Pokyny k modelu DirectQuery v Power BI Desktopu
Tento článek se zaměřuje na modelátory dat, kteří vyvíjejí modely DirectQuery Power BI vyvinuté pomocí Power BI Desktopu nebo služba Power BI. Popisuje případy použití DirectQuery, omezení a pokyny. Konkrétně jsou pokyny navržené tak, aby vám pomohly určit, jestli je DirectQuery vhodný režim pro váš model, a zlepšit výkon sestav založených na modelech DirectQuery. Tento článek se týká modelů DirectQuery hostovaných v služba Power BI nebo Server sestav Power BI.
Tento článek nemá v úmyslu poskytnout úplnou diskuzi o návrhu modelu DirectQuery. Úvod najdete v článku o modelech DirectQuery v Power BI Desktopu . Podrobnější informace najdete v dokumentu white paper služby SQL Server 2016 Analysis Services přímo na DirectQuery. Mějte na paměti, že dokument white paper popisuje použití DirectQuery v Služba Analysis Services serveru SQL. Většina obsahu se ale stále vztahuje na modely DirectQuery Power BI.
Poznámka:
Důležité informace o použití režimu úložiště DirectQuery pro Službu Dataverse najdete v pokynech k modelování Power BI pro Power Platform.
Tento článek přímo nepokrývá složené modely. Složený model se skládá z alespoň jednoho zdroje DirectQuery a případně i více. Pokyny popsané v tomto článku jsou stále relevantní (alespoň zčásti) pro návrh složeného modelu. Důsledky kombinování tabulek importu s tabulkami DirectQuery ale nejsou v oboru pro tento článek. Další informace najdete v tématu Použití složených modelů v Power BI Desktopu.
Je důležité si uvědomit, že modely DirectQuery ukládají různé úlohy do prostředí Power BI (služba Power BI nebo Server sestav Power BI) a také na podkladové zdroje dat. Pokud zjistíte, že DirectQuery je vhodný přístup k návrhu, doporučujeme zapojit správné lidi na projektu. Často vidíme, že úspěšné nasazení modelu DirectQuery je výsledkem týmu IT odborníků, kteří úzce spolupracují. Tým se obvykle skládá z vývojářů modelů a správců zdrojové databáze. Může také zahrnovat architekty dat a vývojáře datového skladu a ETL. Optimalizace je často potřeba použít přímo u zdroje dat, aby se dosáhlo dobrých výsledků výkonu.
Optimalizace výkonu zdroje dat
Zdroj relační databáze lze optimalizovat několika způsoby, jak je popsáno v následujícím seznamu s odrážkami.
Poznámka:
Chápeme, že ne všichni modeléři mají oprávnění nebo dovednosti k optimalizaci relační databáze. I když se jedná o upřednostňovanou vrstvu pro přípravu dat pro model DirectQuery, některé optimalizace je možné dosáhnout také v návrhu modelu beze změny zdrojové databáze. Nejlepších výsledků optimalizace se ale často dosahuje použitím optimalizací u zdrojové databáze.
Ujistěte se, že je integrita dat dokončená: Je zvlášť důležité, aby tabulky typu dimenze obsahovaly sloupec jedinečných hodnot (klíč dimenze), který se mapuje na tabulky faktů. Je také důležité, aby sloupce dimenzí typu fakta obsahovaly platné hodnoty klíče dimenze. Umožní konfigurovat efektivnější relace modelu, které očekávají odpovídající hodnoty na obou stranách relací. Pokud zdrojová data nemají integritu, doporučuje se přidat "neznámý" záznam dimenze pro efektivní opravu dat. Do tabulky Product můžete například přidat řádek, který představuje neznámý produkt, a pak ho přiřadit klíč mimo rozsah, například -1. Pokud řádky v tabulce Sales obsahují chybějící hodnotu kódu Product Key, nahraďte je hodnotou -1. Zajišťuje, že každá hodnota kódu Product Key má odpovídající řádek v tabulce Product (Produkt).
Přidání indexů: Definujte vhodné indexy (v tabulkách nebo zobrazeních), které podporují efektivní načítání dat pro očekávané filtrování a seskupení vizuálů sestavy. Pro zdroje SQL Serveru, Azure SQL Database nebo Azure Synapse Analytics (dříve SQL Data Warehouse) najdete užitečné informace o pokynech k návrhu indexu sql Serveru v příručce k architektuře a návrhu indexu. Informace o nestálých zdrojích SQL Serveru nebo Azure SQL Database najdete v tématu Začínáme se columnstorem pro provozní analýzy v reálném čase.
Návrh distribuovaných tabulek: Pro zdroje Azure Synapse Analytics (dříve SQL Data Warehouse), které používají architekturu MPP (Massively Parallel Processing), zvažte konfiguraci rozsáhlých tabulek typu fakta jako distribuovaných hodnot hash a tabulky dimenzí pro replikaci napříč všemi výpočetními uzly. Další informace najdete v tématu Pokyny k návrhu distribuovaných tabulek ve službě Azure Synapse Analytics (dříve SQL Data Warehouse).
Ujistěte se, že jsou požadované transformace dat materializované: Pro zdroje relační databáze SQL Serveru (a další zdroje relačních databází) je možné do tabulek přidat počítané sloupce. Tyto sloupce jsou založené na výrazu, jako je Množství vynásobené jednotkovouprice. Počítané sloupce můžou být trvalé (materializované) a podobně jako běžné sloupce se někdy dají indexovat. Další informace najdete v tématu Indexy ve vypočítaných sloupcích.
Zvažte také indexovaná zobrazení, která můžou předem agregovat data tabulky faktů s vyšší úrovní. Pokud například tabulka Sales ukládá data na úrovni řádku objednávky, můžete vytvořit zobrazení pro shrnutí těchto dat. Zobrazení může být založené na příkazu SELECT, který seskupuje data tabulky Sales podle data (na úrovni měsíce), zákazníka, produktu a sumarizuje hodnoty měr, jako je prodej, množství atd. Zobrazení pak lze indexovat. Informace o zdrojích SQL Serveru nebo Azure SQL Database najdete v tématu Vytváření indexovaných zobrazení.
Materializace tabulky kalendářních dat: Běžný požadavek na modelování zahrnuje přidání tabulky kalendářních dat pro podporu filtrování na základě času. Pokud chcete podporovat známé časové filtry ve vaší organizaci, vytvořte ve zdrojové databázi tabulku a ujistěte se, že je načtená s rozsahem kalendářních dat zahrnujících kalendářní data tabulky faktů. Také se ujistěte, že obsahuje sloupce pro užitečná časová období, jako je rok, čtvrtletí, měsíc, týden atd.
Optimalizace návrhu modelu
Model DirectQuery lze optimalizovat mnoha způsoby, jak je popsáno v následujícím seznamu s odrážkami.
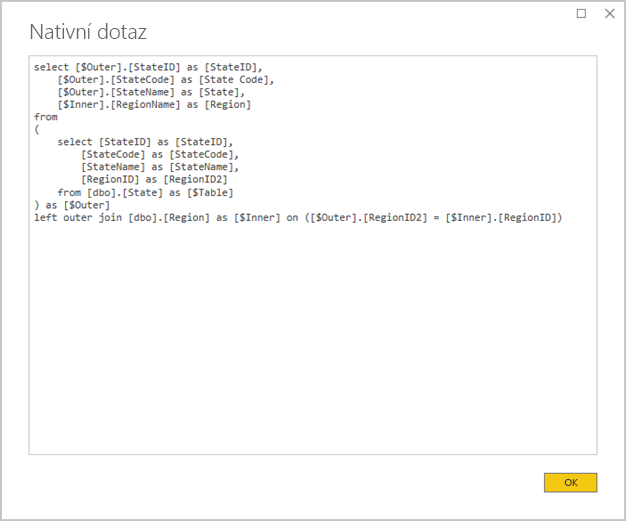
Vyhněte se složitým dotazům Power Query: Efektivní návrh modelu je možné dosáhnout odebráním potřeby dotazů Power Query použít jakékoli transformace. To znamená, že každý dotaz se mapuje na jednu zdrojovou tabulku nebo zobrazení relační databáze. Výběrem možnosti Zobrazit nativní dotaz můžete zobrazit náhled skutečného příkazu dotazu SQL pro použitý krok Power Query.
Prozkoumejte použití počítaných sloupců a změn datového typu: Modely DirectQuery podporují přidávání výpočtů a kroků Power Query pro převod datových typů. Lepšího výkonu se ale často dosahuje materializací výsledků transformace ve zdroji relační databáze, pokud je to možné.
Nepoužívejte filtrování relativního data Power Query: V dotazu Power Query je možné definovat filtrování relativního data. Pokud například chcete načíst prodejní objednávky vytvořené v posledním roce (vzhledem k dnešnímu datu). Tento typ filtru se překládá na neefektivní nativní dotaz následujícím způsobem:
… from [dbo].[Sales] as [_] where [_].[OrderDate] >= convert(datetime2, '2018-01-01 00:00:00') and [_].[OrderDate] < convert(datetime2, '2019-01-01 00:00:00'))Lepším způsobem návrhu je zahrnout sloupce relativního času do tabulky kalendářních dat. Tyto sloupce ukládají hodnoty posunu vzhledem k aktuálnímu datu. Například ve sloupci RelativeYear představuje nula aktuální rok, -1 představuje předchozí rok atd. Pokud možno, sloupec RelativeYear je materializován v tabulce kalendářních dat. I když je méně efektivní, můžete ho také přidat jako počítaný sloupec modelu na základě výrazu pomocí funkcí TODAY a DATE DAX.
Zachovat jednoduché míry: Alespoň zpočátku se doporučuje omezit míry na jednoduché agregace. Mezi agregační funkce patří SUMA, COUNT, MIN, MAX a AVERAGE. Pokud jsou míry dostatečně responzivní, můžete experimentovat se složitějšími mírami, ale věnovat pozornost výkonu pro každou z nich. I když lze funkci CALCULATE DAX použít k vytváření sofistikovaných výrazů měr, které manipulují s kontextem filtru, můžou generovat nákladné nativní dotazy, které dobře nefungují.
Vyhněte se relacím u počítaných sloupců: Relace modelu můžou propojit pouze jeden sloupec v jedné tabulce s jedním sloupcem v jiné tabulce. Někdy je ale nutné propojit tabulky pomocí více sloupců. Například tabulky Sales a Geography souvisejí se dvěma sloupci: CountryRegion (Země) a City (Město). Pokud chcete vytvořit relaci mezi tabulkami, vyžaduje se jeden sloupec a v tabulce Geography musí sloupec obsahovat jedinečné hodnoty. K dosažení tohoto výsledku by mohlo dojít ke zřetězení země/oblasti a města s oddělovačem spojovníku.
Kombinovaný sloupec lze vytvořit buď s vlastním sloupcem Power Query, nebo v modelu jako počítaným sloupcem. Měli byste se však vyhnout, protože výraz výpočtu bude vložen do zdrojových dotazů. Nejen že je neefektivní, obvykle brání použití indexů. Místo toho přidejte materializované sloupce do zdroje relační databáze a zvažte jejich indexování. Můžete také zvážit přidání náhradních klíčových sloupců do tabulek typu dimenze, což je běžný postup při návrhu relačního datového skladu.
V tomto návodu je jedna výjimka a týká se použití funkce COMBINEVALUES DAX. Účelem této funkce je podporovat relace modelu s více sloupci. Místo vygenerování výrazu, který relace používá, vygeneruje predikát spojení SQL s více sloupci.
Vyhněte se relacím ve sloupcích Jedinečný identifikátor: Power BI nativně nepodporuje datový typ jedinečného identifikátoru (GUID). Při definování relace mezi sloupci tohoto typu vygeneruje Power BI zdrojový dotaz se spojením zahrnujícím přetypování. Tento převod dat v době dotazu obvykle vede k nízkému výkonu. Dokud se tento případ neoptimalizuje, jediným alternativním řešením je materializovat sloupce alternativního datového typu v podkladové databázi.
Skryjte jednostranný sloupec relací: Jednostranný sloupec relace by měl být skrytý. (Obvykle se jedná o sloupec primárního klíče tabulek typu dimenze.) Pokud je tato možnost skrytá, není dostupná v podokně Pole , takže se nedá použít ke konfiguraci vizuálu. Sloupec na straně N může zůstat viditelný, pokud je užitečné seskupit nebo filtrovat sestavy podle hodnot sloupců. Představte si například model, ve kterém existuje relace mezi tabulkami Sales (Prodej ) a Product (Produkt ). Sloupce relace obsahují hodnoty skladové položky produktu (Skladová položka jednotky). Pokud se skladová položka produktu musí přidat do vizuálů, měla by být viditelná pouze v tabulce Sales (Prodej). Pokud se tento sloupec používá k filtrování nebo seskupení ve vizuálu, Power BI vygeneruje dotaz, který nepotřebuje spojit tabulky Sales a Product .
Nastavit relace tak, aby vynucovaly integritu: Vlastnost Předpokládat referenční integritu relací DirectQuery určuje, jestli Power BI generuje zdrojové dotazy pomocí vnitřního spojení místo vnějšího spojení. Obecně zvyšuje výkon dotazů, i když závisí na specifikách zdroje relační databáze. Další informace najdete v tématu Předpokládat nastavení referenční integrity v Power BI Desktopu.
Nepoužívejte obousměrné filtrování relací: Použití obousměrného filtrování relací může vést k příkazům dotazů, které dobře nefungují. Tuto funkci relace používejte jenom v případě potřeby a obvykle se jedná o případ implementace relace M:N v tabulce přemostění. Další informace najdete v tématu Relace s kardinalitou M:N v Power BI Desktopu.
Omezit paralelní dotazy: Pro každý podkladový zdroj dat můžete nastavit maximální počet připojení DirectQuery. Řídí počet dotazů současně odesílaných do zdroje dat.
- Nastavení je povolené jenom v případech, kdy je v modelu alespoň jeden zdroj DirectQuery. Hodnota se vztahuje na všechny zdroje DirectQuery a na všechny nové zdroje DirectQuery přidané do modelu.
- Zvýšení hodnoty Maximální počet připojení na zdroj dat zajišťuje, že se do podkladového zdroje dat odešle více dotazů (až do zadaného maximálního počtu), což je užitečné, když je na jedné stránce více vizuálů nebo mnoho uživatelů přistupuje k sestavě najednou. Po dosažení maximálního počtu připojení se další dotazy zařadí do fronty, dokud nebude připojení dostupné. Zvýšení tohoto limitu vede k většímu zatížení podkladového zdroje dat, takže není zaručeno, že se zlepší celkový výkon.
- Při publikování modelu do Power BI závisí maximální počet souběžných dotazů odesílaných do podkladového zdroje dat také na prostředí. Různá prostředí (například Power BI, Power BI Premium nebo Server sestav Power BI) můžou mít různá omezení propustnosti. Další informace o omezeních prostředků kapacity najdete v tématu Licence kapacity Microsoft Fabric a Konfigurace a správa kapacit v Power BI Premium.
Důležité
Někdy se tento článek týká Power BI Premium nebo jejích předplatných kapacity (SKU P). Mějte na paměti, že Microsoft v současné době konsoliduje možnosti nákupu a vyřazuje Power BI Premium na skladové položky kapacity. Místo toho by měli noví a stávající zákazníci zvážit nákup předplatných kapacity Fabric (SKU F).
Další informace najdete v tématu Důležité aktualizace týkající se licencování Power BI Premium a nejčastějších dotazů k Power BI Premium.
Optimalizace návrhů sestav
Sestavy založené na sémantickém modelu DirectQuery je možné optimalizovat mnoha způsoby, jak je popsáno v následujícím seznamu s odrážkami.
- Povolit techniky redukce dotazů: Možnosti a nastavení Power BI Desktopu obsahují stránku Redukce dotazů. Tato stránka obsahuje tři užitečné možnosti. Ve výchozím nastavení je možné zakázat křížové zvýraznění a křížové filtrování, i když je možné je přepsat úpravou interakcí. U průřezů a filtrů je také možné zobrazit tlačítko Použít. Možnosti průřezu nebo filtru se nepoužijí, dokud uživatel sestavy na tlačítko neklikne. Pokud tyto možnosti povolíte, doporučujeme, abyste to udělali při prvním vytvoření sestavy.
- Nejprve použijte filtry: Při prvním návrhu sestav doporučujeme použít všechny použitelné filtry – na úrovni sestavy, stránky nebo vizuálu – před mapováním polí na pole vizuálu. Například místo přetažení v mírách CountryRegion (Země) a Sales (Země) a Sales (Prodej) a následné filtrování podle konkrétního roku použijte filtr na pole Year (Rok). Je to proto, že každý krok vytvoření vizuálu odešle dotaz, a i když je možné provést další změnu před dokončením prvního dotazu, stále zbytečně zatěžuje podkladový zdroj dat. Když použijete filtry na začátku, obvykle tyto zprostředkující dotazy budou méně nákladné a rychlejší. Neúspěšné použití filtrů může také způsobit překročení limitu 1 milionu řádků, jak je popsáno v tématu DirectQuery.
- Omezit počet vizuálů na stránce: Při otevření stránky sestavy (a při použití filtrů stránek) se aktualizují všechny vizuály na stránce. Existuje ale limit počtu dotazů, které je možné paralelně odesílat, a to prostředím Power BI a nastavením maximálního počtu připojení na model zdroje dat, jak je popsáno výše. S rostoucím počtem vizuálů stránek je tedy větší pravděpodobnost, že se aktualizují sériově. Zvyšuje dobu potřebnou k aktualizaci celé stránky a také zvyšuje pravděpodobnost, že vizuály můžou zobrazovat nekonzistentní výsledky (pro nestálé zdroje dat). Z těchto důvodů se doporučuje omezit počet vizuálů na libovolné stránce a místo toho mít jednodušší stránky. Nahrazení více vizuálů karet jedním vizuálem karty s více řádky může dosáhnout podobného rozložení stránky.
- Vypnutí interakce mezi vizuály: Interakce křížového zvýrazňování a křížového filtrování vyžadují odeslání dotazů do podkladového zdroje. Pokud nejsou tyto interakce nutné, doporučujeme je vypnout, pokud by doba potřebná k reagování na výběr uživatelů byla nepřiměřeně dlouhá. Tyto interakce je možné vypnout buď pro celou sestavu (jak je popsáno výše pro možnosti snížení počtu dotazů), nebo případ od případu. Další informace najdete v tématu Jak se vizuály křížově filtrují v sestavě Power BI.
Kromě výše uvedeného seznamu technik optimalizace může každá z následujících funkcí generování sestav přispět k problémům s výkonem:
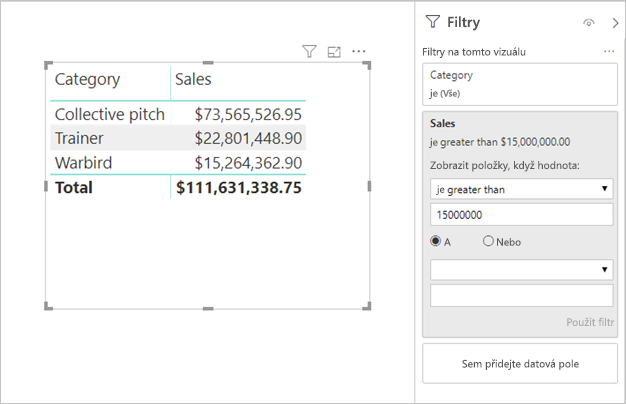
Filtry měr: Vizuály obsahující míry (nebo agregace sloupců) můžou mít na tyto míry použité filtry. Například následující vizuál zobrazuje Prodej podle kategorie, ale pouze pro kategorie s více než 15 miliony dolarů z prodeje.
Může to vést k tomu, že se do podkladového zdroje odesílají dva dotazy:
- První dotaz načte kategorie splňující podmínku (Prodej > 15 milionů USD).
- Druhý dotaz pak načte potřebná data pro vizuál a přidá kategorie, které splňovaly podmínku do klauzule WHERE.
Obecně platí, že pokud existují stovky nebo tisíce kategorií, jako v tomto příkladu. Výkon se ale může snížit, pokud je počet kategorií mnohem větší (a dotaz skutečně selže, pokud splňuje podmínku více než 1 milion kategorií, protože výše probíraný limit 1 milion řádků).
Filtry topn: Rozšířené filtry je možné definovat tak, aby filtry byly filtrovány pouze podle nejvyšších (nebo nejnižších) N hodnot seřazených podle míry. Pokud chcete například zobrazit pouze prvních pět kategorií ve výše uvedeném vizuálu. Stejně jako filtry měr bude mít za následek odeslání dvou dotazů do podkladového zdroje dat. První dotaz ale vrátí všechny kategorie z podkladového zdroje a pak se určí horní N na základě vrácených výsledků. V závislosti na kardinalitě daného sloupce může dojít k problémům s výkonem (nebo k selhání dotazů kvůli limitu 1 milion řádků).
Medián: Obecně se do podkladového zdroje vloží jakákoli agregace (součet, počet jedinečných atd.). Medián ale není pravdivý, protože podkladový zdroj tuto agregaci nepodporuje. V takových případech se z podkladového zdroje načtou podrobná data a Power BI vyhodnotí medián z vrácených výsledků. Je v pořádku, když se medián počítá přes relativně malý počet výsledků, ale pokud je kardinalita velká, dojde k problémům s výkonem (nebo selháním dotazů kvůli limitu 1 milion řádků). Medián populace země/oblasti může být například rozumný, ale medián prodejní ceny nemusí být.
Průřezy s vícenásobným výběrem: Povolení vícenásobného výběru v průřezech a filtrech může způsobit problémy s výkonem. Je to proto, že když uživatel vybere další položky průřezu (například sestavte až 10 produktů, které zajímají), každý nový výběr způsobí odeslání nového dotazu do podkladového zdroje. I když uživatel může vybrat další položku před dokončením dotazu, bude mít za následek dodatečné zatížení podkladového zdroje. Této situaci se můžete vyhnout zobrazením tlačítka Použít, jak je popsáno výše v technikách redukce dotazů.
Vizuální součty: Ve výchozím nastavení se v tabulkách a maticích zobrazují součty a mezisoučty. V mnoha případech musí být do podkladového zdroje odeslány další dotazy, aby se získaly hodnoty součtů. Platí vždy, když používáte agregace Count Distinct nebo Median, a ve všech případech při použití DirectQuery přes SAP HANA nebo SAP Business Warehouse. Tyto součty by měly být v případě potřeby vypnuté (pomocí podokna Formát).
Převod na složený model
Výhody modelů Import a DirectQuery je možné kombinovat do jednoho modelu konfigurací režimu úložiště tabulek modelu. Režim úložiště tabulek může být Import nebo DirectQuery nebo obojí, označované jako Duální. Pokud model obsahuje tabulky s různými režimy úložiště, označuje se jako složený model. Další informace najdete v tématu Použití složených modelů v Power BI Desktopu.
Existuje mnoho vylepšení funkčnosti a výkonu, které lze dosáhnout převodem modelu DirectQuery na složený model. Složený model může integrovat více než jeden zdroj DirectQuery a může také zahrnovat agregace. Agregační tabulky je možné přidat do tabulek DirectQuery, aby se naimportovala souhrnná reprezentace tabulky. Můžou dosáhnout výrazných vylepšení výkonu, když vizuály zadají dotazy na agregace vyšší úrovně. Další informace najdete v tématu Agregace v Power BI Desktopu.
Vzdělávání uživatelů
Je důležité informovat uživatele o tom, jak efektivně pracovat se sestavami založenými na sémantických modelech DirectQuery. Autoři sestav by měli mít informace o obsahu popsaném v části Optimalizace návrhů sestav.
Doporučujeme informovat uživatele sestav o vašich sestavách založených na sémantických modelech DirectQuery. Může být užitečné pochopit obecnou architekturu dat, včetně případných relevantních omezení popsaných v tomto článku. Dejte jim vědět, že odpovědi na aktualizace a interaktivní filtrování můžou být občas pomalé. Když uživatelé sestav pochopí, proč dochází ke snížení výkonu, budou méně pravděpodobné, že ztratí důvěru v sestavy a data.
Při doručování sestav o nestálých zdrojích dat nezapomeňte uživatele sestav informovat o použití tlačítka Aktualizovat. Dejte jim vědět také, že může být možné zobrazit nekonzistentní výsledky a že aktualizace sestavy dokáže vyřešit případné nekonzistence na stránce sestavy.
Související obsah
Další informace o DirectQuery najdete v následujících zdrojích informací: