Parquet formátum az Azure Data Factoryben és az Azure Synapse Analyticsben
A következőkre vonatkozik:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp.
Próbálja ki a Data Factoryt a Microsoft Fabricben, amely egy teljes körű elemzési megoldás a nagyvállalatok számára. A Microsoft Fabric az adattovábbítástól az adatelemzésig, a valós idejű elemzésig, az üzleti intelligenciáig és a jelentéskészítésig mindent lefed. Ismerje meg, hogyan indíthat új próbaverziót ingyenesen!
Kövesse ezt a cikket, ha elemezni szeretné a Parquet-fájlokat, vagy parquet formátumban szeretné írni az adatokat.
A parquet formátum a következő összekötők esetében támogatott:
- Amazon S3
- Amazon S3-kompatibilis tároló
- Azure Blob
- 1. generációs Azure Data Lake Storage
- Azure Data Lake Storage Gen2
- Azure Files
- Fájlrendszer
- FTP
- Google Cloud Storage
- HDFS
- HTTP
- Oracle Cloud Storage
- SFTP
Az összes elérhető összekötő támogatott funkcióinak listáját az Összekötők áttekintése című cikkben találja.
Saját üzemeltetésű integrációs modul használata
Fontos
A saját üzemeltetésű integrációs futtatókörnyezet (például a helyszíni és a felhőbeli adattárak közötti) másoláshoz, ha nem parquet-fájlokat másol, telepítenie kell a 64 bites JRE 8-at (Java Runtime Environment) vagy az OpenJDK-t az integrációs modul gépére. További részletekért tekintse meg a következő bekezdést.
A Parquet-fájlszerializálással/deszerializálással futtatott saját üzemeltetésű integrációs modulon futó példányok esetében a szolgáltatás megkeresi a Java-futtatókörnyezetet, először ellenőrizze a JRE beállításjegyzékét (SOFTWARE\JavaSoft\Java Runtime Environment\{Current Version}\JavaHome) , ha nem található, másodszor pedig ellenőrizze az OpenJDK rendszerváltozóit JAVA_HOME .
- A JRE használatához: A 64 bites integrációs modulhoz 64 bites JRE szükséges. Innen megtalálhatja.
- Az OpenJDK használata: Az INTEGRÁCIÓ 3.13-as verziója óta támogatott. Csomagolja be a jvm.dll az OpenJDK minden más szükséges szerelvényével a saját üzemeltetésű integrációs modulba, és ennek megfelelően állítsa be a rendszerkörnyezet változóját JAVA_HOME, majd indítsa újra a saját üzemeltetésű integrációs modult, hogy azonnal érvénybe lépjen.
Tipp.
Ha saját üzemeltetésű integrációs modullal másol adatokat a Parquet formátumba vagy onnan, és "Hiba történt a java meghívásakor, üzenet: java.lang.OutOfMemoryError:Java halomterület" hibaüzenet jelenik meg, hozzáadhat egy környezeti változót _JAVA_OPTIONS a saját üzemeltetésű integrációs modult futtató géphez, hogy módosítsa a JVM minimális/maximális halomméretét a másolás engedélyezése érdekében, majd futtassa újra a folyamatot.
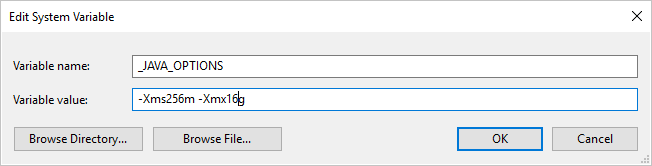
Példa: állítsa be a változót _JAVA_OPTIONS értékként -Xms256m -Xmx16g. A jelölő Xms a Java virtuális gép (JVM) kezdeti memóriafoglalási készletét adja meg, míg Xmx a maximális memóriafoglalási készletet határozza meg. Ez azt jelenti, hogy a JVM a memória mennyiségével Xms lesz elindítva, és maximális Xmx mennyiségű memóriát fog tudni használni. Alapértelmezés szerint a szolgáltatás min. 64 MB-ot és legfeljebb 1G-t használ.
Adathalmaz tulajdonságai
Az adathalmazok meghatározásához elérhető szakaszok és tulajdonságok teljes listáját az Adathalmazok című cikkben találja. Ez a szakasz a Parquet-adatkészlet által támogatott tulajdonságok listáját tartalmazza.
| Tulajdonság | Leírás | Kötelező |
|---|---|---|
| típus | Az adathalmaz típustulajdonságának Parquet értékre kell állítania. | Igen |
| hely | A fájl(ok) helybeállításai. Minden fájlalapú összekötő saját helytípussal és támogatott tulajdonságokkal rendelkezik a(z) < a0/> alatt location. Lásd az összekötőkről szóló cikk –> Adathalmaz tulajdonságai szakasz részleteit. |
Igen |
| compressionCodec | A Parquet-fájlokba való íráskor használandó tömörítési kodek. Parquet-fájlokból való olvasáskor a Data Factories automatikusan meghatározza a tömörítési kodeket a fájl metaadatai alapján. A támogatott típusok a következők: "none", "gzip", "snappy" (alapértelmezett) és "lzo". Vegye figyelembe, hogy jelenleg Copy tevékenység nem támogatja az LZO-t Parquet-fájlok olvasása/írása során. |
Nem |
Feljegyzés
A Parquet-fájlok esetében az oszlopnévben lévő üres terület nem támogatott.
Az alábbiakban egy példa látható az Azure Blob Storage Parquet-adatkészletére:
{
"name": "ParquetDataset",
"properties": {
"type": "Parquet",
"linkedServiceName": {
"referenceName": "<Azure Blob Storage linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"typeProperties": {
"location": {
"type": "AzureBlobStorageLocation",
"container": "containername",
"folderPath": "folder/subfolder",
},
"compressionCodec": "snappy"
}
}
}
Másolási tevékenység tulajdonságai
A tevékenységek meghatározásához elérhető szakaszok és tulajdonságok teljes listáját a Folyamatok című cikkben találja. Ez a szakasz a Parquet-forrás és a fogadó által támogatott tulajdonságok listáját tartalmazza.
Parquet mint forrás
A másolási tevékenység *forrás* szakasza az alábbi tulajdonságokat támogatja.
| Tulajdonság | Leírás | Kötelező |
|---|---|---|
| típus | A másolási tevékenység forrásának típustulajdonságát ParquetSource értékre kell állítani. | Igen |
| storeSettings | Az adatok adattárból való olvasására vonatkozó tulajdonságok csoportja. Minden fájlalapú összekötő saját támogatott olvasási beállításokkal rendelkezik a következő alatt storeSettings: . Az összekötőkről szóló cikk részleteinek megtekintése –> Copy tevékenység tulajdonságok szakasz. |
Nem |
Parquet mint fogadó
A másolási tevékenység *fogadó* szakasza az alábbi tulajdonságokat támogatja.
| Tulajdonság | Leírás | Kötelező |
|---|---|---|
| típus | A másolási tevékenység fogadójának típustulajdonságát ParquetSink értékre kell állítani. | Igen |
| formatSettings | Egy tulajdonságcsoport. Tekintse meg a Parquet írási beállításainak alábbi táblázatát. | Nem |
| storeSettings | Az adatok adattárba való írására vonatkozó tulajdonságok csoportja. Minden fájlalapú összekötő saját támogatott írási beállításokkal rendelkezik a .storeSettings Az összekötőkről szóló cikk részleteinek megtekintése –> Copy tevékenység tulajdonságok szakasz. |
Nem |
Támogatott parquet írási beállítások a következő területenformatSettings:
| Tulajdonság | Leírás | Kötelező |
|---|---|---|
| típus | A formatSettings típusának ParquetWriteSettings értékre kell állítania. | Igen |
| maxRowsPerFile | Ha adatokat ír egy mappába, több fájlba is írhat, és megadhatja a fájlonkénti maximális sorokat. | Nem |
| fileNamePrefix | Konfiguráláskor maxRowsPerFile alkalmazható.Adja meg a fájlnév előtagot, amikor több fájlba ír adatokat, és a következő mintát eredményezte: <fileNamePrefix>_00000.<fileExtension>. Ha nincs megadva, a rendszer automatikusan létrehozza a fájlnév előtagot. Ez a tulajdonság nem érvényes, ha a forrás fájlalapú tároló vagy partícióbeállítás-kompatibilis adattár. |
Nem |
Adatfolyam-tulajdonságok leképezése
Az adatfolyamok leképezése során a következő adattárakban olvashat és írhat parquet formátumban: Azure Blob Storage, Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2 és SFTP, valamint parquet formátumot az Amazon S3-ban.
Forrástulajdonságok
Az alábbi táblázat felsorolja a parquet-forrás által támogatott tulajdonságokat. Ezeket a tulajdonságokat a Forrás beállításai lapon szerkesztheti.
| Név | Leírás | Kötelező | Megengedett értékek | Adatfolyam-szkript tulajdonság |
|---|---|---|---|---|
| Formátum | A formátumnak parquet |
igen | parquet |
format |
| Helyettesítő kártya elérési útjai | A program minden olyan fájlt feldolgoz, amely megfelel a helyettesítő karakter elérési útjának. Felülbírálja az adathalmazban beállított mappát és fájl elérési útját. | nem | Karakterlánc[] | helyettesítő karakterekPaths |
| Partíció gyökérútvonala | A particionált fájladatok esetében megadhat egy partíció gyökérútvonalát, hogy a particionált mappákat oszlopként olvassa be | nem | Sztring | partitionRootPath |
| Fájlok listája | Azt jelzi, hogy a forrás olyan szövegfájlra mutat-e, amely felsorolja a feldolgozandó fájlokat | nem | true vagy false |
fileList |
| A fájlnév tárolására használt oszlop | Új oszlop létrehozása a forrásfájl nevével és elérési útjával | nem | Sztring | rowUrlColumn |
| A befejezés után | A feldolgozás után törölje vagy helyezze át a fájlokat. A fájl elérési útja a tároló gyökerétől indul | nem | Törlés: true vagy false Mozog: [<from>, <to>] |
purgeFiles moveFiles |
| Szűrés utoljára módosítva | Fájlok szűrésének kiválasztása az utolsó módosításuk időpontjától függően | nem | Időbélyegző | modifiedAfter modifiedBefore |
| Nem található fájl engedélyezése | Ha igaz, a rendszer nem ad hibát, ha nem található fájl | nem | true vagy false |
ignoreNoFilesFound |
Példa forrásra
Az alábbi kép egy példa egy parquet-forráskonfigurációra az adatfolyamok leképezésében.
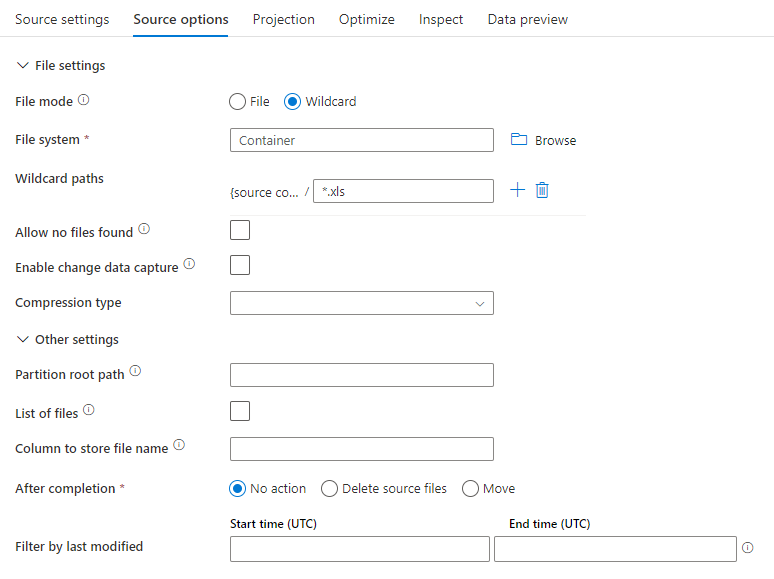
A társított adatfolyam-szkript a következő:
source(allowSchemaDrift: true,
validateSchema: false,
rowUrlColumn: 'fileName',
format: 'parquet') ~> ParquetSource
Fogadó tulajdonságai
Az alábbi táblázat a parketta-fogadó által támogatott tulajdonságokat sorolja fel. Ezeket a tulajdonságokat a Beállítások lapon szerkesztheti.
| Név | Leírás | Kötelező | Megengedett értékek | Adatfolyam-szkript tulajdonság |
|---|---|---|---|---|
| Formátum | A formátumnak parquet |
igen | parquet |
format |
| A mappa törlése | Ha a célmappa írás előtt törlődik | nem | true vagy false |
megcsonkít |
| Fájlnév beállítás | A megírt adatok elnevezési formátuma. Alapértelmezés szerint partíciónként egy fájl formátuma part-#####-tid-<guid> |
nem | Minta: Sztring Partíciónként: Sztring[] Adatok az oszlopban: Sztring Kimenet egyetlen fájlba: ['<fileName>'] |
filePattern partitionFileNames rowUrlColumn partitionFileNames |
Fogadó példa
Az alábbi képen egy parquet fogadó konfigurációja látható az adatfolyamok leképezése során.
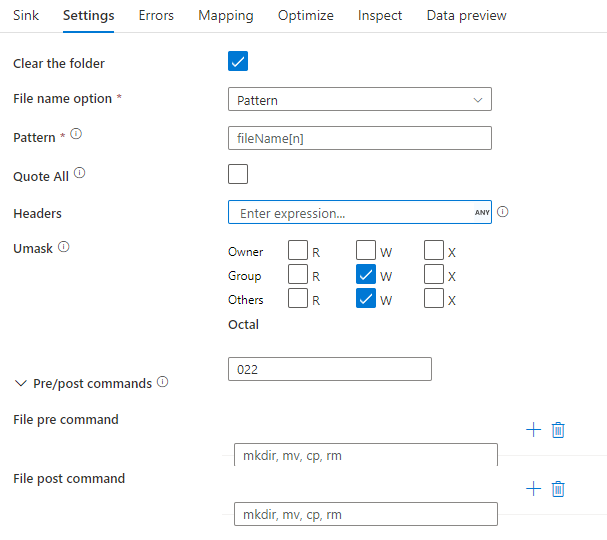
A társított adatfolyam-szkript a következő:
ParquetSource sink(
format: 'parquet',
filePattern:'output[n].parquet',
truncate: true,
allowSchemaDrift: true,
validateSchema: false,
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> ParquetSink
Adattípus támogatása
A parquet összetett adattípusok (pl. MAP, LIST, STRUCT) jelenleg csak Adatfolyam támogatottak, másolási tevékenységben nem. Ha összetett típusokat szeretne használni az adatfolyamokban, ne importálja a fájlsémát az adathalmazba, és hagyja üresen a sémát az adathalmazban. Ezután a Forrás átalakítás során importálja a vetületet.
Kapcsolódó tartalom
Visszajelzés
Hamarosan elérhető: 2024-ben fokozatosan kivezetjük a GitHub-problémákat a tartalom visszajelzési mechanizmusaként, és lecseréljük egy új visszajelzési rendszerre. További információ: https://aka.ms/ContentUserFeedback.
Visszajelzés küldése és megtekintése a következőhöz: