Reliability in Azure Functions
This article describes reliability support in Azure Functions, and covers both intra-regional resiliency with availability zones and cross-region recovery and business continuity. For a more detailed overview of reliability principles in Azure, see Azure reliability.
Availability zone support for Azure Functions is available on both Premium (Elastic Premium) and Dedicated (App Service) plans. This article focuses on zone redundancy support for Premium plans. For zone redundancy on Dedicated plans, see Migrate App Service to availability zone support.
Availability zones are physically separate groups of datacenters within each Azure region. When one zone fails, services can fail over to one of the remaining zones.
For more information on availability zones in Azure, see What are availability zones?
Azure Functions supports a zone-redundant deployment.
When you configure Functions as zone redundant, the platform automatically spreads the function app instances across three zones in the selected region.
Instance spreading with a zone-redundant deployment is determined inside the following rules, even as the app scales in and out:
- The minimum function app instance count is three.
- When you specify a capacity larger than three, the instances are spread evenly only when the capacity is a multiple of 3.
- For a capacity value more than 3*N, extra instances are spread across the remaining one or two zones.
Important
Azure Functions can run on the Azure App Service platform. In the App Service platform, plans that host Premium plan function apps are referred to as Elastic Premium plans, with SKU names like EP1. If you choose to run your function app on a Premium plan, make sure to create a plan with an SKU name that starts with "E", such as EP1. App Service plan SKU names that start with "P", such as P1V2 (Premium V2 Small plan), are actually Dedicated hosting plans. Because they are Dedicated and not Elastic Premium, plans with SKU names starting with "P" won't scale dynamically and may increase your costs.
Zone-redundant Premium plans are available in the following regions:
| Americas | Europe | Middle East | Africa | Asia Pacific |
|---|---|---|---|---|
| Brazil South | France Central | Israel Central | South Africa North | Australia East |
| Canada Central | Germany West Central | Qatar Central | Central India | |
| Central US | Italy North | UAE North | China North 3 | |
| East US | North Europe | East Asia | ||
| East US 2 | Norway East | Japan East | ||
| South Central US | Sweden Central | Southeast Asia | ||
| West US 2 | Switzerland North | |||
| West US 3 | UK South | |||
| West Europe |
Availability zone support is a property of the Premium plan. The following are the current requirements/limitations for enabling availability zones:
- You can only enable availability zones when creating a Premium plan for your function app. You can't convert an existing Premium plan to use availability zones.
- You must use a zone redundant storage account (ZRS) for your function app's storage account. If you use a different type of storage account, Functions can show unexpected behavior during a zonal outage.
- Both Windows and Linux are supported.
- Must be hosted on an Elastic Premium or Dedicated hosting plan. To learn how to use zone redundancy with a Dedicated plan, see Migrate App Service to availability zone support.
- Availability zone support isn't currently available for function apps on Consumption plans.
- Function apps hosted on a Premium plan must have a minimum always ready instances count of three.
- The platform enforces this minimum count behind the scenes if you specify an instance count fewer than three.
- If you aren't using Premium plan or a scale unit that supports availability zones, are in an unsupported region, or are unsure, see the migration guidance.
There's no extra cost associated with enabling availability zones. Pricing for a zone redundant Premium App Service plan is the same as a single zone Premium plan. For each App Service plan you use, you're charged based on the SKU you choose, the capacity you specify, and any instances you scale to based on your autoscale criteria. If you enable availability zones but specify a capacity less than three for an App Service plan, the platform enforces a minimum instance count of three for that App Service plan and charges you for those three instances.
There are currently two ways to deploy a zone-redundant Premium plan and function app. You can use either the Azure portal or an ARM template.
In the Azure portal, go to the Create Function App page. For more information about creating a function app in the portal, see Create a function app.
Select Functions Premium and then select the Select button. This article describes how to create a zone redundant app in a Premium plan. Zone redundancy isn't currently available in Consumption plans. For information on zone redundancy on app service plans, see Reliability in Azure App Service.
On the Create Function App (Functions Premium) page, on the Basics tab, enter the settings for your function app. Pay special attention to the settings in the following table (also highlighted in the following screenshot), which have specific requirements for zone redundancy.
Setting Suggested value Notes for zone redundancy Region Your preferred supported region The region under which the new function app is created. You must pick a region that supports availability zones. See the region availability list. Pricing plan One of the Elastic Premium plans. For more information, see Available instance SKUs. This article describes how to create a zone redundant app in a Premium plan. Zone redundancy isn't currently available in Consumption plans. For information on zone redundancy on App Service plans, see Reliability in Azure App Service. Zone redundancy Enabled This setting specifies whether your app is zone redundant. You won't be able to select Enabledunless you have chosen a region that supports zone redundancy, as described previously.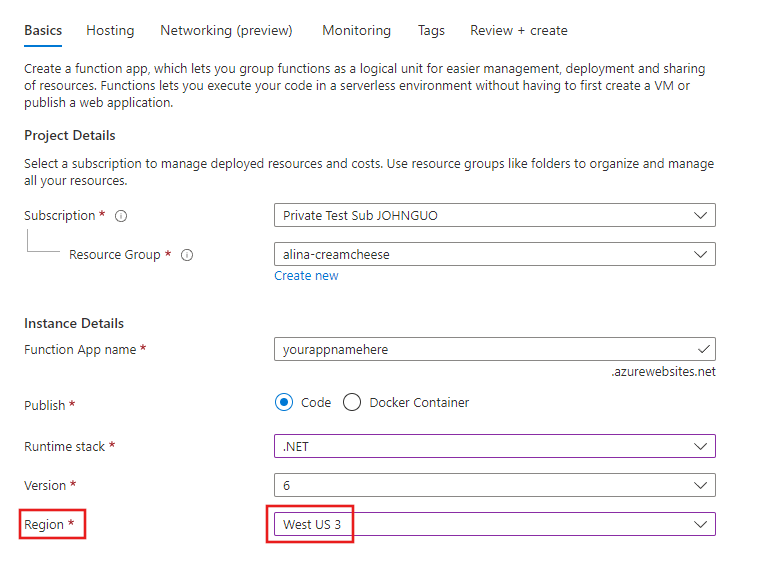
On the Storage tab, enter the settings for your function app storage account. Pay special attention to the setting in the following table, which has specific requirements for zone redundancy.
Setting Suggested value Notes for zone redundancy Storage account A zone-redundant storage account As described in the prerequisites section, we strongly recommend using a zone-redundant storage account for your zone-redundant function app. For the rest of the function app creation process, create your function app as normal. There are no settings in the rest of the creation process that affect zone redundancy.
After the zone-redundant plan is created and deployed, any function app hosted on your new plan is considered zone-redundant.
Azure Function Apps currently doesn't support in-place migration of existing function apps instances. For information on how to migrate the public multitenant Premium plan from non-availability zone to availability zone support, see Migrate App Service to availability zone support.
All available function app instances of zone-redundant function apps are enabled and processing events. When a zone goes down, Functions detect lost instances and automatically attempts to find new replacement instances if needed. Elastic scale behavior still applies. However, in a zone-down scenario there's no guarantee that requests for additional instances can succeed, since back-filling lost instances occurs on a best-effort basis. Applications that are deployed in an availability zone enabled Premium plan continue to run even when other zones in the same region suffer an outage. However, it's possible that non-runtime behaviors could still be impacted from an outage in other availability zones. These impacted behaviors can include Premium plan scaling, application creation, application configuration, and application publishing. Zone redundancy for Premium plans only guarantees continued uptime for deployed applications.
When Functions allocates instances to a zone redundant Premium plan, it uses best effort zone balancing offered by the underlying Azure Virtual Machine Scale Sets. A Premium plan is considered balanced when each zone has either the same number of VMs (± 1 VM) in all of the other zones used by the Premium plan.
Disaster recovery (DR) refers to practices that organizations use to recover from high-impact events, such as natural disasters or failed deployments that result in downtime and data loss. Regardless of the cause, the best remedy for a disaster is a well-defined and tested DR plan and an application design that actively supports DR. Before you start creating your disaster recovery plan, see Recommendations for designing a disaster recovery strategy.
For DR, Microsoft uses the shared responsibility model. In this model, Microsoft ensures that the baseline infrastructure and platform services are available. However, many Azure services don't automatically replicate data or fall back from a failed region to cross-replicate to another enabled region. For those services, you're responsible for setting up a disaster recovery plan that works for your workload. Most services that run on Azure platform as a service (PaaS) offerings provide features and guidance to support DR. You can use service-specific features to support fast recovery to help develop your DR plan.
This section explains some of the strategies that you can use to deploy Functions to allow for disaster recovery.
For disaster recovery for Durable Functions, see Disaster recovery and geo-distribution in Azure Durable Functions.
Because there is no built-in redundancy available, functions run in a function app in a specific Azure region. To avoid loss of execution during outages, you can redundantly deploy the same functions to function apps in multiple regions. To learn more about multi-region deployments, see the guidance in Highly available multi-region web application.
When you run the same function code in multiple regions, there are two patterns to consider, active-active and active-passive.
With an active-active pattern, functions in both regions are actively running and processing events, either in a duplicate manner or in rotation. It's recommended that you use an active-active pattern in combination with Azure Front Door for your critical HTTP triggered functions, which can route and round-robin HTTP requests between functions running in multiple regions. Front door can also periodically check the health of each endpoint. When a function in one region stops responding to health checks, Azure Front Door takes it out of rotation, and only forwards traffic to the remaining healthy functions.
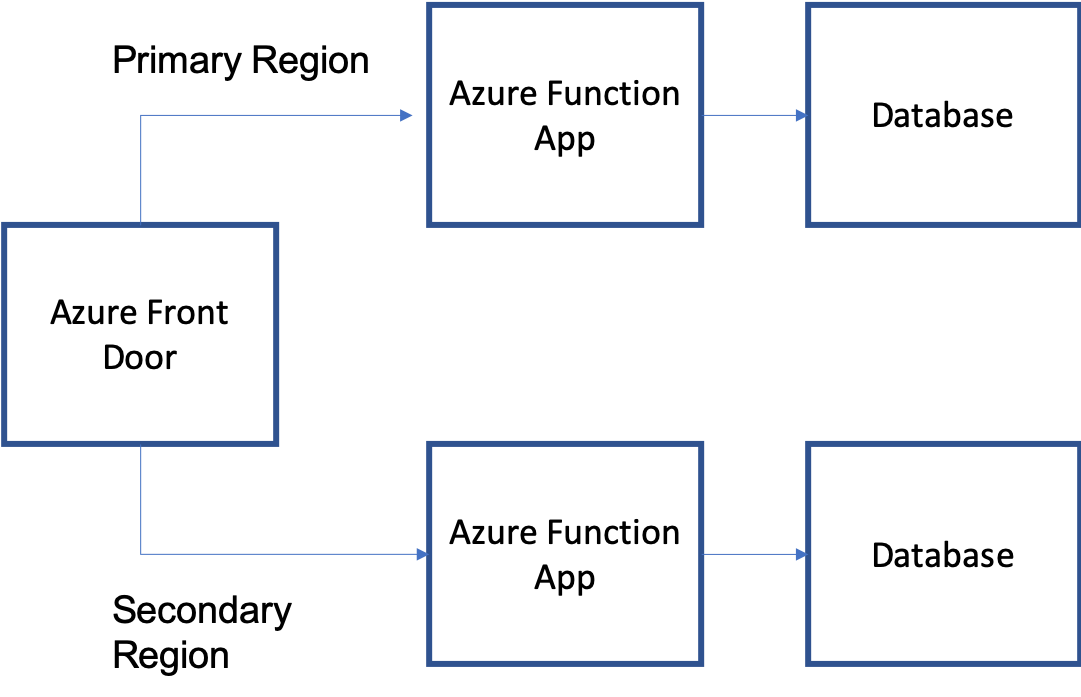
For an example please refer to the sample on how to implement the geode pattern by deploying the API to geodes in distributed Azure regions..
Important
Although, it's highly recommended that you use the active-passive pattern for non-HTTPS trigger functions. You can create active-active deployments for non-HTTP triggered functions. However, you need to consider how the two active regions interact or coordinate with one another. When you deploy the same function app to two regions with each triggering on the same Service Bus queue, they would act as competing consumers on de-queueing that queue. While this means each message is only being processed by either one of the instances, it also means there's still a single point of failure on the single Service Bus instance.
You could instead deploy two Service Bus queues, with one in a primary region, one in a secondary region. In this case, you could have two function apps, with each pointed to the Service Bus queue active in their region. The challenge with this topology is how the queue messages are distributed between the two regions. Often, this means that each publisher attempts to publish a message to both regions, and each message is processed by both active function apps. While this creates the desired active/active pattern, it also creates other challenges around duplication of compute and when or how data is consolidated.
It's recommended that you use active-passive pattern for your event-driven, non-HTTP triggered functions, such as Service Bus and Event Hubs triggered functions.
To create redundancy for non-HTTP trigger functions, use an active-passive pattern. With an active-passive pattern, functions run actively in the region that's receiving events; while the same functions in a second region remain idle. The active-passive pattern provides a way for only a single function to process each message while providing a mechanism to fail over to the secondary region in a disaster. Function apps work with the failover behaviors of the partner services, such as Azure Service Bus geo-recovery and Azure Event Hubs geo-recovery.
Consider an example topology using an Azure Event Hubs trigger. In this case, the active/passive pattern requires involve the following components:
- Azure Event Hubs deployed to both a primary and secondary region.
- Geo-disaster enabled to pair the primary and secondary event hubs. This also creates an alias you can use to connect to event hubs and switch from primary to secondary without changing the connection info.
- Function apps are deployed to both the primary and secondary (failover) region, with the app in the secondary region essentially being idle because messages aren't being sent there.
- Function app triggers on the direct (non-alias) connection string for its respective event hub.
- Publishers to the event hub should publish to the alias connection string.
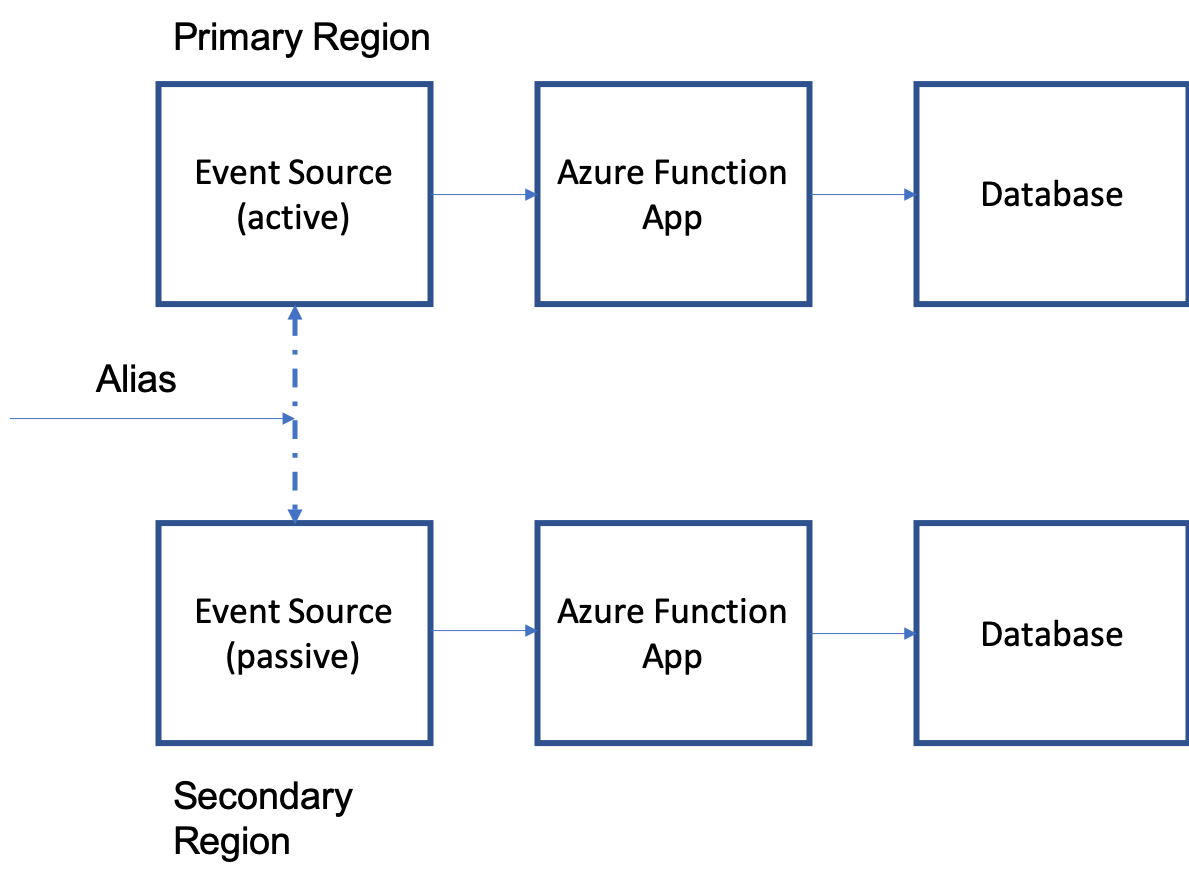
Before failover, publishers sending to the shared alias route to the primary event hub. The primary function app is listening exclusively to the primary event hub. The secondary function app is passive and idle. As soon as failover is initiated, publishers sending to the shared alias are routed to the secondary event hub. The secondary function app now becomes active and starts triggering automatically. Effective failover to a secondary region can be driven entirely from the event hub, with the functions becoming active only when the respective event hub is active.
Read more on information and considerations for failover with Service Bus and Event Hubs.