Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Petunjuk
Data Factory di Microsoft Fabric adalah generasi Azure Data Factory berikutnya, dengan arsitektur yang lebih sederhana, AI bawaan, dan fitur baru. Jika Anda baru menggunakan integrasi data, mulailah dengan Fabric Data Factory. Beban kerja ADF yang ada dapat ditingkatkan ke Fabric untuk mengakses kemampuan baru di seluruh ilmu data, analitik real time, dan pelaporan.
Artikel ini menguraikan cara menggunakan aktivitas salin di alur Azure Data Factory dan Azure Synapse untuk menyalin data dari dan ke database SQL Server dan menggunakan Data Flow untuk mengubah data dalam database SQL Server. Untuk mempelajari selengkapnya, baca artikel pengantar untuk Azure Data Factory atau Azure Synapse Analytics.
Kemampuan yang didukung
Konektor SQL Server ini didukung untuk kemampuan berikut:
| Kemampuan yang didukung | IR |
|---|---|
| Copy activity (sumber/sink) | (1) (2) |
| Memetakan aliran data (sumber/tujuan) | (1) |
| Aktivitas pencarian | (1) (2) |
| Aktivitas GetMetadata | (1) (2) |
| Aktivitas skrip | (1) (2) |
| Aktivitas prosedur tersimpan | (1) (2) |
(1) Azure runtime integrasi (2) Runtime integrasi yang dihost sendiri
Untuk daftar penyimpanan data yang didukung sebagai sumber atau sink oleh aktivitas salin, lihat tabel Penyimpanan data yang didukung.
Secara khusus, konektor SQL Server ini mendukung:
- SQL Server versi 2005 ke atas.
- Menyalin data dengan menggunakan SQL atau Windows authentication.
- Sebagai sumber, mengambil data dengan menggunakan kueri SQL atau prosedur tersimpan. Anda juga dapat memilih untuk menyalin secara paralel dari sumber SQL Server, lihat bagian Parallel dari database SQL untuk detailnya.
- Sebagai sink, secara otomatis membuat sebuah tabel tujuan jika tidak ada berdasarkan skema sumber; menambahkan data ke sebuah tabel atau memanggil prosedur tersimpan dengan logika kustom selama proses penyalinan.
SQL Server Express LocalDB tidak didukung.
Penting
Sumber data harus mendukung jenis data NVARCHAR karena memengaruhi pengodean data saat pengkodean non-universal diterapkan pada data.
Prasyarat
Jika penyimpanan data Anda terletak di dalam jaringan lokal, jaringan virtual Azure, atau Amazon Virtual Private Cloud, Anda perlu mengonfigurasi runtime integrasi yang dihosting sendiri self-hosted integration runtime untuk menyambungkannya.
Jika penyimpanan data Anda adalah layanan data cloud terkelola, Anda dapat menggunakan Azure Integration Runtime. Jika akses dibatasi untuk IP yang disetujui dalam aturan firewall, Anda dapat menambahkan IP Azure Integration Runtime ke daftar izinkan.
Anda juga dapat menggunakan fitur managed virtual network integration runtime di Azure Data Factory untuk mengakses jaringan di lokasi tanpa menginstal dan mengonfigurasi runtime integrasi yang dihosting sendiri.
Untuk informasi selengkapnya tentang mekanisme dan opsi keamanan jaringan yang didukung oleh Data Factory, lihat Strategi akses data.
Mulai sekarang
Untuk melakukan aktivitas salin dengan alur, Anda dapat menggunakan salah satu alat atau SDK berikut:
- Alat Salin Data
- Portal Azure
- .NET SDK
- Python SDK
- Azure PowerShell
- REST API
- templat Azure Resource Manager
Membuat layanan tertaut SQL Server menggunakan UI
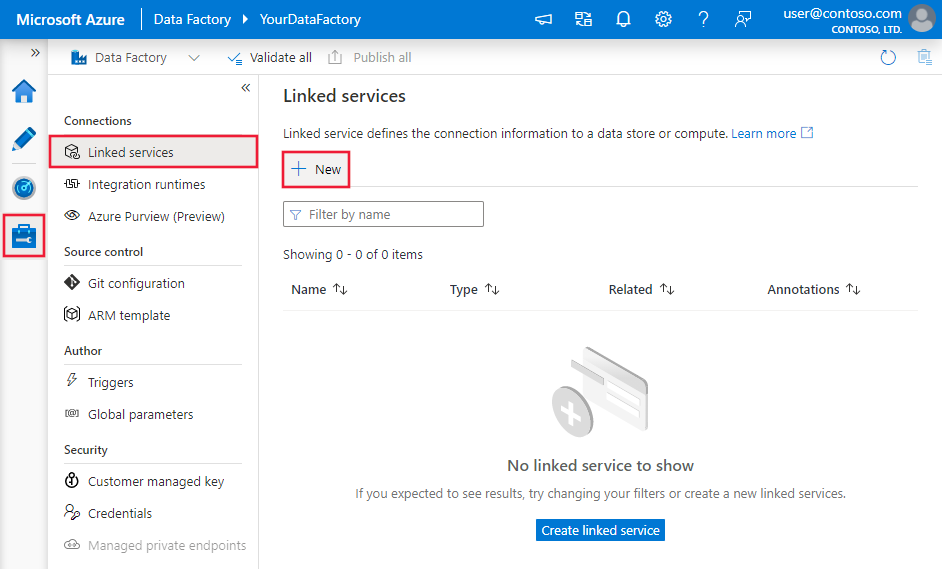
Gunakan langkah-langkah berikut untuk membuat layanan tertaut SQL Server di UI portal Azure.
Telusuri ke tab Kelola di ruang kerja Azure Data Factory atau Synapse Anda dan pilih Layanan Tertaut, lalu klik Baru:
Cari SQL dan pilih konektor SQL Server.
Screenshot dari konektor SQL Server.
Konfigurasikan detail layanan, uji koneksi, dan buat layanan tertaut baru.
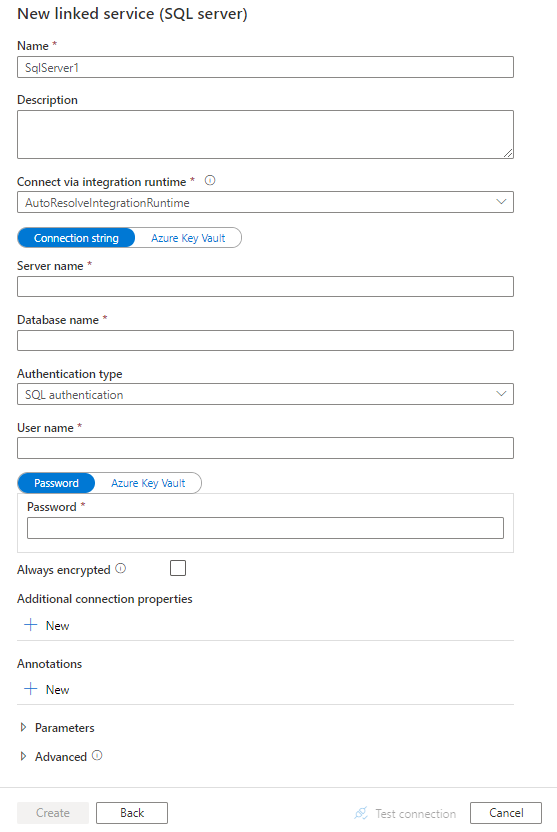
Detail konfigurasi konektor
Bagian berikut ini menyediakan detail tentang properti yang digunakan untuk menentukan entitas alur Data Factory dan Synapse khusus untuk konektor database SQL Server.
Properti layanan terhubung
Versi SQL Server Recommended mendukung TLS 1.3. Lihat section ini untuk meningkatkan layanan tertaut SQL Server jika Anda menggunakan versi Legacy. Untuk detail properti, lihat bagian yang sesuai.
Petunjuk
Jika Anda menemukan kesalahan dengan kode kesalahan "UserErrorFailedToConnectToSqlServer" dan pesan seperti "Batas sesi untuk database adalah XXX dan telah tercapai," tambahkan Pooling=false ke string koneksi Anda dan coba lagi.
Versi yang Direkomendasikan
Properti generik ini didukung untuk layanan tertaut server SQL saat Anda menerapkan versi yang Direkomendasikan :
| Properti | Deskripsi | Wajib |
|---|---|---|
| jenis | Properti jenis harus diatur ke SqlServer. | Ya |
| server | Nama atau alamat jaringan instans server SQL yang ingin Anda sambungkan. | Ya |
| database | Nama database. | Ya |
| jenisOtentikasi | Jenis yang digunakan untuk autentikasi. Nilai yang diizinkan adalah SQL (default), Windows dan UserAssignedManagedIdentity (hanya untuk SQL Server pada VM Azure). Buka bagian autentikasi yang relevan pada properti dan prasyarat tertentu. | Ya |
| pengaturanSelaluTerenkripsi | Tetapkan informasi alwaysencryptedsettings yang diperlukan untuk mengaktifkan Always Encrypted untuk melindungi data sensitif yang disimpan di server SQL dengan menggunakan identitas terkelola atau prinsip layanan. Untuk informasi selengkapnya, lihat contoh JSON mengikuti tabel dan bagian Menggunakan Always Encrypted. Jika tidak ditentukan, pengaturan default selalu dienkripsi akan dinonaktifkan. | Tidak |
| enkripsi | Menunjukkan apakah enkripsi TLS diperlukan untuk semua data yang dikirim antara klien dan server. Opsi: wajib (untuk true, default)/opsional (untuk false)/ketat. | Tidak |
| trustServerCertificate | Tunjukkan apakah saluran akan dienkripsi saat melewati rantai sertifikat untuk memvalidasi kepercayaan. | Tidak |
| NamaHostDalamSertifikat | Nama host yang digunakan saat memvalidasi sertifikat server untuk koneksi. Ketika tidak ditentukan, nama server digunakan untuk validasi sertifikat. | Tidak |
| connectVia | Runtime integrasi ini digunakan untuk menyambungkan ke penyimpanan data. Pelajari selengkapnya dari bagian Prasyarat. Jika tidak ditentukan, runtime integrasi bawaan Azure akan digunakan. | Tidak |
Untuk properti koneksi tambahan, lihat tabel di bawah ini:
| Properti | Deskripsi | Wajib |
|---|---|---|
| applicationIntent | Jenis beban kerja aplikasi saat menyambungkan ke server. Nilai yang diizinkan adalah ReadOnly dan ReadWrite. |
Tidak |
| connectTimeout | Lamanya waktu (dalam detik) untuk menunggu koneksi ke server sebelum mengakhiri upaya dan menghasilkan kesalahan. | Tidak |
| connectRetryCount | Jumlah percobaan koneksi ulang setelah mengidentifikasi kegagalan koneksi tidak aktif. Nilai harus berupa bilangan bulat antara 0 dan 255. | Tidak |
| connectRetryInterval | Jumlah waktu (dalam detik) antara setiap upaya koneksi ulang setelah mengidentifikasi kegagalan koneksi diam. Nilai harus berupa bilangan bulat antara 1 dan 60. | Tidak |
| batas waktu keseimbangan beban | Waktu minimum (dalam detik) agar koneksi hidup di kumpulan koneksi sebelum koneksi dihancurkan. | Tidak |
| commandTimeout | Waktu tunggu default (dalam detik) sebelum mengakhiri upaya untuk menjalankan perintah dan menghasilkan kesalahan. | Tidak |
| keamananTertanam | Nilai yang diizinkan adalah true atau false. Saat menentukan false, tunjukkan apakah userName dan kata sandi ditentukan dalam koneksi. Saat menentukan true, menunjukkan apakah kredensial akun Windows saat ini digunakan untuk autentikasi. |
Tidak |
| failoverPartner | Nama atau alamat server mitra yang akan disambungkan jika server utama tidak berfungsi. | Tidak |
| maxPoolSize | Jumlah maksimum koneksi yang diizinkan dalam kumpulan koneksi untuk koneksi tertentu. | Tidak |
| minPoolSize | Jumlah minimum koneksi yang diizinkan dalam kumpulan koneksi untuk koneksi tertentu. | Tidak |
| multipleActiveResultSets | Nilai yang diizinkan adalah true atau false. Saat Anda menentukan true, aplikasi dapat mempertahankan beberapa kumpulan hasil aktif (MARS). Ketika Anda menentukan false, aplikasi harus memproses atau membatalkan semua kumpulan hasil dari satu batch sebelum dapat menjalankan batch lain pada koneksi tersebut. |
Tidak |
| multiSubnetFailover | Nilai yang diizinkan adalah true atau false. Jika aplikasi Anda tersambung ke grup ketersediaan AlwaysOn (AG) pada subnet yang berbeda, atur properti ini untuk true memberikan deteksi dan koneksi yang lebih cepat ke server yang saat ini aktif. |
Tidak |
| ukuran paket | Ukuran dalam byte paket jaringan yang digunakan untuk berkomunikasi dengan instans server. | Tidak |
| Penggabungan | Nilai yang diizinkan adalah true atau false. Saat Anda menentukan true, koneksi akan dikumpulkan. Ketika Anda menentukan false, koneksi akan dibuka secara eksplisit setiap kali koneksi diminta. |
Tidak |
Autentikasi SQL
Untuk menggunakan autentikasi SQL, selain properti generik yang dijelaskan di bagian sebelumnya, tentukan properti berikut:
| Properti | Deskripsi | Wajib |
|---|---|---|
| userName | Nama pengguna yang akan digunakan saat menyambungkan ke server. | Ya |
| kata sandi | Kata sandi untuk nama pengguna. Tandai bidang ini sebagai SecureString untuk menyimpannya dengan aman. Atau, Anda dapat mengacu pada rahasia yang tersimpan di Azure Key Vault. | Tidak |
Contoh: Menggunakan autentikasi SQL
{
"name": "SqlServerLinkedService",
"properties": {
"type": "SqlServer",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "SQL",
"userName": "<user name>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Example: Gunakan autentikasi SQL dengan kata sandi di Azure Key Vault
{
"name": "SqlServerLinkedService",
"properties": {
"type": "SqlServer",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "SQL",
"userName": "<user name>",
"password": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Contoh: Gunakan Always Encrypted
{
"name": "SqlServerLinkedService",
"properties": {
"type": "SqlServer",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "SQL",
"userName": "<user name>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"alwaysEncryptedSettings": {
"alwaysEncryptedAkvAuthType": "ServicePrincipal",
"servicePrincipalId": "<service principal id>",
"servicePrincipalKey": {
"type": "SecureString",
"value": "<service principal key>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
otentikasi Windows
Untuk menggunakan Windows authentication, selain properti generik yang dijelaskan di bagian sebelumnya, tentukan properti berikut:
| Properti | Deskripsi | Wajib |
|---|---|---|
| userName | Tentukan nama pengguna. Contohnya adalah domainname\username. | Ya |
| kata sandi | Tentukan kata sandi untuk akun pengguna yang Anda tentukan untuk nama pengguna. Tandai bidang ini sebagai SecureString untuk menyimpannya dengan aman. Atau, Anda dapat mengacu pada rahasia yang tersimpan di Azure Key Vault. | Ya |
Catatan
Autentikasi Windows tidak didukung dalam aliran data.
Contoh: Gunakan autentikasi Windows
{
"name": "SqlServerLinkedService",
"properties": {
"type": "SqlServer",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "Windows",
"userName": "<domain\\username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Example: Gunakan Windows authentication dengan kata sandi di Azure Key Vault
{
"name": "SqlServerLinkedService",
"properties": {
"annotations": [],
"type": "SqlServer",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "Windows",
"userName": "<domain\\username>",
"password": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Autentikasi identitas terkelola yang ditetapkan pengguna
Catatan
Autentikasi identitas terkelola yang ditetapkan pengguna hanya berlaku untuk SQL Server pada VM Azure.
Pabrik data atau ruang kerja Synapse dapat dikaitkan dengan identitas terkelola yang ditetapkan pengguna yang mewakili layanan saat mengautentikasi ke sumber daya lain di Azure. Anda dapat menggunakan identitas terkelola ini untuk SQL Server pada Azure VM autentikasi. Pabrik yang ditunjuk atau ruang kerja Synapse dapat mengakses dan menyalin data dari atau ke database Anda dengan menggunakan identitas ini.
Untuk menggunakan autentikasi identitas terkelola yang ditetapkan pengguna, selain properti generik yang dijelaskan di bagian sebelumnya, tentukan properti berikut ini:
| Properti | Deskripsi | Wajib |
|---|---|---|
| kredensial | Tentukan identitas terkelola yang ditetapkan pengguna sebagai objek kredensial. | Ya |
Anda juga harus mengikuti langkah-langkah di bawah:
Berikan izin kepada identitas terkelola yang ditetapkan untuk pengguna Anda.
Aktifkan otentikasi Microsoft Entra ke SQL Server Anda pada VM Azure.
Buat pengguna database mandiri untuk identitas terkelola yang ditetapkan pengguna. Sambungkan ke database dari atau ke mana Anda ingin menyalin data menggunakan alat seperti SQL Server Management Studio, dengan identitas Microsoft Entra yang memiliki setidaknya izin ALTER ANY USER. Jalankan T-SQL berikut:
CREATE USER [your_resource_name] FROM EXTERNAL PROVIDER;Buat satu atau beberapa identitas terkelola yang ditetapkan pengguna dan berikan izin yang diperlukan identitas terkelola yang ditetapkan pengguna seperti yang biasa Anda lakukan untuk pengguna SQL dan lainnya. Jalankan kode berikut. Untuk opsi selengkapnya, lihat dokumen ini.
ALTER ROLE [role name] ADD MEMBER [your_resource_name];Tetapkan satu atau beberapa identitas terkelola yang ditetapkan pengguna ke pabrik data Anda dan buat info masuk untuk setiap identitas terkelola yang ditetapkan pengguna.
Mengonfigurasi layanan tertaut SQL Server.
Contoh
{
"name": "SqlServerLinkedService",
"properties": {
"type": "SqlServer",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "UserAssignedManagedIdentity",
"credential": {
"referenceName": "credential1",
"type": "CredentialReference"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Versi lama
Properti generik ini didukung untuk layanan tertaut server SQL saat Anda menerapkan versi Legacy :
| Properti | Deskripsi | Wajib |
|---|---|---|
| jenis | Properti jenis harus diatur ke SqlServer. | Ya |
| pengaturanSelaluTerenkripsi | Tetapkan informasi alwaysencryptedsettings yang diperlukan untuk mengaktifkan Always Encrypted untuk melindungi data sensitif yang disimpan di server SQL dengan menggunakan identitas terkelola atau prinsip layanan. Untuk informasi selengkapnya, lihat bagian Menggunakan Always Encrypted. Jika tidak ditentukan, pengaturan default selalu dienkripsi akan dinonaktifkan. | Tidak |
| connectVia | Runtime integrasi ini digunakan untuk menyambungkan ke penyimpanan data. Pelajari selengkapnya dari bagian Prasyarat. Jika tidak ditentukan, runtime integrasi bawaan Azure akan digunakan. | Tidak |
Konektor server SQL ini mendukung jenis autentikasi berikut. Lihat bagian terkait untuk detailnya.
Autentikasi SQL untuk versi warisan
Untuk menggunakan autentikasi SQL, selain properti generik yang dijelaskan di bagian sebelumnya, tentukan properti berikut:
| Properti | Deskripsi | Wajib |
|---|---|---|
| String Koneksi | Tentukan informasi connectionString yang diperlukan untuk menyambungkan ke database SQL Server. Tentukan nama login sebagai nama pengguna Anda, dan pastikan database yang ingin Anda sambungkan dipetakan ke login ini. | Ya |
| kata sandi | Jika Anda ingin memasukkan kata sandi ke Azure Key Vault, tarik konfigurasi password dari string koneksi. Untuk informasi selengkapnya, lihat kredensial Store di Azure Key Vault. |
Tidak |
Windows authentication untuk versi lama
Untuk menggunakan Windows authentication, selain properti generik yang dijelaskan di bagian sebelumnya, tentukan properti berikut:
| Properti | Deskripsi | Wajib |
|---|---|---|
| String Koneksi | Tentukan informasi connectionString yang diperlukan untuk menyambungkan ke database SQL Server. | Ya |
| userName | Tentukan nama pengguna. Contohnya adalah domainname\username. | Ya |
| kata sandi | Tentukan kata sandi untuk akun pengguna yang Anda tentukan untuk nama pengguna. Tandai bidang ini sebagai SecureString untuk menyimpannya dengan aman. Atau, Anda dapat mengacu pada rahasia yang tersimpan di Azure Key Vault. | Ya |
Properti himpunan data
Untuk daftar lengkap bagian dan properti yang tersedia untuk menentukan himpunan data, lihat artikel himpunan data. Bagian ini menyediakan daftar properti yang didukung oleh himpunan data SQL Server.
Untuk menyalin data dari dan ke database SQL Server, properti berikut ini didukung:
| Properti | Deskripsi | Wajib |
|---|---|---|
| jenis | Properti jenis himpunan data harus diatur ke SqlServerTable. | Ya |
| skema | Nama skema. | Tidak untuk sumber, Ya untuk penampung |
| tabel | Nama tabel/tampilan. | Tidak untuk sumber, Ya untuk penampung |
| tableName | Nama tabel/tampilan dengan skema. Properti ini didukung untuk kompatibilitas ke belakang. Untuk beban kerja baru, gunakan schema dan table. |
Tidak untuk sumber, Ya untuk penampung |
Contoh
{
"name": "SQLServerDataset",
"properties":
{
"type": "SqlServerTable",
"linkedServiceName": {
"referenceName": "<SQL Server linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"typeProperties": {
"schema": "<schema_name>",
"table": "<table_name>"
}
}
}
Properti Aktivitas Salin
Untuk daftar lengkap bagian dan properti yang tersedia untuk menentukan aktivitas, lihat artikel Pipelines. Bagian ini menyediakan daftar properti yang didukung oleh sumber dan sink SQL Server.
SQL Server sebagai sumber
Petunjuk
Untuk memuat data dari SQL Server secara efisien dengan menggunakan partisi data, pelajari selengkapnya dari Salinanparallel dari database SQL.
Untuk menyalin data dari SQL Server, atur jenis sumber dalam aktivitas salin ke SqlSource. Berikut ini properti yang didukung di bagian sumber aktivitas salin:
| Properti | Deskripsi | Wajib |
|---|---|---|
| jenis | Properti jenis sumber aktivitas salin harus diatur ke SqlSource. | Ya |
| sqlReaderQuery | Gunakan kueri SQL kustom untuk membaca data. Contohnya select * from MyTable. |
Tidak |
| sqlReaderStoredProcedureName | Properti ini adalah nama prosedur tersimpan yang membaca data dari tabel sumber. Pernyataan SQL terakhir harus merupakan pernyataan SELECT dalam prosedur tersimpan. | Tidak |
| parameterProsedurTersimpan | Parameter ini untuk prosedur tersimpan dalam basis data. Nilai yang diizinkan adalah pasangan nama atau nilai. Nama dan kapitalisasi parameter harus sesuai dengan nama dan kapitalisasi parameter prosedur tersimpan. |
Tidak |
| tingkat isolasi | Menentukan perilaku penguncian transaksi untuk sumber SQL. Nilai yang diperbolehkan adalah: ReadCommitted, ReadUncommitted, RepeatableRead, Serializable, Rekam jepret. Jika tidak ditentukan, tingkat isolasi default database digunakan. Lihat ke dokumen ini untuk detail selengkapnya. | Tidak |
| partitionOptions | Menentukan opsi partisi data yang digunakan untuk memuat data dari SQL Server. Nilai yang diizinkan adalah: Tidak ada (default), PhysicalPartitionsOfTable, dan DynamicRange. Ketika opsi partisi diaktifkan (yaitu, bukan None), tingkat paralelisme untuk memuat data secara bersamaan dari SQL Server dikendalikan oleh pengaturan parallelCopies pada aktivitas salin. |
Tidak |
| pengaturan partisi | Tentukan grup pengaturan untuk pemartisian data. Terapkan saat opsi partisi bukan None. |
Tidak |
Di bawah partitionSettings: |
||
| partitionColumnName | Tentukan nama kolom sumber dalam bilangan bulat atau jenis tanggal/waktu (int, smallint, bigint, date, smalldatetime, datetime, datetime2, atau datetimeoffset) yang akan digunakan oleh partisi rentang untuk salinan paralel. Jika tidak ditentukan, indeks atau kunci primer tabel terdeteksi secara otomatis dan digunakan sebagai kolom partisi.Terapkan saat opsi partisi adalah DynamicRange. Jika Anda menggunakan kueri untuk mengambil data sumber, kaitkan ?DfDynamicRangePartitionCondition di klausul WHERE. Misalnya, lihat bagian Penyalinan paralel dari database SQL. |
Tidak |
| partitionUpperBound | Nilai maksimum kolom partisi untuk pemisahan rentang partisi. Nilai ini digunakan untuk menentukan langkah partisi, bukan untuk memfilter baris dalam tabel. Semua baris dalam tabel atau hasil kueri akan dipartisi dan disalin. Jika tidak ditentukan, aktivitas salin secara otomatis mendeteksi nilai. Terapkan saat opsi partisi adalah DynamicRange. Misalnya, lihat bagian Penyalinan paralel dari database SQL. |
Tidak |
| partitionLowerBound | Nilai minimum kolom partisi untuk membagi rentang partisi. Nilai ini digunakan untuk menentukan langkah partisi, bukan untuk memfilter baris dalam tabel. Semua baris dalam tabel atau hasil kueri akan dipartisi dan disalin. Jika tidak ditentukan, aktivitas salin secara otomatis mendeteksi nilai. Terapkan saat opsi partisi adalah DynamicRange. Misalnya, lihat bagian Penyalinan paralel dari database SQL. |
Tidak |
Perhatikan poin-poin berikut:
- Jika sqlReaderQuery ditentukan untuk SqlSource, aktivitas salin menjalankan kueri ini terhadap sumber SQL Server untuk mendapatkan data. Anda juga dapat menentukan prosedur tersimpan dengan menentukan sqlReaderStoredProcedureName dan storedProcedureParameters jika prosedur yang disimpan mengambil parameter.
- Saat menggunakan prosedur tersimpan di sumber untuk mengambil data, perhatikan apakah prosedur tersimpan dirancang sebagai mengembalikan skema yang berbeda ketika nilai parameter yang berbeda diteruskan, Anda mungkin mengalami kegagalan atau melihat hasil yang tidak terduga saat mengimpor skema dari antarmuka pengguna atau saat menyalin data ke database SQL dengan pembuatan tabel otomatis.
Contoh: Gunakan kueri SQL
"activities":[
{
"name": "CopyFromSQLServer",
"type": "Copy",
"inputs": [
{
"referenceName": "<SQL Server input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SqlSource",
"sqlReaderQuery": "SELECT * FROM MyTable"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Contoh: Gunakan prosedur tersimpan
"activities":[
{
"name": "CopyFromSQLServer",
"type": "Copy",
"inputs": [
{
"referenceName": "<SQL Server input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SqlSource",
"sqlReaderStoredProcedureName": "CopyTestSrcStoredProcedureWithParameters",
"storedProcedureParameters": {
"stringData": { "value": "str3" },
"identifier": { "value": "$$Text.Format('{0:yyyy}', <datetime parameter>)", "type": "Int"}
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
Definisi prosedur yang disimpan
CREATE PROCEDURE CopyTestSrcStoredProcedureWithParameters
(
@stringData varchar(20),
@identifier int
)
AS
SET NOCOUNT ON;
BEGIN
select *
from dbo.UnitTestSrcTable
where dbo.UnitTestSrcTable.stringData != stringData
and dbo.UnitTestSrcTable.identifier != identifier
END
GO
SQL Server sebagai sink
Petunjuk
Pelajari selengkapnya tentang perilaku tulis, konfigurasi, dan praktik terbaik yang didukung dari Praktik terbaik untuk memuat data ke SQL Server.
Untuk menyalin data ke SQL Server, atur jenis sink dalam aktivitas salin ke SqlSink. Berikut adalah properti yang didukung di bagian tujuan aktivitas salin:
| Properti | Deskripsi | Wajib |
|---|---|---|
| jenis | Properti tipe sink aktivitas salin harus diatur ke SqlSink. | Ya |
| preCopyScript | Properti ini menentukan kueri SQL agar aktivitas salin berjalan sebelum menulis data ke SQL Server. Ini dipanggil hanya sekali per proses penyalinan. Anda dapat menggunakan properti ini untuk membersihkan data yang telah dimuat sebelumnya. | Tidak |
| opsiTabel | Menentukan apakah akan membuat tabel sink secara otomatis jika tidak ada berdasarkan skema sumber. Pembuatan tabel otomatis tidak didukung saat sink menentukan prosedur tersimpan. Nilai yang diizinkan adalah: none (default), autoCreate. |
Tidak |
| sqlWriterStoredProcedureName | Nama prosedur tersimpan yang menentukan cara menerapkan data sumber ke dalam tabel target. Prosedur tersimpan ini digunakan per batch. Untuk operasi yang hanya berjalan sekali dan tidak ada hubungannya dengan data sumber, misalnya, menghapus atau memotong, gunakan preCopyScript properti.Lihat contoh dari Memanggil prosedur tersimpan dari sink SQL. |
Tidak |
| ProsedurTersimpanJenisTabelNamaParameter | Nama parameter dari jenis tabel yang ditentukan dalam prosedur tersimpan. | Tidak |
| sqlWriterTableType | Tentukan nama jenis tabel yang akan digunakan dalam prosedur tersimpan. Aktivitas salin membuat data yang sedang dipindahkan tersedia dalam tabel sementara dengan jenis tabel ini. Kode prosedur tersimpan kemudian dapat menggabungkan data yang sedang disalin dengan data yang ada. | Tidak |
| parameterProsedurTersimpan | Parameter-parameter untuk prosedur tersimpan. Nilai yang diizinkan adalah pasangan nama dan nilai. Nama dan casing parameter harus sesuai dengan nama dan casing parameter prosedur yang disimpan. |
Tidak |
| writeBatchSize | Jumlah baris yang akan disisipkan ke dalam tabel SQL per batch. Nilai yang diizinkan untuk jumlah baris adalah bilangan bulat. Secara default, layanan secara dinamis menentukan ukuran batch yang sesuai berdasarkan ukuran baris. |
Tidak |
| writeBatchTimeout | Waktu tunggu untuk operasi sisipkan, upsert, dan prosedur tersimpan selesai sebelum waktu habis. Nilai yang diperbolehkan adalah untuk rentang waktu. Contohnya adalah "00:30:00" untuk 30 menit. Jika tidak ada nilai yang ditentukan, batas waktu default ke "00:30:00". |
Tidak |
| maxConcurrentConnections | Batas atas koneksi bersamaan yang ditetapkan ke penyimpanan data selama pelaksanaan aktivitas. Menentukan nilai hanya saat Anda ingin membatasi koneksi bersamaan. | Tidak |
| WriteBehavior | Tentukan perilaku tulis untuk aktivitas penyalinan untuk memuat data ke database SQL Server. Nilai yang diizinkan adalah Insert dan Upsert. Secara default, layanan menggunakan insert untuk memuat data. |
Tidak |
| upsertSettings | Tentukan grup pengaturan untuk perilaku penulisan. Terapkan saat opsi WriteBehavior adalah Upsert. |
Tidak |
Di bawah upsertSettings: |
||
| useTempDB | Tentukan apakah akan menggunakan tabel sementara global atau tabel fisik sebagai tabel sementara untuk upsert. Secara default, layanan menggunakan tabel sementara global sebagai tabel interim. nilai adalah true. |
Tidak |
| interimSchemaName | Tentukan skema interim untuk membuat tabel interim jika tabel fisik digunakan. Catatan: pengguna harus memiliki izin untuk membuat dan menghapus tabel. Secara default, tabel interim akan berbagi skema yang sama dengan tabel sink. Terapkan saat opsi useTempDB adalah False. |
Tidak |
| kunci | Tentukan nama kolom untuk identifikasi baris unik. Salah satu kunci atau serangkaian kunci dapat digunakan. Jika tidak ditentukan, kunci primer digunakan. | Tidak |
Contoh 1: Menambahkan data
"activities":[
{
"name": "CopyToSQLServer",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<SQL Server output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "SqlSink",
"tableOption": "autoCreate",
"writeBatchSize": 100000
}
}
}
]
Contoh 2: Gunakan prosedur tersimpan selama salinan
Pelajari detail selengkapnya dari Gunakan prosedur tersimpan dari sink SQL.
"activities":[
{
"name": "CopyToSQLServer",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<SQL Server output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "SqlSink",
"sqlWriterStoredProcedureName": "CopyTestStoredProcedureWithParameters",
"storedProcedureTableTypeParameterName": "MyTable",
"sqlWriterTableType": "MyTableType",
"storedProcedureParameters": {
"identifier": { "value": "1", "type": "Int" },
"stringData": { "value": "str1" }
}
}
}
}
]
Contoh 3: Memperbarui dan memasukkan data
"activities":[
{
"name": "CopyToSQLServer",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<SQL Server output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "SqlSink",
"tableOption": "autoCreate",
"writeBehavior": "upsert",
"upsertSettings": {
"useTempDB": true,
"keys": [
"<column name>"
]
},
}
}
}
]
Salin paralel dari database SQL
Konektor SQL Server dalam aktivitas salin menyediakan partisi data bawaan untuk menyalin data secara paralel. Anda dapat menemukan opsi pemartisian data pada tab Sumber aktivitas salin.
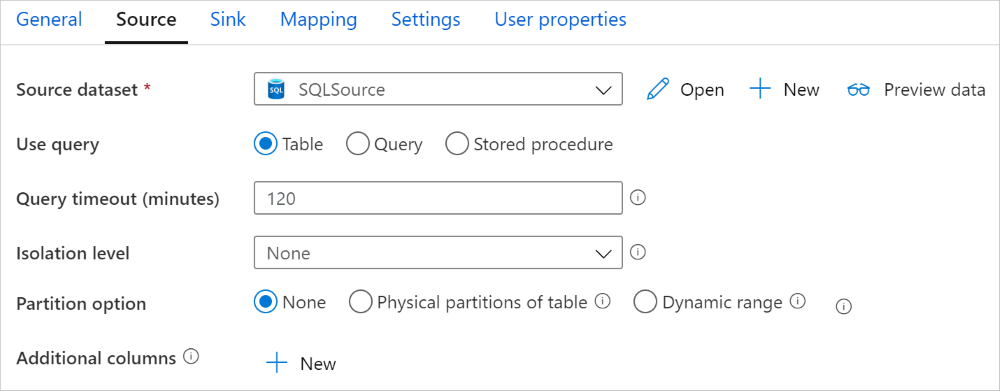
Saat Anda mengaktifkan salinan yang dipartisi, aktivitas salin menjalankan kueri paralel terhadap sumber SQL Server Anda untuk memuat data menurut partisi. Derajat paralel dikendalikan oleh pengaturan parallelCopies pada aktivitas salin. Misalnya, jika Anda mengatur parallelCopies ke empat, layanan secara bersamaan menghasilkan dan menjalankan empat kueri berdasarkan opsi dan pengaturan partisi yang Anda tentukan, dan setiap kueri mengambil sebagian data dari SQL Server Anda.
Anda disarankan untuk mengaktifkan penyalinan paralel dengan pemartisian data terutama saat Anda memuat data dalam jumlah besar dari SQL Server Anda. Berikut ini adalah konfigurasi yang disarankan untuk skenario yang berbeda. Saat menyalin data ke penyimpanan data berbasis file, disarankan untuk menulis ke folder sebagai beberapa file (hanya tentukan nama folder), dalam hal ini performanya lebih baik daripada menulis ke satu file.
| Skenario | Pengaturan yang disarankan |
|---|---|
| Proses pemuatan penuh dari tabel besar, dengan partisi fisik. |
Opsi partisi: Partisi fisik tabel. Selama eksekusi, layanan secara otomatis mendeteksi partisi fisik, dan menyalin data berdasarkan partisi. Untuk memeriksa apakah tabel Anda memiliki partisi fisik atau tidak, Anda dapat merujuk ke kueri ini. |
| Pemuatan penuh dari tabel besar, tanpa partisi fisik, tetapi dengan kolom bilangan bulat atau datetime untuk pemartisian data. |
Opsi partisi: Rentang partisi dinamis. Kolom partisi (opsional): Menentukan kolom yang digunakan untuk mempartisi data. Jika belum ditentukan, kolom kunci primer digunakan. Batas atas partisi dan batas bawah partisi (opsional): Menentukan apakah Anda ingin menentukan langkah partisi. Ini bukan untuk memfilter baris dalam tabel, semua baris dalam tabel akan dipartisi dan disalin. Jika tidak ditentukan, aktivitas penyalinan secara otomatis mendeteksi nilai dan mungkin memakan waktu lama tergantung pada nilai MIN dan MAX. Dianjurkan untuk memberikan batas atas dan batas bawah. Misalnya, jika kolom partisi "ID" Anda memiliki rentang nilai dari 1 hingga 100, dan Anda menetapkan batas bawah sebagai 20 dan batas atas sebagai 80, dengan salinan paralel sebagai 4, layanan mengambil data dengan 4 partisi - ID dalam rentang <=20, [21, 50], [51, 80], dan >=81, masing-masing. |
| Memuat sejumlah besar data dengan menggunakan kueri kustom, tanpa partisi fisik, sedangkan dengan kolom bilangan bulat atau tanggal/tanggalwaktu untuk pemartisian data. |
Opsi partisi: Rentang partisi dinamis. Kueri: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>.Kolom partisi: Menentukan kolom yang digunakan untuk mempartisi data. Batas atas partisi dan batas bawah partisi (opsional): Menentukan apakah Anda ingin menentukan langkah partisi. Ini bukan untuk memfilter baris dalam tabel, semua baris dalam hasil kueri akan dipartisi dan disalin. Jika tidak ditentukan, aktivitas salin secara otomatis mendeteksi nilai. Misalnya, jika kolom partisi "ID" Anda memiliki rentang nilai dari 1 hingga 100, dan Anda menetapkan batas bawah sebagai 20 dan batas atas sebagai 80, dengan salinan paralel sebagai 4, layanan mengambil data dengan 4 partisi- ID dalam rentang <=20, [21, 50], [51, 80], dan >=81, secara berurutan. Berikut adalah sampel kueri lainnya untuk skenario yang berbeda: 1. Kueri seluruh tabel: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition2. Kueri dari tabel dengan pemilihan kolom dan menggunakan filter klausa where tambahan: SELECT <column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>3. Kueri dengan subkueri: SELECT <column_list> FROM (<your_sub_query>) AS T WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>4. Kueri dengan partisi dalam subkueri: SELECT <column_list> FROM (SELECT <your_sub_query_column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition) AS T |
Praktik terbaik untuk memuat data dengan opsi partisi:
- Pilih kolom yang khas sebagai kolom partisi (seperti kunci primer atau kunci unik) untuk menghindari penyimpangan data.
- Jika tabel memiliki partisi bawaan, gunakan opsi partisi "Partisi fisik tabel" untuk mendapatkan performa yang lebih baik.
- Jika Anda menggunakan Azure Integration Runtime untuk menyalin data, Anda dapat mengatur "Data Integration Units (DIU) yang lebih besar " (>4) untuk menggunakan lebih banyak sumber daya komputasi. Periksa skenario yang berlaku di sana.
- "Tingkat paralelisme penyalinan mengontrol jumlah partisi. Mengatur angka ini terlalu besar kadang dapat menurunkan kinerja. Dianjurkan mengatur angka ini sebagai (DIU atau jumlah node IR yang di-host sendiri) * (2 hingga 4)."
Contoh: pemuatan penuh dari tabel besar dengan partisi fisik
"source": {
"type": "SqlSource",
"partitionOption": "PhysicalPartitionsOfTable"
}
Contoh: kueri dengan partisi rentang dinamis
"source": {
"type": "SqlSource",
"query": "SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>",
"partitionOption": "DynamicRange",
"partitionSettings": {
"partitionColumnName": "<partition_column_name>",
"partitionUpperBound": "<upper_value_of_partition_column (optional) to decide the partition stride, not as data filter>",
"partitionLowerBound": "<lower_value_of_partition_column (optional) to decide the partition stride, not as data filter>"
}
}
Sampel kueri untuk memeriksa partisi fisik
SELECT DISTINCT s.name AS SchemaName, t.name AS TableName, pf.name AS PartitionFunctionName, c.name AS ColumnName, iif(pf.name is null, 'no', 'yes') AS HasPartition
FROM sys.tables AS t
LEFT JOIN sys.objects AS o ON t.object_id = o.object_id
LEFT JOIN sys.schemas AS s ON o.schema_id = s.schema_id
LEFT JOIN sys.indexes AS i ON t.object_id = i.object_id
LEFT JOIN sys.index_columns AS ic ON ic.partition_ordinal > 0 AND ic.index_id = i.index_id AND ic.object_id = t.object_id
LEFT JOIN sys.columns AS c ON c.object_id = ic.object_id AND c.column_id = ic.column_id
LEFT JOIN sys.partition_schemes ps ON i.data_space_id = ps.data_space_id
LEFT JOIN sys.partition_functions pf ON pf.function_id = ps.function_id
WHERE s.name='[your schema]' AND t.name = '[your table name]'
Jika tabel memiliki partisi fisik, Anda akan melihat "HasPartition" sebagai "ya" seperti berikut ini.

Praktik terbaik untuk memuat data ke dalam SQL Server
Saat menyalin data ke SQL Server, Anda mungkin memerlukan perilaku tulis yang berbeda:
- Tambahkan: Data sumber saya hanya memiliki rekaman baru.
- Upsert: Data sumber saya memiliki penyisipan dan pembaruan.
- Timpa: Saya ingin memuat ulang seluruh tabel dimensi setiap saat.
- Menulis dengan logika kustom: Saya perlu pemrosesan ekstra sebelum penyisipan akhir ke dalam tabel tujuan.
Lihat bagian masing-masing untuk cara mengonfigurasi dan praktik terbaik.
Menambahkan data
Menambahkan data adalah perilaku default konektor sink SQL Server ini. Layanan melakukan penyisipan massal untuk menulis ke tabel Anda secara efisien. Anda dapat mengonfigurasi sumber dan sink sesuai dengan aktivitas salin.
Memasukkan atau memperbarui data
Copy activity sekarang mendukung memuat data secara asli ke dalam tabel sementara database dan memperbarui data dalam tabel sink jika kunci tersebut ada, dan jika tidak, menyisipkan data baru. Untuk mempelajari selengkapnya tentang pengaturan upsert dalam aktivitas salin, lihat SQL Server sebagai sink.
Timpa tabel seluruhnya
Anda dapat mengonfigurasi properti preCopyScript di bagian output aktivitas penyalinan. Dalam hal ini, untuk setiap aktivitas penyalinan yang berjalan, layanan menjalankan skrip terlebih dahulu. Kemudian menyalakan proses penyalinan untuk memasukkan data. Misalnya, untuk menimpa seluruh tabel dengan data terbaru, tentukan skrip untuk terlebih dahulu menghapus semua catatan sebelum Anda memuat data baru secara besar-besaran dari sumbernya.
Menulis data dengan logika kustom
Langkah-langkah untuk menulis data dengan logika kustom mirip dengan yang dijelaskan di bagian Meng-upsert data. Ketika Anda perlu menerapkan pemrosesan ekstra sebelum penyisipan akhir data sumber ke dalam tabel tujuan, Anda dapat memuat ke tabel pentahapan lalu menggunakan aktivitas prosedur tersimpan, atau menggunakan prosedur tersimpan di sink aktivitas salin untuk menerapkan data.
Memanggil prosedur tersimpan dari SQL sink
Saat menyalin data ke database SQL Server, Anda juga dapat mengonfigurasi dan memanggil prosedur tersimpan yang ditentukan pengguna dengan parameter tambahan pada setiap batch tabel sumber. Fitur prosedur tersimpan memanfaatkan parameter bernilai tabel. Perhatikan bahwa layanan secara otomatis mencakup prosedur tersimpan dalam transaksinya sendiri, sehingga setiap transaksi yang dibuat di dalam prosedur yang disimpan akan menjadi transaksi berlapis, dan dapat memiliki implikasi untuk penanganan pengecualian.
Anda dapat menggunakan prosedur tersimpan saat mekanisme penyalinan bawaan tidak memenuhi tujuan yang diinginkan. Contohnya adalah ketika Anda ingin menerapkan pemrosesan ekstra sebelum penyisipan akhir data sumber ke dalam tabel tujuan. Beberapa contoh pemrosesan tambahan adalah saat Anda ingin menggabungkan kolom, mencari nilai tambahan, dan menyisipkan ke dalam lebih dari satu tabel.
Contoh berikut menunjukkan cara menggunakan prosedur tersimpan untuk melakukan upsert ke dalam tabel di database SQL Server. Asumsikan bahwa data input dan tabel Pemasaran sink masing-masing memiliki tiga kolom: IDProfil, Status, dan Kategori. Lakukan upsert berdasarkan kolom IDProfil, dan hanya menerapkannya untuk kategori tertentu yang disebut "ProductA".
Di database Anda, tentukan jenis tabel dengan nama yang sama dengan sqlWriterTableType. Skema jenis tabel sama dengan skema yang dikembalikan oleh data input Anda.
CREATE TYPE [dbo].[MarketingType] AS TABLE( [ProfileID] [varchar](256) NOT NULL, [State] [varchar](256) NOT NULL, [Category] [varchar](256) NOT NULL )Di database Anda, tentukan prosedur tersimpan dengan nama yang sama dengan sqlWriterStoredProcedureName. Ini menangani data input dari sumber yang Anda tentukan dan bergabung ke dalam tabel output. Nama parameter jenis tabel dalam prosedur tersimpan sama dengan tableName yang ditentukan dalam himpunan data.
CREATE PROCEDURE spOverwriteMarketing @Marketing [dbo].[MarketingType] READONLY, @category varchar(256) AS BEGIN MERGE [dbo].[Marketing] AS target USING @Marketing AS source ON (target.ProfileID = source.ProfileID and target.Category = @category) WHEN MATCHED THEN UPDATE SET State = source.State WHEN NOT MATCHED THEN INSERT (ProfileID, State, Category) VALUES (source.ProfileID, source.State, source.Category); ENDTentukan bagian SQL sink dalam aktivitas penyalinan sebagai berikut:
"sink": { "type": "SqlSink", "sqlWriterStoredProcedureName": "spOverwriteMarketing", "storedProcedureTableTypeParameterName": "Marketing", "sqlWriterTableType": "MarketingType", "storedProcedureParameters": { "category": { "value": "ProductA" } } }
Properti pemetaan aliran data
Saat mengubah data dalam pemetaan aliran data, Anda dapat membaca dan menulis ke tabel dari database SQL Server. Untuk informasi selengkapnya, lihat transformasi sumber dan transformasi sink dalam aliran data pemetaan.
Catatan
Untuk mengakses SQL Server lokal, Anda perlu menggunakan Azure Data Factory atau ruang kerja Synapse Managed Virtual Network menggunakan titik akhir privat. Lihat tutorial ini untuk langkah-langkah terperinci.
Transformasi sumber
Tabel di bawah ini mencantumkan properti yang didukung oleh sumber SQL Server. Anda bisa mengedit properti ini di tab opsi Sumber.
| Nama | Deskripsi | Wajib | Nilai yang diizinkan | Properti skrip aliran data |
|---|---|---|---|---|
| Tabel | Jika Anda memilih Tabel sebagai input, aliran data mengambil semua data dari tabel yang ditentukan dalam himpunan data. | Tidak | - | - |
| Kueri | Jika Anda memilih Kueri sebagai input, tentukan kueri SQL untuk mengambil data dari sumber, yang menggantikan tabel apa pun yang Anda tentukan dalam himpunan data. Menggunakan kueri adalah cara yang bagus untuk mengurangi baris untuk pengujian atau pencarian. Klausa Urutkan Menurut tidak didukung, tetapi Anda dapat mengatur pernyataan SELECT FROM lengkap. Anda juga dapat menggunakan fungsi tabel yang ditentukan pengguna. pilih * dari udfGetData() adalah UDF di SQL yang menghasilkan tabel yang dapat Anda gunakan dalam aliran data. Contoh kueri: Select * from MyTable where customerId > 1000 and customerId < 2000 |
Tidak | String | kueri |
| Ukuran batch | Tentukan ukuran batch untuk membagi data besar ke dalam proses pembacaan. | Tidak | Bilangan bulat | batchSize |
| Tingkat Isolasi | Pilih salah satu tingkat isolasi berikut: - Baca Berkomitmen - Baca Tidak Dikomit (default) - Bacaan yang Dapat Diulang - Dapat diserialisasikan - Tidak ada (abaikan tingkat isolasi) |
Tidak | READ_COMMITTED READ_UNCOMMITTED "REPEATABLE_READ (Pembacaan Berulang)" SERIALIZABLE NONE |
tingkat isolasi |
| Aktifkan ekstrak inkremental | Gunakan opsi ini untuk memberi tahu ADF untuk hanya memproses baris yang telah berubah sejak terakhir kali alur dijalankan. | Tidak | - | - |
| Kolom tanggal bertahap | Saat menggunakan fitur ekstrak inkremental, Anda harus memilih kolom tanggal/waktu yang ingin Anda gunakan sebagai penanda di tabel sumber Anda. | Tidak | - | - |
| Aktifkan pengambilan data perubahan asli (Pratinjau) | Gunakan opsi ini untuk memberi tahu ADF untuk hanya memproses data delta yang diambil oleh teknologi penangkapan data perubahan SQL sejak terakhir kali pipa dieksekusi. Dengan opsi ini, data delta termasuk sisipan baris, pembaruan, dan penghapusan akan dimuat secara otomatis tanpa kolom tanggal tambahan yang diperlukan. Anda perlu penangkapan data perubahan pada SQL Server sebelum menggunakan opsi ini di ADF. Untuk informasi selengkapnya tentang opsi ini di ADF, lihat pengambilan data perubahan asli. | Tidak | - | - |
| Mulai membaca dari awal | Mengatur opsi ini dengan ekstrak inkremental akan menginstruksikan ADF untuk membaca semua baris pada eksekusi pertama alur dengan ekstrak inkremental diaktifkan. | Tidak | - | - |
Petunjuk
Ekspresi tabel umum (CTE) dalam SQL tidak didukung dalam mode Kueri aliran data pemetaan, karena prasyarat penggunaan mode ini adalah kueri dapat digunakan dalam klausul kueri SQL FROM tetapi CTE tidak dapat melakukannya. Untuk menggunakan CTE, Anda perlu membuat prosedur tersimpan menggunakan kueri berikut:
CREATE PROC CTESP @query nvarchar(max)
AS
BEGIN
EXECUTE sp_executesql @query;
END
Kemudian gunakan mode Prosedur tersimpan dalam transformasi sumber aliran data pemetaan dan atur @query seperti contoh with CTE as (select 'test' as a) select * from CTE. Kemudian Anda dapat menggunakan CTE seperti yang diharapkan.
contoh skrip sumber SQL Server
Saat Anda menggunakan SQL Server sebagai jenis sumber, skrip aliran data terkait adalah:
source(allowSchemaDrift: true,
validateSchema: false,
isolationLevel: 'READ_UNCOMMITTED',
query: 'select * from MYTABLE',
format: 'query') ~> SQLSource
Transformasi sink
Tabel di bawah ini mencantumkan properti yang didukung oleh sink SQL Server. Anda dapat mengedit properti ini di tab opsi Sink.
| Nama | Deskripsi | Wajib | Nilai yang diizinkan | Properti skrip aliran data |
|---|---|---|---|---|
| Metode pembaruan | Menentukan operasi apa yang diizinkan di tujuan database Anda. Pengaturan default adalah hanya mengizinkan sisipan. Untuk memperbarui, meningkatkan, atau menghapus baris, transformasi baris Alterdiperlukan untuk menandai baris untuk tindakan tersebut. |
Ya |
true atau false |
dapat dihapus dapat disisipkan dapat diperbarui dapat di-update atau di-insert |
| Kolom utama | Untuk pembaruan, upsert, dan penghapusan, kolom kunci harus diatur untuk menentukan baris mana yang akan diubah. Nama kolom yang Anda pilih sebagai kunci akan digunakan sebagai bagian dari pembaruan, penggabungan, atau penghapusan berikutnya. Oleh karena itu, Anda harus memilih kolom yang ada di pemetaan Sink. |
Tidak | Array | kunci |
| Lewati penulisan kolom kunci | Jika Anda ingin tidak menulis nilai ke kolom kunci, pilih "Lompati penulisan kolom kunci". | Tidak |
true atau false |
skipKeyWrites |
| Tindakan pada tabel | Menentukan apakah akan membuat ulang atau menghapus semua baris dari tabel tujuan sebelum menulis. - None: Tidak ada tindakan yang dilakukan terhadap tabel. - Buat ulang: Tabel akan dihapus dan dibuat ulang. Diperlukan jika membuat tabel baru secara dinamis. - Kosongkan: Semua baris dari tabel target akan dihapus. |
Tidak |
true atau false |
menciptakan ulang Pemangkasan |
| Ukuran batch | Menentukan berapa banyak baris yang sedang ditulis di setiap batch. Ukuran batch yang lebih besar meningkatkan kompresi dan pengoptimalan memori, tetapi berisiko mengalami pengecualian kehabisan memori saat menyimpan cache data. | Tidak | Bilangan bulat | batchSize |
| Skrip Pra dan Pasca SQL | Menentukan skrip SQL multibaris yang akan dijalankan sebelum (prapemrosesan) dan setelah (pascapemrosesan) data ditulis ke database Sink Anda. | Tidak | String | preSQL postSQLs |
Petunjuk
- Disarankan untuk membagi skrip batch tunggal yang memiliki beberapa perintah menjadi beberapa batch.
- Hanya pernyataan Bahasa Definisi Data (DDL) dan Bahasa Manipulasi Data (DML) yang menampilkan jumlah pembaruan sederhana yang dapat dijalankan sebagai bagian dari batch. Pelajari lebih lanjut mengenai Melakukan operasi batch
contoh skrip sink untuk SQL Server
Saat Anda menggunakan SQL Server sebagai jenis sink, skrip aliran data terkait adalah:
IncomingStream sink(allowSchemaDrift: true,
validateSchema: false,
deletable:false,
insertable:true,
updateable:true,
upsertable:true,
keys:['keyColumn'],
format: 'table',
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> SQLSink
Pemetaan jenis data untuk SQL Server
Saat Anda menyalin data dari dan ke SQL Server, pemetaan berikut digunakan dari jenis data SQL Server ke jenis data sementara Azure Data Factory. Pipa sinapsis, yang mengimplementasikan Data Factory, menggunakan pemetaan yang sama. Untuk mempelajari bagaimana aktivitas salin memetakan skema sumber dan tipe data ke tujuan, lihat Pemetaan skema dan tipe data.
| jenis data SQL Server | Jenis data interim di Data Factory |
|---|---|
| bigint | Int64 |
| biner | Byte[] |
| bit | Boolean |
| char | String, Char[] |
| tanggal | TanggalWaktu |
| Tanggalwaktu | TanggalWaktu |
| tanggalwaktu2 | TanggalWaktu |
| Datetimeoffset | DateTimeOffset |
| Desimal | Desimal |
| Atribut FILESTREAM (varbinary(max)) | Byte[] |
| Float | Ganda |
| citra | Byte[] |
| int | Int32 |
| uang | Desimal |
| nchar | String, Char[] |
| ntext | String, Char[] |
| numerik | Desimal |
| nvarchar | String, Char[] |
| asli | Tunggal |
| versi baris | Byte[] |
| smalldatetime | TanggalWaktu |
| smallint | Int16 |
| smallmoney | Desimal |
| sql_variant | Objek |
| kirim pesan teks | String, Char[] |
| waktu | TimeSpan |
| stempel waktu | Byte[] |
| tinyint | Int16 |
| uniqueidentifier | Guid |
| varbinary | Byte[] |
| varchar | String, Char[] |
| xml | String |
Catatan
Untuk jenis data yang memetakan ke jenis sementara Desimal, saat ini Copy activity mendukung presisi hingga 28. Jika Anda memiliki data yang memerlukan presisi lebih besar dari 28, pertimbangkan untuk mengonversi ke string dalam kueri SQL.
Saat menyalin data dari SQL Server menggunakan Azure Data Factory, jenis data bit dipetakan ke jenis data sementara Boolean. Jika Anda memiliki data yang perlu disimpan sebagai tipe data bit, gunakan kueri dengan T-SQL CAST atau CONVERT.
Properti aktivitas pencarian Lookup
Untuk mempelajari detail tentang properti, lihat Aktivitas pencarian.
Properti aktivitas GetMetadata
Untuk mempelajari rincian tentang properti ini, periksa Aktivitas GetMetadata
Menggunakan Always Encrypted
Saat Anda menyalin data dari/ke SQL Server dengan Always Encrypted, ikuti langkah-langkah di bawah ini:
Simpan Column Master Key (CMK) dalam Azure Key Vault. Pelajari selengkapnya tentang cara mengonfigurasi Always Encrypted dengan menggunakan Azure Key Vault
Pastikan untuk memberikan akses ke brankas kunci tempat Column Master Key (CMK) disimpan. Lihat artikel ini untuk izin yang diperlukan.
Buat layanan tertaut untuk terhubung ke database SQL Anda dan aktifkan fungsi 'Always Encrypted' menggunakan identitas terkelola atau perwakilan layanan.
Catatan
SQL Server Always Encrypted mendukung skenario di bawah ini:
- Baik penyimpanan data sumber atau sink menggunakan identitas terkelola atau perwakilan layanan sebagai jenis autentikasi penyedia kunci.
- Penyimpanan data sumber dan sink menggunakan identitas terkelola sebagai jenis autentikasi penyedia kunci.
- Penyimpanan data sumber dan sink menggunakan perwakilan layanan yang sama sebagai jenis autentikasi penyedia kunci.
Catatan
Saat ini, SQL Server Always Encrypted hanya didukung untuk transformasi sumber dalam pemetaan aliran data.
Penangkapan data perubahan bawaan
Azure Data Factory dapat mendukung kemampuan pengambilan data perubahan asli untuk SQL Server, Azure SQL DB, dan Azure SQL MI. Data yang diubah termasuk sisipan baris, pembaruan, dan penghapusan di penyimpanan SQL dapat secara otomatis dideteksi dan diekstrak oleh aliran data pemetaan ADF. Tanpa pengalaman kode dalam memetakan aliran data, pengguna dapat dengan mudah mencapai skenario replikasi data dari penyimpanan SQL dengan menambahkan database sebagai penyimpanan tujuan. Terlebih lagi, pengguna juga dapat menyusun logika transformasi data apa pun di antaranya untuk mencapai skenario ETL inkremental dari penyimpanan SQL.
Pastikan Anda menjaga agar nama alur dan aktivitas tidak berubah, sehingga titik pemeriksaan dapat direkam oleh ADF agar Anda mendapatkan data yang diubah dari yang terakhir dijalankan secara otomatis. Jika Anda mengubah nama alur atau nama aktivitas Anda, titik pemeriksaan akan diatur ulang, yang mengarahkan Anda untuk memulai dari awal atau mendapatkan perubahan mulai sekarang di eksekusi berikutnya. Jika Anda ingin mengubah nama jalur data atau nama aktivitas tetapi masih menyimpan titik pemeriksaan untuk mendapatkan data yang diubah dari eksekusi terakhir secara otomatis, gunakan kunci Titik Pemeriksaan Anda sendiri dalam aktivitas aliran data untuk mencapai tujuan ini.
Saat Anda men-debug alur, fitur ini berfungsi sama. Ketahuilah bahwa pos pemeriksaan akan dihapus saat Anda memuat ulang browser selama sesi debug. Setelah Anda puas dengan hasil alur dari eksekusi debug, Anda dapat melanjutkan untuk menerbitkan dan memicu alur. Pada saat Anda pertama kali memicu alur yang diterbitkan, maka secara otomatis akan dimulai ulang dari awal atau akan mendapatkan perubahan mulai saat ini.
Di bagian pemantauan, Anda selalu memiliki kesempatan untuk menjalankan ulang pipeline. Saat Anda melakukannya, data yang berubah selalu diambil dari pos pemeriksaan sebelumnya dari pelaksanaan pipeline yang Anda pilih.
Contoh 1:
Ketika Anda langsung menautkan transformasi sumber yang direferensikan ke himpunan data yang diaktifkan SQL CDC dengan transformasi sink yang direferensikan ke database dalam aliran data pemetaan, perubahan yang terjadi pada sumber SQL akan secara otomatis diterapkan ke database target, sehingga Anda akan dengan mudah mendapatkan skenario replikasi data antar database. Anda dapat menggunakan metode pembaruan dalam transformasi sink untuk memilih apakah Anda ingin mengizinkan penyisipan, mengizinkan pembaruan, atau mengizinkan penghapusan pada database target. Contoh skrip dalam pemetaan aliran data adalah seperti di bawah ini.
source(output(
id as integer,
name as string
),
allowSchemaDrift: true,
validateSchema: false,
enableNativeCdc: true,
netChanges: true,
skipInitialLoad: false,
isolationLevel: 'READ_UNCOMMITTED',
format: 'table') ~> source1
source1 sink(allowSchemaDrift: true,
validateSchema: false,
deletable:true,
insertable:true,
updateable:true,
upsertable:true,
keys:['id'],
format: 'table',
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true,
errorHandlingOption: 'stopOnFirstError') ~> sink1
Contoh 2:
Jika Anda ingin mengaktifkan skenario ETL alih-alih replikasi data antara database melalui SQL CDC, Anda dapat menggunakan ekspresi dalam memetakan aliran data termasuk isInsert(1), isUpdate(1) dan isDelete(1) untuk membedakan baris dengan jenis operasi yang berbeda. Berikut ini adalah salah satu contoh skrip untuk memetakan aliran data pada mendapatkan satu kolom dengan nilai: 1 untuk menunjukkan baris yang disisipkan, 2 untuk menunjukkan baris yang diperbarui dan 3 untuk menunjukkan baris yang dihapus untuk transformasi hilir untuk memproses data delta.
source(output(
id as integer,
name as string
),
allowSchemaDrift: true,
validateSchema: false,
enableNativeCdc: true,
netChanges: true,
skipInitialLoad: false,
isolationLevel: 'READ_UNCOMMITTED',
format: 'table') ~> source1
source1 derive(operationType = iif(isInsert(1), 1, iif(isUpdate(1), 2, 3))) ~> derivedColumn1
derivedColumn1 sink(allowSchemaDrift: true,
validateSchema: false,
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> sink1
Batasan yang diketahui:
- Hanya perubahan bersih final dari SQL CDC yang akan dimuat oleh ADF menggunakan cdc.fn_cdc_get_net_changes_.
Pemecahan masalah koneksi
Konfigurasikan instans SQL Server Anda untuk menerima koneksi jarak jauh. Mulai SQL Server Management Studio, klik kanan server, dan pilih Properti. Pilih Koneksi dari daftar, dan pilih kotak centang Perbolehkan koneksi jarak jauh ke server.
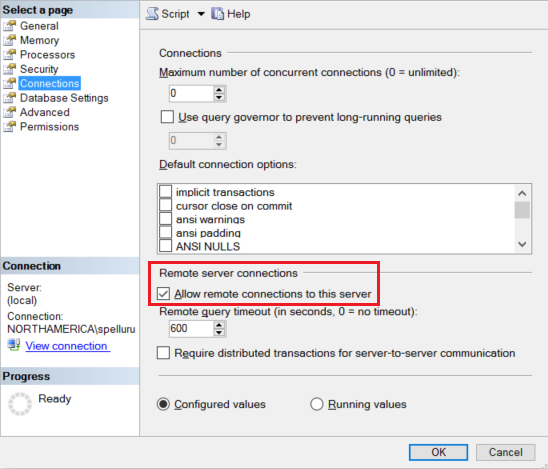
Untuk langkah-langkah yang detail, lihat Mengonfigurasi opsi konfigurasi server akses jarak jauh.
Mulai Pengelola Konfigurasi SQL Server. Perluas SQL Server Konfigurasi Jaringan untuk instans yang Anda inginkan, dan pilih Protocols untuk MSSQLSERVER. Protokol muncul di panel kanan. Aktifkan TCP/IP dengan mengklik kanan TCP/IP dan memilih Aktifkan.
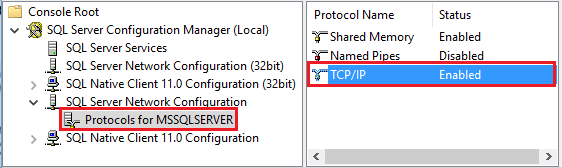
Untuk informasi selengkapnya dan cara alternatif mengaktifkan protokol TCP/IP, lihat Mengaktifkan atau menonaktifkan protokol jaringan server.
Di jendela yang sama, klik ganda TCP/IP untuk meluncurkan jendela Properti TCP/IP.
Beralih ke tab Alamat IP. Gulir ke bawah untuk melihat bagian IPAll. Tuliskan Port TCP. Defaultnya adalah 1433.
Buat rule untuk Firewall Windows pada komputer untuk memungkinkan lalu lintas masuk melalui port ini.
Verify koneksi: Untuk menyambungkan ke SQL Server dengan menggunakan nama yang sepenuhnya memenuhi syarat, gunakan SQL Server Management Studio dari komputer lain. Contohnya
"<machine>.<domain>.corp.<company>.com,1433".
Meningkatkan versi SQL Server
Untuk meningkatkan versi SQL Server, di halaman Edit layanan tertaut, pilih Recommended di bawah Version dan konfigurasikan layanan tertaut dengan merujuk ke properti layanan Linked untuk versi yang direkomendasikan.
Perbedaan antara versi yang direkomendasikan dan warisan
Tabel di bawah ini menunjukkan perbedaan antara SQL Server menggunakan versi yang direkomendasikan dan warisan.
| Versi yang Direkomendasikan | Versi lama |
|---|---|
Dukung TLS 1.3 melalui encrypt sebagai strict. |
TLS 1.3 tidak didukung. |
Konten terkait
Untuk daftar penyimpanan data yang didukung sebagai sumber dan sink oleh aktivitas salin, lihat Penyimpanan data yang didukung.