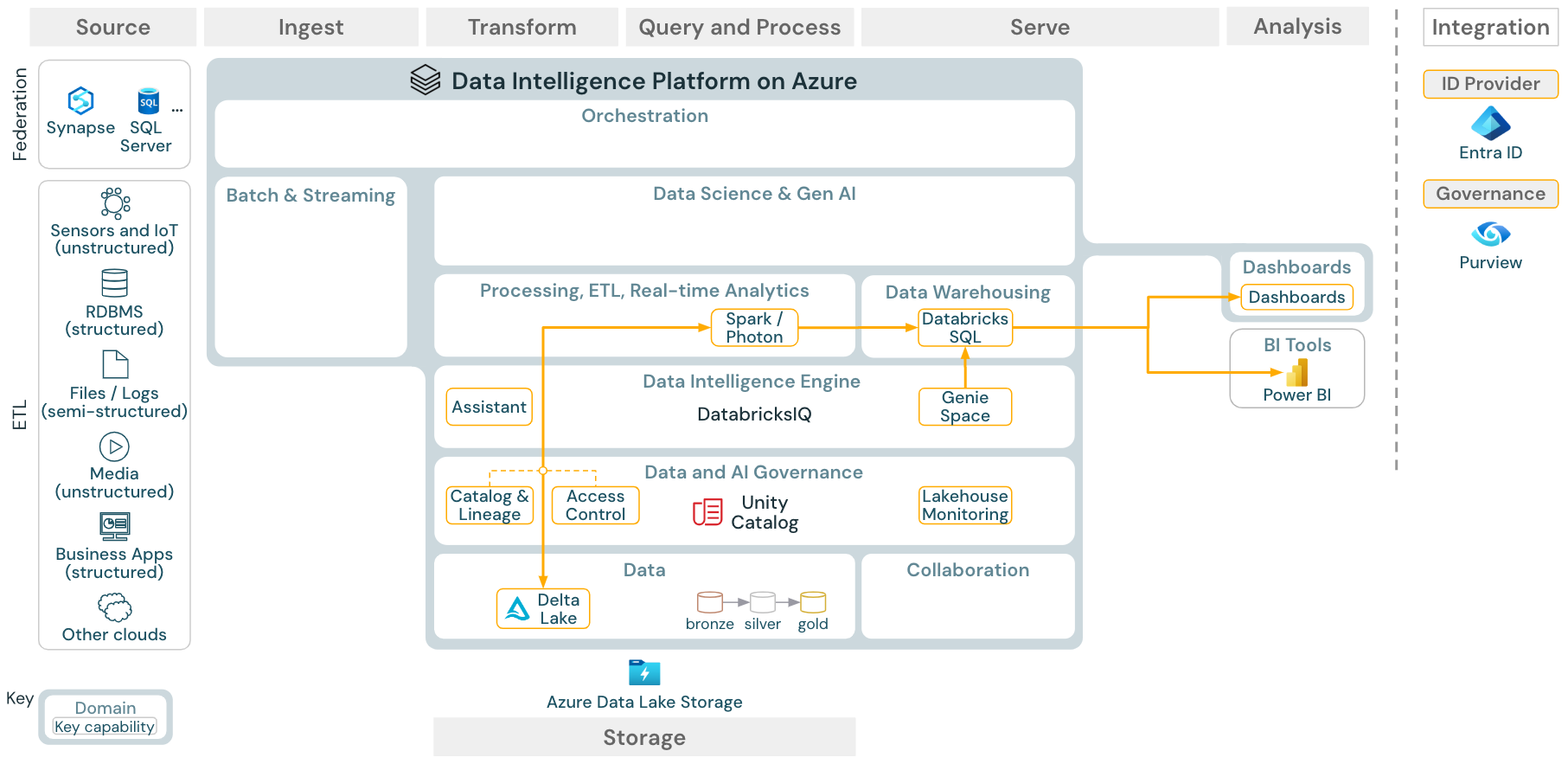
Ladda ned: REFERENSarkitektur för BI- och SQL-analys för Azure Databricks
För BI-användningsfall kan affärsanalytiker använda instrumentpaneler, Databricks SQL-redigeraren eller specifika BI-verktyg som Tableau eller Power BI. I samtliga fall är motorn Databricks SQL (serverlös eller icke-serverlös) och dataidentifiering, utforskning och åtkomstkontroll tillhandahålls av Unity Catalog.
Användningsfall: Lakehouse-federation
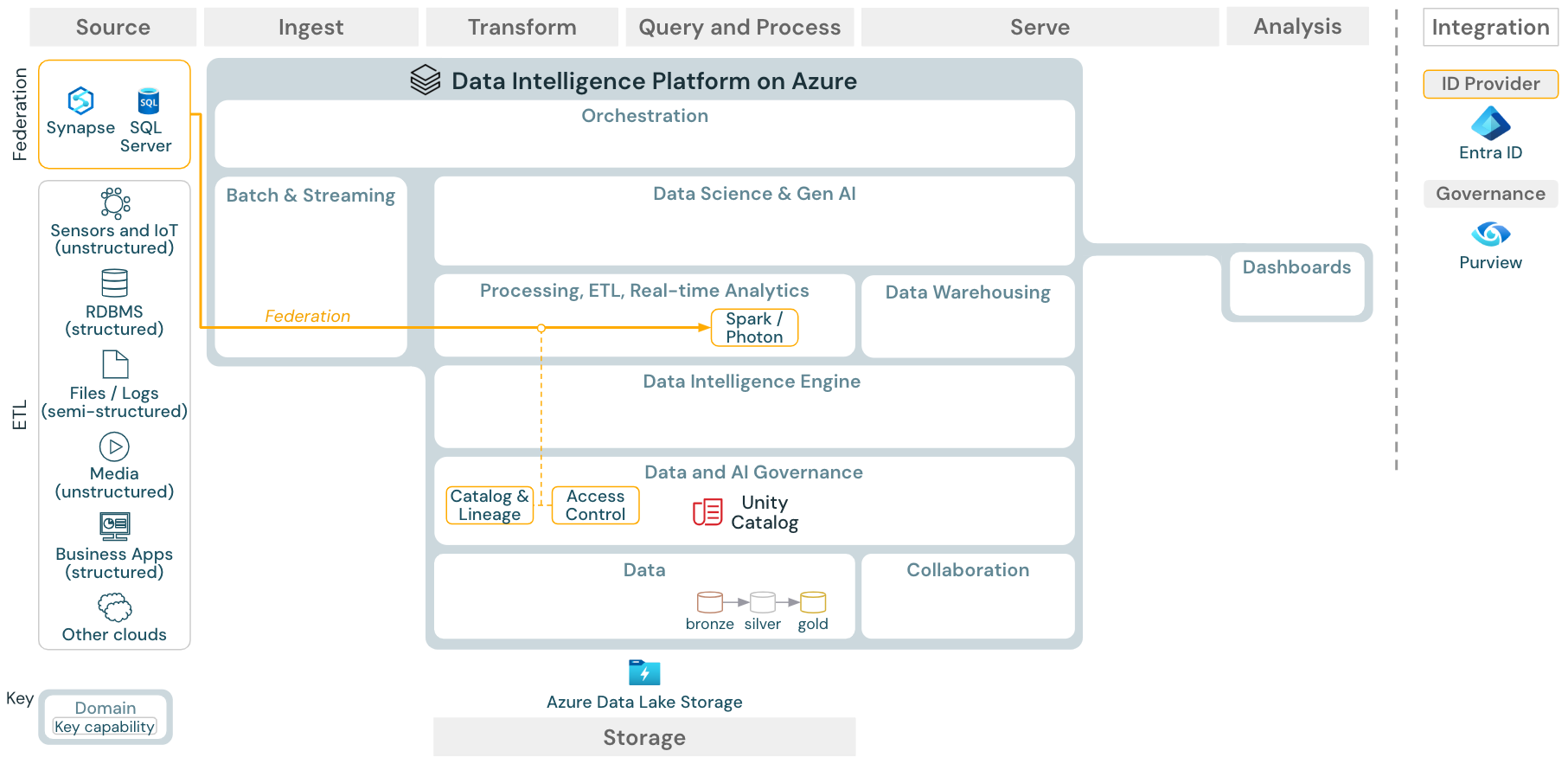
Ladda ned: Referensarkitektur för Lakehouse-federation för Azure Databricks
Lakehouse-federationen tillåter att externa DATA SQL-databaser (till exempel MySQL, Postgres, SQL Server eller Azure Synapse) integreras med Databricks.
Alla arbetsbelastningar (AI, DWH och BI) kan dra nytta av detta utan att först behöva ETL-data till objektlagring. Den externa källkatalogen mappas till Unity-katalogen och detaljerad åtkomstkontroll kan tillämpas på åtkomst via Databricks-plattformen.
Användningsfall: Delning av företagsdata
Ladda ned: Referensarkitektur för företagsdatadelning för Azure Databricks
Datadelning i företagsklass tillhandahålls av DeltaDelning. Det ger direkt åtkomst till data i objektlagret som skyddas av Unity Catalog, och Databricks Marketplace är ett öppet forum för utbyte av dataprodukter.