Anteckning
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Det kan vara svårt att hitta olika innehållstyper som lagras i Azure Blob Storage, men Azure AI Search ger djup integrering i innehållsskiktet, extraherar och härleder textinformation, som sedan kan efterfrågas i ett sökindex.
I den här artikeln granskar du det grundläggande arbetsflödet för att extrahera innehåll och metadata från blobar och skicka det till ett sökindex i Azure AI Search. Det resulterande indexet kan efterfrågas med fulltextsökning eller vektorsökning. Du kan också skicka bearbetat blobinnehåll till ett kunskapslager för scenarier som inte är sökscenarier.
Kommentar
Känner du redan till arbetsflödet och kompositionen? Konfigurera en blobindexerare är nästa steg.
Vad det innebär att lägga till sökning över blobdata
Azure AI Search är en fristående söktjänst som stöder indexering och frågearbetsbelastningar över användardefinierade index som innehåller ditt privata sökbara innehåll i molnet. Det är nödvändigt att samplacera ditt sökbara innehåll med frågemotorn i molnet för prestanda, vilket ger resultat med en hastighet som användarna har kommit att förvänta sig av sökfrågor.
Azure AI Search integreras med Azure Blob Storage på indexeringsskiktet och importerar blobinnehållet som sökdokument som indexeras till inverterade index och andra frågestrukturer som stöder textfrågor i fritt format, vektorfrågor och filteruttryck. Eftersom blobinnehållet indexeras till ett sökindex kan du använda det fullständiga utbudet av frågefunktioner i Azure AI Search för att hitta information i blobinnehållet.
Indata är dina blobar i en enda container i Azure Blob Storage. Blobbar kan vara nästan alla typer av textdata. Om dina blobar innehåller bilder kan du lägga till AI-berikning för att skapa och extrahera text och funktioner från bilder.
Utdata är alltid ett Azure AI Search-index som används för snabb textsökning, hämtning och utforskning i klientprogram. Däremellan finns själva indexeringspipelinearkitekturen. Pipelinen baseras på indexerarens funktion, som beskrivs närmare i den här artikeln.
När indexet har skapats och fyllts i finns det oberoende av din blobcontainer, men du kan köra indexeringsåtgärder igen för att uppdatera indexet baserat på ändrade dokument. Tidsstämpelinformation om enskilda blobar används för ändringsidentifiering. Du kan välja antingen schemalagd körning eller indexering på begäran som uppdateringsmekanism.
Resurser som används i en blobsökningslösning
Du behöver Azure AI Search, Azure Blob Storage och en klient. Azure AI Search är vanligtvis en av flera komponenter i en lösning, där din programkod utfärdar frågor mot API-begäranden och hanterar svaret. Du kan också skriva programkod för att hantera indexering, men för test av konceptbevis och improviserade uppgifter är det vanligt att använda Azure Portal som sökklient.
I Blob Storage behöver du en container som tillhandahåller källinnehåll. Du kan ange kriterier för filinkludering och undantag och ange vilka delar av en blob som indexeras i Azure AI Search.
Du kan börja direkt på portalsidan för lagringskontot.
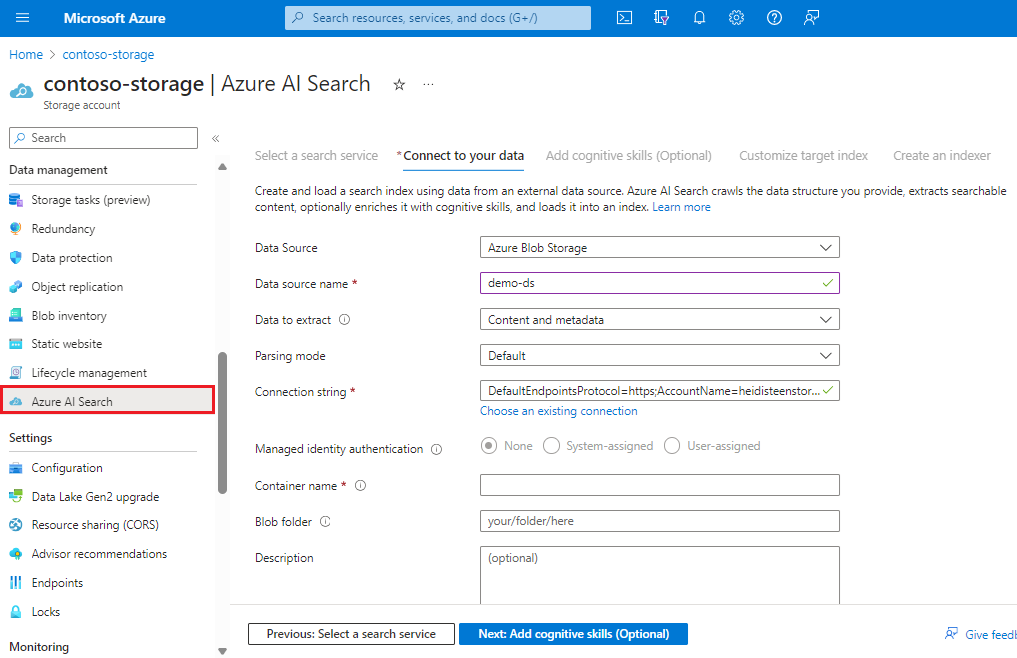
På den vänstra navigeringssidan under Datahantering väljer du Azure AI Search för att välja eller skapa en söktjänst.
Följ stegen i guiden för att extrahera och eventuellt skapa sökbart innehåll från dina blobar. Arbetsflödet är guiden Importera data. Arbetsflödet skapar en indexerare, datakälla, index och alternativ för din Azure AI-tjänsten Search.
Använd Sökutforskaren på sökportalsidan för att fråga efter ditt innehåll.
Guiden är det bästa stället att börja på, men du kommer att upptäcka mer flexibla alternativ när du konfigurerar en blobindexerare själv. Du kan använda en REST-klient. Självstudie: Indexera och söka efter halvstrukturerade data (JSON-blobar) vägleder dig genom stegen för att anropa REST-API:et.
Så här indexeras blobar
Som standard indexeras de flesta blobar som ett enda sökdokument i indexet, inklusive blobar med strukturerat innehåll, till exempel JSON eller CSV, som indexeras som ett enda textsegment. För JSON- eller CSV-dokument som har en intern struktur (avgränsare) kan du dock tilldela parsningslägen för att generera enskilda sökdokument för varje rad eller element:
Ett sammansatt eller inbäddat dokument (till exempel ett ZIP-arkiv, ett Word-dokument med inbäddad Outlook-e-post som innehåller bifogade filer eller en . MSG-fil med bifogade filer) indexeras också som ett enda dokument. Till exempel alla bilder som extraherats från bifogade filer i en . MSG-filen returneras i fältet normalized_images. Om du har bilder kan du överväga att lägga till AI-berikning för att få mer sökverktyg från det innehållet.
Textinnehåll i ett dokument extraheras till ett strängfält med namnet "content". Du kan också extrahera standard- och användardefinierade metadata.
Kommentar
Azure AI Search tillämpar indexerargränser för hur mycket text den extraherar beroende på prisnivån. En varning visas i indexerarens statussvar om dokumenten trunkeras.
Använda en blobindexerare för extrahering av innehåll
En indexerare är en datakällmedveten undertjänst i Azure AI Search, utrustad med intern logik för sampling av data, läsning och hämtning av data och metadata samt serialisering av data från interna format till JSON-dokument för efterföljande import.
Blobar i Azure Storage indexeras med blobindexeraren. Du kan anropa den här indexeraren med hjälp av Azure AI Search-kommandot i Azure Storage, guiden Importera data, ett REST-API eller .NET SDK. I kod använder du den här indexeraren genom att ange typen och genom att ange anslutningsinformation som innehåller ett Azure Storage-konto tillsammans med en blobcontainer. Du kan dela upp dina blobar genom att skapa en virtuell katalog, som du sedan kan skicka som en parameter, eller genom att filtrera på ett filtypstillägg.
En indexerare "spricker ett dokument" och öppnar en blob för att inspektera innehåll. När du har anslutit till datakällan är det det första steget i pipelinen. För blobdata identifieras PDF, Office-dokument och andra innehållstyper. Dokumentsprickor med textextrahering kostar ingenting. Om dina blobar innehåller bildinnehåll ignoreras bilder om du inte lägger till AI-berikning. Standardindexering gäller endast textinnehåll.
Azure Blob-indexeraren levereras med konfigurationsparametrar och stöder ändringsspårning om underliggande data ger tillräcklig information. Du kan lära dig mer om kärnfunktionerna i Indexdata från Azure Blob Storage.
Åtkomstnivåer som stöds
Åtkomstnivåer för Blob Storage omfattar frekvent, lågfrekvent, kall och arkivering. Indexerare kan hämta blobar på frekventa, lågfrekventa och kalla åtkomstnivåer.
Innehållstyper som stöds
Genom att köra en blobindexerare över en container kan du extrahera text och metadata från följande innehållstyper med en enda fråga:
- CSV (se Indexering av CSV-blobar)
- EML
- EPUB
- GZ
- HTML
- JSON (se Indexering av JSON-blobar)
- KML (XML för geografiska representationer)
- Microsoft Office-format: DOCX/DOC/DOCM, XLSX/XLS/XLSM, PPTX/PPT/PPTM, MSG (Outlook-e-post), XML (både 2003 och 2006 WORD XML)
- Öppna dokumentformat: ODT, ODS, ODP
- Oformaterade textfiler (se även Indexering av oformaterad text)
- RTF
- XML
- ZIP-kod
Styra vilka blobar som indexeras
Du kan styra vilka blobar som indexeras och vilka som hoppas över av blobens filtyp eller genom att ange egenskaper för själva blobben, vilket gör att indexeraren hoppar över dem.
Inkludera specifika filnamnstillägg genom att ange "indexedFileNameExtensions" en kommaavgränsad lista med filnamnstillägg (med en inledande punkt). Exkludera specifika filnamnstillägg genom att ange "excludedFileNameExtensions" de tillägg som ska hoppas över. Om samma tillägg finns i båda listorna undantas det från indexering.
PUT /indexers/[indexer name]?api-version=2024-07-01
{
"parameters" : {
"configuration" : {
"indexedFileNameExtensions" : ".pdf, .docx",
"excludedFileNameExtensions" : ".png, .jpeg"
}
}
}
Lägg till "hoppa över" metadata för bloben
Indexerarens konfigurationsparametrar gäller för alla blobar i containern eller mappen. Ibland vill du styra hur enskilda blobar indexeras.
Lägg till följande metadataegenskaper och värden i blobar i Blob Storage. När indexeraren stöter på den här egenskapen hoppar den över bloben eller dess innehåll i indexeringskörningen.
| Egenskapsnamn | Egenskapsvärde | Förklaring |
|---|---|---|
| AzureSearch_Skip | "true" |
Instruerar blobindexeraren att hoppa över bloben helt. Varken metadata eller extrahering av innehåll görs. Detta är användbart när en viss blob misslyckas upprepade gånger och avbryter indexeringsprocessen. |
| "AzureSearch_SkipContent" | "true" |
Detta motsvarar inställningen "dataToExtract" : "allMetadata" som beskrivs ovan omfång för en viss blob. |
Indexera blobmetadata
Ett vanligt scenario som gör det enkelt att sortera igenom blobar av valfri innehållstyp är att indexering av både anpassade metadata och systemegenskaper för varje blob. På så sätt indexeras information för alla blobar oavsett dokumenttyp, som lagras i ett index i söktjänsten. Med ditt nya index kan du sedan fortsätta att sortera, filtrera och fasettera över allt Blob Storage-innehåll.
Kommentar
Blob Index-taggar indexeras internt av Blob Storage-tjänsten och exponeras för frågor. Om dina blobars nyckel-/värdeattribut kräver indexerings- och filtreringsfunktioner bör blobindextaggar användas i stället för metadata.
Mer information om Blob Index finns i Hantera och hitta data på Azure Blob Storage med Blob Index.
Söka efter blobinnehåll i ett sökindex
Utdata från en indexerare är ett sökindex som används för interaktiv utforskning med hjälp av fritext och filtrerade frågor i en klientapp. För inledande utforskning och verifiering av innehåll rekommenderar vi att du börjar med Sökutforskaren i Azure Portal för att undersöka dokumentstrukturen. I Sökutforskaren kan du använda:
En mer permanent lösning är att samla in frågeindata och presentera svaret som sökresultat i ett klientprogram. I följande C#-självstudie beskriver vi hur du skapar ett sökprogram: Lägg till sökning i ett ASP.NET Core-program (MVC).