Pipelines und Aktivitäten in Azure Data Factory und Azure Synapse Analytics
GILT FÜR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Testen Sie Data Factory in Microsoft Fabric, eine All-in-One-Analyselösung für Unternehmen. Microsoft Fabric deckt alle Aufgaben ab, von der Datenverschiebung bis hin zu Data Science, Echtzeitanalysen, Business Intelligence und Berichterstellung. Erfahren Sie, wie Sie kostenlos eine neue Testversion starten!
Wichtig
Der Support für Azure Machine Learning-Studio (klassisch) wird am 31. August 2024 enden. Wir empfehlen, bis zu diesem Datum auf Azure Machine Learning umzustellen.
Ab dem 1. Dezember 2021 können Sie in Machine Learning-Studio (klassisch) keine neuen Ressourcen mehr erstellen (Arbeitsbereichs- und Webdienstplan). Sie können bereits vorhandene Experimente und Webdienste in Machine Learning-Studio (klassisch) noch bis zum 31. August 2024 weiterverwenden. Weitere Informationen finden Sie unter:
- Migrieren zu Azure Machine Learning von Machine Learning-Studio (klassisch)
- Was ist Azure Machine Learning?
Die Dokumentation zu Machine Learning-Studio (klassisch) wird eingestellt und möglicherweise in der Zukunft nicht mehr aktualisiert.
In diesem Artikel erhalten Sie Informationen zu Pipelines und Aktivitäten in Azure Data Factory und Azure Synapse Analytics und erfahren, wie diese zum Erstellen datengesteuerter lückenloser Workflows für Ihre Datenverschiebungs- und Datenverarbeitungsszenarien genutzt werden können.
Übersicht
Ein Data Factory- oder Synapse-Arbeitsbereich kann eine oder mehrere Pipelines haben. Bei einer Pipeline handelt es sich um eine logische Gruppierung von Aktivitäten, die zusammen eine Aufgabe bilden. Eine Pipeline kann beispielsweise eine Gruppe von Aktivitäten enthalten, die Protokolldaten erfassen und bereinigen, und anschließen einen Zuordnungsdatenfluss starten, um die Protokolldaten zu analysieren. Die Pipeline ermöglicht die Verwaltung der Aktivitäten als Gruppe, anstatt jede Aktivität separat zu verwalten. Die Aktivitäten müssen nicht einzeln bereitgestellt und geplant werden. Stattdessen können Sie die Pipeline bereitstellen und planen.
Die Aktivitäten in einer Pipeline definieren Aktionen, die Sie auf Ihre Daten anwenden. Sie können beispielsweise mit einer Kopieraktivität Daten aus einer SQL Server-Instanz in eine Instanz von Azure Blob Storage kopieren. Verwenden Sie anschließend eine Datenfluss- oder Databricks-Notebook-Aktivität, um Daten aus dem Blobspeicher zu verarbeiten und in einen Azure Synapse Analytics-Pool zu transformieren, auf dessen Grundlage Business Intelligence-Berichterstellungslösungen erstellt werden.
Azure Data Factory und Azure Synapse Analytics verfügen über drei Gruppen von Aktivitäten: Datenverschiebungsaktivitäten, Datentransformationsaktivitäten und Steuerungsaktivitäten. Eine Aktivität kann über null oder mehr Eingabedatasets verfügen und ein oder mehrere Ausgabedatasets erstellen. Das folgende Diagramm zeigt die Beziehung zwischen Pipeline, Aktivität und Dataset an:

Ein Eingabedataset entspricht der Eingabe für eine Aktivität in der Pipeline, und ein Ausgabedataset entspricht der Ausgabe für die Aktivität. Datasets bestimmen Daten in verschiedenen Datenspeichern, z.B. Tabellen, Dateien, Ordnern und Dokumenten. Nachdem Sie ein Dataset erstellt haben, können Sie es zusammen mit Aktivitäten in einer Pipeline verwenden. Bei einem Dataset kann es sich beispielsweise um ein Eingabe-/Ausgabedataset einer Kopieraktivität oder einer HDInsightHive-Aktivität handeln. Weitere Informationen über Datasets finden Sie im Artikel Datasets in Azure Data Factory.
Hinweis
Es gibt eine standardmäßige weiche Grenze von maximal 80 Aktivitäten pro Pipeline, einschließlich interner Aktivitäten für Container.
Datenverschiebungsaktivitäten
Die Kopieraktivität in Data Factory kopiert die Daten aus einem Quelldatenspeicher in einen Senkendatenspeicher. Data Factory unterstützt die in der Tabelle in diesem Abschnitt aufgeführten Datenspeicher. Daten aus beliebigen Quellen können in beliebige Senken geschrieben werden.
Weitere Informationen finden Sie im Artikel Übersicht über die Kopieraktivität.
Klicken Sie auf einen Datenspeicher, um zu erfahren, wie Daten in diesen/aus diesem Speicher kopiert werden.
Hinweis
Sie können jeden Connector, der als Vorschauversion gekennzeichnet ist, ausprobieren und uns anschließend Feedback dazu senden. Wenden Sie sich an den Azure-Support, wenn Sie in Ihrer Lösung eine Abhängigkeit von Connectors verwenden möchten, die sich in der Vorschauphase befinden.
Datentransformationsaktivitäten
Azure Data Factory und Azure Synapse Analytics unterstützen die folgenden Transformationsaktivitäten, die entweder einzeln oder mit einer anderen Aktivität verkettet hinzugefügt werden können.
Weitere Informationen finden Sie im Artikel Datentransformationsaktivitäten.
| Datentransformationsaktivität | Compute-Umgebung |
|---|---|
| Datenfluss | Von Azure Data Factory verwaltete Apache Spark-Cluster |
| Azure-Funktion | Azure-Funktionen |
| Hive | HDInsight [Hadoop] |
| Pig | HDInsight [Hadoop] |
| MapReduce | HDInsight [Hadoop] |
| Hadoop-Datenströme | HDInsight [Hadoop] |
| Spark | HDInsight [Hadoop] |
| Aktivitäten in ML Studio (klassisch): Batchausführung und Ressourcenaktualisierung | Azure VM |
| Gespeicherte Prozedur | Azure SQL, Azure Synapse Analytics oder SQL Server |
| U-SQL | Azure Data Lake Analytics |
| Benutzerdefinierte Aktivität | Azure Batch |
| Databricks-Notebook | Azure Databricks |
| Databricks-JAR-Aktivität | Azure Databricks |
| Databricks-Python-Aktivität | Azure Databricks |
| Synapse-Notebook-Aktivität | Azure Synapse Analytics |
Ablaufsteuerungsaktivitäten
Die folgenden Steuerungsablaufaktivitäten werden unterstützt:
| Steuerungsaktivität | BESCHREIBUNG |
|---|---|
| Variable anfügen | Ermöglicht das Hinzufügen eines Werts zu einer vorhandenen Arrayvariablen. |
| Pipeline ausführen | Mit der Aktivität „Pipeline ausführen“ kann eine Data Factory- oder Synapse-Pipeline eine andere Pipeline aufrufen. |
| Filter | Ermöglicht das Anwenden eines Filterausdrucks auf ein Eingabearray. |
| ForEach | Mit der ForEach-Aktivität wird eine wiederholte Ablaufsteuerung in Ihrer Pipeline definiert. Diese Aktivität wird verwendet, um eine Sammlung zu durchlaufen. Sie führt die angegebenen Aktivitäten in einer Schleife aus. Die Schleifenimplementierung dieser Aktivität ähnelt der Foreach-Schleifenstruktur in Programmiersprachen. |
| Abrufen von Metadaten | Die Aktivität „Metadaten abrufen“ kann zum Abrufen von Metadaten für alle Daten in einer Data Factory- oder Synapse-Pipeline verwendet werden. |
| Aktivität „If Condition“ | „If Condition“ kann zum Einrichten einer Verzweigung für Bedingungen verwendet werden, die als TRUE oder FALSE ausgewertet werden. Die Aktivität „If Condition“ bietet die gleiche Funktionalität wie eine If-Anweisung in Programmiersprachen. Sie wertet eine Aktivitätengruppe aus, wenn die Bedingung als true ausgewertet wird, und eine weitere Aktivitätengruppe, wenn die Bedingung als false. ausgewertet wird. |
| Lookup-Aktivität | Mit der Lookup-Aktivität können Sie einen Datensatz/Tabellennamen/Wert in einer externen Quelle lesen oder suchen. Auf die Ausgabe kann durch nachfolgende Aktivitäten verwiesen werden. |
| Variable festlegen | Ermöglicht das Festlegen des Werts einer vorhandenen Variablen. |
| Until-Aktivität | Es wird eine „Wiederholen bis“-Schleife implementiert, die der Struktur einer Do-Until-Schleife in Programmiersprachen ähnelt. Sie führt eine Reihe von Aktivitäten in einer Schleife aus, bis die der Aktivität zugeordnete Bedingung als „true“ ausgewertet wird. Sie können einen Timeoutwert für die Until-Aktivität angeben. |
| Aktivität „Prüfung“ | Stellt sicher, dass die Ausführung einer Pipeline nur fortgesetzt wird, wenn ein Referenzdataset vorhanden ist, ein bestimmtes Kriterium erfüllt ist oder ein Timeout erreicht wurde. |
| Aktivität „Warten“ | Wenn Sie eine Warteaktivität in einer Pipeline verwenden, wartet die Pipeline den angegebenen Zeitraum, bevor sie die Ausführung nachfolgender Aktivitäten fortsetzt. |
| Webaktivität | Die Webaktivität kann verwendet werden, um einen benutzerdefinierten REST-Endpunkt aus einer Pipeline aufzurufen. Sie können Datasets und verknüpfte Dienste zur Verwendung und für den Zugriff durch die Aktivität übergeben. |
| Webhook-Aktivität | Die Webhook-Aktivität ermöglicht das Aufrufen eines Endpunkts und das Übergeben einer Rückruf-URL. Die Pipelineausführung wartet, bis der Rückruf aufgerufen wurde, bevor sie mit der nächsten Aktivität fortfährt. |
Erstellen einer Pipeline über die Benutzeroberfläche
Um eine neue Pipeline zu erstellen, navigieren Sie in Data Factory Studio zur Registerkarte „Erstellen“ (dargestellt durch das Stiftsymbol), klicken Sie dann auf das Pluszeichen, und wählen Sie im Menü „Pipeline“ und im Untermenü erneut „Pipeline“ aus.
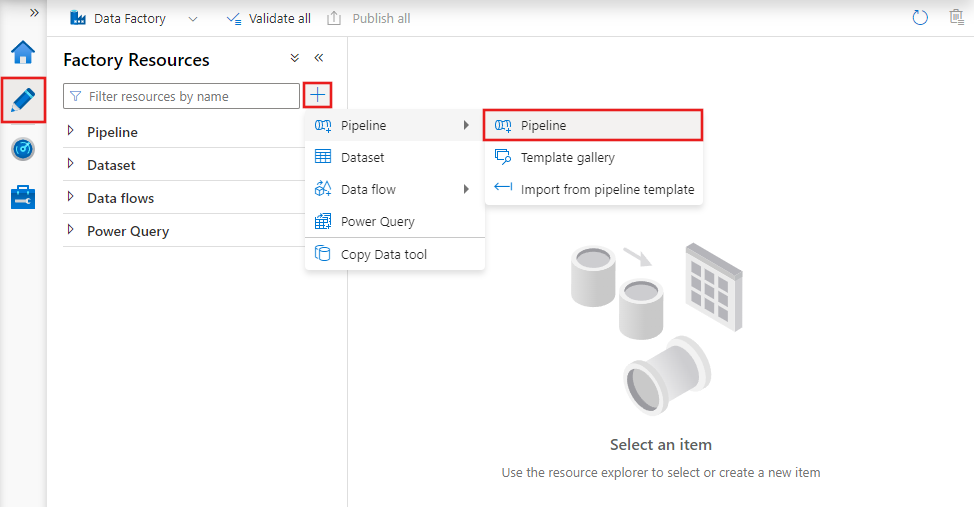
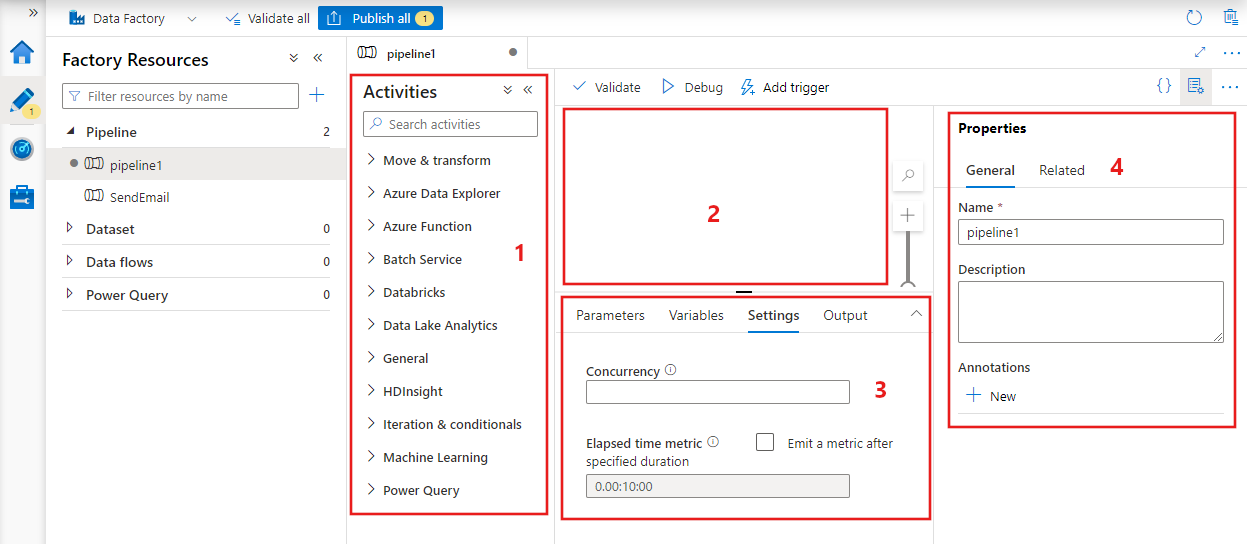
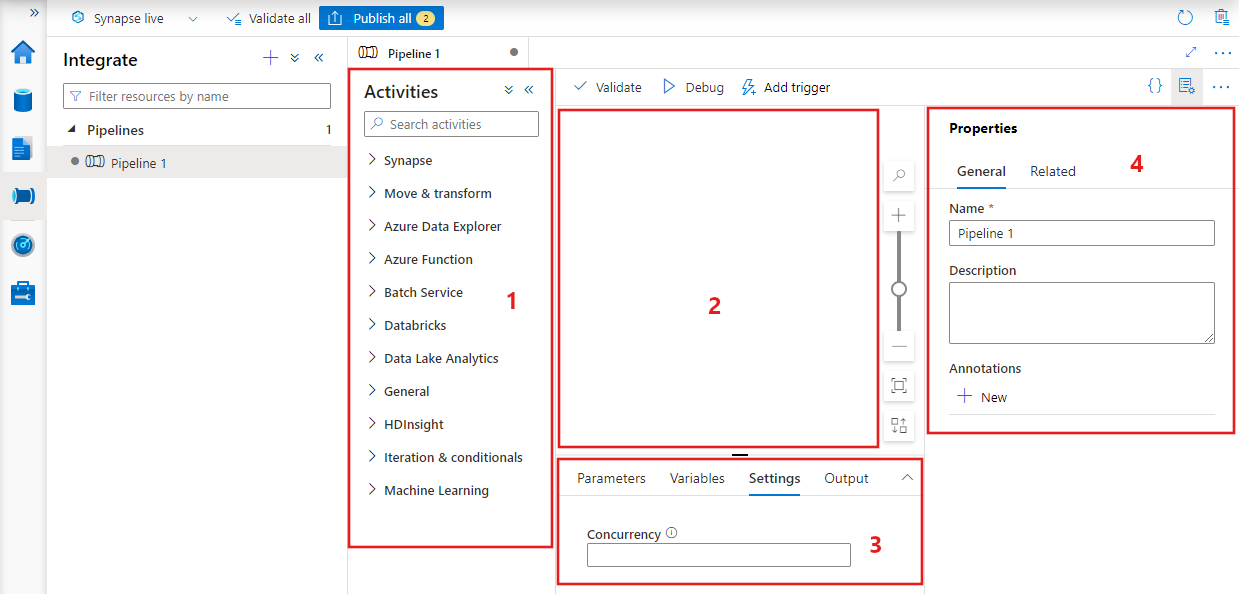
Data Factory zeigt den Pipeline-Editor an, der Folgendes bereitstellt:
- Alle Aktivitäten, die innerhalb der Pipeline verwendet werden können.
- Die Canvas des Pipeline-Editors, in der Aktivitäten angezeigt werden, wenn sie der Pipeline hinzugefügt werden.
- Der Bereich für die Pipelinekonfiguration, einschließlich Parametern, Variablen, allgemeinen Einstellungen und Ausgabe.
- Der Bereich für die Pipelineeigenschaften, in dem der Pipelinename, eine optionale Beschreibung und Anmerkungen konfiguriert werden können. In diesem Bereich werden auch alle zugehörigen Elemente der Pipeline innerhalb der Data Factory angezeigt.
Pipeline-JSON
Eine Pipeline wird wie folgt im JSON-Format definiert:
{
"name": "PipelineName",
"properties":
{
"description": "pipeline description",
"activities":
[
],
"parameters": {
},
"concurrency": <your max pipeline concurrency>,
"annotations": [
]
}
}
| Tag | BESCHREIBUNG | Type | Erforderlich |
|---|---|---|---|
| name | Name der Pipeline. Geben Sie einen Namen an, der die Aktion darstellt, die die Pipeline durchführt.
|
String | Ja |
| description | Geben Sie den Text an, der beschreibt, wofür die Pipeline verwendet wird. | String | Nein |
| activities | Im Abschnitt activities kann mindestens eine Aktivität definiert werden. Weitere Informationen zum JSON-Element der Aktivitäten finden Sie im Abschnitt Aktivitäts-JSON. | Array | Ja |
| parameters | Im Abschnitt Parameter kann mindestens ein Parameter in der Pipeline definiert werden. Dadurch wird die Pipeline flexibel wiederverwendbar. | List | Nein |
| concurrency | Die maximal zulässige Anzahl paralleler Ausführungen für die Pipeline. Standardmäßig ist keine Obergrenze festgelegt. Bei Erreichen des Parallelitätslimits werden weitere Pipelineausführungen in die Warteschlange eingereiht, bis andere Pipelineausführungen abgeschlossen sind. | Number | Nein |
| annotations | Eine Liste mit Tags im Zusammenhang mit der Pipeline. | Array | Nein |
JSON-Definition der Aktivität
Im Abschnitt activities kann mindestens eine Aktivität definiert werden. Es gibt zwei Haupttypen von Aktivitäten: Ausführungs- und Steuerungsaktivitäten.
Ausführungsaktivitäten
Ausführungsaktivitäten beinhalten Datenverschiebungsaktivitäten und Datentransformationsaktivitäten. Sie besitzen auf oberster Ebene die folgende Struktur:
{
"name": "Execution Activity Name",
"description": "description",
"type": "<ActivityType>",
"typeProperties":
{
},
"linkedServiceName": "MyLinkedService",
"policy":
{
},
"dependsOn":
{
}
}
In der folgenden Tabelle werden Eigenschaften in der JSON-Definition der Aktivität beschrieben:
| Tag | BESCHREIBUNG | Erforderlich |
|---|---|---|
| name | Der Name der Aktivität. Geben Sie einen Namen an, der die Aktion darstellt, die die Aktivität durchführt.
|
Ja |
| description | Ein Text, der beschreibt, wofür die Aktivität verwendet wird. | Ja |
| type | Der Typ der Aktivität. Die verschiedenen Aktivitätstypen finden Sie in den Abschnitten Datenverschiebungsaktivitäten, Datentransformationsaktivitäten und Steuerungsaktivitäten. | Ja |
| linkedServiceName | Name des verknüpften Diensts, der von der Aktivität verwendet wird. Für eine Aktivität kann es erforderlich sein, den verknüpften Dienst anzugeben, der mit der erforderlichen Computeumgebung verknüpft ist. |
„Ja“ für HDInsight-Aktivitäten, ML Studio-Aktivitäten (klassisch) für die Batchbewertung und Aktivitäten vom Typ „Gespeicherte Prozedur“. „Nein“ für alle übrigen |
| typeProperties | Eigenschaften im Abschnitt „typeProperties“ sind abhängig vom jeweiligen Typ der Aktivität. Um Typeigenschaften für eine Aktivität anzuzeigen, klicken Sie auf die Links zur Aktivität im vorhergehenden Abschnitt. | Nein |
| policy | Richtlinien, die das Laufzeitverhalten der Aktivität beeinflussen. Diese Eigenschaft enthält ein Zeitlimit- und Wiederholungsverhalten. Falls kein Wert angegeben wird, werden die Standardwerte verwendet. Weitere Informationen finden Sie im Abschnitt Aktivitätsrichtlinie. | Nein |
| dependsOn | Diese Eigenschaft wird zur Definition von Aktivitätsabhängigkeiten und von Abhängigkeiten zwischen nachfolgenden und vorherigen Aktivitäten verwendet. Weitere Informationen finden Sie im Abschnitt Aktivitätsabhängigkeit. | Nein |
Aktivitätsrichtlinie
Richtlinien beeinflussen das Laufzeitverhalten einer Aktivität und stellen Konfigurationsoptionen bereit. Aktivitätsrichtlinien sind nur für Ausführungsaktivitäten verfügbar.
JSON-Definition der Aktivitätsrichtlinien
{
"name": "MyPipelineName",
"properties": {
"activities": [
{
"name": "MyCopyBlobtoSqlActivity",
"type": "Copy",
"typeProperties": {
...
},
"policy": {
"timeout": "00:10:00",
"retry": 1,
"retryIntervalInSeconds": 60,
"secureOutput": true
}
}
],
"parameters": {
...
}
}
}
| JSON-Name | BESCHREIBUNG | Zulässige Werte | Erforderlich |
|---|---|---|---|
| timeout | Gibt das Zeitlimit für die Ausführung der Aktivität an. | Timespan | Nein. Das Standardtimeout beträgt 12 Stunden, mindestens 10 Minuten. |
| retry | Maximale Anzahl der Wiederholungsversuche. | Integer | Nein. Der Standardwert ist 0. |
| retryIntervalInSeconds | Verzögerung zwischen den Wiederholungsversuchen in Sekunden. | Integer | Nein. Der Standardwert ist 30 Sekunden. |
| secureOutput | Bei Festlegung auf „true“ wird die Ausgabe der Aktivität als sicher betrachtet und nicht zur Überwachung protokolliert. | Boolean | Nein. Der Standardwert ist "false". |
Steuerungsaktivität
Steuerungsaktivitäten besitzen auf oberster Ebene die folgende Struktur:
{
"name": "Control Activity Name",
"description": "description",
"type": "<ActivityType>",
"typeProperties":
{
},
"dependsOn":
{
}
}
| Tag | BESCHREIBUNG | Erforderlich |
|---|---|---|
| name | Der Name der Aktivität. Geben Sie einen Namen an, der die Aktion darstellt, die die Aktivität durchführt.
|
Ja |
| description | Ein Text, der beschreibt, wofür die Aktivität verwendet wird. | Ja |
| type | Der Typ der Aktivität. Die verschiedenen Aktivitätstypen finden Sie in den Abschnitten Datenverschiebungsaktivitäten, Datentransformationsaktivitäten und Steuerungsaktivitäten. | Ja |
| typeProperties | Eigenschaften im Abschnitt „typeProperties“ sind abhängig vom jeweiligen Typ der Aktivität. Um Typeigenschaften für eine Aktivität anzuzeigen, klicken Sie auf die Links zur Aktivität im vorhergehenden Abschnitt. | Nein |
| dependsOn | Diese Eigenschaft wird zur Definition der Aktivitätsabhängigkeit und von Abhängigkeiten zwischen nachfolgenden und vorherigen Aktivitäten verwendet. Weitere Informationen finden Sie im Abschnitt Aktivitätsabhängigkeit. | Nein |
Aktivitätsabhängigkeit
Mit der Aktivitätsabhängigkeit wird definiert, wie nachfolgende Aktivitäten von vorherigen Aktivitäten abhängen. Dabei wird bestimmt, bei welcher Bedingung mit der nächsten Aufgabe fortgefahren wird. Eine Aktivität kann mit unterschiedlichen Abhängigkeitsbedingungen von einer oder mehreren vorherigen Aktivitäten abhängen.
Die unterschiedlichen Abhängigkeitsbedingungen lauten: „Erfolgreich“, „Fehlgeschlagen“, „Übersprungen“ und „Abgeschlossen“.
Bei einer Pipeline mit Aktivität A -> Aktivität B lauten die möglichen Szenarios beispielsweise folgendermaßen:
- Die Abhängigkeitsbedingung von Aktivität B zu Aktivität A lautet Erfolgreich: Aktivität B wird nur ausgeführt, wenn Aktivität A den Endstatus „Erfolgreich“ aufweist.
- Die Abhängigkeitsbedingung von Aktivität B zu Aktivität A lautet Fehlgeschlagen: Aktivität B wird nur ausgeführt, wenn Aktivität A den Endstatus „Fehlgeschlagen“ aufweist.
- Die Abhängigkeitsbedingung von Aktivität B zu Aktivität A lautet Abgeschlossen: Aktivität B wird nur ausgeführt, wenn Aktivität A den Endstatus „Erfolgreich“ oder „Fehlgeschlagen“ aufweist.
- Die Abhängigkeitsbedingung von Aktivität B zu Aktivität A lautet Übersprungen: Aktivität B wird nur ausgeführt, wenn Aktivität A den Endstatus „Übersprungen“ aufweist. Die Bedingung „Übersprungen“ tritt im Szenario Aktivität X -> Aktivität Y -> Aktivität Z auf. Hier wird eine Aktivität nur ausgeführt, wenn die vorherige Aktivität erfolgreich war. Tritt bei Aktivität X ein Fehler auf, erhält Aktivität Y den Status „Übersprungen“, da sie nicht ausgeführt wird. Dementsprechend erhält auch Aktivität Z den Status „Übersprungen“.
Beispiel: Aktivität 2 hängt von der erfolgreich abgeschlossenen Aktivität 1 ab
{
"name": "PipelineName",
"properties":
{
"description": "pipeline description",
"activities": [
{
"name": "MyFirstActivity",
"type": "Copy",
"typeProperties": {
},
"linkedServiceName": {
}
},
{
"name": "MySecondActivity",
"type": "Copy",
"typeProperties": {
},
"linkedServiceName": {
},
"dependsOn": [
{
"activity": "MyFirstActivity",
"dependencyConditions": [
"Succeeded"
]
}
]
}
],
"parameters": {
}
}
}
Beispiel einer Kopierpipeline
In der folgenden Beispielpipeline gibt es im Abschnitt Copy in the Aktivitäten . In diesem Beispiel kopieren Sie mit der Kopieraktivität Daten aus Azure Blob Storage in eine Datenbank in Azure SQL-Datenbank.
{
"name": "CopyPipeline",
"properties": {
"description": "Copy data from a blob to Azure SQL table",
"activities": [
{
"name": "CopyFromBlobToSQL",
"type": "Copy",
"inputs": [
{
"name": "InputDataset"
}
],
"outputs": [
{
"name": "OutputDataset"
}
],
"typeProperties": {
"source": {
"type": "BlobSource"
},
"sink": {
"type": "SqlSink",
"writeBatchSize": 10000,
"writeBatchTimeout": "60:00:00"
}
},
"policy": {
"retry": 2,
"timeout": "01:00:00"
}
}
]
}
}
Beachten Sie folgende Punkte:
- Der Abschnitt „Activities“ enthält nur eine Aktivität, deren Typ auf Copy festgelegt ist.
- Die Eingabe für die Aktivität ist auf InputDataset und die Ausgabe für die Aktivität ist auf OutputDataset festgelegt. Informationen zum Definieren von Datasets im JSON-Format finden Sie im Artikel Datasets.
- Im Abschnitt typeProperties ist BlobSource als Quelltyp und SqlSink als Senkentyp angegeben. Klicken Sie im Abschnitt Datenverschiebungsaktivitäten auf den Datenspeicher, den Sie als Quelle oder Senke verwenden möchten, um weitere Informationen zum Verschieben von Daten in den/aus dem Datenspeicher zu erhalten.
Eine ausführliche exemplarische Vorgehensweise zum Erstellen dieser Pipeline finden Sie unter Schnellstart: Erstellen einer Data Factory.
Beispiel einer Transformationspipeline
In der folgenden Beispielpipeline gibt es im Abschnitt HDInsightHive in the Aktivitäten . In diesem Beispiel transformiert die HDInsight Hive-Aktivität Daten aus Azure Blob Storage durch Anwenden einer Hive-Skriptdatei auf einen Azure HDInsight Hadoop-Cluster.
{
"name": "TransformPipeline",
"properties": {
"description": "My first Azure Data Factory pipeline",
"activities": [
{
"type": "HDInsightHive",
"typeProperties": {
"scriptPath": "adfgetstarted/script/partitionweblogs.hql",
"scriptLinkedService": "AzureStorageLinkedService",
"defines": {
"inputtable": "wasb://adfgetstarted@<storageaccountname>.blob.core.windows.net/inputdata",
"partitionedtable": "wasb://adfgetstarted@<storageaccountname>.blob.core.windows.net/partitioneddata"
}
},
"inputs": [
{
"name": "AzureBlobInput"
}
],
"outputs": [
{
"name": "AzureBlobOutput"
}
],
"policy": {
"retry": 3
},
"name": "RunSampleHiveActivity",
"linkedServiceName": "HDInsightOnDemandLinkedService"
}
]
}
}
Beachten Sie folgende Punkte:
- Der Abschnitt „Activities“ enthält nur eine Aktivität, deren Typ auf HDInsightHive festgelegt ist.
- Die Hive-Skriptdatei partitionweblogs.hql ist im Azure Storage-Konto (das durch den scriptLinkedService-Dienst namens „AzureStorageLinkedService“ angegeben ist) und im Skriptordner im Container
adfgetstartedgespeichert. - Der Abschnitt
defineswird zum Angeben der Laufzeiteinstellungen verwendet, die als Hive-Konfigurationswerte (z.B. ${hiveconf:inputtable},${hiveconf:partitionedtable}) an das Hive-Skript übergeben werden.
Der Abschnitt typeProperties ist für jede Transformation unterschiedlich. Um weitere Informationen zu Typeigenschaften zu erhalten, die für eine Transformationsaktivität unterstützt werden, klicken Sie bei den Datentransformationsaktivitäten auf die Transformationsaktivität.
Eine ausführliche exemplarische Vorgehensweise zum Erstellen dieser Pipeline finden Sie im Tutorial: Transformieren von Daten mit Spark.
Mehrere Aktivitäten in einer Pipeline
Die vorherigen beiden Beispielpipelines enthalten nur jeweils eine Aktivität. Sie können mehrere Aktivitäten in einer Pipeline verwenden. Bei mehreren Aktivitäten in einer Pipeline, bei denen die nachfolgenden Aktivitäten nicht von den vorherigen abhängig sind, können die Aktivitäten parallel ausgeführt werden.
Sie können zwei Aktivitäten mithilfe der Aktivitätsabhängigkeit verketten, die definiert, wie nachfolgende Aktivitäten von vorherigen Aktivitäten abhängen. Dabei wird bestimmt, bei welcher Bedingung mit der nächsten Aufgabe fortgefahren wird. Eine Aktivität kann mit unterschiedlichen Abhängigkeitsbedingungen von einer oder mehreren vorherigen Aktivitäten abhängen.
Planen von Pipelines
Pipelines werden von Triggern geplant. Es gibt verschiedene Arten von Triggern (Planer-Trigger, bei denen Pipelines nach einem Zeitplan ausgelöst werden, sowie den manuellen Trigger, bei dem Pipelines bei Bedarf ausgelöst werden). Weitere Informationen zu Triggern finden Sie im Artikel Pipelineausführung und -trigger.
Damit der Trigger die Ausführung der Pipeline startet, müssen Sie in die Triggerdefinition einen Pipelineverweis auf die jeweilige Pipeline einschließen. Zwischen Pipelines und Triggern besteht eine n:m-Beziehung. Mehrere Trigger können eine einzelne Pipeline starten, und ein einzelner Trigger kann mehrere Pipelines starten. Sobald der Trigger definiert wurde, müssen Sie ihn starten, damit er mit dem Auslösen der Pipeline beginnen kann. Weitere Informationen zu Triggern finden Sie im Artikel Pipelineausführung und -trigger.
Angenommen, Sie verfügen über den Scheduler-Trigger "Trigger A", mit dem ich meine Pipeline "MyCopyPipeline" starten möchte. Sie definieren den Trigger, wie im folgenden Beispiel gezeigt:
Definition Trigger A
{
"name": "TriggerA",
"properties": {
"type": "ScheduleTrigger",
"typeProperties": {
...
}
},
"pipeline": {
"pipelineReference": {
"type": "PipelineReference",
"referenceName": "MyCopyPipeline"
},
"parameters": {
"copySourceName": "FileSource"
}
}
}
}