Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Tento článek obsahuje informace o řešení nejčastějších problémů s bezserverovým fondem SQL ve službě Azure Synapse Analytics.
Další informace o Azure Synapse Analytics najdete v tématech v přehledu.
Synapse Studio
Synapse Studio je snadno použitelný nástroj, který můžete použít pro přístup k datům pomocí prohlížeče bez nutnosti instalovat nástroje pro přístup k databázi. Synapse Studio není navržené tak, aby četla velkou sadu dat nebo úplnou správu objektů SQL.
Bezserverový fond SQL je v nástroji Synapse Studio nepřístupný.
Pokud Synapse Studio nemůže navázat připojení k bezserverovém fondu SQL, všimnete si, že bezserverový fond SQL je neaktivní nebo se zobrazí stav Offline.
Obvykle k tomuto problému dochází z jednoho ze dvou důvodů:
- Vaše síť brání komunikaci s back-endem Azure Synapse Analytics. Nejčastějším případem je zablokování portu TCP 1443. Pokud chcete, aby bezserverový fond SQL fungoval, odblokujte tento port. Jiné problémy by mohly zabránit fungování bezserverového fondu SQL. Další informace najdete v průvodci odstraňováním potíží.
- Nemáte oprávnění k přihlášení k bezserverovému fondu SQL. Pokud chcete získat přístup, musí vás správce pracovního prostoru Azure Synapse přidat do role správce pracovního prostoru nebo do role správce SQL. Další informace najdete v tématu Řízení přístupu ke službě Azure Synapse.
Připojení WebSocket se neočekávaně ukončilo.
Dotaz může selhat s chybovou zprávou Websocket connection was closed unexpectedly. Tato zpráva znamená, že připojení prohlížeče k Synapse Studiu se přerušilo, například kvůli problému se sítí.
- Pokud chcete tento problém vyřešit, spusťte dotaz znovu.
- Zkuste Azure Data Studio nebo SQL Server Management Studio použít pro stejné dotazy místo Synapse Studia, abyste je dále prozkoumali.
- Pokud se tato zpráva ve vašem prostředí často vyskytuje, obraťte se na správce sítě. Můžete také zkontrolovat nastavení brány firewall a podívat se do průvodce odstraňováním potíží.
- Pokud problém přetrvává, vytvořte prostřednictvím portálu Azure tiket podpory.
Bezserverové databáze se v nástroji Synapse Studio nezobrazují
Pokud nevidíte databáze vytvořené v bezserverovém fondu SQL, zkontrolujte, jestli se spustil bezserverový fond SQL. Pokud je bezserverový fond SQL deaktivován, databáze se nezobrazí. Spusťte libovolný dotaz, například SELECT 1, v bezserverovém fondu SQL, aby se aktivoval a aby se databáze zobrazily.
Bezserverový fond SQL Synapse se zobrazuje jako nedostupný
Příčinou tohoto chování je často nesprávná konfigurace sítě. Ujistěte se, že jsou porty správně nakonfigurované. Pokud používáte bránu firewall nebo privátní koncové body, zkontrolujte také toto nastavení.
Nakonec se ujistěte, že jsou uděleny příslušné role a nebyly odvolány.
Nelze vytvořit novou databázi, protože požadavek bude používat starý klíč nebo klíč s vypršenou platností.
Příčinou této chyby je změna klíče spravovaného zákazníkem pracovního prostoru používaného k šifrování. Všechna data v pracovním prostoru můžete znovu zašifrovat pomocí nejnovější verze aktivního klíče. Pokud chcete klíč znovu zašifrovat, změňte klíč na webu Azure Portal na dočasný klíč a pak přepněte zpět na klíč, který chcete použít k šifrování. Zde se můžete dozvědět, jak spravovat klíče pracovního prostoru.
Bezserverový SQL fond Synapse není dostupný po převodu předplatného do jiného tenanta Microsoft Entra.
Pokud jste předplatné přesunuli do jiného tenanta Microsoft Entra, mohou nastat problémy s bezserverovým SQL prostředím. Vytvořte lístek podpory a podpora Azure vás bude kontaktovat, abyste tento problém vyřešili.
Přístup k úložišti
Pokud při pokusu o přístup k souborům v úložišti Azure dojde k chybám, ujistěte se, že máte oprávnění pro přístup k datům. Měli byste mít přístup k veřejně dostupným souborům. Pokud se pokusíte získat přístup k datům bez přihlašovacích údajů, ujistěte se, že vaše identita Microsoft Entra má přímý přístup k souborům.
Pokud máte klíč sdíleného přístupového podpisu, který byste měli použít pro přístup k souborům, ujistěte se, že jste vytvořili přihlašovací údaje na úrovni serveru nebo databáze, které obsahují tyto přihlašovací údaje. Přihlašovací údaje se vyžadují, pokud potřebujete přistupovat k datům pomocí spravované identity pracovního prostoru a vlastního hlavního názvu služby (SPN).
Ve službě Azure Data Lake Storage nejde číst, vypsat ani získat přístup k souborům
Pokud používáte přihlášení Microsoft Entra bez explicitních přihlašovacích údajů, ujistěte se, že vaše identita Microsoft Entra má přístup k souborům v úložišti. Pokud chcete získat přístup k souborům, musí mít vaše Microsoft Entra identita oprávnění Čtenář dat Blob nebo oprávnění k výpisu a čteníseznamů řízení přístupu (ACL) v ADLS. Další informace najdete v tématu Dotaz selže, protože soubor nelze otevřít.
Pokud přistupujete k úložišti pomocí přihlašovacích údajů, ujistěte se, že vaše spravovaná identita nebo název služby má roli Čtenář dat nebo Přispěvatel nebo specifická oprávnění ACL. Pokud jste použili token sdíleného přístupového podpisu, ujistěte se, že má rl požadované oprávnění a že nevypršela jeho platnost.
Pokud používáte přihlášení SQL a OPENROWSET funkci bez zdroje dat, ujistěte se, že máte přihlašovací údaje na úrovni serveru, které odpovídají identifikátoru URI úložiště a mají oprávnění pro přístup k úložišti.
Dotaz selže, protože soubor nejde otevřít
Pokud váš dotaz selže s chybou File cannot be opened because it does not exist or it is used by another process a jste si jistí, že oba soubory existují a nejsou používány jiným procesem, nemůže bezserverový fond SQL získat přístup k souboru. K tomuto problému obvykle dochází, protože vaše identita Microsoft Entra nemá oprávnění k přístupu k souboru nebo protože brána firewall blokuje přístup k souboru.
Ve výchozím nastavení se serverless SQL pool pokusí získat přístup k souboru pomocí vaší identity Microsoft Entra. Pokud chcete tento problém vyřešit, musíte mít správná práva pro přístup k souboru. Nejjednodušším způsobem je přiřadit si roli Přispěvatel dat objektů Blob v rámci účtu úložiště, který se pokoušíte dotazovat.
Další informace naleznete v tématu:
- Řízení přístupu k Microsoft Entra ID pro úložiště
- Řízení přístupu k úložišti účtu pro serverless SQL pool ve službě Synapse Analytics
Alternativa k roli Přispěvatel dat v objektech blob služby Storage
Místo udělení role Přispěvatel dat objektů blob služby Storage můžete také udělit granulejší oprávnění k podmnožině souborů.
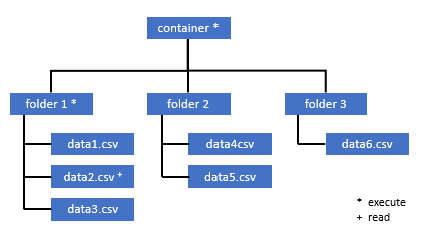
Všichni uživatelé, kteří potřebují přístup k některým datům v tomto kontejneru, musí mít také oprávnění EXECUTE pro všechny nadřazené složky až do kořenového adresáře (kontejneru).
Zjistěte více o tom, jak nastavit ACL v Azure Data Lake Storage Gen2.
Poznámka:
Oprávnění ke spuštění na úrovni kontejneru musí být nastavené v rámci Azure Data Lake Storage Gen2. Oprávnění ke složce je možné nastavit v rámci Azure Synapse.
Pokud chcete dotazovat data2.csv v tomto příkladu, potřebujete následující oprávnění:
- Oprávnění k provedení v kontejneru
- Oprávnění ke spuštění složky 1
- Oprávnění ke čtení u data2.csv
Přihlaste se k Azure Synapse pomocí uživatele správce, který má úplná oprávnění k datům, ke kterým chcete získat přístup.
V podokně dat klikněte pravým tlačítkem myši na soubor a vyberte Spravovat přístup.
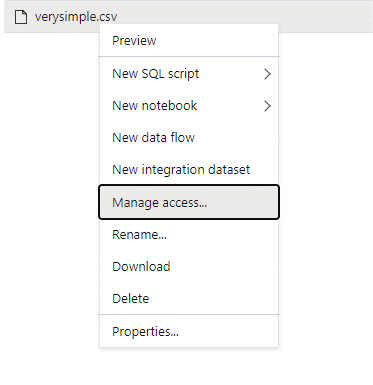
Vyberte alespoň oprávnění ke čtení . Zadejte hlavní název uživatele (UPN) nebo ID objektu, například
user@contoso.com. Vyberte Přidat.Udělte tomuto uživateli oprávnění ke čtení.

Poznámka:
Pro uživatele typu host je potřeba tento krok provést přímo se službou Azure Data Lake, protože ho nejde provést přímo přes Azure Synapse.
Obsah adresáře na dané cestě nelze zobrazit
Tato chyba značí, že uživatel, který dotazuje Azure Data Lake, nemůže vypsat soubory v úložišti. K této chybě může dojít v několika scénářích:
- Uživatel Microsoft Entra, který používá přímé ověřování Microsoft Entra, nemá oprávnění k výpisu souborů ve službě Data Lake Storage.
- Microsoft Entra ID nebo uživatel SQL, který čte data pomocí klíče sdíleného přístupového podpisu nebo spravované identity pracovního prostoru, a tento klíč nebo identita nemá oprávnění k výpisu souborů v úložišti.
- Uživatel, který přistupuje k datům Dataverse, který nemá oprávnění dotazovat se na data v Dataverse. K tomuto scénáři může dojít, pokud používáte uživatele SQL.
- Uživatel, který přistupuje k Delta Lake, nemusí mít oprávnění ke čtení transakčního protokolu Delta Lake.
Nejjednodušší způsob, jak tento problém vyřešit, je udělit si roli Storage Blob Data Contributor v účtu úložiště, na který se pokoušíte dotazovat.
Další informace naleznete v tématu:
- Řízení přístupu k Microsoft Entra ID pro úložiště
- Řízení přístupu k úložišti účtu pro serverless SQL pool ve službě Synapse Analytics
Obsah tabulky Dataverse nejde vypisovat
Pokud ke čtení propojených tabulek DataVerse používáte Azure Synapse Link pro Dataverse, musíte pro přístup k propojeným datům použít účet Microsoft Entra pro přístup k propojeným datům pomocí bezserverového fondu SQL. Další informace najdete v tématu Azure Synapse Link pro Dataverse s Azure Data Lake.
Pokud se pokusíte použít přihlášení SQL ke čtení externí tabulky odkazující na tabulku DataVerse, zobrazí se následující chyba: External table '???' is not accessible because content of directory cannot be listed.
Externí tabulky Dataverse vždy používají předávací ověřování Microsoft Entra. Nemůžete je nakonfigurovat tak, aby používaly klíč sdíleného přístupového podpisu nebo spravovanou identitu pracovního prostoru.
Obsah transakčního protokolu Delta Lake nejde vypisovat
Nastane následující chyba, když serverless SQL pool nemůže číst složku s transakčním protokolem Delta Lake:
Content of directory on path 'https://.....core.windows.net/.../_delta_log/*.json' cannot be listed.
Ujistěte se, že složka _delta_log existuje. Možná provádíte dotazy na obyčejné soubory Parquet, které nejsou převedeny do formátu Delta Lake. Pokud složka _delta_log existuje, ujistěte se, že máte oprávnění ke čtení i seznamu u podkladových složek Delta Lake. Zkuste číst soubory JSON přímo pomocí FORMAT='csv'. Vložte identifikátor URI do parametru BULK:
select top 10 *
from openrowset(BULK 'https://.....core.windows.net/.../_delta_log/*.json',FORMAT='csv', FIELDQUOTE = '0x0b', FIELDTERMINATOR ='0x0b',ROWTERMINATOR = '0x0b')
with (line varchar(max)) as logs
Pokud tento dotaz selže, volající nemá oprávnění ke čtení podkladových souborů úložiště.
Provedení dotazu
Během provádění dotazu se můžou zobrazit chyby v následujících případech:
- Volající nemá přístup k některým objektům.
- Dotaz nemá přístup k externím datům.
- Dotaz obsahuje některé funkce, které nejsou podporované v bezserverových fondech SQL.
Dotaz selže, protože se nedá spustit kvůli aktuálním omezením prostředků
Dotaz může selhat s chybovou zprávou This query cannot be executed due to current resource constraints. Tato zpráva znamená, že v tuto chvíli nejde spustit bezserverový fond SQL. Tady jsou některé možnosti řešení potíží:
- Ujistěte se, že používáte datové typy přiměřených velikostí.
- Pokud váš dotaz cílí na soubory Parquet, zvažte definování explicitních typů pro sloupce řetězců, protože jejich výchozí typ je VARCHAR(8000). Zkontrolujte odvozené datové typy.
- Pokud váš dotaz cílí na soubory CSV, zvažte vytvoření statistiky.
- Pokud chcete dotaz optimalizovat, projděte si osvědčené postupy z hlediska výkonu pro bezserverový fond SQL.
Vypršel časový limit dotazu
Tato chyba Query timeout expired se vrátí, pokud byl dotaz prováděn déle než 30 minut v bezserverovém fondu SQL. Tento limit pro serverless SQL pool nelze změnit.
- Pokuste se dotaz optimalizovat použitím osvědčených postupů.
- Zkuste materializovat části dotazů pomocí create external table as select (CETAS).
- Zkontrolujte, jestli v bezserverovém fondu SQL probíhá souběžná úloha, protože ostatní dotazy mohou spotřebovat dané prostředky. V takovém případě můžete úlohy rozdělit do několika pracovních prostorů.
Neplatný název objektu
Tato chyba Invalid object name 'table name' značí, že používáte objekt, například tabulku nebo zobrazení, která v databázi bezserverového fondu SQL neexistuje. Vyzkoušejte tyto možnosti:
Vypište tabulky nebo zobrazení a zkontrolujte, jestli objekt existuje. Použijte SQL Server Management Studio nebo Azure Data Studio, protože Synapse Studio může zobrazit některé tabulky, které nejsou dostupné v bezserverovém fondu SQL.
Pokud se objekt zobrazí, zkontrolujte, že používáte kolaci databáze s rozlišováním velkých a malých písmen nebo binární kolaci. Název objektu se možná neshoduje s názvem, který jste použili v dotazu. S binární kolací databáze jsou
Employeeaemployeedvě různé objekty.Pokud objekt nevidíte, možná se pokoušíte dotazovat tabulku z databáze Lake nebo Spark. Tabulka nemusí být dostupná v bezserverovém fondu SQL, protože:
- Tabulka obsahuje některé typy sloupců, které nelze reprezentovat v bezserverovém fondu SQL.
- Tabulka má formát, který není podporován v bezserverovém fondu SQL. Příklady jsou Avro nebo ORC.
Řetězcová nebo binární data by byla zkrácena.
K této chybě dochází v případě, že délka řetězce nebo binárního typu sloupce (například VARCHARVARBINARY, neboNVARCHAR) je kratší než skutečná velikost dat, která čtete. Tuto chybu můžete opravit zvýšením délky typu sloupce:
- Pokud je sloupec řetězce definovaný jako typ
VARCHAR(32)a text má 60 znaků, použijte typVARCHAR(60)(nebo delší) ve schématu sloupce. - Pokud používáte odvození schématu (bez schématu
WITH), všechny řetězcové sloupce se automaticky definují jakoVARCHAR(8000)typ. Pokud se vám tato chyba zobrazuje, explicitně definujte schéma vWITHklauzuli s většímVARCHAR(MAX)typem sloupce, abyste tuto chybu vyřešili. - Pokud je vaše tabulka v databázi Lake, zkuste zvětšit velikost řetězcového sloupce ve fondu Spark.
- Zkuste
SET ANSI_WARNINGS OFFpovolit, aby bezserverový fond SQL automaticky zkracoval hodnoty VARCHAR, pokud to neovlivní vaše funkce.
Neuzavřené uvozovky za řetězcem znaků
Ve výjimečných případech, kdy použijete operátor LIKE na řetězcovém sloupci nebo při porovnání s řetězcovými literály, může se zobrazit následující chyba:
Unclosed quotation mark after the character string
K této chybě může dojít v případě, že ve sloupci použijete Latin1_General_100_BIN2_UTF8 kolaci. Zkuste nastavit kolaci Latin1_General_100_CI_AS_SC_UTF8 ve sloupci místo kolace Latin1_General_100_BIN2_UTF8 a problém vyřešit. Pokud se chyba stále vrací, vytvořte žádost o podporu prostřednictvím webu Azure Portal.
Při přenosu dat z jedné distribuce do druhé se nepodařilo přidělit prostor databáze tempdb.
Tato chyba Could not allocate tempdb space while transferring data from one distribution to another se vrátí, když prováděcí modul dotazů nemůže zpracovat data a přenést je mezi uzly, které spouští dotaz. Jedná se o zvláštní případ obecné chyby tempdb nejsou dostatečné ke spuštění dotazu.
Před podáním tiket podpory použijte osvědčené postupy.
Dotaz selže s chybou při zpracování externího souboru (došlo k dosažení maximálního počtu chyb)
Pokud dotaz selže s chybovou zprávou error handling external file: Max errors count reached, znamená to, že existuje neshoda zadaného typu sloupce a data, která je potřeba načíst.
Pokud chcete získat další informace o chybě a o řádcích a sloupcích, na které se chcete podívat, změňte verzi analyzátoru na 2.01.0.
Příklad
Pokud chcete dotazovat soubor names.csv s tímto dotazem Query 1, bezserverový SQL pool Azure Synapse se vrátí s následující chybou: Error handling external file: 'Max error count reached'. File/External table name: [filepath]. Například:
Soubor names.csv obsahuje:
Id,first name,
1, Adam
2,Bob
3,Charles
4,David
5,Eva
Dotaz 1:
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='2.0',
FIELDTERMINATOR =';',
FIRSTROW = 2
)
WITH (
[ID] SMALLINT,
[Text] VARCHAR (1) COLLATE Latin1_General_BIN2
)
AS [result]
Příčina
Jakmile se verze analyzátoru změní z verze 2.0 na 1.0, chybové zprávy vám pomůžou problém identifikovat. Nová chybová zpráva je teď Bulk load data conversion error (truncation) for row 1, column 2 (Text) in data file [filepath].
Zkrácení vám řekne, že typ sloupce je příliš malý, aby odpovídal vašim datům. Nejdelší jméno v tomto names.csv souboru má sedm znaků. Použitý datový typ by měl být alespoň VARCHAR(7). Příčinou chyby je tento řádek kódu:
[Text] VARCHAR (1) COLLATE Latin1_General_BIN2
Změna dotazu odpovídajícím způsobem vyřeší chybu. Po ladění změňte znovu verzi analyzátoru na 2.0, abyste dosáhli maximálního výkonu.
Další informace o tom, kdy použít verzi analyzátoru, naleznete v tématu Použití OPENROWSET pomocí bezserverového fondu SQL ve službě Synapse Analytics.
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='2.0',
FIELDTERMINATOR =';',
FIRSTROW = 2
)
WITH (
[ID] SMALLINT,
[Text] VARCHAR (7) COLLATE Latin1_General_BIN2
)
AS [result]
Nelze hromadně načíst, protože soubor se nepodařilo otevřít.
Chyba Cannot bulk load because the file could not be opened se vrátí, pokud se během provádění dotazu upraví soubor. Obvykle se může zobrazit chyba typu Cannot bulk load because the file {file path} could not be opened. Operating system error code 12. (The access code is invalid.)
Bezserverové fondy SQL nemůžou číst soubory, které se upravují, když je dotaz spuštěný. Dotaz nemůže zamknout soubory. Pokud víte, že operace úpravy je připojena, můžete zkusit nastavit následující možnost: {"READ_OPTIONS":["ALLOW_INCONSISTENT_READS"]}.
Další informace najdete, jak dotazovat přírůstkové soubory nebo vytvářet tabulky na přírůstkových souborech.
Dotaz selže s chybou převodu dat
Dotaz může selhat s chybovou zprávou Bulk load data conversion error (type mismatches or invalid character for the specified code page) for row n, column m [columnname] in the data file [filepath]. Tato zpráva znamená, že datové typy neodpovídají skutečným datům pro číslo řádku n a sloupec m.
Pokud například očekáváte pouze celá čísla v datech, ale v řádku n je řetězec, tato chybová zpráva je ta, kterou získáte.
Chcete-li tento problém vyřešit, zkontrolujte soubor a datové typy, které jste zvolili. Zkontrolujte také správnost nastavení oddělovače řádků a ukončovacího prvku pole. Následující příklad ukazuje, jak lze prohlížení provést použitím typu sloupce VARCHAR.
Další informace o ukončovacích znacích polí, oddělovačích řádků a únikových uvozovacích znacích naleznete v části Dotazování souborů CSV.
Příklad
Pokud chcete zadat dotaz na soubor names.csv:
Id, first name,
1,Adam
2,Bob
3,Charles
4,David
five,Eva
S následujícím dotazem:
Dotaz 1:
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='1.0',
FIELDTERMINATOR =',',
FIRSTROW = 2
)
WITH (
[ID] SMALLINT,
[Firstname] VARCHAR (25) COLLATE Latin1_General_BIN2
)
AS [result]
Bezserverový SQL pool ve službě Azure Synapse vrátí chybu Bulk load data conversion error (type mismatch or invalid character for the specified code page) for row 6, column 1 (ID) in data file [filepath].
Je nutné procházet data a informovaně rozhodnout, jak tento problém vyřešit. Pokud se chcete podívat na data, která způsobují tento problém, je potřeba nejprve změnit datový typ. Místo dotazování sloupce ID s datovým typem SMALLINT se teď k analýze tohoto problému používá VARCHAR(100).
S tímto mírně změněným dotazem 2 je teď možné data zpracovat a vrátit seznam názvů.
Dotaz 2:
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='1.0',
FIELDTERMINATOR =',',
FIRSTROW = 2
)
WITH (
[ID] VARCHAR(100),
[Firstname] VARCHAR (25) COLLATE Latin1_General_BIN2
)
AS [result]
Můžete si všimnout, že data mají neočekávané hodnoty ID v pátém řádku. Za takových okolností je důležité shodnout se s vlastníkem údajů a dohodnout na tom, jak by bylo možné předejít poškozeným datům, jako je tento příklad. Pokud prevence není na úrovni aplikace možná, může být zde jedinou možností rozumná velikost VARCHAR.
Doporučení
Snažte se, aby funkce VARCHAR() byla co nejkratší. Pokud je to možné, vyhněte se funkci VARCHAR(MAX), protože může narušit výkon.
Výsledek dotazu nevypadá podle očekávání.
Dotaz nemusí selhat, ale může se zobrazit, že sada výsledků není podle očekávání. Výsledné sloupce můžou být prázdné nebo můžou být vrácena neočekávaná data. V tomto scénáři je pravděpodobné, že byl nesprávně zvolen oddělovač řádků nebo ukončovací znak pole.
Pokud chcete tento problém vyřešit, podívejte se na data a změňte tato nastavení. Ladění tohoto dotazu je snadné, jak je znázorněno v následujícím příkladu.
Příklad
Pokud chcete provést dotaz na soubor names.csv pomocí dotazu 1, vrátí se bezserverový SQL pool Azure Synapse s výsledkem, který vypadá zvláštně.
V names.csv:
Id,first name,
1, Adam
2, Bob
3, Charles
4, David
5, Eva
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='1.0',
FIELDTERMINATOR =';',
FIRSTROW = 2
)
WITH (
[ID] VARCHAR(100),
[Firstname] VARCHAR (25) COLLATE Latin1_General_BIN2
)
AS [result]
| ID | Firstname |
| ------------- |------------- |
| 1,Adam | NULL |
| 2,Bob | NULL |
| 3,Charles | NULL |
| 4,David | NULL |
| 5,Eva | NULL |
Zdá se, že ve sloupci Firstnamenení žádná hodnota . Místo toho všechny hodnoty skončily ve sloupci ID . Tyto hodnoty jsou oddělené čárkou. Problém byl způsoben tímto řádkem kódu, protože je nutné zvolit čárku místo symbolu středníku jako ukončovací znak pole:
FIELDTERMINATOR =';',
Změna tohoto jediného znaku vyřeší problém:
FIELDTERMINATOR =',',
Sada výsledků vytvořená dotazem 2 teď vypadá podle očekávání:
Dotaz 2:
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='1.0',
FIELDTERMINATOR =',',
FIRSTROW = 2
)
WITH (
[ID] VARCHAR(100),
[Firstname] VARCHAR (25) COLLATE Latin1_General_BIN2
)
AS [result]
Návraty:
| ID | Firstname |
| ------------- |------------- |
| 1 | Adam |
| 2 | Bob |
| 3 | Charles |
| 4 | David |
| 5 | Eva |
Sloupec typu není kompatibilní s externím datovým typem
Pokud dotaz selže s chybovou zprávou Column [column-name] of type [type-name] is not compatible with external data type […], , je pravděpodobné, že byl datový typ PARQUET namapován na nesprávný datový typ SQL.
Pokud má například soubor Parquet cenu sloupce s čísly float (například 12,89) a pokusili jste se ho namapovat na INT, zobrazí se tato chybová zpráva.
Pokud chcete tento problém vyřešit, zkontrolujte soubor a datové typy, které jste zvolili. Tato tabulka mapování pomáhá zvolit správný datový typ SQL. Osvědčeným postupem je určit mapování pouze pro sloupce, které by se jinak převedly na datový typ VARCHAR. Vyhýbání se VARCHAR, pokud je to možné, vede k lepšímu výkonu dotazů.
Příklad
Pokud chcete dotazovat soubor taxi-data.parquet s tímto dotazem 1, vrátí bezserverový fond SQL Azure Synapse následující chybu:
Soubor taxi-data.parquet obsahuje:
|PassengerCount |SumTripDistance|AvgTripDistance |
|---------------|---------------|----------------|
| 1 | 2635668.66000064 | 6.72731710678951 |
| 2 | 172174.330000005 | 2.97915543404919 |
| 3 | 296384.390000011 | 2.8991352022851 |
| 4 | 12544348.58999806| 6.30581582240281 |
| 5 | 13091570.2799993 | 111.065989028627 |
Dotaz 1:
SELECT
*
FROM
OPENROWSET(
BULK '<filepath>taxi-data.parquet',
FORMAT='PARQUET'
) WITh
(
PassengerCount INT,
SumTripDistance INT,
AVGTripDistance FLOAT
)
AS [result]
Column 'SumTripDistance' of type 'INT' is not compatible with external data type 'Parquet physical type: DOUBLE', please try with 'FLOAT'. File/External table name: '<filepath>taxi-data.parquet'.
Tato chybová zpráva vám řekne, že datové typy nejsou kompatibilní a jsou součástí návrhu použít funkci FLOAT místo INT. Příčinou chyby je tento řádek kódu:
SumTripDistance INT,
S tímto mírně změněným dotazem 2 je teď možné data zpracovat a zobrazit všechny tři sloupce:
Dotaz 2:
SELECT
*
FROM
OPENROWSET(
BULK '<filepath>taxi-data.parquet',
FORMAT='PARQUET'
) WITh
(
PassengerCount INT,
SumTripDistance FLOAT,
AVGTripDistance FLOAT
)
AS [result]
Dotaz odkazuje na objekt, který není podporovaný v režimu distribuovaného zpracování.
Tato chyba The query references an object that is not supported in distributed processing mode značí, že jste použili objekt nebo funkci, která se nedá použít při dotazování na data ve službě Azure Storage nebo analytickém úložišti Azure Cosmos DB.
Některé objekty, jako jsou systémová zobrazení a funkce, se nedají použít při dotazování na data uložená v Azure Data Lake nebo analytickém úložišti Azure Cosmos DB. Nepoužívejte dotazy, které spojují externí data se systémovými zobrazeními, načítají externí data do dočasné tabulky nebo používají některé funkce zabezpečení nebo metadat k filtrování externích dat.
Volání WaitIOCompletion se nezdařilo
Chybová zpráva WaitIOCompletion call failed značí, že dotaz selhal při čekání na dokončení vstupně-výstupní operace, která čte data ze vzdáleného úložiště Azure Data Lake.
Chybová zpráva má následující vzor: Error handling external file: 'WaitIOCompletion call failed. HRESULT = ???'. File/External table name...
Ujistěte se, že je vaše úložiště umístěné ve stejném regionu jako serverless SQL pool. Zkontrolujte metriky úložiště a ověřte, že na vrstvě úložiště nejsou žádné jiné úlohy, například nahrání nových souborů, které by mohly zahltit vstupně-výstupní požadavky.
Pole HRESULT obsahuje kód výsledku. Následující kódy chyb jsou nejběžnější spolu s jejich potenciálními řešeními.
Tento kód chyby znamená, že zdrojový soubor není v úložišti.
K tomuto kódu chyby může dojít z těchto důvodů:
- Soubor odstranila jiná aplikace.
- V tomto obvyklém scénáři se dotaz spustí, provádí se enumerace souborů a soubory se najdou. Později se během provádění dotazu odstraní soubor. Může ho například odstranit Databricks, Spark nebo Azure Data Factory. Dotaz selže, protože soubor nebyl nalezen.
- K tomuto problému může také dojít ve formátu Delta. Dotaz může být úspěšný při opakování, protože existuje nová verze tabulky a odstraněný soubor se již více nevyhledává.
- Neplatný plán spuštění je uložen v mezipaměti.
- Jako dočasné řešení situace spusťte příkaz
DBCC FREEPROCCACHE. Pokud problém přetrvává, vytvořte lístek podpory.
- Jako dočasné řešení situace spusťte příkaz
Nesprávná syntaxe poblíž NOT
Tato chyba Incorrect syntax near 'NOT' značí, že existují některé externí tabulky se sloupci, které obsahují omezení NOT NULL v definici sloupce.
- Aktualizujte tabulku tak, aby z definice sloupce odebrala HODNOTU NOT NULL.
- K této chybě může někdy dojít také přechodně s tabulkami vytvořenými z příkazu CETAS. Pokud se problém nevyřeší, můžete zkusit externí tabulku odstranit a znovu vytvořit.
Sloupec oddílu vrací hodnoty NULL.
Pokud váš dotaz vrátí hodnoty NULL místo sloupců pro dělení nebo nemůže najít sloupce pro dělení, existuje několik možných kroků pro řešení problémů:
- Pokud k dotazování na dělenou datovou sadu používáte tabulky, tabulky nepodporují dělení. Nahraďte tabulku rozdělenými zobrazeními.
- Pokud použijete dělené zobrazení s OPENROWSET, která dotazuje dělené soubory pomocí funkce FILEPATH(), ujistěte se, že jste správně zadali vzor zástupných znaků v umístění a použili správný index pro odkazování na zástupný znak.
- Pokud se dotazujete na soubory přímo v dělené složce, sloupce dělení nejsou části sloupců souborů. Hodnoty dělení se umístí do cest ke složce, nikoli do souborů. Z tohoto důvodu soubory neobsahují hodnoty dělení.
Vložení hodnoty do zpracování pro datový typ sloupce DATETIME2 selhalo
Tato chyba Inserting value to batch for column type DATETIME2 failed značí, že bezserverový fond nemůže číst hodnoty dat z zdrojových souborů. Hodnota datetime uložená v souboru Parquet nebo Delta Lake nemůže být reprezentována jako sloupec DATETIME2.
Zkontrolujte minimální hodnotu v souboru pomocí Sparku a zkontrolujte, jestli jsou některá data menší než 0001-01-03. Pokud jste soubory uložili pomocí vyšší verze Sparku, která stále používá starší formát úložiště datetime, dřívější hodnoty data a času byly zapsány pomocí juliánského kalendáře, který není v souladu s proleptickým gregoriánským kalendářem používaným v bezserverových fondech SQL.
Mezi julianovým kalendářem, který se používá k zápisu hodnot v Parquetu (v některých verzích Sparku), a proleptického gregoriánského kalendáře používaného v bezserverovém fondu SQL, může existovat dvoudenní rozdíl. Tento rozdíl může způsobit převod na zápornou hodnotu data, která je neplatná.
Pokuste se použít Spark k aktualizaci těchto hodnot, protože se považují za neplatné hodnoty kalendářních dat v SQL. Následující ukázka ukazuje, jak aktualizovat hodnoty, které jsou mimo rozsahy dat SQL, na hodnotu NULL v Delta Lake:
from delta.tables import *
from pyspark.sql.functions import *
deltaTable = DeltaTable.forPath(spark,
"abfss://my-container@myaccount.dfs.core.windows.net/delta-lake-data-set")
deltaTable.update(col("MyDateTimeColumn") < '0001-02-02', { "MyDateTimeColumn": null } )
Tato změna odebere hodnoty, které nelze reprezentovat. Ostatní hodnoty kalendářních dat mohou být správně načteny, ale nesprávně reprezentovány, protože stále existuje rozdíl mezi Julianem a proleptickými gregoriánskými kalendáři. Pokud používáte Spark 3.0 nebo starší verze, mohou se posuny dat vyskytnout neočekávaně, dokonce i pro data před 1900-01-01.
Zvažte migraci na Spark 3.1 nebo novější a přechod na proleptický gregoriánský kalendář. Nejnovější verze Sparku používají ve výchozím nastavení proleptický gregoriánský kalendář, který je v souladu s kalendářem v bezserverovém fondu SQL. Znovu načtěte starší data s vyšší verzí Sparku a pomocí následujícího nastavení opravte data:
spark.conf.set("spark.sql.legacy.parquet.int96RebaseModeInWrite", "CORRECTED")
Dotaz selhal kvůli změně topologie nebo selhání výpočetního kontejneru
Tato chyba může znamenat, že v bezserverovém fondu SQL došlo k nějakému problému s interním procesem. Vytvořte lístek podpory se všemi potřebnými podrobnostmi, které by mohly týmu podpora Azure pomoct problém prošetřit.
Popište vše, co může být neobvyklé v porovnání s běžnou úlohou. Například možná došlo k velkému počtu souběžných požadavků nebo ke spuštění speciální úlohy nebo dotazu dříve, než k této chybě došlo.
Časový limit pro rozšíření zástupných znaků byl překročen
Jak je popsáno v části Dotazovací složky a více souborů, serverless SQL pool podporuje čtení více souborů a složek pomocí zástupných znaků. Pro každý dotaz platí maximální limit 10 zástupných znaků. Musíte mít na paměti, že tato funkce je nákladná. Trvá nějakou dobu, než fond bezserverového výpočetního prostředí vypíše všechny soubory, které odpovídají zástupnému znaku. To představuje latenci a tato latence se může zvýšit, pokud je počet souborů, které se pokoušíte dotazovat, vysoké. V takovém případě můžete narazit na následující chybu:
"Wildcard expansion timed out after X seconds."
Existuje několik kroků pro zmírnění rizik, které můžete udělat, abyste se tomu vyhnuli:
- Použijte osvědčené postupy popsané v Best Practices Serverless SQL Pool.
- Zkuste snížit počet souborů, které se pokoušíte dotazovat, tím, že zkomprimujete soubory do větších souborů. Zkuste zachovat velikosti souborů nad 100 MB.
- Ujistěte se, že se filtry používají při dělení sloupců všude, kde je to možné.
- Pokud používáte delta formát souboru, využijte funkci optimalizace zápisu ve Sparku. To může zlepšit výkon dotazů snížením množství dat, která je potřeba číst a zpracovávat. Použití optimalizace zápisu je popsáno v tématu Použití optimalizace zápisu v Apache Sparku.
- Pokud se chcete vyhnout některým zástupným znakům nejvyšší úrovně, efektivně pevně zakódujte implicitní filtry nad dělením sloupců pomocí dynamického SQL.
Chybějící sloupec při použití automatického odvození schématu
Soubory můžete snadno dotazovat bez znalosti nebo zadání schématu tak, že vynecháte klauzuli WITH. V takovém případě se názvy sloupců a datové typy odvozí ze souborů. Mějte na paměti, že pokud čtete více souborů najednou, schéma se odvodí z prvního souboru, který služba získá z úložiště. To může znamenat, že některé z očekávaných sloupců jsou vynechány, protože soubor používaný službou k definování schématu tyto sloupce neobsahoval. Pokud chcete explicitně zadat schéma, použijte klauzuli OPENROWSET WITH. Pokud zadáte schéma (pomocí externí tabulky nebo klauzule OPENROWSET WITH), použije se výchozí laxní režim cesty. To znamená, že sloupce, které v některých souborech neexistují, se vrátí jako hodnoty NUL (pro řádky z těchto souborů). Pokud chcete zjistit, jak se používá režim cesty, projděte si následující dokumentaci a ukázku.
Konfigurace
Bezserverové fondy SQL umožňují konfigurovat databázové objekty pomocí jazyka T-SQL. Existují určitá omezení:
- V databázích
mastera databázích Sparklakehousenemůžete vytvářet objekty. - Abyste mohli vytvořit přihlašovací údaje, musíte mít hlavní klíč.
- Musíte mít oprávnění k odkazování na data, která se používají v objektech.
Nejde vytvořit databázi
Pokud se zobrazí chyba CREATE DATABASE failed. User database limit has been already reached., vytvořili jste maximální počet databází podporovaných v jednom pracovním prostoru. Další informace najdete v tématu Omezení.
- Pokud potřebujete oddělit objekty, použijte schémata v databázích.
- Pokud potřebujete odkazovat na Azure Data Lake Storage, vytvořte databáze Lakehouse nebo databáze Sparku, které se budou synchronizovat v bezserverovém fondu SQL.
Vytvoření nebo změna tabulky se nezdařilo, protože minimální velikost řádku překračuje maximální povolenou velikost řádku tabulky 8060 bajtů.
Každá tabulka může mít velikost až 8 kB na řádek (nezahrnuje data VARCHAR(MAX)/VARBINARY(MAX). Pokud vytvoříte tabulku, ve které celková velikost buněk v řádku překročí 8060 bajtů, zobrazí se následující chyba:
Msg 1701, Level 16, State 1, Line 3
Creating or altering table '<table name>' failed because the minimum row size would be <???>,
including <???> bytes of internal overhead.
This exceeds the maximum allowable table row size of 8060 bytes.
K této chybě může také dojít v databázi Lake, pokud vytvoříte tabulku Sparku s velikostmi sloupců, které překračují 8060 bajtů, a bezserverový fond SQL nemůže vytvořit tabulku, která odkazuje na data tabulky Sparku.
Jako zmírnění rizik nepoužívejte typy pevných velikostí jako CHAR(N) a nahraďte je typy proměnných velikostí VARCHAR(N) nebo zmenšujte velikost .CHAR(N) Viz omezení skupiny řádků 8 kB na SQL Serveru.
Vytvoření hlavního klíče v databázi nebo otevření hlavního klíče v relaci před provedením této operace
Pokud dotaz selže s chybovou zprávou Please create a master key in the database or open the master key in the session before performing this operation., znamená to, že vaše uživatelská databáze nemá v tuto chvíli přístup k hlavnímu klíči.
S největší pravděpodobností jste vytvořili novou uživatelskou databázi a ještě jste nevytvořili hlavní klíč.
Pokud chcete tento problém vyřešit, vytvořte hlavní klíč s následujícím dotazem:
CREATE MASTER KEY [ ENCRYPTION BY PASSWORD ='strongpasswordhere' ];
Poznámka:
Nahraďte 'strongpasswordhere' zde jiným tajným kódem.
Příkaz CREATE není v hlavní databázi podporován.
Pokud váš dotaz selže s chybovou zprávou Failed to execute query. Error: CREATE EXTERNAL TABLE/DATA SOURCE/DATABASE SCOPED CREDENTIAL/FILE FORMAT is not supported in master database., znamená to, že master databáze v bezserverovém fondu SQL nepodporuje vytváření:
- Externí tabulky.
- Externí zdroje dat
- Přihlašovací údaje s vymezeným oborem databáze
- Formáty externích souborů
Tady je řešení:
Vytvoření uživatelské databáze:
CREATE DATABASE <DATABASE_NAME>Vykonejte příkaz CREATE v kontextu databáze <DATABASE_NAME>, která dříve selhala pro databázi
master.Tady je příklad vytvoření externího formátu souboru:
USE <DATABASE_NAME> CREATE EXTERNAL FILE FORMAT [SynapseParquetFormat] WITH ( FORMAT_TYPE = PARQUET)
Nejde vytvořit přihlášení nebo uživatele Microsoft Entra
Pokud při pokusu o vytvoření nového přihlášení nebo uživatele Microsoft Entra v databázi dojde k chybě, zkontrolujte přihlašovací jméno, které jste použili pro připojení k databázi. Přihlašovací jméno, které se pokouší vytvořit nového uživatele Microsoft Entra, musí mít oprávnění pro přístup k doméně Microsoft Entra a zkontrolovat, jestli uživatel existuje. Mějte na paměti, že:
- Přihlášení SQL toto oprávnění nemají, takže pokud používáte ověřování SQL, zobrazí se tato chyba vždy.
- Pokud k vytvoření nových přihlášení používáte Microsoft Entra, zkontrolujte, jestli máte oprávnění pro přístup k doméně Microsoft Entra.
Azure Cosmos DB
Bezserverové fondy SQL umožňují dotazovat analytické úložiště Azure Cosmos DB pomocí OPENROWSET funkce. Ujistěte se, že váš kontejner Azure Cosmos DB má analytické úložiště. Ujistěte se, že jste správně zadali název účtu, databáze a kontejneru. Ujistěte se také, že je klíč účtu služby Azure Cosmos DB platný. Další informace najdete v části Předpoklady.
Nejde dotazovat službu Azure Cosmos DB pomocí funkce OPENROWSET
Pokud se nemůžete připojit ke svému účtu služby Azure Cosmos DB, projděte si požadavky. Možné chyby a akce řešení potíží jsou uvedeny v následující tabulce.
| Chyba | Původní příčina |
|---|---|
| Chyby syntaxe: - Nesprávná syntaxe v blízkosti OPENROWSET.- ... není uznávanou BULK OPENROWSET variantou poskytovatele.- Nesprávná syntaxe v blízkosti .... |
Možné původní příčiny: – Nepoužíváte službu Azure Cosmos DB jako první parametr. – Použití řetězcového literálu místo identifikátoru ve třetím parametru. – Nezadávejte třetí parametr (název kontejneru). |
| Došlo k chybě v připojovacím řetězci Azure Cosmos DB. | – Účet, databáze nebo klíč není zadaný. – Možnost v připojovacím řetězci není rozpoznána. - Středník ( ;) je na konci připojovacího řetězce. |
| Řešení cesty ke službě Azure Cosmos DB selhalo s chybou Nesprávný název účtu nebo Nesprávný název databáze. | Zadaný název účtu, název databáze nebo kontejner nelze najít nebo pro zadanou kolekci není povolené analytické úložiště. |
| Řešení cesty ke službě Azure Cosmos DB selhalo s chybou: "Nesprávná hodnota tajného klíče" nebo "Tajný klíč je null nebo prázdný." | Klíč účtu není platný nebo chybí. |
Při čtení typů řetězců služby Azure Cosmos DB se vrací upozornění kolace UTF-8
Bezserverový SQL fond vrátí upozornění na kompilaci, pokud OPENROWSET kolace sloupce nemá kódování UTF-8. Výchozí kolaci všech OPENROWSET funkcí spuštěných v aktuální databázi můžete snadno změnit pomocí příkazu T-SQL:
ALTER DATABASE CURRENT COLLATE Latin1_General_100_CI_AS_SC_UTF8;
Porovnávání znaků Latin1_General_100_BIN2_UTF8 poskytuje nejlepší výkon při filtrování dat pomocí řetězcových predikátů.
Chybějící řádky v analytickém úložišti Azure Cosmos DB
Některé položky ze služby Azure Cosmos DB nemusí být vráceny funkcí OPENROWSET. Mějte na paměti, že:
- Mezi transakčním a analytickým úložištěm dochází ke zpoždění synchronizace. Dokument, který jste zadali v transakčním úložišti Azure Cosmos DB, se může objevit v analytickém úložišti po dvou až třech minutách.
- Dokument může porušit některá omezení schématu.
Dotaz vrátí hodnoty NULL v některých položkách služby Azure Cosmos DB.
Azure Synapse SQL vrátí hodnotu NULL místo hodnot, které vidíte v úložišti transakcí v následujících případech:
- Mezi transakčním a analytickým úložištěm dochází ke zpoždění synchronizace. Hodnota, kterou jste zadali v transakčním úložišti Azure Cosmos DB, se může v analytickém úložišti objevit po dvou až třech minutách.
- V klauzuli WITH může být chybný název sloupce nebo výraz cesty. Název sloupce (nebo výraz cesty za typem sloupce) v klauzuli WITH musí odpovídat názvům vlastností v kolekci Azure Cosmos DB. Porovnání je citlivé na velikost písmen. Například
productCodeaProductCodejsou různé vlastnosti. Ujistěte se, že názvy sloupců přesně odpovídají názvům vlastností služby Azure Cosmos DB. - Vlastnost nemusí být přesunuta do analytického úložiště, protože porušuje některá omezení schématu, například více než 1 000 vlastností nebo více než 127 úrovní vnoření.
- Pokud používáte dobře definovanou reprezentaci schématu, může mít hodnota v transakčním úložišti nesprávný typ. Dobře definované schéma uzamkne typy pro každou vlastnost vzorkováním dokumentů. Jakákoli přidaná hodnota v transakčním úložišti, která neodpovídá typu, se považuje za nesprávnou hodnotu a nemigruje se do analytického úložiště.
- Pokud používáte reprezentaci schématu s plnou věrností, ujistěte se, že přidáváte příponu typu za název vlastnosti, například
$.price.int64. Pokud nevidíte hodnotu pro odkazovanou cestu, možná je uložená pod jinou cestou typu,$.price.float64například . Další informace naleznete v tématu Dotazování kolekcí Azure Cosmos DB ve schématu s plnou věrností.
Sloupec není kompatibilní s externím datovým typem
Chyba Column 'column name' of the type 'type name' is not compatible with the external data type 'type name'. se vrátí, pokud zadaný typ sloupce v klauzuli WITH neodpovídá typu v kontejneru Azure Cosmos DB. Zkuste změnit typ sloupce podle popisu v části Azure Cosmos DB na mapování typů SQL nebo použijte typ VARCHAR.
Řešení: Cesta ke službě Azure Cosmos DB selhala s chybou
Pokud se zobrazí chyba Resolving Azure Cosmos DB path has failed with error 'This request is not authorized to perform this operation'., zkontrolujte, jestli jste ve službě Azure Cosmos DB použili privátní koncové body. Pokud chcete umožnit fondu serverless SQL přístup k analytickému úložišti přes privátní koncové body, musíte nakonfigurovat privátní koncové body pro analytické úložiště Azure Cosmos DB.
Problémy s výkonem služby Azure Cosmos DB
Pokud dojde k neočekávaným problémům s výkonem, ujistěte se, že jste použili osvědčené postupy, například:
- Ujistěte se, že jste umístili klientskou aplikaci, bezserverový fond a analytické úložiště Azure Cosmos DB do stejné oblasti.
- Ujistěte se, že používáte klauzuli WITH s optimálními datovými typy.
- Při filtrování dat pomocí predikátů řetězců se ujistěte, že používáte Latin1_General_100_BIN2_UTF8 kolaci .
- Pokud máte opakující se dotazy, které by mohly být uložené v mezipaměti, zkuste použít CETAS k ukládání výsledků dotazů ve službě Azure Data Lake Storage.
Delta Lake
Existují určitá omezení, která se můžou zobrazit v podpoře Delta Lake v bezserverových fondech SQL:
- Ujistěte se, že odkazujete na kořenovou složku Delta Lake ve funkci OPENROWSET nebo v umístění externí tabulky.
- Kořenová složka musí mít podsložku s názvem
_delta_log. Dotaz selže, pokud neexistuje žádná_delta_logsložka. Pokud tuto složku nevidíte, odkazujete na prosté soubory Parquet, které je potřeba převést na Delta Lake pomocí clusterů Apache Spark. - Nezadávejte zástupné cardy pro popis schématu oddílu. Dotaz Delta Lake automaticky identifikuje oddíly Delta Lake.
- Kořenová složka musí mít podsložku s názvem
- Tabulky Delta Lake vytvořené ve fondech Apache Spark jsou automaticky dostupné v bezserverovém fondu SQL, ale schéma se neaktualizuje (omezení verze Public Preview). Pokud do tabulky Delta přidáte sloupce pomocí fondu Sparku, změny se nezobrazí v bezserverové databázi fondu SQL.
- Externí tabulky nepodporují dělení. K odstranění oddílu použijte dělené zobrazení ve složce Delta Lake. Projděte si známé problémy a alternativní řešení dále v článku.
- Bezserverové fondy SQL nepodporují dotazy na časové cestování. Ke čtení historických dat použijte fondy Apache Sparku ve službě Synapse Analytics.
- Bezserverové fondy SQL nepodporují aktualizaci souborů Delta Lake. K dotazování nejnovější verze Delta Lake můžete použít bezserverový fond SQL. K aktualizaci Delta Lake použijte fondy Apache Sparku ve službě Synapse Analytics.
- Výsledky dotazu nemůžete uložit do úložiště ve formátu Delta Lake pomocí příkazu CETAS. Příkaz CETAS podporuje jako výstupní formáty pouze Parquet a CSV.
- Bezserverové fondy SQL ve službě Synapse Analytics jsou kompatibilní se čtečkou Delta verze 1.
- Bezserverové fondy SQL ve službě Synapse Analytics nepodporují datové sady s filtrem BLOOM. Bezserverový fond SQL ignoruje filtry BLOOM.
- Podpora Delta Lake není dostupná ve vyhrazených fondech SQL. Ujistěte se, že k dotazování souborů Delta Lake používáte bezserverové fondy SQL.
- Další informace o známých problémech s bezserverovými fondy SQL najdete v tématu Známé problémy se službou Azure Synapse Analytics.
Bezserverová podpora verze Delta 1.0
Bezserverové fondy SQL čtou jenom verzi Delta Lake 1.0. Bezserverové fondy SQL jsou čtečkou Delta s úrovní 1 a nepodporují následující funkce:
- Mapování sloupců se ignorují – bezserverové fondy SQL vrátí původní názvy sloupců.
- Vektory odstranění se ignorují a vrátí se stará verze odstraněných nebo aktualizovaných řádků (pravděpodobně nesprávné výsledky).
- Následující funkce Delta Lake nejsou podporovány: kontrolní body V2, časové razítko bez časového pásma, kontrola protokolu VAKUA
Odstraňovací vektory se ignorují.
Pokud je vaše tabulka Delta Lake nakonfigurovaná tak, aby používala Delta Writer verze 7, uloží odstraněné řádky a staré verze aktualizovaných řádků v delete vectors (DV). Vzhledem k tomu, že bezserverové fondy SQL mají úroveň Čtečka Delta 1, budou ignorovat vektory odstranění a při načítání nepodporované verze Delta Lake pravděpodobně mohou poskytovat nesprávné výsledky.
Přejmenování sloupce v tabulce Delta se nepodporuje.
Bezserverový SQL fond nepodporuje dotazování tabulek Delta Lake s přejmenovanými sloupci. Serverless SQL pool nemůže číst data z přejmenovaného sloupce.
Hodnota sloupce v tabulce Delta má hodnotu NULL.
Pokud používáte sadu dat Delta, která vyžaduje čtečku Delta verze 2 nebo vyšší, a používá funkce, které nejsou podporovány ve verzi 1 (například přejmenování sloupců, vyřazení sloupců nebo mapování sloupců), nemusí se zobrazit hodnoty v odkazovaných sloupcích.
Text JSON není správně naformátovaný
Tato chyba značí, že SQL fond bez serveru nemůže číst transakční protokol Delta Lake. Pravděpodobně se zobrazí následující chyba:
Msg 13609, Level 16, State 4, Line 1
JSON text is not properly formatted. Unexpected character '' is found at position 263934.
Msg 16513, Level 16, State 0, Line 1
Error reading external metadata.
Ujistěte se, že datová sada Delta Lake není poškozená. Ověřte, že obsah složky Delta Lake můžete číst pomocí fondu Apache Spark ve službě Azure Synapse. Tímto způsobem zajistíte, že _delta_log soubor není poškozený.
Alternativní řešení
Zkuste vytvořit kontrolní bod v datové sadě Delta Lake pomocí fondu Apache Spark a znovu spustit dotaz. Kontrolní bod agreguje transakční soubory protokolu JSON a může problém vyřešit.
Pokud je datová sada platná, vytvořte lístek podpory a zadejte další informace:
- Neprovázejte žádné změny, jako je přidání nebo odebrání sloupců nebo optimalizace tabulky, protože tato operace může změnit stav souborů transakčního protokolu Delta Lake.
- Zkopírujte obsah
_delta_logsložky do nové prázdné složky. Soubory nekopírujte.parquet data. - Zkuste přečíst obsah, který jste zkopírovali do nové složky, a ověřte, že se zobrazuje stejná chyba.
- Odešle obsah zkopírovaného
_delta_logsouboru do podpora Azure.
Nyní můžete dál používat složku Delta Lake s fondem Spark. Pokud máte povoleno sdílet tyto informace, poskytnete do podpory Microsoftu zkopírovaná data. Tým Azure prozkoumá obsah delta_log souboru a poskytne další informace o možných chybách a alternativních řešeních.
Vyřešení protokolů Delta se nezdařilo
Následující chyba značí, že bezserverový fond SQL nedokáže vyřešit protokoly Delta: Resolving Delta logs on path '%ls' failed with error: Cannot parse json object from log folder. Nejběžnější příčinou je, že last_checkpoint_file ve _delta_log složce je větší než 200 bajtů kvůli checkpointSchema poli přidanému do Sparku 3.3.
K dispozici jsou dvě možnosti, jak tuto chybu obejít:
- Upravte v poznámkovém bloku Sparku odpovídající konfiguraci a vygenerujte nový kontrolní bod, aby
last_checkpoint_filese znovu vytvořil. V případě, že používáte Azure Databricks, je změna konfigurace následující:spark.conf.set("spark.databricks.delta.checkpointSchema.writeThresholdLength", 0); - Přechod na starší verzi Spark 3.2.1.
Náš technický tým v současné době pracuje na úplné podpoře Sparku 3.3.
Tabulka Delta vytvořená ve Sparku se nezobrazuje v bezserverovém fondu
Poznámka:
Replikace tabulek Delta vytvořených ve Sparku je stále ve verzi Public Preview.
Pokud jste ve Sparku vytvořili tabulku Delta, která se nezobrazuje v bezserverovém fondu SQL, zkontrolujte následující:
- Chvíli počkejte (obvykle 30 sekund), protože tabulky Sparku se synchronizují se zpožděním.
- Pokud se tabulka po nějaké době nezobrazí v bezserverovém fondu SQL, zkontrolujte schéma tabulky Spark Delta. Tabulky Sparku se složitými typy nebo typy, které nejsou v bezserverové verzi podporované, nejsou dostupné. Zkuste vytvořit tabulku Spark Parquet se stejným schématem v databázi lake a zkontrolujte, jestli se tato tabulka zobrazí v bezserverovém fondu SQL.
- Zkontrolujte složku Spravované identity pracovního prostoru Delta Lake, na kterou odkazuje tabulka. Bezserverový fond SQL používá spravovanou identitu pracovního prostoru k získání informací o sloupcích tabulky z úložiště, aby mohl tabulku vytvořit.
Databáze Lake
Databázové tabulky Lake vytvořené pomocí Návrháře Sparku nebo Synapse jsou automaticky dostupné v bezserverovém fondu SQL pro dotazování. Bezserverový fond SQL můžete použít k provádění dotazů na tabulky Parquet, CSV a Delta Lake, které byly vytvořeny pomocí fondu Spark, a k přidání dalších schémat, zobrazení, procedur, funkcí tabulek a uživatelů Microsoft Entra v roli db_datareader do vaší databáze Lake. Možné problémy jsou uvedené v této části.
Tabulka vytvořená ve Sparku není dostupná v bezserverovém fondu.
Vytvořené tabulky nemusí být okamžitě dostupné v bezserverovém fondu SQL.
- Tabulky budou k dispozici v bezserverových fondech s mírným zpožděním. Možná budete muset počkat 5 až 10 minut po vytvoření tabulky ve Sparku, abyste ji viděli v bezserverovém fondu SQL.
- V bezserverovém fondu SQL jsou k dispozici pouze tabulky odkazované na formáty Parquet, CSV a Delta. Jiné typy tabulek nejsou k dispozici.
- Tabulka, která obsahuje některé nepodporované typy sloupců, nebudou dostupné v bezserverovém fondu SQL.
- Přístup k tabulkám Delta Lake v databázích Lake je ve verzi Public Preview. Zkontrolujte další problémy uvedené v této části nebo v části Delta Lake.
Externí tabulka vytvořená ve Sparku zobrazuje neočekávané výsledky v bezserverovém fondu.
Může se stát, že mezi zdrojovou externí tabulkou Sparku a replikovanou externí tabulkou v bezserverovém fondu došlo k neshodě. K tomu může dojít v případě, že soubory použité při vytváření externích tabulek Sparku nejsou bez přípon. Abyste získali správné výsledky, ujistěte se, že všechny soubory mají přípony, jako je .parquet.
Operace není povolená pro replikovanou databázi.
Tato chyba se vrátí, pokud se pokoušíte upravit databázi Lake, vytvořit externí tabulky, externí zdroje dat, přihlašovací údaje s oborem databáze nebo jiné objekty v databázi Lake. Tyto objekty lze vytvářet pouze v databázích SQL.
Databáze Lake se replikují z fondu Apache Spark a spravují je Apache Spark. Proto nemůžete vytvářet objekty jako v SQL Database pomocí jazyka T-SQL.
V databázích Lake jsou povoleny pouze následující operace:
- Vytváření, odstranění nebo změna zobrazení, procedur a inline funkcí vracejících hodnotu tabulky (iTVF) v jiných schématech než
dbo. - Vytvoření a vyřazení uživatelů databáze z Microsoft Entra ID.
- Přidání nebo odebrání uživatelů databáze ze
db_datareaderschématu
Jiné operace nejsou v databázích Lake povolené.
Poznámka:
Pokud vytváříte zobrazení, proceduru nebo funkci ve dbo schématu (nebo vynecháte schéma a použijete výchozí schéma, které je obvykle dbo), zobrazí se chybová zpráva.
Tabulky Delta v databázích Lake nejsou dostupné v bezserverovém fondu SQL
Ujistěte se, že spravovaná identita vašeho pracovního prostoru má přístup pro čtení do úložiště ADLS, které obsahuje složku Delta. Bezserverový fond SQL čte schéma tabulky Delta Lake z logů Delta, které jsou uložené v ADLS, a používá spravovanou identitu pracovního prostoru pro vstup k transakčním logům Delta.
Zkuste v některé službě SQL Database nastavit zdroj dat, který odkazuje na úložiště Azure Data Lake pomocí přihlašovacích údajů spravované identity, a zkuste vytvořit externí tabulku nad zdrojem dat se spravovanou identitou , abyste potvrdili, že tabulka s spravovanou identitou má přístup k vašemu úložišti.
Tabulky Delta v databázích Lake nemají stejné schéma ve fondech Spark a bezserverových poolech.
Bezserverové fondy SQL umožňují přístup k tabulkám Parquet, CSV a Delta vytvořeným v databázi Lake pomocí Návrháře Sparku nebo Synapse. Přístup k tabulkám Delta je stále v režimu veřejného náhledu a v současné době bezserverové prostředí synchronizuje tabulku Delta se Sparkem při jejím vytváření, ale neaktualizuje schéma, když jsou sloupce později přidány pomocí příkazu ve Sparku ALTER TABLE.
Jedná se o omezení verze Public Preview. Odstraňte a znovu vytvořte tabulku Delta ve Sparku (pokud je to možné) místo změny tabulek, abyste tento problém vyřešili.
Vypršení časového limitu dotazu nebo snížení výkonu v tabulce
Při změně původní tabulky ve Sparku nebo Dataverse se automaticky znovu vytvoří odpovídající tabulky v bezserverovém fondu. Výsledkem tohoto procesu je ztráta existujících statistik v tabulce. Bez těchto statistik můžou dotazy na tabulku mít zpoždění nebo dokonce vypršení časových limitů.
Pokud narazíte na tento problém, zvažte nastavení úlohy pro opětovné vytvoření statistik v tabulkách po změnách ve Spark/Dataverse nebo pravidelně.
Výkon
Bezserverový fond SQL přiřazuje prostředky dotazům na základě velikosti datové sady a složitosti dotazů. Nemůžete změnit ani omezit prostředky, které jsou k dispozici pro dotazy. V některých případech může docházet k neočekávanému snížení výkonu dotazů a možná budete muset identifikovat původní příčiny.
Doba trvání dotazu je velmi dlouhá
Pokud máte dotazy s dobou trvání delší než 30 minut, dotaz pomalu vrací výsledky klientovi. Fond SQL bez serveru má limit 30 minut pro spuštění. Další čas se stráví streamováním výsledků. Vyzkoušejte následující postupy:
- Pokud používáte Synapse Studio, zkuste reprodukovat problémy s jinou aplikací, jako je SQL Server Management Studio nebo Azure Data Studio.
- Pokud je dotaz pomalý při spuštění pomocí aplikace SQL Server Management Studio, Azure Data Studio, Power BI nebo jiné aplikace, zkontrolujte problémy se sítěmi a osvědčené postupy.
- Vložte dotaz do příkazu CETAS a změřte dobu trvání dotazu. Příkaz CETAS ukládá výsledky do služby Azure Data Lake Storage a nezávisí na připojení klienta. Pokud se příkaz CETAS dokončí rychleji než původní dotaz, zkontrolujte šířku pásma sítě mezi klientem a bezserverovým fondem SQL.
Dotaz je pomalý při spuštění pomocí nástroje Synapse Studio
Pokud používáte Synapse Studio, zkuste použít desktopového klienta, jako je SQL Server Management Studio nebo Azure Data Studio. Synapse Studio je webový klient, který se připojuje k bezserverovém fondu SQL pomocí protokolu HTTP, což je obecně pomalejší než nativní připojení SQL používaná v sadě SQL Server Management Studio nebo Azure Data Studio.
Dotaz je pomalý při spuštění pomocí aplikace.
Pokud dochází k pomalému spouštění dotazů, zkontrolujte následující problémy:
- Ujistěte se, že jsou klientské aplikace umístěné společně s koncovým bodem bezserverového SQL fondu. Spuštění dotazu v celé oblasti může způsobit další latenci a pomalé streamování sady výsledků.
- Ujistěte se, že nemáte problémy se sítí, které můžou způsobit pomalé streamování sady výsledků.
- Ujistěte se, že klientská aplikace má dostatek prostředků (například nepoužívá 100% procesor).
- Ujistěte se, že je účet úložiště nebo analytické úložiště Azure Cosmos DB umístěné ve stejné oblasti jako bezserverový koncový bod SQL.
Podívejte se na osvědčené postupy pro kolaci prostředků.
Vysoké variace v době trvání dotazu
Pokud provádíte stejný dotaz a pozorujete variace v době trvání dotazu, může toto chování způsobit několik důvodů:
- Zkontrolujte, jestli se jedná o první spuštění dotazu. První spuštění dotazu shromažďuje statistiky potřebné k vytvoření plánu. Statistiky se shromažďují kontrolou podkladových souborů a můžou prodloužit dobu trvání dotazu. V nástroji Synapse Studio uvidíte dotazy na vytvoření globálních statistik v seznamu žádanek SQL, které se spouští před vaším dotazem.
- Statistika může po nějaké době vypršet. Občas si můžete všimnout dopadu na výkon, protože bezserverový fond musí provádět skenování a obnovu statistik. V seznamu žádostí SQL, které se spouští před dotazem, si můžete všimnout dalších dotazů globálních statistik.
- Zkontrolujte, jestli na stejném koncovém bodu běží nějaká úloha při spuštění dotazu s delší dobou trvání. Bezserverový koncový bod SQL rovnoměrně přiděluje prostředky všem dotazům, které se spouští paralelně, a dotaz může být zpožděný.
Propojení
Bezserverový fond SQL umožňuje připojení pomocí protokolu TDS a pomocí jazyka T-SQL k dotazování dat. Většina nástrojů, které se můžou připojit k SQL Serveru nebo Azure SQL Database, se může také připojit k bezserverovém fondu SQL.
SQL fond se zahřívá
Po delší době nečinnosti se deaktivuje bezserverový fond SQL. Aktivace se provede automaticky při první další aktivitě, například při prvním pokusu o připojení. Proces aktivace může trvat o něco déle, než je interval jednoho pokusu o připojení, proto se zobrazí chybová zpráva. Opakování pokusu o připojení by mělo být dostatečné.
Osvědčeným postupem je, pro klienty, kteří to podporují, použití klíčových slov ConnectionRetryCount a ConnectRetryInterval v připojovacím řetězci ke kontrole chování opětovného připojení. Většina klientských ovladačů SQL má výchozí časový limit připojení nastavený na 15 sekund. Ujistěte se, že je časový limit připojení nakonfigurovaný tak, aby umožňoval všechny pokusy o opakování. Vybrané hodnoty by například měly splňovat následující podmínku: Connection Timeout > ConnectRetryCount * ConnectionRetryInterval.
Pokud chybová zpráva přetrvává, vytvořte podpůrný ticket prostřednictvím Azure portálu.
Nejde se připojit ze sady Synapse Studio
Podívejte se na část Synapse Studio.
Nejde se připojit k fondu Azure Synapse z nástroje
Některé nástroje nemusí mít explicitní možnost, kterou můžete použít pro připojení k bezserverovém fondu SQL Azure Synapse. Použijte možnost, kterou byste použili pro připojení k SQL Serveru nebo sql Database. Dialogové okno připojení nemusí být označené jako Synapse, protože bezserverový fond SQL používá stejný protokol jako SQL Server nebo SQL Database.
I když nástroj umožňuje zadat pouze název logického serveru a předdefinuje database.windows.net doménu, vložte název pracovního prostoru Azure Synapse následovaný -ondemand příponou a doménou database.windows.net .
Zabezpečení
Ujistěte se, že má uživatel oprávnění pro přístup k databázím, oprávnění ke spouštění příkazů a oprávnění pro přístup k Úložišti Azure Data Lake nebo Azure Cosmos DB.
Nejde získat přístup k účtu služby Azure Cosmos DB
Pro přístup k analytickému úložišti musíte použít klíč služby Azure Cosmos DB jen pro čtení, proto se ujistěte, že nevypršela nebo se znovu nevygenerovala.
Pokud se zobrazí chyba "Řešení cesty ke službě Azure Cosmos DB selhalo s chybou", ujistěte se, že jste nakonfigurovali bránu firewall.
Nejde získat přístup k databázi Lakehouse nebo Spark
Pokud uživatel nemá přístup k databázi Lakehouse nebo Spark, nemusí mít oprávnění k přístupu a čtení databáze. Uživatel s oprávněním CONTROL SERVER by měl mít úplný přístup ke všem databázím. Jako omezené oprávnění se můžete pokusit použít CONNECT ANY DATABASE a SELECT ALL USER SECURABLES.
Uživatel SQL nemůže získat přístup k tabulkám Dataverse
Tabulky Dataverse přistupují k úložišti pomocí identity volajícího v rámci služby Microsoft Entra. Uživatel SQL s vysokými oprávněními se může pokusit vybrat data z tabulky, ale tato tabulka by neměla přístup k datům Dataverse. Tento scénář není podporován.
Selhání přihlášení instančního objektu Microsoft Entra při vytváření přiřazení role
Pokud chcete vytvořit přiřazení role pro identifikátor služby (SPI) nebo aplikaci Microsoft Entra pomocí jiného SPI, nebo jste ho už vytvořili a přihlášení se nezdaří, pravděpodobně se zobrazí následující chyba: Login error: Login failed for user '<token-identified principal>'.
Pro instanční objekty služby by mělo být vytvořeno přihlášení s ID aplikace jako identifikátorem zabezpečení (SID), nikoliv s ID objektu. U instančních objektů existuje známé omezení, které službě Azure Synapse brání v načtení ID aplikace z Microsoft Graphu při vytváření přiřazení role pro jiný SPI nebo jinou aplikaci.
Řešení 1
Přejděte na Azure portal>Synapse Studio>Správa>řízení přístupu a ručně přidejte správce Synapse nebo správce Synapse SQL pro požadovaný služební principál.
Řešení 2
Musíte ručně vytvořit správné přihlášení pomocí kódu SQL:
use master
go
CREATE LOGIN [<service_principal_name>] FROM EXTERNAL PROVIDER;
go
ALTER SERVER ROLE sysadmin ADD MEMBER [<service_principal_name>];
go
Řešení 3
Pomocí PowerShellu můžete také nastavit principála služby Azure Synapse jako správce. Musíte mít nainstalovaný modul Az.Synapse.
Řešením je použít rutinu New-AzSynapseRoleAssignment s -ObjectId "parameter". V poli parametru zadejte ID aplikace místo ID objektu pomocí přihlašovacích údajů hlavní služby správce pracovního prostoru Azure.
Skript PowerShellu:
$spAppId = "<app_id_which_is_already_an_admin_on_the_workspace>"
$SPPassword = "<application_secret>"
$tenantId = "<tenant_id>"
$secpasswd = ConvertTo-SecureString -String $SPPassword -AsPlainText -Force
$cred = New-Object -TypeName System.Management.Automation.PSCredential -ArgumentList $spAppId, $secpasswd
Connect-AzAccount -ServicePrincipal -Credential $cred -Tenant $tenantId
New-AzSynapseRoleAssignment -WorkspaceName "<workspaceName>" -RoleDefinitionName "Synapse Administrator" -ObjectId "<app_id_to_add_as_admin>" [-Debug]
Poznámka:
V tomto případě uživatelské rozhraní sady Synapse Data Studio nezobrazí přiřazení role přidané výše uvedenou metodou, proto se doporučuje přidat přiřazení role k ID objektu i ID aplikace současně, aby ho bylo možné zobrazit i v uživatelském rozhraní.
New-AzSynapseRoleAssignment -WorkspaceName "<workspaceName>" -RoleDefinitionName "Správce Synapse" -ObjectId "<object_id_to_add_as_admin>" [-Debug]
Ověření
Připojte se ke koncovému bodu SQL bez serveru a ověřte, že se vytvoří externí přihlášení pomocí identifikátoru SID (app_id_to_add_as_admin v předchozí ukázce):
SELECT name, convert(uniqueidentifier, sid) AS sid, create_date
FROM sys.server_principals
WHERE type in ('E', 'X');
Nebo se zkuste přihlásit k bezserverovému koncovému bodu SQL pomocí administrační aplikace.
Omezení
Některá obecná omezení systému můžou mít vliv na vaši úlohu:
| Vlastnost | Omezení |
|---|---|
| Maximální počet pracovních prostorů Azure Synapse na předplatné | Zobrazit limity. |
| Maximální počet databází pro fond bez serveru | 100 (nezahrnuje databáze synchronizované z fondu Apache Sparku). |
| Maximální počet databází synchronizovaných z fondu Apache Spark | Není omezený. |
| Maximální počet objektů databází na databázi | Součet počtu všech objektů v databázi nesmí překročit 2 147 483 647. Viz Omezení databázového stroje SQL Serveru. |
| Maximální délka identifikátoru ve znacích | 128. Viz Omezení v databázovém stroji SQL Serveru. |
| Maximální doba trvání dotazu | 30 minut. |
| Maximální velikost sady výsledků | Až 400 GB je sdíleno mezi souběžnými dotazy. |
| Maximální souběžnost | Není omezeno a závisí na složitosti dotazu a množství kontrolovaných dat. Jeden bezserverový fond SQL může souběžně zpracovávat 1 000 aktivních relací, které provádějí nenáročné dotazy. Čísla se sníží, pokud jsou dotazy složitější nebo prohledávají větší množství dat, takže v takovém případě zvažte snížení souběžnosti a provádějte dotazy po delší dobu, pokud je to možné. |
| Maximální velikost názvu externí tabulky | 100 znaků. |
Nejde vytvořit databázi v bezserverovém fondu SQL
Bezserverové fondy SQL mají omezení a nemůžete vytvořit více než 100 databází na pracovní prostor. Pokud potřebujete oddělit objekty a izolovat je, použijte schémata.
Pokud se zobrazí chyba CREATE DATABASE failed. User database limit has been already reached , vytvořili jste maximální počet databází podporovaných v jednom pracovním prostoru.
K izolaci dat pro různé tenanty nemusíte používat samostatné databáze. Všechna data se ukládají externě v datovém jezeře a ve službě Azure Cosmos DB. Metadata, jako jsou tabulky, zobrazení a definice funkcí, je možné úspěšně izolovat pomocí schémat. Izolace založená na schématu se používá také ve Sparku, kde databáze a schémata jsou stejné koncepty.