Külső csomagok használata Jupyter-notebookokkal a HDInsighton futó Apache Spark-fürtökben
Megtudhatja, hogyan konfigurálhat egy Jupyter Notebookot a HDInsighton futó Apache Spark-fürtben olyan külső, közösség által közreműködő Apache Maven-csomagok használatára, amelyek nem szerepelnek a fürtben.
A Maven-adattárban megkeresheti az elérhető csomagok teljes listáját. Az elérhető csomagok listáját más forrásokból is lekérheti. A Közösség által létrehozott csomagok teljes listája például elérhető a Spark Packagesben.
Ebben a cikkben megtudhatja, hogyan használhatja a spark-csv csomagot a Jupyter Notebookkal.
Előfeltételek
Apache Spark-fürt megléte a HDInsightban. További útmutatásért lásd: Apache Spark-fürt létrehozása az Azure HDInsightban.
A Jupyter-notebookok és a HDInsighton futó Spark használatának ismerete. További információ: Adatok betöltése és lekérdezések futtatása az Apache Spark on HDInsight használatával.
A fürtök elsődleges tárolójának URI-sémája . Ez az Azure Storage esetében,
abfs://az Azure Data Lake Storage Gen2 esetében lennewasb://. Ha a biztonságos átvitel engedélyezve van az Azure Storage vagy a Data Lake Storage Gen2 esetében, az URI vagyabfss://– lásd még – biztonságos átvitel leszwasbs://.
Külső csomagok használata Jupyter Notebookokkal
Keresse meg
https://CLUSTERNAME.azurehdinsight.net/jupyterCLUSTERNAMEa Spark-fürt nevét.Hozzon létre új notebookot. Válassza az Új, majd a Spark lehetőséget.
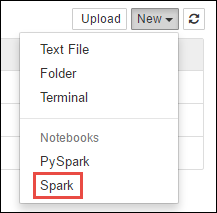
Az új notebook létrejött, és Untitled.pynb néven nyílt meg. Válassza ki a jegyzetfüzet nevét a tetején, és adjon meg egy rövid nevet.
A varázslattal
%%configurekonfigurálhatja a jegyzetfüzetet külső csomag használatára. Külső csomagokat használó jegyzetfüzetekben mindenképpen hívja meg a%%configurevarázslatot az első kódcellában. Ez biztosítja, hogy a kernel konfigurálva legyen a csomag használatára a munkamenet megkezdése előtt.Fontos
Ha elfelejtette konfigurálni a kernelt az első cellában, használhatja a
%%configure-fparamétert, de ez újraindítja a munkamenetet, és az összes folyamat elveszik.HDInsight-verzió Parancs HDInsight 3.5 és HDInsight 3.6 esetén %%configure{ "conf": {"spark.jars.packages": "com.databricks:spark-csv_2.11:1.5.0" }}HDInsight 3.3 és HDInsight 3.4 esetén %%configure{ "packages":["com.databricks:spark-csv_2.10:1.4.0"] }A fenti kódrészlet a Maven Central-adattárban lévő külső csomag maven-koordinátáit várja. Ebben a kódrészletben
com.databricks:spark-csv_2.11:1.5.0található a Spark-csv csomag maven koordinátája. Így hozhatja létre a csomagok koordinátáit.a. Keresse meg a csomagot a Maven-adattárban. Ebben a cikkben spark-csv-t használunk.
b. Az adattárból gyűjtse össze a GroupId, az ArtifactId és a Version értékeit. Győződjön meg arról, hogy az összegyűjtött értékek megfelelnek a fürtnek. Ebben az esetben Scala 2.11 és Spark 1.5.0 csomagot használunk, de előfordulhat, hogy a fürt megfelelő Scala vagy Spark-verziójához különböző verziókat kell kiválasztania. A Scala-verziót a fürtön a Spark Jupyter kernelen vagy a Spark-küldésen futtatva
scala.util.Properties.versionStringtalálhatja meg. A Spark-verziót a fürtön jupyter notebookokon futtatvasc.versiontalálja meg.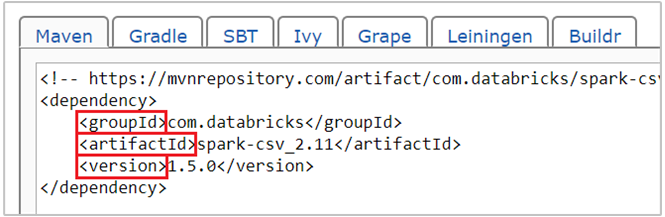
c. Fűzd össze a három értéket kettősponttal (:) elválasztva.
com.databricks:spark-csv_2.11:1.5.0Futtassa a kódcellát a
%%configurevarázslattal. Ezzel konfigurálja a mögöttes Livy-munkamenetet a megadott csomag használatára. A jegyzetfüzet későbbi celláiban mostantól használhatja a csomagot, ahogy az alább látható.val df = spark.read.format("com.databricks.spark.csv"). option("header", "true"). option("inferSchema", "true"). load("wasb:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv")A HDInsight 3.4 és újabb verzió esetén használja az alábbi kódrészletet.
val df = sqlContext.read.format("com.databricks.spark.csv"). option("header", "true"). option("inferSchema", "true"). load("wasb:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv")Ezután futtathatja a kódrészleteket, ahogyan az alább látható, az előző lépésben létrehozott adatkeretből származó adatok megtekintéséhez.
df.show() df.select("Time").count()
Lásd még
Forgatókönyvek
- Apache Spark bi-val: Interaktív adatelemzés végrehajtása a Spark in HDInsight használatával BI-eszközökkel
- Apache Spark és Machine Learning: A Spark használata a HDInsightban az épülethőmérséklet HVAC-adatokkal történő elemzéséhez
- Apache Spark és Machine Learning: A Spark használata a HDInsightban az élelmiszer-ellenőrzési eredmények előrejelzéséhez
- Webhelynapló-elemzés az Apache Spark használatával a HDInsightban
Alkalmazások létrehozása és futtatása
- Önálló alkalmazás létrehozása a Scala használatával
- Feladatok távoli futtatása Apache Spark-fürtön az Apache Livy használatával
Eszközök és bővítmények
- Külső Python-csomagok használata Jupyter-notebookokkal a HDInsight Linuxon futó Apache Spark-fürtökben
- Az IntelliJ IDEA HDInsight-eszközei beépülő moduljának használata Spark Scala-alkalmazások létrehozásához és elküldéséhez
- Az Apache Spark-alkalmazások távoli hibakereséséhez használja a HDInsight Tools beépülő modult az IntelliJ IDEA-hoz
- Apache Zeppelin-jegyzetfüzetek használata Apache Spark-fürttel a HDInsighton
- A HDInsighthoz készült Apache Spark-fürtben elérhető Jupyter Notebook-kernelek
- A Jupyter telepítése a számítógépre, majd csatlakozás egy HDInsight Spark-fürthöz