Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Sugerencia
Microsoft Fabric Data Warehouse es un almacenamiento relacional de escala empresarial en una base de lago de datos, con una arquitectura lista para el futuro, inteligencia artificial integrada y nuevas características. Si no está familiarizado con el almacenamiento de datos, comience con Fabric Data Warehouse. Las cargas de trabajo del grupo de SQL dedicadas pueden actualizarse a Fabric para acceder a nuevas funcionalidades en ciencia de datos, análisis en tiempo real e informes.
Este artículo contiene información sobre cómo solucionar los problemas más frecuentes con grupos de SQL sin servidor en Azure Synapse Analytics.
Para más información sobre Azure Synapse Analytics, consulte los temas en Información general.
Synapse Studio
Synapse Studio es una herramienta fácil de utilizar que permite acceder a los datos desde un explorador sin necesidad de instalar herramientas de acceso a bases de datos. Synapse Studio no está diseñado para leer un conjunto de datos de gran tamaño ni para la administración completa de los objetos de SQL.
El grupo de SQL sin servidor está atenuado en Synapse Studio
Si Synapse Studio no puede establecer una conexión con el grupo de SQL sin servidor, observará que este aparece atenuado o con el estado Sin conexión.
Normalmente, este problema se debe a una de estas dos razones:
- La red impide la comunicación con el back-end de Azure Synapse Analytics. El caso más frecuente es que el puerto TCP 1443 está bloqueado. Para que el grupo de SQL sin servidor funcione, desbloquee este puerto. Otros problemas podrían impedir también el funcionamiento del grupo de SQL sin servidor. Para más información, consulte la guía de solución de problemas.
- No tiene permiso para iniciar sesión en el grupo de SQL sin servidor. Para obtener acceso, uno de los administradores del área de trabajo de Azure Synapse le debe asignar el rol de administrador de áreas de trabajo o el rol de administrador de SQL. Para más información, consulte Control de acceso de Azure Synapse.
La conexión a WebSocket se cerró de forma inesperada
La consulta podría devolver el mensaje de error Websocket connection was closed unexpectedly., lo que significa que se interrumpió la conexión del explorador a Synapse Studio debido, por ejemplo, a un problema de red.
- Para resolver este problema, vuelva a ejecutar la consulta.
- Pruebe la extensión MSSQL para Visual Studio Code o SQL Server Management Studio para las mismas consultas en lugar de Synapse Studio para una investigación más detallada.
- Si este mensaje se produce con frecuencia en su entorno, pida ayuda a su administrador de red. También puede comprobar la configuración del firewall y consultar la guía de solución de problemas.
- Si el problema continúa, cree una incidencia de soporte técnico desde Azure Portal.
Las bases de datos sin servidor no se muestran en Synapse Studio
Si no ve las bases de datos que se crean en un grupo de SQL sin servidor, compruebe que se haya iniciado el grupo de SQL sin servidor. Si el grupo de SQL sin servidor está desactivado, las bases de datos no se mostrarán. Ejecute cualquier consulta, por ejemplo, SELECT 1, en el grupo de SQL sin servidor para activarla y que aparezcan las bases de datos.
El grupo de SQL sin servidor de Synapse se muestra como no disponible
A menudo, la causa de este comportamiento es una configuración incorrecta de la red. Asegúrese de que los puertos están configurados correctamente. Si usa un firewall o puntos de conexión privados, compruebe también esta configuración.
Por último, asegúrese de que se conceden los roles adecuados y que no se han revocado.
No se puede crear una nueva base de datos, ya que la solicitud usará la clave antigua o expirada
Este error se debe a la modificación de la clave administrada por el cliente del área de trabajo que se usa para el cifrado. Puede optar por volver a cifrar todos los datos del área de trabajo con la versión más reciente de la clave activa. Para realizar un nuevo cifrado, cambie la clave en Azure Portal por una clave temporal y, luego, vuelva a cambiar a la clave que quiera usar para el cifrado. Obtenga información aquí sobre cómo administrar las claves del área de trabajo.
El grupo de SQL sin servidor de Synapse no está disponible después de transferir una suscripción a otro inquilino de Microsoft Entra
Si ha movido una suscripción a otro inquilino de Microsoft Entra, es posible que experimente algunos problemas con el grupo de SQL sin servidor. Cree una incidencia de soporte técnico y el Soporte técnico de Azure se pondrá en contacto con usted para resolver la incidencia.
Acceso al almacenamiento
Si aparecen errores al intentar acceder a los archivos del almacenamiento de Azure, asegúrese de que tiene los permisos necesarios para acceder a los datos. Debería poder acceder a los archivos disponibles públicamente. Si intenta acceder a los datos sin credenciales, asegúrese de que su identidad de Microsoft Entra pueda acceder directamente a los archivos.
Si tiene una clave de firma de acceso compartido que debe usar para acceder a los archivos, asegúrese de que ha creado una credencial de nivel de servidor o con ámbito de base de datos que contenga esa credencial. Las credenciales son obligatorias si es necesario acceder a los datos mediante la identidad administrada del área de trabajo y el nombre de entidad de seguridad de servicio (SPN) personalizado.
No se pueden leer ni enumerar archivos en Azure Data Lake Storage, ni acceder a ellos
Si usa un inicio de sesión de Microsoft Entra sin credenciales explícitas, asegúrese de que su identidad de Microsoft Entra pueda acceder a los archivos en el almacenamiento. Para acceder a los archivos, la identidad de Microsoft Entra debe tener el permiso de Lector de datos de blobs o permisos para enumerar y leerlistas de control de acceso (ACL) en ADLS. Para más información, consulte Error en la consulta porque no se puede abrir el archivo.
Si accede al almacenamiento mediante credenciales, asegúrese de que la identidad administrada o el SPN tengan los roles de Lector de datos o de Colaborador o permisos de ACL concretos. Si ha usado un token de firma de acceso compartido, asegúrese de tener el permiso rl y que no haya expirado.
Si usa un inicio de sesión de SQL y la función OPENROWSETsin origen de datos, asegúrese de tener una credencial de nivel de servidor que coincida con el identificador URI de almacenamiento y que tenga permiso para acceder al almacenamiento.
La consulta produce un error porque el archivo no se puede abrir
Si la consulta muestra el error File cannot be opened because it does not exist or it is used by another process y está seguro de que ambos archivos existen y no están siendo usados por otro proceso, entonces el grupo de SQL sin servidor no puede acceder al archivo. Este problema suele ocurrir porque la identidad de Microsoft Entra no tiene derechos para acceder al archivo o porque un firewall bloquea el acceso a este.
De manera predeterminada, el grupo de SQL sin servidor intenta acceder al archivo mediante la identidad de Microsoft Entra. Para resolver este problema, debe tener los derechos adecuados para acceder al archivo. La forma más sencilla es concederse a sí mismo un rol de colaborador de datos de blob de almacenamiento en la cuenta de almacenamiento que intenta consultar.
Para más información, consulte:
- Control de acceso de Microsoft Entra ID para almacenamiento
- Control del acceso a la cuenta de almacenamiento del grupo de SQL sin servidor en Synapse Analytics
Alternativa al rol Colaborador de datos de Storage Blob
En lugar de concederse el rol de colaborador de datos de blob de almacenamiento, también puede conceder permisos más específicos sobre un subconjunto de archivos.
Todos los usuarios que necesitan acceso a algunos datos de este contenedor también deben tener el permiso EXECUTE sobre todas las carpetas principales hasta la raíz (el contenedor).
Aprenda a establecer listas ACL en Azure Data Lake Storage Gen2.
Nota:
El permiso de ejecución sobre el nivel de contenedor debe establecerse en Azure Data Lake Storage Gen2. Los permisos sobre la carpeta se pueden establecer en Azure Synapse.
Si quiere consultar data2.csv en este ejemplo, se necesitan los siguientes permisos:
- Permiso de ejecución sobre el contenedor
- Permiso de ejecución sobre folder1
- Permiso de lectura sobre data2.csv

Inicie sesión en Azure Synapse con un usuario administrador que tenga permisos completos sobre los datos a los que quiere acceder.
En el panel de datos, haga clic con el botón derecho en el archivo y seleccione Administrar acceso.
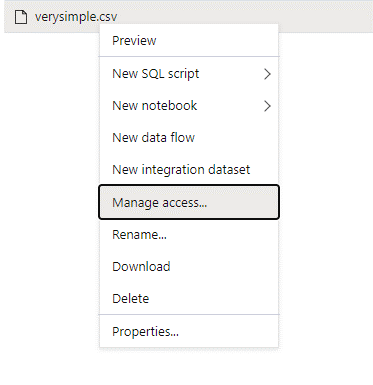
Seleccione al menos el permiso Lectura. Escriba el UPN o el identificador de objeto del usuario, por ejemplo,
user@contoso.com. Seleccione Agregar.Conceda a este usuario permiso de lectura.

Nota:
En el caso de los usuarios invitados, este paso debe hacerse directamente con el servicio Azure Data Lake, ya que no se puede hacer directamente mediante Azure Synapse.
No se puede enumerar el contenido del directorio en la ruta de acceso
Este error indica que el usuario que consulta Azure Data Lake no puede enumerar los archivos en el almacenamiento. Hay varios escenarios en los que podría producirse este error:
- El usuario de Microsoft Entra que usa la autenticación transferida de Microsoft Entra no tiene permisos para enumerar los archivos en Data Lake Storage.
- El usuario de Microsoft Entra ID o SQL que lee los datos mediante una clave de firma de acceso compartido o una identidad administrada del área de trabajo y esa clave o identidad no tiene permiso para enumerar los archivos en el almacenamiento.
- El usuario que accede a los datos de Dataverse no tiene permiso para consultar datos en Dataverse. Este escenario puede ocurrir si se utilizan usuarios de SQL.
- Es posible que el usuario que accede a Delta Lake no tenga permiso para leer el registro de transacciones de Delta Lake.
La forma más sencilla de resolver este problema es concederse a sí mismo el rol de Colaborador de datos de Storage Blob en la cuenta de almacenamiento que intenta consultar.
Para más información, consulte:
- Control de acceso de Microsoft Entra ID para almacenamiento
- Control del acceso a la cuenta de almacenamiento del grupo de SQL sin servidor en Synapse Analytics
No se puede enumerar el contenido de la tabla de Dataverse
Si usa el vínculo de Azure Synapse Link para Dataverse para leer las tablas de Dataverse vinculadas, debe usar una cuenta de Microsoft Entra para acceder a los datos vinculados mediante el grupo de SQL sin servidor. Para más información, consulte Azure Synapse Link para Dataverse con Azure Data Lake.
Si intenta usar un inicio de sesión de SQL para leer una tabla externa que hace referencia a la tabla de DataVerse, recibirá el siguiente error: External table '???' is not accessible because content of directory cannot be listed.
Las tablas externas de Dataverse siempre usan la autenticación transferida de Microsoft Entra. No se pueden configurar para usar una clave de firma de acceso compartido ni una identidad administrada del área de trabajo.
No se puede enumerar el contenido del registro de transacciones de Delta Lake
El siguiente error se devuelve cuando el grupo de SQL sin servidor no puede leer la carpeta del registro de transacciones de Delta Lake:
Content of directory on path 'https://.....core.windows.net/.../_delta_log/*.json' cannot be listed.
Asegúrese de que la carpeta _delta_log exista. Asegúrese de que consulta archivos Parquet sin formato que no se convierten al formato de Delta Lake. Si la carpeta _delta_log existe, asegúrese de que tiene permisos de lectura y enumeración en las carpetas de Delta Lake subyacentes. Pruebe a leer archivos json directamente mediante FORMAT='csv'. Coloque el URI en el parámetro BULK:
select top 10 *
from openrowset(BULK 'https://.....core.windows.net/.../_delta_log/*.json',FORMAT='csv', FIELDQUOTE = '0x0b', FIELDTERMINATOR ='0x0b',ROWTERMINATOR = '0x0b')
with (line varchar(max)) as logs
Si se produce un error en esta consulta, el autor de llamada no tiene permiso para leer los archivos del almacenamiento subyacente.
Ejecución de la consulta
Es posible que reciba errores durante la ejecución de la consulta en los casos siguientes:
- El autor de la llamada no puede acceder a algunos objetos.
- La consulta no puede acceder a datos externos.
- La consulta contiene algunas funcionalidades que no se admiten en grupos de SQL sin servidor.
La consulta produce un error porque no se puede ejecutar debido a las restricciones de recursos actuales
Es posible que la consulta muestre el mensaje de error This query cannot be executed due to current resource constraints.. Este mensaje significa que el grupo de SQL sin servidor no se puede ejecutar en este momento. Estas son algunas opciones de solución de problemas:
- Asegúrese de que se usan tipos de datos de tamaños razonables.
- Si la consulta se dirige a archivos Parquet, considere la posibilidad de definir tipos explícitos para las columnas de cadena, ya que serán VARCHAR(8000) de forma predeterminada. Comprobación de los tipos de datos inferidos
- Si la consulta se dirige a archivos CSV, considere la posibilidad de crear estadísticas.
- Para optimizar la consulta, vea Procedimientos recomendados de rendimiento para el grupo de SQL sin servidor.
Se ha superado el tiempo de expiración de la consulta
Se recibe el error Query timeout expired si la consulta se ha ejecutado más de 30 minutos en un grupo de SQL sin servidor. Este límite para el grupo de SQL sin servidor no se puede cambiar.
- Puede intentar optimizar la consulta aplicando procedimientos recomendados.
- Pruebe a materializar partes de las consultas mediante la creación de una tabla externa como select (CETAS).
- Compruebe si hay una carga de trabajo simultánea que se ejecuta en el grupo de SQL sin servidor, ya que las demás consultas podrían ocupar los recursos. En ese caso, podría dividir la carga de trabajo en varias áreas de trabajo.
Nombre de objeto no válido.
El error Invalid object name 'table name' indica que está usando un objeto, como una tabla o una vista, que no existe en la base de datos del grupo de SQL sin servidor. Pruebe estas opciones:
Enumere las tablas o vistas y comprueba si el objeto existe. Use SQL Server Management Studio o Visual Studio Code, ya que Synapse Studio podría mostrar algunas tablas que no están disponibles en el grupo de SQL sin servidor.
Si ve el objeto, compruebe que usa alguna intercalación de base de datos binaria o que distingue mayúsculas de minúsculas. Es posible que el nombre del objeto no coincida con el nombre que usó en la consulta. Con una intercalación de base de datos binaria,
Employeeyemployeeson dos objetos diferentes.Si no ve el objeto, quizás está intentando consultar una tabla desde un lago o una base de datos de Spark. Es posible que la tabla no esté disponible en el grupo de SQL sin servidor por los siguientes motivos:
- La tabla tiene algunos tipos de columna que no se pueden representar en el grupo de SQL sin servidor.
- La tabla tiene un formato que no se admite en el grupo de SQL sin servidor. Algunos ejemplos son Avro u ORC.
Los datos binarios o de tipo cadena se truncarían.
Este error se produce si la longitud del tipo de columna binaria o de cadena (por ejemplo VARCHAR, VARBINARY o NVARCHAR) es menor que el tamaño real de los datos que está leyendo. Puede corregir este error aumentando la longitud del tipo de columna:
- Si la columna de cadena se define como el tipo
VARCHAR(32)y el texto tiene 60 caracteres, use el tipoVARCHAR(60)(o más largo) en el esquema de columna. - Si usa la inferencia de esquema (sin el esquema
WITH), todas las columnas de cadena se definen automáticamente como del tipoVARCHAR(8000). Si recibe este error, defina explícitamente el esquema en una cláusulaWITHcon el tipo de columnaVARCHAR(MAX)más grande para resolver este error. - Si la tabla está en la base de datos de Lake, intente aumentar el tamaño de la columna de cadena en el grupo de Spark.
- Intente
SET ANSI_WARNINGS OFFpara habilitar el grupo de SQL sin servidor para truncar automáticamente los valores VARCHAR, si esto no afecta a las funcionalidades.
Falta la comilla de cierre después de la cadena de caracteres
En algunos casos excepcionales, donde se usa el operador LIKE en una columna de cadena o alguna comparación con los literales de cadena, puede aparecer el siguiente error:
Unclosed quotation mark after the character string
Este error puede producirse si usa la intercalación Latin1_General_100_BIN2_UTF8 en la columna. Para resolver el problema, intente establecer la intercalación Latin1_General_100_CI_AS_SC_UTF8 en la columna en lugar de la intercalación Latin1_General_100_BIN2_UTF8. Si se sigue devolviendo el error, genere una solicitud de soporte técnico a través de Azure Portal.
No se pudo asignar espacio de tempdb al transferir datos de una distribución a otra
Se devuelve el error Could not allocate tempdb space while transferring data from one distribution to another cuando el motor de ejecución de consultas no puede procesar los datos ni transferirlos entre los nodos que ejecutan la consulta. Es un caso especial del error genérico que indica que la consulta produce un error porque no se puede ejecutar debido a las restricciones de recursos actuales. Este error se devuelve cuando los recursos asignados a la base de datos tempdb no son suficientes para ejecutar la consulta.
Aplique los procedimientos recomendados antes de presentar una incidencia de soporte técnico.
Se produce un error en la consulta al controlar un archivo externo (se ha alcanzado el número máximo de errores)
Si la consulta no se realiza y aparece el mensaje de error error handling external file: Max errors count reached, significa que hay un error de coincidencia de un tipo de columna especificado y es necesario cargar los datos.
Para más información sobre el error y las filas y columnas que se deben examinar, cambie la versión del analizador de 2.0 a 1.0.
Ejemplo
Si quiere consultar el archivo names.csv con esta consulta 1, el grupo de SQL sin servidor de Azure Synapse devuelve el siguiente error: Error handling external file: 'Max error count reached'. File/External table name: [filepath].. Por ejemplo:
El archivo names.csv contiene:
Id,first name,
1, Adam
2,Bob
3,Charles
4,David
5,Eva
Consulta 1:
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='2.0',
FIELDTERMINATOR =';',
FIRSTROW = 2
)
WITH (
[ID] SMALLINT,
[Text] VARCHAR (1) COLLATE Latin1_General_BIN2
)
AS [result]
Causa
En cuanto se cambia la versión del analizador de 2.0 a 1.0, los mensajes de error ayudan a identificar el problema. El nuevo mensaje de error es ahora Bulk load data conversion error (truncation) for row 1, column 2 (Text) in data file [filepath].
El truncamiento indica que el tipo de columna es demasiado pequeño para los datos. El nombre más largo de este archivo, names.csv, tiene siete caracteres. Por lo tanto, el tipo de datos correspondiente que se va a usar debe ser al menos VARCHAR(7). El error se debe a esta línea de código:
[Text] VARCHAR (1) COLLATE Latin1_General_BIN2
Al cambiar la consulta en consecuencia, se resuelve el error. Después de la depuración, cambie de nuevo la versión del analizador a 2.0 para lograr el máximo rendimiento.
Para más información sobre cuándo usar la versión del analizador, consulte Uso de OPENROWSET mediante un grupo de SQL sin servidor en Synapse Analytics.
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='2.0',
FIELDTERMINATOR =';',
FIRSTROW = 2
)
WITH (
[ID] SMALLINT,
[Text] VARCHAR (7) COLLATE Latin1_General_BIN2
)
AS [result]
No se puede realizar la carga masiva porque no se pudo abrir el archivo
El error Cannot bulk load because the file could not be opened se devuelve si se modifica un archivo durante la ejecución de la consulta. Normalmente, puede que reciba un error como Cannot bulk load because the file {file path} could not be opened. Operating system error code 12. (The access code is invalid.).
Los grupos de SQL sin servidor no pueden leer los archivos que se modifican mientras se ejecuta la consulta. La consulta no puede bloquear los archivos. Si sabe que la operación de modificación es append, puede intentar establecer la siguiente opción: {"READ_OPTIONS":["ALLOW_INCONSISTENT_READS"]}.
Para más información, vea cómo consultar archivos de solo anexión o crear tablas en archivos de solo anexión.
La consulta produce un error de conversión de datos
Es posible que la consulta no se realice y aparezca el mensaje de error Bulk load data conversion error (type mismatches or invalid character for the specified code page) for row n, column m [columnname] in the data file [filepath]., lo que significa que los tipos de datos no coinciden con los datos reales en el número de fila n y la columna m.
Por ejemplo, si solo espera enteros en los datos, pero en la fila n hay una cadena, este es el mensaje de error que recibirá.
Para resolver este problema, inspeccione el archivo y los tipos de datos que eligió. Compruebe también si la configuración del delimitador de filas y el terminador de campo es correcta. En el ejemplo siguiente se muestra cómo se puede realizar la inspección mediante VARCHAR como tipo de columna.
Para más información sobre los terminadores de campo, los delimitadores de fila y los caracteres de comillas de escape, vea Consulta de archivos CSV.
Ejemplo
Si quiere consultar el archivo names.csv:
Id, first name,
1,Adam
2,Bob
3,Charles
4,David
five,Eva
Con la siguiente consulta:
Consulta 1:
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='1.0',
FIELDTERMINATOR =',',
FIRSTROW = 2
)
WITH (
[ID] SMALLINT,
[Firstname] VARCHAR (25) COLLATE Latin1_General_BIN2
)
AS [result]
El grupo de SQL sin servidor de Azure Synapse devuelve el errorBulk load data conversion error (type mismatch or invalid character for the specified code page) for row 6, column 1 (ID) in data file [filepath].
Es necesario examinar los datos y tomar una decisión informada para tratar este problema. Para ver los datos que ocasionan este problema, primero es necesario cambiar el tipo de datos. En lugar de consultar la columna "ID" con el tipo de datos "SMALLINT", ahora se usa VARCHAR(100) para analizar este problema.
Con esta consulta 2 ligeramente modificada, ahora se pueden procesar los datos para devolver la lista de nombres.
Consulta 2:
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='1.0',
FIELDTERMINATOR =',',
FIRSTROW = 2
)
WITH (
[ID] VARCHAR(100),
[Firstname] VARCHAR (25) COLLATE Latin1_General_BIN2
)
AS [result]
Tal vez vea que los datos tienen valores de ID inesperados en la quinta fila. En tales circunstancias, es importante trabajar con el propietario empresarial de los datos para acordar cómo se puede evitar dañar datos como los de este ejemplo. Si la prevención no es posible en el nivel de aplicación, VARCHAR con un tamaño razonable podría ser la única opción aquí.
Sugerencia
Intente que VARCHAR() sea lo más corto posible. Evite VARCHAR(MAX) si es posible, ya que esta opción puede afectar al rendimiento.
El resultado de la consulta no parece el esperado
Es posible que la consulta no produzca un error, pero puede que vea que el conjunto de resultados no es el esperado. Es posible que las columnas resultantes estén vacías o que se devuelvan datos inesperados. En este escenario, es probable que se haya elegido incorrectamente un delimitador de fila o terminador de campo.
Para resolver este problema, es necesario examinar de nuevo los datos y cambiar esa configuración. La depuración de esta consulta es sencilla, como se muestra en el ejemplo siguiente.
Ejemplo
Si quiere consultar el archivo names.csv con la consulta de la consulta 1, el grupo de SQL sin servidor de Azure Synapse devuelve un resultado que parece extraño:
En names.csv:
Id,first name,
1, Adam
2, Bob
3, Charles
4, David
5, Eva
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='1.0',
FIELDTERMINATOR =';',
FIRSTROW = 2
)
WITH (
[ID] VARCHAR(100),
[Firstname] VARCHAR (25) COLLATE Latin1_General_BIN2
)
AS [result]
| ID | Firstname |
| ------------- |------------- |
| 1,Adam | NULL |
| 2,Bob | NULL |
| 3,Charles | NULL |
| 4,David | NULL |
| 5,Eva | NULL |
Parece que no hay ningún valor en la columna Firstname. En su lugar, todos los valores terminaron en la columna ID. Los valores están separados por una coma. El problema se debe a esta línea de código, ya que es necesario elegir la coma en lugar del símbolo de punto y coma como terminador de campo:
FIELDTERMINATOR =';',
El cambio de este carácter único resuelve el problema:
FIELDTERMINATOR =',',
El conjunto de resultados creado por la consulta 2 es ahora como se esperaba:
Consulta 2:
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='1.0',
FIELDTERMINATOR =',',
FIRSTROW = 2
)
WITH (
[ID] VARCHAR(100),
[Firstname] VARCHAR (25) COLLATE Latin1_General_BIN2
)
AS [result]
Devuelve:
| ID | Firstname |
| ------------- |------------- |
| 1 | Adam |
| 2 | Bob |
| 3 | Charles |
| 4 | David |
| 5 | Eva |
La columna del tipo no es compatible con el tipo de datos externos
Si la consulta no se realiza y aparece el mensaje de error Column [column-name] of type [type-name] is not compatible with external data type […],, es probable que un tipo de datos de PARQUET se asigne al tipo de datos de SQL incorrecto.
Por ejemplo, si el archivo Parquet tiene un precio de columna con números flotantes (como 12,89) y ha intentado asignarlo a INT, este es el mensaje de error que recibirá.
Para resolverlo, inspeccione el archivo y los tipos de datos que eligió. Esta tabla de asignación ayuda a elegir un tipo de datos SQL correcto. Como procedimiento recomendado, especifique la asignación solo para las columnas que, si no, se resolverían en el tipo de datos VARCHAR. Evitar VARCHAR cuando sea posible conduce a un mejor rendimiento en las consultas.
Ejemplo
Si quiere consultar el archivo taxi-data.parquet con esta Consulta 1, el grupo de SQL sin servidor de Azure Synapse devuelve el siguiente error:
El archivo taxi-data.parquet contiene los siguientes elementos:
|PassengerCount |SumTripDistance|AvgTripDistance |
|---------------|---------------|----------------|
| 1 | 2635668.66000064 | 6.72731710678951 |
| 2 | 172174.330000005 | 2.97915543404919 |
| 3 | 296384.390000011 | 2.8991352022851 |
| 4 | 12544348.58999806| 6.30581582240281 |
| 5 | 13091570.2799993 | 111.065989028627 |
Consulta 1:
SELECT
*
FROM
OPENROWSET(
BULK '<filepath>taxi-data.parquet',
FORMAT='PARQUET'
) WITh
(
PassengerCount INT,
SumTripDistance INT,
AVGTripDistance FLOAT
)
AS [result]
Column 'SumTripDistance' of type 'INT' is not compatible with external data type 'Parquet physical type: DOUBLE', please try with 'FLOAT'. File/External table name: '<filepath>taxi-data.parquet'.
Este mensaje de error nos indica que los tipos de datos no son compatibles e incluye la sugerencia de usar FLOAT en lugar de INT. El error se debe a esta línea de código:
SumTripDistance INT,
Con esta consulta 2 ligeramente modificada, ahora se pueden procesar los datos y se muestran las tres columnas:
Consulta 2:
SELECT
*
FROM
OPENROWSET(
BULK '<filepath>taxi-data.parquet',
FORMAT='PARQUET'
) WITh
(
PassengerCount INT,
SumTripDistance FLOAT,
AVGTripDistance FLOAT
)
AS [result]
La consulta hace referencia a un objeto que no se admite en el modo de procesamiento distribuido
El error The query references an object that is not supported in distributed processing mode indica que ha usado un objeto o una función que no se pueden usar al consultar datos en Azure Storage o en el almacenamiento analítico de Cosmos DB.
Algunos objetos, como las vistas del sistema y las funciones no se pueden usar al consultar los datos almacenados en Azure Data Lake o en el almacenamiento analítico de Azure Cosmos DB. Evite usar las consultas que unen datos externos con vistas del sistema, cargan datos externos en una tabla temporal o usan algunas funciones de seguridad o metadatos para filtrar datos externos.
Error en la llamada WaitIOCompletion
El mensaje de error WaitIOCompletion call failed indica que se ha producido un error en la consulta mientras se esperaba completar la operación de E/S que lee datos del almacenamiento remoto, Azure Data Lake.
El mensaje de error tiene el siguiente patrón: Error handling external file: 'WaitIOCompletion call failed. HRESULT = ???'. File/External table name...
Asegúrese de que el almacenamiento se encuentra en la misma región que el grupo de SQL sin servidor. Compruebe las métricas de almacenamiento y confirme que no haya otras cargas de trabajo en la capa de almacenamiento, como la carga de nuevos archivos, que pueda saturar las solicitudes de E/S.
El campo HRESULT contiene el código de resultado. Los siguientes códigos de error son los más comunes junto con sus posibles soluciones.
Este código de error significa que el archivo de origen no está en el almacenamiento.
Hay distintos motivos por los que este código de error puede ocurrir:
- Otra aplicación ha eliminado el archivo.
- En este escenario común, se inicia la ejecución de la consulta, se enumeran los archivos y se encuentran los archivos. Más adelante, durante la ejecución de la consulta, se elimina un archivo. Por ejemplo, podría eliminarse en Databricks, Spark o Azure Data Factory. Se produce un error en la consulta porque no se encuentra el archivo.
- Este problema también puede producirse con el formato Delta. La consulta podría realizarse correctamente al reintentarlo porque hay una nueva versión de la tabla y el archivo eliminado no se vuelve a consultar.
- Se ha almacenado en la caché, un plan de ejecución no válido.
- Ejecute el comando
DBCC FREEPROCCACHEcomo mitigación temporal. Si el problema persiste, cree una incidencia de soporte técnico.
- Ejecute el comando
Sintaxis incorrecta cerca de "NOT"
El error Incorrect syntax near 'NOT' indica que hay algunas tablas externas con las columnas que contienen la restricción NOT NULL en la definición de columna.
- Actualice la tabla para quitar NOT NULL de la definición de columna.
- Este error también puede producirse de forma transitoria con tablas creadas a partir de una instrucción CETAS. Si el problema no se resuelve, puede intentar quitar y volver a crear la tabla externa.
La columna de partición devuelve valores NULL
Si la consulta devuelve valores NULL en lugar de columnas de partición o no se encuentran las columnas de partición, no hay mucho que hacer para resolver el problema:
- Si usa tablas para consultar un conjunto de datos con particiones, las tablas no admiten la creación de particiones. Reemplace la tabla por las vistas con particiones.
- Si usa las vistas con particiones con OPENROWSET que consulta los archivos con particiones mediante la función FILEPATH(), asegúrese de que haya especificado correctamente el patrón de caracteres comodín en la ubicación y de que haya utilizado el índice adecuado para hacer referencia al carácter comodín.
- Si está consultando los archivos directamente en la carpeta con particiones, las columnas de partición no son parte de las columnas de archivo. Los valores de creación de particiones se colocan en las rutas de acceso de las carpetas, no en los archivos. Por este motivo, los archivos no contienen los valores de creación de particiones.
Error al insertar el valor en el lote para el tipo de columna DATETIME2
El error Inserting value to batch for column type DATETIME2 failed indica que el grupo sin servidor no puede leer los valores de fecha de los archivos subyacentes. El valor datetime almacenado en el archivo de Parquet o Delta Lake no se puede representar como una columna DATETIME2.
Inspeccione el valor mínimo del archivo mediante Spark y compruebe que algunas fechas anteriores sean inferiores a 03-01-0001. Si ha almacenado los archivos con la versión superior de Spark que todavía usa el formato de almacenamiento datetime heredado, los valores datetime anteriores se escriben con el calendario juliano que no está alineado con el calendario gregoriano proléptico que se usa en grupos de SQL sin servidor.
Puede haber una diferencia de dos días entre el calendario juliano usado para escribir los valores en Parquet (en algunas versiones de Spark) y el calendario gregoriano proléptico usado en el grupo de SQL sin servidor. Esta diferencia puede provocar la conversión a un valor de fecha negativo, que no es válido.
Pruebe a usar Spark para actualizar estos valores, ya que se tratan como valores de fecha no válidos en SQL. En el siguiente ejemplo se muestra cómo actualizar los valores que están fuera de los intervalos de fechas de SQL a NULL en Delta Lake:
from delta.tables import *
from pyspark.sql.functions import *
deltaTable = DeltaTable.forPath(spark,
"abfss://my-container@myaccount.dfs.core.windows.net/delta-lake-data-set")
deltaTable.update(col("MyDateTimeColumn") < '0001-02-02', { "MyDateTimeColumn": null } )
Este cambio quita los valores que no se pueden representar. Los otros valores de fecha podrían cargarse de forma correcta pero representarse de forma incorrecta, ya que todavía hay una diferencia entre los calendarios juliano y gregoriano proléptico. Es posible que vea cambios de fecha inesperados incluso para en el caso de fechas anteriores a 1900-01-01 si usa Spark 3.0 o versiones anteriores.
Considere la posibilidad de migrar a Spark 3.1 o superior y cambiar al calendario gregoriano proléptico. Las versiones más recientes de Spark usan de forma predeterminada un calendario gregoriano proléptico que está en línea con el calendario del grupo de SQL sin servidor. Vuelva a cargar los datos heredados con la versión superior de Spark y use la siguiente configuración para corregir las fechas:
spark.conf.set("spark.sql.legacy.parquet.int96RebaseModeInWrite", "CORRECTED")
Error de consulta debido a un cambio de topología o a un error del contenedor de proceso
Este error podría indicar que se produjo algún problema de proceso interno en el grupo de SQL sin servidor. Abra una incidencia de soporte técnico con todos los detalles que puedan ayudar al equipo de Soporte técnico de Azure a investigar el problema.
Describa cualquier cosa que pueda ser inusual en comparación con la carga de trabajo normal. Por ejemplo, tal vez haya un gran número de solicitudes simultáneas o una carga de trabajo especial o una consulta iniciada en ejecución antes de que se produzca este error.
Se ha agotado el tiempo de espera de la expansión de caracteres comodín
Como se indica en la sección Consulta de carpetas y varios archivos, el grupo de SQL sin servidor admite la lectura de varios archivos o carpetas mediante caracteres comodín. Hay un límite máximo de 10 caracteres comodín por consulta. Debe tener en cuenta que esta funcionalidad conlleva un costo. El grupo sin servidor tarda un tiempo en enumerar todos los archivos que pueden coincidir con el carácter comodín. Esto conlleva una latencia y esta latencia puede aumentar si el número de archivos que intenta consultar es alto. En este caso, puede aparecer el siguiente error:
"Wildcard expansion timed out after X seconds."
Hay varios pasos de mitigación que puede realizar para evitar esto:
- Aplique los procedimientos recomendados descritos en Procedimientos recomendados para un grupo de SQL sin servidor.
- Intente reducir el número de archivos que está intentando consultar mediante la compactación de archivos en otros más grandes. Intente mantener los tamaños de archivo por encima de 100 MB.
- Asegúrese de que los filtros sobre las columnas de partición se usen siempre que sea posible.
- Si usa el formato de archivo delta, use la característica Optimizar escritura de Spark. Esto puede mejorar el rendimiento de las consultas ya que reduce la cantidad de datos que se deben leer y procesar. El uso de esta característica se describe en Uso de Optimizar escritura en Apache Spark.
- Para evitar algunos de los caracteres comodín de nivel superior mediante la codificación eficaz de los filtros implícitos sobre las columnas de partición, use SQL dinámico.
Falta una columna al usar la inferencia automática de esquemas
Puede consultar fácilmente archivos sin necesidad de conocer o especificar el esquema; para ello, omita la cláusula WITH. En ese caso, los nombres de columna y los tipos de datos se inferirán de los archivos. Tenga en cuenta que, si lee varios archivos a la vez, el esquema se inferirá del primer servicio de archivos que se obtenga del almacenamiento. Esto puede significar que algunas de las columnas esperadas estén omitidas, y todo porque el archivo utilizado por el servicio para definir el esquema no contenía estas columnas. Para especificar explícitamente el esquema, use la cláusula OPENROWSET WITH. Si especifica el esquema (mediante la tabla externa o la cláusula OPENROWSET WITH), se usará el modo de ruta de acceso lax predeterminado. Esto significa que las columnas que no existen en algunos archivos se devolverán como valores NULL (para las filas de esos archivos). Para comprender cómo se usa el modo de ruta de acceso, consulte la siguiente documentación y ejemplo.
Configuración
Los grupos de SQL sin servidor permiten usar T-SQL para configurar objetos de base de datos. Hay algunas restricciones:
- No se pueden crear objetos en
masterylakehouseo bases de datos de Spark. - Debe tener una clave maestra para crear credenciales.
- Debe tener permiso para hacer referencia a datos que se usan en los objetos.
No se puede crear una base de datos
Si aparece el error CREATE DATABASE failed. User database limit has been already reached., significa que ha creado el número máximo de bases de datos que se admiten en un área de trabajo. Para más información, vea Restricciones.
- Si necesita separar los objetos, use esquemas dentro de las bases de datos.
- Si solo necesita hacer referencia a Azure Data Lake Storage, cree bases de datos de lago o bases de datos de Spark que se sincronicen en el grupo de SQL sin servidor.
Error al crear o modificar la tabla porque el tamaño mínimo de fila supera el tamaño máximo permitido de fila de tabla de 8060 bytes
Cualquier tabla puede tener hasta un tamaño de 8 KB por fila (sin incluir datos VARCHAR(MAX)/VARBINARY(MAX) fuera de la fila). Si crea una tabla en la que el tamaño total de las celdas de la fila supera los 8060 bytes, obtendrá el siguiente error:
Msg 1701, Level 16, State 1, Line 3
Creating or altering table '<table name>' failed because the minimum row size would be <???>,
including <???> bytes of internal overhead.
This exceeds the maximum allowable table row size of 8060 bytes.
Este error también puede producirse en la base de datos de Lake si crea una tabla de Spark con los tamaños de columna que superan los 8060 bytes y el grupo de SQL sin servidor no puede crear una tabla que haga referencia a los datos de la tabla de Spark.
Como mitigación, evite usar los tipos de tamaño fijo como CHAR(N) y reemplácelos por tipos de tamaño variable VARCHAR(N) o reduzca el tamaño en CHAR(N). Consulte limitación del grupo de filas de 8 KB en SQL Server.
Cree una clave maestra en la base de datos o abra la clave maestra en la sesión antes de realizar esta operación.
Si la consulta no se realiza y aparece el mensaje de error Please create a master key in the database or open the master key in the session before performing this operation., significa que la base de datos de usuario no tiene acceso a una clave maestra en este momento.
Lo más probable es que haya creado una base de datos de usuario nueva y aún no haya creado una clave maestra.
Para resolver este problema, cree una clave maestra con la siguiente consulta:
CREATE MASTER KEY [ ENCRYPTION BY PASSWORD ='strongpasswordhere' ];
Nota:
Reemplace aquí 'strongpasswordhere' por otro secreto.
La instrucción CREATE no se admite en la base de datos maestra
Si la consulta no se realiza y aparece el mensaje de error Failed to execute query. Error: CREATE EXTERNAL TABLE/DATA SOURCE/DATABASE SCOPED CREDENTIAL/FILE FORMAT is not supported in master database., significa que la base de datos master del grupo de SQL sin servidor no admite la creación de:
- Tablas externas.
- Orígenes de datos externos
- Credenciales cuyo ámbito es la base de datos
- Formatos de archivo externos
La solución:
Cree una base de datos de usuarios:
CREATE DATABASE <DATABASE_NAME>Ejecute una instrucción CREATE en el contexto de <NOMBRE_DE_BASE DE DATOS>, que anteriormente produjo un error en la base de datos
master.Este es un ejemplo de la creación de un formato de archivo externo:
USE <DATABASE_NAME> CREATE EXTERNAL FILE FORMAT [SynapseParquetFormat] WITH ( FORMAT_TYPE = PARQUET)
No se puede crear el inicio de sesión ni el usuario de Microsoft Entra
Si recibe un error al intentar crear un inicio de sesión o un usuario de Microsoft Entra en una base de datos, compruebe el inicio de sesión que usó para conectarse a la base de datos. El inicio de sesión que intenta crear un usuario de Microsoft Entra debe tener permiso para acceder al dominio de Microsoft Entra y comprobar si el usuario existe. Tenga en cuenta que:
- Los inicios de sesión de SQL no tienen este permiso, por lo que siempre recibirá este error si usa la autenticación de SQL.
- Si usa un inicio de sesión de Microsoft Entra para crear inicios de sesión, compruebe que tenga permiso para acceder al dominio de Microsoft Entra.
Azure Cosmos DB
Los grupos de SQL sin servidor permiten consultar el almacenamiento analítico de Azure Cosmos DB mediante la función OPENROWSET. Asegúrese de que el contenedor de Azure Cosmos DB tenga almacenamiento analítico. Asegúrese de que haya especificado correctamente el nombre de la cuenta, de la base de datos y del contenedor. Además, asegúrese de que la clave de cuenta de Azure Cosmos DB sea válida. Para obtener más información, consulte la sección Requisitos previos.
No se puede consultar Azure Cosmos DB mediante la función OPENROWSET
Si no puede conectarse a su cuenta de Azure Cosmos DB, examine los requisitos previos. En la tabla siguiente se enumeran los posibles errores y las acciones para solucionar problemas.
| Error | Causa principal |
|---|---|
| Errores de sintaxis: - Sintaxis incorrecta cerca de OPENROWSET.- ... no es una opción de proveedor BULK OPENROWSET reconocida.- Sintaxis incorrecta cerca de .... |
Posibles causas principales: - No se usa Azure Cosmos DB como primer parámetro. - Se usa un literal de cadena, en lugar de un identificador en el tercer parámetro. - No se especifica el tercer parámetro (nombre del contenedor). |
| Se produjo un error en la cadena de conexión de Azure Cosmos DB. | - No se ha especificado la cuenta, la base de datos ni la clave. - Una de las opciones de una cadena de conexión no se reconoce. - Un signo de punto y coma ( ;) se coloca al final de la cadena de conexión. |
| Error al resolver la ruta de acceso de Azure Cosmos DB: "Nombre de cuenta incorrecto" o "Nombre de base de datos incorrecto". | No se encuentra el nombre de cuenta, el nombre de la base de datos o el contenedor especificados, o bien no se han habilitado el almacenamiento analítico para la colección especificada. |
| Error al resolver la ruta de acceso de Azure Cosmos DB: "Valor de secreto incorrecto" o "El secreto es nulo o está vacío". | La clave de cuenta falta o no es válida. |
Se devuelve una advertencia de intercalación de UTF-8 al leer los tipos de cadena de Azure Cosmos DB
Un grupo de SQL sin servidor devuelve una advertencia en tiempo de compilación si la intercalación de columnas OPENROWSET no tiene codificación UTF-8. Puede cambiar fácilmente la intercalación predeterminada de todas las funciones OPENROWSET que se ejecutan en la base de datos actual mediante la instrucción T-SQL:
ALTER DATABASE CURRENT COLLATE Latin1_General_100_CI_AS_SC_UTF8;
La intercalación Latin1_General_100_BIN2_UTF8 ofrece el mejor rendimiento al filtrar los datos mediante predicados de cadena.
Faltan filas en el almacén analítico de Azure Cosmos DB
Puede que la función OPENROWSET no devuelva algunos elementos de Azure Cosmos DB. Tenga en cuenta que:
- Hay un retraso en la sincronización entre el almacén transaccional y el analítico. El documento que especificó en el almacén transaccional de Azure Cosmos DB podría aparecer en el almacén analítico al cabo de dos o tres minutos.
- El documento podría infringir algunas restricciones de esquema.
La consulta devuelve valores NULL en algunos elementos de Azure Cosmos DB
Azure Synapse SQL devuelve NULL en lugar de los valores que ve en el almacén de transacciones en los casos siguientes:
- Hay un retraso en la sincronización entre el almacén transaccional y el analítico. El valor que especificó en el almacén transaccional de Azure Cosmos DB podría aparecer en el almacén analítico al cabo de dos o tres minutos.
- Puede que el nombre de columna o la expresión de la ruta de acceso sean incorrectos en la cláusula WITH. El nombre de columna (o la expresión de la ruta de acceso después del tipo de columna) de la cláusula WITH debe coincidir con los nombres de propiedad de la colección de Azure Cosmos DB. La comparación distingue mayúsculas de minúsculas. Por ejemplo,
productCodeyProductCodeson propiedades diferentes. Asegúrese de que los nombres de columna coinciden exactamente con los nombres de propiedad de Azure Cosmos DB. - La propiedad podría no moverse al almacenamiento analítico porque infringe algunas restricciones de esquema, por ejemplo, más de 1000 propiedades o más de 127 niveles de anidamiento.
- Si usa una representación de esquema bien definida, el valor del almacén transaccional podría tener un tipo incorrecto. Un esquema bien definido bloquea los tipos de cada propiedad mediante el muestreo de los documentos. Cualquier valor agregado en el almacén transaccional que no coincida con el tipo se trata como un valor incorrecto y no se migra al almacén analítico.
- Si usa la representación de esquema de máxima fidelidad, asegúrese de que agrega el sufijo de tipo después del nombre de propiedad, como
$.price.int64. Si no ve un valor para la ruta de acceso a la que se hace referencia, quizás se almacene en una ruta de acceso de tipo diferente, por ejemplo,$.price.float64. Para más información, consulte Consulta de colecciones de Azure Cosmos DB en el esquema de fidelidad completa.
La columna no es compatible con el tipo de datos externos
Se devuelve el error Column 'column name' of the type 'type name' is not compatible with the external data type 'type name'. si el tipo de columna especificado en la cláusula WITH no coincide con el tipo del contenedor de Azure Cosmos DB. Pruebe a cambiar el tipo de columna como se describe en la sección Asignaciones de tipos de Azure Cosmos DB a SQL o use el tipo VARCHAR.
Resolver: se ha producido un error en la ruta de acceso de Azure Cosmos DB
Si recibe el error Resolving Azure Cosmos DB path has failed with error 'This request is not authorized to perform this operation'., compruebe si ha usado puntos de conexión privados en Azure Cosmos DB. Para permitir que el grupo de SQL sin servidor acceda a un almacén analítico con puntos de conexión privados, debe configurar puntos de conexión privados para el almacén analítico de Azure Cosmos DB.
Problemas de rendimiento de Azure Cosmos DB
Si experimenta algunos problemas de rendimiento inesperados, asegúrese de aplicar los procedimientos recomendados, por ejemplo:
- Asegúrese de que ha colocado la aplicación cliente, el grupo sin servidor y el almacenamiento analítico de Azure Cosmos DB en la misma región.
- Asegúrese de que usa la cláusula WITH con tipos de datos óptimos.
- Asegúrese de que usa la intercalación Latin1_General_100_BIN2_UTF8 al filtrar los datos mediante predicados de cadena.
- Si tiene consultas repetitivas que se podrían almacenar en caché, intente usar CETAS para almacenar los resultados de la consulta en Azure Data Lake Storage.
Delta Lake
Hay algunas limitaciones que puede ver en la compatibilidad con Delta Lake en grupos de SQL sin servidor:
- Asegúrese de que hace referencia a la carpeta raíz de Delta Lake en la función OPENROWSET o en la ubicación de la tabla externa.
- La carpeta raíz debe tener una subcarpeta denominada
_delta_log. Se produce un error en la consulta si no hay ninguna carpeta_delta_log. Si no ve esa carpeta, significa que hace referencia a archivos Parquet sin formato que se deben convertir a Delta Lake mediante grupos de Apache Spark. - No especifique caracteres comodín para describir el esquema de partición. La consulta de Delta Lake identifica automáticamente las particiones de Delta Lake.
- La carpeta raíz debe tener una subcarpeta denominada
- Las tablas de Delta Lake creadas en los grupos de Apache Spark están disponibles automáticamente en el grupo de SQL sin servidor, pero el esquema no se actualiza (limitación de la versión preliminar pública). Si agrega columnas en la tabla Delta mediante un grupo de Spark, los cambios no se mostrarán en la base de datos del grupo de SQL sin servidor.
- Las tablas externas no admiten la creación de particiones. Use vistas con particiones en la carpeta de Delta Lake para usar la eliminación de particiones. Consulte problemas conocidos y soluciones alternativas más adelante en el artículo.
- Los grupos de SQL sin servidor no admiten consultas de viaje en el tiempo. Use grupos de Apache Spark en Synapse Analytics para leer datos históricos.
- Los grupos de SQL sin servidor no admiten la actualización de archivos de Delta Lake. Puede usar el grupo de SQL sin servidor para consultar la versión más reciente de Delta Lake. Use grupos de Apache Spark en Azure Synapse Analytics para actualizar Delta Lake.
- No es posible almacenar los resultados de la consulta en formato Delta Lake mediante el comando CETAS. El comando CETAS solo admite los formatos de salida Parquet y CSV.
- Los grupos de SQL sin servidor de Synapse Analytics son compatibles con la versión 1 del lector de Delta.
- Los grupos de SQL sin servidor de Synapse Analytics no admiten los conjuntos de datos con el filtro BLOOM. El grupo de SQL sin servidor omite los filtros BLOOM.
- La compatibilidad con Delta Lake no está disponible en grupos de SQL dedicados. Asegúrese de que usa grupos de SQL sin servidor para consultar archivos de Delta Lake.
- Para más información sobre los problemas conocidos con los grupos de SQL sin servidor, consulte los problemas conocidos de Azure Synapse Analytics.
Compatibilidad con la versión 1.0 de Delta sin servidor
Los grupos de SQL sin servidor solo leen la versión 1.0 de Delta Lake. Los grupos de SQL sin servidor son un lector de Delta con el nivel 1 y no admiten las siguientes características:
- Las asignaciones de columnas se ignoran: los grupos de SQL sin servidor devolverán nombres de columna originales.
- Los vectores de eliminación se ignoran y se devolverá la versión anterior de las filas eliminadas o actualizadas (posiblemente haya resultados incorrectos).
- Las siguientes características de Delta Lake no se admiten: puntos de comprobación de V2, marca de tiempo sin zona horaria y comprobación del protocolo VACUUM
Los vectores de eliminación se ignoran
Si su tabla de Delta Lake está configurada para usar la versión 7 del escritor delta, almacenará las filas eliminadas y las versiones anteriores de las filas actualizadas en Eliminar vectores (DV). Dado que los grupos de SQL sin servidor tienen el nivel 1 del lector Delta, ignorarán los vectores de eliminación y probablemente generarán resultados incorrectos al leer la versión de Delta Lake no compatible.
No se admite el cambio de nombre de columna en la tabla Delta
El grupo de SQL sin servidor no admite la consulta de tablas de Delta Lake con las columnas cuyo nombre ha cambiado. El grupo de SQL sin servidor no puede leer datos de la columna cuyo nombre ha cambiado.
El valor de una columna de la tabla Delta es NULL
Si usa un conjunto de datos Delta que requiere una versión 2 o superior del lector Delta y usa las características que no se admiten en la versión 1 (por ejemplo, cambiar el nombre de columnas, quitar columnas o asignar columnas), es posible que no se muestren los valores de las columnas a las que se hace referencia.
El texto JSON no tiene el formato correcto
Este error indica que el grupo de SQL sin servidor no puede leer el registro de transacciones de Delta Lake. Probablemente vea el error siguiente:
Msg 13609, Level 16, State 4, Line 1
JSON text is not properly formatted. Unexpected character '' is found at position 263934.
Msg 16513, Level 16, State 0, Line 1
Error reading external metadata.
Asegúrese de que el conjunto de datos de Delta Lake no esté dañado. Compruebe que puede leer el contenido de la carpeta de Delta Lake mediante el grupo de Apache Spark en Azure Synapse. De este modo, se asegurará de que el archivo _delta_log no esté dañado.
Solución alternativa
Intente crear un punto de comprobación en el conjunto de datos de Delta Lake mediante un grupo de Apache Spark y vuelva a ejecutar la consulta. El punto de comprobación agregará archivos de registro JSON transaccionales y podría resolver el problema.
Si el conjunto de datos es válido, cree una incidencia de soporte técnico y especifique más información:
- No realice ningún cambio, como agregar o quitar las columnas u optimizar la tabla, ya que esta operación podría cambiar el estado de los archivos de registro de transacciones de Delta Lake.
- Copie el contenido de la carpeta
_delta_logen una nueva carpeta vacía. No copie los archivos.parquet data. - Intente leer el contenido que copió en la nueva carpeta y compruebe que recibe el mismo error.
- Envíe el contenido del archivo copiado
_delta_loga Soporte técnico de Azure.
Ahora puede seguir usando la carpeta de Delta Lake con el grupo de Spark. Si tiene permiso para compartir esta información, proporcionará los datos copiados al servicio de soporte técnico de Microsoft. El equipo de Azure investigará el contenido del archivo delta_log y proporcionará más información sobre los posibles errores y las soluciones alternativas.
Error al resolver los registros Delta
El siguiente error indica que el grupo de SQL sin servidor no puede resolver los registros Delta: Resolving Delta logs on path '%ls' failed with error: Cannot parse json object from log folder.. a causa más común es que last_checkpoint_file en la carpeta _delta_log sea superior a 200 bytes debido al campo checkpointSchema agregado en Spark 3.3.
Hay dos opciones disponibles para evitar este error:
- Modifique la configuración adecuada en el cuaderno de Spark y genere un nuevo punto de control para que
last_checkpoint_filese vuelva a crear. En caso de que use Azure Databricks, la modificación de la configuración es la siguiente:spark.conf.set("spark.databricks.delta.checkpointSchema.writeThresholdLength", 0); - Cambie a una versión anterior de Spark, 3.2.1.
Nuestro equipo de ingeniería está trabajando actualmente en la compatibilidad completa para Spark 3.3.
La tabla Delta creada en Spark no se muestra en el grupo sin servidor
Nota:
La replicación de tablas Delta que se crean en Spark todavía está en versión preliminar pública.
Si ha creado una tabla Delta en Spark y no se muestra en el grupo de SQL sin servidor, compruebe lo siguiente:
- Espere un tiempo (normalmente 30 segundos), ya que las tablas de Spark se sincronizan con retraso.
- Si la tabla no ha aparecido en el grupo de SQL sin servidor pasado algún tiempo, compruebe el esquema de la tabla Delta de Spark. Las tablas de Spark con tipos complejos o los tipos que no se admiten en la opción sin servidor no están disponibles. Intente crear una tabla Parquet de Spark con el mismo esquema en una base de datos de lago y compruebe si esa tabla aparece en el grupo de SQL sin servidor.
- Verifique que la tabla hace referencia a la carpeta Delta Lake de acceso a la identidad administrada del área de trabajo. El grupo de SQL sin servidor usa la identidad administrada del área de trabajo para obtener la información de columna de tabla del almacenamiento a fin de crear la tabla.
Base de datos de lago
Las tablas de base de datos de lago que se crean mediante el diseñador de Synapse o Spark están disponibles automáticamente en el grupo de SQL sin servidor para realizar consultas. Puede usar el grupo de SQL sin servidor para consultar las tablas de Parquet, CSV y Delta Lake que se crean mediante el grupo de Spark y agregar otros esquemas, vistas, procedimientos, funciones de valores de tabla y usuarios de Microsoft Entra en el rol db_datareader a la base de datos de lago. En esta sección se enumeran los posibles problemas.
Una tabla creada en Spark no está disponible en el grupo sin servidor
Es posible que las tablas creadas no estén disponibles inmediatamente en el grupo de SQL sin servidor.
- Las tablas estarán disponibles en los grupos sin servidor con algún retraso. Es posible que tenga que esperar entre 5 y 10 minutos después de la creación de una tabla en Spark para verla en el grupo de SQL sin servidor.
- Solo las tablas que hacen referencia a formatos Parquet, CSV y Delta están disponibles en el grupo de SQL sin servidor. Otros tipos de tabla no están disponibles.
- Una tabla que contiene algunos tipos de columna no admitidos no estará disponible en el grupo de SQL sin servidor.
- El acceso a tablas de Delta Lake en las bases de datos de lago está en versión preliminar pública. Compruebe otros problemas enumerados en esta sección o en la sección de Delta Lake.
Una tabla externa creada en Spark muestra resultados inesperados en el grupo de servidores
Puede ocurrir que haya una discrepancia entre la tabla externa de Spark de origen y la tabla externa replicada en la grupo de servidores. Esto puede ocurrir si los archivos usados en la creación de tablas externas de Spark no tienen extensiones. Para obtener los resultados adecuados, asegúrese de que todos los archivos están con extensiones como .parquet.
No se permite la operación en una base de datos replicada
Este error se devuelve si intenta modificar una base de datos de lago, crear tablas externas, orígenes de datos externos, credenciales con ámbito de base de datos u otros objetos en la base de datos de lago. Estos objetos solo se pueden crear en bases de datos SQL.
Las bases de datos de lago se replican desde el grupo de Apache Spark y se administran mediante Apache Spark. Por lo tanto, no se pueden crear objetos como en las bases de datos SQL mediante el lenguaje T-SQL.
Solo se permiten las siguientes operaciones en las bases de datos de Lake:
- Crear, quitar o modificar vistas, procedimientos y funciones de valores de tabla insertadas (iTVF) en los esquemas distintos a
dbo. - Creación y eliminación de los usuarios de la base de datos de Microsoft Entra ID.
- Agregar o quitar usuarios de base de datos del esquema
db_datareader.
No se permiten otras operaciones en las bases de datos de Lake.
Nota:
Si va a crear una vista, un procedimiento o una función en el esquema dbo (o va a omitir el esquema y usará el valor predeterminado, que suele ser dbo), obtendrá el mensaje de error.
Las tablas de Delta de las bases de datos de lago no están disponibles en el grupo de SQL sin servidor
Asegúrese de que la identidad administrada del área de trabajo tenga acceso de lectura en el almacenamiento de ADLS que contiene la carpeta de Delta. El grupo de SQL sin servidor lee el esquema de tabla de Delta Lake del registro de Delta que se coloca en ADLS y usa la identidad administrada del área de trabajo para acceder a los registros de transacciones de Delta.
Intente configurar un origen de datos en alguna instancia de SQL Database que haga referencia a Azure Data Lake Storage mediante la credencial de identidad administrada e intente crear una tabla externa sobre el origen de datos con la identidad administrada para confirmar que una tabla con la identidad administrada puede acceder al almacenamiento.
Las tablas Delta de las bases de datos de Lake no tienen un esquema idéntico en los grupos de Spark y sin servidor
Los grupos de SQL sin servidor permiten acceder a las tablas Parquet, CSV y Delta que se crean en la base de datos de Lake mediante Spark o el diseñador de Synapse. El acceso a las tablas Delta todavía está en versión preliminar pública y, actualmente, el servicio sin servidor sincronizará una tabla Delta con Spark en el momento de la creación, pero no actualizará el esquema si las columnas se agregan más adelante con la instrucción ALTER TABLE en Spark.
Esta es una limitación de la versión preliminar pública. Anule y vuelva a crear la tabla Delta en Spark (si es posible) en lugar de modificar las tablas para resolver este problema.
Tiempo de espera de consulta o degradación del rendimiento en una tabla
Cuando se modifica la tabla original en Spark o Dataverse, las tablas correspondientes del grupo sin servidor se vuelven a crear automáticamente. Este proceso tiene como consecuencia la pérdida de estadísticas existentes en la tabla. Sin estas estadísticas, las consultas de la tabla podrían experimentar retrasos o, incluso, tiempos de espera.
En caso de que se produzca este problema, considere la posibilidad de configurar un trabajo para volver a crear estadísticas en las tablas después de los cambios en Spark/Dataverse o según una programación normal.
Rendimiento
El grupo de SQL sin servidor asigna los recursos a las consultas en función del tamaño del conjunto de datos y la complejidad de las consultas. No puede cambiar ni limitar los recursos que se proporcionan a las consultas. Hay algunos casos en los que puede experimentar degradaciones inesperadas del rendimiento de las consultas y puede que deba identificar las causas principales.
La duración de la consulta es muy larga
Si tiene consultas con una duración de consulta superior a 30 minutos, la devolución de resultados al cliente será lenta. El grupo de SQL sin servidor tiene un límite de 30 minutos para la ejecución. Más tiempo se dedica a la transmisión de resultados. Pruebe estas soluciones alternativas:
- Si usa Synapse Studio, intente reproducir los problemas con alguna otra aplicación, como SQL Server Management Studio o Visual Studio Code.
- Si la consulta es lenta cuando se ejecuta mediante SQL Server Management Studio, Visual Studio Code, Power BI o alguna otra aplicación, compruebe los problemas de red y los procedimientos recomendados.
- Coloque la consulta en el comando CETAS y mida la duración de la consulta. El comando CETAS almacena los resultados en Azure Data Lake Storage y no depende de la conexión del cliente. Si el comando CETAS finaliza más rápido que la consulta original, compruebe el ancho de banda de red entre el cliente y el grupo de SQL sin servidor.
La consulta es lenta cuando se ejecuta con Synapse Studio
Si usa Synapse Studio, pruebe a usar un cliente de escritorio como SQL Server Management Studio o Visual Studio Code. Synapse Studio es un cliente web que se conecta al grupo de SQL sin servidor mediante el protocolo HTTP, que suele ser más lento que las conexiones SQL nativas que se usan en SQL Server Management Studio o Visual Studio Code.
La consulta es lenta cuando se ejecuta mediante una aplicación
Compruebe los siguientes problemas si experimenta la ejecución de consultas lentas:
- Asegúrese de que las aplicaciones cliente se coloquen con el punto de conexión del grupo de SQL sin servidor. La ejecución de una consulta en toda la región puede provocar una latencia adicional y una transmisión lenta del conjunto de resultados.
- Asegúrese de que no tiene problemas de red que puedan provocar una transmisión lenta del conjunto de resultados.
- Asegúrese de que la aplicación cliente tenga suficientes recursos (por ejemplo, no usa el 100 % de CPU).
- Asegúrese de que la cuenta de almacenamiento o el almacenamiento analítico de Azure Cosmos DB se coloquen en la misma región que el punto de conexión de SQL sin servidor.
Consulte los procedimientos recomendados para ubicar conjuntamente los recursos.
Altas variaciones en las duraciones de las consulta
Si ejecuta la misma consulta y observa variaciones en las duraciones, puede haber varias razones que pueden provocar este comportamiento:
- Compruebe si se trata de la primera ejecución de una consulta. La primera ejecución de una consulta recopila las estadísticas necesarias para crear un plan. Las estadísticas se recopilan mediante el examen de los archivos subyacentes y pueden aumentar la duración de la consulta. En Synapse Studio, verá consultas de "creación de estadísticas globales" en la lista de solicitudes SQL, que se ejecutan antes de la consulta.
- Las estadísticas pueden expirar después de algún tiempo. Puede que observe periódicamente un efecto sobre el rendimiento, ya que el grupo sin servidor debe examinar y volver a crear las estadísticas. Es posible que observe otras consultas de "creación de estadísticas globales" en la lista de solicitudes SQL, que se ejecutan antes de la consulta.
- Compruebe si hay alguna carga de trabajo que se ejecute en el mismo punto de conexión cuando se ejecutó la consulta con la duración mayor. El punto de conexión de SQL sin servidor asigna equitativamente los recursos a todas las consultas que se ejecutan en paralelo y es posible que la consulta se retrase.
Conexiones
El grupo de SQL sin servidor le permite conectarse mediante el protocolo TDS y usar el lenguaje T-SQL para consultar los datos. La mayoría de las herramientas que se pueden conectar a SQL Server o Azure SQL Database, también se pueden conectar al grupo de SQL sin servidor.
El grupo de SQL se está preparando
Después de un período más largo de inactividad, se desactivará el grupo de SQL sin servidor. La activación se realiza automáticamente en la primera actividad siguiente, por ejemplo, el primer intento de conexión. El proceso de activación puede tardar un poco más que un solo intervalo de intentos de conexión, así que se muestra el mensaje de error. Bastará con volver a realizar el intento de conexión.
Como procedimiento recomendado, para los clientes que lo admitan, use las palabras clave de cadena de conexión ConnectionRetryCount y ConnectRetryInterval para controlar el comportamiento de reconexión. La mayoría de los controladores de cliente SQL tienen el tiempo de espera de conexión predeterminado establecido en 15 segundos. Asegúrese de que el tiempo de espera de la conexión está configurado para permitir todos los reintentos. Por ejemplo, los valores elegidos deben cumplir la siguiente condición: Connection Timeout > ConnectRetryCount * ConnectionRetryInterval.
Si el mensaje de error persiste, presente una incidencia de soporte técnico mediante Azure Portal.
No es posible conectarse desde Synapse Studio
Consulte la sección sobre Synapse Studio.
No se puede conectar al grupo de Azure Synapse con una herramienta
Es posible que algunas herramientas no tengan una opción explícita que le permita conectarse al grupo de SQL sin servidor de Azure Synapse. Use una opción que usaría para conectarse a SQL Server o SQL Database. No es necesario que el cuadro de diálogo de conexión tenga la marca "Synapse" porque el grupo de SQL sin servidor usa el mismo protocolo que SQL Server o SQL Database.
Incluso si una herramienta le permite escribir solo un nombre de servidor lógico y predefine el dominio database.windows.net, coloque el nombre del área de trabajo de Azure Synapse seguido del sufijo -ondemand y el dominio database.windows.net.
Seguridad
Asegúrese de que un usuario tenga permisos para acceder a bases de datos, permisos para ejecutar comandos y permisos para acceder a Azure Data Lake o a almacenamiento de Azure Cosmos DB.
No se puede acceder a una cuenta de Azure Cosmos DB
Debe usar una clave de Azure Cosmos DB de solo lectura para acceder al almacenamiento analítico, así que asegúrese de que no ha expirado o de que no se vuelve a generar.
Si recibe el error "Error al resolver la ruta de acceso a Azure Cosmos DB", asegúrese de configurar un firewall.
No se puede acceder al lago o a la base de datos de Spark
Si un usuario no puede acceder a un lago o una base de datos de Spark, es posible que no tenga permisos para acceder a la base de datos y leerla. Un usuario con permiso CONTROL SERVER debe tener acceso total a todas las bases de datos. Como permiso restringido, puede intentar usar CONNECT ANY DATABASE y SELECT ALL USER SECURABLES.
Un usuario de SQL no puede acceder a las tablas de Dataverse
Las tablas de Dataverse acceden al almacenamiento mediante la identidad de Microsoft Entra del autor de la llamada. Un usuario de SQL con permisos elevados podría intentar seleccionar datos de una tabla, pero la tabla no podría acceder a los datos de Dataverse. Este escenario no se admite.
Errores de inicio de sesión de la entidad de servicio de Microsoft Entra cuando SPI crea una asignación de roles
Si quiere crear una asignación de roles para un identificador de entidad de servicio (SPI) o una aplicación de Microsoft Entra mediante otro SPI, o ya ha creado una, pero esta no puede iniciar sesión, es probable que reciba el siguiente error: Login error: Login failed for user '<token-identified principal>'.
En el caso de las entidades de servicio, se debe crear el inicio de sesión con un identificador de aplicación como identificador de seguridad (SID) no con un identificador de objeto. Hay una limitación conocida para las entidades de servicio, que impide que el servicio Azure Synapse recupere el identificador de aplicación de Microsoft Graph al crear una asignación de roles para otra aplicación o SPI.
Solución 1
Vaya a Azure Portal>Synapse Studio>Administrar>Control de acceso y agregue manualmente Administrador de Synapse o Administrador de Synapse SQL a la entidad de servicio deseada.
Solución 2
Debe crear manualmente un inicio de sesión adecuado con código SQL:
use master
go
CREATE LOGIN [<service_principal_name>] FROM EXTERNAL PROVIDER;
go
ALTER SERVER ROLE sysadmin ADD MEMBER [<service_principal_name>];
go
Solución 3
También puede configurar una entidad de servicio de administrador de Azure Synapse mediante PowerShell. Debe tener instalado el módulo Az.Synapse.
Esta solución es para usar el cmdlet New-AzSynapseRoleAssignment con -ObjectId "parameter". En ese campo de parámetro, proporcione el identificador de aplicación en lugar del identificador de objeto mediante las credenciales de la entidad de servicio de Azure de administrador del área de trabajo.
Script de PowerShell:
$spAppId = "<app_id_which_is_already_an_admin_on_the_workspace>"
$SPPassword = "<application_secret>"
$tenantId = "<tenant_id>"
$secpasswd = ConvertTo-SecureString -String $SPPassword -AsPlainText -Force
$cred = New-Object -TypeName System.Management.Automation.PSCredential -ArgumentList $spAppId, $secpasswd
Connect-AzAccount -ServicePrincipal -Credential $cred -Tenant $tenantId
New-AzSynapseRoleAssignment -WorkspaceName "<workspaceName>" -RoleDefinitionName "Synapse Administrator" -ObjectId "<app_id_to_add_as_admin>" [-Debug]
Nota:
En este caso, la interfaz de usuario del estudio de datos de Synapse no mostrará la asignación de roles agregada por el método anterior, por lo que se recomienda agregar la asignación de roles tanto al identificador de objeto como al identificador de aplicación al mismo tiempo para que también se pueda mostrar en la interfaz de usuario.
New-AzSynapseRoleAssignment -WorkspaceName "<workspaceName>" -RoleDefinitionName "Synapse Administrator" -ObjectId "<object_id_to_add_as_admin>" [-Debug]
Validación
Conéctese a un punto de conexión de SQL sin servidor y compruebe que se crea el inicio de sesión externo con SID (app_id_to_add_as_admin en el ejemplo anterior):
SELECT name, convert(uniqueidentifier, sid) AS sid, create_date
FROM sys.server_principals
WHERE type in ('E', 'X');
O bien, intente iniciar sesión en el punto de conexión de SQL sin servidor mediante la aplicación de administración establecida.
Restricciones
Algunas restricciones generales del sistema pueden afectar a la carga de trabajo:
| Propiedad | Limitación |
|---|---|
| Número máximo de áreas de trabajo de Azure Synapse por suscripción | Consulte los límites. |
| Número máximo de bases de datos por grupo sin servidor | 100 (sin incluir las bases de datos sincronizadas desde el grupo de Apache Spark). |
| Número máximo de bases de datos sincronizadas desde el grupo de Apache Spark | Sin limitación. |
| Número máximo de objetos de base de datos por base de datos | La suma de todos estos objetos en una base de datos no puede superar 2 147 483 647. Consulte Limitaciones del motor de base de datos de SQL Server. |
| Longitud máxima del identificador en caracteres | 128. Consulte Limitaciones del motor de base de datos de SQL Server. |
| Duración máxima de la consulta | 30 minutos. |
| Tamaño máximo del conjunto de resultados | Hasta 400 GB compartidos entre consultas simultáneas. |
| Simultaneidad máxima | No está limitada y depende de la complejidad de las consultas y la cantidad de datos analizados. Un grupo de SQL sin servidor puede manejar simultáneamente 1000 sesiones activas que ejecuten consultas ligeras. Los números se quitarán si las consultas son más complejas o examinan una mayor cantidad de datos, por lo que, en ese caso, considere la posibilidad de reducir la simultaneidad y ejecutar consultas durante un período de tiempo más largo si es posible. |
| Tamaño máximo del nombre de tabla externa | 100 caracteres. |
No se puede crear una base de datos en un grupo de SQL sin servidor
Los grupos de SQL sin servidor tienen limitaciones y no puede crear más de 100 bases de datos por área de trabajo. Si necesita separar objetos y aislarlos, use esquemas.
Si aparece el error CREATE DATABASE failed. User database limit has been already reached, significa que ha creado el número máximo de bases de datos que se admiten en un área de trabajo.
No es necesario usar bases de datos independientes para aislar los datos de distintos inquilinos. Todos los datos se almacenan externamente en un lago de datos y en Azure Cosmos DB. Los metadatos, como tabla, vistas y definiciones de función, se pueden aislar correctamente mediante esquemas. El aislamiento basado en esquemas también se usa en Spark, donde las bases de datos y los esquemas son los mismos conceptos.