Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Tato stránka popisuje možnosti výpočetních prostředků poznámkového bloku. Poznámkový blok můžete spustit na univerzálním výpočetním prostředku, bezserverovém výpočetním prostředku, nebo pro příkazy SQL můžete použít SQL Warehouse, typ výpočetního prostředku optimalizovaný pro SQL analýzu. Další informace o typech výpočetních prostředků najdete v tématu Výpočty.
Výchozí výpočet
V pracovních prostorech s povolenou službou Unity Catalog jsou nové poznámkové bloky ve výchozím nastavení nastaveny na bezserverový výpočetní výkon. Pokud ručně nevyberete výpočetní prostředek a spustíte buňku, poznámkový blok se automaticky připojí k bezserverovému výpočetnímu prostředí.
Automatické připojení výpočetních prostředků
V nastavení pro vývojáře můžete nakonfigurovat poznámkové bloky tak, aby se automaticky připojily k výpočetnímu prostředku, a spustit relaci při interakci s editorem:
V levém horním rohu klikněte na ikonu uživatele.
Klikněte na Nastavení.
Kliknutím na Vývojář přejdete do nastavení pro vývojáře.
Zapněte možnost Automaticky vytvořit relaci při interakci s editorem , aby se automaticky spustila výpočetní relace při interakci s editorem. Databricks ve výchozím nastavení používá výpočetní prostředek na základě vašich preferencí (bezserverové služby nebo SQL Warehouse) a posledního použitého výpočetního prostředku.
OR
Toto nastavení vypněte, pokud nechcete, aby se poznámkový blok automaticky připojil k výpočetnímu prostředku a spustil ho.
Funkce pomoci s kódem, včetně automatického dokončování, formátování kódu a ladicího programu, vyžadují, aby byl poznámkový blok připojený k aktivní výpočetní relaci. Pokud notebook nezahájil výpočetní relaci, funkce pomoci s kódem jsou neaktivní.
Bezserverové výpočetní služby pro notebooky
Bezserverové výpočtové zdroje umožňují rychle připojit notebook k výpočetním zdrojům na vyžádání.
Pokud se chcete připojit k bezserverovým výpočtům, klikněte v poznámkovém bloku na rozevírací nabídku výpočtů a vyberte Serverless.
Další informace najdete v tématu Bezserverové výpočetní prostředky pro poznámkové bloky .
Automatizované obnovení relací pro bezserverové poznámkové bloky
Nečinné ukončení bezserverového výpočetního prostředí může způsobit ztrátu probíhající práce, jako je Python hodnoty proměnných, v poznámkových blocích. Pokud se tomu chcete vyhnout, zapněte automatické obnovení relací pro bezserverové notebooky.
- Klikněte na své uživatelské jméno v pravém horním rohu pracovního prostoru a potom v rozevíracím seznamu klikněte na Nastavení .
- Na bočním panelu Nastavení vyberte Vývojář.
- V části Experimentální funkce zapněte automatické obnovení relace pro bezserverové poznámkové bloky.
Povolením tohoto nastavení umožníte Databricks vytvořit snímek stavu paměti bezserverového poznámkového bloku před ukončením nečinnosti. Když se po odpojení nečinnosti vrátíte do poznámkového bloku, zobrazí se v horní části stránky banner. Chcete-li obnovit pracovní stav, klikněte na Tlačítko Znovu připojit .
Když se znovu připojíte, Databricks obnoví celé pracovní prostředí, včetně následujících:
- Definice proměnných, funkcí a tříd v Pythonu: Stav Pythonu je serializován v rámci procesu pomocí pickle/cloudpickle a obnoven do nového REPL, takže není potřeba znovu importovat ani znovu deklarovat.
- Datové rámce Sparku, uložená v mezipaměti a dočasná zobrazení: Data, která jste načetli, transformovali nebo v mezipaměti (včetně dočasných zobrazení), se zachovají, takže se vyhnete nákladnému opětovnému načítání nebo překompilace.
- Stav relace Sparku: Nastavení konfigurace na úrovni Sparku, dočasná zobrazení, úpravy katalogu a uživatelem definované funkce (UDF) se obnoví prostřednictvím migrace relace Spark Connect, takže je nemusíte resetovat.
Pokud se prostředí změnilo způsobem, který by znebezpečil deserializaci, například nekompatibilní Python nebo verze balíčků, snímek se zneplatní a poznámkový blok se vrátí do nové relace.
Úložiště dat snímků
Data snímku se ukládají do výchozího úložiště vašeho pracovního prostoru. Samotný poznámkový blok ukládá pouze metadata, včetně ukazatele s ID poznámkového bloku, časového razítka a informací o relaci. Datový payload není uložen v notebooku. Cesty objektů blob jsou před uložením v atributech poznámkového bloku zašifrované a cesty snímků jsou vyloučené z exportu a importu poznámkového bloku, aby se zabránilo obnovení stavu do jiného pracovního prostoru.
Snímky se řídí výchozími nastaveními hodnoty TTL cloudového ukládání (přibližně jeden měsíc) a automaticky exspirují. Odstraněním poznámkového bloku se odstraní také jeho snímky. Váš cloudový účet v rámci standardního využití úložiště pracovního prostoru nese náklady na úložiště. Tato funkce používá serializaci procesů v Pythonu místo kontrolních bodů na úrovni kontejneru, což udržuje snímky menší a rychlejší pro vytváření.
Zabezpečení a řízení přístupu
Obnovení snímku respektuje oprávnění poznámkového bloku. Obnovení stavu vyžaduje oprávnění SPUSTIT v poznámkovém bloku. Šifrovaná metadata brání prohlížečům v přímém načítání objektů blob snímků a při obnovení se vynucují kontroly oprávnění.
Omezení
Tato funkce má omezení a nepodporuje obnovení následujících:
- Stavy Sparku starší než 4 dny
- Stavy Sparku o velikosti větší než 50 MB
- Data související se skriptováním SQL
- Popisovače souborů
- Zámky a další primitivy souběžnosti
- Síťová připojení
Připojení poznámkového bloku k výpočetnímu prostředku pro všechny účely
Pokud chcete připojit poznámkový blok k výpočetnímu prostředku pro všechny účely, potřebujete MŮŽE PŘIPOJIT k oprávněním výpočetního prostředku.
Důležité
Pokud je poznámkový blok připojen k výpočetnímu prostředku, má každý uživatel s oprávněním CAN RUN na poznámkovém bloku implicitní právo pro přístup k výpočetnímu prostředku.
Pokud chcete připojit poznámkový blok k výpočetnímu prostředku, klikněte na ikonu pro výběr výpočetního prostředku v panelu nástrojů poznámkového bloku a v rozevírací nabídce vyberte prostředek.
V nabídce se zobrazí výběr výpočetních prostředků pro všechny účely a služby SQL Warehouse, které jste nedávno použili nebo které jsou aktuálně spuštěné.

Pokud chcete vybrat ze všech dostupných výpočetních prostředků, klikněte na Další.... Vyberte si z dostupných obecných výpočetních prostředků nebo skladů SQL.
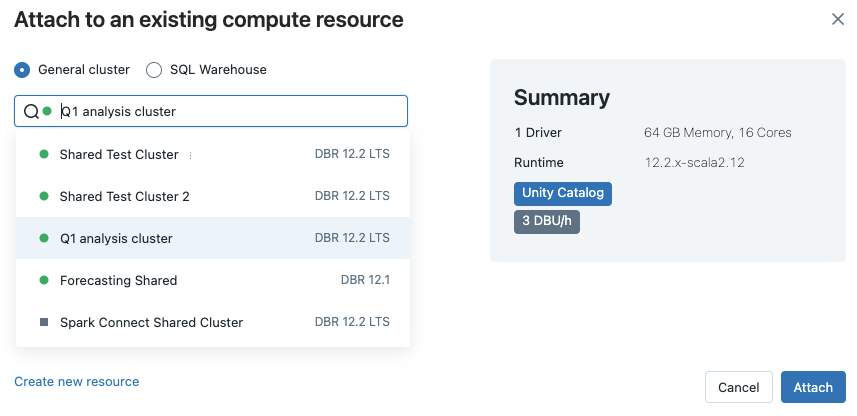
Nový výpočetní prostředek pro všechny účely můžete vytvořit také tak, že v rozevírací nabídce vyberete Vytvořit nový prostředek...
Důležité
Připojený poznámkový blok má definované následující proměnné Apache Sparku.
| Třída | Název proměnné |
|---|---|
SparkContext |
sc |
SQLContext/HiveContext |
sqlContext |
SparkSession (Spark 2.x) |
spark |
Nevytvářejte SparkSession, SparkContext nebo SQLContext. To vede k nekonzistentnímu chování.
Použití poznámkového bloku se službou SQL Warehouse
Když je poznámkový blok připojený ke službě SQL Warehouse, můžete spouštět buňky SQL a Markdown. Spuštění buňky v jiném jazyce (například Python nebo R) vyvolá chybu. Buňky SQL spuštěné ve službě SQL Warehouse se zobrazují v historii dotazů SQL Warehouse. Uživatel, který spustil dotaz, může zobrazit profil dotazu z poznámkového bloku kliknutím na uplynulý čas v dolní části výstupu.
Poznámkové bloky připojené k SQL Warehouse podporují relace SQL Warehouse, kde můžete definovat proměnné, vytvářet dočasná zobrazení a uchovávat stav napříč několika spuštěními dotazů. Logiku SQL můžete vytvořit iterativním způsobem, aniž byste museli spouštět všechny příkazy najednou. Podívejte se na co jsou relace SQL Warehouse?
Spuštění poznámkového bloku vyžaduje profesionální nebo bezserverový SQL Warehouse. Musíte mít přístup k pracovnímu prostoru a SQL Warehouse.
Pokud chcete k SQL Warehouse připojit poznámkový blok, postupujte takto:
Na panelu nástrojů poznámkového bloku klikněte na selektor výpočetních prostředků. V rozevírací nabídce se zobrazují výpočetní prostředky, které jsou aktuálně spuštěné nebo které jste nedávno použili. Sklady SQL jsou označené značkou
 .
.V nabídce vyberte SQL Warehouse.
Pokud chcete zobrazit všechny dostupné sklady SQL, v rozevírací nabídce vyberte Další... Zobrazí se dialogové okno s výpočetními prostředky dostupnými pro poznámkový blok. Vyberte SQL Warehouse, vyberte sklad, který chcete použít, a klikněte na Připojit.
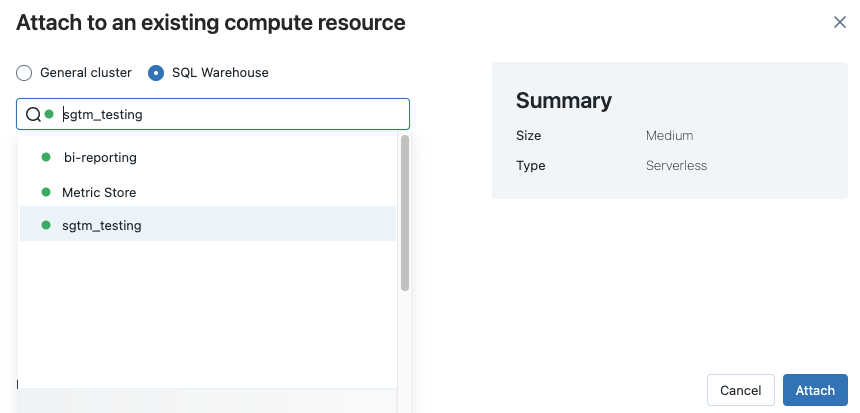
Při vytváření pracovního postupu nebo naplánované úlohy můžete také jako výpočetní prostředek pro poznámkový blok SQL vybrat SQL Warehouse.
Omezení SQL Warehouse
Pro více informací si přečtěte Známá omezení poznámkových bloků Databricks.