Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Dataflöden är en molnbaserad dataförberedelseteknik med självbetjäning. I den här artikeln skapar du ditt första dataflöde, hämtar data för ditt dataflöde och transformerar sedan data och publicerar dataflödet.
Förutsättningar
Följande krav krävs innan du börjar:
- Ett Microsoft Fabric klientkonto med en aktiv prenumeration. Skapa ett kostnadsfritt konto.
- Kontrollera att du har en Microsoft Fabric aktiverad arbetsyta: Skapa en arbetsyta.
Skapa ett dataflöde
I det här avsnittet skapar du ditt första dataflöde.
Anmärkning
Från och med april 2026 skapas alla nya Dataflow Gen2-objekt med CI/CD- och Git-integreringsstöd som standard. Alternativet för att skapa Dataflow Gen2-objekt utan CI/CD-stöd är inte längre tillgängligt. Befintliga icke-CI/CD-dataflöden fortsätter att fungera.
Gå till din Microsoft Fabric arbetsyta genom att gå till Microsoft Fabric-portalen, välj Arbetsytor i det vänstra navigeringsfönstret och välj sedan din arbetsyta i listan.
Välj +Nytt objekt och välj sedan Dataflöde Gen2.
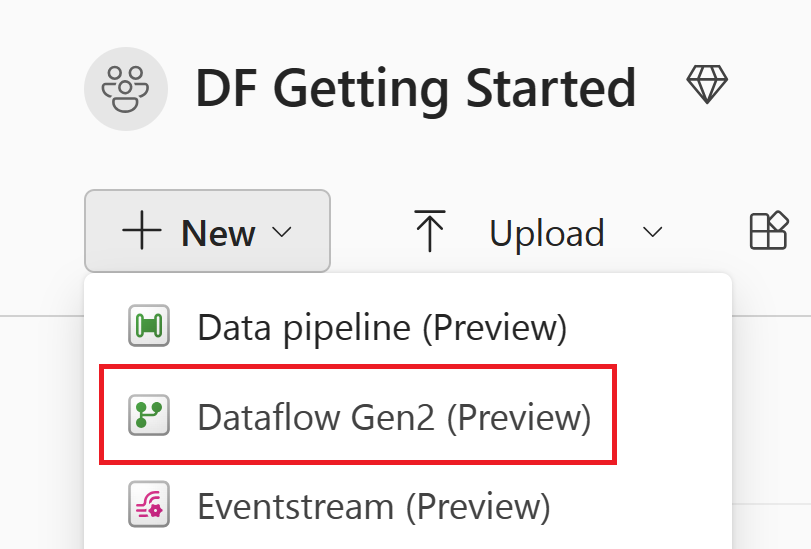
Hämta data
Nu ska vi hämta lite data! I det här exemplet får du data från en OData-tjänst. Använd följande steg för att hämta data i ditt dataflöde.
I dataflödesredigeraren väljer du Hämta data och sedan Mer.
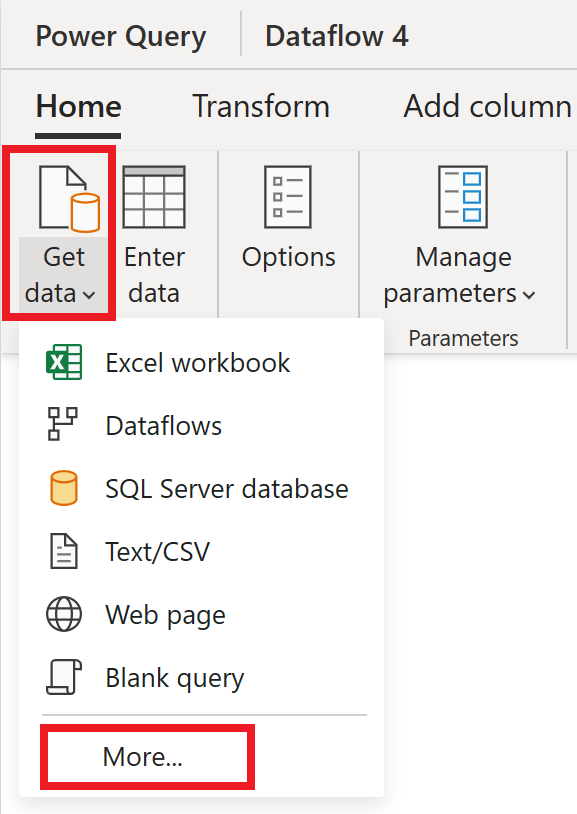
I Välj datakälla väljer du Visa mer.

I Ny källa väljer du Andra>OData som datakälla.

Ange URL:en
https://services.odata.org/v4/northwind/northwind.svc/och välj sedan Nästa.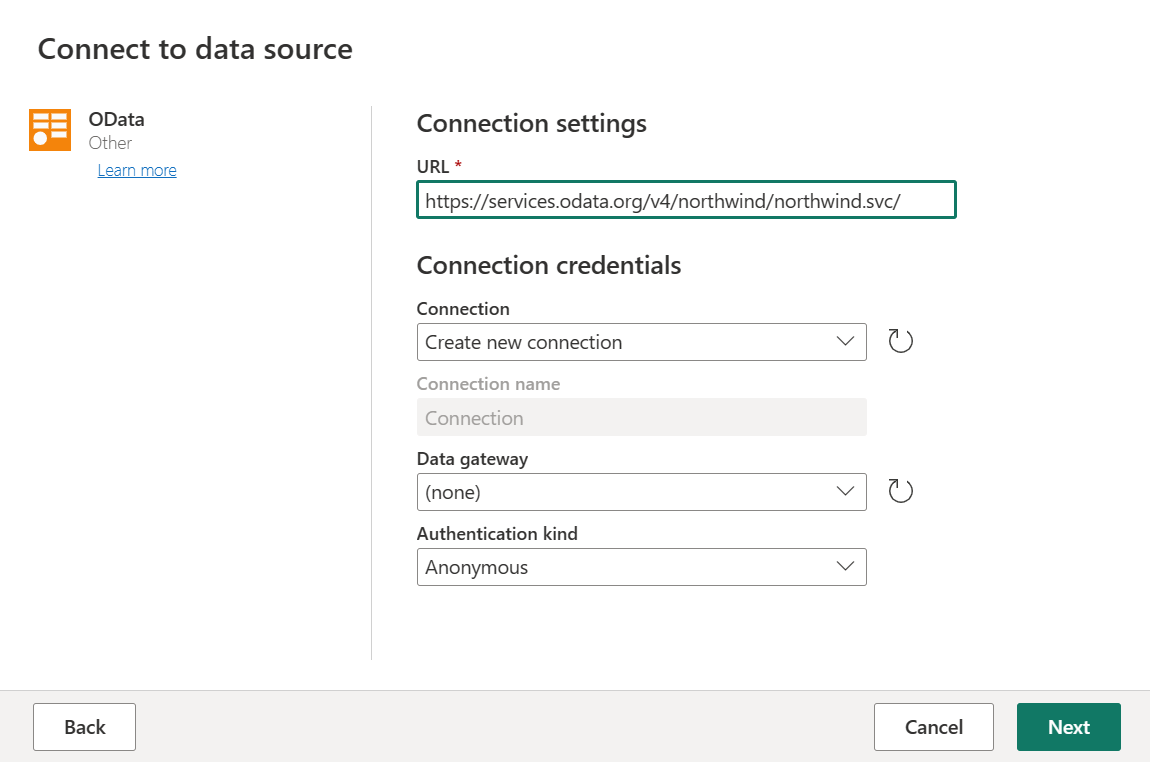
Välj tabellerna Beställningar och Kunder och välj sedan Skapa.
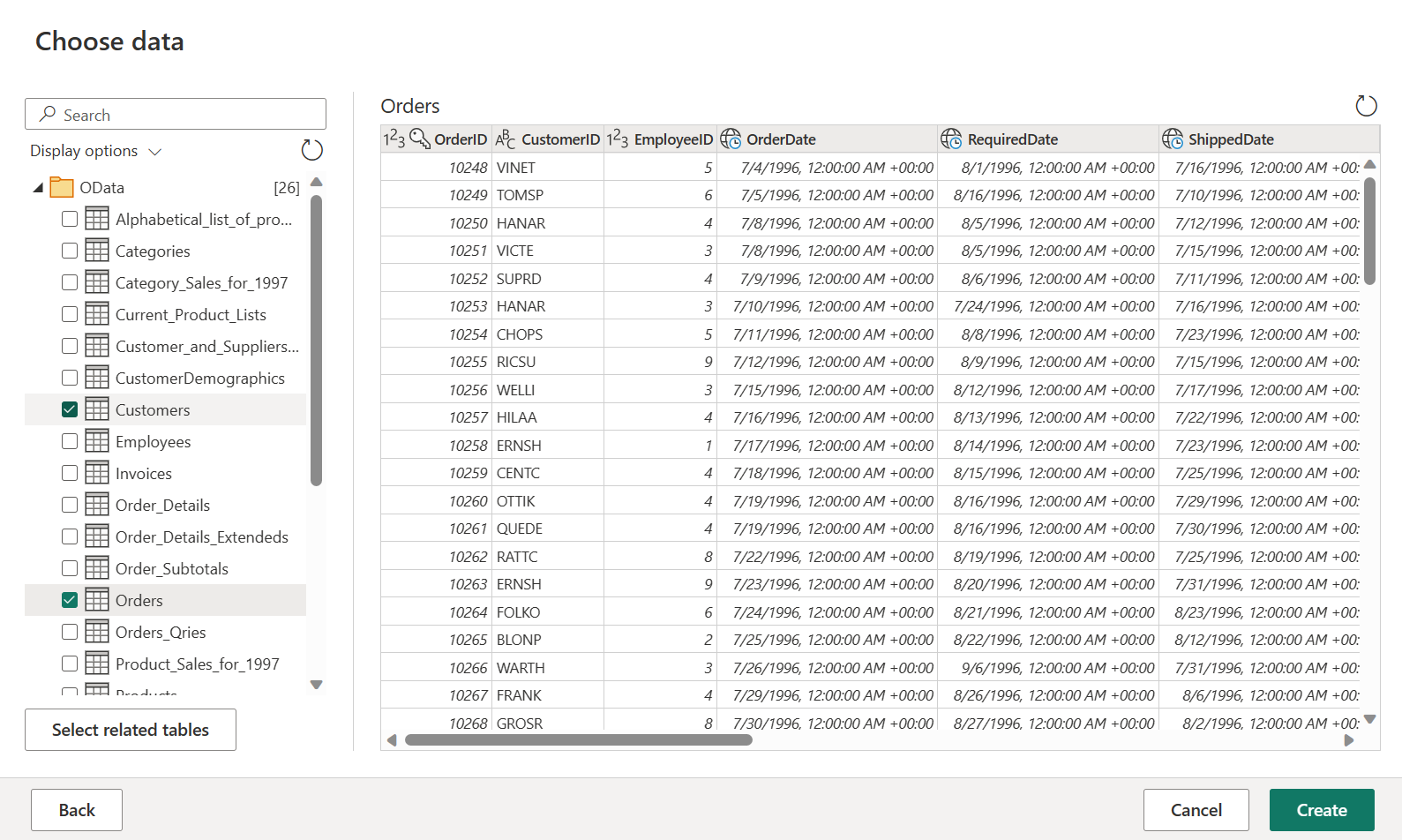



Du kan lära dig mer om erfarenhet av datahämtning och funktioner i översikten för datahämtning.
Tillämpa transformeringar och publicera
Du läste in dina data i ditt första dataflöde. Grattis! Nu är det dags att tillämpa ett par transformeringar för att föra dessa data till den form vi behöver.
Du transformerar data i Power Query-redigeraren. Du hittar en detaljerad översikt över Power Query redigeraren på Det Power Query användargränssnittet, men det här avsnittet tar dig igenom de grundläggande stegen:
Kontrollera att verktygen för dataprofilering är aktiverade. Gå tillGlobala alternativ för>> och välj sedan alla alternativ under Kolumnprofil.
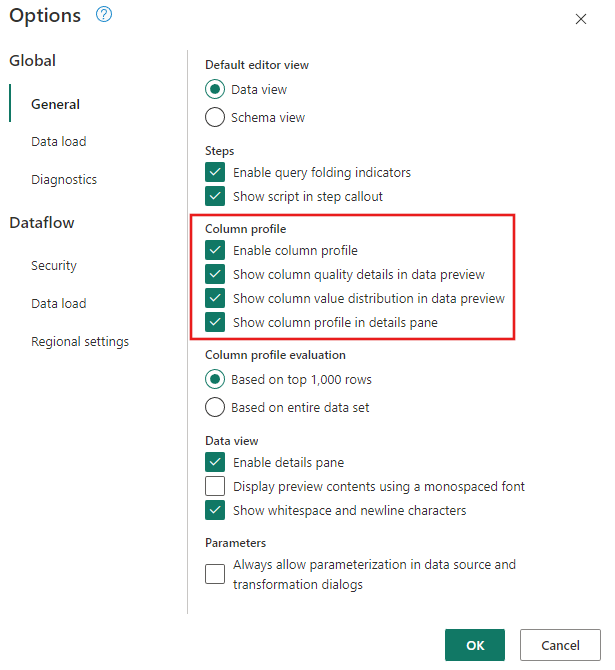
Se också till att du aktiverar vyn diagram med hjälp av layoutkonfigurationerna under fliken View i menyfliksområdet Power Query redigerare, eller genom att välja diagramvyikonen längst ned till höger i Power Query-fönstret.
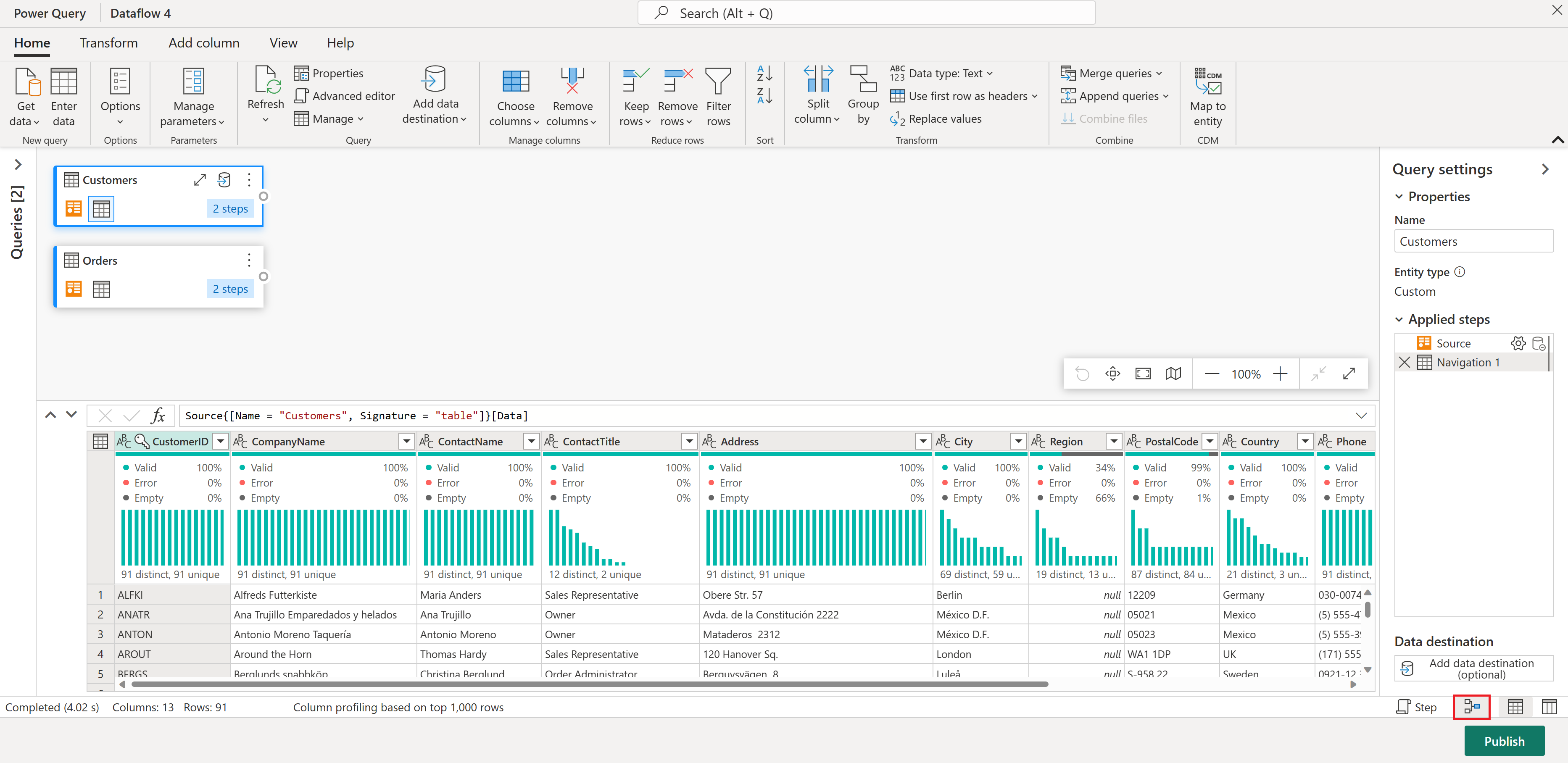
I tabellen Beställningar beräknar du det totala antalet beställningar per kund: Välj kolumnen CustomerID i dataförhandsgranskningen och välj sedan Gruppera efter under fliken Transformera i menyfliksområdet.

Du räknar antal rader som en aggregeringsmetod inom Gruppera efter. Du kan lära dig mer om Group By-funktioner i Gruppera eller sammanfatta rader.
När vi har grupperat data i tabellen Beställningar hämtar vi en tabell med två kolumner med CustomerID och Count som kolumner.
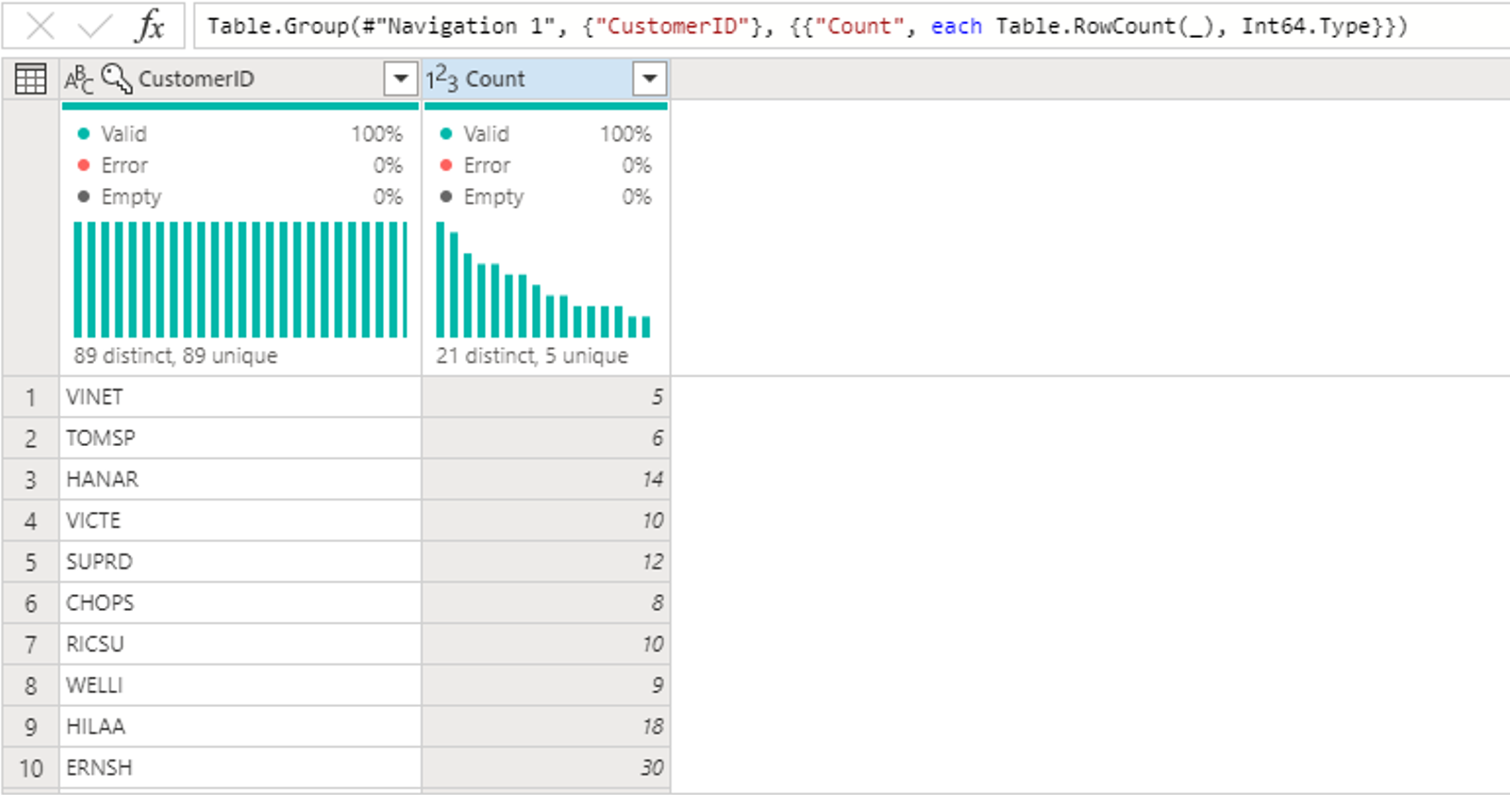
Sedan vill du kombinera data från tabellen Kunder med antalet beställningar per kund: Välj frågan Kunder i diagramvyn och använd menyn "⋮" för att komma åt sammanfoga frågor som ny transformering.
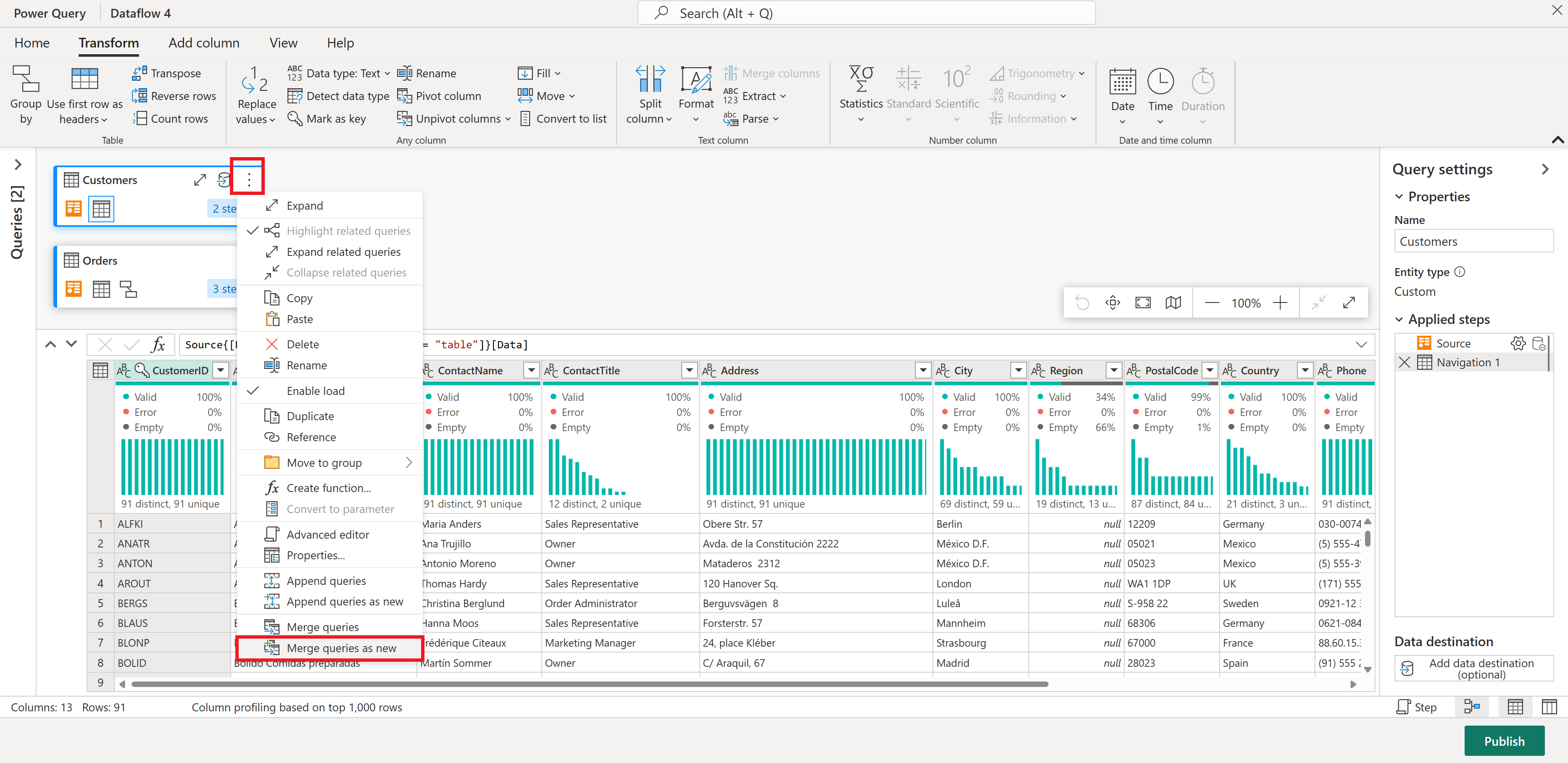
Konfigurera sammanslagningsåtgärden genom att välja CustomerID som matchande kolumn i båda tabellerna. Välj sedan Ok.
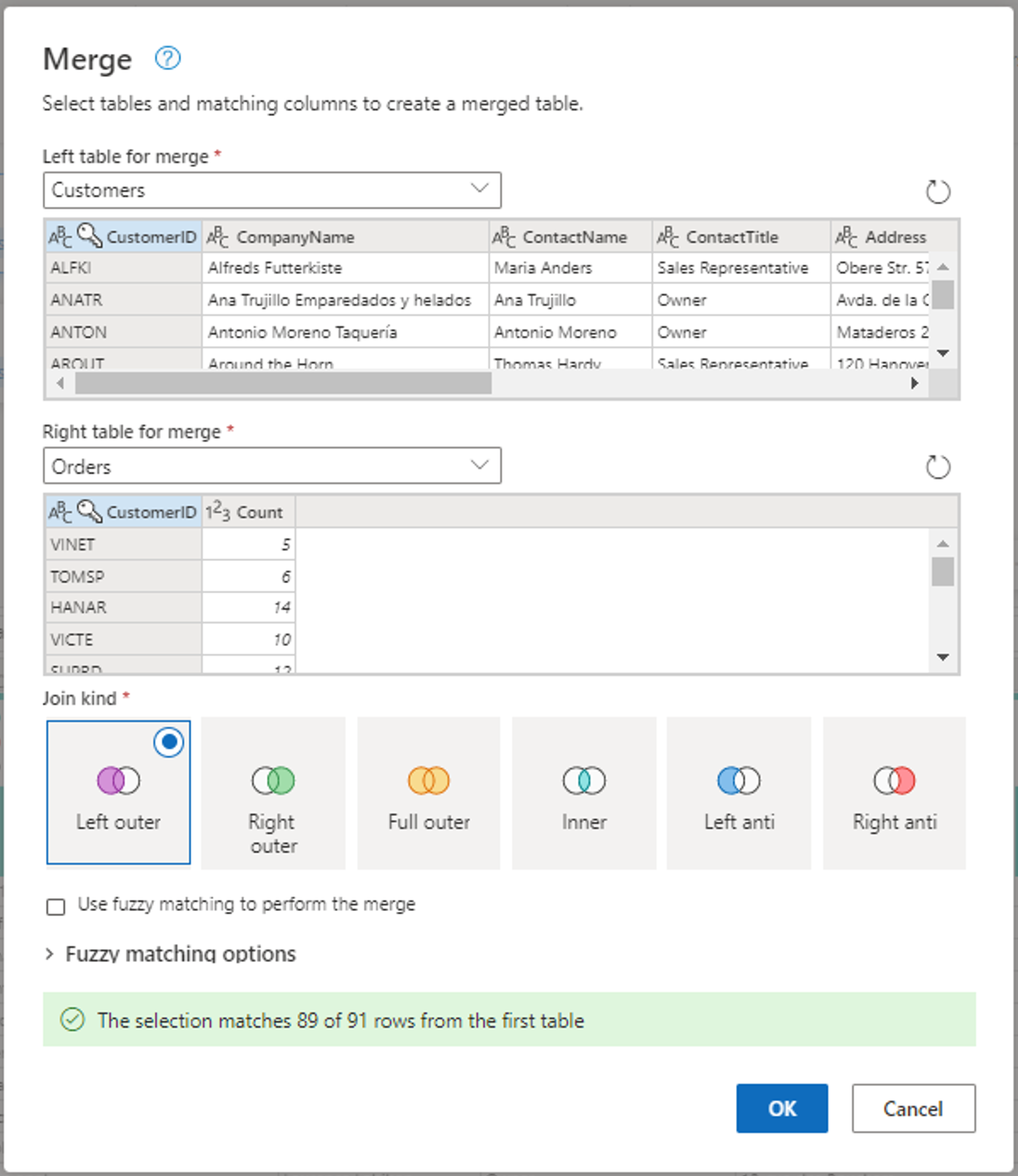
Skärmbild av fönstret Slå samman, med den vänstra tabellen för sammanslagning inställd på tabellen Kunder och den högra tabellen för sammanslagning inställd på tabellen Beställningar. Kolumnen CustomerID har valts för tabellerna Kunder och Beställningar. Kopplingstyp är också inställd på Vänster yttre koppling. Alla andra val är inställda på deras standardvärde.
Nu finns det en ny fråga med alla kolumner från tabellen Kunder och en kolumn med kapslade data från tabellen Beställningar.
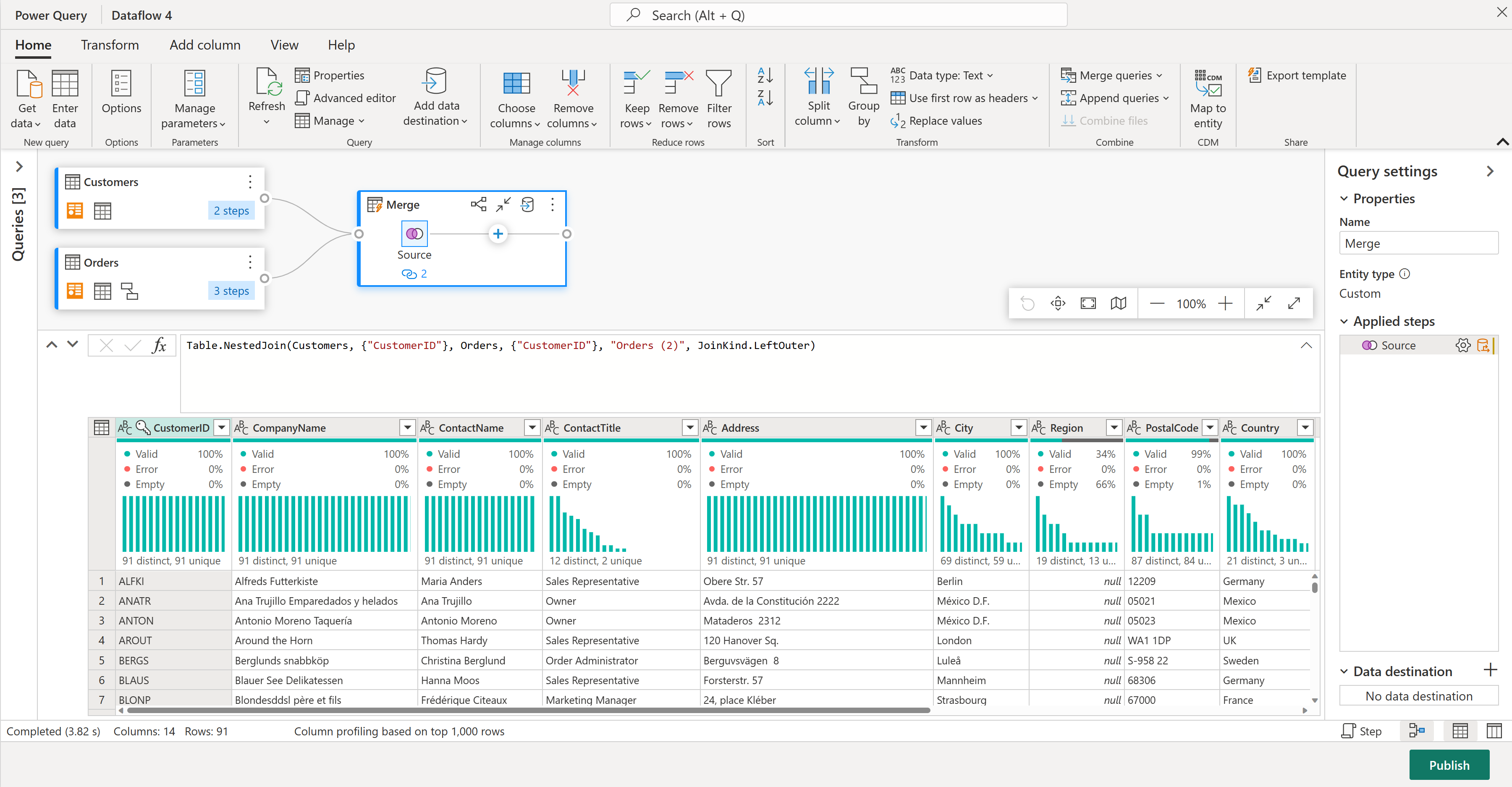
Nu ska vi fokusera på några få kolumner från tabellen Kunder. Det gör du genom att aktivera schemavyn genom att välja knappen schemavy i det nedre högra hörnet i dataflödesredigeraren.
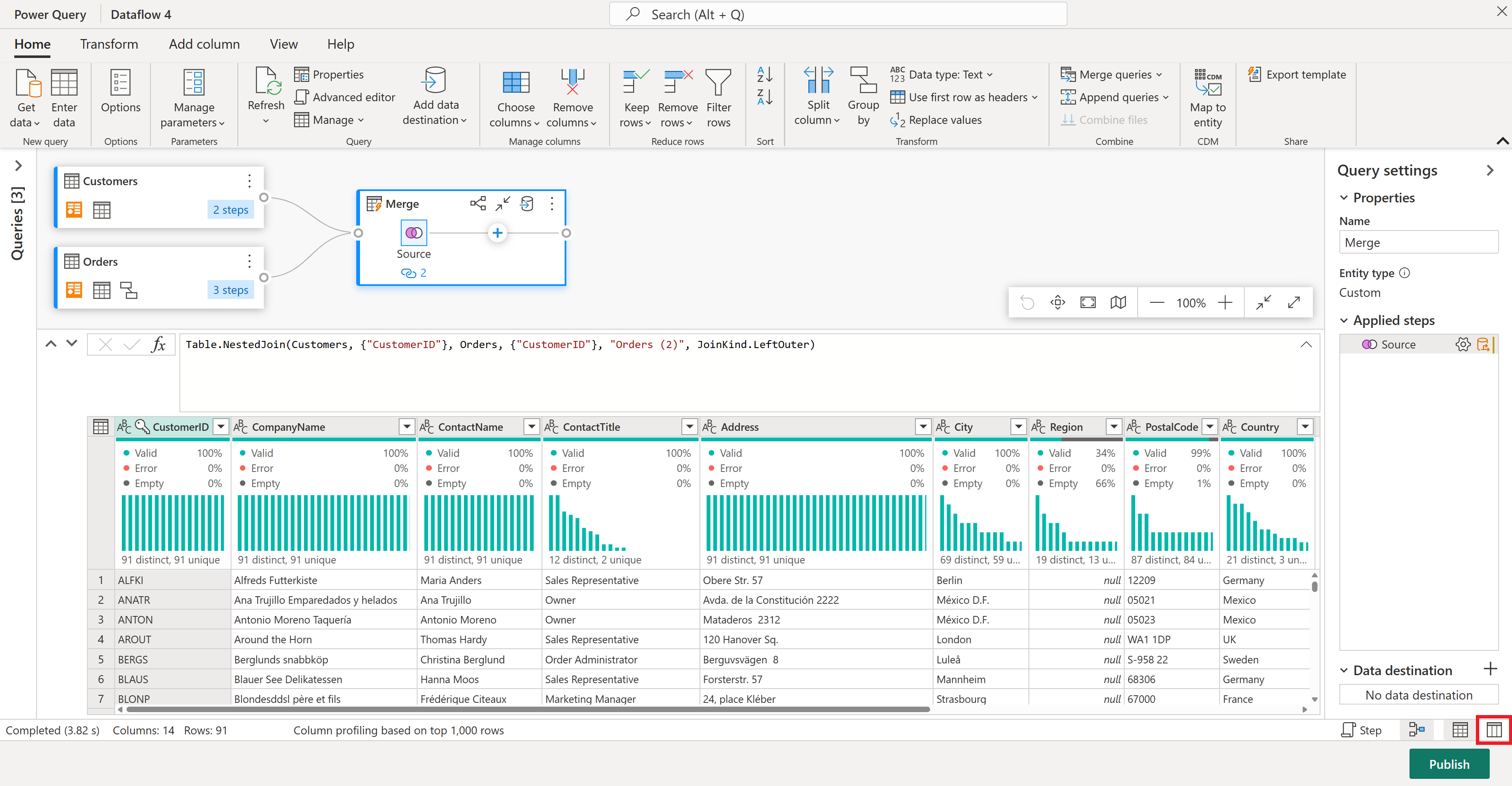
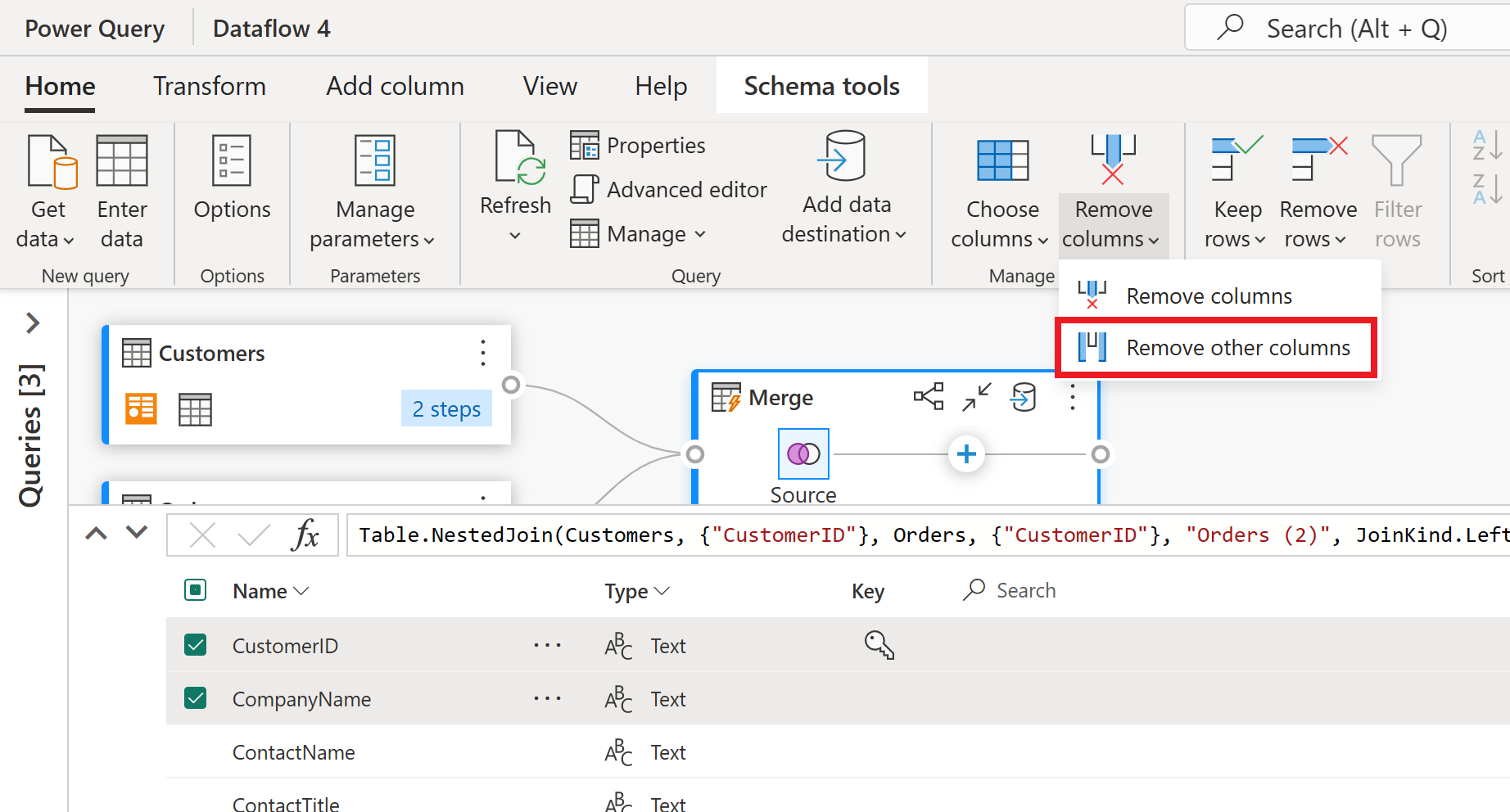
I schemavyn ser du alla kolumner i tabellen. Välj CustomerID, CompanyName och Orders (2). Gå sedan till fliken Schemaverktyg , välj Ta bort kolumner och välj Ta bort andra kolumner. Detta behåller bara de kolumner du vill ha.
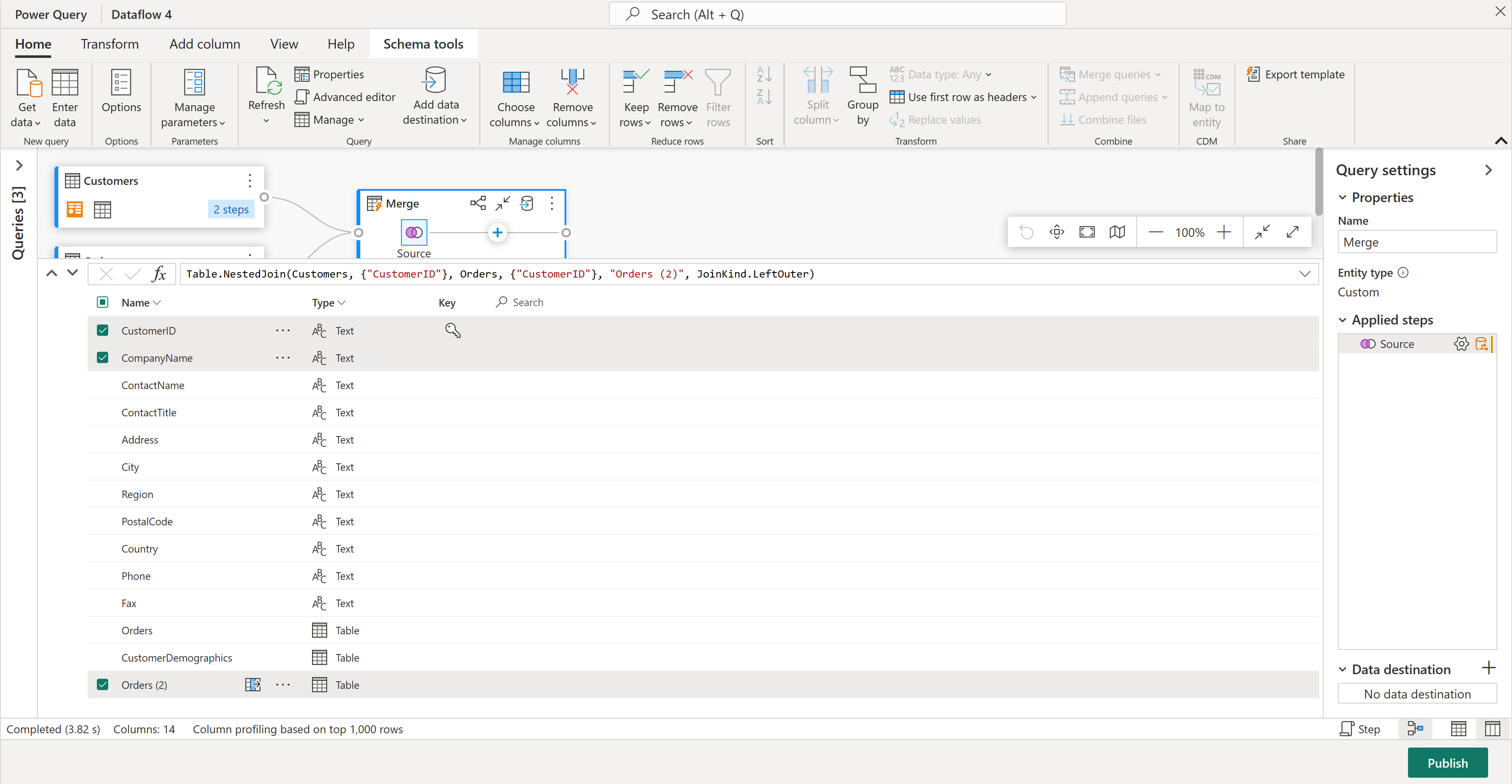
Kolumnen Beställningar (2) innehåller extra information från kopplingssteget. Om du vill se och använda dessa data väljer du knappen Visa datavy i det nedre högra hörnet bredvid Visa schemavy. I kolumnrubriken Beställningar (2) väljer du sedan ikonen Expandera kolumn och väljer kolumnen Antal . Detta lägger till orderantalet för varje kund i tabellen.

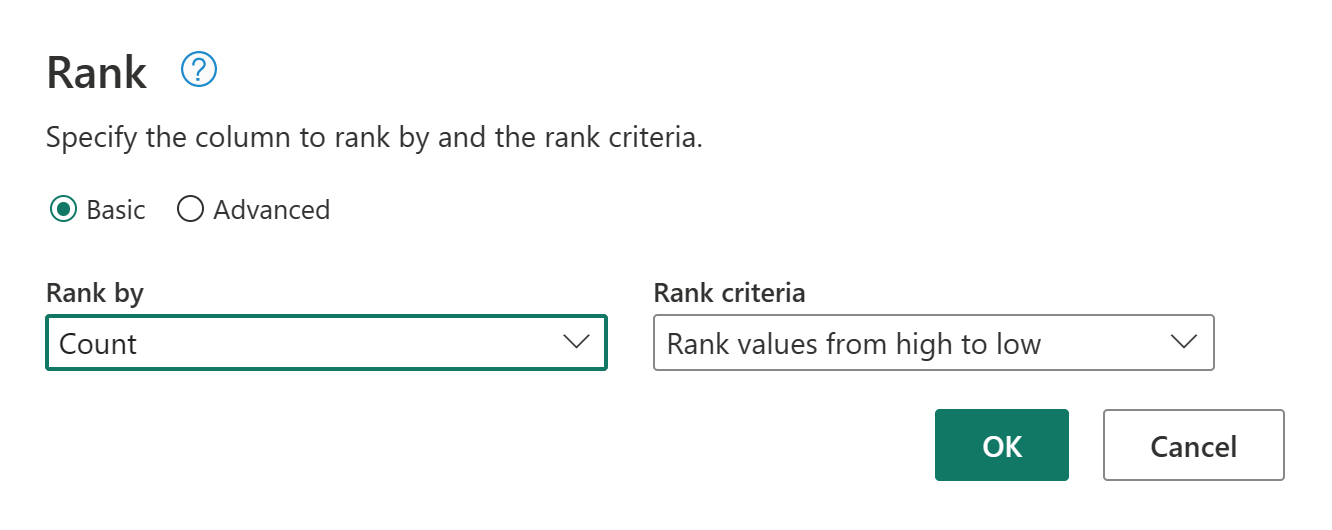
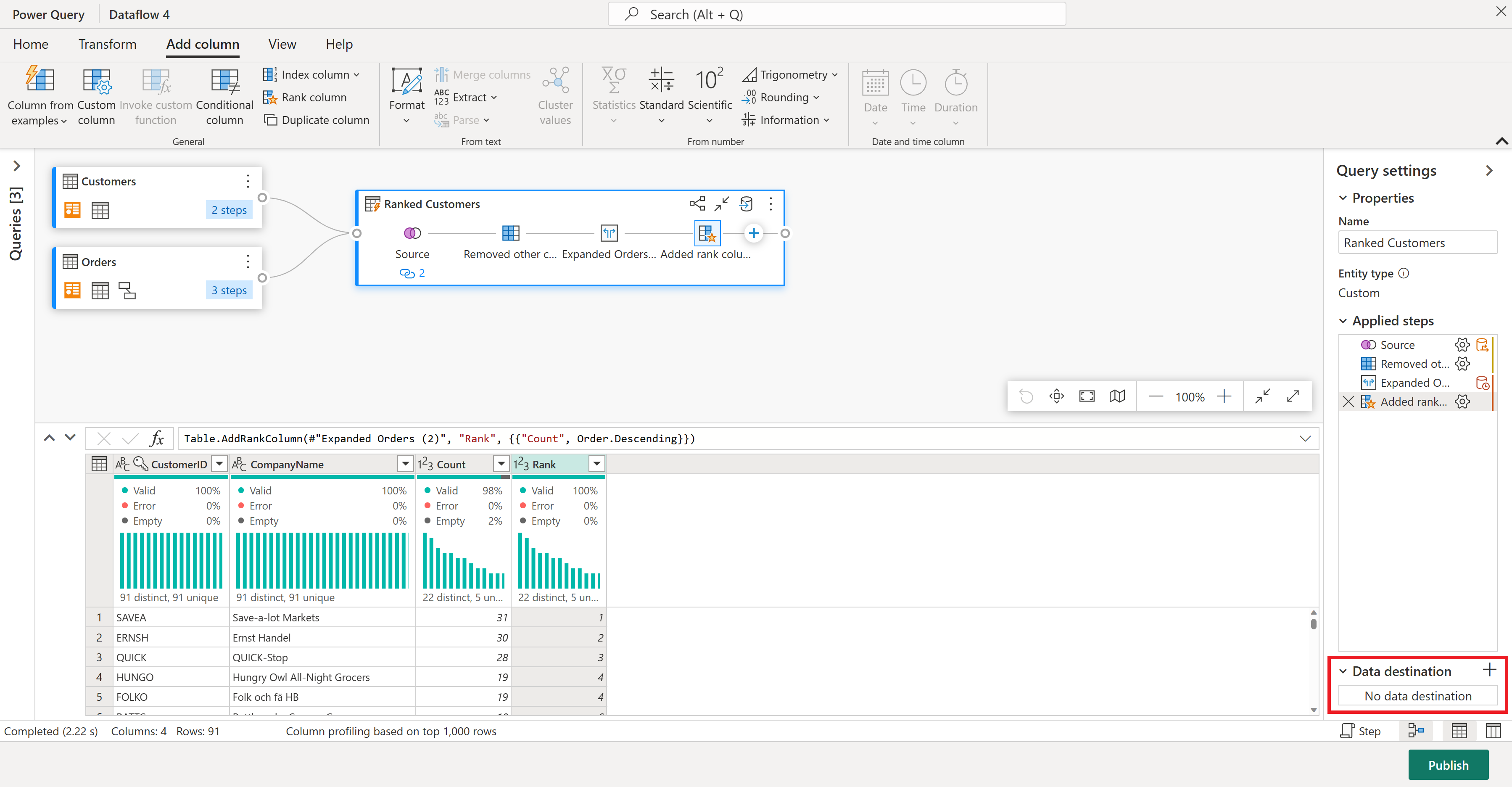
Nu ska vi rangordna dina kunder efter hur många beställningar de har gjort. Välj kolumnen Antal och gå sedan till fliken Lägg till kolumn och välj Rankningskolumn. Detta lägger till en ny kolumn som visar varje kunds rangordning baserat på deras orderantal.

Behåll standardinställningarna i Rangordningskolumn. Välj sedan OK för att tillämpa den här omvandlingen.
Byt nu namn på den resulterande frågan till Rankade kunder med hjälp av fönstret Frågeinställningar till höger på skärmen.
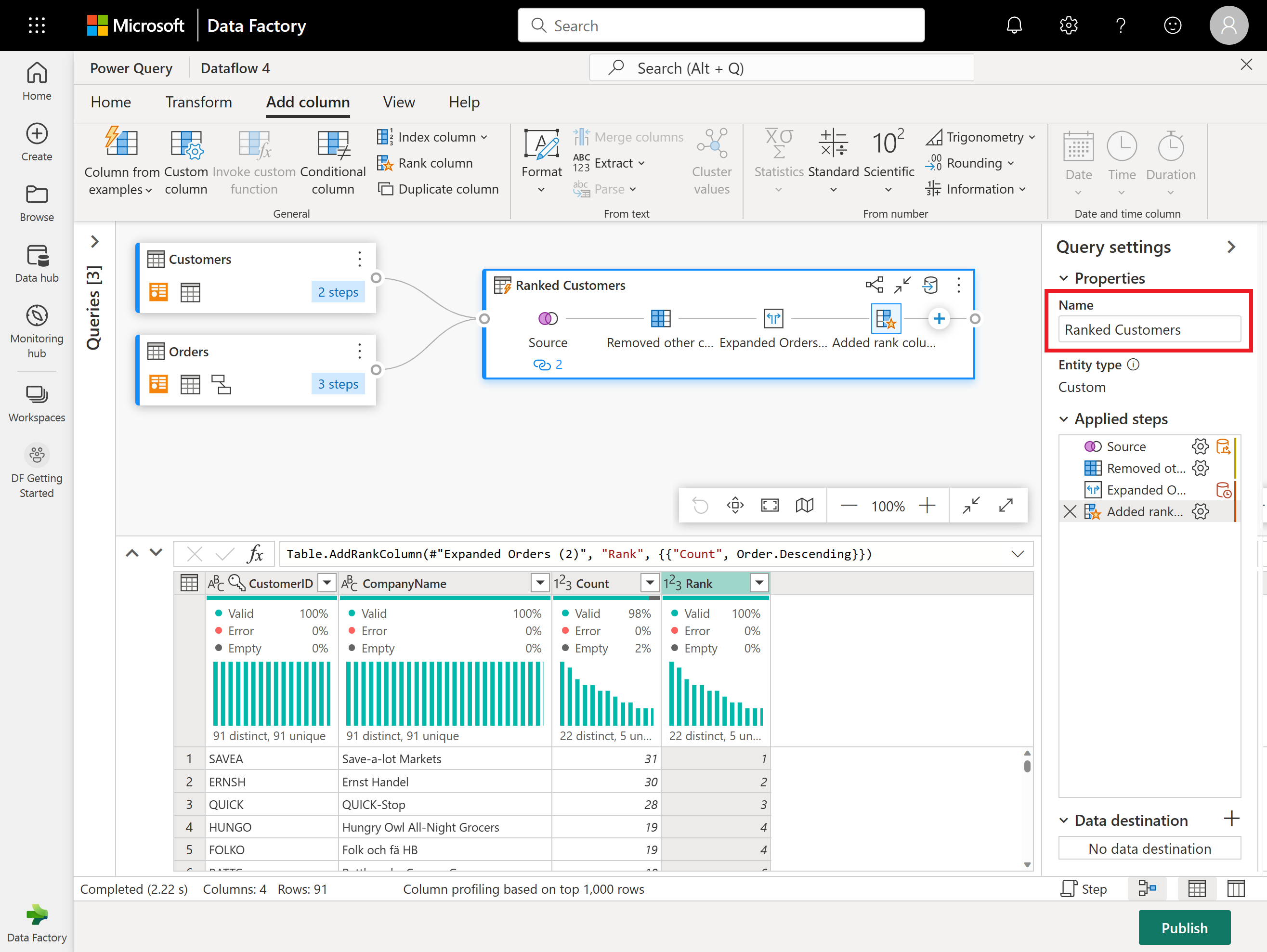
Du är redo att ange vart dina data ska gå. I fönstret Frågeinställningar bläddrar du längst ned och väljer Välj datamål.
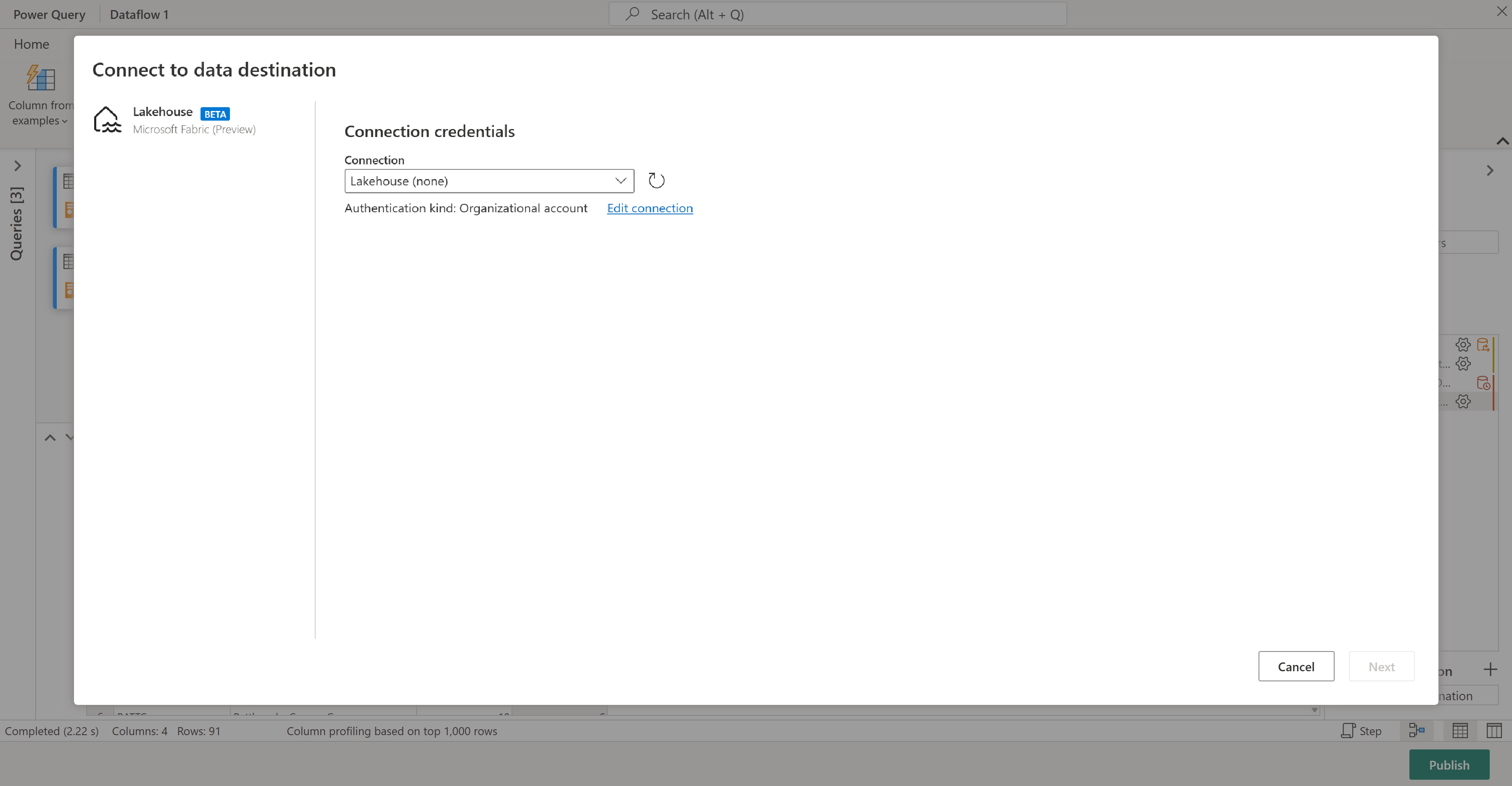
Du kan skicka dina resultat till ett sjöhus om du har ett eller hoppa över det här steget om du inte gör det. Här kan du välja vilken lakehouse och tabell som ska användas för dina data och välja om du vill lägga till nya data (Lägg till) eller ersätta det som finns där (Ersätt).
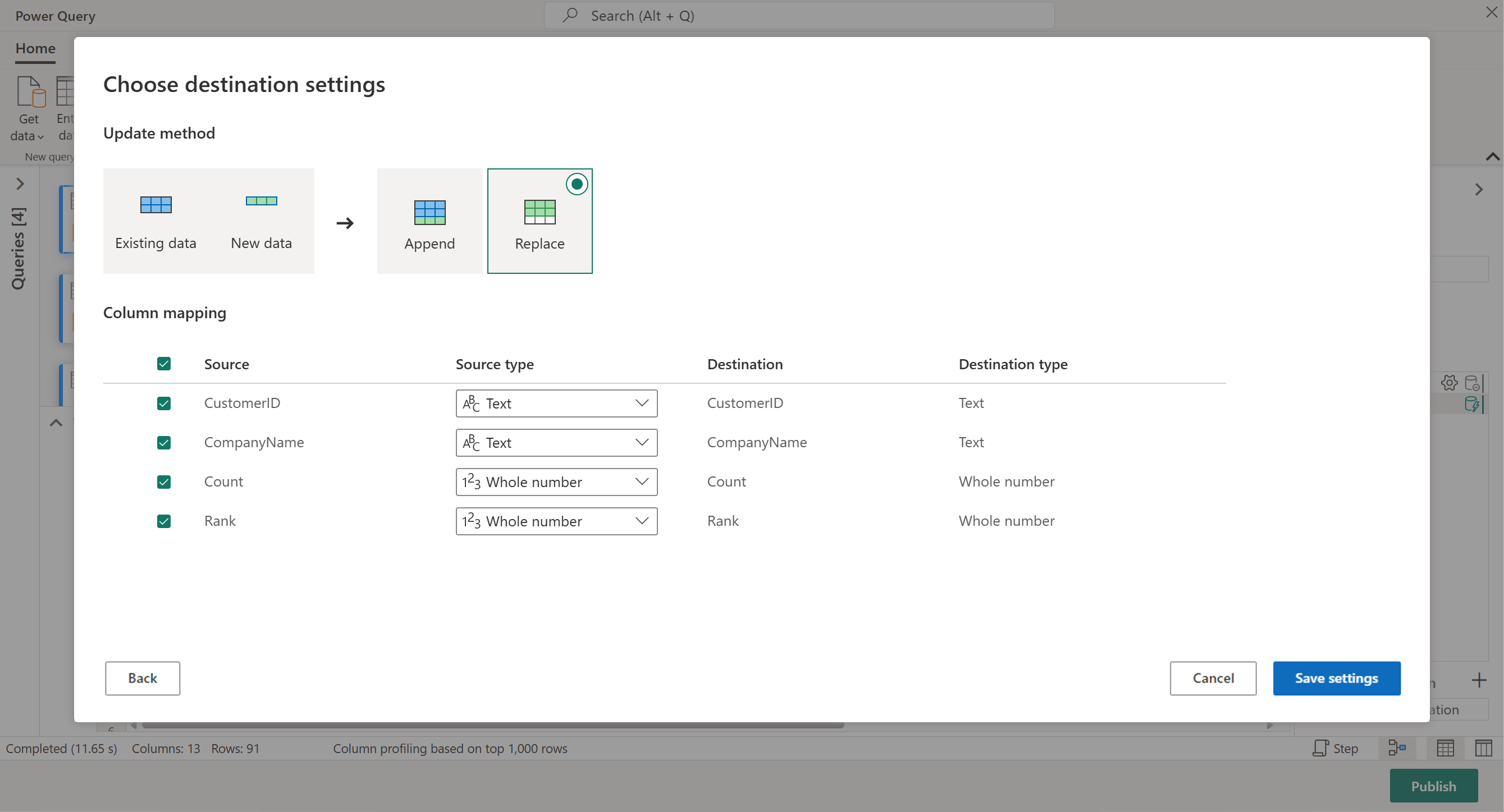
Ditt dataflöde är nu redo att publiceras. Granska frågorna i diagramvyn och välj sedan Publicera.
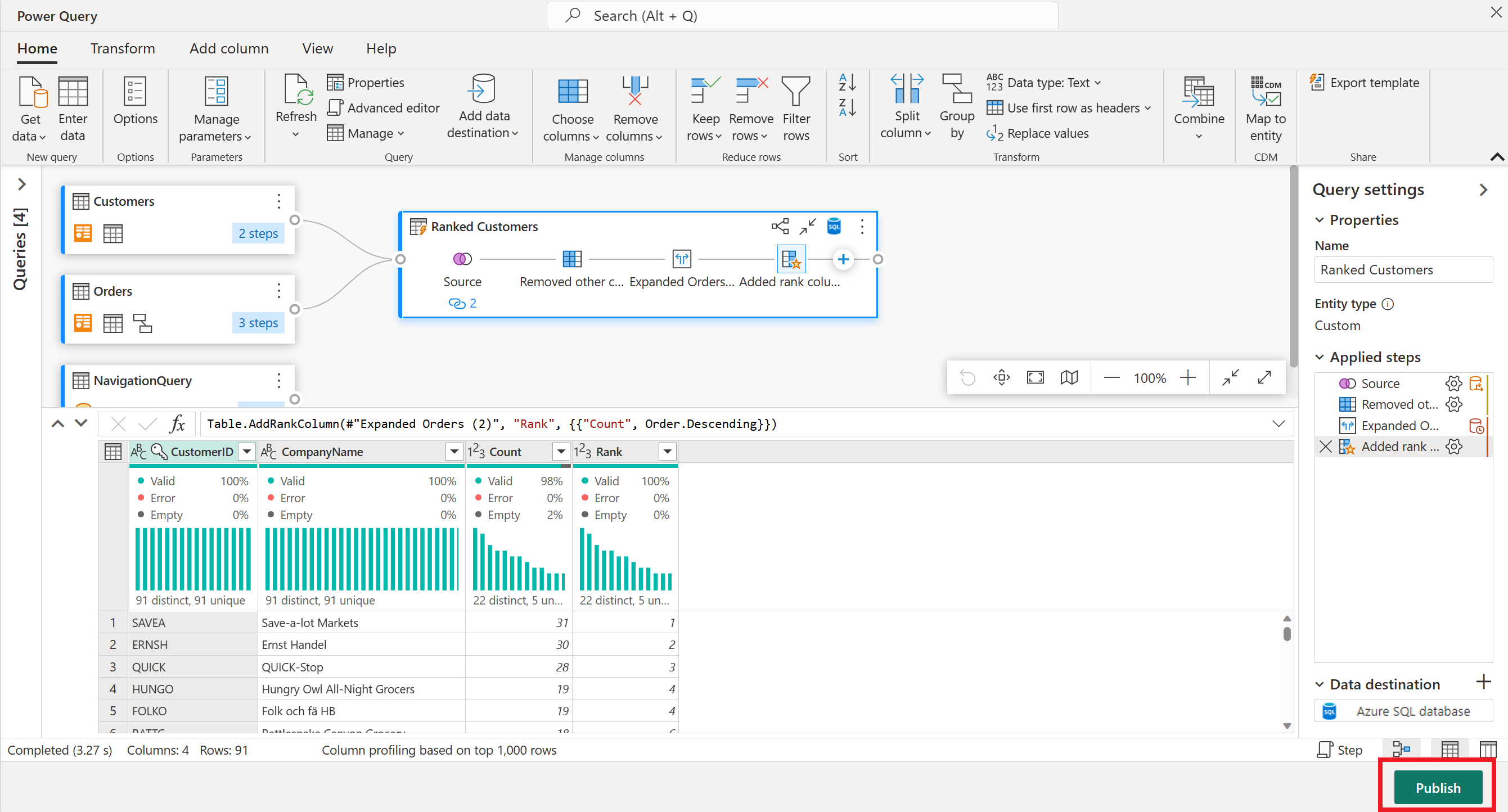
Välj Publicera i det nedre högra hörnet för att spara ditt dataflöde. Du går tillbaka till din arbetsyta, där en spinnikon bredvid ditt dataflödesnamn visar publiceringen. När spinnaren försvinner är ditt dataflöde redo att uppdateras!
Viktigt!
Första gången du skapar ett Dataflöde Gen2 på en arbetsyta Fabric konfigurerar vissa bakgrundsobjekt (Lakehouse och Warehouse) som hjälper ditt dataflöde att köras. Dessa objekt delas av alla dataflöden på arbetsytan och du bör inte ta bort dem. De är inte avsedda att användas direkt och är vanligtvis inte synliga på din arbetsyta, men du kan se dem på andra platser som Notebooks eller SQL-analys. Leta efter namn som börjar med
DataflowStagingför att upptäcka dem.På arbetsytan väljer du ikonen Schemalägg uppdatering .

Aktivera den schemalagda uppdateringen, välj Lägg till en annan tid och konfigurera uppdateringen enligt följande skärmbild.
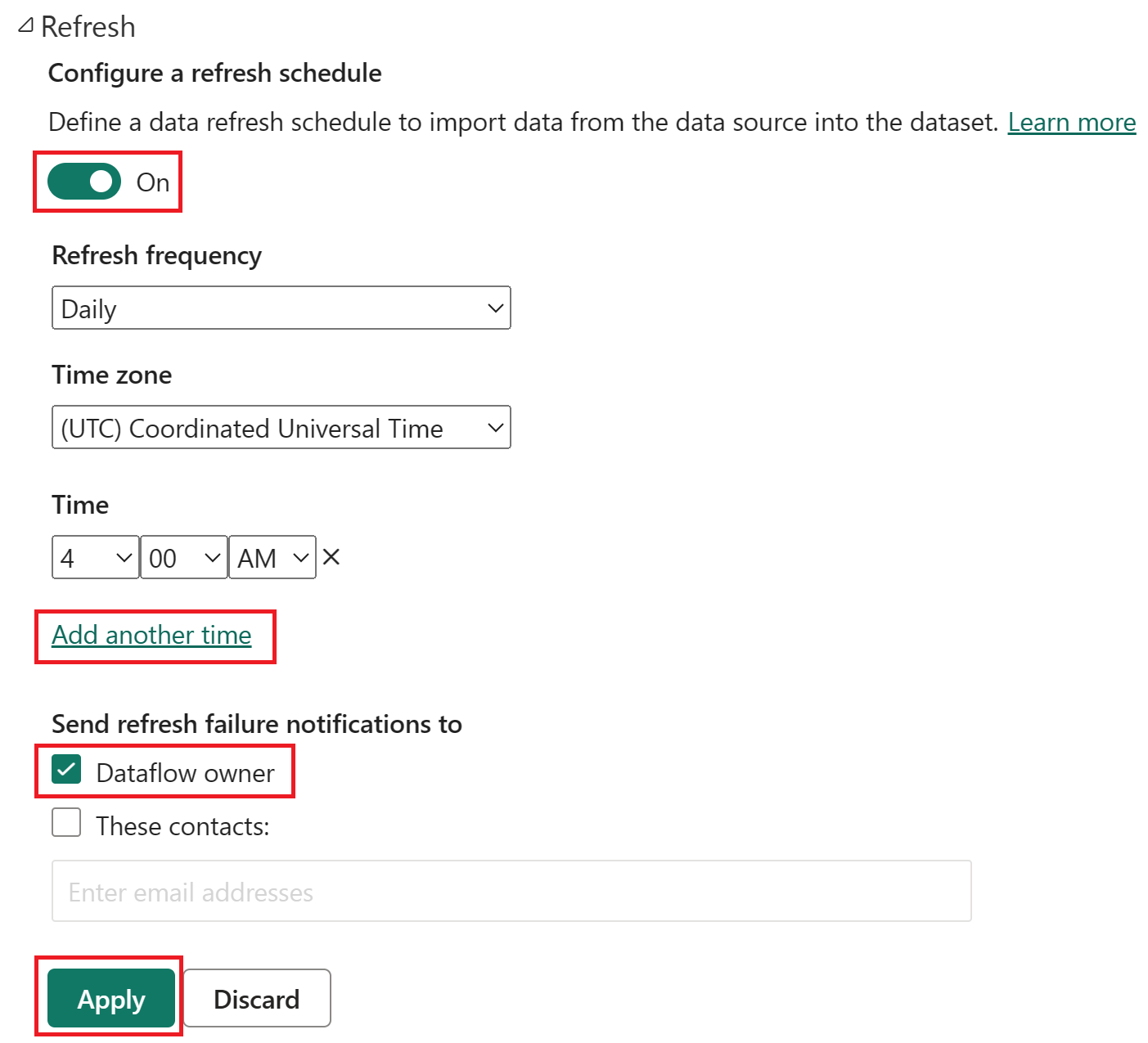
Skärmbild av alternativen för schemalagd uppdatering, med schemalagd uppdatering aktiverad, uppdateringsfrekvensen inställd på Daglig, Tidszon inställd på samordnad universell tid och Tid inställd på 04:00. På-knappen, lägg till ett ytterligare tidsval, dataflödesägaren och tillämpa-knappen framhävs.













Rensa resurser
Om du inte kommer att fortsätta att använda det här dataflödet tar du bort dataflödet med hjälp av följande steg:
Gå till din Microsoft Fabric arbetsyta.
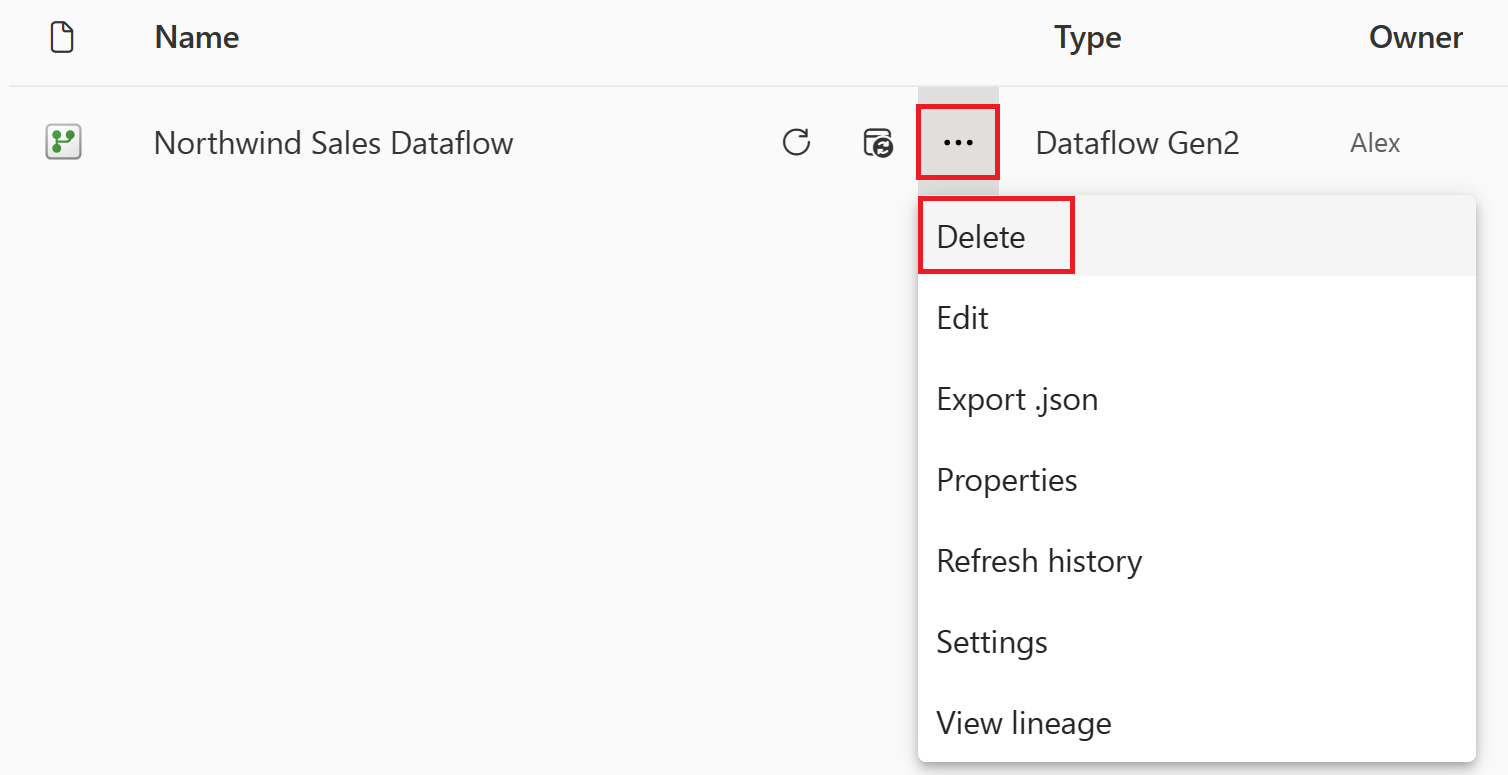
Välj den lodräta ellipsen bredvid namnet på dataflödet och välj sedan Ta bort.
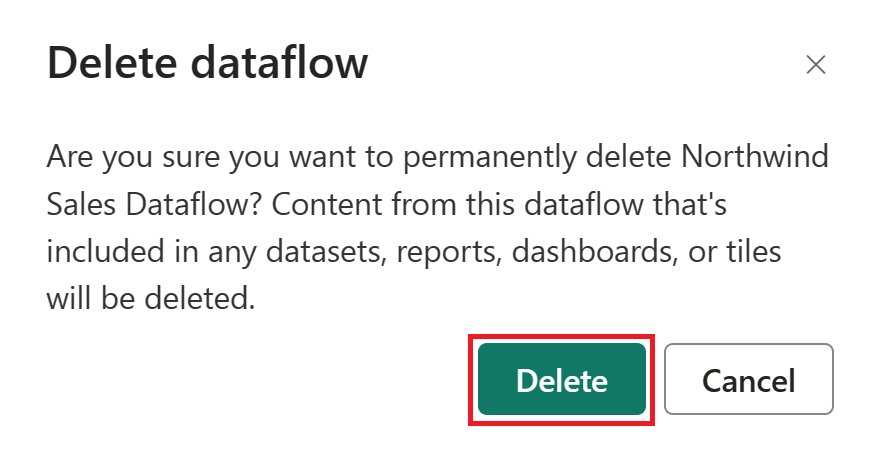
Välj Ta bort för att bekräfta borttagningen av dataflödet.
Relaterat innehåll
Dataflödet i det här exemplet visar hur du läser in och transformerar data i Dataflöde Gen2. Du har lärt dig att:
- Skapa ett Dataflöde Gen2.
- Transformera data.
- Konfigurera målinställningar för transformerade data.
- Kör igång och schemalägg din pipeline.
Gå vidare till nästa artikel för att lära dig hur du skapar din första pipeline.