Tagolt szövegformátum az Azure Data Factoryben és az Azure Synapse Analyticsben
A következőkre vonatkozik:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp.
Próbálja ki a Data Factoryt a Microsoft Fabricben, amely egy teljes körű elemzési megoldás a nagyvállalatok számára. A Microsoft Fabric az adattovábbítástól az adatelemzésig, a valós idejű elemzésig, az üzleti intelligenciáig és a jelentéskészítésig mindent lefed. Ismerje meg, hogyan indíthat új próbaverziót ingyenesen!
Kövesse ezt a cikket, ha elemezni szeretné a tagolt szövegfájlokat, vagy ha az adatokat tagolt szövegformátumba szeretné írni.
A tagolt szövegformátum a következő összekötők esetében támogatott:
- Amazon S3
- Amazon S3-kompatibilis tároló
- Azure Blob
- 1. generációs Azure Data Lake Storage
- Azure Data Lake Storage Gen2
- Azure Files
- Fájlrendszer
- FTP
- Google Cloud Storage
- HDFS
- HTTP
- Oracle Cloud Storage
- SFTP
Adathalmaz tulajdonságai
Az adathalmazok meghatározásához elérhető szakaszok és tulajdonságok teljes listáját az Adathalmazok című cikkben találja. Ez a szakasz a tagolt szöveges adatkészlet által támogatott tulajdonságok listáját tartalmazza.
| Tulajdonság | Leírás | Kötelező |
|---|---|---|
| típus | Az adathalmaz típustulajdonságának delimitedText értékre kell állítania. | Igen |
| hely | A fájl(ok) helybeállításai. Minden fájlalapú összekötő saját helytípussal és támogatott tulajdonságokkal rendelkezik a(z) < a0/> alatt location. |
Igen |
| columnDelimiter | A fájl oszlopainak elválasztásához használt karakter(ek). Az alapértelmezett érték a vessző ,. Ha az oszlopelválasztó üres sztringként van definiálva, ami azt jelenti, hogy nincs elválasztójel, a teljes sor egyetlen oszlopként lesz megadva.Az oszlopelválasztó üres sztringként jelenleg csak az adatfolyam leképezéséhez támogatott, de Copy tevékenység nem. |
Nem |
| rowDelimiter | A Copy tevékenység esetében a fájl sorainak elválasztásához használt egyetlen karakter vagy "\r\n". Az alapértelmezett érték a következő értékek bármelyike az olvasáskor: ["\r\n", "\r", "\n"]; íráskor: "\r\n". A "\r\n" csak a másolási parancsban támogatott. Az adatfolyam leképezéséhez a fájlok sorainak elválasztásához használt egy vagy két karakter. Az alapértelmezett érték a következő értékek bármelyike az olvasáskor: ["\r\n", "\r", "\n"]; íráskor: "\n". Ha a sorelválasztó nincs elválasztó (üres sztring) értékre van állítva, az oszlopelválasztót elválasztójelként (üres sztring) is be kell állítani, ami azt jelenti, hogy a teljes tartalmat egyetlen értékként kell kezelni. A sorelválasztó üres sztringként jelenleg csak az adatfolyam leképezéséhez támogatott, de Copy tevékenység nem. |
Nem |
| quoteChar | Az oszlopértékeket idéző egyetlen karakter, ha oszlopelválasztót tartalmaz. Az alapértelmezett érték a dupla idézőjel. " Ha quoteChar üres sztringként van definiálva, az azt jelenti, hogy nincs idézőjel, és az oszlop értéke nem idézőjel, és escapeChar az oszlopelválasztó és magát az oszlopelválasztót is elkerüli. |
Nem |
| escapeChar | Az idézőjelek egy adott értéken belüli feloldásához használható karakter. Az alapértelmezett érték a fordított perjel \. Ha escapeChar üres sztringként van definiálva, az quoteChar üres sztringet is be kell állítani, ebben az esetben győződjön meg arról, hogy az összes oszlopérték nem tartalmaz elválasztójeleket. |
Nem |
| firstRowAsHeader | Megadja, hogy az első sort oszlopnevekkel rendelkező fejlécsorként kell-e kezelni/készíteni. Az engedélyezett értékek igazak és hamisak (alapértelmezett). Ha az első sor fejlécként hamis, vegye figyelembe, hogy a felhasználói felület adatainak előnézete és a keresési tevékenység kimenete automatikusan létrehoz oszlopneveket Prop_{n} néven (0-tól kezdve), a másolási tevékenységhez explicit leképezésre van szükség a forrástól a fogadóig, és sorszám szerint megkeresi az oszlopokat (1-től kezdve), valamint leképezi az adatfolyam-listákat, és megkeresi a Column_{n} nevű oszlopokat (1-től kezdve). |
Nem |
| nullValue | A null érték sztring-ábrázolását adja meg. Az alapértelmezett érték üres sztring. |
Nem |
| encodingName | A tesztfájlok olvasásához/írásához használt kódolási típus. Az engedélyezett értékek a következők: "UTF-8","UTF-8 BOM nélkül", "UTF-16", "UTF-16BE", "UTF-32", "UTF-32BE", "US-ASCII", "UTF-7", "BIG5", "EUC-JP", "EUC-KR", "GB2312", "GB18030", "JOHAB", "SHIFT-JIS", "CP875", "CP866", "IBM00858", "IBM037", "IBM273", "IBM437", "IBM500", "IBM737", "IBM775", "IBM850", "IBM852", "IBM855", "IBM857", "IBM860", "IBM861", "IBM863", "IBM864", "IBM865", "IBM865", "IBM869", "IBM870", "IBM01140", "IBM01141", "IBM01142", "IBM01143", "IBM01144", "IBM01145", "IBM01146", "IBM01147", "IBM01148", "IBM01149", "ISO-2022-JP", "ISO-2022-KR", "ISO-8859-1", "ISO-8859-2", "ISO-8859-3", "ISO-8859-4", "ISO-8859-5", "ISO-8859-6", "ISO-8859-7", "ISO-8859-8", "ISO-8859-9", "ISO-8859-13", "ISO-8859-15", "WINDOWS-874", "WINDOWS-1250", "WINDOWS-1251", "WINDOWS-125 2", "WINDOWS-1253", "WINDOWS-1254", "WINDOWS-1255", "WINDOWS-1256", "WINDOWS-1257", "WINDOWS-1258". Megjegyzés: A leképezési adatfolyam nem támogatja az UTF-7 kódolást. Megjegyzés: A leképezési adatfolyam nem támogatja az UTF-8 kódolást byte Order Mark (BOM) használatával. |
Nem |
| compressionCodec | A szövegfájlok olvasásához/írásához használt tömörítési kodek. Az engedélyezett értékek a következők: bzip2, gzip, deflate, ZipDeflate, TarGzip, Tar, snappy vagy lz4. Az alapértelmezett beállítás nincs tömörítve. Vegye figyelembe, hogy Copy tevékenység jelenleg nem támogatja a "snappy" & "lz4" elemet, és a leképezési adatfolyam nem támogatja a "ZipDeflate", a "TarGzip" és a "Tar" elemet. Figyelje meg, hogy a ZipDeflate/TarGzip/Tar fájl(ok) kibontásához és a fájlalapú fogadóadattárba való íráshoz a másolási tevékenység során alapértelmezés szerint a fájlok a mappába lesznek kinyerve: <path specified in dataset>/<folder named as source compressed file>/ a másolási tevékenység forrásának használatával preserveZipFileNameAsFolder/preserveCompressionFileNameAsFolder szabályozhatja, hogy a tömörített fájl(ok) neve megmarad-e mappastruktúraként. |
Nem |
| compressionLevel | A tömörítési arány. Az engedélyezett értékek optimálisak vagy leggyorsabbak. - Leggyorsabb: A tömörítési műveletnek a lehető leggyorsabban végre kell hajtania, még akkor is, ha az eredményül kapott fájl nincs optimálisan tömörítve. - Optimális: A tömörítési műveletet optimálisan kell tömöríteni, még akkor is, ha a művelet végrehajtása hosszabb időt vesz igénybe. További információ: Tömörítési szint témakör. |
Nem |
Az alábbiakban egy példa látható az Azure Blob Storage-ban tagolt szöveges adatkészletre:
{
"name": "DelimitedTextDataset",
"properties": {
"type": "DelimitedText",
"linkedServiceName": {
"referenceName": "<Azure Blob Storage linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"typeProperties": {
"location": {
"type": "AzureBlobStorageLocation",
"container": "containername",
"folderPath": "folder/subfolder",
},
"columnDelimiter": ",",
"quoteChar": "\"",
"escapeChar": "\"",
"firstRowAsHeader": true,
"compressionCodec": "gzip"
}
}
}
Másolási tevékenység tulajdonságai
A tevékenységek meghatározásához elérhető szakaszok és tulajdonságok teljes listáját a Folyamatok című cikkben találja. Ez a szakasz a tagolt szövegforrás és fogadó által támogatott tulajdonságok listáját tartalmazza.
Elhatárolt szöveg forrásként
A másolási tevékenység *forrás* szakasza az alábbi tulajdonságokat támogatja.
| Tulajdonság | Leírás | Kötelező |
|---|---|---|
| típus | A másolási tevékenység forrásának típustulajdonságát DelimitedTextSource értékre kell állítani. | Igen |
| formatSettings | Egy tulajdonságcsoport. Tekintse meg a tagolt szöveg olvasási beállításainak alábbi táblázatát. | Nem |
| storeSettings | Az adatok adattárból való olvasására vonatkozó tulajdonságok csoportja. Minden fájlalapú összekötő saját támogatott olvasási beállításokkal rendelkezik a következő alatt storeSettings: . |
Nem |
A támogatott tagolt szövegolvasási beállítások a következő területenformatSettings:
| Tulajdonság | Leírás | Kötelező |
|---|---|---|
| típus | A formatSettings típusának delimitedTextReadSettings értékre kell állítania. | Igen |
| skipLineCount | A bemeneti fájlokból származó adatok olvasásakor kihagyandó nem üres sorok számát jelzi. Ha a skipLineCount és a firstRowAsHeader tulajdonság is meg van adva, a rendszer először kihagyja a sorokat, majd beolvassa a fejléc-információkat a bemeneti fájlból. |
Nem |
| compressionProperties | Egy adott tömörítési kodek adatainak felbontására vonatkozó tulajdonságok csoportja. | Nem |
| preserveZipFileNameAsFolder (under compressionProperties->type as ZipDeflateReadSettings) |
Akkor érvényes, ha a bemeneti adatkészlet ZipDeflate tömörítéssel van konfigurálva. Azt jelzi, hogy a másolás során meg kell-e őrizni a forrás zip-fájl nevét mappastruktúraként. - Ha igaz (alapértelmezett) értékre van állítva, a szolgáltatás a kibontott fájlokat a következőre <path specified in dataset>/<folder named as source zip file>/írja: .- Ha hamis értékre van állítva, a szolgáltatás a kibontott fájlokat közvetlenül a következőre <path specified in dataset>írja: . Győződjön meg arról, hogy nincsenek ismétlődő fájlnevek a különböző forrás zip-fájlokban, hogy elkerülje a versenyzést vagy a váratlan viselkedést. |
Nem |
| preserveCompressionFileNameAsFolder (alatt compressionProperties->type mint TarGZipReadSettings vagy TarReadSettings) |
Akkor érvényes, ha a bemeneti adatkészlet TarGzip/Tar-tömörítéssel van konfigurálva. Azt jelzi, hogy a másolás során megőrzi-e a forrás tömörített fájlnevét mappastruktúraként. - Ha igaz (alapértelmezett) értékre van állítva, a szolgáltatás a tömörített fájlokat a következőre <path specified in dataset>/<folder named as source compressed file>/írja: . - Ha hamis értékre van állítva, a szolgáltatás közvetlenül <path specified in dataset>ide írja a tömörített fájlokat. Győződjön meg arról, hogy nem duplikált fájlnevek szerepelnek a különböző forrásfájlokban, hogy elkerülje a versenyzést vagy a váratlan viselkedést. |
Nem |
"activities": [
{
"name": "CopyFromDelimitedText",
"type": "Copy",
"typeProperties": {
"source": {
"type": "DelimitedTextSource",
"storeSettings": {
"type": "AzureBlobStorageReadSettings",
"recursive": true
},
"formatSettings": {
"type": "DelimitedTextReadSettings",
"skipLineCount": 3,
"compressionProperties": {
"type": "ZipDeflateReadSettings",
"preserveZipFileNameAsFolder": false
}
}
},
...
}
...
}
]
Elhatárolt szöveg fogadóként
A másolási tevékenység *fogadó* szakasza az alábbi tulajdonságokat támogatja.
| Tulajdonság | Leírás | Kötelező |
|---|---|---|
| típus | A másolási tevékenység forrásának típustulajdonságát DelimitedTextSink értékre kell állítani. | Igen |
| formatSettings | Egy tulajdonságcsoport. Tekintse meg az alábbi tagolt szövegírási beállítások táblázatát. | Nem |
| storeSettings | Az adatok adattárba való írására vonatkozó tulajdonságok csoportja. Minden fájlalapú összekötő saját támogatott írási beállításokkal rendelkezik a .storeSettings |
Nem |
Támogatott tagolt szövegírási beállítások a következő területenformatSettings:
| Tulajdonság | Leírás | Kötelező |
|---|---|---|
| típus | A formatSettings típusának delimitedTextWriteSettings értékre kell állítania. | Igen |
| fileExtension | A kimeneti fájlok elnevezésére használt fájlkiterjesztés, például : .csv. .txt Ezt akkor kell megadni, ha a fileName kimeneti DelimitedText adatkészletben nincs megadva. Ha a fájlnév konfigurálva van a kimeneti adatkészletben, a rendszer fogadófájlnévként fogja használni, és a fájlkiterjesztési beállítás figyelmen kívül lesz hagyva. |
Igen, ha a fájlnév nincs megadva a kimeneti adatkészletben |
| maxRowsPerFile | Ha adatokat ír egy mappába, több fájlba is írhat, és megadhatja a fájlonkénti maximális sorokat. | Nem |
| fileNamePrefix | Konfiguráláskor maxRowsPerFile alkalmazható.Adja meg a fájlnév előtagot, amikor több fájlba ír adatokat, és a következő mintát eredményezte: <fileNamePrefix>_00000.<fileExtension>. Ha nincs megadva, a rendszer automatikusan létrehozza a fájlnév előtagot. Ez a tulajdonság nem érvényes, ha a forrás fájlalapú tároló vagy partícióbeállítás-kompatibilis adattár. |
Nem |
Adatfolyam-tulajdonságok leképezése
Az adatfolyamok leképezése során a következő adattárakban olvashat és írhat tagolt szövegformátumba: Azure Blob Storage, Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2 és SFTP, és az Amazon S3-ban is olvashat tagolt szövegformátumot.
Beágyazott adatkészlet
Az adatfolyamok leképezése támogatja a "beágyazott adathalmazokat" a forrás és a fogadó meghatározásához. A beágyazott, tagolt adathalmazok közvetlenül a forrás- és fogadóátalakításokon belül vannak definiálva, és nem lesznek megosztva a definiált adatfolyamon kívül. Hasznos az adathalmaz tulajdonságainak közvetlenül az adatfolyamon belüli paraméterezéséhez, és a megosztott ADF-adathalmazok jobb teljesítményének előnyeit is élvezheti.
Ha nagy számú forrásmappát és fájlt olvas, javíthatja az adatfolyam-fájlok felderítésének teljesítményét a "Felhasználó által előrejelzett séma" lehetőség beállításával a Projection | Sémabeállítások párbeszédpanel. Ez a beállítás kikapcsolja az ADF alapértelmezett séma automatikus felderítését, és jelentősen javítja a fájlfelderítés teljesítményét. A beállítás megadása előtt mindenképpen importálja a vetítést, hogy az ADF rendelkezik meglévő vetületi sémával. Ez a beállítás nem működik a sémaeltolódással.
Forrástulajdonságok
Az alábbi táblázat a tagolt szövegforrás által támogatott tulajdonságokat sorolja fel. Ezeket a tulajdonságokat a Forrás beállításai lapon szerkesztheti.
| Név | Leírás | Kötelező | Megengedett értékek | Adatfolyam-szkript tulajdonság |
|---|---|---|---|---|
| Helyettesítő kártya elérési útjai | A program minden olyan fájlt feldolgoz, amely megfelel a helyettesítő karakter elérési útjának. Felülbírálja az adathalmazban beállított mappát és fájl elérési útját. | nem | Karakterlánc[] | helyettesítő karakterekPaths |
| Partíció gyökérútvonala | A particionált fájladatok esetében megadhat egy partíció gyökérútvonalát, hogy a particionált mappákat oszlopként olvassa be | nem | Sztring | partitionRootPath |
| Fájlok listája | Azt jelzi, hogy a forrás olyan szövegfájlra mutat-e, amely felsorolja a feldolgozandó fájlokat | nem | true vagy false |
fileList |
| Többsoros sorok | A forrásfájl több sorra kiterjedő sorokat tartalmaz? A többsoros értékeknek idézőjelekben kell lenniük. | nem true vagy false |
multiLineRow | |
| A fájlnév tárolására használt oszlop | Új oszlop létrehozása a forrásfájl nevével és elérési útjával | nem | Sztring | rowUrlColumn |
| A befejezés után | A feldolgozás után törölje vagy helyezze át a fájlokat. A fájl elérési útja a tároló gyökerétől indul | nem | Törlés: true vagy false Mozog: ['<from>', '<to>'] |
purgeFiles moveFiles |
| Szűrés utoljára módosítva | Fájlok szűrésének kiválasztása az utolsó módosításuk időpontjától függően | nem | Időbélyegző | modifiedAfter modifiedBefore |
| Nem található fájl engedélyezése | Ha igaz, a rendszer nem ad hibát, ha nem található fájl | nem | true vagy false |
ignoreNoFilesFound |
| Oszlopok maximális száma | Az alapértelmezett érték 20480. Ennek az értéknek a testreszabása, ha az oszlop száma meghaladja a 20480-at | nem | Egész | maxColumns |
Feljegyzés
Az adatfolyam-források a fájllistában legfeljebb 1024 bejegyzést támogatnak. További fájlok hozzáadásához használjon helyettesítő karaktereket a fájllistában.
Példa forrásra
Az alábbi képen egy tagolt szöveges forráskonfiguráció látható az adatfolyamok leképezése során.
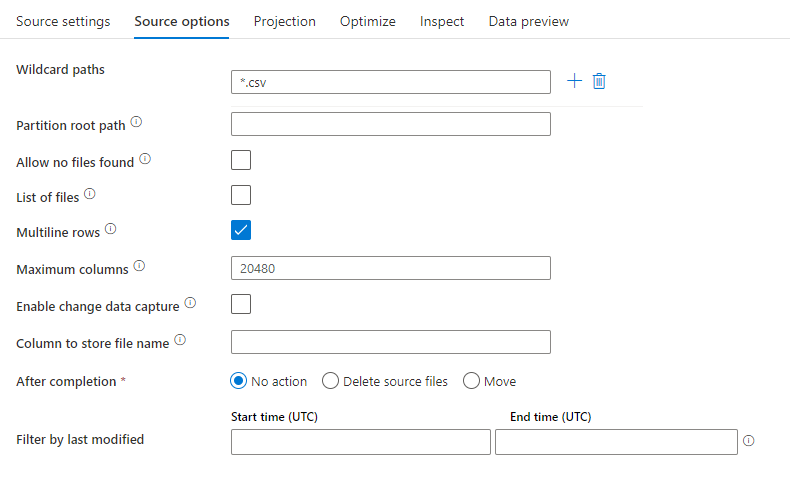
A társított adatfolyam-szkript a következő:
source(
allowSchemaDrift: true,
validateSchema: false,
ignoreNoFilesFound: false,
multiLineRow: true,
wildcardPaths:['*.csv']) ~> CSVSource
Feljegyzés
Az adatfolyam-források a Hadoop fájlrendszerei által támogatott Linux-globbing korlátozott halmazát támogatják
Fogadó tulajdonságai
Az alábbi táblázat felsorolja azokat a tulajdonságokat, amelyeket egy tagolt szövegelválasztó támogat. Ezeket a tulajdonságokat a Beállítások lapon szerkesztheti.
| Név | Leírás | Kötelező | Megengedett értékek | Adatfolyam-szkript tulajdonság |
|---|---|---|---|---|
| A mappa törlése | Ha a célmappa írás előtt törlődik | nem | true vagy false |
megcsonkít |
| Fájlnév beállítás | A megírt adatok elnevezési formátuma. Alapértelmezés szerint partíciónként egy fájl formátuma part-#####-tid-<guid> |
nem | Minta: Sztring Partíciónként: Sztring[] Névfájl oszlopadatokként: Sztring Kimenet egyetlen fájlba: ['<fileName>'] Névmappa oszlopadatokként: Sztring |
filePattern partitionFileNames rowUrlColumn partitionFileNames rowFolderUrlColumn |
| Az összes idézőjele | Az összes érték beágyazása idézőjelekbe | nem | true vagy false |
quoteAll |
| Fejléc | Ügyfélfejlécek hozzáadása kimeneti fájlokhoz | nem | [<string array>] |
header |
Fogadó példa
Az alábbi képen egy tagolt szöveg fogadó konfigurációja látható az adatfolyamok leképezése során.
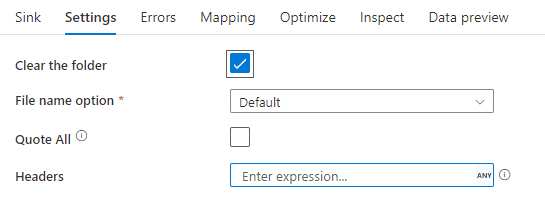
A társított adatfolyam-szkript a következő:
CSVSource sink(allowSchemaDrift: true,
validateSchema: false,
truncate: true,
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> CSVSink
Kapcsolódó összekötők és formátumok
Íme néhány gyakori összekötő és formátum a tagolt szövegformátumhoz:
- Azure Blob Storage
- Bináris formátum
- Dataverse
- Delta formátum
- Excel-formátum
- Fájlrendszer
- FTP
- HTTP
- JSON formátum
- Parquet formátum