Konfigurera AutoML för att träna en prognosmodell för tidsserier med SDK och CLI
GÄLLER FÖR: Azure CLI ml extension v2 (current)Python SDK azure-ai-ml v2 (aktuell)
Azure CLI ml extension v2 (current)Python SDK azure-ai-ml v2 (aktuell)
I den här artikeln får du lära dig hur du konfigurerar AutoML för tidsserieprognoser med Azure Mašinsko učenje automatiserad ML i Azure Mašinsko učenje Python SDK.
Det gör du på följande sätt:
- Förbereda data för träning.
- Konfigurera specifika tidsserieparametrar i ett prognostiseringsjobb.
- Samordna träning, slutsatsdragning och modellutvärdering med hjälp av komponenter och pipelines.
En låg kodupplevelse finns i Självstudie: Prognostisera efterfrågan med automatiserad maskininlärning för ett prognostiseringsexempel för tidsserier med automatiserad ML i Azure Mašinsko učenje Studio.
AutoML använder standardmaskininlärningsmodeller tillsammans med välkända tidsseriemodeller för att skapa prognoser. Vår metod innehåller historisk information om målvariabeln, funktioner som tillhandahålls av användaren i indata och automatiskt utformade funktioner. Modellsökningsalgoritmer arbetar sedan med att hitta en modell med bästa förutsägelsenoggrannhet. Mer information finns i våra artiklar om prognostiseringsmetodik och modellsökning.
Förutsättningar
För den här artikeln behöver du
En Azure Machine Learning-arbetsyta. Information om hur du skapar arbetsytan finns i Skapa arbetsyteresurser.
Möjligheten att starta AutoML-träningsjobb. Följ guiden för att konfigurera AutoML för mer information.
Tränings- och valideringsdata
Indata för AutoML-prognostisering måste innehålla giltiga tidsserier i tabellformat. Varje variabel måste ha en egen motsvarande kolumn i datatabellen. AutoML kräver minst två kolumner: en tidskolumn som representerar tidsaxeln och målkolumnen som är den kvantitet som ska prognostiseras. Andra kolumner kan fungera som prediktorer. Mer information finns i hur AutoML använder dina data.
Viktigt!
När du tränar en modell för att prognostisera framtida värden ska du se till att alla funktioner som används i träning kan användas när du kör förutsägelser för din avsedda horisont.
Till exempel kan en funktion för aktuell aktiekurs kraftigt öka träningsnoggrannheten. Men om du tänker prognostisera med en lång horisont kanske du inte kan förutsäga framtida aktievärden som motsvarar framtida tidsseriepunkter, och modellnoggrannheten kan bli lidande.
AutoML-prognosjobb kräver att dina träningsdata representeras som ett MLTable-objekt . En MLTable anger en datakälla och steg för att läsa in data. Mer information och användningsfall finns i instruktionsguiden för MLTable. Som ett enkelt exempel antar vi att dina träningsdata finns i en CSV-fil i en lokal katalog, ./train_data/timeseries_train.csv.
Du kan skapa en MLTable med hjälp av mltable Python SDK som i följande exempel:
import mltable
paths = [
{'file': './train_data/timeseries_train.csv'}
]
train_table = mltable.from_delimited_files(paths)
train_table.save('./train_data')
Den här koden skapar en ny fil, ./train_data/MLTable, som innehåller filformatet och inläsningsinstruktionerna.
Nu definierar du ett indataobjekt som krävs för att starta ett träningsjobb med hjälp av Azure Mašinsko učenje Python SDK enligt följande:
from azure.ai.ml.constants import AssetTypes
from azure.ai.ml import Input
# Training MLTable defined locally, with local data to be uploaded
my_training_data_input = Input(
type=AssetTypes.MLTABLE, path="./train_data"
)
Du anger valideringsdata på ett liknande sätt genom att skapa en MLTable och ange indata för valideringsdata. Om du inte anger valideringsdata skapar AutoML automatiskt korsvalideringsdelningar från dina träningsdata som ska användas för modellval. Mer information finns i vår artikel om val av prognosmodell. Mer information om hur mycket träningsdata du behöver för att träna en prognosmodell finns i kraven på datalängd för träning.
Läs mer om hur AutoML tillämpar korsvalidering för att förhindra överanpassning.
Beräkning för att köra experiment
AutoML använder Azure Mašinsko učenje Compute, som är en fullständigt hanterad beräkningsresurs, för att köra träningsjobbet. I följande exempel skapas ett beräkningskluster med namnet cpu-compute :
from azure.ai.ml.entities import AmlCompute
# specify aml compute name.
cpu_compute_target = "cpu-cluster"
try:
ml_client.compute.get(cpu_compute_target)
except Exception:
print("Creating a new cpu compute target...")
compute = AmlCompute(
name=cpu_compute_target, size="STANDARD_D2_V2", min_instances=0, max_instances=4
)
ml_client.compute.begin_create_or_update(compute).result()Konfigurera experiment
Du använder automl-fabriksfunktionerna för att konfigurera prognostiseringsjobb i Python SDK. I följande exempel visas hur du skapar ett prognostiseringsjobb genom att ange det primära måttet och ange gränser för träningskörningen:
from azure.ai.ml import automl
# note that the below is a code snippet -- you might have to modify the variable values to run it successfully
forecasting_job = automl.forecasting(
compute="cpu-compute",
experiment_name="sdk-v2-automl-forecasting-job",
training_data=my_training_data_input,
target_column_name=target_column_name,
primary_metric="normalized_root_mean_squared_error",
n_cross_validations="auto",
)
# Limits are all optional
forecasting_job.set_limits(
timeout_minutes=120,
trial_timeout_minutes=30,
max_concurrent_trials=4,
)
Inställningar för prognostiseringsjobb
Prognostiseringsaktiviteter har många inställningar som är specifika för prognostisering. Den mest grundläggande av dessa inställningar är namnet på tidskolumnen i träningsdata och prognoshorisonten.
Använd metoderna ForecastingJob för att konfigurera de här inställningarna:
# Forecasting specific configuration
forecasting_job.set_forecast_settings(
time_column_name=time_column_name,
forecast_horizon=24
)
Tidskolumnnamnet är en obligatorisk inställning och du bör vanligtvis ange prognoshorisonten enligt ditt förutsägelsescenario. Om dina data innehåller flera tidsserier kan du ange namnen på tidsserie-ID-kolumnerna. Dessa kolumner, när de grupperas, definierar de enskilda serierna. Anta till exempel att du har data som består av försäljning per timme från olika butiker och varumärken. Följande exempel visar hur du anger kolumner för tidsserie-ID förutsatt att data innehåller kolumner med namnet "store" och "brand":
# Forecasting specific configuration
# Add time series IDs for store and brand
forecasting_job.set_forecast_settings(
..., # other settings
time_series_id_column_names=['store', 'brand']
)
AutoML försöker automatiskt identifiera tidsserie-ID-kolumner i dina data om inga anges.
Andra inställningar är valfria och granskas i nästa avsnitt.
Valfria inställningar för prognostiseringsjobb
Valfria konfigurationer är tillgängliga för prognostiseringsuppgifter, till exempel att aktivera djupinlärning och ange en målsammanfattning för rullande fönster. En fullständig lista över parametrar finns i dokumentationen för prognosreferensen.
Inställningar för modellsökning
Det finns två valfria inställningar som styr modellutrymmet där AutoML söker efter den bästa modellen allowed_training_algorithms och blocked_training_algorithms. Om du vill begränsa sökutrymmet till en viss uppsättning modellklasser använder du parametern allowed_training_algorithms som i följande exempel:
# Only search ExponentialSmoothing and ElasticNet models
forecasting_job.set_training(
allowed_training_algorithms=["ExponentialSmoothing", "ElasticNet"]
)
I det här fallet söker prognosjobbet bara över modellklasserna Exponential Smoothing och Elastic Net. Om du vill ta bort en viss uppsättning modellklasser från sökutrymmet använder du blocked_training_algorithms som i följande exempel:
# Search over all model classes except Prophet
forecasting_job.set_training(
blocked_training_algorithms=["Prophet"]
)
Nu söker jobbet över alla modellklasser utom Prophet. En lista över prognosmodellnamn som godkänns i och finns i allowed_training_algorithms referensdokumentationen för träningsegenskaper.blocked_training_algorithms Antingen, men inte båda, av allowed_training_algorithms och blocked_training_algorithms kan tillämpas på en träningskörning.
Aktivera djupinlärning
AutoML levereras med en anpassad DNN-modell (Deep Neural Network) med namnet TCNForecaster. Den här modellen är ett temporalt convolutional-nätverk, eller TCN, som tillämpar vanliga metoder för avbildningsaktiviteter för tidsseriemodellering. Det vill säga att endimensionella "kausala" faltningar utgör nätverkets stamnät och gör det möjligt för modellen att lära sig komplexa mönster under långa perioder i träningshistoriken. Mer information finns i vår TCNForecaster-artikel.
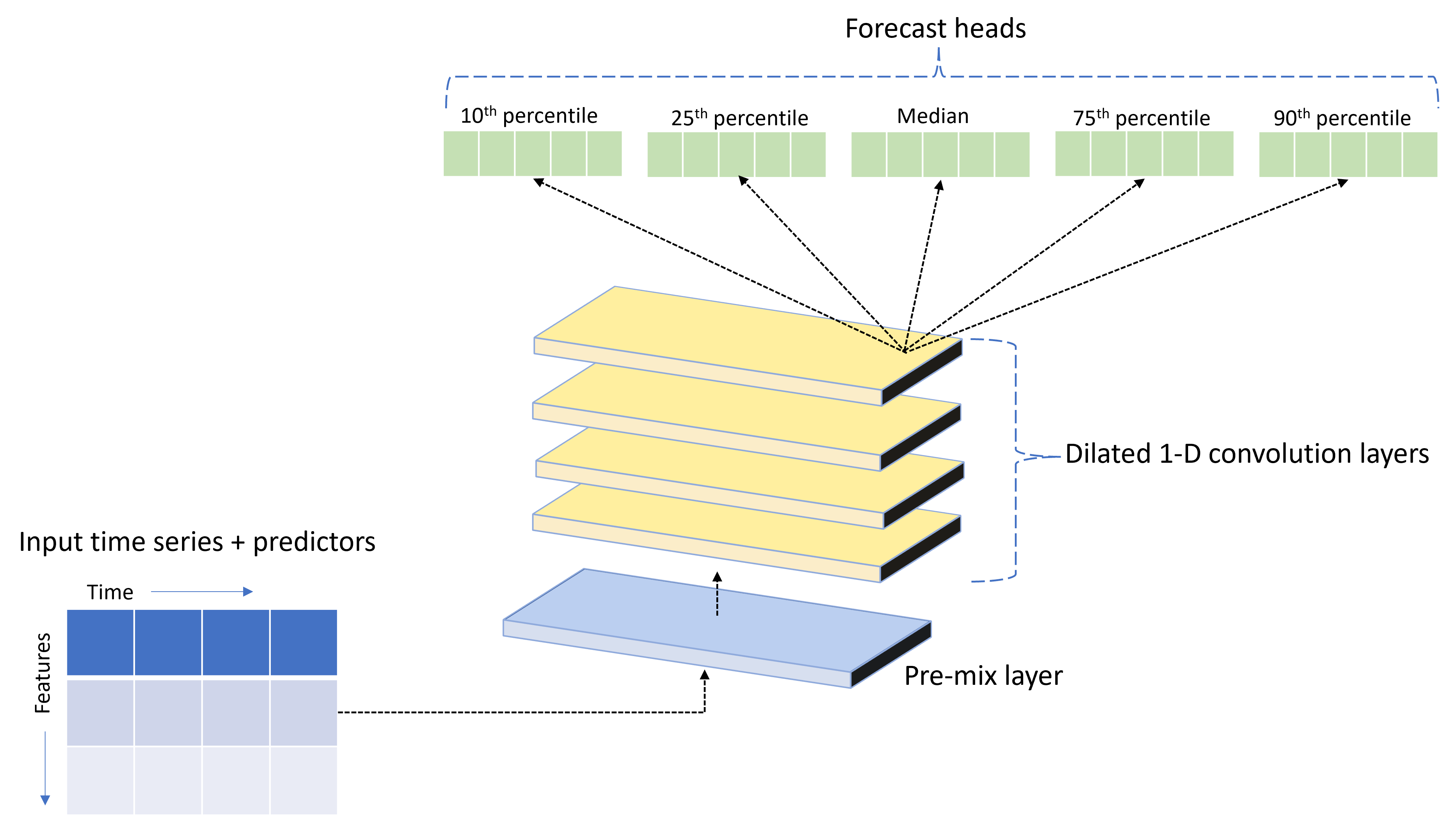
TCNForecaster uppnår ofta högre noggrannhet än standardtidsseriemodeller när det finns tusentals eller fler observationer i träningshistoriken. Men det tar också längre tid att träna och sopa över TCNForecaster-modeller på grund av deras högre kapacitet.
Du kan aktivera TCNForecaster i AutoML genom att ange enable_dnn_training flaggan i träningskonfigurationen på följande sätt:
# Include TCNForecaster models in the model search
forecasting_job.set_training(
enable_dnn_training=True
)
Som standard är TCNForecaster-träning begränsad till en enda beräkningsnod och en enda GPU, om tillgängligt, per modellutvärdering. För stora datascenarier rekommenderar vi att du distribuerar varje TCNForecaster-utvärderingsversion över flera kärnor/GPU:er och noder. Mer information och kodexempel finns i artikeln om distribuerad utbildning .
Information om hur du aktiverar DNN för ett AutoML-experiment som skapats i Azure Mašinsko učenje Studio finns i inställningarna för aktivitetstyp i studiogränssnittet.
Kommentar
- När du aktiverar DNN för experiment som skapats med SDK inaktiveras de bästa modellförklaringarna .
- DNN-stöd för prognostisering i automatiserade Mašinsko učenje stöds inte för körningar som initieras i Databricks.
- GPU-beräkningstyper rekommenderas när DNN-träning är aktiverad
Funktioner för fördröjning och rullande fönster
De senaste värdena för målet är ofta effektfulla funktioner i en prognosmodell. Därför kan AutoML skapa tidsfördröjnings- och rullande fönsteraggregeringsfunktioner för att potentiellt förbättra modellens noggrannhet.
Tänk dig ett scenario för prognostisering av energiefterfrågan där väderdata och historisk efterfrågan är tillgängliga. Tabellen visar resulterande funktionsframställning som inträffar när fönsteraggregering tillämpas under de senaste tre timmarna. Kolumner för minimum, maximum och sum genereras i ett skjutfönster på tre timmar baserat på de definierade inställningarna. För observationen som är giltig den 8 september 2017 04:00 beräknas till exempel de högsta, lägsta och totala värdena med hjälp av efterfrågevärdena för 8 september 2017 01:00–03:00. Det här fönstret med tre timmar skiftar för att fylla i data för de återstående raderna. Mer information och exempel finns i artikeln om fördröjningsfunktionen.

Du kan aktivera aggregeringsfunktioner för fördröjning och rullande fönster för målet genom att ange storleken på rullande fönster, som var tre i föregående exempel, och de fördröjningsbeställningar som du vill skapa. Du kan också aktivera fördröjningar för funktioner med inställningen feature_lags . I följande exempel ställer vi in alla dessa inställningar så auto att AutoML automatiskt fastställer inställningarna genom att analysera korrelationsstrukturen för dina data:
forecasting_job.set_forecast_settings(
..., # other settings
target_lags='auto',
target_rolling_window_size='auto',
feature_lags='auto'
)
Kort seriehantering
Automatiserad ML betraktar en tidsserie som en kort serie om det inte finns tillräckligt med datapunkter för att genomföra tränings- och valideringsfaserna för modellutveckling. Mer information om längdkrav finns i krav på träningsdatalängd.
AutoML har flera åtgärder som kan utföras för korta serier. Dessa åtgärder kan konfigureras med inställningen short_series_handling_config . Standardvärdet är "auto". I följande tabell beskrivs inställningarna:
| Inställning | beskrivning |
|---|---|
auto |
Standardvärdet för kort seriehantering. - Om alla serier är korta kan du fylla på data. - Om inte alla serier är korta släpper du den korta serien. |
pad |
Om short_series_handling_config = padlägger automatiserad ML till slumpmässiga värden till varje kort serie som hittas. Följande listar kolumntyperna och vad de är vadderade med: - Objektkolumner med NaN – Numeriska kolumner med 0 – Booleska/logiska kolumner med false - Målkolumnen är vadderad med vitt brus. |
drop |
Om short_series_handling_config = drop, tar automatiserad ML bort den korta serien och den kommer inte att användas för träning eller förutsägelse. Förutsägelser för dessa serier returnerar NaN:er. |
None |
Ingen serie är vadderad eller tappad |
I följande exempel anger vi kortseriehanteringen så att alla korta serier är vadderade till minsta längd:
forecasting_job.set_forecast_settings(
..., # other settings
short_series_handling_config='pad'
)
Varning
Utfyllnad kan påverka den resulterande modellens noggrannhet, eftersom vi introducerar artificiella data för att undvika träningsfel. Om många av serierna är korta kan du också se en viss inverkan på förklaringsresultaten
Frekvens- och måldataaggregering
Använd alternativen frekvens och dataaggregering för att undvika fel som orsakas av oregelbundna data. Dina data är oregelbundna om de inte följer en angiven takt i tiden, till exempel varje timme eller varje dag. Point-of-sales-data är ett bra exempel på oregelbundna data. I dessa fall kan AutoML aggregera dina data till önskad frekvens och sedan skapa en prognosmodell från aggregeringarna.
Du måste ange frequency inställningarna och target_aggregate_function för att hantera oregelbundna data. Frekvensinställningen accepterar Pandas DateOffset-strängar som indata. Värden som stöds för aggregeringsfunktionen är:
| Function | beskrivning |
|---|---|
sum |
Summan av målvärden |
mean |
Medelvärde eller medelvärde för målvärden |
min |
Minimivärde för ett mål |
max |
Maximalt värde för ett mål |
- Målkolumnvärdena aggregeras enligt den angivna åtgärden. Vanligtvis är summan lämplig för de flesta scenarier.
- Numeriska förutsägelsekolumner i dina data aggregeras med summa, medelvärde, minimivärde och högsta värde. Därför genererar automatiserad ML nya kolumner suffix med sammansättningsfunktionens namn och tillämpar den valda aggregeringsåtgärden.
- För kategoriska förutsägelsekolumner aggregeras data efter läge, den mest framträdande kategorin i fönstret.
- Datumförutsägarkolumner aggregeras efter minsta värde, högsta värde och läge.
I följande exempel anges frekvensen till varje timme och aggregeringsfunktionen till sammanfattning:
# Aggregate the data to hourly frequency
forecasting_job.set_forecast_settings(
..., # other settings
frequency='H',
target_aggregate_function='sum'
)
Anpassade inställningar för korsvalidering
Det finns två anpassningsbara inställningar som styr korsvalidering för prognostiseringsjobb n_cross_validations: antalet vikningar och stegstorleken som definierar tidsförskjutningen mellan vikningar, cv_step_size. Se val av prognosmodell för mer information om innebörden av dessa parametrar. Som standard anger AutoML båda inställningarna automatiskt baserat på dina datas egenskaper, men avancerade användare kanske vill ange dem manuellt. Anta till exempel att du har dagliga försäljningsdata och att du vill att valideringskonfigurationen ska bestå av fem gånger med en sjudagars förskjutning mellan intilliggande veck. Följande kodexempel visar hur du anger följande:
from azure.ai.ml import automl
# Create a job with five CV folds
forecasting_job = automl.forecasting(
..., # other training parameters
n_cross_validations=5,
)
# Set the step size between folds to seven days
forecasting_job.set_forecast_settings(
..., # other settings
cv_step_size=7
)
Anpassad funktionalisering
Som standard utökar AutoML träningsdata med konstruerade funktioner för att öka modellernas noggrannhet. Mer information finns i automatiserad funktionsutveckling . Vissa av förbearbetningsstegen kan anpassas med hjälp av konfigurationen av prognostiseringsjobbet.
Anpassningar som stöds för prognostisering finns i följande tabell:
| Anpassning | beskrivning | Alternativ |
|---|---|---|
| Uppdatering av kolumnsyfte | Åsidosätt den automatiskt identifierade funktionstypen för den angivna kolumnen. | "Kategorisk", "DateTime", "Numerisk" |
| Uppdatering av transformeringsparameter | Uppdatera parametrarna för den angivna imputern. | {"strategy": "constant", "fill_value": <value>}, , {"strategy": "median"}{"strategy": "ffill"} |
Anta till exempel att du har ett scenario för detaljhandelsefterfrågan där data innehåller priser, en "till salu"-flagga och en produkttyp. Följande exempel visar hur du kan ange anpassade typer och imputer för dessa funktioner:
from azure.ai.ml.automl import ColumnTransformer
# Customize imputation methods for price and is_on_sale features
# Median value imputation for price, constant value of zero for is_on_sale
transformer_params = {
"imputer": [
ColumnTransformer(fields=["price"], parameters={"strategy": "median"}),
ColumnTransformer(fields=["is_on_sale"], parameters={"strategy": "constant", "fill_value": 0}),
],
}
# Set the featurization
# Ensure that product_type feature is interpreted as categorical
forecasting_job.set_featurization(
mode="custom",
transformer_params=transformer_params,
column_name_and_types={"product_type": "Categorical"},
)
Om du använder Azure Mašinsko učenje Studio för experimentet kan du läsa om hur du anpassar funktionalisering i studion.
Skicka ett prognostiseringsjobb
När alla inställningar har konfigurerats startar du prognosjobbet på följande sätt:
# Submit the AutoML job
returned_job = ml_client.jobs.create_or_update(
forecasting_job
)
print(f"Created job: {returned_job}")
# Get a URL for the job in the AML studio user interface
returned_job.services["Studio"].endpoint
När jobbet har skickats etablerar AutoML beräkningsresurser, tillämpar funktionalisering och andra förberedelsesteg på indata och börjar sedan sopa över prognosmodeller. Mer information finns i våra artiklar om prognostiseringsmetodik och modellsökning.
Orkestrera utbildning, slutsatsdragning och utvärdering med komponenter och pipelines
Viktigt!
Den här funktionen är för närvarande i allmänt tillgänglig förhandsversion. Den här förhandsversionen tillhandahålls utan ett serviceavtal och vi rekommenderar det inte för produktionsarbetsbelastningar. Vissa funktioner kanske inte stöds eller kan vara begränsade.
Mer information finns i Kompletterande villkor för användning av Microsoft Azure-förhandsversioner.
Ditt ML-arbetsflöde kräver troligen mer än bara träning. Slutsatsdragning eller hämtning av modellförutsägelser på nyare data och utvärdering av modellprecision på en testuppsättning med kända målvärden är andra vanliga uppgifter som du kan orkestrera i AzureML tillsammans med träningsjobb. För att stödja slutsatsdragnings- och utvärderingsuppgifter tillhandahåller AzureML komponenter, som är fristående koddelar som utför ett steg i en AzureML-pipeline.
I följande exempel hämtar vi komponentkod från ett klientregister:
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential, InteractiveBrowserCredential
# Get a credential for access to the AzureML registry
try:
credential = DefaultAzureCredential()
# Check if we can get token successfully.
credential.get_token("https://management.azure.com/.default")
except Exception as ex:
# Fall back to InteractiveBrowserCredential in case DefaultAzureCredential fails
credential = InteractiveBrowserCredential()
# Create a client for accessing assets in the AzureML preview registry
ml_client_registry = MLClient(
credential=credential,
registry_name="azureml-preview"
)
# Create a client for accessing assets in the AzureML preview registry
ml_client_metrics_registry = MLClient(
credential=credential,
registry_name="azureml"
)
# Get an inference component from the registry
inference_component = ml_client_registry.components.get(
name="automl_forecasting_inference",
label="latest"
)
# Get a component for computing evaluation metrics from the registry
compute_metrics_component = ml_client_metrics_registry.components.get(
name="compute_metrics",
label="latest"
)
Därefter definierar vi en fabriksfunktion som skapar pipelines som samordnar träning, slutsatsdragning och måttberäkning. Mer information om träningsinställningar finns i avsnittet träningskonfiguration .
from azure.ai.ml import automl
from azure.ai.ml.constants import AssetTypes
from azure.ai.ml.dsl import pipeline
@pipeline(description="AutoML Forecasting Pipeline")
def forecasting_train_and_evaluate_factory(
train_data_input,
test_data_input,
target_column_name,
time_column_name,
forecast_horizon,
primary_metric='normalized_root_mean_squared_error',
cv_folds='auto'
):
# Configure the training node of the pipeline
training_node = automl.forecasting(
training_data=train_data_input,
target_column_name=target_column_name,
primary_metric=primary_metric,
n_cross_validations=cv_folds,
outputs={"best_model": Output(type=AssetTypes.MLFLOW_MODEL)},
)
training_node.set_forecasting_settings(
time_column_name=time_column_name,
forecast_horizon=max_horizon,
frequency=frequency,
# other settings
...
)
training_node.set_training(
# training parameters
...
)
training_node.set_limits(
# limit settings
...
)
# Configure the inference node to make rolling forecasts on the test set
inference_node = inference_component(
test_data=test_data_input,
model_path=training_node.outputs.best_model,
target_column_name=target_column_name,
forecast_mode='rolling',
forecast_step=1
)
# Configure the metrics calculation node
compute_metrics_node = compute_metrics_component(
task="tabular-forecasting",
ground_truth=inference_node.outputs.inference_output_file,
prediction=inference_node.outputs.inference_output_file,
evaluation_config=inference_node.outputs.evaluation_config_output_file
)
# return a dictionary with the evaluation metrics and the raw test set forecasts
return {
"metrics_result": compute_metrics_node.outputs.evaluation_result,
"rolling_fcst_result": inference_node.outputs.inference_output_file
}
Nu definierar vi tränings- och testdataindata förutsatt att de finns i lokala mappar ./train_data och ./test_data:
my_train_data_input = Input(
type=AssetTypes.MLTABLE,
path="./train_data"
)
my_test_data_input = Input(
type=AssetTypes.URI_FOLDER,
path='./test_data',
)
Slutligen skapar vi pipelinen, anger dess standardberäkning och skickar jobbet:
pipeline_job = forecasting_train_and_evaluate_factory(
my_train_data_input,
my_test_data_input,
target_column_name,
time_column_name,
forecast_horizon
)
# set pipeline level compute
pipeline_job.settings.default_compute = compute_name
# submit the pipeline job
returned_pipeline_job = ml_client.jobs.create_or_update(
pipeline_job,
experiment_name=experiment_name
)
returned_pipeline_job
När den har skickats kör pipelinen AutoML-träning, löpande utvärderingsinferens och måttberäkning i följd. Du kan övervaka och inspektera körningen i studiogränssnittet. När körningen är klar kan de löpande prognoserna och utvärderingsmåtten laddas ned till den lokala arbetskatalogen:
# Download the metrics json
ml_client.jobs.download(returned_pipeline_job.name, download_path=".", output_name='metrics_result')
# Download the rolling forecasts
ml_client.jobs.download(returned_pipeline_job.name, download_path=".", output_name='rolling_fcst_result')
Sedan kan du hitta måttresultaten i ./named-outputs/metrics_results/evaluationResult/metrics.json och prognoserna, i JSON-linjeformat, i ./named-outputs/rolling_fcst_result/inference_output_file.
Mer information om löpande utvärdering finns i vår utvärderingsartikel för prognostiseringsmodellen.
Prognostisering i stor skala: många modeller
Viktigt!
Den här funktionen är för närvarande i allmänt tillgänglig förhandsversion. Den här förhandsversionen tillhandahålls utan ett serviceavtal och vi rekommenderar det inte för produktionsarbetsbelastningar. Vissa funktioner kanske inte stöds eller kan vara begränsade.
Mer information finns i Kompletterande villkor för användning av Microsoft Azure-förhandsversioner.
Med de många modellkomponenterna i AutoML kan du träna och hantera miljontals modeller parallellt. Mer information om många modellbegrepp finns i artikeln om många modeller.
Träningskonfiguration för många modeller
Träningskomponenten för många modeller accepterar en YAML-formatkonfigurationsfil med AutoML-träningsinställningar. Komponenten tillämpar dessa inställningar på varje AutoML-instans som startas. Den här YAML-filen har samma specifikation som prognostiseringsjobbet plus ytterligare parametrar partition_column_names och allow_multi_partitions.
| Parameter | Description |
|---|---|
| partition_column_names | Kolumnnamn i data som, när de grupperas, definierar datapartitionerna. Träningskomponenten många modeller startar ett oberoende träningsjobb på varje partition. |
| allow_multi_partitions | En valfri flagga som tillåter träning av en modell per partition när varje partition innehåller mer än en unik tidsserie. Standardvärdet är False. |
Följande exempel innehåller en konfigurationsmall:
$schema: https://azuremlsdk2.blob.core.windows.net/preview/0.0.1/autoMLJob.schema.json
type: automl
description: A time series forecasting job config
compute: azureml:<cluster-name>
task: forecasting
primary_metric: normalized_root_mean_squared_error
target_column_name: sales
n_cross_validations: 3
forecasting:
time_column_name: date
time_series_id_column_names: ["state", "store"]
forecast_horizon: 28
training:
blocked_training_algorithms: ["ExtremeRandomTrees"]
limits:
timeout_minutes: 15
max_trials: 10
max_concurrent_trials: 4
max_cores_per_trial: -1
trial_timeout_minutes: 15
enable_early_termination: true
partition_column_names: ["state", "store"]
allow_multi_partitions: false
I efterföljande exempel antar vi att konfigurationen lagras på sökvägen, ./automl_settings_mm.yml.
Pipeline för många modeller
Därefter definierar vi en fabriksfunktion som skapar pipelines för orkestrering av många modellers träning, slutsatsdragning och måttberäkning. Parametrarna för den här fabriksfunktionen beskrivs i följande tabell:
| Parameter | Description |
|---|---|
| max_nodes | Antal beräkningsnoder som ska användas i träningsjobbet |
| max_concurrency_per_node | Antal AutoML-processer som ska köras på varje nod. Därför är max_nodes * max_concurrency_per_nodeden totala samtidigheten för många modelljobb . |
| parallel_step_timeout_in_seconds | Tidsgränsen för många modellers komponent anges i antal sekunder. |
| retrain_failed_models | Flagga för att aktivera omträning för misslyckade modeller. Detta är användbart om du har gjort tidigare många modellkörningar som resulterade i misslyckade AutoML-jobb på vissa datapartitioner. När den här flaggan är aktiverad startar många modeller endast träningsjobb för tidigare misslyckade partitioner. |
| forecast_mode | Slutsatsdragningsläge för modellutvärdering. Giltiga värden är "recursive" och "rolling". Mer information finns i artikeln om modellutvärdering. |
| forecast_step | Stegstorlek för rullande prognos. Mer information finns i artikeln om modellutvärdering. |
Följande exempel illustrerar en fabriksmetod för att konstruera många modellers tränings- och modellutvärderingspipelines:
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential, InteractiveBrowserCredential
# Get a credential for access to the AzureML registry
try:
credential = DefaultAzureCredential()
# Check if we can get token successfully.
credential.get_token("https://management.azure.com/.default")
except Exception as ex:
# Fall back to InteractiveBrowserCredential in case DefaultAzureCredential fails
credential = InteractiveBrowserCredential()
# Get a many models training component
mm_train_component = ml_client_registry.components.get(
name='automl_many_models_training',
version='latest'
)
# Get a many models inference component
mm_inference_component = ml_client_registry.components.get(
name='automl_many_models_inference',
version='latest'
)
# Get a component for computing evaluation metrics
compute_metrics_component = ml_client_metrics_registry.components.get(
name="compute_metrics",
label="latest"
)
@pipeline(description="AutoML Many Models Forecasting Pipeline")
def many_models_train_evaluate_factory(
train_data_input,
test_data_input,
automl_config_input,
compute_name,
max_concurrency_per_node=4,
parallel_step_timeout_in_seconds=3700,
max_nodes=4,
retrain_failed_model=False,
forecast_mode="rolling",
forecast_step=1
):
mm_train_node = mm_train_component(
raw_data=train_data_input,
automl_config=automl_config_input,
max_nodes=max_nodes,
max_concurrency_per_node=max_concurrency_per_node,
parallel_step_timeout_in_seconds=parallel_step_timeout_in_seconds,
retrain_failed_model=retrain_failed_model,
compute_name=compute_name
)
mm_inference_node = mm_inference_component(
raw_data=test_data_input,
max_nodes=max_nodes,
max_concurrency_per_node=max_concurrency_per_node,
parallel_step_timeout_in_seconds=parallel_step_timeout_in_seconds,
optional_train_metadata=mm_train_node.outputs.run_output,
forecast_mode=forecast_mode,
forecast_step=forecast_step,
compute_name=compute_name
)
compute_metrics_node = compute_metrics_component(
task="tabular-forecasting",
prediction=mm_inference_node.outputs.evaluation_data,
ground_truth=mm_inference_node.outputs.evaluation_data,
evaluation_config=mm_inference_node.outputs.evaluation_configs
)
# Return the metrics results from the rolling evaluation
return {
"metrics_result": compute_metrics_node.outputs.evaluation_result
}
Nu skapar vi pipelinen via fabriksfunktionen, förutsatt att tränings- och testdata finns i lokala mappar ./data/train respektive ./data/test. Slutligen anger vi standardberäkningen och skickar jobbet som i följande exempel:
pipeline_job = many_models_train_evaluate_factory(
train_data_input=Input(
type="uri_folder",
path="./data/train"
),
test_data_input=Input(
type="uri_folder",
path="./data/test"
),
automl_config=Input(
type="uri_file",
path="./automl_settings_mm.yml"
),
compute_name="<cluster name>"
)
pipeline_job.settings.default_compute = "<cluster name>"
returned_pipeline_job = ml_client.jobs.create_or_update(
pipeline_job,
experiment_name=experiment_name,
)
ml_client.jobs.stream(returned_pipeline_job.name)
När jobbet är klart kan utvärderingsmåtten laddas ned lokalt med samma procedur som i pipelinen för en träningskörning.
Se även efterfrågeprognoser med många modeller notebook-fil för ett mer detaljerat exempel.
Kommentar
De många modellernas tränings- och slutsatsdragningskomponenter partitioneras villkorligt dina data enligt partition_column_names inställningen så att varje partition finns i en egen fil. Den här processen kan vara mycket långsam eller misslyckas när data är mycket stora. I det här fallet rekommenderar vi att du partitionerar dina data manuellt innan du kör många modellers träning eller slutsatsdragning.
Prognostisering i stor skala: hierarkisk tidsserie
Viktigt!
Den här funktionen är för närvarande i allmänt tillgänglig förhandsversion. Den här förhandsversionen tillhandahålls utan ett serviceavtal och vi rekommenderar det inte för produktionsarbetsbelastningar. Vissa funktioner kanske inte stöds eller kan vara begränsade.
Mer information finns i Kompletterande villkor för användning av Microsoft Azure-förhandsversioner.
Med HTS-komponenter (hierarkisk tidsserie) i AutoML kan du träna ett stort antal modeller på data med hierarkisk struktur. Mer information finns i artikeln om HTS.
HTS-träningskonfiguration
HTS-träningskomponenten accepterar en YAML-formatkonfigurationsfil med AutoML-träningsinställningar. Komponenten tillämpar dessa inställningar på varje AutoML-instans som startas. Den här YAML-filen har samma specifikation som prognostiseringsjobbet plus ytterligare parametrar relaterade till hierarkiinformationen:
| Parameter | Description |
|---|---|
| hierarchy_column_names | En lista med kolumnnamn i data som definierar datans hierarkiska struktur. Ordningen på kolumnerna i den här listan bestämmer hierarkinivåerna. aggregeringsgraden minskar med listindexet. Den sista kolumnen i listan definierar alltså lövnivån (den mest disaggregerade) i hierarkin. |
| hierarchy_training_level | Hierarkinivån som ska användas för träning av prognosmodeller. |
Följande visar en exempelkonfiguration:
$schema: https://azuremlsdk2.blob.core.windows.net/preview/0.0.1/autoMLJob.schema.json
type: automl
description: A time series forecasting job config
compute: azureml:cluster-name
task: forecasting
primary_metric: normalized_root_mean_squared_error
log_verbosity: info
target_column_name: sales
n_cross_validations: 3
forecasting:
time_column_name: "date"
time_series_id_column_names: ["state", "store", "SKU"]
forecast_horizon: 28
training:
blocked_training_algorithms: ["ExtremeRandomTrees"]
limits:
timeout_minutes: 15
max_trials: 10
max_concurrent_trials: 4
max_cores_per_trial: -1
trial_timeout_minutes: 15
enable_early_termination: true
hierarchy_column_names: ["state", "store", "SKU"]
hierarchy_training_level: "store"
I efterföljande exempel antar vi att konfigurationen lagras på sökvägen, ./automl_settings_hts.yml.
HTS-pipeline
Därefter definierar vi en fabriksfunktion som skapar pipelines för orkestrering av HTS-utbildning, slutsatsdragning och måttberäkning. Parametrarna för den här fabriksfunktionen beskrivs i följande tabell:
| Parameter | Description |
|---|---|
| forecast_level | Nivån på hierarkin för att hämta prognoser för |
| allocation_method | Allokeringsmetod som ska användas när prognoser delas upp. Giltiga värden är "proportions_of_historical_average" och "average_historical_proportions". |
| max_nodes | Antal beräkningsnoder som ska användas i träningsjobbet |
| max_concurrency_per_node | Antal AutoML-processer som ska köras på varje nod. Därför är max_nodes * max_concurrency_per_nodeden totala samtidigheten för ett HTS-jobb . |
| parallel_step_timeout_in_seconds | Tidsgränsen för många modellers komponent anges i antal sekunder. |
| forecast_mode | Slutsatsdragningsläge för modellutvärdering. Giltiga värden är "recursive" och "rolling". Mer information finns i artikeln om modellutvärdering. |
| forecast_step | Stegstorlek för rullande prognos. Mer information finns i artikeln om modellutvärdering. |
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential, InteractiveBrowserCredential
# Get a credential for access to the AzureML registry
try:
credential = DefaultAzureCredential()
# Check if we can get token successfully.
credential.get_token("https://management.azure.com/.default")
except Exception as ex:
# Fall back to InteractiveBrowserCredential in case DefaultAzureCredential fails
credential = InteractiveBrowserCredential()
# Get a HTS training component
hts_train_component = ml_client_registry.components.get(
name='automl_hts_training',
version='latest'
)
# Get a HTS inference component
hts_inference_component = ml_client_registry.components.get(
name='automl_hts_inference',
version='latest'
)
# Get a component for computing evaluation metrics
compute_metrics_component = ml_client_metrics_registry.components.get(
name="compute_metrics",
label="latest"
)
@pipeline(description="AutoML HTS Forecasting Pipeline")
def hts_train_evaluate_factory(
train_data_input,
test_data_input,
automl_config_input,
max_concurrency_per_node=4,
parallel_step_timeout_in_seconds=3700,
max_nodes=4,
forecast_mode="rolling",
forecast_step=1,
forecast_level="SKU",
allocation_method='proportions_of_historical_average'
):
hts_train = hts_train_component(
raw_data=train_data_input,
automl_config=automl_config_input,
max_concurrency_per_node=max_concurrency_per_node,
parallel_step_timeout_in_seconds=parallel_step_timeout_in_seconds,
max_nodes=max_nodes
)
hts_inference = hts_inference_component(
raw_data=test_data_input,
max_nodes=max_nodes,
max_concurrency_per_node=max_concurrency_per_node,
parallel_step_timeout_in_seconds=parallel_step_timeout_in_seconds,
optional_train_metadata=hts_train.outputs.run_output,
forecast_level=forecast_level,
allocation_method=allocation_method,
forecast_mode=forecast_mode,
forecast_step=forecast_step
)
compute_metrics_node = compute_metrics_component(
task="tabular-forecasting",
prediction=hts_inference.outputs.evaluation_data,
ground_truth=hts_inference.outputs.evaluation_data,
evaluation_config=hts_inference.outputs.evaluation_configs
)
# Return the metrics results from the rolling evaluation
return {
"metrics_result": compute_metrics_node.outputs.evaluation_result
}
Nu skapar vi pipelinen via fabriksfunktionen, förutsatt att tränings- och testdata finns i lokala mappar ./data/train respektive ./data/test. Slutligen anger vi standardberäkningen och skickar jobbet som i följande exempel:
pipeline_job = hts_train_evaluate_factory(
train_data_input=Input(
type="uri_folder",
path="./data/train"
),
test_data_input=Input(
type="uri_folder",
path="./data/test"
),
automl_config=Input(
type="uri_file",
path="./automl_settings_hts.yml"
)
)
pipeline_job.settings.default_compute = "cluster-name"
returned_pipeline_job = ml_client.jobs.create_or_update(
pipeline_job,
experiment_name=experiment_name,
)
ml_client.jobs.stream(returned_pipeline_job.name)
När jobbet är klart kan utvärderingsmåtten laddas ned lokalt med samma procedur som i pipelinen för en träningskörning.
Se även efterfrågeprognoser med notebook-filen för hierarkisk tidsserie för ett mer detaljerat exempel.
Kommentar
HTS-tränings- och slutsatsdragningskomponenterna partitioneras villkorligt dina data enligt hierarchy_column_names inställningen så att varje partition finns i en egen fil. Den här processen kan vara mycket långsam eller misslyckas när data är mycket stora. I det här fallet rekommenderar vi att du partitionerar dina data manuellt innan du kör HTS-träning eller slutsatsdragning.
Prognostisering i stor skala: distribuerad DNN-utbildning
- Mer information om hur distribuerad utbildning fungerar för prognostiseringsuppgifter finns i vår artikel om prognostisering i stor skala.
- Se avsnittet om distribuerad konfigurationsträning för tabelldata för kodexempel.
Exempelnotebook-filer
Notebook-filerna med prognosexempel innehåller detaljerade kodexempel för avancerad konfiguration av prognostisering, inklusive:
- Exempel på pipeline för efterfrågeprognoser
- Djupinlärningsmodeller
- Funktionalisering och identifiering av helgdagar
- Manuell konfiguration för fördröjningar och sammansättningsfunktioner för rullande fönster
Nästa steg
- Läs mer om hur du distribuerar en AutoML-modell till en onlineslutpunkt.
- Lär dig mer om tolkning: modellförklaringar i automatiserad maskininlärning (förhandsversion).
- Lär dig mer om hur AutoML bygger prognosmodeller.
- Lär dig mer om prognostisering i stor skala.
- Lär dig hur du konfigurerar AutoML för olika prognostiseringsscenarier.
- Lär dig mer om slutsatsdragning och utvärdering av prognosmodeller.
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för