Pokyny k modelování Power BI pro Power Platform
Microsoft Dataverse je standardní datová platforma pro mnoho produktů obchodních aplikací Microsoftu, včetně aplikací plátna Dynamics 365 Customer Engagement a Power Apps, a také Dynamics 365 Customer Voice (dříve Microsoft Forms Pro), schválení Power Automate, portály Power Apps a další.
Tento článek obsahuje pokyny k vytvoření datového modelu Power BI, který se připojuje k Dataverse. Popisuje rozdíly mezi schématem Dataverse a optimalizovaným schématem Power BI a poskytuje pokyny k rozšíření viditelnosti obchodních dat aplikací v Power BI.
Vzhledem k jeho snadnému nastavení, rychlému nasazení a rozšířenému přijetí data Dataverse ukládá a spravuje rostoucí objem dat v prostředích napříč organizacemi. To znamená, že existuje ještě větší potřeba (a příležitost) integrovat analýzy s těmito procesy. Mezi příležitosti patří:
- Sestava pro všechna data Dataverse, která přesahují omezení předdefinovaných grafů.
- Umožňuje snadný přístup k relevantním kontextově filtrovaným sestavám v rámci konkrétního záznamu.
- Vylepšete hodnotu dat Dataverse jejich integrací s externími daty.
- Využijte výhod integrované umělé inteligence (AI) Power BI, aniž byste museli psát složitý kód.
- Zvyšte přijetí řešení Power Platform zvýšením jejich užitečnosti a hodnoty.
- Doručte hodnotu dat v aplikaci firemním rozhodovacím pravomocím.
Připojení Power BI k Dataverse
Připojení power BI do Dataverse zahrnuje vytvoření datového modelu Power BI. Můžete si vybrat ze tří metod pro vytvoření modelu Power BI.
- Import dat Dataverse pomocí konektoru Dataverse: Tato metoda ukládá (ukládá) data dataverse do modelu Power BI. Díky dotazování v paměti zajišťuje rychlý výkon. Nabízí také flexibilitu návrhu pro modelátory, což jim umožňuje integrovat data z jiných zdrojů. Z těchto silných stránek je import dat výchozím režimem při vytváření modelu v Power BI Desktopu.
- Import dat Dataverse pomocí Azure Synapse Linku: Tato metoda je variantou metody importu, protože také ukládá data do mezipaměti v modelu Power BI, ale dělá to připojením k Azure Synapse Analytics. Pomocí Azure Synapse Linku pro Dataverse se tabulky Dataverse průběžně replikují do Azure Synapse nebo Azure Data Lake Storage (ADLS) Gen2. Tento přístup se používá k hlášení stovek tisíc nebo dokonce milionů záznamů v prostředích Dataverse.
- Vytvoření připojení DirectQuery pomocí konektoru Dataverse: Tato metoda je alternativou k importu dat. Model DirectQuery se skládá pouze z metadat definujících strukturu modelu. Když uživatel otevře sestavu, Power BI odešle do Dataverse nativní dotazy, aby načetl data. Zvažte vytvoření modelu DirectQuery, když sestavy musí zobrazovat data Dataverse téměř v reálném čase nebo když Dataverse musí vynutit zabezpečení na základě role, aby uživatelé viděli jenom data, ke kterým mají oprávnění pro přístup.
Důležité
I když model DirectQuery může být dobrou alternativou v případě, že v sestavě potřebujete téměř v reálném čase hlásit nebo vynucovat zabezpečení Dataverse, může to mít za následek nízký výkon této sestavy.
Informace o aspektech DirectQuery najdete dále v tomto článku.
Pokud chcete určit správnou metodu pro model Power BI, měli byste zvážit:
- Výkon dotazů
- Objem dat
- Latence dat
- Zabezpečení na základě rolí
- Složitost nastavení
Tip
Podrobnou diskuzi o modelových architekturách (import, DirectQuery nebo složené), jejich výhodách a omezeních a funkcích, které vám pomůžou optimalizovat datové modely Power BI, najdete v tématu Volba architektury modelu Power BI.
Výkon dotazů
Dotazy odeslané do modelů importu jsou rychlejší než nativní dotazy odeslané do zdrojů dat DirectQuery. Je to proto, že importovaná data jsou uložená v mezipaměti a jsou optimalizovaná pro analytické dotazy (operace filtrování, seskupení a shrnutí).
Naopak modely DirectQuery načítají data ze zdroje jenom poté, co uživatel otevře sestavu, což vede k sekundám zpoždění při vykreslení sestavy. Interakce uživatelů se sestavou navíc vyžadují, aby se Power BI znovu dotazuje na zdroj, čímž se snižuje rychlost odezvy.
Objem dat
Při vývoji modelu importu byste se měli snažit minimalizovat data načtená do modelu. Platí to zejména pro velké modely nebo modely, které očekáváte, že se časem zvětší. Další informace najdete v tématu Techniky redukce dat pro modelování importu.
Připojení DirectQuery k Dataverse je dobrou volbou v případech, kdy výsledek dotazu sestavy není velký. Ve zdrojových tabulkách sestavy má velký výsledek dotazu více než 20 000 řádků nebo výsledek vrácený do sestavy po použití filtrů je více než 20 000 řádků. V takovém případě můžete vytvořit sestavu Power BI pomocí konektoru Dataverse.
Poznámka:
Velikost řádku 20 000 není pevný limit. Každý dotaz na zdroj dat ale musí vrátit výsledek do 10 minut. Dále v tomto článku se dozvíte, jak pracovat v těchto omezeních a o dalších aspektech návrhu DirectQuery služby Dataverse.
Výkon větších sémantických modelů (dříve označovaných jako datové sady) můžete zlepšit pomocí konektoru Dataverse k importu dat do datového modelu.
Ještě větší sémantické modely – s několika stovkami nebo dokonce miliony řádků – můžou těžit z použití Azure Synapse Linku pro Dataverse. Tento přístup nastaví průběžný spravovaný kanál, který kopíruje data Dataverse do ADLS Gen2 jako soubory CSV nebo Parquet. Power BI pak může dotazovat bezserverový fond SQL Azure Synapse a načíst model importu.
Latence dat
Když se data Dataverse rychle změní a uživatelé sestav potřebují zobrazit aktuální data, model DirectQuery může poskytovat výsledky dotazů téměř v reálném čase.
Tip
Můžete vytvořit sestavu Power BI, která používá automatickou aktualizaci stránky k zobrazení aktualizací v reálném čase, ale jenom v případě, že se sestava připojí k modelu DirectQuery.
Modely importu dat musí dokončit aktualizaci dat, aby bylo možné vytvářet sestavy nedávných změn dat. Mějte na paměti, že počet každodenních plánovaných operací aktualizace dat má určitá omezení. Ve sdílené kapacitě můžete naplánovat až osm aktualizací za den. V kapacitě Premium nebo kapacitě Microsoft Fabric můžete naplánovat až 48 aktualizací za den, což může dosáhnout 15minutové frekvence aktualizace.
Důležité
Někdy se tento článek týká Power BI Premium nebo jejích předplatných kapacity (SKU P). Mějte na paměti, že Microsoft v současné době konsoliduje možnosti nákupu a vyřazuje Power BI Premium na skladové položky kapacity. Místo toho by měli noví a stávající zákazníci zvážit nákup předplatných kapacity Fabric (SKU F).
Další informace najdete v tématu Důležité aktualizace týkající se licencování Power BI Premium a nejčastějších dotazů k Power BI Premium.
Můžete také zvážit použití přírůstkové aktualizace k dosažení rychlejších aktualizací a téměř v reálném čase (k dispozici pouze u Premium nebo Fabric).
Zabezpečení na základě rolí
Pokud potřebujete vynutit zabezpečení na základě role, může to přímo ovlivnit výběr architektury modelu Power BI.
Dataverse může vynutit komplexní zabezpečení na základě role, aby bylo možné řídit přístup ke konkrétním záznamům konkrétním uživatelům. Prodejce může mít například povoleno zobrazit jenom své prodejní příležitosti, zatímco prodejní manažer může zobrazit všechny prodejní příležitosti pro všechny prodejce. Úroveň složitosti můžete přizpůsobit na základě potřeb vaší organizace.
Model DirectQuery založený na službě Dataverse se může připojit pomocí kontextu zabezpečení uživatele sestavy. Uživatel sestavy tak uvidí jenom data, ke kterým má povolený přístup. Tento přístup může zjednodušit návrh sestavy a zajistit, aby byl výkon přijatelný.
Pro zvýšení výkonu můžete vytvořit model importu, který se místo toho připojuje k Dataverse. V takovém případě můžete do modelu v případě potřeby přidat zabezpečení na úrovni řádků (RLS ).
Poznámka:
Jako zabezpečení na základě role v Power BI může být obtížné replikovat některé zabezpečení na základě role Dataverse, zejména když Služba Dataverse vynucuje složitá oprávnění. Dále může vyžadovat průběžnou správu, aby se oprávnění Power BI synchronizovala s oprávněními Dataverse.
Další informace o zabezpečení na úrovni řádků (RLS) v Power BI Desktopu najdete v tématu Zabezpečení na úrovni řádků (RLS).
Složitost nastavení
Použití konektoru Dataverse v Power BI – ať už pro modely importu nebo DirectQuery – je jednoduché a nevyžaduje žádná speciální softwarová nebo zvýšená oprávnění Dataverse. To je výhoda pro organizace nebo oddělení, které začínají.
Možnost Azure Synapse Link vyžaduje přístup správce systému k Dataverse a určitým oprávněním Azure. Tato oprávnění Azure se vyžadují k nastavení účtu úložiště a pracovního prostoru Synapse.
Doporučené postupy
Tato část popisuje vzory návrhu (a anti-patterny), které byste měli zvážit při vytváření modelu Power BI, který se připojuje k Dataverse. Dataverse je jedinečná jenom u několika z těchto vzorů, ale při vytváření sestav Power BI se obvykle jedná o běžné výzvy pro tvůrce Dataverse.
Zaměřte se na konkrétní případ použití.
Místo pokusu o vyřešení všeho se zaměřte na konkrétní případ použití.
Toto doporučení je pravděpodobně nejběžnější a nejobvyklejší anti-vzor, abyste se vyhnuli. Pokus o vytvoření jednoho modelu, který dosahuje všech potřeb samoobslužného generování sestav, je náročný. Skutečností je, že úspěšné modely jsou vytvořené tak, aby odpovídaly na otázky týkající se centrální sady faktů v jednom základním tématu. I když se to může zdát, že model zpočátku omezuje, ve skutečnosti to umožňuje, protože model můžete ladit a optimalizovat pro odpovědi na otázky v rámci daného tématu.
Abyste měli jistotu, že máte jasný přehled o účelu modelu, položte si následující otázky.
- Jakou oblast témat bude tento model podporovat?
- Kdo je cílová skupina sestav?
- Jaké otázky se sestavy snaží odpovědět?
- Jaký je minimální sémantický model?
Odporujte kombinování více oblastí témat do jednoho modelu, protože uživatel sestavy má otázky napříč několika oblastmi témat, které chce řešit jedna sestava. Když tuto sestavu rozdělíte do více sestav, každá se zaměřením na jiné téma (neboli tabulku faktů), můžete vytvářet mnohem efektivnější, škálovatelné a spravovatelné modely.
Návrh hvězdicového schématu
Vývojáři a správci služby Dataverse, kteří jsou obeznámeni se schématem Dataverse, můžou být v Power BI lákaví reprodukovat stejné schéma. Tento přístup je anti-vzor, a je pravděpodobně nejsnápadnější překonat, protože se jen cítí správně udržovat konzistenci.
Dataverse, jako relační model, je vhodný pro svůj účel. Není ale navržený jako analytický model, který je optimalizovaný pro analytické sestavy. Nejběžnější vzor pro modelování analytických dat je návrh hvězdicového schématu . Hvězdicové schéma je vyspělý přístup k modelování široce přijímaný relačními datovými sklady. Vyžaduje, aby modelátoři klasifikovali tabulky modelu jako dimenze nebo fakta. Sestavy můžou filtrovat nebo seskupovat pomocí sloupců tabulky dimenzí a sumarizovat sloupce tabulky faktů.
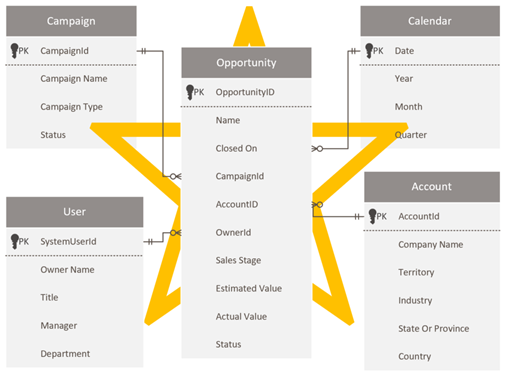
Další informace najdete v tématu Vysvětlení hvězdicového schématu a důležitosti pro Power BI.
Optimalizace dotazů Power Query
Mashupový modul Power Query se snaží dosáhnout posouvání dotazů, kdykoli je to možné z důvodů efektivity. Dotaz, který dosahuje skládání, deleguje zpracování dotazů do zdrojového systému.
Zdrojový systém v tomto případě Dataverse potřebuje do Power BI doručovat jenom filtrované nebo souhrnné výsledky. Přeložený dotaz je často výrazně rychlejší a efektivnější než dotaz, který se nepřeloží.
Další informace o tom, jak dosáhnout posouvání dotazů, najdete v tématu posouvání dotazů Power Query.
Poznámka:
Optimalizace Power Query je široké téma. Pokud chcete lépe porozumět tomu, co Power Query dělá při vytváření a v době aktualizace modelu v Power BI Desktopu, podívejte se na diagnostiku dotazů.
Minimalizace počtu sloupců dotazu
Pokud k načtení tabulky Dataverse použijete Power Query, načte všechny řádky a všechny sloupce. Když zadáte dotaz na systémovou uživatelskou tabulku, může například obsahovat více než 1 000 sloupců. Sloupce v metadatech zahrnují relace s jinými entitami a vyhledáváním popisků možností, takže celkový počet sloupců roste s složitostí tabulky Dataverse.
Pokus o načtení dat ze všech sloupců je anti-vzor. Často vede k rozšířeným operacím aktualizace dat a způsobí selhání dotazu v případě, že doba potřebná k vrácení dat překročí 10 minut.
Doporučujeme načíst jenom sloupce, které sestavy vyžadují. Při dokončení vývoje sestav je často vhodné znovu vyhodnotit a refaktorovat dotazy, které umožňují identifikovat a odebrat nepoužívané sloupce. Další informace najdete v tématu Techniky redukce dat pro modelování importu (odebrání nepotřebných sloupců).
Kromě toho se ujistěte, že v rané fázi zavádíte krok Odebrání sloupců Power Query, aby se přeložil zpět do zdroje. Power Query se tak může vyhnout zbytečné práci extrahování zdrojových dat, aby je později zahodili (v rozbaleném kroku).
Pokud máte tabulku, která obsahuje mnoho sloupců, může být nepraktické používat tvůrce interaktivních dotazů Power Query. V takovém případě můžete začít vytvořením prázdného dotazu. Potom můžete použít Rozšířený editor k vložení minimálního dotazu, který vytvoří výchozí bod.
Představte si následující dotaz, který načte data z pouhých dvou sloupců tabulky účtů .
let
Source = CommonDataService.Database("demo.crm.dynamics.com", [CreateNavigationProperties=false]),
dbo_account = Source{[Schema="dbo", Item="account"]}[Data],
#"Removed Other Columns" = Table.SelectColumns(dbo_account, {"accountid", "name"})
in
#"Removed Other Columns"
Psaní nativních dotazů
Pokud máte specifické požadavky na transformaci, můžete dosáhnout lepšího výkonu pomocí nativního dotazu napsaného v Dataverse SQL, což je podmnožina jazyka Transact-SQL. Nativní dotaz můžete napsat do:
- Snižte počet řádků (pomocí
WHEREklauzule). - Agregujte data (pomocí
GROUP BYklauzulí aHAVINGklauzulí). - Spojování tabulek určitým způsobem (pomocí
JOINsyntaxe)APPLY - Použijte podporované funkce SQL.
Další informace naleznete v tématu:
Spouštění nativních dotazů s možností EnableFolding
Power Query spustí nativní dotaz pomocí Value.NativeQuery funkce.
Při použití této funkce je důležité přidat EnableFolding=true možnost, aby se dotazy přeložily zpět do služby Dataverse. Nativní dotaz se nepřeloží, pokud není tato možnost přidána. Povolení této možnosti může vést k významným vylepšením výkonu – v některých případech až o 97 procent rychleji.
Představte si následující dotaz, který používá nativní dotaz ke zdroji vybraných sloupců z tabulky účtů . Nativní dotaz se přeloží, protože EnableFolding=true je tato možnost nastavená.
let
Source = CommonDataService.Database("demo.crm.dynamics.com"),
dbo_account = Value.NativeQuery(
Source,
"SELECT A.accountid, A.name FROM account A"
,null
,[EnableFolding=true]
)
in
dbo_account
Při načítání podmnožina dat z velkého objemu dat můžete očekávat největší vylepšení výkonu.
Tip
Zlepšení výkonu může také záviset na tom, jak Power BI dotazuje zdrojovou databázi. Například míra, která používá COUNTDISTINCT funkci DAX, ukázala téměř žádné zlepšení s skládací nápovědou nebo bez. Když se vzorec míry přepsal tak, aby používal SUMX funkci DAX, dotaz se přeložil a výsledkem bylo zlepšení o 97 procent oproti stejnému dotazu bez nápovědy.
Další informace naleznete v tématu Value.NativeQuery. (Možnost EnableFolding není zdokumentovaná, protože je specifická jenom pro určité zdroje dat.)
Zrychlení fáze vyhodnocení
Pokud používáte konektor Dataverse (dříve označovaný jako Common Data Service), můžete přidat CreateNavigationProperties=false možnost zrychlit fázi vyhodnocení importu dat.
Fáze vyhodnocení importu dat prochází metadaty jeho zdroje, aby se určily všechny možné relace mezi tabulkami. Tato metadata můžou být rozsáhlá, zejména pro Službu Dataverse. Přidáním této možnosti do dotazu dáte Power Query vědět, že tyto relace nemáte v úmyslu používat. Tato možnost umožňuje Power BI Desktopu přeskočit tuto fázi aktualizace a přejít k načtení dat.
Poznámka:
Tuto možnost nepoužívejte, pokud dotaz závisí na všech rozbalených sloupcích relací.
Představte si příklad, který načte data z tabulky účtu . Obsahuje tři sloupce související s územím: territory, territoryid a territoryidname.
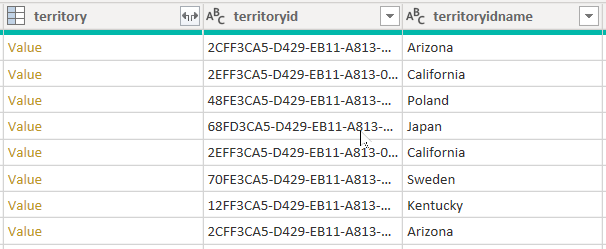
Když nastavíte CreateNavigationProperties=false možnost, sloupce territoryid a territoryidname zůstanou, ale sloupec oblasti, což je sloupec relace (zobrazuje odkazy na hodnotu), bude vyloučen. Je důležité si uvědomit, že sloupce relací Power Query představují jiný koncept než relace modelu, které šíří filtry mezi tabulkami modelů.
Zvažte následující dotaz, který používá CreateNavigationProperties=false možnost (v kroku Zdroj ) ke zrychlení fáze vyhodnocení importu dat.
let
Source = CommonDataService.Database("demo.crm.dynamics.com"
,[CreateNavigationProperties=false]),
dbo_account = Source{[Schema="dbo", Item="account"]}[Data],
#"Removed Other Columns" = Table.SelectColumns(dbo_account, {"accountid", "name", "address1_stateorprovince", "address1_country", "industrycodename", "territoryidname"}),
#"Renamed Columns" = Table.RenameColumns(#"Removed Other Columns", {{"name", "Account Name"}, {"address1_country", "Country"}, {"address1_stateorprovince", "State or Province"}, {"territoryidname", "Territory"}, {"industrycodename", "Industry"}})
in
#"Renamed Columns"
Při použití této možnosti pravděpodobně dojde k významnému zlepšení výkonu v případě, že tabulka Dataverse má mnoho relací s jinými tabulkami. Například vzhledem k tomu, že tabulka SystemUser souvisí s každou druhou tabulkou v databázi, může být výkon aktualizace této tabulky výhodný nastavením CreateNavigationProperties=false možnosti.
Poznámka:
Tato možnost může zlepšit výkon aktualizace dat importovaných tabulek nebo tabulek režimu duálního úložiště, včetně procesu použití Editor Power Query změn okna. Nezlepší výkon interaktivního křížového filtrování tabulek režimu úložiště DirectQuery.
Řešení popisků prázdných voleb
Pokud zjistíte, že popisky voleb Dataverse jsou v Power BI prázdné, může to být proto, že popisky nebyly publikovány do koncového bodu TDS (Tabular Data Stream).
V tomto případě otevřete portál tvůrce služby Dataverse, přejděte do oblasti Řešení a pak vyberte Publikovat všechna vlastní nastavení. Proces publikování aktualizuje koncový bod TDS nejnovějšími metadaty a zpřístupní popisky možností pro Power BI.
Větší sémantické modely s využitím Azure Synapse Linku
Dataverse zahrnuje možnost synchronizovat tabulky se službou Azure Data Lake Storage (ADLS) a pak se k datům připojit prostřednictvím pracovního prostoru Azure Synapse. S minimálním úsilím můžete nastavit Azure Synapse Link tak, aby naplnil data dataverse do Azure Synapse a umožnili datovým týmům objevovat hlubší přehledy.
Azure Synapse Link umožňuje průběžnou replikaci dat a metadat z Dataverse do datového jezera. Poskytuje také integrovaný bezserverový fond SQL jako pohodlný zdroj dat pro dotazy Power BI.
Silné stránky tohoto přístupu jsou významné. Zákazníci získají možnost spouštět analytické úlohy, business intelligence a strojového učení napříč daty Dataverse pomocí různých pokročilých služeb. Mezi pokročilé služby patří Apache Spark, Power BI, Azure Data Factory, Azure Databricks a Azure Machine Učení.
Vytvoření Azure Synapse Linku pro službu Dataverse
Pokud chcete vytvořit Azure Synapse Link pro službu Dataverse, budete potřebovat následující požadavky.
- Přístup správce systému k prostředí Dataverse.
- Pro Azure Data Lake Storage:
- Pro použití s ADLS Gen2 musíte mít účet úložiště.
- Musíte mít přiřazený přístup vlastníka dat objektů blob služby Storage a Přispěvatel dat objektů blob úložiště k účtu úložiště. Další informace najdete v tématu Řízení přístupu na základě role (Azure RBAC).
- Účet úložiště musí povolit hierarchický obor názvů.
- Doporučuje se, aby účet úložiště používal geograficky redundantní úložiště jen pro čtení (RA-GRS).
- Pracovní prostor Synapse:
- Musíte mít přístup k pracovnímu prostoru Synapse a mít přiřazený přístup k Synapse Správa istrator. Další informace najdete v tématu Předdefinované role a obory Synapse RBAC.
- Pracovní prostor musí být ve stejné oblasti jako účet úložiště ADLS Gen2.
Nastavení zahrnuje přihlášení k Power Apps a připojení Dataverse k pracovnímu prostoru Azure Synapse. Prostředí podobné průvodci umožňuje vytvořit nový odkaz výběrem účtu úložiště a tabulek k exportu. Azure Synapse Link pak zkopíruje data do úložiště ADLS Gen2 a automaticky vytvoří zobrazení v integrovaném bezserverovém fondu SQL Azure Synapse. Pak se k těmto zobrazením můžete připojit a vytvořit model Power BI.
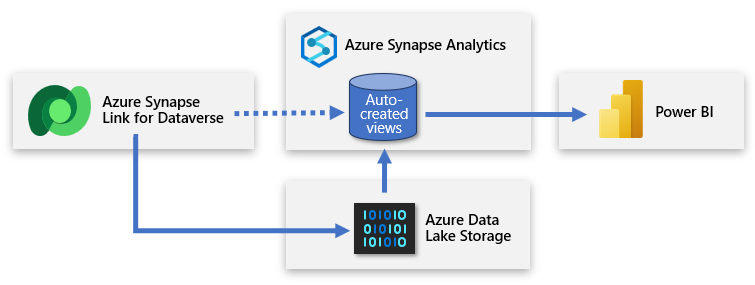
Tip
Kompletní dokumentaci k vytváření, správě a monitorování služby Azure Synapse Link najdete v tématu Vytvoření azure Synapse Linku pro službu Dataverse s pracovním prostorem Azure Synapse.
Vytvoření druhé bezserverové databáze SQL
Můžete vytvořit druhou bezserverovou databázi SQL a použít ji k přidání vlastních zobrazení sestav. Díky tomu můžete tvůrci Power BI představit zjednodušenou sadu dat, která jim umožní vytvořit model založený na užitečných a relevantních datech. Nová bezserverová databáze SQL se stane primárním zdrojovým připojením tvůrce a přátelskou reprezentací dat zdrojových z datového jezera.
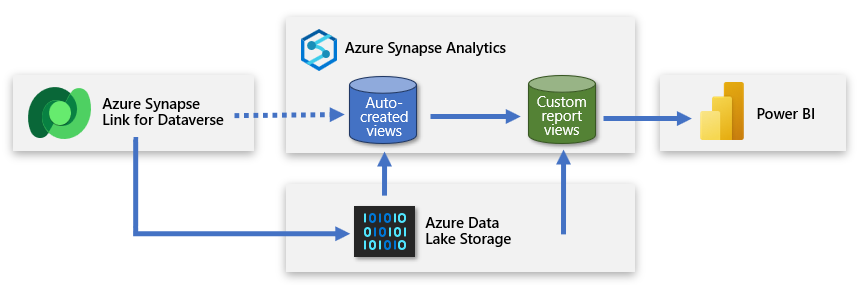
Tento přístup poskytuje data do Power BI, která jsou zaměřená, rozšířená a filtrovaná.
Bezserverovou databázi SQL můžete vytvořit v pracovním prostoru Azure Synapse pomocí nástroje Azure Synapse Studio. Jako typ databáze SQL vyberte bezserverový typ a zadejte název databáze. Power Query se může k této databázi připojit připojením ke koncovému bodu SQL pracovního prostoru.
Vytváření vlastních zobrazení
Můžete vytvořit vlastní zobrazení, která zabalí dotazy bezserverového fondu SQL. Tato zobrazení budou sloužit jako jednoduché a čisté zdroje dat, ke kterým se Power BI připojuje. Zobrazení by měla:
- Zahrnout popisky přidružené k polím výběru.
- Zmenšete složitost zahrnutím jenom sloupců požadovaných pro modelování dat.
- Vyfiltrujte nepotřebné řádky, například neaktivní záznamy.
Podívejte se na následující zobrazení, které načítá data kampaní.
CREATE VIEW [VW_Campaign]
AS
SELECT
[base].[campaignid] AS [CampaignID]
[base].[name] AS [Campaign],
[campaign_status].[LocalizedLabel] AS [Status],
[campaign_typecode].[LocalizedLabel] AS [Type Code]
FROM
[<MySynapseLinkDB>].[dbo].[campaign] AS [base]
LEFT OUTER JOIN [<MySynapseLinkDB>].[dbo].[OptionsetMetadata] AS [campaign_typecode]
ON [base].[typecode] = [campaign_typecode].[option]
AND [campaign_typecode].[LocalizedLabelLanguageCode] = 1033
AND [campaign_typecode].[EntityName] = 'campaign'
AND [campaign_typecode].[OptionSetName] = 'typecode'
LEFT OUTER JOIN [<MySynapseLinkDB>].[dbo].[StatusMetadata] AS [campaign_status]
ON [base].[statuscode] = [campaign_Status].[status]
AND [campaign_status].[LocalizedLabelLanguageCode] = 1033
AND [campaign_status].[EntityName] = 'campaign'
WHERE
[base].[statecode] = 0;
Všimněte si, že zobrazení obsahuje pouze čtyři sloupce, přičemž každý alias má popisný název. K dispozici je také WHERE klauzule, která vrátí pouze nezbytné řádky, v tomto případě aktivní kampaně. Zobrazení také dotazuje tabulku kampaně, která je připojená k tabulkám OptionsetMetadata a StatusMetadata , které načítají popisky voleb.
Tip
Další informace o tom, jak načíst metadata, najdete v tématu Popisky voleb accessu přímo z Azure Synapse Linku pro Dataverse.
Dotazování příslušných tabulek
Azure Synapse Link pro Dataverse zajišťuje, že se data průběžně synchronizují s daty v datovém jezeře. V případě aktivity s vysokým využitím můžou souběžné zápisy a čtení vytvářet zámky, které způsobují selhání dotazů. Kvůli zajištění spolehlivosti při načítání dat se v Azure Synapse synchronizují dvě verze dat tabulky.
- Data téměř v reálném čase: Poskytuje kopii dat synchronizovaných z Dataverse prostřednictvím Azure Synapse Linku efektivním způsobem tím, že zjistí, která data se od počátečního extrahování nebo poslední synchronizace změnila.
- Data snímku: Poskytuje kopii dat jen pro čtení téměř v reálném čase, která se aktualizují v pravidelných intervalech (v tomto případě každou hodinu). Názvy tabulek dat snímků mají _partitioned připojeny k jejich názvu.
Pokud předpokládáte, že se současně spustí velký objem operací čtení a zápisu, načtěte data z tabulek snímků, abyste se vyhnuli selháním dotazů.
Další informace najdete v tématu Přístup k datům téměř v reálném čase a datům snímků jen pro čtení.
Připojení do Synapse Analytics
Pokud chcete dotazovat bezserverový fond SQL Azure Synapse, budete potřebovat jeho koncový bod SQL pracovního prostoru. Koncový bod můžete načíst ze sady Synapse Studio otevřením vlastností bezserverového fondu SQL.
V Power BI Desktopu se můžete připojit k Azure Synapse pomocí konektoru SQL služby Azure Synapse Analytics. Po zobrazení výzvy k zadání serveru zadejte koncový bod SQL pracovního prostoru.
Důležité informace o DirectQuery
Při použití režimu úložiště DirectQuery může vaše požadavky vyřešit mnoho případů použití. Použití DirectQuery ale může negativně ovlivnit výkon sestav Power BI. Sestava, která používá připojení DirectQuery k Dataverse, nebude tak rychlá jako sestava, která používá model importu. Obecně platí, že pokud je to možné, měli byste data importovat do Power BI.
Při práci s DirectQuery doporučujeme zvážit témata v této části.
Další informace o určení, kdy pracovat s režimem úložiště DirectQuery, najdete v tématu Volba architektury modelu Power BI.
Použití tabulek dimenzí v režimu duálního úložiště
Tabulka režimu duálního úložiště je nastavená tak, aby používala režimy úložiště importu i DirectQuery. Power BI v době dotazu určuje nejúčinnější režim, který se má použít. Kdykoli je to možné, Power BI se pokusí vyhovět dotazům pomocí importovaných dat, protože je rychlejší.
Pokud je to vhodné, měli byste zvážit nastavení tabulek dimenzí na duální režim úložiště. Díky tomu se vizuály průřezů a seznamy karet filtru, které jsou často založené na sloupcích tabulky dimenzí, vykreslují rychleji, protože se budou dotazovat z importovaných dat.
Důležité
Pokud tabulka dimenzí potřebuje dědit model zabezpečení Dataverse, není vhodné použít režim duálního úložiště.
Tabulky faktů, které obvykle ukládají velké objemy dat, by měly zůstat jako tabulky režimu úložiště DirectQuery. Filtrují se podle souvisejících tabulek dimenzí v režimu duálního úložiště, které se dají spojit s tabulkou faktů, aby se dosáhlo efektivního filtrování a seskupování.
Zvažte následující návrh datového modelu. Tři tabulky dimenzí, Vlastník, Účet a Kampaň mají pruhované horní ohraničení, což znamená, že jsou nastavené na duální režim úložiště.
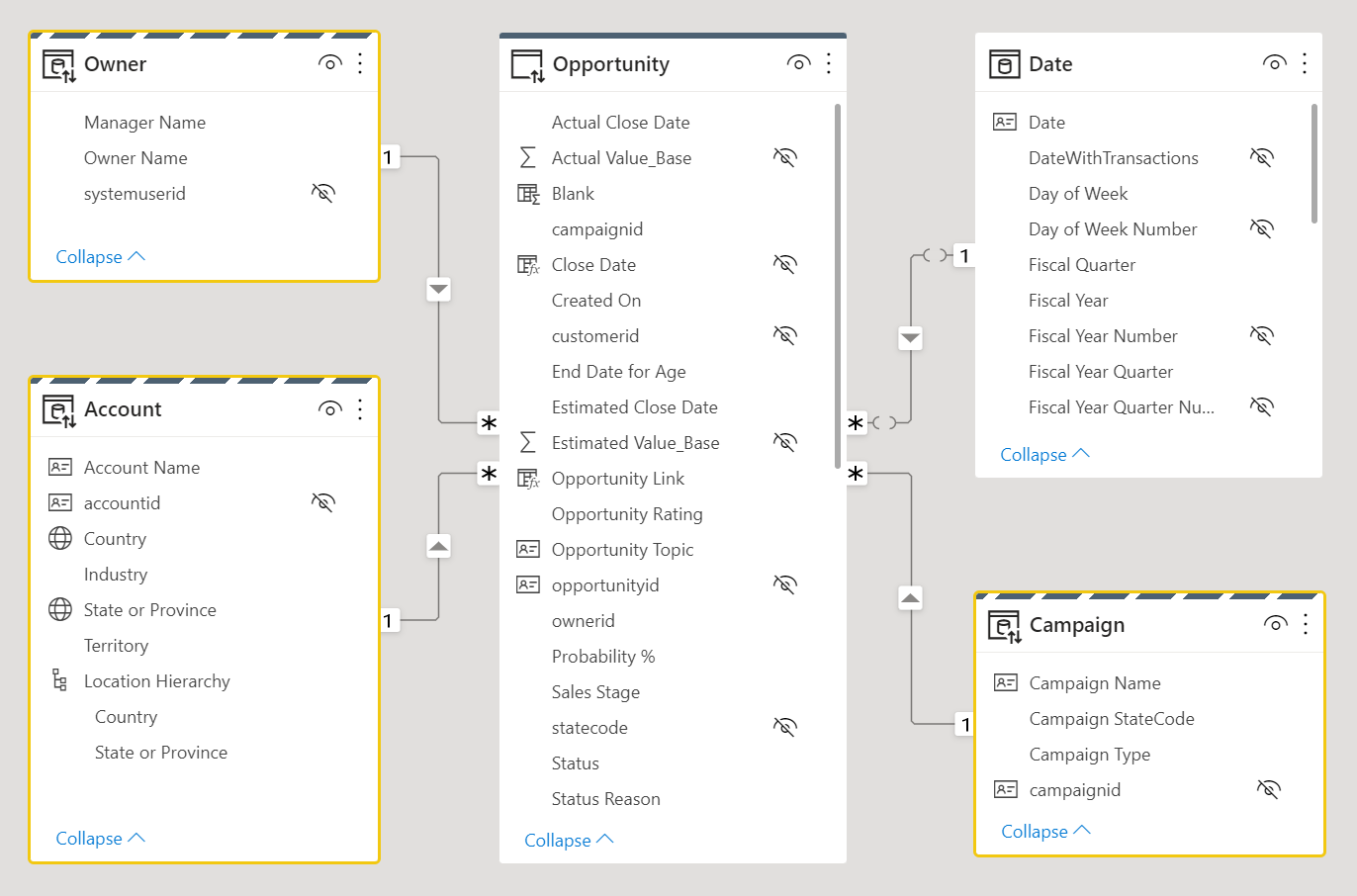
Další informace o režimech úložiště tabulek, včetně duálního úložiště, najdete v tématu Správa režimu úložiště v Power BI Desktopu.
Povolení jednoduchého přihlášení
Když publikujete model DirectQuery do služba Power BI, můžete použít nastavení sémantického modelu k povolení jednotného přihlašování (SSO) pomocí Microsoft Entra ID (dříve označovaného jako Azure Active Directory) OAuth2 pro uživatele sestavy. Tuto možnost byste měli povolit, když se dotazy Dataverse musí spouštět v kontextu zabezpečení uživatele sestavy.
Pokud je povolená možnost jednotného přihlašování, Power BI odešle uživateli sestavy ověřené přihlašovací údaje Microsoft Entra v dotazech do Služby Dataverse. Tato možnost umožňuje Power BI respektovat nastavení zabezpečení, která jsou nastavená ve zdroji dat.
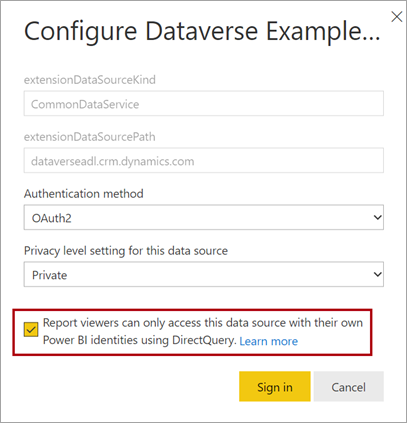
Další informace najdete v tématu Jednotné přihlašování (SSO) pro zdroje DirectQuery.
Replikace filtrů My v Power Query
Když používáte Microsoft Dynamics 365 Customer Engagement (CE) a modelem řízené Power Apps založené na službě Dataverse, můžete vytvořit zobrazení, která zobrazují jenom záznamy, ve kterých se pole uživatelského jména, například Vlastník, rovná aktuálnímu uživateli. Můžete například vytvořit zobrazení s názvem Moje otevřené příležitosti, Moje aktivní případy a další.
Podívejte se na příklad, jak zobrazení Dynamics 365 My Active Accounts obsahuje filtr, ve kterém se vlastník rovná aktuálnímu uživateli.
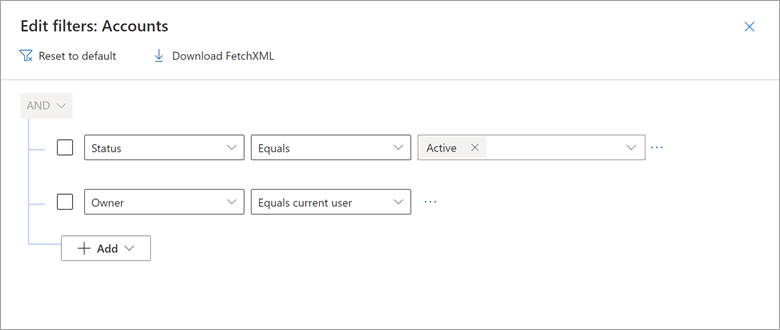
Tento výsledek můžete reprodukovat v Power Query pomocí nativního dotazu, který token vloží CURRENT_USER .
Podívejte se na následující příklad, který ukazuje nativní dotaz, který vrací účty pro aktuálního uživatele. WHERE V klauzuli si všimněte, že sloupec ownerid je filtrován tokenemCURRENT_USER.
let
Source = CommonDataService.Database("demo.crm.dynamics.com", [CreateNavigationProperties=false],
dbo_account = Value.NativeQuery(Source, "
SELECT
accountid, accountnumber, ownerid, address1_city, address1_stateorprovince, address1_country
FROM account
WHERE statecode = 0
AND ownerid = CURRENT_USER
", null, [EnableFolding]=true])
in
dbo_account
Když model publikujete do služba Power BI, musíte povolit jednotné přihlašování (SSO), aby Služba Power BI odeslala ověřené přihlašovací údaje uživatele sestavy do Služby Dataverse.
Vytvoření doplňkových modelů importu
Můžete vytvořit model DirectQuery, který vynucuje oprávnění Dataverse s vědomím , že výkon bude pomalý. Tento model pak můžete doplnit o modely importu, které cílí na konkrétní předměty nebo cílové skupiny, které by mohly vynutit oprávnění zabezpečení na úrovni řádků.
Model importu může například poskytnout přístup ke všem datům Dataverse, ale nevynucuje žádná oprávnění. Tento model by byl vhodný pro vedoucí pracovníky, kteří už mají přístup ke všem datům Dataverse.
Jako další příklad, když Dataverse vynucuje oprávnění založená na rolích podle prodejní oblasti, můžete vytvořit jeden model importu a replikovat tato oprávnění pomocí zabezpečení na úrovni řádků. Případně můžete vytvořit model pro každou prodejní oblast. Pak můžete těmto modelům udělit oprávnění ke čtení (sémantické modely) prodejcům každé oblasti. K usnadnění vytváření těchto regionálních modelů můžete použít parametry a šablony sestav. Další informace najdete v tématu Vytváření a používání šablon sestav v Power BI Desktopu.
Související obsah
Další informace týkající se tohoto článku najdete v následujících zdrojích informací.
Váš názor
Připravujeme: V průběhu roku 2024 budeme postupně vyřazovat problémy z GitHub coby mechanismus zpětné vazby pro obsah a nahrazovat ho novým systémem zpětné vazby. Další informace naleznete v tématu: https://aka.ms/ContentUserFeedback.
Odeslat a zobrazit názory pro