Vägledning för sammansatt modell i Power BI Desktop
Den här artikeln riktar sig till datamodellerare som utvecklar sammansatta Power BI-modeller. Den beskriver användningsfall för sammansatta modeller och ger dig designvägledning. Mer specifikt kan vägledningen hjälpa dig att avgöra om en sammansatt modell är lämplig för din lösning. I så fall hjälper den här artikeln dig också att utforma optimala sammansatta modeller och rapporter.
Kommentar
En introduktion till sammansatta modeller beskrivs inte i den här artikeln. Om du inte är helt bekant med sammansatta modeller rekommenderar vi att du först läser artikeln Använd sammansatta modeller i Power BI Desktop .
Eftersom sammansatta modeller består av minst en DirectQuery-källa är det också viktigt att du har en grundlig förståelse för modellrelationer, DirectQuery-modeller och designvägledning för DirectQuery-modeller.
Användningsfall för sammansatt modell
Per definition kombinerar en sammansatt modell flera källgrupper. En källgrupp kan representera importerade data eller en anslutning till en DirectQuery-källa. En DirectQuery-källa kan vara antingen en relationsdatabas eller en annan tabellmodell, som kan vara en Power BI-semantisk modell (tidigare känd som en datauppsättning) eller en Analysis Services-tabellmodell. När en tabellmodell ansluter till en annan tabellmodell kallas den för länkning. Mer information finns i Använda DirectQuery för Power BI-semantiska modeller och Analysis Services.
Kommentar
När en modell ansluter till en tabellmodell men inte utökar den med ytterligare data är den inte en sammansatt modell. I det här fallet är det en DirectQuery-modell som ansluter till en fjärrmodell, så den består bara av en källgrupp. Du kan skapa den här typen av modell för att ändra egenskaper för källmodellobjekt, till exempel tabellnamn, kolumnsorteringsordning eller formatsträng.
Anslut till tabellmodeller är särskilt relevant när du utökar en företagssemantisk modell (när det är en Power BI-semantisk modell eller Analysis Services-modell). En företagssemantisk modell är grundläggande för utvecklingen och driften av ett informationslager. Det ger ett abstraktionslager över data i informationslagret för att presentera affärsdefinitioner och terminologi. Det används ofta som en länk mellan fysiska datamodeller och rapporteringsverktyg, till exempel Power BI. I de flesta organisationer hanteras det av ett centralt team, och därför beskrivs det som företag. Mer information finns i företags-BI-användningsscenariot .
Du kan överväga att utveckla en sammansatt modell i följande situationer.
- Din modell kan vara en DirectQuery-modell och du vill öka prestandan. I en sammansatt modell kan du förbättra prestanda genom att konfigurera lämplig lagring för varje tabell. Du kan också lägga till användardefinierade aggregeringar. Båda dessa optimeringar beskrivs senare i den här artikeln.
- Du vill kombinera en DirectQuery-modell med mer data, som måste importeras till modellen. Du kan läsa in importerade data från en annan datakälla eller från beräknade tabeller.
- Du vill kombinera två eller flera DirectQuery-datakällor till en enda modell. Dessa källor kan vara relationsdatabaser eller andra tabellmodeller.
Kommentar
Sammansatta modeller kan inte inkludera anslutningar till vissa externa analysdatabaser. Dessa databaser omfattar SAP Business Warehouse och SAP HANA när du behandlar SAP HANA som en flerdimensionell källa.
Utvärdera andra designalternativ för modeller
Power BI-sammansatta modeller kan lösa specifika designutmaningar, men de kan bidra till långsamma prestanda. I vissa situationer kan också oväntade beräkningsresultat uppstå (beskrivs senare i den här artikeln). Därför utvärderar du andra designalternativ för modellen när de finns.
När det är möjligt är det bäst att utveckla en modell i importläge. Det här läget ger den största designflex flexibiliteten och bästa prestanda.
Utmaningar som rör stora datavolymer eller rapportering av data i nära realtid kan dock inte alltid lösas med importmodeller. I något av dessa fall kan du överväga en DirectQuery-modell, förutsatt att dina data lagras i en enda datakälla som stöds av DirectQuery-läget. Mer information finns i DirectQuery-modeller i Power BI Desktop.
Dricks
Om ditt mål bara är att utöka en befintlig tabellmodell med mer data lägger du när det är möjligt till den befintliga datakällan.
Lagringsläge för tabell
I en sammansatt modell kan du ange lagringsläget för varje tabell (förutom beräknade tabeller).
- DirectQuery: Vi rekommenderar att du ställer in det här läget för tabeller som representerar stora datavolymer eller som behöver leverera resultat i nära realtid. Data importeras aldrig till dessa tabeller. Dessa tabeller är vanligtvis tabeller av faktatyp, som är tabeller som sammanfattas.
- Importera: Vi rekommenderar att du anger det här läget för tabeller som inte används för filtrering och gruppering av faktatabeller i DirectQuery- eller Hybridläge. Det är också det enda alternativet för tabeller baserade på källor som inte stöds av DirectQuery-läget. Beräknade tabeller är alltid importtabeller.
- Dubbla: Vi rekommenderar att du ställer in det här läget för tabeller av dimensionstyp när det finns en möjlighet att de efterfrågas tillsammans med DirectQuery-tabeller av faktatyp från samma källa.
- Hybrid: Vi rekommenderar att du anger det här läget genom att lägga till importpartitioner och en DirectQuery-partition i en faktatabell när du vill inkludera de senaste dataändringarna i realtid eller när du vill ge snabb åtkomst till de data som används oftast via importpartitioner samtidigt som du lämnar huvuddelen av mer sällan använda data i informationslagret.
Det finns flera möjliga scenarier när Power BI frågar en sammansatt modell.
- Frågor importerar endast eller dubbla tabeller: Power BI hämtar alla data från modellcachen. Det ger snabbast möjliga prestanda. Det här scenariot är vanligt för tabeller av dimensionstyp som efterfrågas av filter eller utsnittsvisualiseringar.
- Frågar dubbla tabeller eller DirectQuery-tabeller från samma källa: Power BI hämtar alla data genom att skicka en eller flera interna frågor till DirectQuery-källan. Det ger bra prestanda, särskilt när det finns lämpliga index i källtabellerna. Det här scenariot är vanligt för frågor som relaterar tabeller av dubbel dimensionstyp och DirectQuery-tabeller av faktatyp. Dessa frågor är inom källgruppen och därför utvärderas alla en-till-en-relationer eller en-till-många-relationer som vanliga relationer.
- Frågar dubbla tabeller eller hybridtabeller från samma källa: Det här scenariot är en kombination av de föregående två scenarierna. Power BI hämtar data från modellcachen när de är tillgängliga i importpartitioner, annars skickas en eller flera interna frågor till DirectQuery-källan. Det ger snabbast möjliga prestanda eftersom endast en del av data efterfrågas i informationslagret, särskilt när det finns lämpliga index i källtabellerna. När det gäller tabeller av dubbel dimensionstyp och DirectQuery-faktatyp är dessa frågor intrakällgrupper, och därför utvärderas alla en-till-en-relationer eller en-till-många-relationer som vanliga relationer.
- Alla andra frågor: Dessa frågor omfattar relationer mellan källgrupper. Det beror antingen på att en importtabell relaterar till en DirectQuery-tabell eller att en dubbel tabell relaterar till en DirectQuery-tabell från en annan källa, i vilket fall den fungerar som en importtabell. Alla relationer utvärderas som begränsade relationer. Det innebär också att grupper som tillämpas på icke-DirectQuery-tabeller måste skickas till DirectQuery-källan som materialiserade underfrågor (virtuella tabeller). I det här fallet kan den interna frågan vara ineffektiv, särskilt för stora grupperingsuppsättningar.
Sammanfattningsvis rekommenderar vi att du:
- Tänk noga på att en sammansatt modell är rätt lösning – även om den tillåter integrering på modellnivå av olika datakällor, introducerar den även designkomplexiteter med möjliga konsekvenser (beskrivs senare i den här artikeln).
- Ställ in lagringsläget på DirectQuery när en tabell är en tabell av faktatyp som lagrar stora datavolymer eller när den behöver leverera resultat i nära realtid.
- Överväg att använda hybridläge genom att definiera en inkrementell uppdateringsprincip och realtidsdata, eller genom att partitionera faktatabellen med hjälp av TOM, TMSL eller ett verktyg från tredje part. Mer information finns i Inkrementell uppdatering och realtidsdata för semantiska modeller och användningsscenariot för hantering av avancerade datamodeller.
- Ställ in lagringsläget på Dubbla när en tabell är en tabell av dimensionstyp, och den kommer att frågas tillsammans med DirectQuery- eller hybridtabeller av faktatyp som finns i samma källgrupp.
- Ange lämpliga uppdateringsfrekvenser för att hålla modellcachen för dubbla tabeller och hybridtabeller (och eventuella beroende beräknade tabeller) synkroniserade med källdatabaserna.
- Sträva efter att säkerställa dataintegritet mellan källgrupper (inklusive modellcachen) eftersom begränsade relationer eliminerar rader i frågeresultat när relaterade kolumnvärden inte matchar.
- När det är möjligt optimerar du DirectQuery-datakällor med lämpliga index för effektiva kopplingar, filtrering och gruppering.
Användardefinierade sammansättningar
Du kan lägga till användardefinierade aggregeringar i DirectQuery-tabeller. Syftet är att förbättra prestanda för frågor med högre kornighet .
När aggregeringar cachelagras i modellen fungerar de som importtabeller (även om de inte kan användas som en modelltabell). Om du lägger till importaggregeringar i en DirectQuery-modell resulterar det i en sammansatt modell.
Kommentar
Hybridtabeller stöder inte aggregeringar eftersom vissa partitioner fungerar i importläge. Det går inte att lägga till aggregeringar på nivån för en enskild DirectQuery-partition.
Vi rekommenderar att en aggregering följer en grundläggande regel: Antalet rader bör vara minst en faktor på 10 mindre än den underliggande tabellen. Om den underliggande tabellen till exempel lagrar 1 miljard rader bör sammansättningstabellen inte överstiga 100 miljoner rader. Den här regeln säkerställer att det finns en tillräcklig prestandavinst i förhållande till kostnaden för att skapa och underhålla aggregeringen.
Relationer mellan källgrupper
När en modellrelation sträcker sig över källgrupper kallas den för en korskällgruppsrelation. Relationer mellan källgrupper är också begränsade relationer eftersom det inte finns någon garanterad "en" sida. Mer information finns i Relationsutvärdering.
Kommentar
I vissa situationer kan du undvika att skapa en relation mellan källgrupper. Mer information finns i avsnittet Använd synkroniserings utsnitt senare i den här artikeln.
När du definierar relationer mellan källgrupper bör du överväga följande rekommendationer.
- Använd relationskolumner med låg kardinalitet: För bästa prestanda rekommenderar vi att relationskolumnerna har låg kardinalitet, vilket innebär att de bör lagra mindre än 50 000 unika värden. Den här rekommendationen gäller särskilt när du kombinerar tabellmodeller och för icke-textkolumner.
- Undvik att använda stora textrelationskolumner: Om du måste använda textkolumner i en relation beräknar du den förväntade textlängden för filtret genom att multiplicera kardinaliteten med den genomsnittliga längden på textkolumnen. Den möjliga textlängden får inte överstiga 1 000 000 tecken.
- Öka relationens kornighet: Skapa om möjligt relationer på en högre kornighetsnivå. Använd till exempel månadsnyckeln i stället för att relatera en datumtabell för dess datumnyckel. Den här designmetoden kräver att den relaterade tabellen innehåller en månadsnyckelkolumn och att rapporter inte kan visa dagliga fakta.
- Sträva efter att uppnå en enkel relationsdesign: Skapa bara en korskällgruppsrelation när den behövs och försök att begränsa antalet tabeller i relationssökvägen. Den här designmetoden hjälper till att förbättra prestanda och undvika tvetydiga relationssökvägar.
Varning
Eftersom Power BI Desktop inte verifierar relationer mellan källgrupper är det möjligt att skapa tvetydiga relationer.
Relationsscenario för korskällgrupp 1
Överväg ett scenario med en komplex relationsdesign och hur den kan ge olika– men giltiga – resultat.
I det här scenariot har tabellen Region i källgruppen A en relation till tabellen Datum och tabellen Försäljning i källgrupp B. Relationen mellan tabellen Region och tabellen Datum är aktiv, medan relationen mellan tabellen Region och tabellen Försäljning är inaktiv. Det finns också en aktiv relation mellan tabellen Region och tabellen Försäljning , som båda finns i källgrupp B. Tabellen Försäljning innehåller ett mått med namnet TotalSales och tabellen Region innehåller två mått med namnet RegionalSales och RegionalSalesDirect.
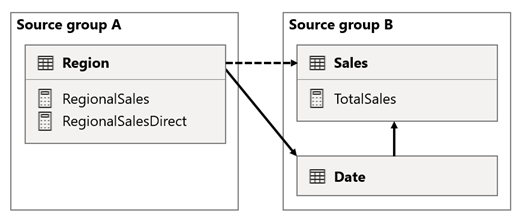
Här är måttdefinitionerna.
TotalSales = SUM(Sales[Sales])
RegionalSales = CALCULATE([TotalSales], USERELATIONSHIP(Region[RegionID], Sales[RegionID]))
RegionalSalesDirect = CALCULATE(SUM(Sales[Sales]), USERELATIONSHIP(Region[RegionID], Sales[RegionID]))
Observera hur måttet RegionalSales refererar till måttet TotalSales , medan måttet RegionalSalesDirect inte gör det. I stället använder måttet RegionalSalesDirect uttrycket SUM(Sales[Sales]), som är uttrycket för måttet TotalSales .
Skillnaden i resultatet är subtil. När Power BI utvärderar måttet RegionalSales tillämpas filtret från tabellen Region på både tabellen Försäljning och tabellen Datum . Därför sprids filtret också från tabellen Datum till tabellen Försäljning . När Power BI däremot utvärderar måttet RegionalSalesDirect sprids endast filtret från tabellen Region till tabellen Försäljning . Resultaten som returneras av RegionalSales-måttet och RegionalSalesDirect-måttet kan skilja sig åt, även om uttrycken är semantiskt likvärdiga.
Viktigt!
Testa beräkningsresultaten CALCULATE noggrant när du använder funktionen med ett uttryck som är ett mått i en fjärrkällagrupp.
Relationsscenario för korskällgrupp 2
Tänk dig ett scenario när en korskällgruppsrelation har relationskolumner med hög kardinalitet.
I det här scenariot är tabellen Datum relaterad till tabellen Försäljning i DateKey-kolumnerna. Datatypen för DateKey-kolumnerna är heltal och lagrar heltal som använder yyyymmdd-formatet . Tabellerna tillhör olika källgrupper. Dessutom är det en relation med hög kardinalitet eftersom det tidigaste datumet i tabellen Datum är 1 januari 1900 och det senaste datumet är den 31 december 2100, så det finns totalt 73 414 rader i tabellen (en rad för varje datum under tidsperioden 1900–2100).
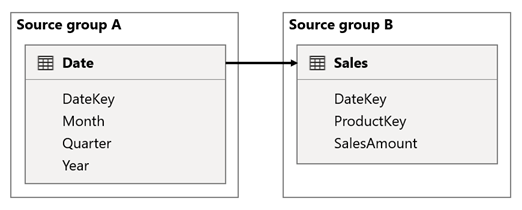
Det finns två problem.
När du först använder datumtabellkolumnerna som filter filtrerar filterspridning kolumnen DateKey i tabellen Försäljning för att utvärdera mått. Vid filtrering efter ett enda år, till exempel 2022, innehåller DAX-frågan ett filteruttryck som Sales[DateKey] IN { 20220101, 20220102, …20221231 }. Frågans textstorlek kan bli mycket stor när antalet värden i filteruttrycket är stort eller när filtervärdena är långa strängar. Det är dyrt för Power BI att generera den långa frågan och att datakällan kör frågan.
För det andra, när du använder datumtabellkolumner, till exempel År, Kvartal eller Månad, som grupperingskolumner, resulterar det i filter som innehåller alla unika kombinationer av år, kvartal eller månad ochdatekey-kolumnvärdena. Strängstorleken för frågan, som innehåller filter för grupperingskolumnerna och relationskolumnen, kan bli extremt stor. Detta gäller särskilt när antalet grupperingskolumner och/eller kardinaliteten för kopplingskolumnen (Kolumnen DateKey ) är stor.
För att åtgärda eventuella prestandaproblem kan du:
- Lägg till tabellen Datum i datakällan, vilket resulterar i en enda källgruppsmodell (vilket innebär att den inte längre är en sammansatt modell).
- Öka relationens kornighet. Du kan till exempel lägga till en MonthKey-kolumn i båda tabellerna och skapa relationen för dessa kolumner. Men genom att öka relationens kornighet förlorar du möjligheten att rapportera om den dagliga försäljningsaktiviteten (om du inte använder kolumnen DateKey från tabellen Försäljning ).
Relationsscenario för korskällgrupp 3
Tänk dig ett scenario när det inte finns matchande värden mellan tabeller i en grupprelation mellan källor.
I det här scenariot har tabellen Datum i källgruppen B en relation till tabellen Sales i den källgruppen och även till tabellen Target i källgrupp A. Alla relationer är en-till-många från tabellen Datum som relaterar kolumnerna År . Tabellen Försäljning innehåller en SalesAmount-kolumn som lagrar försäljningsbelopp, medan tabellen Target innehåller en TargetAmount-kolumn som lagrar målbelopp.
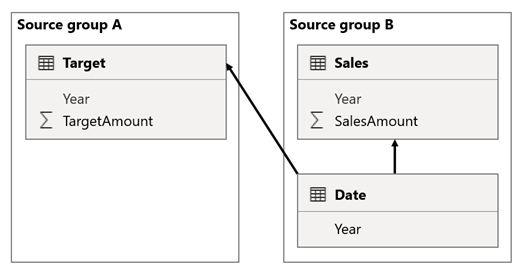
Tabellen Datum lagrar åren 2021 och 2022. Tabellen Försäljning lagrar försäljningsbelopp för år 2021 (100) och 2022 (200), medan måltabellenlagrar målbelopp för 2021 (100), 2022 (200) och 2023 (300)– ett kommande år.
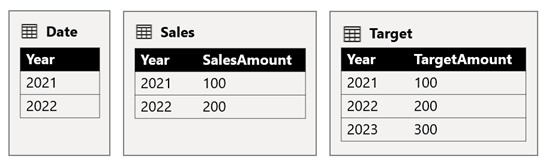
När ett visuellt Power BI-tabellobjekt frågar den sammansatta modellen genom att gruppera på kolumnen Year från tabellen Date och summera kolumnerna SalesAmount och TargetAmount visas inte ett målbelopp för 2023. Det beror på att relationen mellan källgrupper är en begränsad relation och därför använder INNER JOIN den semantik, vilket eliminerar rader där det inte finns något matchande värde på båda sidor. Det ger dock ett korrekt målbelopp totalt (600), eftersom ett datumtabellfilter inte gäller för utvärderingen.
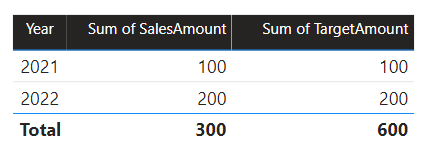
Om relationen mellan tabellen Datum och tabellen Mål är en relation mellan källgruppen (förutsatt att måltabellen tillhör källgrupp B) innehåller det visuella objektet ett (tomt) år för att visa målbeloppet för 2023 (och andra omatchade år).
Viktigt!
Undvik felrapportering genom att se till att det finns matchande värden i relationskolumnerna när dimensions- och faktatabeller finns i olika källgrupper.
Mer information om begränsade relationer finns i Relationsutvärdering.
Beräkningar
Du bör överväga specifika begränsningar när du lägger till beräknade kolumner och beräkningsgrupper i en sammansatt modell.
Beräknade kolumner
Beräknade kolumner som läggs till i en DirectQuery-tabell som hämtar sina data från en relationsdatabas, till exempel Microsoft SQL Server, är begränsade till uttryck som körs på en enda rad i taget. Dessa uttryck kan inte använda DAX-iteratorfunktioner som SUMX, eller filterkontextändringsfunktioner, till exempel CALCULATE.
Kommentar
Det går inte att lägga till beräknade kolumner eller beräknade tabeller som är beroende av länkade tabellmodeller.
Ett beräknat kolumnuttryck i en directquery-fjärrtabell begränsas endast till utvärdering inom rad. Du kan dock skapa ett sådant uttryck, men det resulterar i ett fel när det används i ett visuellt objekt. Om du till exempel lägger till en beräknad kolumn i en directquery-fjärrtabell med namnet DimProduct med uttrycket [Product Sales] / SUM (DimProduct[ProductSales])kan du spara uttrycket i modellen. Det resulterar dock i ett fel när det används i ett visuellt objekt eftersom det bryter mot begränsningen för utvärdering inom rad.
Däremot är beräknade kolumner som lagts till i en directquery-fjärrtabell som är en tabellmodell, som antingen är en Power BI-semantisk modell eller Analysis Services-modell, mer flexibla. I det här fallet tillåts alla DAX-funktioner eftersom uttrycket utvärderas i källfliksmodellen.
Många uttryck kräver att Power BI materialiserar den beräknade kolumnen innan den används som en grupp eller ett filter eller aggregerar den. När en beräknad kolumn materialiseras över en stor tabell kan den vara kostsam när det gäller processor och minne, beroende på kardinaliteten för de kolumner som den beräknade kolumnen är beroende av. I det här fallet rekommenderar vi att du lägger till de beräknade kolumnerna i källmodellen.
Kommentar
När du lägger till beräknade kolumner i en sammansatt modell bör du testa alla modellberäkningar. Överordnade beräkningar kanske inte fungerar korrekt eftersom de inte tog hänsyn till deras påverkan på filterkontexten.
Beräkningsgrupper
Om beräkningsgrupper finns i en källgrupp som ansluter till en Power BI-semantisk modell eller en Analysis Services-modell kan Power BI returnera oväntade resultat. Mer information finns i Beräkningsgrupper , fråge- och måttutvärdering.
Modelldesign
Du bör alltid optimera en Power BI-modell genom att använda en star-schemadesign.
Dricks
Mer information finns i Förstå star-schema och vikten för Power BI.
Se till att skapa dimensionstabeller som är separata från faktatabeller så att Power BI kan tolka kopplingar korrekt och skapa effektiva frågeplaner. Även om den här vägledningen gäller för alla Power BI-modeller gäller det särskilt för modeller som du känner igen blir en källgrupp för en sammansatt modell. Det möjliggör enklare och effektivare integrering av andra tabeller i underordnade modeller.
Undvik när det är möjligt att ha dimensionstabeller i en källgrupp som är relaterade till en faktatabell i en annan källgrupp. Det beror på att det är bättre att ha relationer mellan källgrupper än relationer mellan källgrupper, särskilt för kolumner med hög kardinalitetsrelation. Som tidigare beskrivits förlitar sig relationer mellan källgrupper på att ha matchande värden i relationskolumnerna, annars kan oväntade resultat visas i visuella rapportobjekt.
Säkerhet på radnivå
Om din modell innehåller användardefinierade aggregeringar, beräknade kolumner i importtabeller eller beräknade tabeller kontrollerar du att alla säkerheter på radnivå (RLS) har konfigurerats korrekt och testats.
Om den sammansatta modellen ansluter till andra tabellmodeller tillämpas RLS-regler endast på den källgrupp (lokal modell) där de definieras. De tillämpas inte på andra källgrupper (fjärrmodeller). Du kan inte heller definiera RLS-regler i en tabell från en annan källgrupp och du kan inte heller definiera RLS-regler i en lokal tabell som har en relation till en annan källgrupp.
Rapportdesign
I vissa situationer kan du förbättra prestandan för en sammansatt modell genom att utforma en optimerad rapportlayout.
Visuella objekt med en källgrupp
När det är möjligt skapar du visuella objekt som använder fält från en enda källgrupp. Det beror på att frågor som genereras av visuella objekt presterar bättre när resultatet hämtas från en enda källgrupp. Överväg att skapa två visuella objekt placerade sida vid sida som hämtar data från två olika källgrupper.
Använda synkroniserings utsnitt
I vissa situationer kan du konfigurera synkroniseringsutsnitt för att undvika att skapa en relation mellan källgrupper i din modell. Det kan göra att du kan kombinera källgrupper visuellt som kan fungera bättre.
Tänk dig ett scenario när din modell har två källgrupper. Varje källgrupp har en produktdimensionstabell som används för att filtrera återförsäljare och internetförsäljning.
I det här scenariot innehåller källgrupp A tabellen Produkt som är relaterad till tabellen ResellerSales. Källgrupp B innehåller tabellen Product2 som är relaterad till tabellen InternetSales . Det finns inga relationer mellan källgrupper.
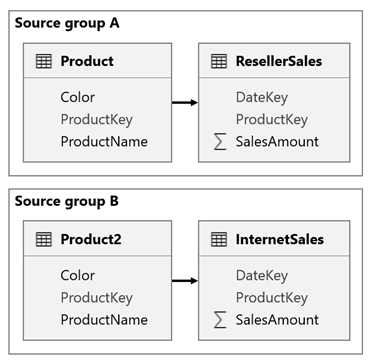
I rapporten lägger du till ett utsnitt som filtrerar sidan med hjälp av kolumnen Färg i tabellen Produkt . Som standard filtrerar utsnittet tabellen ResellerSales , men inte tabellen InternetSales . Sedan lägger du till ett dolt utsnitt med hjälp av kolumnen Färg i tabellen Product2 . Genom att ange ett identiskt gruppnamn (som finns i synkroniseringsutsnitten Avancerade alternativ) sprids filter som tillämpas på det synliga utsnittet automatiskt till det dolda utsnittet.
Kommentar
När du använder synkroniseringsutsnitt kan du undvika behovet av att skapa en korskällgruppsrelation, men det ökar komplexiteten i modelldesignen. Var noga med att utbilda andra användare om varför du har utformat modellen med dubbla dimensionstabeller. Undvik förvirring genom att dölja dimensionstabeller som du inte vill att andra användare ska använda. Du kan också lägga till beskrivningstext i de dolda tabellerna för att dokumentera deras syfte.
Mer information finns i Synkronisera separata utsnitt.
Annan vägledning
Här är några andra riktlinjer som hjälper dig att utforma och underhålla sammansatta modeller.
- Prestanda och skalning: Om dina rapporter tidigare var liveanslutna till en Power BI-semantisk modell eller Analysis Services-modell kan Power BI-tjänst återanvända visuella cacheminnen i rapporter. När du har konverterat live-anslutningen för att skapa en lokal DirectQuery-modell kommer rapporterna inte längre att dra nytta av dessa cacheminnen. Därför kan du uppleva långsammare prestanda eller till och med uppdateringsfel. Dessutom ökar arbetsbelastningen för Power BI-tjänst, vilket kan kräva att du skalar upp din kapacitet eller distribuerar arbetsbelastningen över andra kapaciteter. Mer information om datauppdatering och cachelagring finns i Datauppdatering i Power BI.
- Byt namn: Vi rekommenderar inte att du byter namn på semantiska modeller som används av sammansatta modeller eller byter namn på deras arbetsytor. Det beror på att sammansatta modeller ansluter till Power BI-semantiska modeller med hjälp av arbetsytan och semantiska modellnamn (och inte deras interna unika identifierare). Att byta namn på en semantisk modell eller arbetsyta kan bryta de anslutningar som används av din sammansatta modell.
- Styrning: Vi rekommenderar inte att din enda version av sanningsmodellen är en sammansatt modell. Det beror på att det skulle vara beroende av andra datakällor eller modeller, vilket om det uppdateras kan leda till att den sammansatta modellen bryts. I stället rekommenderar vi att du publicerar en företagssemantisk modell som en enda version av sanningen. Betrakta den här modellen som en tillförlitlig grund. Andra datamodellerare kan sedan skapa sammansatta modeller som utökar grundmodellen för att skapa specialiserade modeller.
- Data härkomst: Använd funktionerna för data härkomst och semantisk modellpåverkan innan du publicerar ändringar i sammansatta modeller. Dessa funktioner är tillgängliga i Power BI-tjänst, och de kan hjälpa dig att förstå hur semantiska modeller är relaterade och används. Det är viktigt att förstå att du inte kan utföra påverkansanalyser på externa semantiska modeller som visas i ursprungsvyn men som faktiskt finns på en annan arbetsyta. Om du vill utföra påverkansanalys på en extern semantisk modell måste du navigera till källarbetsytan.
- Schemauppdateringar: Du bör uppdatera din sammansatta modell i Power BI Desktop när schemaändringar görs i överordnade datakällor. Sedan måste du publicera om modellen till Power BI-tjänst. Se till att noggrant testa beräkningar och beroende rapporter.
Relaterat innehåll
Mer information om den här artikeln finns i följande resurser.
- Använda sammansatta modeller i Power BI Desktop
- Modellrelationer i Power BI Desktop
- DirectQuery-modeller i Power BI Desktop
- Använda DirectQuery i Power BI Desktop
- Använda DirectQuery för Power BI-semantiska modeller och Analysis Services
- Lagringsläge i Power BI Desktop
- Användardefinierade sammansättningar
- Frågor? Prova att fråga Power BI Community
- Förslag? Bidra med idéer för att förbättra Power BI
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för