Tillförlitlighet i Azure AI Search
I Hela Azure innebär tillförlitlighet återhämtning och tillgänglighet om det uppstår avbrott i tjänsten eller en försämring. I Azure AI Search kan tillförlitlighet uppnås inom en enda tjänst eller via flera söktjänster i separata regioner.
Distribuera en enda söktjänst och skala upp för hög tillgänglighet. Du kan lägga till flera repliker för att hantera högre indexering och köra frågor mot arbetsbelastningar. Om söktjänsten stöder tillgänglighetszoner etableras repliker automatiskt i olika fysiska datacenter för extra återhämtning.
Distribuera flera söktjänster i olika geografiska regioner. Alla sökarbetsbelastningar är helt inneslutna i en enda tjänst som körs i en enda geografisk region, men i ett scenario med flera tjänster har du alternativ för att synkronisera innehåll så att det är detsamma för alla tjänster. Du kan också konfigurera en belastningsutjämningslösning för att omdistribuera begäranden eller redundansväxla om det uppstår ett tjänstfel.
För affärskontinuitet och återställning efter katastrofer på regional nivå planerar du en topologi mellan regioner som består av flera söktjänster med identisk konfiguration och innehåll. Ditt anpassade skript eller din kod ger redundansmekanismen till en alternativ söktjänst om en plötsligt blir otillgänglig.
Hög tillgänglighet
I Azure AI Search är repliker kopior av ditt index. En söktjänst beställs med minst en replik och kan ha upp till 12 repliker. Genom att lägga till repliker kan Azure AI Search göra datoromstarter och underhåll mot en replik, medan frågekörningen fortsätter på andra repliker.
För varje enskild söktjänst garanterar Microsoft minst 99,9 % tillgänglighet för konfigurationer som uppfyller följande kriterier:
Två repliker för hög tillgänglighet för skrivskyddade arbetsbelastningar (frågor)
Tre eller fler repliker för hög tillgänglighet för skrivskyddade arbetsbelastningar (frågor och indexering)
Systemet har interna mekanismer för övervakning av replikhälsa och partitionsintegritet. Om du etablerar en specifik kombination av repliker och partitioner säkerställer systemet den kapacitetsnivån för din tjänst.
Inget serviceavtal (SLA) tillhandahålls för den kostnadsfria nivån. Mer information finns i serviceavtalet för Azure AI Search.
Stöd för tillgänglighetszon
Tillgänglighetszoner är en Azure-plattformsfunktion som delar upp en regions datacenter i olika fysiska platsgrupper för att ge hög tillgänglighet inom samma region. I Azure AI Search är enskilda repliker enheter för zontilldelning. En söktjänst körs inom en region. dess repliker körs i olika fysiska datacenter (eller zoner) inom den regionen.
Tillgänglighetszoner används när du lägger till två eller flera repliker i söktjänsten. Varje replik placeras i en annan tillgänglighetszon i regionen. Om du har fler repliker än tillgängliga zoner i söktjänstregionen distribueras replikerna mellan zoner så jämnt som möjligt. Det finns ingen specifik åtgärd från din sida, förutom att skapa en söktjänst i en region som tillhandahåller tillgänglighetszoner och sedan konfigurera tjänsten för att använda flera repliker.
Förutsättningar
- Tjänstnivån måste vara Standard eller högre
- Tjänstregionen måste finnas i en region som har tillgängliga zoner (visas i följande avsnitt)
- Konfigurationen måste innehålla flera repliker: två för skrivskyddade frågearbetsbelastningar, tre för skrivskyddade arbetsbelastningar som inkluderar indexering
Regioner som stöds
Stöd för tillgänglighetszoner beror på infrastruktur och lagring. För närvarande har följande zon otillräcklig lagring och tillhandahåller ingen tillgänglighetszon för Azure AI Search:
- Västra Japan
Annars stöds tillgänglighetszoner för Azure AI Search i följande regioner:
| Region | Utrullningsdatum |
|---|---|
| Australien, östra | 30 januari 2021 eller senare |
| Brasilien, södra | 2 maj 2021 eller senare |
| Kanada, centrala | 30 januari 2021 eller senare |
| Indien, centrala | 20 januari 2022 eller senare |
| USA, centrala | 4 december 2020 eller senare |
| Norra Kina 3 | 7 september 2022 eller senare |
| Asien, östra | 13 januari 2022 eller senare |
| USA, östra | 27 januari 2021 eller senare |
| USA, östra 2 | 30 januari 2021 eller senare |
| Centrala Frankrike | 23 oktober 2020 eller senare |
| Tyskland, västra centrala | 3 maj 2021 eller senare |
| Israel, centrala | 1 april 2024 eller senare |
| Italien, norra | 1 april 2024 eller senare |
| Japan, östra | 30 januari 2021 eller senare |
| Sydkorea, centrala | 20 januari 2022 eller senare |
| Europa, norra | 28 januari 2021 eller senare |
| Norge, östra | 20 januari 2022 eller senare |
| Qatar, centrala | 25 augusti 2022 eller senare |
| Sydafrika, norra | 7 september 2022 eller senare |
| USA, södra centrala | 30 april 2021 eller senare |
| Sydostasien | 31 januari 2021 eller senare |
| Sverige, centrala | 21 januari 2022 eller senare |
| Schweiz, norra | 7 september 2022 eller senare |
| Förenade Arabemiraten, norra | 9 september 2022 eller senare |
| Storbritannien, södra | 30 januari 2021 eller senare |
| US Gov, Virginia | 30 april 2021 eller senare |
| Europa, västra | 29 januari 2021 eller senare |
| USA, västra 2 | 30 januari 2021 eller senare |
| USA, västra 3 | 02 juni 2021 eller senare |
Kommentar
Tillgänglighetszoner ändrar inte villkoren i serviceavtalet. Du behöver fortfarande tre eller fler repliker för hög tillgänglighet för frågor.
Flera tjänster i separata geografiska regioner
Tjänstredundans krävs om dina driftkrav omfattar:
Krav på affärskontinuitet och haveriberedskap (BCDR). Azure AI Search ger inte omedelbar redundans om det uppstår ett avbrott.
Snabba prestanda för ett globalt distribuerat program. Om fråge- och indexeringsbegäranden kommer från hela världen får användare som är närmast värddatacentret snabbare prestanda. Om du skapar fler tjänster i regioner nära dessa användare kan du utjämna prestanda för alla användare.
Om du behöver två eller flera söktjänster kan skapandet av dem i olika regioner uppfylla programkraven för kontinuitet och återställning och snabbare svarstider för en global användarbas.
Azure AI Search tillhandahåller inte någon automatiserad metod för replikering av sökindex i geografiska regioner, men det finns vissa tekniker som kan göra den här processen enkel att implementera och hantera. Dessa tekniker beskrivs i de kommande avsnitten.
Målet med en geo-distribuerad uppsättning söktjänster är att ha två eller flera index tillgängliga i två eller flera regioner, där en användare dirigeras till Azure AI-tjänsten Search som ger den lägsta svarstiden:
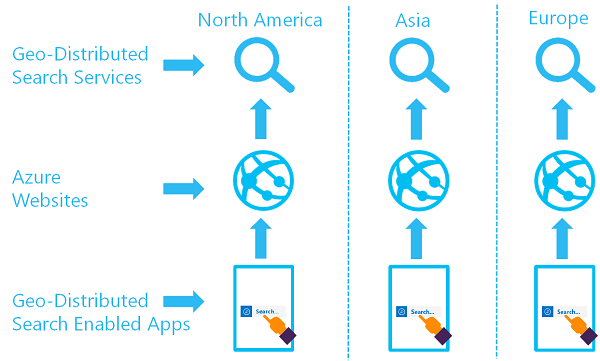
Du kan implementera den här arkitekturen genom att skapa flera tjänster och utforma en strategi för datasynkronisering. Du kan också inkludera en resurs som Azure Traffic Manager för routningsbegäranden.
Dricks
Hjälp med att distribuera flera söktjänster i flera regioner finns i det här Bicep-exemplet på GitHub som distribuerar en fullständigt konfigurerad söklösning för flera regioner. Exemplet ger dig två alternativ för indexsynkronisering och omdirigering av begäranden med Hjälp av Traffic Manager.
Synkronisera data mellan flera tjänster
Det finns två alternativ för att hålla två eller flera distinkta söktjänster synkroniserade:
- Hämta innehållsuppdateringar till ett sökindex med hjälp av en indexerare.
- Skicka innehåll till ett index med hjälp av REST-API:et (Add or Update Documents) eller ett Motsvarande API för Azure SDK.
För att konfigurera något av alternativen rekommenderar vi att du använder Bicep-exempelskriptet på lagringsplatsen azure-search-multiple-region , ändrat till dina regioner och indexeringsstrategier.
Alternativ 1: Använd indexerare för att uppdatera innehåll på flera tjänster
Om du redan använder indexerare på en tjänst kan du konfigurera en andra indexerare för en andra tjänst för att använda samma datakällaobjekt och hämta data från samma plats. Varje tjänst i varje region har en egen indexerare och ett målindex (ditt sökindex delas inte, vilket innebär att varje index har en egen kopia av data), men varje indexerare refererar till samma datakälla.
Här är ett visuellt objekt på hög nivå av hur arkitekturen skulle se ut.
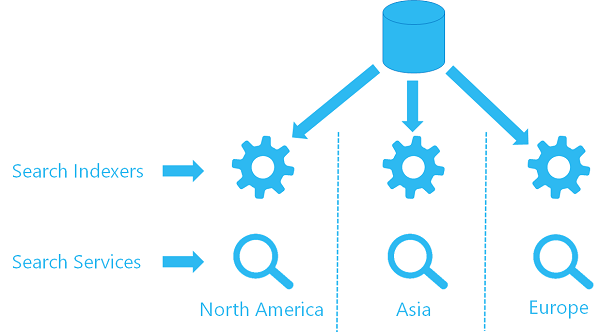
Alternativ 2: Använd REST-API:er för att skicka innehållsuppdateringar på flera tjänster
Om du använder REST-API:et för Azure AI Search för att skicka innehåll till ditt sökindex kan du hålla dina olika söktjänster synkroniserade genom att skicka ändringar till alla söktjänster när en uppdatering krävs. I koden ska du se till att hantera fall där en uppdatering av en söktjänst misslyckas men lyckas för andra söktjänster.
Begäranden om redundansväxling eller omdirigering av frågor
Om du behöver redundans på begärandenivå tillhandahåller Azure flera alternativ för belastningsutjämning:
- Azure Traffic Manager används för att dirigera begäranden till flera geo-lokaliserade webbplatser som sedan backas upp av flera söktjänster.
- Application Gateway, som används för att belastningsutjämning mellan servrar i en region på programnivå.
- Azure Front Door, som används för att optimera global routning av webbtrafik och tillhandahålla global redundans.
Några saker att tänka på när du utvärderar alternativ för belastningsutjämning:
Sökning är en serverdelstjänst som accepterar fråge- och indexeringsbegäranden från en klient.
Begäranden från klienten till en söktjänst måste autentiseras. För åtkomst till sökåtgärder måste anroparen ha rollbaserade behörigheter eller ange en API-nyckel för begäran.
Tjänstslutpunkter nås som standard via en offentlig Internetanslutning. Om du konfigurerar en privat slutpunkt för klientanslutningar som kommer från ett virtuellt nätverk använder du Application Gateway.
Azure AI Search accepterar begäranden som är adresserade till
<your-search-service-name>.search.windows.netslutpunkten. Om du når samma slutpunkt med ett annat DNS-namn i värdhuvudet, till exempel ett CNAME, avvisas begäran.
Azure AI Search innehåller ett distributionsexempel för flera regioner som använder Azure Traffic Manager för omdirigering av begäranden om den primära slutpunkten misslyckas. Den här lösningen är användbar när du dirigerar till en sökaktiverad klient som bara anropar en söktjänst i samma region.
Azure Traffic Manager används främst för att dirigera nätverkstrafik över olika slutpunkter baserat på specifika routningsmetoder (till exempel prioritet, prestanda eller geografisk plats). Den agerar på DNS-nivå för att dirigera inkommande begäranden till rätt slutpunkt. Om en slutpunkt som Traffic Manager betjänar börjar neka begäranden dirigeras trafiken till en annan slutpunkt.
Traffic Manager tillhandahåller inte någon slutpunkt för en direktanslutning till Azure AI Search, vilket innebär att du inte kan placera en söktjänst direkt bakom Traffic Manager. Antagandet är i stället att begäranden flödar till Traffic Manager, sedan till en sökaktiverad webbklient och slutligen till en söktjänst på serverdelen. Klienten och tjänsten finns i samma region. Om en söktjänst slutar fungera börjar sökklienten misslyckas och Traffic Manager omdirigeras till den återstående klienten.
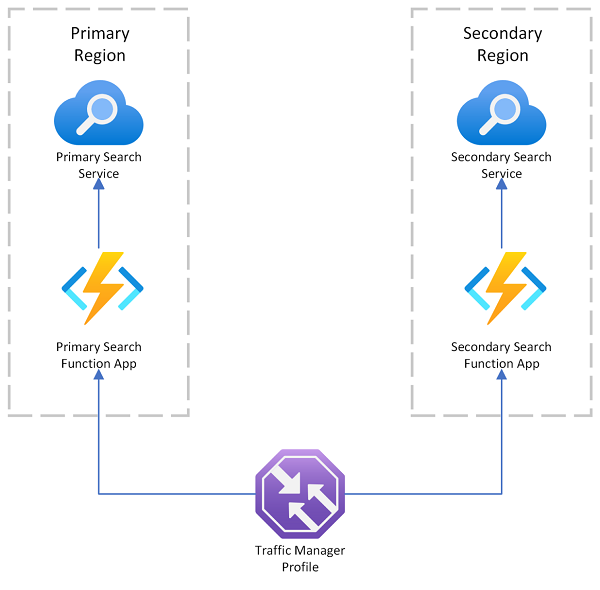
Datahemvist i en distribution i flera regioner
När du distribuerar flera söktjänster i olika geografiska regioner lagras innehållet i den region som du har valt för varje söktjänst.
Azure AI Search lagrar inte data utanför din angivna region utan din auktorisering. Auktorisering är implicit när du använder funktioner som skriver till en Azure Storage-resurs: berikande cache, felsökningssession, kunskapslager. I samtliga fall är lagringskontot ett som du anger i valfri region.
Kommentar
Om både lagringskontot och söktjänsten finns i samma region använder nätverkstrafik mellan sökning och lagring en privat IP-adress och sker via Microsofts stamnätverk. Eftersom privata IP-adresser används kan du inte konfigurera IP-brandväggar eller en privat slutpunkt för nätverkssäkerhet. Använd i stället undantaget för betrodda tjänster som ett alternativ när båda tjänsterna finns i samma region.
Om avbrott i tjänsten och katastrofala händelser
Som anges i serviceavtalet garanterar Microsoft en hög tillgänglighetsnivå för begäranden om indexfrågor när en Azure AI-tjänsten Search-instans konfigureras med två eller flera repliker och indexuppdateringsbegäranden när en Azure AI-tjänsten Search-instans konfigureras med tre eller flera repliker. Det finns dock ingen inbyggd mekanism för haveriberedskap. Om kontinuerlig tjänst krävs i händelse av ett oåterkalleligt fel utanför Microsofts kontroll rekommenderar vi att du etablerar en andra tjänst i en annan region och implementerar en geo-replikeringsstrategi för att säkerställa att index är helt redundanta för alla tjänster.
Kunder som använder indexerare för att fylla i och uppdatera index kan hantera haveriberedskap via geospecifika indexerare som hämtar data från samma datakälla. Två tjänster i olika regioner, som var och en kör en indexerare, kan indexera samma datakälla för att uppnå geo-redundans. Om du indexerar från datakällor som också är geo-redundanta ska du komma ihåg att Azure AI Search-indexerare bara kan utföra inkrementell indexering (slå samman uppdateringar från nya, ändrade eller borttagna dokument) från primära repliker. I en redundanshändelse måste du omdirigera indexeraren till den nya primära repliken.
Om du inte använder indexerare använder du programkoden för att skicka objekt och data till olika söktjänster parallellt. Mer information finns i Synkronisera data mellan flera tjänster.
Säkerhetskopiera och återställa alternativ
En strategi för affärskontinuitet för datalagret innehåller vanligtvis ett steg för återställning från säkerhetskopiering. Eftersom Azure AI Search inte är en primär datalagringslösning tillhandahåller Microsoft ingen formell mekanism för självbetjäning av säkerhetskopiering och återställning. Du kan dock använda exempelkoden index-backup-restore i den här Azure AI Search .NET-exempellagringsplatsen för att säkerhetskopiera indexdefinitionen och ögonblicksbilden till en serie JSON-filer och sedan använda dessa filer för att återställa indexet om det behövs. Det här verktyget kan också flytta index mellan tjänstnivåer.
Annars är programkoden som används för att skapa och fylla i ett index det faktiska återställningsalternativet om du tar bort ett index av misstag. Om du vill återskapa ett index tar du bort det (förutsatt att det finns), återskapar indexet i tjänsten och läser in det igen genom att hämta data från ditt primära datalager.
Relaterat innehåll
- Granska tjänstbegränsningar för att lära dig mer om prisnivåer och tjänstgränser.
- Mer information om partitions- och replikkombinationer finns i Planera för kapacitet .
- Granska fallstudie: Använd Kognitiv sökning för att stödja komplexa AI-scenarier för mer konfigurationsvägledning.