Tento článek popisuje, jak vývojový tým použil metriky k nalezení kritických bodů a zlepšení výkonu distribuovaného systému. Tento článek je založený na skutečném zátěžovém testování, které se provedlo pro ukázkovou aplikaci. Aplikace pochází ze směrného plánu Azure Kubernetes Service (AKS) pro mikroslužby spolu s projektem zátěžového testu sady Visual Studio, který se používá ke generování výsledků.
Tento článek je součástí série článků. Přečtěte si první část.
Scénář: Voláním několika back-endových služeb načtěte informace a agregujte výsledky.
Tento scénář zahrnuje aplikaci pro doručování pomocí dronů. Klienti se můžou dotazovat rozhraní REST API, aby získali nejnovější informace o faktuře. Faktura obsahuje souhrn dodávek, balíčků a celkového využití dronů zákazníka. Tato aplikace používá architekturu mikroslužeb běžící v AKS a informace potřebné pro fakturu jsou rozložené mezi několik mikroslužeb.
Místo toho, aby klient volal jednotlivé služby přímo, implementuje aplikace model Agregace brány . Pomocí tohoto vzoru klient odešle jeden požadavek na službu brány. Brána zase volá back-endové služby paralelně a pak agreguje výsledky do jedné datové části odpovědi.
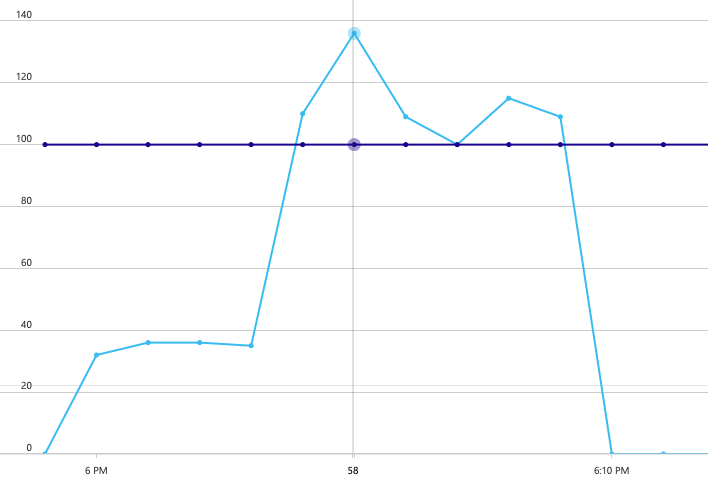
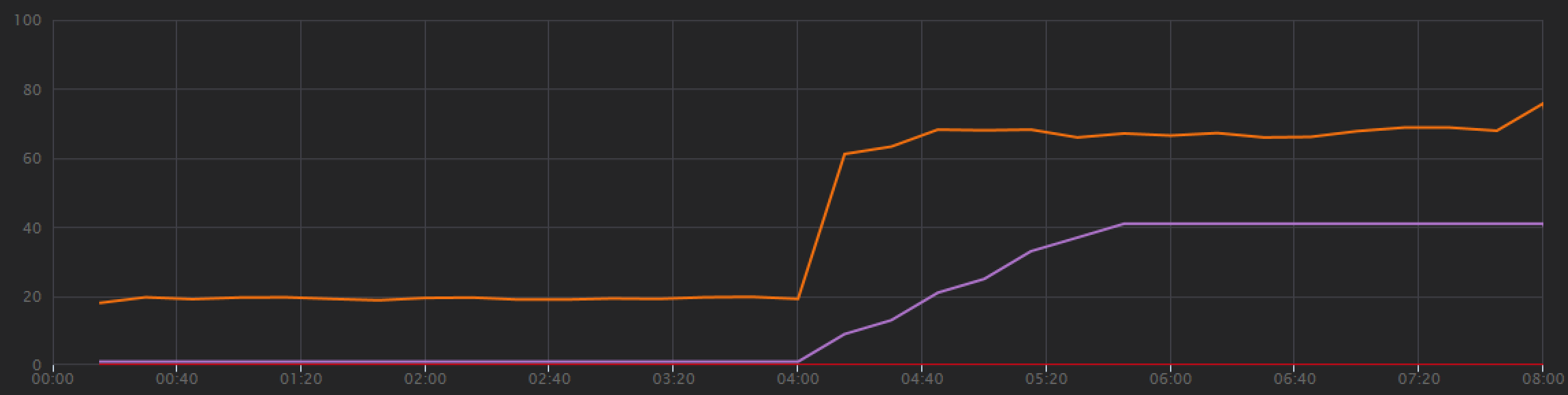
Vývojový tým začal s krokovým zátěžovým testem, který navýšil zatížení od jednoho simulovaného uživatele až na 40 uživatelů za celkovou dobu trvání 8 minut. Následující graf, převzatý ze sady Visual Studio, ukazuje výsledky. Fialová čára znázorňuje uživatelské zatížení a oranžová čára propustnost (průměrný počet požadavků za sekundu).
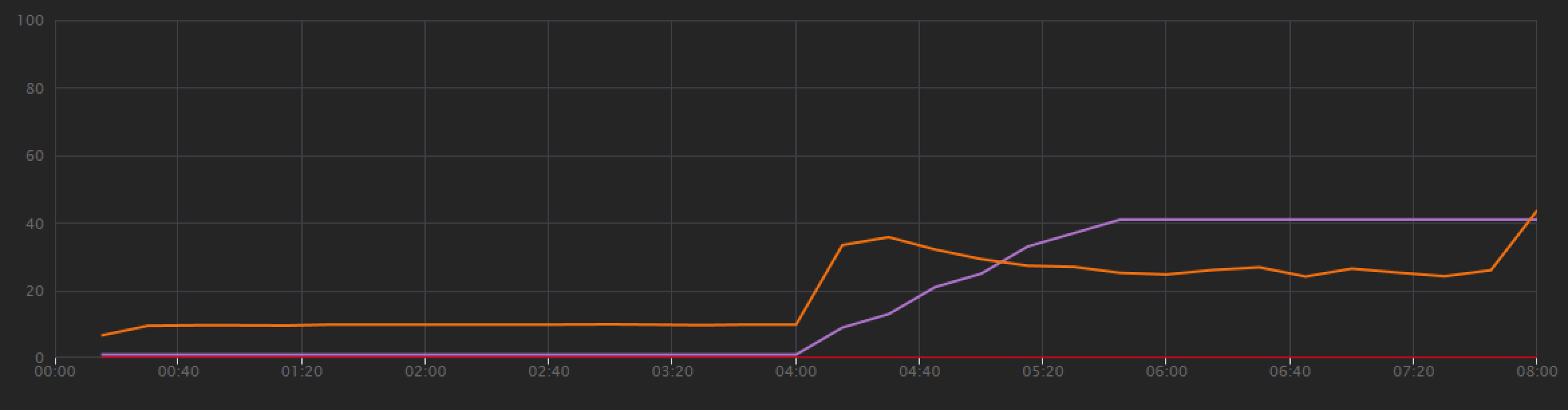
Červená čára v dolní části grafu ukazuje, že klientovi nebyly vráceny žádné chyby, což je povzbudivé. Průměrná propustnost ale přibližně v polovině testu dosáhne maxima a zbytek poklesne, i když se zatížení bude dál zvyšovat. To znamená, že back-end nemůže držet krok. Tento vzor je běžný, když systém začne dosahovat limitů prostředků – po dosažení maxima propustnost ve skutečnosti výrazně klesne. K tomuto modelu můžou přispívat kolize prostředků, přechodné chyby nebo zvýšení míry výjimek.
Pojďme se podívat na data monitorování, abychom zjistili, co se děje uvnitř systému. Další graf je převzatý z Application Insights. Zobrazuje průměrnou dobu trvání volání HTTP z brány do back-endových služeb.
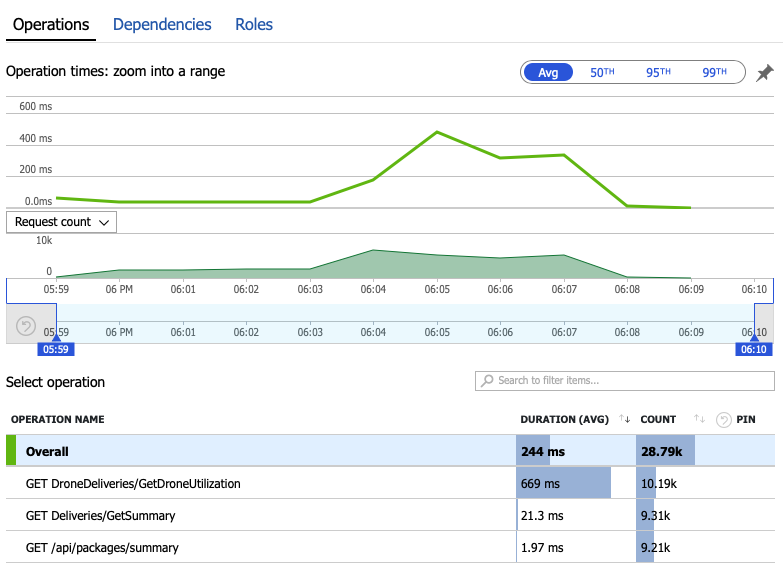
Tento graf ukazuje, GetDroneUtilizationže konkrétně jedna operace trvá v průměru mnohem déle – řádově. Brána provádí tato volání paralelně, takže nejpomalejší operace určuje, jak dlouho trvá dokončení celého požadavku.
Je zřejmé, že dalším krokem je prozkoumání GetDroneUtilization operace a vyhledání případných kritických bodů. Jednou z možností je vyčerpání prostředků. Možná, že této konkrétní back-endové službě dochází procesor nebo paměť. V případě clusteru AKS jsou tyto informace k dispozici v Azure Portal prostřednictvím funkce Přehledy kontejnerů služby Azure Monitor. Následující grafy znázorňují využití prostředků na úrovni clusteru:
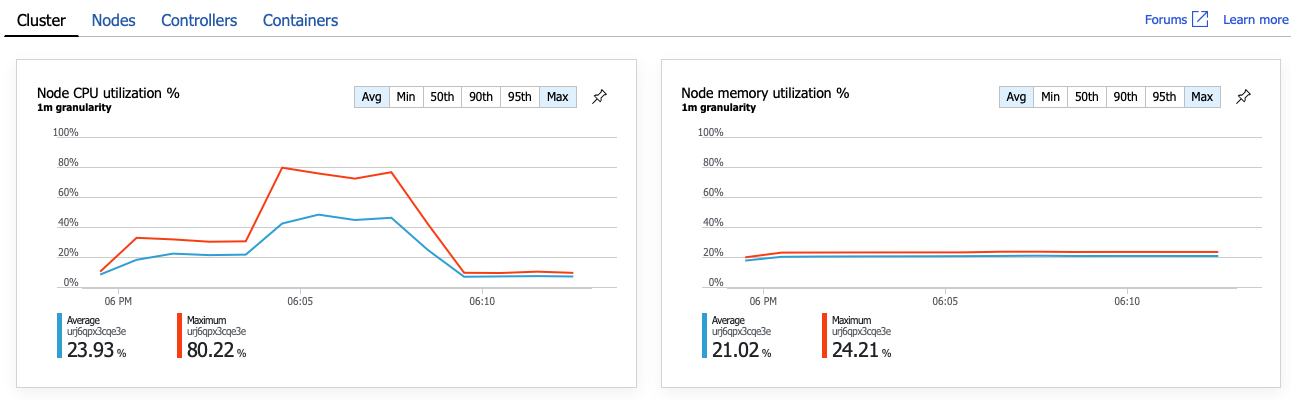
Na tomto snímku obrazovky se zobrazí průměrná i maximální hodnota. Je důležité podívat se na více než jen průměr, protože průměr může skrýt špičky v datech. Tady průměrné využití procesoru zůstává pod 50 %, ale existuje několik špiček na 80 %. To je blízko kapacity, ale stále v mezích tolerance. Kritický bod způsobuje něco jiného.
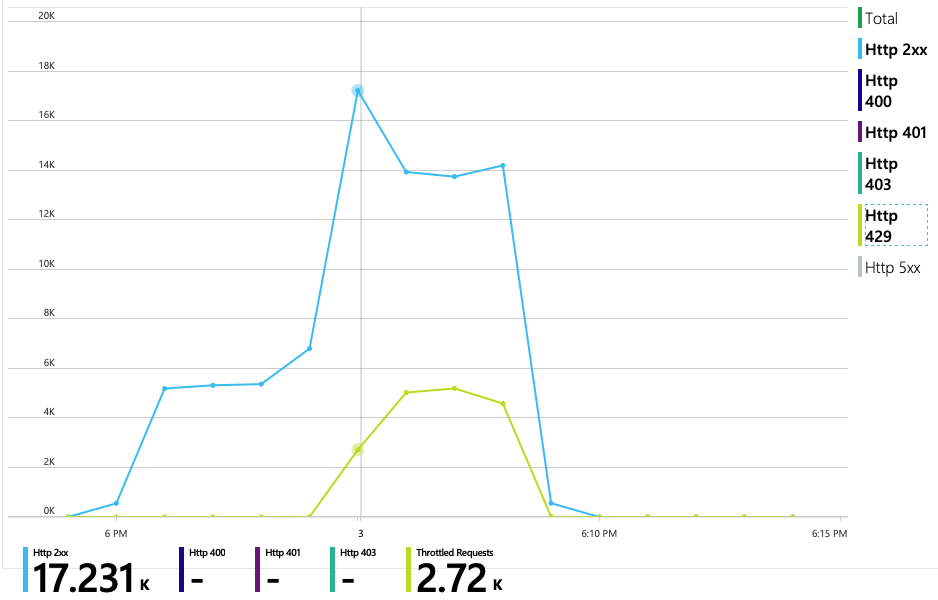
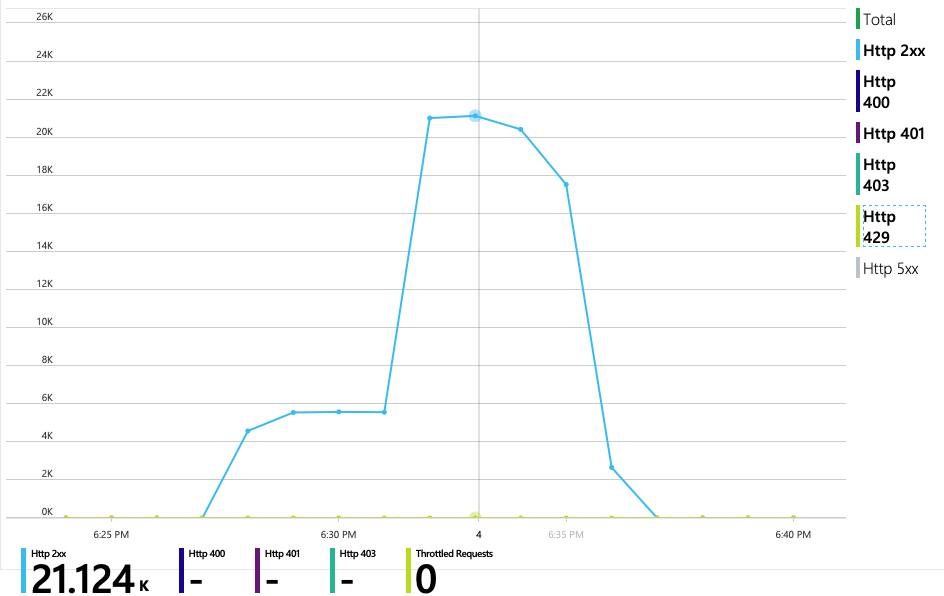
Následující graf odhalí skutečného viníka. Tento graf zobrazuje kódy odpovědí HTTP z back-end databáze služby Delivery Service, což je v tomto případě Azure Cosmos DB. Modrá čára představuje kódy úspěchu (HTTP 2xx), zatímco zelená čára představuje chyby HTTP 429. Návratový kód HTTP 429 znamená, že služba Azure Cosmos DB dočasně omezuje požadavky, protože volající spotřebovává více jednotek prostředků (RU), než kolik je zřízených.
Aby vývojový tým získal další přehled, použil Application Insights k zobrazení kompletní telemetrie pro reprezentativní vzorek požadavků. Tady je jedna instance:
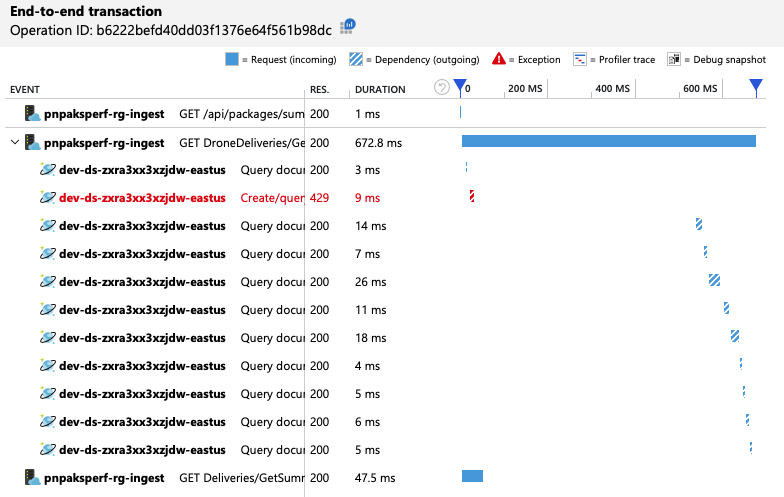
Toto zobrazení ukazuje volání související s jedním požadavkem klienta spolu s informacemi o načasování a kódy odpovědí. Volání nejvyšší úrovně jsou z brány do back-endových služeb. Volání GetDroneUtilization je rozbalené, aby zobrazovalo volání externích závislostí – v tomto případě Azure Cosmos DB. Červené volání vrátilo chybu HTTP 429.
Všimněte si velké mezery mezi chybou HTTP 429 a dalším voláním. Když klientská knihovna Azure Cosmos DB obdrží chybu HTTP 429, automaticky se vrátí zpět a počká na opakování operace. Toto zobrazení ukazuje, že během 672 ms trvala tato operace většinu času čekáním na opakování pokusu o službu Azure Cosmos DB.
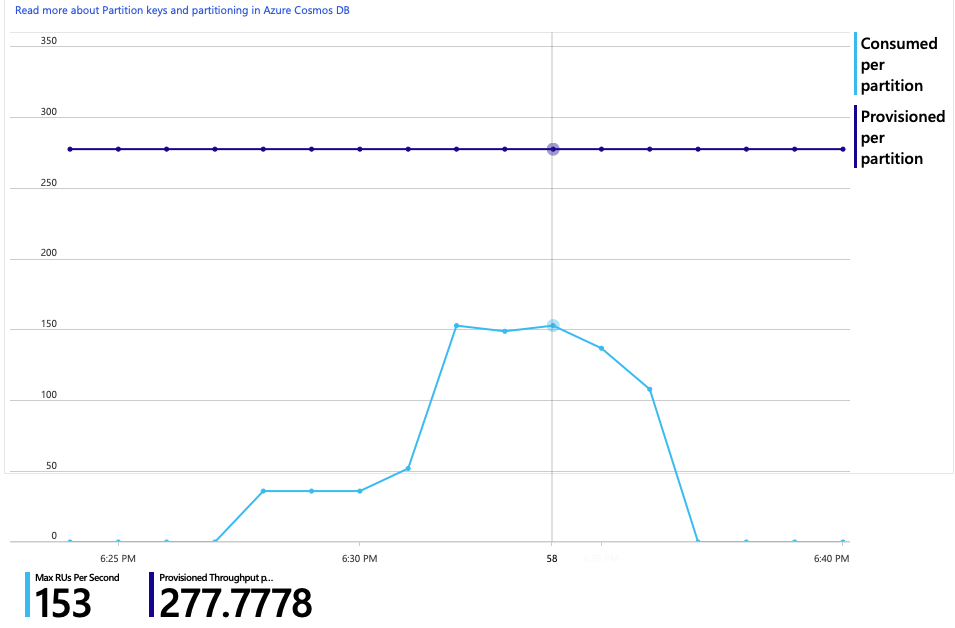
Tady je další zajímavý graf pro tuto analýzu. Zobrazuje spotřebu RU na fyzický oddíl a počet zřízených RU na fyzický oddíl:
Aby byl tento graf srozumitelný, musíte porozumět tomu, jak Azure Cosmos DB spravuje oddíly. Kolekce ve službě Azure Cosmos DB můžou mít klíč oddílu. Každá možná hodnota klíče definuje logický oddíl dat v rámci kolekce. Azure Cosmos DB distribuuje tyto logické oddíly mezi jeden nebo více fyzických oddílů. Správu fyzických oddílů zajišťuje služba Azure Cosmos DB automaticky. Při ukládání dalších dat může Azure Cosmos DB přesunout logické oddíly do nových fyzických oddílů, aby se zatížení rozložilo mezi fyzické oddíly.
Pro účely tohoto zátěžového testu byla kolekce Azure Cosmos DB zřízena s 900 RU. Graf ukazuje 100 RU na fyzický oddíl, což znamená celkem devět fyzických oddílů. Přestože Azure Cosmos DB automaticky zpracovává horizontální dělení fyzických oddílů, znalost počtu oddílů vám může poskytnout přehled o výkonu. Vývojový tým tyto informace použije později, až bude pokračovat v optimalizaci. Tam, kde modrá čára protíná fialovou vodorovnou čáru, spotřeba RU překročila zřízené RU. V tomto okamžiku začne Azure Cosmos DB omezovat volání.
Pro druhý zátěžový test tým škáloval kolekci Azure Cosmos DB z 900 RU na 2500 RU. Propustnost se zvýšila z 19 požadavků za sekundu na 23 požadavků za sekundu a průměrná latence klesla z 669 ms na 569 ms.
| Metric | Test 1 | Test 2 |
|---|---|---|
| Propustnost (početq/s) | 19 | 23 |
| Průměrná latence (ms) | 669 | 569 |
| Úspěšné požadavky | 9,8 K | 11 kB |
Nejsou to obrovské zisky, ale pohled na graf v průběhu času ukazuje úplnější obrázek:
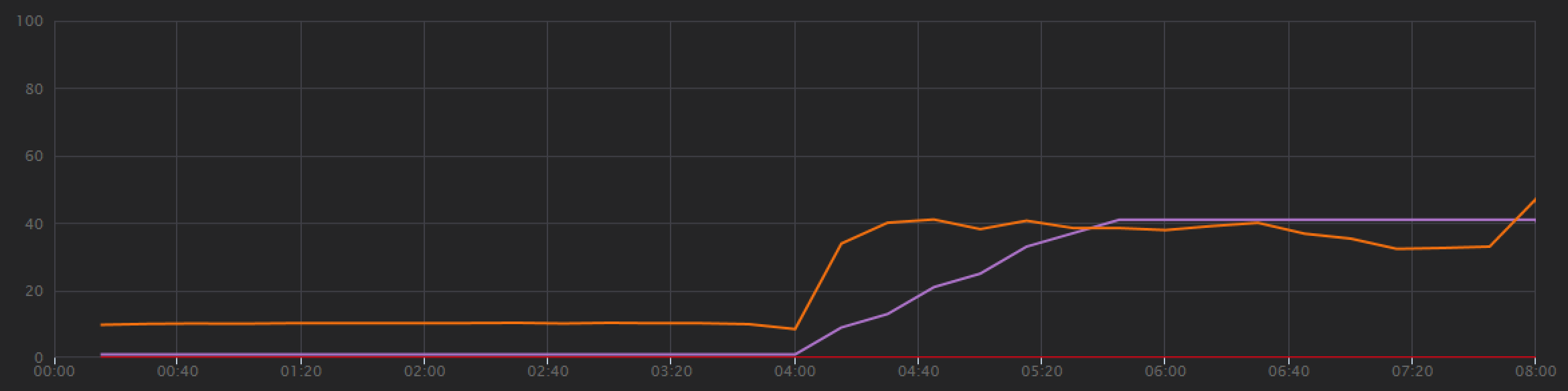
Zatímco předchozí test ukázal počáteční špičku následovanou prudkým poklesem, tento test ukazuje konzistentnější propustnost. Maximální propustnost ale není výrazně vyšší.
Všechny požadavky na službu Azure Cosmos DB vrátily stav 2xx a chyby HTTP 429 se odebraly:
Graf spotřeby RU a zřízených RU ukazuje, že je k dispozici dostatek prostoru. Na fyzický oddíl je přibližně 275 RU a zátěžový test má špičku přibližně 100 jednotek RU spotřebovaných za sekundu.
Další zajímavou metrikou je počet volání služby Azure Cosmos DB na úspěšnou operaci:
| Metric | Test 1 | Test 2 |
|---|---|---|
| Volání na operaci | 11 | 9 |
Za předpokladu, že nedošlo k chybám, by počet volání měl odpovídat skutečnému plánu dotazu. V tomto případě operace zahrnuje dotaz napříč oddíly, který zasáhne všech devět fyzických oddílů. Vyšší hodnota v prvním zátěžovém testu odráží počet volání, která vrátila chybu 429.
Tato metrika se vypočítala spuštěním vlastního dotazu Log Analytics:
let start=datetime("2020-06-18T20:59:00.000Z");
let end=datetime("2020-07-24T21:10:00.000Z");
let operationNameToEval="GET DroneDeliveries/GetDroneUtilization";
let dependencyType="Azure DocumentDB";
let dataset=requests
| where timestamp > start and timestamp < end
| where success == true
| where name == operationNameToEval;
dataset
| project reqOk=itemCount
| summarize
SuccessRequests=sum(reqOk),
TotalNumberOfDepCalls=(toscalar(dependencies
| where timestamp > start and timestamp < end
| where type == dependencyType
| summarize sum(itemCount)))
| project
OperationName=operationNameToEval,
DependencyName=dependencyType,
SuccessRequests,
AverageNumberOfDepCallsPerOperation=(TotalNumberOfDepCalls/SuccessRequests)
Abychom to shrnuli, druhý zátěžový test ukazuje zlepšení. Operace ale GetDroneUtilization stále trvá přibližně o řád déle než příští nejpomalejší operace. Když se podíváte na transakce od začátku do konce, pomůže vám to vysvětlit, proč:
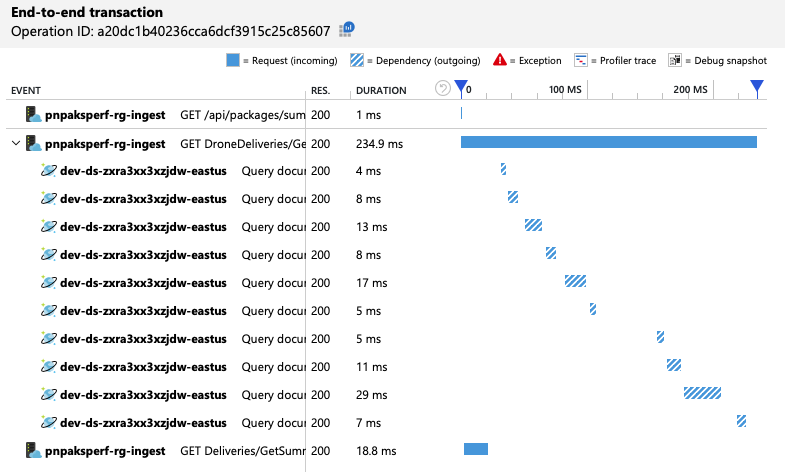
Jak už bylo zmíněno dříve, GetDroneUtilization operace zahrnuje dotaz na službu Azure Cosmos DB napříč oddíly. To znamená, že klient Azure Cosmos DB musí dotaz rozmíslit do každého fyzického oddílu a shromáždit výsledky. Jak ukazuje kompletní zobrazení transakcí, tyto dotazy se provádějí sériově. Operace trvá tak dlouho, jak dlouho se součet všech dotazů – a tento problém se bude zhoršovat jen s tím, jak se zvětší velikost dat a přidají se další fyzické oddíly.
Na základě předchozích výsledků je zřejmým způsobem, jak snížit latenci, paralelní vydávání dotazů. Klientská sada SDK služby Azure Cosmos DB má nastavení, které řídí maximální stupeň paralelismu.
| Hodnota | Popis |
|---|---|
| 0 | Bez paralelismu (výchozí) |
| > 0 | Maximální počet paralelních volání |
| -1 | Klientská sada SDK vybere optimální stupeň paralelismu. |
U třetího zátěžového testu bylo toto nastavení změněno z 0 na -1. Následující tabulka shrnuje výsledky:
| Metric | Test 1 | Test 2 | Test 3 |
|---|---|---|---|
| Propustnost (početq/s) | 19 | 23 | 42 |
| Průměrná latence (ms) | 669 | 569 | 215 |
| Úspěšné požadavky | 9,8 K | 11 kB | 20 kB |
| Omezené požadavky | 2,72 K | 0 | 0 |
Z grafu zátěžového testu je nejen mnohem vyšší celková propustnost (oranžová čára), ale propustnost také drží krok se zatížením (fialová čára).
Můžeme ověřit, že klient Služby Azure Cosmos DB provádí dotazy paralelně, a to tak, že se podíváme na kompletní zobrazení transakcí:
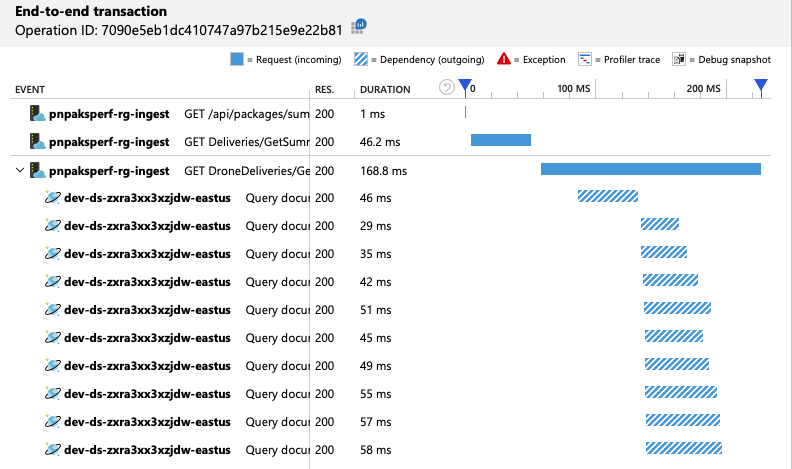
Je zajímavé, že vedlejším účinkem zvýšení propustnosti je, že se také zvyšuje počet jednotek RU spotřebovaných za sekundu. Přestože Azure Cosmos DB během tohoto testu neomezovala žádné požadavky, spotřeba se blížila zřízenému limitu RU:
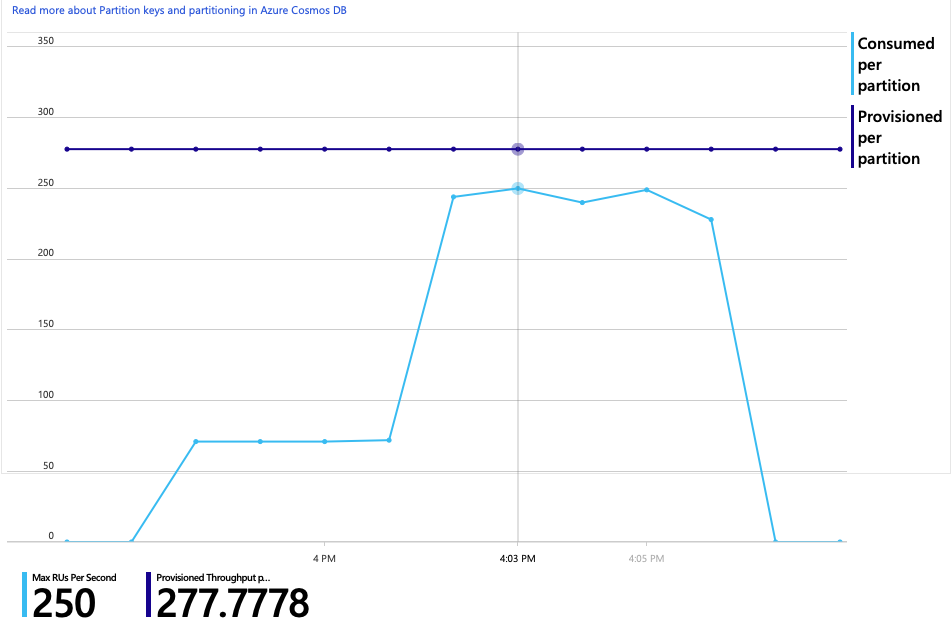
Tento graf může být signálem k dalšímu horizontálnímu navýšení kapacity databáze. Ukázalo se však, že místo toho můžeme dotaz optimalizovat.
Předchozí zátěžový test ukázal lepší výkon z hlediska latence a propustnosti. Průměrná latence požadavků se snížila o 68 % a propustnost se zvýšila o 220 %. Dotaz napříč oddíly je ale problém.
Problém s dotazy napříč oddíly spočívá v tom, že platíte za RU napříč všemi oddíly. Pokud se dotaz spouští jenom občas, třeba jednou za hodinu, nemusí to být důležité. Kdykoli ale uvidíte úlohu s velkými nároky na čtení, která zahrnuje dotaz napříč oddíly, měli byste zjistit, jestli je možné dotaz optimalizovat zahrnutím klíče oddílu. (Možná budete muset kolekci přepracovat tak, aby používala jiný klíč oddílu.)
Tady je dotaz pro tento konkrétní scénář:
SELECT * FROM c
WHERE c.ownerId = <ownerIdValue> and
c.year = <yearValue> and
c.month = <monthValue>
Tento dotaz vybere záznamy, které odpovídají konkrétnímu ID vlastníka a měsíc/rok. V původním návrhu není žádná z těchto vlastností klíčem oddílu. To vyžaduje, aby klient rozmíslal dotaz do každého fyzického oddílu a shromáždil výsledky. Za účelem zvýšení výkonu dotazů změnil vývojový tým návrh tak, aby ID vlastníka bylo klíčem oddílu pro kolekci. Dotaz tak může cílit na konkrétní fyzický oddíl. (Azure Cosmos DB to zpracovává automaticky, nemusíte spravovat mapování mezi hodnotami klíčů oddílů a fyzickými oddíly.)
Po přepnutí kolekce na nový klíč oddílu došlo k dramatickému zlepšení spotřeby RU, což přímo znamená nižší náklady.
| Metric | Test 1 | Test 2 | Test 3 | Test 4 |
|---|---|---|---|---|
| Jednotky RU na operaci | 29 | 29 | 29 | 3.4 |
| Volání na operaci | 11 | 9 | 10 | 1 |
Kompletní zobrazení transakcí ukazuje, že podle předpovědi dotaz čte pouze jeden fyzický oddíl:
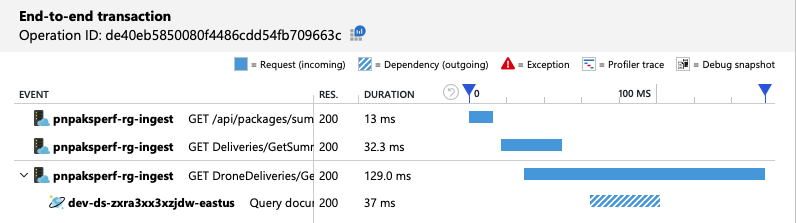
Zátěžový test ukazuje vyšší propustnost a latenci:
| Metric | Test 1 | Test 2 | Test 3 | Test 4 |
|---|---|---|---|---|
| Propustnost (početq/s) | 19 | 23 | 42 | 59 |
| Průměrná latence (ms) | 669 | 569 | 215 | 176 |
| Úspěšné požadavky | 9,8 K | 11 kB | 20 kB | 29 kB |
| Omezené požadavky | 2,72 K | 0 | 0 | 0 |
Výsledkem vyššího výkonu je velmi vysoké využití procesoru uzlu:
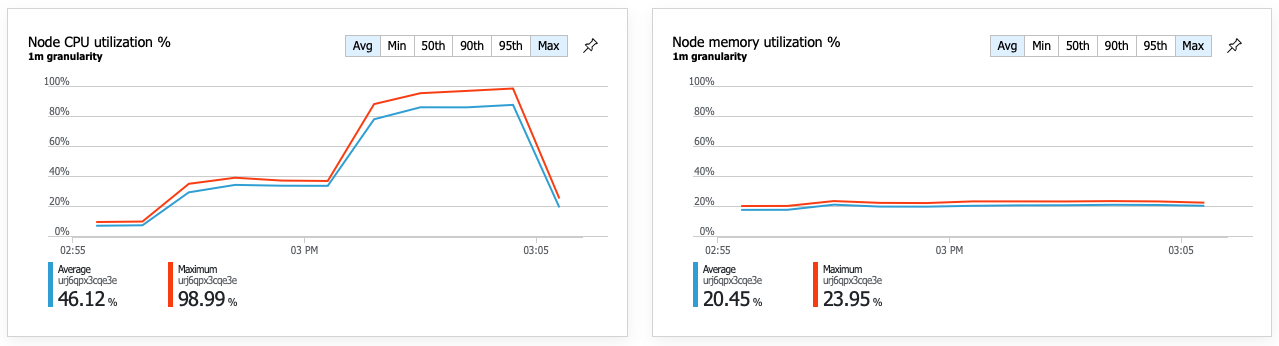
Ke konci zátěžového testu dosáhl průměrný procesor přibližně 90 % a maximální využití procesoru 100 %. Tato metrika označuje, že procesor je dalším kritickým bodem v systému. Pokud potřebujete vyšší propustnost, dalším krokem může být horizontální navýšení kapacity služby Delivery Service na více instancí.
V tomto scénáři byly identifikovány následující kritické body:
- Požadavky na omezování služby Azure Cosmos DB kvůli nedostatečným zřízeným RU
- Vysoká latence způsobená dotazováním více databázových oddílů v sériovém pořadí.
- Neefektivní dotaz napříč oddíly, protože dotaz neobsažil klíč oddílu.
Využití procesoru bylo navíc identifikováno jako potenciální kritický bod ve vyšším měřítku. Při diagnostice těchto problémů se vývojový tým podíval na:
- Latence a propustnost ze zátěžového testu.
- Chyby služby Azure Cosmos DB a spotřeba RU
- Kompletní zobrazení transakcí v Application Insight.
- Využití procesoru a paměti v přehledech kontejnerů služby Azure Monitor
Kontrola antipatternů výkonu