Azure OpenAI na vašich datech
V tomto článku se dozvíte o Službě Azure OpenAI ve vašich datech, což vývojářům usnadňuje rychlé připojení, ingestování a uzemnění podnikových dat, aby mohli rychle vytvářet přizpůsobené kopírky (Preview). Zlepšuje porozumění uživatelům, urychluje dokončování úkolů, zlepšuje provozní efektivitu a pomáhá při rozhodování.
Co je Azure OpenAI ve vašich datech
Azure OpenAI On Your Data umožňuje spouštět pokročilé modely AI, jako je GPT-35-Turbo a GPT-4, na vlastních podnikových datech bez nutnosti trénování nebo vyladění modelů. Můžete chatovat nad daty a analyzovat je s větší přesností. Můžete určit zdroje pro podporu odpovědí na základě nejnovějších informací dostupných ve vašich určených zdrojích dat. K Azure OpenAI Na vašich datech můžete přistupovat pomocí rozhraní REST API, a to prostřednictvím sady SDK nebo webového rozhraní v nástroji Azure OpenAI Studio. Můžete také vytvořit webovou aplikaci, která se připojí k vašim datům, a povolit tak vylepšené řešení chatu nebo ho nasadit přímo jako kopírovací objekt v sadě Copilot Studio (Preview).
Vývoj s využitím Azure OpenAI na vašich datech
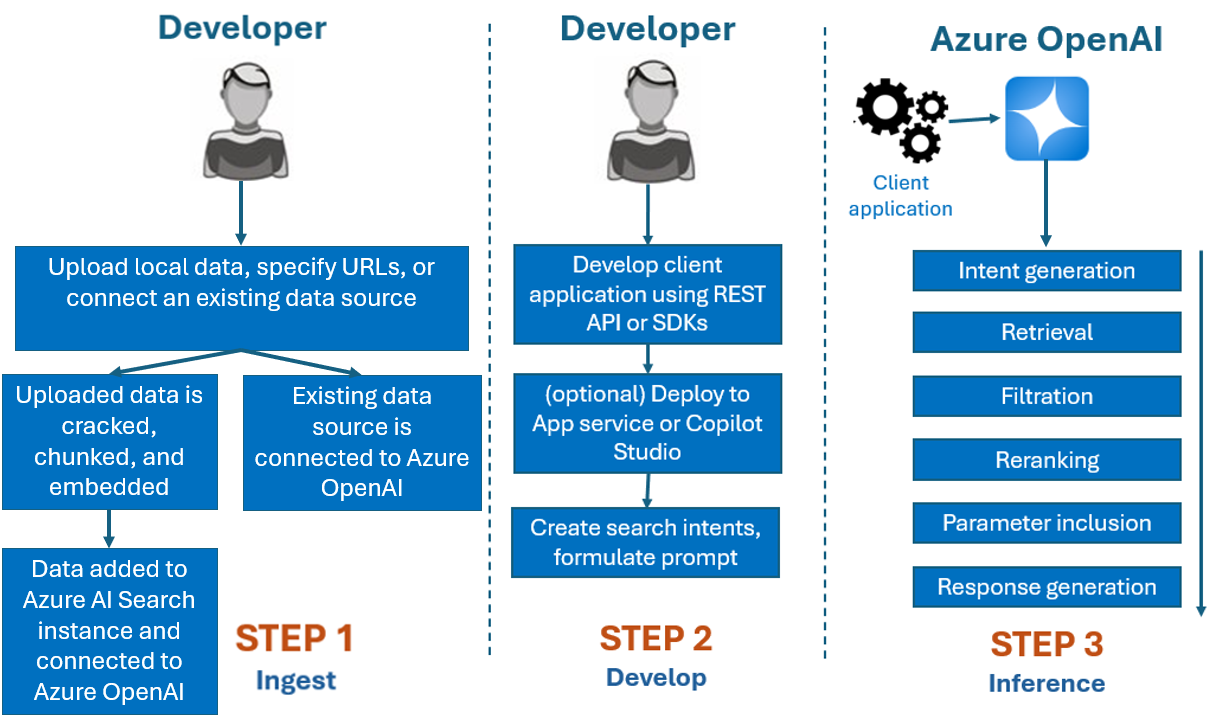
Proces vývoje, který byste použili s Azure OpenAI na vašich datech, je obvykle následující:
Ingestace: Nahrajte soubory pomocí nástroje Azure OpenAI Studio nebo rozhraní API pro příjem dat. To umožňuje, aby vaše data byla prolomené, blokované a vložené do instance služby Azure AI Search, kterou můžou používat modely Azure Open AI. Pokud máte existující podporovaný zdroj dat, můžete ho připojit také přímo.
Vývoj: Po vyzkoušení Azure OpenAI na vašich datech začněte vyvíjet aplikaci pomocí dostupných rozhraní REST API a sad SDK, které jsou dostupné v několika jazycích. Vytvoří výzvy a záměry hledání, které se mají předat službě Azure OpenAI.
Odvozování: Po nasazení aplikace ve vašem upřednostňovaném prostředí se do Azure OpenAI odešlou výzvy, které před vrácením odpovědi provede několik kroků:
Generování záměru: Služba určí záměr výzvy uživatele k určení správné odpovědi.
Načtení: Služba načte relevantní bloky dostupných dat z připojeného zdroje dat dotazováním. Například pomocí sémantického nebo vektorového vyhledávání. K ovlivnění načítání se používají parametry , jako je striktnost a počet dokumentů, které se mají načíst.
Filtrace a změna pořadí: Výsledky hledání z kroku načítání jsou vylepšeny řazením a filtrováním dat pro upřesnění relevance.
Generování odpovědí: Výsledná data se odesílají spolu s dalšími informacemi, jako je systémová zpráva do modelu LLM (Large Language Model) a odpověď se odešle zpět do aplikace.
Začněte tím, že připojíte zdroj dat pomocí nástroje Azure OpenAI Studio a začnete klást otázky a chatovat s daty.
Řízení přístupu na základě role v Azure (Azure RBAC) pro přidávání zdrojů dat
Pokud chcete plně používat Azure OpenAI ve vašich datech, musíte nastavit jednu nebo více rolí Azure RBAC. Další informace najdete v tématu Bezpečné použití Azure OpenAI na vašich datech .
Formáty dat a typy souborů
Azure OpenAI On Your Data podporuje následující typy souborů:
.txt.md.html.docx.pptx.pdf
Existuje limit nahrávání a existuje několik upozornění na strukturu dokumentů a na to, jak může ovlivnit kvalitu odpovědí z modelu:
Pokud převádíte data z nepodporovaného formátu do podporovaného formátu, optimalizujte kvalitu odpovědi modelu zajištěním převodu:
- Nepřivádí k významné ztrátě dat.
- Nepřidává do dat neočekávaný šum.
Pokud mají vaše soubory speciální formátování, jako jsou tabulky a sloupce nebo odrážky, připravte data pomocí skriptu pro přípravu dat, který je k dispozici na GitHubu.
U dokumentů a datových sad s dlouhým textem byste měli použít dostupný skript pro přípravu dat. Skript obsahuje data tak, aby odpovědi modelu byly přesnější. Tento skript také podporuje naskenované soubory a obrázky PDF.
Podporované zdroje dat
Abyste mohli nahrát data, musíte se připojit ke zdroji dat. Když chcete data použít k chatování s modelem Azure OpenAI, data se blokují do indexu vyhledávání, aby se příslušná data našla na základě uživatelských dotazů.
Integrovaná vektorová databáze v Azure Cosmos DB pro MongoDB založená na virtuálních jádrech nativně podporuje integraci s Azure OpenAI ve vašich datech.
U některých zdrojů dat, jako je nahrávání souborů z místního počítače (Preview) nebo dat obsažených v účtu úložiště objektů blob (Preview), se používá Azure AI Search. Když zvolíte následující zdroje dat, data se ingestují do indexu Azure AI Search.
| Ingestování dat prostřednictvím služby Azure AI Search | Popis |
|---|---|
| Azure AI Search | Použijte existující index Azure AI Search s Azure OpenAI ve vašich datech. |
| Nahrání souborů (Preview) | Nahrajte soubory z místního počítače, které se mají uložit do databáze Azure Blob Storage, a ingestované do služby Azure AI Search. |
| Adresa URL/webová adresa (Preview) | Webový obsah z adres URL je uložený ve službě Azure Blob Storage. |
| Azure Blob Storage (Preview) | Nahrajte soubory ze služby Azure Blob Storage, které se mají ingestovat do indexu služby Azure AI Search. |

- Azure AI Search
- Vector Database ve službě Azure Cosmos DB pro MongoDB
- Azure Blob Storage (Preview)
- Nahrání souborů (Preview)
- Adresa URL/webová adresa (Preview)
- Elasticsearch (Preview)
Pokud chcete, můžete zvážit použití indexu Azure AI Search:
- Přizpůsobte proces vytváření indexu.
- Znovu použijte index vytvořený dříve tím, že ingestuje data z jiných zdrojů dat.
Poznámka:
- Pokud chcete použít existující index, musí mít alespoň jedno prohledávatelné pole.
- Nastavte CORS Povolit typ
allzdroje možnost a povolenou možnost původu na*hodnotu .
Typy hledání
Azure OpenAI On Your Data poskytuje následující typy hledání, které můžete použít při přidávání zdroje dat.
Vektorové vyhledávání pomocí modelů vkládání Ada, které jsou k dispozici ve vybraných oblastech
Pokud chcete povolit vektorové vyhledávání, potřebujete existující model vkládání nasazený ve vašem prostředku Azure OpenAI. Vyberte nasazení vkládání při připojování dat a pak v části Správa dat vyberte jeden z typů vektorového vyhledávání. Pokud jako zdroj dat používáte Azure AI Search, ujistěte se, že máte v indexu vektorový sloupec.
Pokud používáte vlastní index, můžete při přidávání zdroje dat přizpůsobit mapování polí a definovat pole, která se mapují při odpovídání na otázky. Pokud chcete přizpůsobit mapování polí, vyberte Při přidávání zdroje dat možnost Použít vlastní mapování polí na stránce Zdroj dat.
Důležité
- Sémantické vyhledávání podléhá dodatečným cenům. Pokud chcete povolit sémantické vyhledávání nebo vektorové vyhledávání, musíte zvolit skladovou položku Basic nebo vyšší. Další informace najdete v cenových úrovních a omezeních služeb.
- Pokud chcete zlepšit kvalitu načítání informací a odpovědi modelu, doporučujeme povolit sémantické vyhledávání následujících jazyků zdrojů dat: angličtina, francouzština, španělština, portugalština, italština, Německo, čínština (Zh), japonština, korejština, ruština a arabština.
| Možnost hledání | Typ načítání | Další ceny? | Zaměstnanecké výhody |
|---|---|---|---|
| klíčové slovo | Vyhledávání klíčových slov | Žádné další ceny. | Provádí rychlé a flexibilní parsování a porovnávání dotazů v prohledávatelných polích pomocí výrazů nebo frází v libovolném podporovaném jazyce s operátory nebo bez operátorů. |
| sémantický | Sémantické vyhledávání | Další ceny pro sémantické využití vyhledávání | Zlepšuje přesnost a relevanci výsledků hledání pomocí nástroje pro přeřazení (s modely AI) k pochopení sémantického významu termínů dotazu a dokumentů vrácených počátečním rankerem vyhledávání. |
| vektor | Vektorové vyhledávání | Další ceny účtu Azure OpenAI z volání modelu vkládání | Umožňuje najít dokumenty, které se podobají zadanému vstupu dotazu na základě vektorových vkládání obsahu. |
| hybrid (vector + keyword) | Hybridní vyhledávání vektorů a hledání klíčových slov | Další ceny účtu Azure OpenAI z volání modelu vkládání | Provádí vyhledávání podobnosti u vektorových polí pomocí vektorových vložených hodnot a podporuje také flexibilní analýzu dotazů a fulltextové vyhledávání v alfanumerických polích pomocí dotazů termínů. |
| hybrid (vector + klíčové slovo) + sémantika | Hybridní vyhledávání vektorů, sémantické vyhledávání a hledání klíčových slov. | Další ceny účtu Azure OpenAI od volání modelu vkládání a dalších cen pro sémantické využití vyhledávání | Používá vektorové vkládání, porozumění jazyku a flexibilní analýzu dotazů k vytváření bohatých vyhledávacích prostředí a generování aplikací umělé inteligence, které dokážou zpracovávat složité a různorodé scénáře načítání informací. |
Inteligentní vyhledávání
Služba Azure OpenAI On Your Data má pro vaše data povolené inteligentní vyhledávání. Sémantické vyhledávání je ve výchozím nastavení povolené, pokud máte sémantické vyhledávání i hledání klíčových slov. Pokud máte vložené modely, inteligentní vyhledávání ve výchozím nastavení používá hybridní a sémantické vyhledávání.
Řízení přístupu na úrovni dokumentu
Poznámka:
Řízení přístupu na úrovni dokumentu se podporuje, když jako zdroj dat vyberete Azure AI Search.
Azure OpenAI On Your Data umožňuje omezit dokumenty, které se dají použít v odpovědích pro různé uživatele pomocí filtrů zabezpečení služby Azure AI Search. Když povolíte přístup na úrovni dokumentu, výsledky hledání vrácené službou Azure AI Search a použijí se k vygenerování odpovědi na základě členství ve skupině Microsoft Entra uživatele. Přístup na úrovni dokumentu můžete povolit jenom u existujících indexů Azure AI Search. Další informace najdete v tématu Použití Azure OpenAI Na vašich datech.
Mapování polí indexu
Pokud používáte vlastní index, zobrazí se v nástroji Azure OpenAI Studio výzva k definování polí, která chcete mapovat pro odpovědi na otázky při přidávání zdroje dat. Pro data obsahu můžete zadat více polí a měli byste zahrnout všechna pole, která obsahují text související s vaším případem použití.

V tomto příkladu pole mapovaná na data obsahu a název poskytují modelu informace, které odpovídají na otázky. Název se také používá k názvu textu citace. Pole namapované na název souboru vygeneruje v odpovědi názvy citací.
Správné mapování těchto polí pomáhá zajistit, aby model měl lepší kvalitu odezvy a citace. Můžete ho také nakonfigurovat v rozhraní API pomocí parametru fieldsMapping .
Filtr vyhledávání (ROZHRANÍ API)
Pokud chcete implementovat další kritéria založená na hodnotách pro spuštění dotazu, můžete nastavit vyhledávací filtr pomocí parametru filter v rozhraní REST API.
Jak se data ingestují do služby Azure AI Search
Data se ingestují do vyhledávání Azure AI pomocí následujícího procesu:
Prostředky příjmu dat se vytvářejí v prostředku Azure AI Search a účtu úložiště Azure. V současné době jsou tyto prostředky: indexery, indexy, zdroje dat, vlastní dovednost ve vyhledávacím prostředku a kontejner (později označovaný jako kontejner bloků dat) v účtu úložiště Azure. Vstupní kontejner úložiště Azure můžete zadat pomocí sady Azure OpenAI Studio nebo rozhraní API pro příjem dat (Preview). Ve výchozím nastavení se předpokládá použití kódování UTF-8. Chcete-li zadat jiné kódování, použijte vlastnost konfigurace kódování. Seznam podporovaných kódování najdete v dokumentaci k .NET.
Data se čtou ze vstupního kontejneru, obsah se otevírá a rozděluje do malých bloků dat s maximálně 1 024 tokeny. Pokud je povolené vektorové vyhledávání, služba vypočítá vektor představující vkládání do jednotlivých bloků dat. Výstup tohoto kroku (označovaný jako "předzpracovaná" nebo "blokovaná" data) se uloží do kontejneru bloků dat vytvořených v předchozím kroku.
Předzpracovaná data se načtou z kontejneru bloků dat a indexují se v indexu Azure AI Search.
Datové připojení
Musíte vybrat způsob ověřování připojení z Azure OpenAI, Azure AI Search a Azure Blob Storage. Můžete zvolit spravovanou identitu přiřazenou systémem nebo klíč rozhraní API. Když jako typ ověřování vyberete klíč rozhraní API, systém automaticky naplní klíč rozhraní API pro připojení k prostředkům Azure AI Search, Azure OpenAI a Azure Blob Storage. Výběrem spravované identity přiřazené systémem bude ověřování založeno na přiřazení role, kterou máte. Spravovaná identita přiřazená systémem je ve výchozím nastavení vybrána pro zabezpečení.

Jakmile vyberete další tlačítko, automaticky ověří nastavení tak, aby používalo vybranou metodu ověřování. Pokud dojde k chybě, přečtěte si článek o přiřazení rolí a aktualizujte instalaci.
Jakmile nastavení opravíte, znovu vyberte, abyste ověřili a pokračovali. Uživatelé rozhraní API můžou také nakonfigurovat ověřování s přiřazenou spravovanou identitou a klíči rozhraní API.






Nasazení do copilotu (Preview), aplikace Teams (Preview) nebo webové aplikace
Po připojení Azure OpenAI k datům je můžete nasadit pomocí tlačítka Nasadit do v nástroji Azure OpenAI Studio.

Tím získáte několik možností pro nasazení řešení.
Do copilotu v sadě Copilot Studio (Preview) můžete nasadit přímo z Azure OpenAI Studia a umožnit tak konverzační prostředí do různých kanálů, jako jsou Microsoft Teams, weby, Dynamics 365 a další kanály Azure Bot Service. Tenant použitý ve službě Azure OpenAI a Copilot Studio (Preview) by měl být stejný. Další informace najdete v tématu Použití připojení k Azure OpenAI ve vašich datech.
Poznámka:
Nasazení do kopírovacíholotu v sadě Copilot Studio (Preview) je dostupné jenom v oblastech USA.
Bezpečné používání Azure OpenAI na vašich datech
Azure OpenAI On Your Data můžete bezpečně používat tím, že chráníte data a prostředky pomocí řízení přístupu na základě role na základě ID Microsoft Entra, virtuálních sítí a privátních koncových bodů. Můžete také omezit dokumenty, které se dají použít v odpovědích pro různé uživatele s filtry zabezpečení služby Azure AI Search. Podívejte se , jak bezpečně používat Azure OpenAI na vašich datech.
Osvědčené postupy
V následujících částech se dozvíte, jak zlepšit kvalitu odpovědí udělených modelem.
Parametr příjmu dat
Když se data ingestují do služby Azure AI Search, můžete upravit následující další nastavení v rozhraní API pro příjem dat ve studiu nebo v rozhraní API pro příjem dat.
Velikost bloku dat (Preview)
Azure OpenAI ve vašich datech zpracovává dokumenty jejich rozdělením na bloky dat před jejich ingestováním. Velikost bloku je maximální velikost z hlediska počtu tokenů libovolného bloku ve vyhledávacím indexu. Velikost bloku dat a počet načtených dokumentů společně určují, kolik informací (tokenů) je součástí výzvy odeslané do modelu. Obecně platí, že velikost bloku dat vynásobená počtem načtených dokumentů je celkový počet tokenů odeslaných do modelu.
Nastavení velikosti bloku pro váš případ použití
Výchozí velikost bloku je 1 024 tokenů. Vzhledem k jedinečnosti dat ale můžete najít jinou velikost bloku dat (například 256, 512 nebo 1 536 tokenů).
Úprava velikosti bloku dat může zvýšit výkon chatovacího robota. Při hledání optimální velikosti bloku dat je potřeba zvážit určitou zkušební a chybovou hodnotu, začněte zvážením povahy vaší datové sady. Menší velikost bloku dat je obecně lepší pro datové sady s přímými fakty a méně kontexty, zatímco větší velikost bloku dat může být přínosnější pro více kontextových informací, i když by to mohlo ovlivnit výkon načítání.
Malá velikost bloku dat jako 256 vytváří podrobnější bloky dat. Tato velikost také znamená, že model k vygenerování výstupu využije méně tokenů (pokud není počet načtených dokumentů velmi vysoký), což může být méně nákladné. Menší bloky dat také znamenají, že model nemusí zpracovávat a interpretovat dlouhé části textu, což snižuje šum a rušivé prvky. Tato členitost a zaměření však představují potenciální problém. Důležité informace nemusí být mezi hlavními načtené bloky dat, zejména pokud je počet načtených dokumentů nastavený na nízkou hodnotu, například 3.
Tip
Mějte na paměti, že změna velikosti bloku dat vyžaduje opakované ingestování dokumentů, takže je vhodné nejprve upravit parametry modulu runtime, jako je striktnost a počet načtených dokumentů. Pokud stále nedostáváte požadované výsledky, zvažte změnu velikosti bloku dat:
- Pokud narazíte na velký počet odpovědí, například "Nevím" u otázek s odpověďmi, které by měly být v dokumentech, zvažte zmenšení velikosti bloku dat na 256 nebo 512, aby se zlepšila členitost.
- Pokud chatbot poskytuje nějaké správné podrobnosti, ale chybí ostatním, které se zjeví v citacích, může zvětšením velikosti bloku na 1 536 pomoct zachytit další kontextové informace.
Parametry modulu runtime
V části Parametry dat v nástroji Azure OpenAI Studio a rozhraní API můžete upravit následující další nastavení. Při aktualizaci těchto parametrů nemusíte data znovu ingestovat.
| Název parametru | Popis |
|---|---|
| Omezení odpovědí na data | Tento příznak konfiguruje přístup chatovacího robota ke zpracování dotazů nesouvisejících se zdrojem dat nebo v případě, že pro úplnou odpověď nestačí vyhledávací dokumenty. Když je toto nastavení zakázané, model doplňuje své odpovědi svými vlastními znalostmi kromě dokumentů. Pokud je toto nastavení povolené, model se pokusí spoléhat jenom na dokumenty pro odpovědi. Toto je inScope parametr v rozhraní API a ve výchozím nastavení je nastavený na true. |
| Načtené dokumenty | Tento parametr je celé číslo, které lze nastavit na 3, 5, 10 nebo 20 a řídí počet bloků dokumentů zadaných pro velký jazykový model pro formulaci konečné odpovědi. Ve výchozím nastavení je nastavená hodnota 5. Proces hledání může být hlučný a někdy kvůli blokům dat můžou být relevantní informace rozložené do několika bloků v indexu vyhledávání. Výběrem čísla k nejvyšší K, například 5, zajistíte, že model dokáže extrahovat relevantní informace, a to i přes svá omezení vyhledávání a bloků dat. Zvýšením příliš vysokého počtu ale může model rozptylovat. Maximální počet dokumentů, které lze efektivně použít, závisí také na verzi modelu, protože každá z nich má jinou velikost kontextu a kapacitu pro zpracování dokumentů. Pokud zjistíte, že odpovědi chybí důležitý kontext, zkuste tento parametr zvýšit. Toto je topNDocuments parametr v rozhraní API a ve výchozím nastavení je 5. |
| Přísnost | Určuje agresivitu systému při filtrování vyhledávacích dokumentů na základě skóre podobnosti. Systém se dotazuje na Azure Search nebo jiné úložiště dokumentů a pak rozhodne, které dokumenty se mají poskytovat velkým jazykovým modelům, jako je ChatGPT. Filtrování irelevantních dokumentů může výrazně zvýšit výkon koncového chatovacího robota. Některé dokumenty jsou z výsledků top-K vyloučeny, pokud mají před předáním do modelu nízké skóre podobnosti. To je řízeno celočíselnou hodnotou v rozsahu od 1 do 5. Nastavení této hodnoty na hodnotu 1 znamená, že systém bude minimálně filtrovat dokumenty na základě podobnosti vyhledávání s uživatelským dotazem. Naopak nastavení 5 znamená, že systém agresivně vyfiltruje dokumenty a použije velmi vysokou prahovou hodnotu podobnosti. Pokud zjistíte, že chatbot vynechá relevantní informace, snižte striktnost filtru (nastavte hodnotu blíže k 1), aby obsahoval více dokumentů. Naopak pokud irelevantní dokumenty ruší odpovědi, zvyšte prahovou hodnotu (nastavte hodnotu blíže k 5). Toto je strictness parametr v rozhraní API a ve výchozím nastavení je nastavený na 3. |
Necitované odkazy
Model se může vrátit "TYPE":"UNCITED_REFERENCE" místo "TYPE":CONTENT v rozhraní API pro dokumenty, které se načítají ze zdroje dat, ale nejsou zahrnuté do citace. To může být užitečné pro ladění a toto chování můžete řídit úpravou striktnosti a načtených parametrů modulu runtime dokumentů popsaných výše.
Systémová zpráva
Při použití Azure OpenAI ve vašich datech můžete definovat systémovou zprávu, která bude odpovídat modelu. Tato zpráva umožňuje přizpůsobit odpovědi nad vzorem rag (Retrieval Augmented Generation), který Azure OpenAI ve vašich datech používá. Systémová zpráva se používá kromě interní základní výzvy k poskytování prostředí. Abychom to podpořili, zkrátíme systémovou zprávu po určitém počtu tokenů , abychom zajistili, že model může odpovídat na otázky pomocí vašich dat. Pokud definujete nad výchozím prostředím další chování, ujistěte se, že je výzva systému podrobná a vysvětluje přesné očekávané přizpůsobení.
Jakmile vyberete přidat datovou sadu, můžete použít část Systémová zpráva v nástroji Azure OpenAI Studio nebo role_information parametr v rozhraní API.

Potenciální vzory využití
Definování role
Můžete definovat roli, kterou chcete mít svého asistenta. Pokud například vytváříte robota podpory, můžete přidat "Jste odborník pomocník pro podporu incidentů, který pomáhá uživatelům řešit nové problémy".
Definování typu načtených dat
Můžete také přidat povahu dat, která poskytujete asistentovi.
- Definujte téma nebo rozsah datové sady, například "finanční sestavu", "akademický dokument" nebo "sestavu incidentů". Pro technickou podporu můžete například přidat dotaz "Odpovíte na dotazy pomocí informací z podobných incidentů v načtených dokumentech".
- Pokud vaše data mají určité charakteristiky, můžete tyto podrobnosti přidat do systémové zprávy. Pokud jsou například vaše dokumenty v japonštině, můžete přidat "Načítáte japonské dokumenty a měli byste je pečlivě číst v japonštině a odpovídat v japonštině".
- Pokud vaše dokumenty obsahují strukturovaná data, jako jsou tabulky z finanční sestavy, můžete tento fakt také přidat do systémové výzvy. Pokud například vaše data mají tabulky, můžete přidat "Máte data ve formě tabulek týkajících se finančních výsledků a měli byste číst řádek po řádku tabulky, abyste mohli zodpovědět uživatelské otázky."
Definování stylu výstupu
Výstup modelu můžete také změnit definováním systémové zprávy. Pokud například chcete zajistit, aby odpovědi asistenta byly ve francouzštině, můžete přidat výzvu typu "Jste asistent AI, který pomáhá uživatelům, kteří chápou francouzské informace. Dotazy uživatelů můžou být v angličtině nebo francouzštině. Přečtěte si načtené dokumenty pečlivě a odpovězte na ně ve francouzštině. Přeložte znalosti z dokumentů do francouzštiny, abyste měli jistotu, že jsou všechny odpovědi ve francouzštině."
Opětovné potvrzení kritického chování
Azure OpenAI On Your Data funguje tak, že odešle pokyny do velkého jazykového modelu ve formě výzev k odpovídání na dotazy uživatelů pomocí vašich dat. Pokud je pro aplikaci důležité určité chování, můžete toto chování opakovat v systémových zprávách a zvýšit tak jeho přesnost. Pokud chcete například model vést jenom na odpovědi z dokumentů, můžete přidat "Odpovědět pouze pomocí načítaných dokumentů a bez použití vašich znalostí. Vygenerujte citace pro načtení dokumentů pro každou deklaraci identity ve vaší odpovědi. Pokud na uživatelskou otázku nelze odpovědět pomocí načtených dokumentů, vysvětlete prosím odůvodnění, proč jsou dokumenty relevantní pro dotazy uživatelů. V každém případě neodpovídejte pomocí vlastních znalostí."
Výzva k technickým trikům
V oblasti přípravy výzvy existuje mnoho triků, které se můžete pokusit vylepšit výstup. Jedním zpříkladůch Extrahování relevantních znalostí pro dotazy uživatelů z dokumentů krok za krokem a vytvoření odpovědi směrem dolů z extrahovaných informací z relevantních dokumentů."
Poznámka:
Systémová zpráva slouží ke změně způsobu reakce pomocníka GPT na otázku uživatele na základě načtené dokumentace. Nemá vliv na proces načítání. Pokud chcete poskytnout pokyny pro proces načítání, je lepší je zahrnout do otázek. Systémová zpráva je pouze pokyny. Model nemusí dodržovat každou zadanou instrukci, protože byl uveden s určitými chováními, jako je objektivita, a vyhnout se kontroverzním prohlášením. K neočekávanému chování může dojít v případě, že systémová zpráva je v rozporu s těmito chováními.
Maximální odpověď
Nastavte limit počtu tokenů na odpověď modelu. Horní limit pro Azure OpenAI On Your Data je 1500. To je ekvivalentem nastavení parametru max_tokens v rozhraní API.
Omezení odpovědí na data
Tato možnost podporuje model, aby reagoval pouze na vaše data a ve výchozím nastavení je vybraný. Pokud tuto možnost zrušíte, model může snadněji použít interní znalosti, aby reagoval. Na základě vašeho případu použití a scénáře určete správný výběr.
Interakce s modelem
Při chatování s modelem využijte následující postupy.
Historie konverzací
- Než začnete s novou konverzací (nebo položíte otázku, která nesouvisí s předchozími), vymažte historii chatu.
- Získání různých odpovědí na stejnou otázku mezi prvním konverzačním turnem a následnými obraty lze očekávat, protože historie konverzací mění aktuální stav modelu. Pokud dostanete nesprávné odpovědi, nahlaste ji jako kvalitu chyby.
Odpověď modelu
Pokud nejste spokojení s odpovědí modelu na konkrétní otázku, zkuste otázku zvidvidovat konkrétněji nebo obecněji, abyste zjistili, jak model odpovídá, a podle toho znovu zastavte svůj dotaz.
Při získávání modelu k vytváření požadovaných výstupů pro složité otázky a úlohy se ukázalo, že řetězové výzvy jsou efektivní.
Délka otázky
Pokud je to možné, vyhněte se kladení dlouhých otázek a rozdělte je na několik otázek. Modely GPT mají omezení počtu tokenů, které mohou přijmout. Limity tokenů se počítají do: otázka uživatele, systémová zpráva, načtené vyhledávací dokumenty (bloky dat), interní výzvy, historie konverzací (pokud existuje) a odpověď. Pokud otázka překročí limit tokenu, zkrátí se.
Podpora vícejazyčných jazyků
Vyhledávání klíčových slov a sémantické vyhledávání v Azure OpenAI On Your Data v současné době podporuje dotazy ve stejném jazyce jako data v indexu. Pokud jsou například vaše data v japonštině, musí být vstupní dotazy také v japonštině. Pro načítání dokumentů napříč jazyky doporučujeme sestavit index s povoleným vyhledáváním vektorů.
Pokud chcete zlepšit kvalitu načítání informací a odpovědi modelu, doporučujeme povolit sémantické vyhledávání v následujících jazycích: angličtina, francouzština, španělština, portugalština, italština, Německo, čínština (Zh), japonština, korejština, ruština, arabština
K informování modelu, že jsou vaše data v jiném jazyce, doporučujeme použít systémovou zprávu. Příklad:
*"*Jste asistent AI navržený tak, aby uživatelům pomohl extrahovat informace z načtených japonských dokumentů. Před vytvořením odpovědi pečlivě prověřte japonské dokumenty. Dotaz uživatele bude v japonštině a v japonštině musíte odpovědět také v japonštině."
Pokud máte dokumenty ve více jazycích, doporučujeme vytvořit nový index pro každý jazyk a připojit je samostatně k Azure OpenAI.
Streamování dat
Streamovací požadavek můžete odeslat pomocí parametru stream , který umožňuje odesílání a přijímání dat přírůstkově, aniž byste čekali na celou odpověď rozhraní API. To může zlepšit výkon a uživatelské prostředí, zejména u velkých nebo dynamických dat.
{
"stream": true,
"dataSources": [
{
"type": "AzureCognitiveSearch",
"parameters": {
"endpoint": "'$AZURE_AI_SEARCH_ENDPOINT'",
"key": "'$AZURE_AI_SEARCH_API_KEY'",
"indexName": "'$AZURE_AI_SEARCH_INDEX'"
}
}
],
"messages": [
{
"role": "user",
"content": "What are the differences between Azure Machine Learning and Azure AI services?"
}
]
}
Historie konverzací pro lepší výsledky
Když chatujete s modelem, poskytnutí historie chatu pomůže modelu vrátit výsledky vyšší kvality. Do požadavků rozhraní API nemusíte zahrnout context vlastnost zpráv asistenta, aby se zlepšila kvalita odezvy. Příklady najdete v referenční dokumentaci k rozhraní API.
Volání funkcí
Některé modely Azure OpenAI umožňují definovat nástroje a tool_choice parametry pro povolení volání funkcí. Můžete nastavit volání funkcí prostřednictvím rozhraní REST API /chat/completions. Pokud jsou v požadavku oba tools zdroje dat, použijí se následující zásady.
- Pokud
tool_choiceanonone, nástroje se ignorují a k vygenerování odpovědi se používají pouze zdroje dat. - V opačném případě, pokud
tool_choicenení zadán nebo zadán jakoautoobjekt, zdroje dat budou ignorovány a odpověď bude obsahovat název vybraných funkcí a argumenty, pokud existují. I když model rozhodne, že není vybraná žádná funkce, zdroje dat se stále ignorují.
Pokud výše uvedené zásady nevyhovují vašim potřebám, zvažte další možnosti, například: rozhraní API pro tok výzvy nebo asistenty.
Odhad využití tokenů pro Azure OpenAI ve vašich datech
Azure OpenAI ve vaší rozšířené generaci načítání dat (RAG) je služba, která využívá vyhledávací službu (jako je Azure AI Search) a generování (modely Azure OpenAI) a umožňuje uživatelům získat odpovědi na své otázky na základě poskytnutých dat.
V rámci tohoto kanálu RAG existují tři kroky na vysoké úrovni:
Přeformátujte uživatelský dotaz na seznam záměrů hledání. To se provádí voláním modelu s výzvou, která obsahuje pokyny, otázku uživatele a historii konverzací. Zavoláme tuto výzvu k záměru.
Pro každý záměr se z vyhledávací služby načte několik bloků dokumentů. Po vyfiltrování irelevantních bloků dat na základě prahové hodnoty striktnosti zadané uživatelem a opětovného řazení/agregace bloků dat na základě interní logiky se vybere počet bloků dokumentů zadaný uživatelem.
Tyto bloky dokumentů spolu s otázkou uživatele, historií konverzací, informacemi o rolích a pokyny se odesílají do modelu, aby se vygenerovala konečná odpověď modelu. Zavoláme tuto výzvu ke generování.
V modelu se celkem provádějí dvě volání:
Pro zpracování záměru: Odhad tokenu pro výzvu k záměru zahrnuje otázky uživatele, historii konverzací a pokyny odeslané do modelu pro generování záměru.
Pro vygenerování odpovědi: Odhad tokenu pro výzvu ke generování zahrnuje otázky uživatele, historii konverzací, načtený seznam bloků dokumentů, informace o rolích a pokyny odeslané na generování.
Při odhadu celkového tokenu tokenů je potřeba vzít v úvahu vygenerované výstupní tokeny modelu (záměry i odpovědi). Součtem všech čtyř sloupců níže získáte průměrné celkové tokeny použité k vygenerování odpovědi.
| Model | Počet tokenů výzvy generování | Počet tokenů výzvy záměru | Počet tokenů odpovědi | Počet tokenů záměru |
|---|---|---|---|---|
| gpt-35-turbo-16k | 4297 | 1366 | 111 | 25 |
| gpt-4-0613 | 3997 | 1385 | 118 | 18 |
| gpt-4-1106-preview | 4538 | 811 | 119 | 27 |
| gpt-35-turbo-1106 | 4854 | 1372 | 110 | 26 |
Výše uvedená čísla jsou založená na testování datové sady s následujícími údaji:
- 191 konverzací
- 250 otázek
- 10 průměrných tokenů na otázku
- 4 konverzační zapnutí v průměru na konverzaci
A následující parametry.
| Nastavení | Hodnota |
|---|---|
| Počet načtených dokumentů | 5 |
| Přísnost | 3 |
| Velikost bloku dat | 1024 |
| Omezit odpovědi na přijatá data? | True |
Tyto odhady se budou lišit v závislosti na hodnotách nastavených pro výše uvedené parametry. Pokud je například počet načtených dokumentů nastavený na 10 a striktnost je nastavená na 1, počet tokenů se zvýší. Pokud vrácené odpovědi nejsou omezené na ingestované data, je modelu přiděleno méně instrukcí a počet tokenů se zpomalí.
Odhady také závisejí na povaze dokumentů a otázek, které jsou kladeny. Pokud jsou například otázky otevřené, budou odpovědi pravděpodobně delší. Podobně by delší systémová zpráva přispěla k delší výzvě, která spotřebovává více tokenů, a pokud je historie konverzací dlouhá, výzva bude delší.
| Model | Maximální počet tokenů pro systémovou zprávu |
|---|---|
| GPT-35-0301 | 400 |
| GPT-35-0613-16K | 1000 |
| GPT-4-0613-8K | 400 |
| GPT-4-0613-32K | 2000 |
| GPT-35-turbo-0125 | 2000 |
| GPT-4-turbo-0409 | 4000 |
| GPT-4o | 4000 |
| GPT-4o-mini | 4000 |
Výše uvedená tabulka ukazuje maximální počet tokenů, které lze použít pro systémovou zprávu. Pokud chcete zobrazit maximální počet tokenů pro odpověď modelu, přečtěte si článek o modelech. Kromě toho také následující tokeny využívají:
Meta prompt: Pokud omezíte odpovědi z modelu na obsah podkladových dat (
inScope=Truev rozhraní API), maximální počet tokenů vyšší. Jinak (například pokudinScope=False) je maximum nižší. Toto číslo je proměnlivé v závislosti na délce tokenu uživatelské otázky a historie konverzací. Tento odhad zahrnuje základní výzvu a výzvu k přepsání dotazu k načtení.Otázka a historie uživatele: Proměnná, ale omezena na 2 000 tokenů.
Načtené dokumenty (bloky): Počet tokenů používaných bloky načtených dokumentů závisí na několika faktorech. Horní mez je počet načtených bloků dokumentů vynásobený velikostí bloku dat. Zkrátí se ale na základě dostupných tokenů tokenů pro konkrétní model, který se použije po počítání zbývajících polí.
20 % dostupných tokenů je vyhrazeno pro odpověď modelu. Zbývajících 80 % dostupných tokenů zahrnuje meta výzvu, otázku uživatele a historii konverzací a systémovou zprávu. Zbývající rozpočet tokenu se používá pro načtené bloky dokumentů.
Pokud chcete vypočítat počet tokenů spotřebovaných vaším vstupem (například informace o systémové zprávě nebo roli), použijte následující vzorový kód.
import tiktoken
class TokenEstimator(object):
GPT2_TOKENIZER = tiktoken.get_encoding("gpt2")
def estimate_tokens(self, text: str) -> int:
return len(self.GPT2_TOKENIZER.encode(text))
token_output = TokenEstimator.estimate_tokens(input_text)
Řešení problému
Při řešení potíží s neúspěšnými operacemi vždy hledejte chyby nebo upozornění zadaná v odpovědi rozhraní API nebo v nástroji Azure OpenAI Studio. Tady jsou některé běžné chyby a upozornění:
Neúspěšné úlohy příjmu dat
Problémy s omezeními kvót
Index s názvem X ve službě Y nelze vytvořit. Pro tuto službu byla překročena kvóta indexu. Nejprve musíte odstranit nepoužívané indexy, přidat prodlevu mezi požadavky na vytvoření indexu nebo upgradovat službu pro vyšší limity.
U této služby byla překročena standardní kvóta indexeru X. Aktuálně máte standardní indexery X. Nejprve musíte odstranit nepoužívané indexery, změnit indexer executionMode nebo upgradovat službu pro vyšší limity.
Řešení:
Upgradujte na vyšší cenovou úroveň nebo odstraňte nepoužívané prostředky.
Problémy s vypršením časového limitu předběžného zpracování
Nepodařilo se spustit dovednost, protože požadavek webového rozhraní API selhal.
Dovednost se nepovedlo spustit, protože odpověď na dovednosti webového rozhraní API je neplatná.
Řešení:
Rozdělte vstupní dokumenty na menší dokumenty a zkuste to znovu.
Problémy s oprávněními
Tento požadavek nemá oprávnění k provedení této operace.
Řešení:
To znamená, že účet úložiště není přístupný s danými přihlašovacími údaji. V tomto případě zkontrolujte přihlašovací údaje účtu úložiště předané rozhraní API a ujistěte se, že účet úložiště není skrytý za privátním koncovým bodem (pokud pro tento prostředek není nakonfigurovaný privátní koncový bod).
Chyby 503 při odesílání dotazů pomocí služby Azure AI Search
Každá zpráva uživatele může přeložit na více vyhledávacích dotazů, z nichž všechny se paralelně odesílají do vyhledávacího prostředku. To může způsobit omezování chování v případě, že je nízký počet replik a oddílů vyhledávání. Maximální počet dotazů za sekundu, které může podporovat jeden oddíl a jedna replika, nemusí být dostatečný. V takovém případě zvažte zvýšení počtu replik a oddílů nebo přidání logiky režimu spánku nebo opakování ve vaší aplikaci. Další informace najdete v dokumentaci ke službě Azure AI Search.
Regionální dostupnost a podpora modelů
| Oblast | gpt-35-turbo-16k (0613) |
gpt-35-turbo (1106) |
gpt-4-32k (0613) |
gpt-4 (1106-preview) |
gpt-4 (0125-preview) |
gpt-4 (0613) |
gpt-4o** |
gpt-4 (turbo-2024-04-09) |
|---|---|---|---|---|---|---|---|---|
| Austrálie – východ | ✅ | ✅ | ✅ | ✅ | ✅ | |||
| Kanada – východ | ✅ | ✅ | ✅ | ✅ | ✅ | |||
| East US | ✅ | ✅ | ✅ | |||||
| USA – východ 2 | ✅ | ✅ | ✅ | ✅ | ||||
| Francie – střed | ✅ | ✅ | ✅ | ✅ | ✅ | |||
| Japonsko – východ | ✅ | |||||||
| USA – středosever | ✅ | ✅ | ✅ | |||||
| Norsko – východ | ✅ | ✅ | ||||||
| Středojižní USA | ✅ | ✅ | ||||||
| Indie – jih | ✅ | ✅ | ||||||
| Švédsko – střed | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ||
| Švýcarsko – sever | ✅ | ✅ | ✅ | |||||
| Velká Británie – jih | ✅ | ✅ | ✅ | ✅ | ||||
| USA – západ | ✅ | ✅ | ✅ |
**Toto je pouze textová implementace.
Pokud je váš prostředek Azure OpenAI v jiné oblasti, nebudete moct ve svých datech používat Azure OpenAI.