適用於: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
提示
Data Factory in Microsoft Fabric 是下一代的 Azure Data Factory,擁有更簡單的架構、內建 AI 及新功能。 如果你是資料整合新手,建議先從 Fabric Data Factory 開始。 現有的 ADF 工作負載可升級至 Fabric,以存取資料科學、即時分析與報告等新能力。
本文說明如何在 Azure Data Factory 和 Azure Synapse 管線中使用複製活動,將資料從 SQL Server 資料庫複製到,並使用 Data Flow 轉換 SQL Server 資料庫中的資料。 想了解更多,請閱讀Azure Data Factory或Azure Synapse Analytics的介紹文章。
注意
此連接器也可在 Microsoft Fabric 的 Data Factory 中取得。 關於Fabric專屬的配置與功能,請參閱 Fabric SQL Server 連接器文件。
支援的功能
此 SQL Server 連接器支援以下功能:
| 支援的功能 | IR |
|---|---|
| 複製活動 (來源/接收) | (1) (2) |
| 映射資料流 (來源/匯入) | 1. |
| 查找活動 | (1) (2) |
| GetMetadata 活動 | (1) (2) |
| 指令碼活動 | (1) (2) |
| 預存程序活動 | (1) (2) |
(1) Azure 整合執行時 (2) 自架整合執行時
如需複製活動所支援作為來源或接收器的資料存放區清單,請參閱支援的資料存放區表格。
具體來說,這個 SQL Server 連接器支援:
- SQL Server 版本 2005 及以上。
- 使用 SQL 或 Windows 驗證 複製資料。
- 作為來源時,使用 SQL 查詢或預存程序來擷取資料。 你也可以選擇從SQL Server來源平行複製,詳情請參見 從 SQL 資料庫 平行複製章節。
- 作為接收器,如果目的地資料表不存在,則會根據來源架構自動建立;在複製期間會將資料附加至資料表,或叫用具有自訂邏輯的預存程序。
SQL Server Express LocalDB 不被支援。
重要
資料來源必須支援 NVARCHAR 資料類型,因為在資料上套用非通用編碼時,該類型會影響資料編碼。
必要條件
如果你的資料儲存位於本地網路、Azure虛擬網路或亞馬遜虛擬私人雲中,你需要配置一個自架整合執行時來連接它。
如果你的資料儲存是雲端管理型資料服務,你可以使用Azure Integration Runtime。 如果存取權限限制在防火牆規則中核准的 IP,你可以將 Azure Integration Runtime IPs 加入允許清單。
你也可以在 Azure Data Factory 中使用 managed 虛擬網路整合執行時功能,無需安裝和設定自架整合執行環境即可存取本地網路。
如需 Data Factory 支援的網路安全性機制和選項的詳細資訊,請參閱資料存取策略。
開始
若要使用管線執行複製活動,您可以使用下列其中一個工具或 SDK:
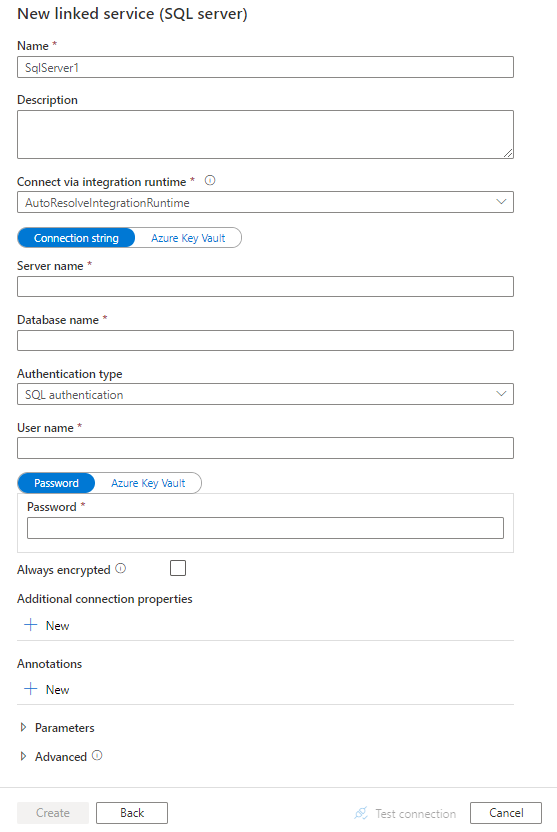
使用 UI 建立一個 SQL Server 連結服務
請依照以下步驟在 Azure 入口網站介面中建立一個與 SQL Server 連結的服務。
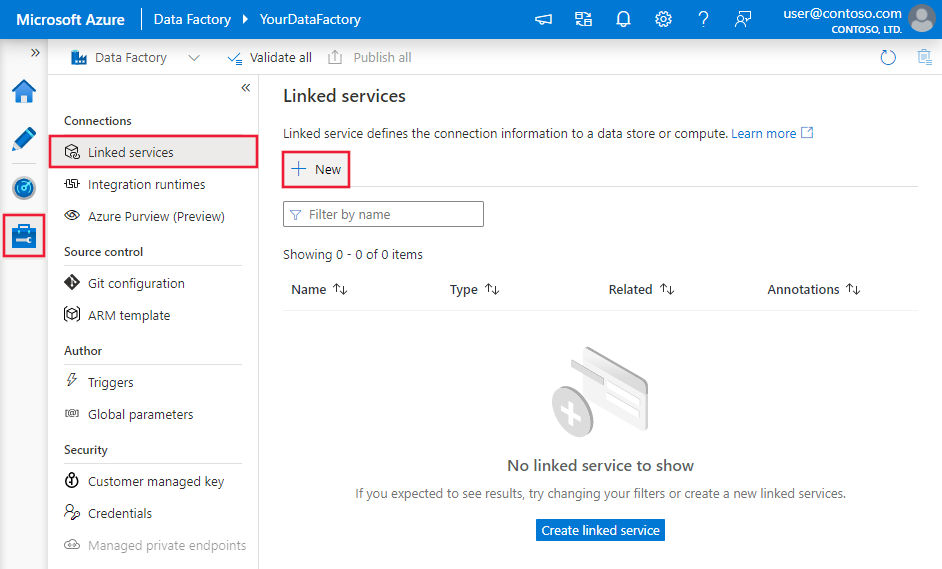
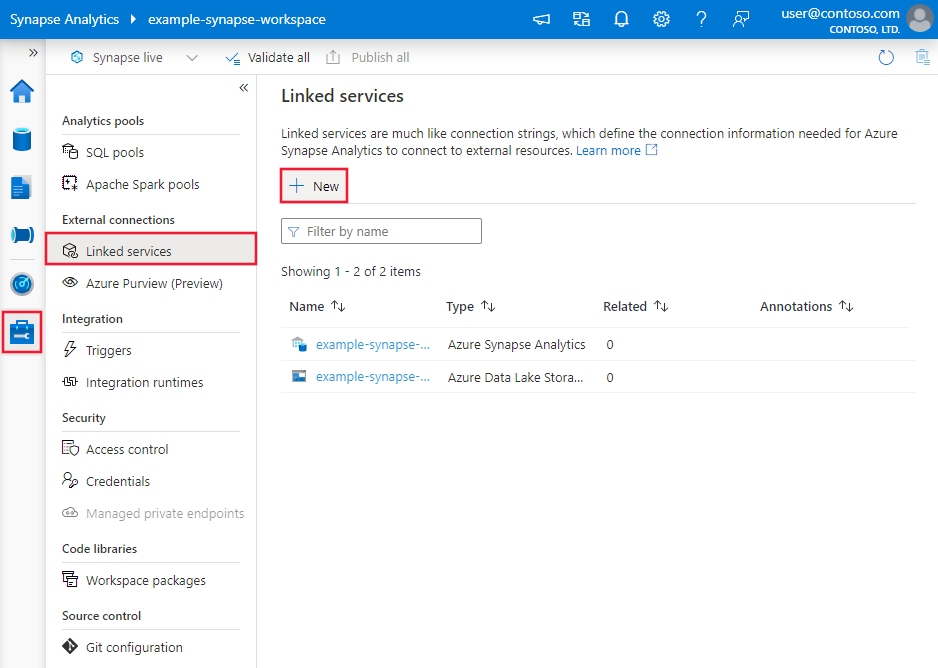
請瀏覽 Azure Data Factory 或 Synapse 工作區的管理標籤,選擇連結服務,然後點選新建:
搜尋 SQL,並選擇 SQL Server 連接器。

設定服務詳細資料,測試連線,然後建立新的連結服務。
連接器設定詳細資料
以下章節將詳細說明用於定義 SQL Server 資料庫連接器特定資料工廠與 Synapse 管線實體的屬性。
連結服務屬性
SQL Server Recommended 版本支援 TLS 1.3。 如果你使用 Legacy版本,請參考此 section 來升級你的 SQL Server 連結服務。 如需屬性詳細資料,請參閱對應的章節。
提示
如果你遇到錯誤代碼「UserErrorFailedToConnectToSqlServer」,且訊息如「資料庫的會話限制是 XXX 且已達成」,請在連接字串中加上 Pooling=false 再試一次。
建議的版本
當您套用建議版本時,SQL Server 連結服務支援下列泛型屬性:
| 屬性 | 描述 | 必要 |
|---|---|---|
| 型別 | 類型屬性必須設定為 SqlServer。 | Yes |
| 伺服器 | 您想要連線的 SQL Server 執行個體名稱或其網路位址。 | Yes |
| 資料庫 | 資料庫的名稱。 | Yes |
| 認證類型 | 用於驗證的類型。 允許的值為 SQL(預設)、Windows 以及 UserAssignedManagedIdentity(僅限於Azure虛擬機上的 SQL Server)。 移至特定屬性和必要條件的相關驗證一節。 | Yes |
| 始終加密設置 | 指定 alwaysencryptedsettings 資訊,讓 Always Encrypted 能夠使用受控身分識別或服務主體來保護儲存在 SQL Server 的敏感性資料。 如需詳細資訊,請參閱表格下方的 JSON 範例和使用 Always Encrypted 一節。 如果未指定,則會停用預設的一律加密設定。 | No |
| 加密 | 指出用戶端與伺服器之間傳送的所有資料是否都需要 TLS 加密。 選項:強制 (若為 true,預設值)/選擇性 (若為 false)/strict。 | No |
| trustServerCertificate | 指出通道是否會加密,同時略過驗證信任的憑證鏈結。 | No |
| 證書中的主機名 | 針對連線驗證伺服器憑證時要使用的主機名稱。 未指定時,伺服器名稱會用於憑證驗證。 | No |
| connectVia | 這個整合執行階段用於連接到資料存放區。 深入了解必要條件一節。 若未指定,則使用預設的 Azure 整合執行環境。 | No |
如需其他連線屬性,請參閱下表:
| 屬性 | 描述 | 必要 |
|---|---|---|
| 應用程序意圖 | 連線至伺服器時的應用程式工作負載類型。 允許值為:ReadOnly 和 ReadWrite。 |
No |
| connectTimeout | 等待連接到伺服器的時間長度(以秒為單位),在達到此時限後將終止嘗試並產生錯誤。 | No |
| connectRetryCount | 識別到閒置連線失敗之後,嘗試重新連線的次數。 此值應為介於 0 到 255 之間的整數。 | No |
| connectRetryInterval | 識別閒置連線失敗之後,每次重新連線嘗試之間的時間 (以秒為單位)。 此值應為介於 1 到 60 之間的整數。 | No |
| loadBalanceTimeout | 在連線終結之前,連線在連線集區中存在的最短時間 (以秒為單位)。 | No |
| commandTimeout | 終止嘗試執行命令並產生錯誤之前的預設等候時間 (以秒為單位)。 | No |
| integratedSecurity | 允許的值為 true 或 false。 指定 false 時,指出是否已在連線中指定 userName 和 password。 在指定 true 時,表示是否使用目前的Windows帳號憑證進行驗證。 |
No |
| failoverPartner | 當主要伺服器關閉時,應連線的合作夥伴伺服器名稱或位址。 | No |
| 最大池大小 | 特定連線的連線集區中允許的連線數目上限。 | No |
| minPoolSize (最小池大小) | 特定連線的連線集區中允許的連線數目下限。 | No |
| 多重主動結果集 (multipleActiveResultSets) | 允許的值為 true 或 false。 當您指定 true 時,應用程式可以維護多個使用中結果集 (MARS)。 當您指定 false 時,應用程式必須先處理或取消一個批次的所有結果集,才能在該連線上執行任何其他批次。 |
No |
| multiSubnetFailover | 允許的值為 true 或 false。 如果您的應用程式連線至不同子網路上的 AlwaysOn 可用性群組 (AG),則將此屬性設定為 true 可以更快地偵測並連線到目前使用中的伺服器。 |
No |
| 封包大小 (packetSize) | 用來與伺服器執行個體通訊的網路封包大小 (位元組)。 | No |
| 共用 | 允許的值為 true 或 false。 當您指定 true 時,連線會是集區式連線。 當您指定 false 時,每次要求連線時都會明確開啟連線。 |
No |
SQL 驗證
若要使用 SQL 驗證,除了上一節所述的泛型屬性外,請指定下列屬性:
| 屬性 | 描述 | 必要 |
|---|---|---|
| userName | 連線到伺服器時要使用的使用者名稱。 | Yes |
| 密碼 | 使用者名稱的密碼。 將此欄位標記為 SecureString 以將其安全地儲存。 或者,你可以引用儲存在 Azure Key Vault 中的秘密。 | No |
範例:使用 SQL 驗證
{
"name": "SqlServerLinkedService",
"properties": {
"type": "SqlServer",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "SQL",
"userName": "<user name>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
範例:使用 SQL 認證並設定密碼為 Azure Key Vault
{
"name": "SqlServerLinkedService",
"properties": {
"type": "SqlServer",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "SQL",
"userName": "<user name>",
"password": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
範例:使用 Always Encrypted
{
"name": "SqlServerLinkedService",
"properties": {
"type": "SqlServer",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "SQL",
"userName": "<user name>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"alwaysEncryptedSettings": {
"alwaysEncryptedAkvAuthType": "ServicePrincipal",
"servicePrincipalId": "<service principal id>",
"servicePrincipalKey": {
"type": "SecureString",
"value": "<service principal key>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Windows 驗證
要使用 Windows 驗證,除了前節所述的一般屬性外,還需指定以下屬性:
| 屬性 | 描述 | 必要 |
|---|---|---|
| userName | 指定使用者名稱。 範例為 domainname\username。 | Yes |
| 密碼 | 指定您為使用者名稱所指定之使用者帳戶的密碼。 將此欄位標記為 SecureString 以將其安全地儲存。 或者,你可以引用儲存在 Azure Key Vault 中的秘密。 | Yes |
注意
Windows 驗證不支援於資料流中。
範例:使用 Windows 驗證
{
"name": "SqlServerLinkedService",
"properties": {
"type": "SqlServer",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "Windows",
"userName": "<domain\\username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
範例:使用Windows 驗證,密碼設於 Azure Key Vault
{
"name": "SqlServerLinkedService",
"properties": {
"annotations": [],
"type": "SqlServer",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "Windows",
"userName": "<domain\\username>",
"password": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
使用者指定的受控身分識別驗證
注意
使用者指派的管理的身份驗證僅適用於 Azure 虛擬機上的 SQL Server 。
資料工廠或 Synapse 工作區可以與由 user 指派的管理身份 綁定,該身份在 Azure 中驗證其他資源時代表該服務。 你可以用這個管理身份來為Azure 虛擬機器上的 SQL Server進行身份驗證。 指定的處理站或 Synapse 工作區,可以使用此識別身分,從您的資料庫存取並複製資料,或將資料複製到您的資料庫。
若要使用使用者指派的受控識別驗證,除了上一節所述的一般屬性外,請指定下列屬性:
| 屬性 | 描述 | 必要 |
|---|---|---|
| 憑證 | 將使用者指派的受控身分識別指定為認證物件。 | Yes |
此外,請依照下列步驟操作:
為使用者指派的受控識別建立內含資料庫使用者。 使用具有至少 ALTER ANY USER 權限的 Microsoft Entra 身分識別,透過 SQL Server Management Studio 等工具,連線到您要從中複製資料或複製資料至其中的資料庫。 執行下列 T-SQL:
CREATE USER [your_resource_name] FROM EXTERNAL PROVIDER;依照您平常為 SQL 使用者和其他人所進行的作業一樣,建立一或多個使用者指派的受控身分識別,並授與使用者指派的受控身分識別所需的權限。 執行下列程式碼。 如需更多選項,請參閱此文件。
ALTER ROLE [role name] ADD MEMBER [your_resource_name];將一或多個使用者指派的受控身分識別指派給資料處理站,並為每個使用者指派的受控身分識別建立認證。
設定一個 SQL Server 連結服務。
範例
{
"name": "SqlServerLinkedService",
"properties": {
"type": "SqlServer",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "UserAssignedManagedIdentity",
"credential": {
"referenceName": "credential1",
"type": "CredentialReference"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
舊版
當您套用舊版版本時,SQL Server 連結服務支援下列泛型屬性:
| 屬性 | 描述 | 必要 |
|---|---|---|
| 型別 | 類型屬性必須設定為 SqlServer。 | Yes |
| 始終加密設置 | 指定 alwaysencryptedsettings 資訊,讓 Always Encrypted 能夠使用受控身分識別或服務主體來保護儲存在 SQL Server 的敏感性資料。 如需詳細資訊,請參閱使用 Always Encrypted 一節。 如果未指定,則會停用預設的一律加密設定。 | No |
| connectVia | 這個整合執行階段用於連接到資料存放區。 深入了解必要條件一節。 若未指定,則使用預設的 Azure 整合執行環境。 | No |
SQL Server 連接器支援下列驗證類型。 如需詳細資料,請參閱對應章節。
舊版的 SQL 驗證
若要使用 SQL 驗證,除了上一節所述的泛型屬性外,請指定下列屬性:
| 屬性 | 描述 | 必要 |
|---|---|---|
| connectionString | 指定連接 SQL Server 資料庫所需的 connectionString 資訊。 將登入名稱指定為您的使用者名稱,並確定您要連線的資料庫會對應至此登入。 | Yes |
| 密碼 | 如果你想在Azure Key Vault設定密碼,請從連接字串中移除password設定。 欲了解更多資訊,請參閱在 Azure Key Vault 中存儲憑證。 |
No |
舊版的 Windows 驗證
要使用 Windows 驗證,除了前節所述的一般屬性外,還需指定以下屬性:
| 屬性 | 描述 | 必要 |
|---|---|---|
| connectionString | 指定連接 SQL Server 資料庫所需的 connectionString 資訊。 | Yes |
| userName | 指定使用者名稱。 範例為 domainname\username。 | Yes |
| 密碼 | 指定您為使用者名稱所指定之使用者帳戶的密碼。 將此欄位標記為 SecureString 以將其安全地儲存。 或者,你可以引用儲存在 Azure Key Vault 中的秘密。 | Yes |
資料集屬性
如需可用來定義資料集的區段和屬性完整清單,請參閱資料集一文。 本節提供 SQL Server 資料集所支援的屬性清單。
為了從 SQL Server 資料庫複製資料,支援以下屬性:
| 屬性 | 描述 | 必要 |
|---|---|---|
| 型別 | 資料集的類型屬性必須設定為 SqlServerTable。 | Yes |
| 結構描述 | 架構名稱。 | 來源為否,接收器為是 |
| 表格 | 資料表/檢視的名稱。 | 來源為否,接收器為是 |
| 資料表名稱 | 具有結構描述的資料表/檢視名稱。 此屬性支援是為了向後相容性。 對於新的工作負載,請使用 schema 和 table。 |
來源為否,接收器為是 |
範例
{
"name": "SQLServerDataset",
"properties":
{
"type": "SqlServerTable",
"linkedServiceName": {
"referenceName": "<SQL Server linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"typeProperties": {
"schema": "<schema_name>",
"table": "<table_name>"
}
}
}
複製活動屬性
如需可用來定義活動的區段和屬性完整清單,請參閱管線一文。 本節提供 SQL Server 來源與匯入所支援的屬性清單。
SQL Server 作為來源
提示
若要利用資料分區技術有效地從 SQL Server 載入資料,請參考 從 SQL 資料庫平行複製 以了解更多資訊。
若要從SQL Server複製資料,請將複製活動中的來源類型設為 SqlSource。 複製活動的 [來源] 區段支援下列屬性:
| 屬性 | 描述 | 必要 |
|---|---|---|
| 型別 | 複製活動來源的 type屬性必須設定為 SqlSource。 | Yes |
| sqlReaderQuery | 使用自訂 SQL 查詢來讀取資料。 例如 select * from MyTable。 |
No |
| sqlReaderStoredProcedureName(SQL 資料讀取存儲過程名稱) | 此屬性是從來源資料表讀取資料的預存程序名稱。 最後一個 SQL 陳述式必須是預存程序中的 SELECT 陳述式。 | No |
| 儲存過程參數 | 這些是預存程序的參數。 允許的值為名稱或值組。 參數的名稱和大小寫必須符合預存程序參數的名稱和大小寫。 |
No |
| 隔離級別 (isolationLevel) | 指定 SQL 來源的交易鎖定行為。 允許的值為:ReadCommitted、ReadUncommitted、RepeatableRead、Serializable、Snapshot。 如果未指定,則會使用資料庫的預設隔離等級。 如需詳細資訊,請參閱這篇文件。 | No |
| 分割選項 | 指定用於從 SQL Server 載入資料的資料分割選項。 允許的值為:None (預設值)、PhysicalPartitionsOfTable 和 DynamicRange。 當分割區選項啟用(即非 None)時,從SQL Server同時載入資料的平行程度由複製活動中的parallelCopies設定控制。 |
No |
| 分割設定 | 指定資料分割的設定群組。 當分割選項不是 None 時套用。 |
No |
partitionSettings 底下: |
||
| partitionColumnName (分區列名稱) | 以整數類型或 date/datetime 類型 (int、smallint、bigint、date、smalldatetime、datetime、datetime2 或 datetimeoffset) 指定來源資料行的名稱,供平行複製的範圍分割使用。 如果未指定,則會自動偵測資料表的索引或主鍵,並用作分割分區欄位。當分割選項是 DynamicRange 時套用。 如果您使用查詢來取出來源資料,請在 WHERE 子句中加上 ?DfDynamicRangePartitionCondition 。 如需範例,請參閱從 SQL 資料庫平行複製一節。 |
No |
| partitionUpperBound(分區上限) | 用於分割分割範圍的分割欄位最大值。 這個值用於決定分割區的跨距,而不是用於篩選資料表中的資料列。 資料表或查詢結果中的所有資料列都會進行分割和複製。 如果未指定,複製活動會自動偵測該值。 當分割選項是 DynamicRange 時套用。 如需範例,請參閱從 SQL 資料庫平行複製一節。 |
No |
| partitionLowerBound | 用於分割分割範圍的分割欄位最小值。 這個值用於決定分割區的跨距,而不是用於篩選資料表中的資料列。 資料表或查詢結果中的所有資料列都會進行分割和複製。 如果未指定,複製活動會自動偵測該值。 當分割選項是 DynamicRange 時套用。 如需範例,請參閱從 SQL 資料庫平行複製一節。 |
No |
請注意下列幾點:
- 如果
SqlSource 指定了 sqlReaderQuery ,複製活動會對SQL Server來源執行此查詢以取得資料。 如果預存程序接受參數,您也可以藉由指定 sqlReaderStoredProcedureName 和 storedProcedureParameters 來指定預存程序。 - 在來源中使用預存程序來擷取資料時,請注意,如果您的預存程序設計為在傳入不同的參數值時傳回不同的結構描述,在從 UI 匯入結構描述,或使用自動資料表建立將資料複製到 SQL 資料庫時,您可能遇到失敗,或看到非預期的結果。
範例:使用 SQL 查詢
"activities":[
{
"name": "CopyFromSQLServer",
"type": "Copy",
"inputs": [
{
"referenceName": "<SQL Server input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SqlSource",
"sqlReaderQuery": "SELECT * FROM MyTable"
},
"sink": {
"type": "<sink type>"
}
}
}
]
範例:使用預存程序
"activities":[
{
"name": "CopyFromSQLServer",
"type": "Copy",
"inputs": [
{
"referenceName": "<SQL Server input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SqlSource",
"sqlReaderStoredProcedureName": "CopyTestSrcStoredProcedureWithParameters",
"storedProcedureParameters": {
"stringData": { "value": "str3" },
"identifier": { "value": "$$Text.Format('{0:yyyy}', <datetime parameter>)", "type": "Int"}
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
預存程序定義
CREATE PROCEDURE CopyTestSrcStoredProcedureWithParameters
(
@stringData varchar(20),
@identifier int
)
AS
SET NOCOUNT ON;
BEGIN
select *
from dbo.UnitTestSrcTable
where dbo.UnitTestSrcTable.stringData != stringData
and dbo.UnitTestSrcTable.identifier != identifier
END
GO
SQL Server 作為接收器
提示
了解更多關於 將資料載入 SQL Server 的最佳實務,包括支援的寫入行為、配置,以及最佳實務。
要將資料複製到 SQL Server,請在複製活動中將匯入類型設為 SqlSink。 複製活動接收器區段支援下列屬性:
| 屬性 | 描述 | 必要 |
|---|---|---|
| 型別 | 複製活動接收器的 type 屬性必須設定為 SqlSink。 | Yes |
| preCopyScript | 此特性指定在將資料寫入 SQL Server 前執行複製活動的 SQL 查詢。 每次複製執行只會調用此查詢一次。 您可以使用此屬性來清除預先載入的資料。 | No |
| 表格選項 | 指定是否根據來源結構描述,在接收器資料表不存在時自動建立接收器資料表。 當接收器指定預存程序時,不支援自動建立資料表。 允許的值包為:none (預設) 或 autoCreate。 |
No |
| sqlWriterStoredProcedureName | 定義如何將來源資料套用到目標資料表的預存程序名稱。 此預存程序將會依批次叫用。 針對只執行一次且與來源資料無關的作業 (例如刪除或截斷),請使用 preCopyScript 屬性。請參閱叫用 SQL 接收器中的預存程序的範例。 |
No |
| 儲存程序表類型參數名稱 | 預存程序中指定資料表類型的參數名稱。 | No |
| sqlWriterTableType | 在預存程序中使用的資料表類型名稱。 複製活動會透過此資料表類型,讓移動中的資料可供暫存資料表使用。 然後,預存程序程式碼可以合併正在複製的資料與現有的資料。 | No |
| 儲存過程參數 | 預存程序的參數。 允許的值為:名稱和值組。 參數的名稱和大小寫必須符合預存程序參數的名稱和大小寫。 |
No |
| writeBatchSize |
每個批次插入 SQL 資料表的資料列數。 允許的值為資料列數目的整數。 根據預設,服務會依據資料列大小動態決定適當的批次大小。 |
No |
| writeBatchTimeout | 插入、upsert 和預存程序作業在逾時前完成的等候時間。 允許的值為時間範圍。 例如 “00:30:00” 為 30 分鐘。 如果未指定任何值,逾時預設為 “00:30:00”。 |
No |
| 最大併發連線數 | 在活動執行期間建立至資料存放區的併發連線上限。 僅在想要限制並行連線時,才需要指定值。 | No |
| WriteBehavior | 指定複製活動的寫入行為,以將資料載入 SQL Server 資料庫。 允許的值為 Insert 和 Upsert。 根據預設,服務會使用 Insert 載入資料。 |
No |
| upsertSettings | 指定寫入行為的設定群組。 當 WriteBehavior 選項為 Upsert 時套用。 |
No |
upsertSettings 底下: |
||
| useTempDB | 指定是否要使用全域暫存資料表或實體資料表作為 upsert 的過渡資料表。 根據預設,服務會使用全域暫存表作為中介資料表。 值為 true。 |
No |
| interimSchemaName | 如果使用實體資料表,請指定建立過渡資料表的過渡結構描述。 注意:使用者必須具有建立和刪除資料表的權限。 根據預設,過渡資料表會與接收資料表共用相同的結構描述。 套用當 useTempDB 選項為 False 時。 |
No |
| 金鑰 | 指定用於唯一識別資料列的欄位名稱。 您可以使用單一按鍵或一組按鍵。 如果未指定,則會使用主索引鍵。 | No |
範例 1:附加資料
"activities":[
{
"name": "CopyToSQLServer",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<SQL Server output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "SqlSink",
"tableOption": "autoCreate",
"writeBatchSize": 100000
}
}
}
]
範例 2:在複製期間叫用預存程序
若要了解更多詳細資料,請參閱叫用 SQL 接收中的預存程序。
"activities":[
{
"name": "CopyToSQLServer",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<SQL Server output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "SqlSink",
"sqlWriterStoredProcedureName": "CopyTestStoredProcedureWithParameters",
"storedProcedureTableTypeParameterName": "MyTable",
"sqlWriterTableType": "MyTableType",
"storedProcedureParameters": {
"identifier": { "value": "1", "type": "Int" },
"stringData": { "value": "str1" }
}
}
}
}
]
範例 3:更新或插入 (Upsert) 資料
"activities":[
{
"name": "CopyToSQLServer",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<SQL Server output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "SqlSink",
"tableOption": "autoCreate",
"writeBehavior": "upsert",
"upsertSettings": {
"useTempDB": true,
"keys": [
"<column name>"
]
},
}
}
}
]
從 SQL 資料庫平行複製
複製活動中的 SQL Server 連接器提供內建的資料分割功能,以平行複製資料。 您可以在複製活動的 [來源] 索引標籤上找到資料分割選項。
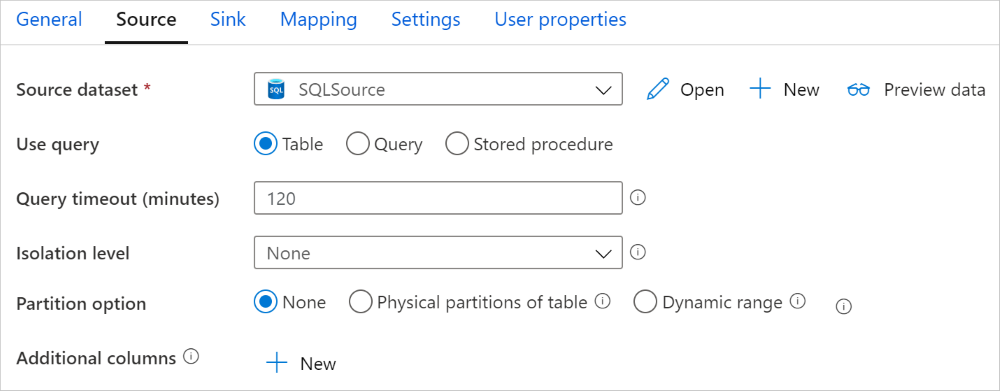
啟用分割複製時,複製活動會對你的 SQL Server 來源執行平行查詢,以分區載入資料。 平行程度由複製活動的 parallelCopies 設定所控制。 例如,如果你將 parallelCopies 設為四,服務會根據你指定的分割選項和設定同時產生並執行四個查詢,每個查詢都會從你的SQL Server中擷取部分資料。
建議你啟用平行複製並啟用資料分割,特別是當你從 SQL Server 載入大量資料時。 以下針對各種情節的建議設定。 將資料複製到以檔案為基礎的資料存放區時,建議分成多個檔案來寫入資料夾 (僅指定資料夾名稱),這樣效能會比寫入單一檔案更好。
| 情境 | 建議的設定 |
|---|---|
| 從大型資料表進行完整載入,並使用實體分割。 |
分割選項:資料表的實體分割區。 在執行期間,服務會自動偵測實體分割區,並依分割區複製資料。 若要檢查您的資料表是否有實體分割區,您可以參考此查詢。 |
| 從大型資料表進行完整載入,不使用實體分區,但需使用整數或日期時間欄位進行資料分區。 |
分割選項:動態範圍分割。 分割資料行 (選用):指定用來分割資料的資料行。 若未指定,將使用主索引鍵欄位。 分割區上限和分割區下限 (選用):指定是否要決定分割區跨距。 這不適用於篩選資料表中的資料列,資料表中的所有資料列都會分割並複製。 如果未指定,複製活動會自動偵測值,而且可能需要很長的時間,視 MIN 和 MAX 值而定。 建議提供上限和下限。 例如,如果您的分割區資料行「識別碼」具有範圍 1 到 100 之間的值,而您將下限設定為 20、上限設定為 80,且平行複製為 4,則服務會分別依 4 個分割區擷取資料 - 範圍中的識別碼分別為 <=20、[21, 50]、[51, 80] 和 >=81。 |
| 使用自訂查詢載入大量資料,不使用實體分割區,同時包含整數或日期/日期時間資料行用於資料分割。 |
分割選項:動態範圍分割。 查詢: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>。分割資料行:指定用來分割資料的資料行。 分割區上限和分割區下限 (選用):指定是否要決定分割區跨距。 這不適用於篩選資料表中的資料列,查詢結果中的所有資料列都會分割並複製。 如果未指定,複製活動會自動偵測該值。 例如,如果您的分割區資料行「識別碼」具有範圍 1 到 100 之間的值,而您將下限設定為 20、上限設定為 80,且平行複製為 4,則服務會分別依 4 個分割區擷取資料 - 範圍中的識別碼分別為 <=20、[21, 50]、[51, 80] 和 >=81。 以下是不同案例的更多範例查詢: 1.查詢整個資料表: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition2. 執行來自資料表的查詢,包含欄位選擇及附加的 where 子句篩選: SELECT <column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>3.使用子查詢進行查詢: SELECT <column_list> FROM (<your_sub_query>) AS T WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>4.在子查詢中使用分割區進行查詢: SELECT <column_list> FROM (SELECT <your_sub_query_column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition) AS T |
使用分割區選項載入資料的最佳做法:
- 選擇獨特的欄位作為分割欄位(例如主鍵或唯一鍵)以避免資料不均。
- 如果資料表有內建分割區,請使用分割選項「資料表的實體分割區」,以獲得更佳的效能。
- 如果你用 Azure Integration Runtime 複製資料,可以設定較大的「Data Integration Units (DIU)」(>4)來利用更多運算資源。 檢查該處適用的案例。
- 「複製平行處理原則的程度」會控制分割區數目,將此數目設定過大有時會損害效能,建議將此數目設定為 (DIU 或自我裝載 IR 節點數目) * (2 到 4)。
範例:從實體分割區的大型資料表進行完整載入
"source": {
"type": "SqlSource",
"partitionOption": "PhysicalPartitionsOfTable"
}
範例:使用動態範圍分割進行查詢
"source": {
"type": "SqlSource",
"query": "SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>",
"partitionOption": "DynamicRange",
"partitionSettings": {
"partitionColumnName": "<partition_column_name>",
"partitionUpperBound": "<upper_value_of_partition_column (optional) to decide the partition stride, not as data filter>",
"partitionLowerBound": "<lower_value_of_partition_column (optional) to decide the partition stride, not as data filter>"
}
}
用於檢查實體分割的範例查詢
SELECT DISTINCT s.name AS SchemaName, t.name AS TableName, pf.name AS PartitionFunctionName, c.name AS ColumnName, iif(pf.name is null, 'no', 'yes') AS HasPartition
FROM sys.tables AS t
LEFT JOIN sys.objects AS o ON t.object_id = o.object_id
LEFT JOIN sys.schemas AS s ON o.schema_id = s.schema_id
LEFT JOIN sys.indexes AS i ON t.object_id = i.object_id
LEFT JOIN sys.index_columns AS ic ON ic.partition_ordinal > 0 AND ic.index_id = i.index_id AND ic.object_id = t.object_id
LEFT JOIN sys.columns AS c ON c.object_id = ic.object_id AND c.column_id = ic.column_id
LEFT JOIN sys.partition_schemes ps ON i.data_space_id = ps.data_space_id
LEFT JOIN sys.partition_functions pf ON pf.function_id = ps.function_id
WHERE s.name='[your schema]' AND t.name = '[your table name]'
如果資料表具有實體分割區,您會看到 “HasPartition” 顯示為 “yes”,如下所示。

載入資料到 SQL Server 的最佳實務
當你將資料複製到 SQL Server 時,可能需要不同的寫入行為:
如需設定方式和最佳做法,請參閱個別章節。
附加資料
附加資料是這個 SQL Server 匯入連接器的預設行為。 服務會執行大量插入,以有效率地寫入您的資料表。 您可以在複製活動中,據此設定來源與接收器。
Upsert 資料
複製活動現在原生支援先將資料載入資料庫暫存資料表,然後在索引鍵存在時更新接收資料表中的資料,否則插入新資料。 若要深入了解複製活動中的 upsert 設定,請參閱 SQL Server 作為接收器。
覆寫整個資料表
您可以在複製活動接收器中設定 preCopyScript 屬性。 在此情況下,針對執行的每個複製活動,服務會先執行指令碼。 然後執行複製以插入資料。 例如,若要以最新的資料覆寫整個資料表,可以指定先刪除所有記錄,再從來源大量載入新資料的指令碼。
使用自訂邏輯寫入資料
使用自訂邏輯寫入資料的步驟類似於更新插入資料一節中所述的步驟。 當您需要在最終插入來源資料至目的地資料表之前套用額外的處理時,您可以載入暫存表格,然後叫用預存程序活動,或在複製活動接收器中叫用預存程序來套用資料。
從 SQL 接收器調用預存程序
當你將資料複製到 SQL Server 資料庫時,也可以設定並呼叫使用者指定的儲存程序,並在每個來源資料表的批次上加入額外參數。 預存程序功能使用資料表值參數。 請注意,服務會自動將預存程序包裝在自己的交易中,因此在預存程式內建立的任何交易都會變成巢狀交易,而且可能會對例外狀況處理造成影響。
當內建的複製機制無法滿足需求時,您可以使用預存程序。 例如,當您想要在最終插入來源資料至目的地資料表之前,套用額外的處理。 額外處理的一些範例包括:合併資料行、查閱其他的值,以及插入多個資料表中。
下列範例說明如何使用預存程序,將資料 upsert 到 SQL Server 資料庫中的資料表。 假設輸入資料和接收器 Marketing 資料表各有三個資料行:ProfileID、State 和 Category。 根據 ProfileID 資料行執行 upsert,且僅針對名為「ProductA」的特定類別套用。
在資料庫中,使用與 sqlWriterTableType 相同的名稱來定義資料表類型。 資料表類型的結構描述會與輸入資料所傳回的結構描述相同。
CREATE TYPE [dbo].[MarketingType] AS TABLE( [ProfileID] [varchar](256) NOT NULL, [State] [varchar](256) NOT NULL, [Category] [varchar](256) NOT NULL )在資料庫中,使用與 sqlWriterStoredProcedureName 相同的名稱來定義預存程序。 它會處理來自指定來源的輸入資料,並合併至輸出資料表。 預存程序中資料表類型的參數名稱會與資料集中定義的 tableName 相同。
CREATE PROCEDURE spOverwriteMarketing @Marketing [dbo].[MarketingType] READONLY, @category varchar(256) AS BEGIN MERGE [dbo].[Marketing] AS target USING @Marketing AS source ON (target.ProfileID = source.ProfileID and target.Category = @category) WHEN MATCHED THEN UPDATE SET State = source.State WHEN NOT MATCHED THEN INSERT (ProfileID, State, Category) VALUES (source.ProfileID, source.State, source.Category); END依下列方式,在複製活動中定義 SQL 接收器區段:
"sink": { "type": "SqlSink", "sqlWriterStoredProcedureName": "spOverwriteMarketing", "storedProcedureTableTypeParameterName": "Marketing", "sqlWriterTableType": "MarketingType", "storedProcedureParameters": { "category": { "value": "ProductA" } } }
映射資料流屬性
在映射資料流中轉換資料時,你可以從 SQL Server 資料庫讀取和寫入資料表。 如需詳細資訊,請參閱對應資料流程中的來源轉換和接收轉換。
注意
要存取本地SQL Server,你需要使用 Azure Data Factory 或 Synapse 工作空間
來源轉換
下表列出 SQL Server 原始碼所支援的屬性。 您可以在 [來源選項] 索引標籤中編輯這些屬性。
| 名稱 | 描述 | 必要 | 允許的值 | 資料流程指令碼屬性 |
|---|---|---|---|---|
| 資料表 | 如果您選取 [資料表] 作為輸入,資料流程會從資料集中指定的資料表擷取所有資料。 | No | - | - |
| 查詢 | 如果您選取 [查詢] 作為輸入,請指定要從來源擷取資料的 SQL 查詢,這會覆寫您在資料集中指定的任何資料表。 使用查詢是減少測試或查找資料列的絕佳方式。 不支援 Order By 子句,但您可以設定完整的 SELECT FROM 陳述式。 您也可使用使用者定義的資料表函數。 select * from udfGetData() 是 SQL 中的 UDF,您可以在資料流程中用於傳回資料表。 查詢範例: Select * from MyTable where customerId > 1000 and customerId < 2000 |
No | 字符串 | 查詢 |
| 批次大小 | 指定批次大小,以將大量資料分成多次讀取。 | No | 整數 | 批次大小 |
| 隔離等級 | 選擇下列其中一個隔離等級: - 已認可讀取 - 未認可讀取 (預設) - 可重複讀取 - 可序列化 - 無 (忽略隔離等級) |
No | READ_COMMITTED READ_UNCOMMITTED REPEATABLE_READ 可序列化 NONE |
隔離級別 (isolationLevel) |
| 啟用累加式擷取 | 使用此選項可告訴 ADF 只處理自上次執行管線後已變更的資料列。 | No | - | - |
| 遞增日期欄位 | 使用累加式擷取功能時,您必須選擇想要在來源資料表中用做浮水印的日期/時間資料行。 | No | - | - |
| 啟用原生異動資料擷取 (預覽) | 使用此選項可告知 ADF,只處理自上次管線執行後,由 SQL 變更資料擷取技術所擷取的差異資料。 使用此選項時,差異資料包括資料列插入、更新與刪除,將會自動載入,而不需要任何增量日期資料行。 你需要><在 SQL Server 上啟用 change data capture,才能在 ADF 中使用這個選項。 如需 ADF 中此選項的詳細資訊,請參閱原生異動資料擷取。 | No | - | - |
| 從頭開始讀取 | 使用累加擷取設定此選項時,會指示 ADF 在第一次執行管線時讀取所有資料列,並開啟累加擷取。 | No | - | - |
提示
對應資料流程查詢模式不支援 SQL 的 通用資料表運算式 (CTE),因為使用此模式的必要條件是查詢必須能用於 SQL 查詢的 FROM 子句中,但 CTE 不符合此要求。 若要使用 CTE,您必須使用下列查詢來建立預存程序:
CREATE PROC CTESP @query nvarchar(max)
AS
BEGIN
EXECUTE sp_executesql @query;
END
接著,在對應資料流程的來源轉換中使用預存程序模式,並將 @query 設定為類似下列範例:with CTE as (select 'test' as a) select * from CTE。 接著,您就可以如預期般使用 CTE。
SQL Server 原始碼腳本範例
當你使用 SQL Server 作為原始碼類型時,相關的資料流程腳本如下:
source(allowSchemaDrift: true,
validateSchema: false,
isolationLevel: 'READ_UNCOMMITTED',
query: 'select * from MYTABLE',
format: 'query') ~> SQLSource
接收轉換
下表列出 SQL Server sink 所支援的屬性。 您可以在 接收器選項 索引標籤中編輯這些屬性。
| 名稱 | 描述 | 必要 | 允許的值 | 資料流程指令碼屬性 |
|---|---|---|---|---|
| 更新方法 | 指定您的資料庫目的地所允許的作業。 預設僅允許插入。 若要更新、插入或刪除資料列,必須使用 [變更資料列轉換] 來標記要進行這些操作的資料列。 |
Yes |
true 或 false |
可刪除的 可插入的 可更新的 可執行 upsert |
| 主鍵欄 | 對於更新、upsert 和刪除,必須設定索引鍵資料行,以決定要變更哪一個資料列。 您選擇作為索引鍵的資料行名稱,將會作為後續更新、upsert、刪除的一部分。 因此,您必須選擇接收器對應中存在的資料行。 |
No | 陣列 | 金鑰 |
| 略過寫入索引鍵資料行 | 如果您不想將值寫入索引鍵資料行,請選取 [跳過寫入索引鍵資料行]。 | No |
true 或 false |
skipKeyWrites |
| 資料表動作 | 決定在寫入之前,是否要重新建立或移除目的地資料表中的所有資料列。 - 無:不會對資料表執行任何動作。 - 重新建立:將會刪除並重新建立資料表。 如果要動態建立新的資料表,則為必要。 - 截斷:將會移除目標資料表中的所有資料列。 |
No |
true 或 false |
重新創建 截斷 |
| 批次大小 | 指定要在每個批次中寫入的資料列數目。 較大的批次大小可改善壓縮與記憶體最佳化,但在快取資料時,會有記憶體不足例外狀況的風險。 | No | 整數 | 批次大小 |
| 前置和後置 SQL 指令碼 | 指定多行 SQL 指令碼,這些指令碼會在資料寫入接收器資料庫之前 (前置處理) 與之後 (後置處理) 執行。 | No | 字符串 | preSQLs postSQLs |
提示
- 建議將含有多個命令的單一批次指令碼分成多個批次。
- 只有傳回簡單更新計數的資料定義語言 (DDL) 和資料操作語言 (DML) 陳述式可以當作批次的一部份來執行。 若要深入了解,請參閱執行批次作業
SQL Server sink 腳本範例
當你使用 SQL Server 作為匯入型別時,相關的資料流程腳本如下:
IncomingStream sink(allowSchemaDrift: true,
validateSchema: false,
deletable:false,
insertable:true,
updateable:true,
upsertable:true,
keys:['keyColumn'],
format: 'table',
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> SQLSink
SQL Server 的資料型態映射
當你從 SQL Server 複製資料時,會使用以下從 SQL Server 資料型態到 Azure Data Factory 臨時資料型態的映射。 實作 Data Factory 的 Synapse 管線,使用相同的對應。 若要了解複製活動如何將來源結構描述和資料類型對應至接收端,請參閱結構描述和資料類型對應。
| SQL Server 資料型別 | Data Factory 過渡期資料類型 |
|---|---|
| Bigint | Int64 |
| 二進位 | Byte[] |
| 位元 | 布林值 |
| Char | 字串、字符[] |
| 日期 | 日期時間 |
| 日期與時間 | 日期時間 |
| datetime2 | 日期時間 |
| Datetimeoffset | DateTimeOffset |
| Decimal | Decimal |
| FILESTREAM 屬性(varbinary(max)) | Byte[] |
| 浮點數 | Double |
| 圖片 | Byte[] |
| int(整數) | Int32 |
| 錢 | Decimal |
| NCHAR | 字串、字符[] |
| ntext | 字串、字符[] |
| 數值型 | Decimal |
| Nvarchar | 字串、字符[] |
| real | Single |
| rowversion | Byte[] |
| smalldatetime | 日期時間 |
| SMALLINT | Int16 |
| smallmoney | Decimal |
| sql_variant | 物件 |
| 收發簡訊 | 字串、字符[] |
| 時間 | TimeSpan |
| 時間戳記 | Byte[] |
| Tinyint | Int16 |
| 唯一識別碼 | Guid |
| varbinary | Byte[] |
| varchar | 字串、字符[] |
| xml | 字符串 |
注意
對於對應至 Decimal 中繼類型的資料類型,目前複製活動支援的精確度最高為 28。 如果您的資料需要精度大於 28,請考慮在 SQL 查詢中轉換成字串。
使用 Azure Data Factory 從 SQL Server 複製資料時,位元資料類型會映射到布林臨時資料類型。 如果您有需要保留為位元資料類型的資料,請使用具有 T-SQL CAST 或 CONVERT 的查詢。
查閱活動屬性
若要了解屬性的詳細資料,請參閱查詢活動。
GetMetadata 活動屬性
若要了解關於屬性的詳細資料,請參閱 GetMetadata 活動
使用 Always Encrypted
當你用Always Encrypted從/SQL Server複製資料時,請依照以下步驟操作:
將 Column 主金鑰(CMK) 存放在 Azure Key Vault。 進一步了解 如何藉由使用 Azure Key Vault 來設定 Always Encrypted
請務必將金鑰保存庫的存取權授與儲存資料行主要金鑰 (CMK) 的位置。 如需取得權限,請參閱這篇文章。
建立連結服務以連線到您的 SQL 資料庫,並使用受控身分識別或服務主體啟用 'Always Encrypted' 函式。
注意
SQL Server Always Encrypted 支援以下情境:
- 來源或接收資料存放區都使用受控識別或服務主體作為金鑰提供者驗證類型。
- 來源和接收資料存放區都會使用受控身分識別作為金鑰提供者驗證類型。
- 來源和接收資料存放區都使用與金鑰提供者驗證類型相同的服務主體。
注意
目前,SQL Server Always Encrypted 僅支援映射資料流中的原始碼轉換。
原生異動資料擷取
Azure Data Factory 可支援 SQL Server、Azure SQL DB 及 Azure SQL MI 的原生變更資料擷取功能。 ADF 對應資料流程可以自動偵測及擷取異動的資料,包括在 SQL 存放區中的資料列插入、更新和刪除。 若使用者在資料流程對應中不需要程式碼經驗,只需將資料庫設定為目的地存放區,即可輕鬆達成從 SQL 存放區進行資料複寫的情境。 此外,使用者也可以在兩者之間撰寫任何的資料轉換邏輯,以從 SQL 存放區達到累加式 ETL 的情境。
請確定管線和活動名稱保持不變,如此 ADF 便可以為您記錄檢查點,以便自動取得上次執行的變更資料。 如果您變更管線名稱或活動名稱,檢查點便會重設,這會導致您在下次執行時得從頭開始,或是取得從現在開始的變更。 如果您確實想要變更管線名稱或活動名稱,但仍想保留檢查點,以便自動從上次執行取得變更資料,請在資料流程活動中使用您自己的 Checkpoint 索引鍵。
偵錯流程時,此功能的運作方式不變。 請注意,當您在偵錯執行期間重新整理瀏覽器時,將會重設檢查點。 在您對管線經過除錯運行後的結果感到滿意之後,您可以發佈並啟動管線。 目前,當您第一次觸發已發佈的管線時,它會自動從頭重新啟動,或從目前開始取得變更。
在監視區段中,您一律有機會重新執行管線。 當您這麼做時,系統一律會從您所選管線執行的上一個檢查點擷取變更資料。
範例 1:
當您在對應資料流程中,直接串接一個參考已啟用 SQL CDC 資料集的來源轉換,以及一個參考資料庫的接收器轉換時,SQL 來源上發生的變更將會自動套用到目標資料庫,因此您可以輕鬆達成資料庫之間的資料複寫情境。 您可以在匯入轉換中使用更新方法,以選擇是否在目標資料庫上允許插入、允許更新或允許刪除。 以下是對應資料流程中的範例指令碼。
source(output(
id as integer,
name as string
),
allowSchemaDrift: true,
validateSchema: false,
enableNativeCdc: true,
netChanges: true,
skipInitialLoad: false,
isolationLevel: 'READ_UNCOMMITTED',
format: 'table') ~> source1
source1 sink(allowSchemaDrift: true,
validateSchema: false,
deletable:true,
insertable:true,
updateable:true,
upsertable:true,
keys:['id'],
format: 'table',
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true,
errorHandlingOption: 'stopOnFirstError') ~> sink1
範例 2:
如果您想要啟用 ETL 情境,而不是透過 SQL CDC 在資料庫之間進行資料複寫,可以在對應資料流程中使用運算式,包括 isInsert(1)、isUpdate(1),以及 isDelete(1) 來區分不同作業類型的資料列。 以下是對應資料流程範例指令碼之一,會衍生一個值為 1 的資料行,以表示插入的資料列、值為 2 表示更新的資料列,以及值為 3 表示刪除的資料列,供下游轉換處理差異資料。
source(output(
id as integer,
name as string
),
allowSchemaDrift: true,
validateSchema: false,
enableNativeCdc: true,
netChanges: true,
skipInitialLoad: false,
isolationLevel: 'READ_UNCOMMITTED',
format: 'table') ~> source1
source1 derive(operationType = iif(isInsert(1), 1, iif(isUpdate(1), 2, 3))) ~> derivedColumn1
derivedColumn1 sink(allowSchemaDrift: true,
validateSchema: false,
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> sink1
已知的限制:
- 只有來自 SQL CDC 的淨變更會由 ADF 透過 cdc.fn_cdc_get_net_changes_ 來載入。
排解連線問題
設定你的 SQL Server 實例接受遠端連線。 開始SQL Server Management Studio,右鍵點擊 server,然後選擇 Properties。 從清單中選取 [連線],然後選取 [允許此伺服器的遠端連接] 核取方塊。
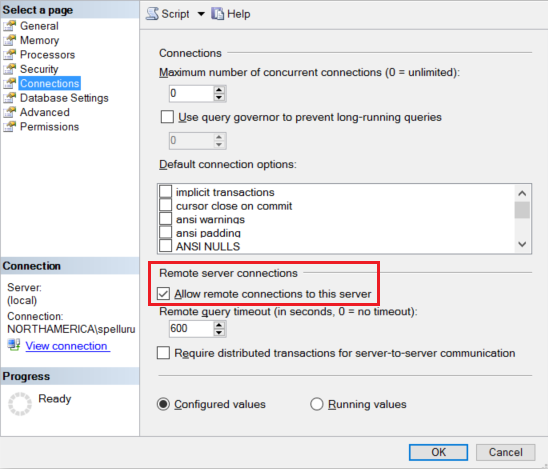
如需詳細步驟,請參閱設定 remote access 伺服器組態選項。
開始SQL Server 組態管理員。 展開適用於您要設定的實例的 SQL Server Network Configuration,然後選擇 Protocols for MSSQLSERVER。 這些通訊協定會出現在右窗格中。 用滑鼠右鍵按一下 [TCP/IP],然後選取 [啟用] 來啟用 TCP/IP。
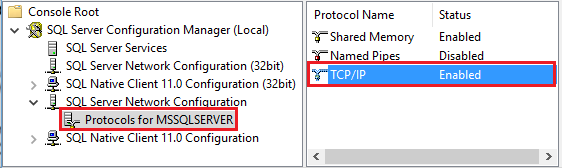
如需啟用 TCP/IP 通訊協定的詳細資料及替代方式,請參閱啟用或停用伺服器網路通訊協定。
在相同的視窗中,按兩下 [TCP/IP] 來啟動 [TCP/IP 屬性] 視窗。
切換到 [IP 位址] 索引標籤。向下捲動以查看 [IPAll] 區段。 記下 TCP 埠。 預設值是 1433。
為機器上的Windows防火牆建立
規則,允許透過此埠的進出流量。 Verify connection:若要使用完全限定的名稱連接SQL Server,請使用另一台機器的SQL Server Management Studio。 例如
"<machine>.<domain>.corp.<company>.com,1433"。
升級 SQL Server 版本
要升級 SQL Server 版本,請在 編輯連結服務 頁面,於 版本 下選擇 推薦,並參考推薦版本的 連結服務屬性 來設定連結服務。
建議的版本與舊版之間的差異
下表顯示了使用 SQL Server 使用推薦版本與舊版版本之間的差異。
| 建議的版本 | 舊版 |
|---|---|
使用 encrypt 以作為 strict 支援 TLS 1.3。 |
不支援 TLS 1.3。 |
相關內容
如需複製活動支援作為來源和接收器的資料存放區清單,請參閱支援的資料存放區。