Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Poznámkové bloky Databricks podporují formátování kódu, automatické dokončování, více jazyků a příkazy magic pro vývoj kódu v Python, SQL, Scala a R.
Další podrobnosti o pokročilých funkcích dostupných v editoru, jako je automatické dokončování, výběr proměnných, podpora více kurzorů a porovnání vedle sebe, najdete v tématu Navigace v poznámkovém bloku Databricks a editoru souborů.
Při použití poznámkového bloku nebo editoru souborů je k dispozici Genie Code, který vám pomůže vygenerovat, vysvětlit a ladit kód. Další informace najdete v tématu Použití kódu Genie .
Poznámkové bloky Databricks také obsahují integrovaný interaktivní ladicí program pro Python poznámkové bloky. Viz Ladění poznámkových bloků Databricks.
Důležité
Poznámkový blok musí být připojený k aktivní výpočetní relaci pro funkce asistence při psaní kódu, včetně automatického dokončování, formátování kódu v jazyce Python a ladicího programu.
Modularizace kódu
S modulem Databricks Runtime 11.3 LTS a novějším můžete v pracovním prostoru Azure Databricks vytvářet a spravovat soubory zdrojového kódu a podle potřeby je importovat do svých poznámkových bloků.
Další informace o práci se soubory zdrojového kódu najdete v tématu Sdílení kódu mezi poznámkovými bloky Databricks a Work with Python and R modules.
Formátování buněk kódu
Azure Databricks poskytuje nástroje, které umožňují formátovat Python a kód SQL v buňkách poznámkového bloku. Tyto nástroje snižují úsilí o formátování kódu a pomáhají vynucovat stejné standardy kódování v poznámkových blocích.
Python černá knihovna formátovače
Důležité
Tato funkce je ve verzi Public Preview.
Azure Databricks podporuje formátování kódu Python pomocí black v poznámkovém bloku. Poznámkový blok musí být připojený ke clusteru s nainstalovanými balíčky black a tokenize-rt Python.
V Databricks Runtime 11.3 LTS a novějších Azure Databricks předinstaluje black a tokenize-rt. Formátovací modul můžete použít přímo bez nutnosti instalovat tyto knihovny.
V Databricks Runtime 10.4 LTS a dřívějších verzích je nutné nainstalovat black==22.3.0 a tokenize-rt==4.2.1 od PyPI na váš notebook nebo cluster, abyste mohli použít Python formatter. V poznámkovém bloku můžete spustit následující příkaz:
%pip install black==22.3.0 tokenize-rt==4.2.1
nebo nainstalujte knihovnu do clusteru.
Další podrobnosti o instalaci knihoven najdete v tématu Python správa prostředí.
Pro soubory a poznámkové bloky ve složkách Databricks Git můžete nakonfigurovat formátovací Python na základě souboru pyproject.toml. Pokud chcete tuto funkci použít, vytvořte soubor v kořenovém pyproject.toml adresáři složky Git a nakonfigurujte ho podle formátu konfigurace Black. Upravte v souboru oddíl [tool.black]. Konfigurace se použije při formátování libovolného souboru a poznámkového bloku v této složce Git.
Jak formátovat buňky Python a SQL
Abyste mohli formátovat kód, musíte mít oprávnění CAN EDIT v poznámkovém bloku.
Azure Databricks používá vlastní formátovač SQL k formátování SQL a Black formátovač kódu pro Python.
Formátovací modul můžete aktivovat následujícími způsoby:
Formátování jedné buňky
- Klávesová zkratka: Stiskněte Cmd+Shift+F.
- Nabídka příkazového kontextu
- Formát buňky SQL: Vyberte Formát SQL v rozevírací nabídce kontextu příkazu buňky SQL. Tato položka nabídky je viditelná jenom v buňkách poznámkového bloku SQL nebo v buňkách, které mají jazykové
%sqlkouzlo. - Formát Python buňky: V rozbalovací nabídce příkazu buňky Python vyberte Formát Python. Tato položka nabídky je viditelná jenom v buňkách poznámkového bloku Python nebo v buňkách s
%pythonlanguage magic.
- Formát buňky SQL: Vyberte Formát SQL v rozevírací nabídce kontextu příkazu buňky SQL. Tato položka nabídky je viditelná jenom v buňkách poznámkového bloku SQL nebo v buňkách, které mají jazykové
- Nabídka Edit: Vyberte buňku Python nebo SQL a pak vyberte Edit > Formát buněk .
Formátování více buněk
Vyberte více buněk a pak vyberte Upravit > formát buněk. Pokud vyberete buňky ve více než jednom jazyce, formátují se pouze buňky SQL a Python. To zahrnuje ty, které používají
%sqla%python.Formátovat všechny buňky Python a SQL v poznámkovém bloku
Vyberte Upravit > formát poznámkového bloku. Pokud poznámkový blok obsahuje více jazyků, formátují se jenom buňky SQL a Python. To zahrnuje ty, které používají
%sqla%python.
Pokud chcete přizpůsobit formátování dotazů SQL, podívejte se na příkazy SQL vlastního formátu.
Omezení formátování kódu
- Black přísně dodržuje standardy PEP 8 pro čtyřmezerové odsazení. Odsazení nejde upravit dle potřeby.
- Formátování vložených Python řetězců uvnitř UDF SQL se nepodporuje. Podobně není podporováno formátování řetězců SQL uvnitř Python UDF.
Jazyky kódu v notebooku
Nastavení výchozího jazyka
Pod názvem poznámkového bloku se zobrazí výchozí jazyk.

Pokud chcete změnit výchozí jazyk, klikněte na tlačítko jazyka a v rozevírací nabídce vyberte nový jazyk. Aby bylo zajištěno, že stávající příkazy budou dál fungovat, jsou příkazy předchozího výchozího jazyka automaticky opatřeny příkazem pro nastavení jazyka.
Smíchat jazyky
Ve výchozím nastavení používají buňky výchozí jazyk poznámkového bloku. Výchozí jazyk v buňce můžete přepsat kliknutím na tlačítko jazyka a výběrem jazyka z rozevírací nabídky.
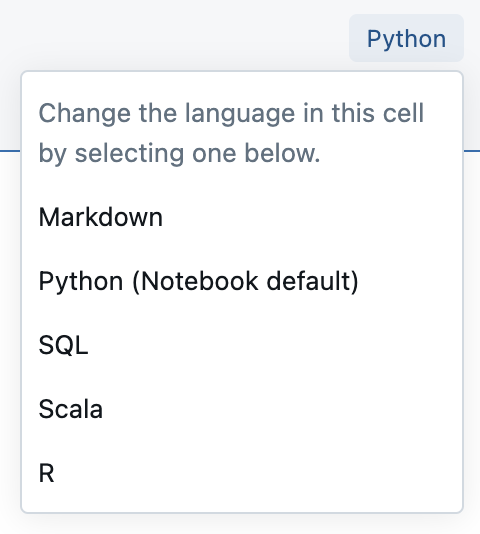
Případně můžete použít jazykový příkaz magic %<language> na začátku buňky. Podporované příkazy magic jsou: %python, %r, %scalaa %sql.
Poznámka:
Když vyvoláte příkaz jazyka magic, příkaz se odešle do REPL v prostředí provádění pro tento poznámkový blok. Proměnné definované v jednom jazyce (a proto v REPL pro tento jazyk) nejsou k dispozici v REPL jiného jazyka. REPLy mohou sdílet stav pouze prostřednictvím externích prostředků, jako jsou soubory v DBFS nebo objekty v objektovém úložišti.
Poznámkové bloky také podporují několik pomocných "magic" příkazů.
-
%sh: Umožňuje spustit shell kód v programátorském poznámkovém bloku. Aby buňka selhala, pokud příkaz prostředí skončí s nenulovým stavem ukončení, přidejte možnost-e. Tento příkaz se spouští pouze na ovladači Apache Spark, nikoli na pracovnících. Ke spuštění shellového příkazu na všech uzlech použijte inicializační skript. -
%fs: Umožňuje používatdbutilspříkazy systému souborů. Pokud chcete například spustitdbutils.fs.lspříkaz pro výpis souborů, můžete místo toho zadat%fs ls. Další informace najdete v tématu Work with files on Azure Databricks. -
%md: Umožňuje zahrnout různé typy dokumentace, včetně textu, obrázků a matematických vzorců a rovnic. Postup najdete v další části.
Zvýraznění syntaxe SQL a automatické dokončování v příkazech Python
Zvýraznění syntaxe a funkce SQL autocomplete jsou k dispozici, když používáte SQL uvnitř příkazu Python, například v příkazu spark.sql.
Prozkoumejte výsledky buněk SQL
V poznámkovém bloku Databricks se výsledky z buňky jazyka SQL automaticky zpřístupňují jako implicitní datový rámec přiřazený proměnné _sqldf. Tuto proměnnou pak můžete použít v libovolném Python a buňkách SQL, které pak spustíte, bez ohledu na jejich pozici v poznámkovém bloku.
Poznámka:
Tato funkce má následující omezení:
- Proměnná
_sqldfnení k dispozici v poznámkových blocích, které pro výpočty používají SQL Warehouse . - Použití
_sqldfv následujících Pythonových buňkách je podporováno v Databricks Runtime 13.3 a vyšší. - Použití
_sqldfv následujících buňkách SQL je podporováno pouze v Databricks Runtime 14.3 a vyšší. - Pokud dotaz používá klíčová slova
CACHE TABLEneboUNCACHE TABLE,_sqldfproměnná není k dispozici.
Následující snímek obrazovky ukazuje, jak lze _sqldf použít v následujících buňkách Python a SQL:

Důležité
Proměnná _sqldf se znovu přiřazuje při každém spuštění buňky SQL. Pokud se chcete vyhnout ztrátě odkazu na konkrétní výsledek datového rámce, přiřaďte ho novému názvu proměnné před spuštěním další buňky SQL:
Python
new_dataframe_name = _sqldf
SQL
ALTER VIEW _sqldf RENAME TO new_dataframe_name
Paralelní spouštění buněk SQL
Když je spuštěný příkaz a poznámkový blok je připojený k interaktivnímu clusteru, můžete spustit buňku SQL současně s aktuálním příkazem. V nové paralelní relaci se spustí buňka SQL.
Pro paralelní spuštění buňky:
Klikněte na možnost Spustit. Buňka se okamžitě spustí.

Vzhledem k tomu, že se buňka spouští v nové relaci, dočasná zobrazení, funkce definované uživatelem a implicit Python DataFrame (_sqldf) nejsou podporovány pro buňky, které se spouští paralelně. Kromě toho se při paralelním provádění používají výchozí názvy katalogů a databází. Pokud váš kód odkazuje na tabulku v jiném katalogu nebo databázi, je nutné zadat název tabulky pomocí tříúrovňového oboru názvů (catalog.schema.).table
Spouštění buněk SQL ve službě SQL Warehouse
Příkazy SQL můžete spouštět v poznámkovém bloku Databricks ve službě SQL Warehouse, typ výpočetních prostředků, který je optimalizovaný pro analýzu SQL. Viz Použití poznámkového bloku se službou SQL Warehouse.
Použijte magické příkazy
Poznámkové bloky Databricks podporují různé magické příkazy, které rozšiřují funkčnost nad rámec standardní syntaxe a zjednodušují běžné úlohy. Magické příkazy mají předponu % a platí pro jeden řádek. Magie buněk mají předponu %% a vztahují se na celé tělo buňky.
| Kouzelný příkaz | Příklad | Description |
|---|---|---|
%python |
%pythonprint("Hello") |
Přepněte jazyk buňky na Python. Spustí Python kód v buňce. |
%r |
%rprint("Hello") |
Přepněte jazyk buňky na R. Spustí kód R v buňce. |
%scala |
%scalaprintln("Hello") |
Přepněte jazyk buňky na Scala. Spustí kód Scala v buňce. |
%sql |
%sqlSELECT * FROM table |
Přepněte jazyk buňky na SQL. Výsledky jsou k dispozici jako _sqldf v buňkách Python/SQL. |
%md |
%md# TitleContent here |
Přepněte jazyk buňky na Markdown. Vykreslí obsah Markdownu v buňce. Podporuje text, obrázky, vzorce a LaTeX. |
%pip |
%pip install pandas |
Instalace balíčků Pythonu (v rozsahu poznámkového bloku) Viz knihovny Python v rámci notebooků. |
%run |
%run /path/to/notebook |
Spusťte další poznámkový blok a importujte jeho funkce a proměnné. Viz pracovní postupy poznámkového bloku. |
%fs |
%fs ls /path |
Spusťte příkazy systému souborů dbutils. Zkrácená forma pro dbutils.fs příkazy. Viz Práce se soubory. |
%sh |
%sh ls -la |
Spusťte příkazy shellu. Spouští se jenom na uzlu ovladače. Použijte -e k selhání v případě chyby. |
%tensorboard |
%tensorboard --logdir /logs |
Zobrazí uživatelské rozhraní TensorBoardu přímo v řádku. K dispozici pouze pro Databricks Runtime ML. Viz TensorBoard. |
%set_cell_max_output_size_in_mb |
%set_cell_max_output_size_in_mb 10 |
Nastavte maximální velikost výstupu buňky. Rozsah: 1–20 MB. Platí pro všechny následující buňky v poznámkovém bloku. |
%skip |
%skipprint("This won't run") |
Přeskočte provádění buněk. Zabrání spuštění buňky při spuštění poznámkového bloku. |
%%profile |
%%profilemy_function() |
Spuštění kódu Python profilu. Zobrazí hierarchický strom volání s informacemi o časování. Vyžaduje Databricks Runtime 17.2 a vyšší. |
%%oprofile |
%%oprofilemy_function() |
Vytváření profilového objektu během spuštění buňky. Zobrazí tabulku čistých nových objektů seskupených podle typu vytvořených. Vyžaduje Databricks Runtime 17.2 a vyšší. |
%uv pip |
%uv pip install simplejson |
Instalace a správa balíčků Python (v rámci poznámkového bloku) pomocí uv a standardních dílčích příkazů pip (install, uninstall, list, show, freeze, check, tree). Podívejte se, jak dosáhnout rychlejší instalace pomocí %uv pip. |
Poznámka:
IPython Automagic: Poznámkové bloky Databricks mají ve výchozím nastavení povolenou automatickou magii IPythonu, což umožňuje fungování některých příkazů pip bez předpony %. Například pip install pandas funguje stejně jako %pip install pandas.
Důležité
- Proměnné a stav jsou izolované mezi různými jazykovými prostředími REPL. Například Python proměnné nejsou v buňkách Scala přístupné.
- Buňka poznámkového bloku může mít jenom jeden příkaz magic buňky a musí to být první řádek buňky.
-
%runmusí být v samostatné buňce, protože jej spouští v rámci celého poznámkového bloku. - Při použití
%pipv Databricks Runtime 12.2 LTS a níže umístěte všechny instalační příkazy balíčku na začátek poznámkového bloku, protože po instalaci se resetuje stav Python.