Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Följande Databricks SQL-funktioner och förbättringar släpptes 2025.
November 2025
Databricks SQL version 2025.35 lanseras i Aktuell
den 20 november 2025
Databricks SQL version 2025.35 rullas ut i den Aktuella kanalen. Se funktioner i 2025.35.
Databricks SQL-aviseringar finns nu i offentlig förhandsversion
den 14 november 2025
- Databricks SQL-aviseringar: Den senaste versionen av Databricks SQL-aviseringar, med en ny redigeringsupplevelse, finns nu i offentlig förhandsversion. Se Databricks SQL-aviseringar.
Korrigering av visualisering i SQL-redigeraren
den 6 november 2025
- Problem med visning av knappbeskrivningar har åtgärdats: Löste ett problem där knappbeskrivningar var dolda bakom förklaringen i visualiseringar av notebook- och SQL-redigerare.
Oktober 2025
Databricks SQL version 2025.35 är nu tillgänglig i förhandsversionen
den 30 oktober 2025
Databricks SQL version 2025.35 är nu tillgänglig i förhandsgranskningskanalen . Läs följande avsnitt om du vill veta mer om nya funktioner, beteendeändringar och felkorrigeringar.
EXECUTE IMMEDIATE använda konstanta uttryck
Nu kan du skicka konstanta uttryck som SQL-strängen och som argument till parametermarkörer i EXECUTE IMMEDIATE -instruktioner.
LIMIT ALL stöd för rekursiva CTE:er
Du kan nu använda LIMIT ALL för att ta bort den totala storleksbegränsningen för rekursiva vanliga tabelluttryck (CTE).
st_dump funktionsstöd
Nu kan du använda st_dump funktionen för att hämta en matris som innehåller de enskilda geometrierna i indatageometrin. Se st_dump funktion.
Polygons invändiga ringfunktioner stöds nu
Du kan nu använda följande funktioner för att arbeta med interiörringar av polygoner.
-
st_numinteriorrings: Hämta antalet inre gränser (ringar) för en polygon. Sest_numinteriorringsfunktion. -
st_interiorringn: Extrahera den n:e inre gränsen för en polygon och returnera den som en linjedragning. Sest_interiorringnfunktion.
Stöd för uppdateringsinformation för MV/ST i DESCRIBE EXTENDED AS JSON
Azure Databricks genererar nu ett avsnitt för materialiserad vy och uppdateringsinformation för strömmande tabell i DESCRIBE EXTENDED AS JSON utdata, inklusive senaste uppdateringstid, uppdateringstyp, status och schema.
Lägg till metadatakolumn i DESCRIBE QUERY och DESCRIBE TABLE
Azure Databricks innehåller nu en metadatakolumn i utdata från DESCRIBE QUERY och DESCRIBE TABLE för semantiska metadata.
För DESCRIBE QUERY, när du beskriver en fråga med måttvyer, sprids semantiska metadata via frågan om dimensioner refereras direkt och mått använder MEASURE() funktionen.
För DESCRIBE TABLEvisas metadatakolumnen endast för måttvyer, inte andra tabelltyper.
Korrekt hantering av nullstrukturer när kolumner tas bort NullType
När du skriver till Delta-tabeller bevarar Azure Databricks nu null struct-värden korrekt när du släpper NullType kolumner från schemat. Tidigare ersattes felaktigt noll-strukturer med icke-null strukturvärden där alla fält var satta till null.
Ny upplevelse för aviseringsredigering
den 20 oktober 2025
- Ny upplevelse för aviseringsredigering: Skapa eller redigera en avisering öppnas nu i den nya redigeringsredigeraren med flera flikar, vilket ger ett enhetligt redigeringsarbetsflöde. Se Databricks SQL-aviseringar.
Korrigering av visualiseringar
den 9 oktober 2025
- Förklaringsval för aliasserienamn: Val av förklaring fungerar nu korrekt för diagram med aliasserienamn i SQL-redigeraren och notebook-filer.
Semantiska metadata i måttvyer
2 oktober 2025
Nu kan du definiera semantiska metadata inom en måttvy. Semantiska metadata hjälper AI-verktyg som Genie Agents (tidigare Genie Spaces) och AI/BI-instrumentpaneler att tolka och använda dina data mer effektivt.
Om du vill använda semantiska metadata måste din måttvy använda YAML-specifikation version 1.1 eller senare och köras på Databricks Runtime 17.3 eller senare. Motsvarande Databricks SQL-version är 2025.30, tillgänglig i förhandsgranskningskanalen för SQL-lager.
Se Agentmetadata i måttvyer och Uppgradera till YAML 1.1.
2025 september
Databricks SQL version 2025.30 är nu tillgänglig i förhandsversionen
den 25 september 2025
Databricks SQL version 2025.30 är nu tillgänglig i förhandsgranskningskanalen . Läs följande avsnitt om du vill veta mer om nya funktioner, beteendeändringar och felkorrigeringar.
UTF8-baserade sorteringar har nu stöd för LIKE-operatorn
Nu kan du använda LIKE med kolumner som har någon av följande sorteringar aktiverade: UTF8_Binary, UTF8_Binary_RTRIM, UTF8_LCASE, . UTF8_LCASE_RTRIM Se Sammanställning.
ST_ExteriorRing funktionen stöds nu
Nu kan du använda ST_ExteriorRing funktionen för att extrahera den yttre gränsen för en polygon och returnera den som en linjedragning. Se st_exteriorring funktion.
Deklarera flera sessioner eller lokala variabler i en enda DECLARE instruktion
Nu kan du deklarera flera sessionsvariabler eller lokala variabler av samma typ och standardvärde i en enda DECLARE instruktion. Se DECLARE VARIABLE och BEGIN END-komplex instruktion.
Stöd för TEMPORARY nyckelord för att skapa metrisk vy
Du kan nu använda nyckelordet TEMPORARY när du skapar en måttvy. Tillfälliga måttvyer visas endast i sessionen som skapade dem och tas bort när sessionen avslutas. Se CREATE VIEW.
DESCRIBE CONNECTION visar miljöinställningar för JDBC-anslutningar
Azure Databricks innehåller nu användardefinierade miljöinställningar i DESCRIBE CONNECTION utdata för JDBC-anslutningar som stöder anpassade drivrutiner och körs isolerat. Andra anslutningstyper förblir oförändrade.
SQL-syntax för Delta-läsningsalternativ i strömmande frågeprocesser
Nu kan du ange Delta-läsalternativ för SQL-baserade strömningsfrågor med hjälp av WITH -satsen. Till exempel:
SELECT * FROM STREAM tbl WITH (SKIPCHANGECOMMITS=true, STARTINGVERSION=X);
Rätt resultat för split med tom regex och positiv gräns
Azure Databricks returnerar nu rätt resultat när du använder split function med en tom regex och en positiv gräns. Tidigare trunkerade funktionen felaktigt den återstående strängen i stället för att inkludera den i det sista elementet.
Åtgärda felhantering för url_decode och try_url_decode i Photon
I Photon returnerar try_url_decode(), url_decode() och failOnError = false nu NULL för ogiltiga URL-kodade strängar i stället för att frågan misslyckas.
Augusti 2025
Standardinställningen för informationslager är nu tillgänglig i Beta
den 28 augusti 2025
Ange ett standardlager som väljs automatiskt i beräkningsväljaren i SQL-redigeraren, AI/BI-instrumentpaneler, Genie-agenter (tidigare Genie Spaces), Aviseringar och Catalog Explorer. Enskilda användare kan åsidosätta den här inställningen genom att välja ett annat lager innan en fråga körs. De kan också definiera sitt eget standardlager på användarnivå som ska tillämpas i alla sessioner. Se Ange ett SQL-standardlager för arbetsytan och Ange ett standardlager på användarnivå.
Databricks SQL version 2025.25 lanseras i Aktuell
den 21 augusti 2025
Databricks SQL version 2025.25 rullas ut till Current-kanalen från 20 augusti 2025 till 28 augusti 2025. Se funktioner i 2025.25.
Databricks SQL version 2025.25 är nu tillgänglig i förhandsversionen
den 14 augusti 2025
Databricks SQL version 2025.25 är nu tillgänglig i förhandsgranskningskanalen . Läs följande avsnitt om du vill veta mer om nya funktioner och beteendeändringar.
Rekursiva vanliga tabelluttryck (rCTE) är allmänt tillgängliga
Rekursiva vanliga tabelluttryck (rCTEs) är allmänt tillgängliga. Navigera i hierarkiska data med hjälp av en självrefererande CTE med UNION ALL för att följa den rekursiva relationen.
Stöd för standardsortering på schema- och katalognivå
Nu kan du ange en standardsortering för scheman och kataloger. På så sätt kan du definiera en sortering som gäller för alla objekt som skapats i schemat eller katalogen, vilket säkerställer konsekvent sorteringsbeteende för dina data.
Stöd för spatiala SQL-uttryck och datatyper för GEOMETRI och GEOGRAFI
Nu kan du lagra geospatiala data i inbyggda GEOMETRY och GEOGRAPHY kolumner för bättre prestanda för spatiala frågor. Den här versionen lägger till fler än 80 nya rumsliga SQL-uttryck, inklusive funktioner för att importera, exportera, mäta, konstruera, redigera, validera, transformera och fastställa topologiska relationer med rumsliga kopplingar. Se geospatiala ST-funktioner, GEOGRAPHY typ och GEOMETRY typ.
Stöd för standardsortering på schema- och katalognivå
Nu kan du ange en standardsortering för scheman och kataloger. På så sätt kan du definiera en sortering som gäller för alla objekt som skapats i schemat eller katalogen, vilket säkerställer konsekvent sorteringsbeteende för dina data.
Bättre hantering av JSON-alternativ med VARIANT
Funktionerna from_json och to_json tillämpar nu JSON-alternativ korrekt när du arbetar med scheman på den översta nivån VARIANT . Detta säkerställer konsekvent beteende med andra datatyper som stöds.
Stöd för TIDSSTÄMPEL UTAN TIDSZONssyntax
Nu kan du ange TIMESTAMP WITHOUT TIME ZONE i stället för TIMESTAMP_NTZ. Den här ändringen förbättrar kompatibiliteten med SQL Standard.
Löst problem med korrelation av underfrågor
Azure Databricks korrelerar inte längre semantiskt lika aggregeringsuttryck mellan en underfråga och dess yttre fråga på ett felaktigt sätt. Tidigare kan detta leda till felaktiga frågeresultat.
Fel vid ogiltiga CHECK begränsningar
Azure Databricks genererar nu en AnalysisException om ett CHECK villkorsuttryck inte kan matchas under begränsningsverifieringen.
Striktare regler för stream-stream-kopplingar i append-läge
Azure Databricks tillåter nu inte strömmande frågor i tilläggsläge som använder en stream-stream-koppling följt av fönsteraggregering, såvida inte vattenstämplar definieras på båda sidor. Frågeställningar utan korrekta vattenstämplar kan ge ofullständiga resultat, vilket bryter mot garantier för append-läge.
Ny SQL-redigerare är allmänt tillgänglig
den 14 augusti 2025
Den nya SQL-redigeraren är nu allmänt tillgänglig. Den nya SQL-redigeraren ger en enhetlig redigeringsmiljö med stöd för flera instruktionsresultat, infogad körningshistorik, realtidssamarbete, förbättrad Integrering av Databricks Assistant och ytterligare produktivitetsfunktioner. Se Skriva frågor och utforska data i den nya SQL-redigeraren.
Fast timeouthantering för materialiserade vyer och strömmande tabeller
den 14 augusti 2025
Nytt timeoutbeteende för materialiserade vyer och strömmande tabeller som skapats i Databricks SQL:
- Materialiserade vyer och strömningstabeller som skapats efter den 14 augusti 2025 kommer att få datavarulagrets tidsgräns applicerad automatiskt.
- För materialiserade vyer och strömmande tabeller som skapats före den 14 augusti 2025 kör du
CREATE OR REFRESHför att synkronisera timeout-inställningen med timeout-konfigurationen för lagret. - Alla materialiserade vyer och strömmande tabeller har nu en standardtidsgräns på två dagar.
Juli 2025
Förinställda datumintervall för parametrar i SQL-redigeraren
den 31 juli 2025
I den nya SQL-redigeraren kan du nu välja mellan förinställda datumintervall, till exempel Den här veckan, Senaste 30 dagarna eller Senaste året när du använder parametrar för tidsstämpel, datum och datumintervall. Dessa förinställningar gör det snabbare att använda vanliga tidsfilter utan att ange datum manuellt.
Jobb- och pipelineslistan innehåller nu Databricks SQL-pipelines
den 29 juli 2025
Listan Jobb och pipelines innehåller nu pipelines för materialiserade vyer och strömmande tabeller som har skapats med Databricks SQL.
Körningshistorik inline i SQL-redigeraren
den 24 juli 2025
Inbyggd körningshistorik är nu tillgänglig i den nya SQL-redigeraren, så att du snabbt kan få åtkomst till tidigare resultat utan att behöva köra frågorna igen. Referera enkelt till tidigare körningar, navigera direkt till tidigare frågeprofiler, eller jämför körningstider och status – allt inom kontexten av din aktuella fråga.
Databricks SQL version 2025.20 är nu tillgänglig i Aktuell
den 17 juli 2025
Databricks SQL version 2025.20 lanseras stegvis till den aktuella kanalen. Funktioner och uppdateringar i den här versionen finns i 2025.20-funktioner.
Uppdateringar av SQL-redigeraren
den 17 juli 2025
Förbättringar av namngivna parametrar: Parametrar för datumintervall och flera val stöds nu. För datumintervallparametrar, se Lägg till ett datumintervall genom att använda
.minoch.max. Flervalsparametrar finns i Skicka flera värden som en sträng.Uppdaterad sidhuvudlayout i SQL-redigeraren: Körningsknappen och katalogväljaren har flyttats till rubriken, vilket skapar mer lodrätt utrymme för att skriva frågor.
Git-stöd för aviseringar
den 17 juli 2025
Du kan nu använda Databricks Git-mappar för att spåra och hantera ändringar i aviseringar. Om du vill spåra aviseringar med Git placerar du dem i en Databricks Git-mapp. Nyligen klonade aviseringar visas bara på sidan med aviseringar eller API:et när en användare har interagerat med dem. De har pausat scheman och måste uttryckligen återupptas av användarna. Se Hur Git-integrering fungerar med aviseringar.
Databricks SQL version 2025.20 är nu tillgänglig i förhandsversionen
den 3 juli 2025
Databricks SQL version 2025.20 är nu tillgänglig i förhandsgranskningskanalen . Läs följande avsnitt om du vill veta mer om nya funktioner och beteendeändringar.
Stöd för SQL-procedur
SQL-skript kan nu kapslas in i en procedur som lagras som en återanvändbar tillgång i Unity Catalog. Du kan skapa en procedur med kommandot CREATE PROCEDURE och sedan anropa den med kommandot CALL .
Ange en standardsortering för SQL Functions
Med hjälp av den nya DEFAULT COLLATION satsen i CREATE FUNCTION kommandot definieras standardsortering som används för STRING parametrar, returtyp och STRING literaler i funktionstexten.
Stöd för rekursiva vanliga tabelluttryck (rCTE)
Azure Databricks stöder nu navigering av hierarkiska data med hjälp av recursive common table expressions (rCTEs).
Använd en självrefererande CTE med UNION ALL för att följa den rekursiva relationen.
Stöd ALL CATALOGS i SHOW SCHEMAN
Syntaxen SHOW SCHEMAS uppdateras för att acceptera följande syntax:
SHOW SCHEMAS [ { FROM | IN } { catalog_name | ALL CATALOGS } ] [ [ LIKE ] pattern ]
När ALL CATALOGS anges i en SHOW fråga itererar körningen genom alla aktiva kataloger som stöder namnområden med hjälp av kataloghanteraren (DsV2). För varje katalog innehåller den namnrymderna på den översta nivån.
Utdataattributen och schemat för kommandot har ändrats för att lägga till en catalog kolumn som anger katalogen för motsvarande namnområde. Den nya kolumnen läggs till i slutet av utdataattributen enligt nedan:
Tidigare utdata
| Namespace |
|------------------|
| test-namespace-1 |
| test-namespace-2 |
Nya utdata
| Namespace | Catalog |
|------------------|----------------|
| test-namespace-1 | test-catalog-1 |
| test-namespace-2 | test-catalog-2 |
Flytande klustring komprimerar nu borttagningsvektorer mer effektivt
Deltatabeller med Liquid-klustring tillämpar nu fysiska ändringar från borttagningsvektorer mer effektivt när OPTIMIZE körs. Mer information finns i Tillämpa ändringar på Parquet-datafiler.
Tillåt icke-deterministiska uttryck i UPDATE/INSERT kolumnvärden för åtgärder MERGE
Azure Databricks tillåter nu användning av icke-deterministiska uttryck i uppdaterade och infogade kolumnvärden för MERGE åtgärder. Icke-deterministiska uttryck i villkoren MERGE för instruktioner stöds dock inte.
Nu kan du till exempel generera dynamiska eller slumpmässiga värden för kolumner:
MERGE INTO target USING source
ON target.key = source.key
WHEN MATCHED THEN UPDATE SET target.value = source.value + rand()
Detta kan vara användbart för datasekretessen genom att dölja faktiska data samtidigt som dataegenskaperna bevaras (till exempel medelvärden eller andra beräknade kolumner).
Stöd för VAR-nyckelord för att deklarera och släppa SQL-variabler
SQL-syntax för att deklarera och släppa variabler stöder nu nyckelordet VAR utöver VARIABLE. Den här ändringen förenar syntaxen för alla variabelrelaterade åtgärder, vilket förbättrar konsekvensen och minskar förvirringen för användare som redan använder VAR när de anger variabler.
CREATE VIEW satser på kolumnnivå utlöser nu fel när satsen bara gäller materialiserade vyer
De CREATE VIEW kommandon som anger en kolumnspecifik klausul som endast är giltig för MATERIALIZED VIEWs utlöser nu ett fel. De berörda satserna för CREATE VIEW kommandon är:
NOT NULL- En angiven datatyp, till exempel
FLOATellerSTRING DEFAULTCOLUMN MASK
Juni 2025
Uppgraderingar av Databricks SQL Serverless-motorn
11 juni 2025
Följande motoruppgraderingar lanseras nu globalt, och tillgängligheten utökas till alla regioner under de kommande veckorna.
- Kortare svarstid: Instrumentpaneler, ETL-jobb och blandade arbetslaster körs nu snabbare, med upp till 25% förbättring. Uppgraderingen tillämpas automatiskt på serverlösa SQL-lager utan extra kostnad eller konfiguration.
- Prediktiv frågekörning (PQE): PQE övervakar uppgifter i realtid och justerar dynamiskt frågekörning för att undvika skevhet, spill och onödigt arbete.
- Fotovektoriserad blandning: Håller data i kompakt kolumnformat, sorterar dem i processorns höghastighetscachen och bearbetar flera värden samtidigt med hjälp av vektoriserade instruktioner. Detta förbättrar dataflödet för CPU-bundna arbetsbelastningar, till exempel stora kopplingar och bred aggregering.
Uppdateringar av användargränssnittet
5 juni 2025
-
Förbättringar av frågeinsikter: När du besöker sidan Frågehistorik genereras
listHistoryQuerieshändelsen. Att öppna en frågeprofil avger nugetHistoryQuery-händelsen.
Maj 2025
Måttvyer finns i offentlig förhandsversion
29 maj 2025
Måttvyer för Unity Catalog är ett centraliserat sätt att definiera och hantera konsekventa, återanvändbara och reglerade kärnaffärsmått. De sammanfattar komplex affärslogik i en centraliserad definition, vilket gör det möjligt för organisationer att definiera viktiga prestandaindikatorer en gång och använda dem konsekvent i rapporteringsverktyg som instrumentpaneler, Genie-agenter (tidigare Genie Spaces) och aviseringar. Använd ett SQL-lager som körs på förhandsgranskningskanalen (2025.16) eller någon annan beräkningsresurs som kör Databricks Runtime 16.4 eller senare för att arbeta med måttvyer. Se Metriska vyer för Unity Catalog.
Uppdateringar av användargränssnittet
29 maj 2025
-
Nya förbättringar av SQL-redigeraren:
- Nya frågor i mappen Utkast: Nya frågor skapas nu som standard i mappen Utkast. När de sparas eller byter namn flyttas de automatiskt från utkasten.
-
Stöd för frågefragment: Du kan nu skapa och återanvända frågefragment – fördefinierade segment av SQL, till exempel
JOINellerCASEuttryck, med stöd för automatisk komplettering och dynamiska insättningspunkter. Skapa kodfragment genom att välja Visa>frågefragment. - Granskningslogghändelser: Granskningslogghändelser genereras nu för åtgärder som vidtas i den nya SQL-redigeraren.
- Filter påverkar visualiseringar: Filter som tillämpas på resultattabeller påverkar nu även visualiseringar, vilket möjliggör interaktiv utforskning utan att ändra SQL-frågan.
Ny aviseringsversion i Beta
22 maj 2025
En ny version av aviseringar finns nu i Beta. Den här versionen förenklar skapandet och hanteringen av aviseringar genom att konsolidera frågekonfiguration, villkor, scheman och meddelandemål i ett enda gränssnitt. Du kan fortfarande använda äldre aviseringar tillsammans med den nya versionen. Se Databricks SQL-aviseringar.
Uppdateringar av användargränssnittet
22 maj 2025
- Knappbeskrivningsformatering i diagram: Knappbeskrivningar i diagram från SQL-redigeraren och notebook-filer följer nu nummerformateringen som definierats på fliken Dataetiketter . Se Visualiseringar i Databricks Notebooks och SQL-redigeraren.
Databricks SQL version 2025.16 är nu tillgänglig
15 maj 2025
Databricks SQL version 2025.16 är nu tillgänglig i förhandsgranskningskanalen . Läs följande avsnitt om du vill veta mer om nya funktioner, beteendeändringar och felkorrigeringar.
IDENTIFIER support nu tillgänglig i Databricks SQL för katalogåtgärder
Du kan nu använda IDENTIFIER -satsen när du utför följande katalogåtgärder:
CREATE CATALOGDROP CATALOGCOMMENT ON CATALOGALTER CATALOG
Med den här nya syntaxen kan du dynamiskt ange katalognamn med hjälp av parametrar som definierats för dessa åtgärder, vilket möjliggör mer flexibla och återanvändbara SQL-arbetsflöden. Som ett exempel på syntaxen bör du överväga CREATE CATALOG IDENTIFIER(:param) var param är en parameter som tillhandahålls för att ange ett katalognamn.
Mer information finns i IDENTIFIER satsen.
Sorterade uttryck tillhandahåller nu automatiskt genererade tillfälliga alias
Autogenererade alias för sammanställda uttryck inkorporerar nu alltid deterministiskt COLLATE-information. Autogenererade alias är tillfälliga (instabila) och bör inte användas. Använd i stället expression AS alias konsekvent och explicit som en bästa praxis.
UNION/EXCEPT/INTERSECT i en vy och EXECUTE IMMEDIATE returnerar nu rätt resultat
Frågor om tillfälliga och beständiga vydefinitioner med kolumner på den översta nivån UNION/EXCEPT/INTERSECT och oaliaserade kolumner returnerade tidigare felaktiga resultat eftersomUNION/EXCEPT/INTERSECT nyckelord betraktades som alias. Nu kommer dessa frågeförfrågningar att korrekt utföra hela mängdoperationen.
EXECUTE IMMEDIATE ... INTO med en toppnivå UNION/EXCEPT/INTERSECT och oaliaserade kolumner skrev ett felaktigt resultat av en mängdoperation i den angivna variabeln eftersom parsern tolkade dessa nyckelord som alias. På samma sätt tilläts även SQL-frågor med ogiltig sluttext. Ange åtgärder i dessa fall och skriv nu ett korrekt resultat till den angivna variabeln eller misslyckas i händelse av ogiltig SQL-text.
Nya listagg funktioner och string_agg funktioner
Du kan nu använda listagg funktionerna eller string_agg för att aggregera STRING och BINARY värden i en grupp. Mer information finns i string_agg .
Korrigering för gruppering på avbildade heltalslitteraler blev problematisk vid vissa operationer
Grupperingsuttryck på en aliassatt heltalsliteral fungerade tidigare inte för vissa operationer som MERGE INTO. Det här uttrycket skulle till exempel returneras GROUP_BY_POS_OUT_OF_RANGE eftersom värdet (val) skulle ersättas med 202001:
merge into t
using
(select 202001 as val, count(current_date) as total_count group by val) on 1=1
when not matched then insert (id, name) values (val, total_count)
Detta har åtgärdats. För att undvika problemet i dina befintliga frågor kontrollerar du att konstanterna du använder inte är lika med kolumnpositionen som måste finnas i grupperingsuttrycken.
Aktivera flagga för att förhindra inaktivering av källmaterialisering för MERGE åtgärder.
Tidigare kunde användare inaktivera källmaterialisering i MERGE genom att ange merge.materializeSource till none. Med den nya flaggan aktiverad kommer detta att förbjudas och orsaka ett fel. Databricks planerar att endast aktivera flaggan för kunder som inte har använt den här konfigurationsflaggan tidigare, så ingen kund bör märka några ändringar i beteendet.
April år 2025
Databricks SQL version 2025.15 är nu tillgänglig
den 10 april 2025
Databricks SQL version 2025.15 är nu tillgänglig i förhandsgranskningskanalen . Läs följande avsnitt om du vill veta mer om nya funktioner, beteendeändringar och felkorrigeringar.
Redigera flera kolumner med hjälp av ALTER TABLE
Nu kan du ändra flera kolumner i en enda ALTER TABLE instruktion. Se ALTER TABLE ... COLUMN klausul.
Nedgradering av Delta-tabellprotokoll är allmänt tillgänglig med kontrollpunktskydd
DROP FEATURE är allmänt tillgängligt för att ta bort Delta Lake-tabellfunktioner och nedgradera tabellprotokollet. Som standard skapar DROP FEATURE nu skyddade kontrollpunkter som inte kräver någon väntetid eller historiktrunkering, för en mer optimerad och förenklad nedgraderingsupplevelse. Se Ta bort en Delta Lake-tabellfunktion och nedgradera tabellprotokollet.
Skriva procedurmässiga SQL-skript baserat på ANSI SQL/PSM (offentlig förhandsversion)
Nu kan du använda skriptfunktioner baserade på ANSI SQL/PSM för att skriva procedurlogik med SQL, inklusive villkorssatser, loopar, lokala variabler och undantagshantering. Se SQL-skript.
Standardsortering på tabell- och visningsnivå
Nu kan du ange en standardsortering för tabeller och vyer. Detta förenklar skapandet av tabeller och vyer där alla eller de flesta kolumner delar samma sortering. Se Sammanställning.
Nya H3-funktioner
Följande H3-funktioner har lagts till:
Stöd för äldre instrumentpaneler har upphört
den 10 april 2025
Det officiella stödet för äldre instrumentpaneler har upphört. Du kan inte längre skapa eller klona äldre instrumentpaneler med hjälp av användargränssnittet eller API:et. Databricks fortsätter att hantera kritiska säkerhetsproblem och tjänststopp, men rekommenderar att du använder AI/BI-instrumentpaneler för all ny utveckling. Mer information om AI/BI-instrumentpaneler finns i Instrumentpaneler. Mer information om hur du migrerar finns i Klona en äldre instrumentpanel till en AI/BI-instrumentpanel och Använda instrumentpanels-API:er för att skapa och hantera instrumentpaneler.
Alternativ för anpassad autoformatering för SQL-frågor
den 3 april 2025
Anpassa alternativ för automatisk formatering för alla dina SQL-frågor. Se SQL-uttryck i anpassat format.
Problem med Boxplot-visualiseringar har åtgärdats
den 3 april 2025
Åtgärdade ett problem där Databricks SQL boxplot-visualiseringar med endast en kategorisk x-axel inte visade kategorier och staplar korrekt. Visualiseringar återges nu som förväntat.
CAN VIEW-behörigheten för SQL-lager finns i offentlig förhandsversion
den 3 april 2025
CAN VIEW-behörigheten finns nu i offentlig förhandsversion. Med den här behörigheten kan användare övervaka SQL-lager, inklusive tillhörande frågehistorik och frågeprofiler. Användare med CAN VIEW-behörighet kan inte köra frågor i SQL-informationslagret utan att beviljas ytterligare behörigheter. Se ACL:er för SQL-lager.
mars 2025
Uppdateringar av användargränssnittet
den 27 mars 2025
- Frågeprofiler har uppdaterats för bättre användbarhet: Frågeprofiler har uppdaterats för att förbättra användbarheten och hjälpa dig att snabbt få åtkomst till viktiga insikter. Se Frågeprofil.
Uppdateringar av användargränssnittet
20 mars 2025
- Överför ägarskap för SQL-lager till tjänstehuvudnamn: Du kan nu använda användargränssnittet för att överföra SQL-lagerägarskapet till ett tjänstehuvudnamn.
Uppdateringar av användargränssnittet
6 mars 2025
- Diagram med dubbla axlar stöder nu zoomning: Du kan nu klicka och dra för att zooma in på diagram med dubbla axlar.
- Fäst tabellkolumner: Nu kan du fästa tabellkolumner till vänster i tabellvisningen. Kolumner förblir i vyn när du rullar åt höger i tabellen. Se Kolumninställningar.
- Åtgärdade ett problem med kombinationsdiagram: Löste feljustering mellan x-axisetiketter och staplar när ett tidsmässigt fält används på x-axeln.
Februari 2025
Databricks SQL version 2025.10 är nu tillgänglig
den 21 februari 2025
Databricks SQL version 2025.10 är nu tillgänglig i kanalen Preview. Läs följande avsnitt om du vill veta mer om nya funktioner, beteendeändringar och felkorrigeringar.
I Deltadelning är tabellhistorik aktiverad som standard
Andelar som skapats med SQL-kommandot ALTER SHARE <share> ADD TABLE <table> har nu historikdelning (WITH HISTORY) aktiverade som standard. Se ALTER SHARE.
SQL-instruktioner för autentiseringsuppgifter returnerar ett fel vid matchningstypfel.
Med den här versionen returneras ett fel om den typ av autentiseringsuppgifter som anges i sql-instruktionen för hantering av autentiseringsuppgifter inte matchar typen av argumentet för autentiseringsuppgifter och instruktionen inte körs. Till exempel, för utsagan DROP STORAGE CREDENTIAL 'credential-name', om credential-name inte är en lagringsautentiseringsuppgift, misslyckas uttalandet med ett fel.
Den här ändringen görs för att förhindra användarfel. Tidigare kördes dessa uttryck framgångsrikt även om en referens som inte matchade den angivna autentiseringstypen skickades. För exempel, följande uttalande skulle framgångsrikt ta bort storage-credential: DROP SERVICE CREDENTIAL storage-credential.
Den här ändringen påverkar följande uttalanden:
- DROP CREDENTIAL
- ALTER CREDENTIAL
- DESCRIBE CREDENTIAL
- GRANT... PÅ... AUTENTISERING
- REVOKE... PÅ... AUTENTISERING
- SHOW GRANTS ANGÅENDE... REFERENSER
Använd timestampdiff & timestampadd i genererade kolumnuttryck
Delta Lake-genererade kolumnuttryck stöder nu timestampdiff och timestampadd funktioner.
Stöd för SQL-pipelinesyntax
Nu kan du skapa SQL-pipelines. En SQL-pipeline strukturerar en standardfråga, till exempel SELECT c2 FROM T WHERE c1 = 5, i en stegvis sekvens, enligt följande exempel:
FROM T
|> SELECT c2
|> WHERE c1 = 5
Mer information om syntaxen som stöds för SQL-pipelines finns i SQL Pipeline Syntax.
Bakgrund om det här branschöverskridande tillägget finns i SQL Har problem. Vi kan åtgärda dem: Pipe Syntax in SQL (by Google Research).
Gör HTTP-begäran med hjälp av funktionen http_request
Nu kan du skapa HTTP-anslutningar och via dem göra HTTP-begäranden med hjälp av funktionen http_request.
Uppdatera till DESCRIBE TABLE returnerar metadata som strukturerad JSON
Du kan nu använda kommandot DESCRIBE TABLE AS JSON för att returnera tabellmetadata som ett JSON-dokument. JSON-utdata är mer strukturerade än standardrapporten som kan läsas av människor och kan användas för att tolka en tabells schema programmatiskt. Mer information finns i DESCRIBE TABLE AS JSON-.
Avslutande tomma okänsliga sorteringar
Stöd har lagts till för efterföljande blankstegskänsliga sorteringsordningar. Dessa sorteringar behandlar till exempel 'Hello' och 'Hello ' som lika. Mer information finns i RTRIM-sortering.
Förbättrad inkrementell klonbearbetning
Den här versionen innehåller en lösning på ett extremfall där en inkrementell CLONE kan kopiera filer som redan kopierats från en källtabell till en måltabell. Se Kopiera en tabell på Azure Databricks.
Uppdateringar av användargränssnittet
13 februari 2025
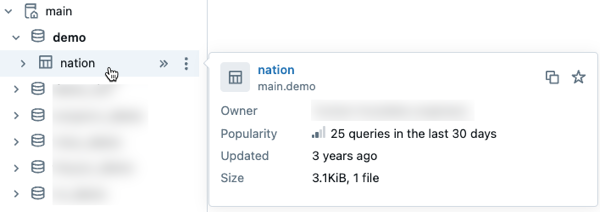
- Förhandsgranska Unity Catalog-metadata vid dataidentifiering: Förhandsgranska metadata för Unity Catalog-tillgångar genom att hålla muspekaren över en tillgång i schemabläddraren. Den här funktionen är tillgänglig i Catalog Explorer och andra gränssnitt där du använder schemawebbläsaren, till exempel AI/BI-instrumentpaneler och SQL-redigeraren.
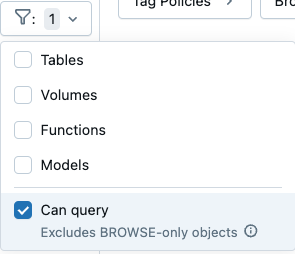
- Filtrera för att hitta datatillgångar som du kan fråga: Filterinställningar i Katalogutforskarens schemawebbläsare innehåller nu kryssrutan Kan fråga . Om du väljer det här alternativet undantas objekt som du kan visa men inte fråga efter.
Januari 2025
Uppdateringar av användargränssnittet
30 januari 2025
Slutfört frågeräkningsdiagram för SQL-lager (offentlig förhandsversion): Ett nytt diagram över antal slutförda frågor är nu tillgängligt i SQL Warehouse-övervakningsgränssnittet. Det här diagrammet visar antalet frågor som har slutförts i ett tidsfönster, inklusive avbrutna och misslyckade frågor. Diagrammet kan användas med de andra diagrammen och tabellen Frågehistorik för att utvärdera och felsöka informationslagrets prestanda. Förfrågan allokeras i tidsfönstret när den är slutförd. Antal räknas i genomsnitt per minut. Mer information finns i Övervaka ett SQL-lager.
Utökad datavisning i SQL-redigeringsdiagram: Visualiseringar som skapats i SQL-redigeraren stöder nu upp till 15 000 rader data.
Databricks SQL version 2024.50 är nu tillgänglig
23 januari 2025
Databricks SQL version 2024.50 är nu tillgänglig i förhandsgranskningskanalen . Läs följande avsnitt om du vill veta mer om nya funktioner, beteendeändringar och felkorrigeringar.
Den VARIANT datatypen kan inte längre användas med åtgärder som kräver jämförelser
Du kan inte använda följande satser eller operatorer i frågor som innehåller en VARIANT datatyp:
DISTINCTINTERSECTEXCEPTUNIONDISTRIBUTE BY
Dessa åtgärder utför jämförelser och jämförelser som använder datatypen VARIANT ger odefinierade resultat och stöds inte i Databricks. Om du använder VARIANT-typen i dina Azure Databricks arbetsbelastningar eller tabeller rekommenderar Databricks följande ändringar:
- Uppdatera frågor eller uttryck för att uttryckligen omvandla
VARIANTvärden till icke-VARIANTdatatyper. - Om du har fält som måste användas med någon av ovanstående åtgärder extraherar du dessa fält från
VARIANTdatatypen och lagrar dem med hjälp av icke-VARIANTdatatyper.
För mer information, se Frågevariantdata.
Stöd för parameterisering av USE CATALOG with IDENTIFIER-satsen
IDENTIFIER-satsen stöds för USE CATALOG-uttrycket. Med det här stödet kan du parameterisera den aktuella katalogen baserat på en strängvariabel eller parametermarkör.
COMMENT ON COLUMN stöd för tabeller och vyer
Instruktionen COMMENT ON har stöd för att ändra kommentarer för vy- och tabellkolumner.
Nya SQL-funktioner
Följande nya inbyggda SQL-funktioner är tillgängliga:
- dayname(expr) returnerar den engelska förkortningen med tre bokstäver för veckodagen för det angivna datumet.
- uniform(expr1, expr2 [,seed]) returnerar ett slumpmässigt värde med oberoende och identiskt distribuerade värden inom det angivna intervallet med tal.
-
randstr(längd) returnerar en slumpmässig sträng med
lengthalfanumeriska tecken.
Namngivna parameteranrop för fler funktioner
Följande funktioner stöder anrop med namngivna parametrar :
Kapslade typer accepterar nu null-begränsningar korrekt
Den här versionen åtgärdar en bugg som påverkar vissa Delta-genererade kolumner av kapslade typer, till exempel STRUCT. Dessa kolumner avvisar ibland felaktigt uttryck baserat på NULL eller NOT NULL begränsningar för kapslade fält. Detta har åtgärdats.
Uppdateringar av användargränssnittet för SQL-redigeraren
15 januari 2025
Den nya SQL-redigeraren (offentlig förhandsversion) innehåller följande förbättringar av användargränssnittet:
- Förbättrad nedladdningsupplevelse: Frågeutdata namnges automatiskt efter frågan när de laddas ned.
-
Keyboard-genvägar för teckenstorlek: Använd
Alt +ochAlt -(Windows/Linux) ellerOpt +ochOpt -(macOS) för att snabbt justera teckenstorleken i SQL-redigeraren. -
Användaromnämnanden i kommentarer: Tagga specifika användare med
@i kommentarer för att skicka e-postaviseringar till dem. - Snabbare fliknavigering: Flikväxlingen är nu upp till 80% snabbare för inlästa flikar och 62% snabbare för borttagna flikar.
- Förenklat lagerval: Information om SQL Warehouse-storlek visas direkt i beräkningsväljaren för enklare val.
-
Parameter-genvägar: Använd
Ctrl + Enter(Windows/Linux) ellerCmd + Enter(macOS) för att köra frågor när du redigerar parametervärden. - Förbättrad versionskontroll: Frågeresultat bevaras i versionshistoriken för bättre samarbete.
Uppdateringar av diagramvisualisering
15 januari 2025
Det nya diagramsystemet med bättre prestanda, förbättrade färgscheman och snabbare interaktivitet är nu allmänt tillgängligt. Se Visualiseringar i databricks notebook-filer och SQL-redigerare och visualiseringstyper för notebook- och SQL-redigerare.